运用机器学习技术和脑电进行大脑解码
科学研究中的大脑解码
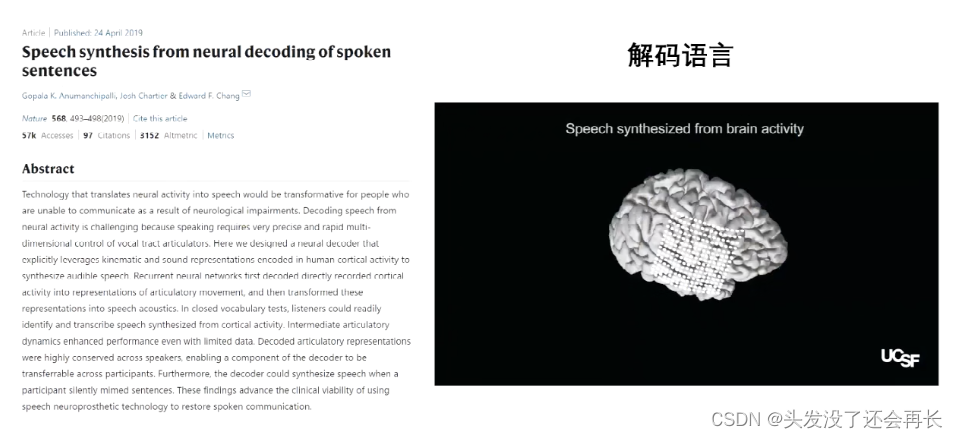
比如2019年在Nature上一篇文章,来自UCSF的Chang院士的课题组,利用大脑活动解码语言,帮助一些患者恢复语言功能。
大脑解码的重要步骤
大脑解码最重要的两步就是信号采集和信号解码 ,信号采集就是所说的脑电技术,信号解码就是机器学习的方法。

机器学习-基本流程

机器学习-数据采集
- 数据采集:确保训练和测试数据集
充足且具有代表性- 充足的数据:确保存在足够多的数据来训练分类器
- 有代表的数据:确保有意义的变化都可以从训练和测试数据采样得到
机器数据-预处理
预处理:对获取的数据进行调整,金尽可能消除各种来源的噪声滤波(去除噪声):- 有限冲激响应FIR/无限冲激响应IIR滤波
- 自适应滤波
- 空间滤波(独立成分分析)等
剔除异常值(outlier removal)归一化(normalization)
预处理-剔除异常值
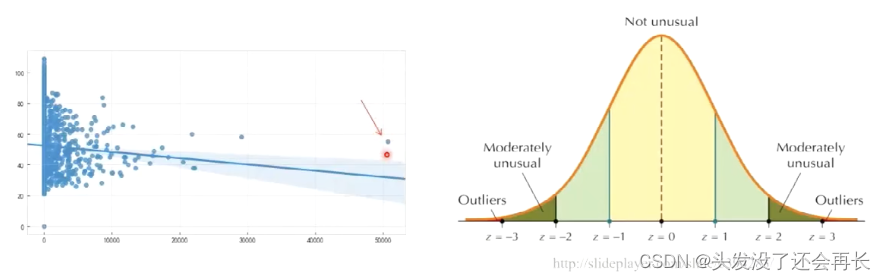
异常值(outlier):数值上与其他数据距离过于远的数据,它将极大地影响正确分类器的训练。
比如:被EOG干扰的EEG试次可能是异常值(在幅度上差别极大)。

典型方法:设置一个阈值,如果样本值大于阈值,则可以将该样本视为异常值。
例如:3标准差原则,剔除超过样本均值3个标准差的样本值(仅局限于正态或近似正态分布的样本)。
预处理-归一化
归一化(特征缩放):由于原始数据的取值范围变化很大,如果不进行归一化,某些分类器无法正常工作。- 例如,大多数分类器会计算两个样本之间的距离。如果其中一个特征的范围很广,则计算的距离将主要受该特定特征的影响。因此需要对所有特征的范围进行归一化,使每个特征对最终距离的贡献成比例。
归一化的方法有两种:标准化(standardization)和再缩放(re-scaling)

还有一种情况可采用对数变换:当特征值存在较大差异的时候,使用对数变换来减小特征值的动态范围。

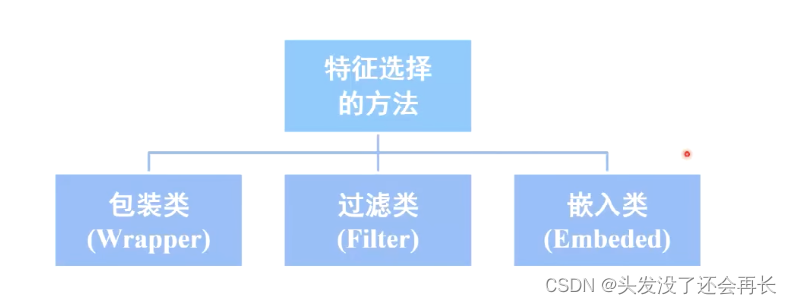
机器学习-特征提取和选择
当对正眼闭眼状态的EEG进行分类时
重要特征为枕区的 α \alpha α频段能量冗余特征可能为枕区不同通道的 α \alpha α频段能量无用特征可能为其它频段其它脑区的EEG能量
Q: 为什么要进行特征提取和选择?
A: 因为数据维数过高会面临无法找到重要特征和过拟合问题,所以需要选择有用的特征进行训练。这里用到的方法叫做降维。

