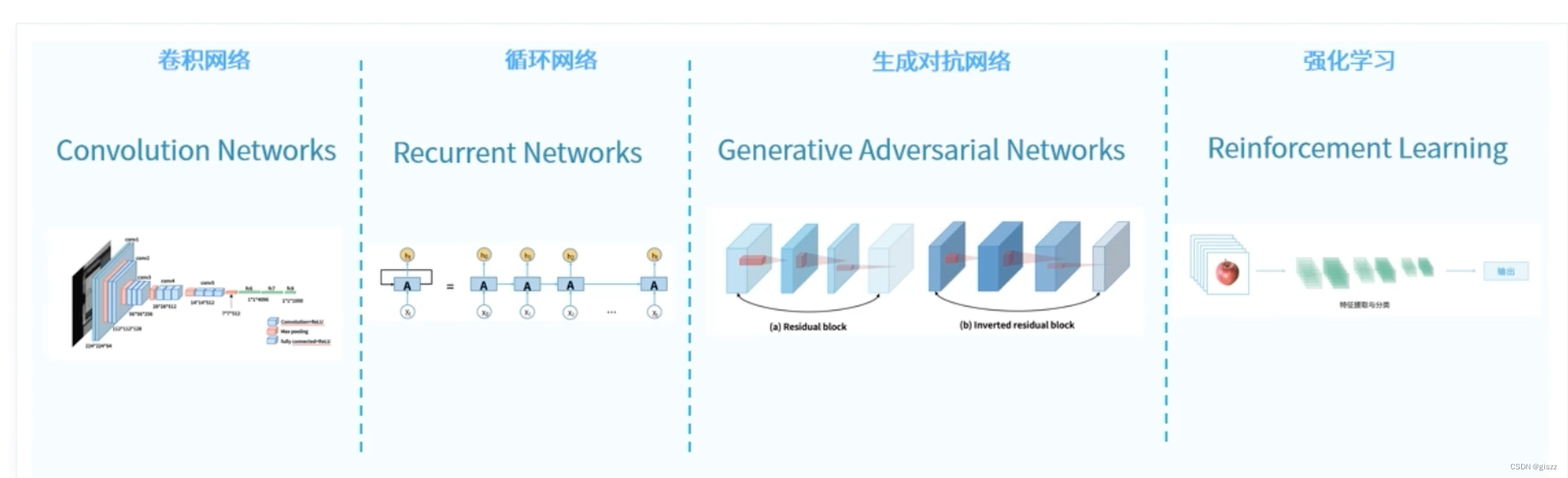
源码地址:https://gitee.com/guojialiang2023/gpt2
GPT2
- 模型
- 词表
- Tokenizer
- `Tokenizer` 类
- `_normalize` 方法
- `_tokenize` 方法
- `_CHINESE_CHAR_RANGE` 和 `_PUNCTUATION_RANGE`
- 数据集
- 语料库
- `TokenizedCorpus` 类
模型

词表
定义了一个名为 Vocab 的类,用于处理和管理一个词汇表。这个词汇表是从一个文本文件中加载的,通常用于自然语言处理任务。
-
类定义与初始化 (
__init__方法)-
Vocab类在初始化时接收几个参数:vocab_path: 一个字符串,表示词汇表文件的路径。unk_token,bos_token,eos_token,pad_token: 这些是特殊的标记,分别用于表示未知词汇、句子开始、句子结束和填充。这些特殊标记有默认值。
-
在初始化过程中,类首先会保存这些特殊标记为属性,然后从
vocab_path指定的文件中加载词汇,并将特殊标记添加到词汇表的开始。 -
self.words是一个列表,包含了所有的词汇(包括额外的特殊标记)。 -
self.vocab是一个字典,将每个词汇映射到其在列表中的索引,以便快速查找。
-
-
索引或词汇检索 (
__getitem__方法)- 这个方法允许使用词汇(字符串)或索引(整数)来检索对应的索引或词汇。如果输入是字符串,它返回该字符串对应的索引;如果输入是整数,它返回该索引对应的词汇。
-
词汇存在性检查 (
__contains__方法)- 此方法用于检查一个特定的词汇是否存在于词汇表中。
-
获取词汇表长度 (
__len__方法)- 这个方法返回词汇表的长度。这里有一个特殊的处理:词汇表的大小被调整为8的倍数。这是为了确保某些计算上的效率,如前面所讨论的。
-
特殊标记的索引属性
unk_idx,bos_idx,eos_idx,pad_idx分别提供了unk_token,bos_token,eos_token,pad_token这些特殊标记在词汇表中的索引。这对于某些处理流程(如输入预处理或模型的解码过程)是很有用的。
from typing import Unionclass Vocab(object):def __init__(self,vocab_path: str,unk_token: str = '<unk>',bos_token: str = '<s>',eos_token: str = '</s>',pad_token: str = '<pad>'):self.unk_token = unk_tokenself.bos_token = bos_tokenself.eos_token = eos_tokenself.pad_token = pad_tokenwith open(vocab_path, 'r', encoding='utf-8') as fp:self.additional_tokens = [bos_token, eos_token, pad_token]# The additional tokens would be inserted before the words.self.words = self.additional_tokens + fp.read().split()self.vocab = {word: i for i, word in enumerate(self.words)}def __getitem__(self, idx_or_token: Union[int, str]) -> Union[str, int]:if isinstance(idx_or_token, str):return self.vocab[idx_or_token]else:return self.words[idx_or_token]def __contains__(self, token: str) -> bool:return token in self.wordsdef __len__(self) -> int:# Note that vocabulary size must be a multiple of 8 although the actual# number of words is less than it.return (len(self.words) + 7) // 8 * 8@propertydef unk_idx(self) -> int:return self.vocab[self.unk_token]@propertydef bos_idx(self) -> int:return self.vocab[self.bos_token]@propertydef eos_idx(self) -> int:return self.vocab[self.eos_token]@propertydef pad_idx(self) -> int:return self.vocab[self.pad_token]注意,构建词表时,词表的长度必须为8的倍数。