降维
降维(dimension reduction):主要是由脑电研究中面临的“大数据”挑战所驱动的。
降维的重要性:
少量但信息量大的特征可以显著减少- 分类算法的复杂度
- 运行算法时对时间以及机器的需求
- 过拟合出现的可能性
- 特征提取和特征选择都是
降维过程
无监督降维-主成分分析
-
最常见的无监督降维方法为
主成分分析(Principal Component Analysis,PCA)。 -
PCA通常用于高维特征投影到底维空间中,从而有效地降低维数
-
在数学上,PCA使用正交变换将相关变量的一组观测值转换为一组被称为
主成分(Principal Components,PCs)的线性不相关变量。 -
主成分分析将观测到的数据转换到一个新的坐标系中,这样对数据进行投影后得到的最大方差就会落在第一个坐标上(即主成分),第二大方差落在第二个坐标上,以此类推。

如何理解选择方差大的特征呢? 因为PCA的目的就是选择重要的特征,重要的特征应该能够区别不同样本,方差大意味着样本在这一个特征下的区分度大,所以我们选择方差大的特征作为主成分。 -
主成分分析是一种强大的降维工具。
-
如果一个主成分的方差很小,从数据中删除这个成分后,我们只损失了少量的信息。
-
假设我们只保留L个主成分,那么新数据将只有L列,但却包含了原始数据中绝大多数的信息。

算法如下:

-
主成分分析可应用于脑电分析,以降低以下域上的维数
时间(相邻时间点信号幅度近似)频率(相邻频率点功率值相似)空间(相邻通道的脑电相似程度高)
-
原因:脑电信号在这些域内包涵冗余特征
有监督降维
有监督的降维:利用类标签来确保高纬度数据可以被映射到底维空间,且不同的类可以在这个空间中被很好的区分。

机器学习-模型选择与训练
多数分类器为二分类器(输出两个类别),但也有一些分类器允许使用两个以上的类。
多分类:将样本分为L类,其中L>2。
通常来说,多分类是利用常用的二分类器通过不同的策略来实现的:
- 一对多(One-vs.-Rest)
- 一对一(One-vs.-One)
模型选择与训练-多分类

脑电分析中常用的分类器
- 支持向量机
- 贝叶斯决策
- 决策树与随机森林
- 聚类
- 神经网络与深度学习
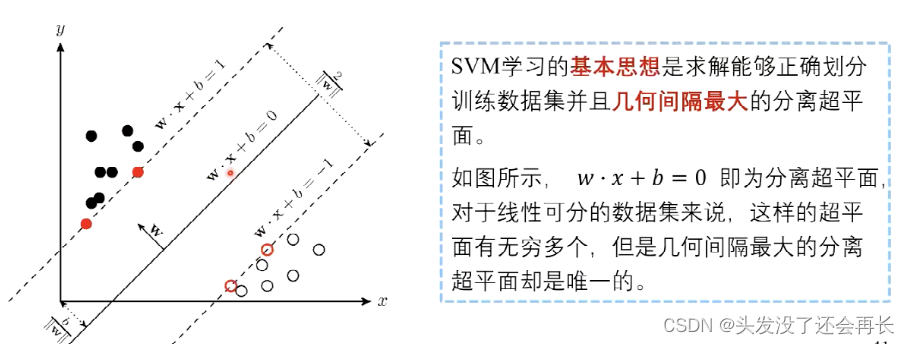
模型选择与训练-支持向量机
支持向量机(Support Vector Machine,SVM)是一类有监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面
模型选择与训练-贝叶斯决策
贝叶斯决策(Bayesian Decision Theory)是概率框架下实施的基本方法。对于分类任务来说,在所有相关概念都已知的理想情形下,贝叶斯决策论考虑如何基于这些概念和误判损失选择最优的类别标记。

模型选择与训练-决策树与随机森林
决策树(Decision Tree)是一类常见的机器学习方法。顾名思义,决策树是基于书结构来进行决策的。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶节点则对于从根节点到该叶节点所经历的路径所表示的对象的值。

模型选择与训练-聚类
聚类:将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。

模型选择与训练-神经网络与深度学习

机器学习-评估
利用训练数据完成模型选择和训练后,需要在测试数据进行广泛化性能评估

评估的方法之一是交叉验证

评估的性能度量指标

所以需要其它指标来进一步评估分类器性能