在构建词表的场景中,将词表大小设置为8的倍数可以确保数据在内存中的对齐。内存对齐是指数据在内存中按照一定的边界存储,这样做可以减少CPU或GPU在访问内存时的负载,从而提高数据处理的速度和效率。如果数据没有对齐,处理器可能需要进行额外的内存访问操作来获取完整的数据,这会增加处理时间和能耗。‘
Tokenizer
代码实现了一个文本标记化(Tokenization)工具,特别适用于处理中文文本。它包含了一个Tokenizer类,这个类使用了一个词汇表(Vocab)实例和一些其他参数来进行文本的处理和标记化。下面是对代码中主要部分的详细解释:
Tokenizer 类
-
构造函数 (
__init__):vocab: 一个Vocab类的实例,包含了词汇表和一些特殊标记(如未知词标记unk_token)。max_word_len: 最大词长,默认为100。这是为了防止处理极长的单词时出现性能问题。
-
encode方法:- 输入一个字符串
text,返回一个标记化后的字符串列表。 - 它首先对文本进行标准化(
_normalize),然后对每个标准化后的词进行标记化(_tokenize)。
- 输入一个字符串
-
decode方法:- 将标记列表转换回字符串形式。
- 主要是将特殊字符(如标点符号)重新还原到它们在文本中的正确位置。
_normalize 方法
- 对输入文本进行预处理。
- 首先,它通过正则表达式删除控制字符和替换空白字符。
- 接着,它在中文字符之间插入空格,以确保在后续的标记化过程中中文字符被正确分隔。
- 最后,它对文本进行额外的分割,特别是在标点符号处进行分割。
_tokenize 方法
- 对文本进行实际的标记化处理。
- 这个方法通过对每个单词进行分解,尝试找到词汇表中的匹配项。
- 如果单词太长或者无法匹配词汇表中的任何词,它会使用未知词标记(
unk_token)。 - 对于每个词,它使用贪心算法逐步减少词的长度,直到找到词汇表中的匹配项。
_CHINESE_CHAR_RANGE 和 _PUNCTUATION_RANGE
- 这两个变量定义了用于正则表达式的字符范围。
_CHINESE_CHAR_RANGE包含了中文字符的Unicode范围。_PUNCTUATION_RANGE包含了标点符号的字符范围。
import regex as re
from data import Vocab
from typing import List_CHINESE_CHAR_RANGE = ('\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df''\U0002a700-\U0002b73f\U0002b740-\U0002b81f''\U0002b820-\U0002ceaf\uf900-\ufaff''\U0002f800-\U0002fa1f')
_PUNCTUATION_RANGE = '\\p{P}\x21-\x2f\x3a-\x40\x5b-\x60\x7b-\x7e'class Tokenizer(object):def __init__(self,vocab: Vocab,max_word_len: int = 100):self.vocab = vocabself.exclude_tokens = [vocab.unk_token] + vocab.additional_tokensself.max_word_len = max_word_lendef encode(self, text: str) -> List[str]:return [tokenfor normalized in self._normalize(text)for token in self._tokenize(normalized)]def decode(self, tokens: List[str]) -> str:return (' '.join(tokens).replace(' ##', '').replace(' .', '.').replace(' ?', '?').replace(' !', '!').replace(' ,', ',').replace(' \' ', '\'').replace(' \" ', '\"').replace('\'\'', '\' \'').replace('\"\"', "\" \""))def _normalize(self, text: str) -> List[str]:# Normalize whitespace characters and remove control characters.text = ' '.join(re.sub('[\x00\uFFFD\\p{C}]', '', t)for t in text.split())# Insert whitespaces between chinese characters.text = re.sub(f'([{_CHINESE_CHAR_RANGE}])', r' \1 ', text)normalized = []for t in text.split():if t in self.exclude_tokens:normalized.append(t)else:# Prevent from treating tokens with punctuations.normalized += re.split(f'([{_PUNCTUATION_RANGE}])', t.lower())return ' '.join(normalized).split()def _tokenize(self, text: str) -> List[str]:subwords = []for token in text.split():if len(token) > self.max_word_len:subwords.append(self.vocab.unk_token)continuechildren = []while token and token != '##':current, token = token, ''while current and current != '##':# If subword is in vocabulary, add to list and re-calibrate# the target token.if current in self.vocab:children.append(current)token = '##' + tokenbreak# If subword is not in vocabulary, reduce the search range# and test it again.current, token = current[:-1], current[-1] + token# Process current token as `unknown` since there is no any# proper tokenization (in greedy).if not current:children, token = None, Nonesubwords += children or [self.vocab.unk_token]return subwords
数据集
import torch
from typing import Optional, Dict, Anyclass Dataset(object):def skip(self, count: int):raise NotImplementedError()def fetch(self, batch: Optional[int] = None) -> Dict[str, torch.Tensor]:raise NotImplementedError()def where(self) -> Dict[str, Any]:raise NotImplementedError()def assign(self, where: Dict[str, Any]):raise NotImplementedError()语料库
代码定义了一个名为 TokenizedCorpus 的类,它继承自 Dataset 类。这个类的主要目的是为了处理一个经过分词处理的语料库,并在此基础上提供一些实用功能,适用于深度学习和自然语言处理任务中。以下是对代码的详细解释:
TokenizedCorpus 类
-
构造函数 (
__init__):corpus_path: 语料库文件的路径。vocab: 一个Vocab类的实例,包含词汇表。seq_len: 序列长度,定义了语料库中每个样本的固定长度。repeat: 一个布尔值,指示是否在语料库读取完毕后从头开始重复。
-
skip方法:- 跳过指定数量的行(即样本)。
- 如果到达文件末尾且
repeat为真,则会从文件开始处继续读取。 - 如果
repeat为假,则在达到文件末尾时抛出StopIteration异常。
-
_fetch_one方法:- 私有方法,用于获取单个样本。
- 从文件中读取一行,将其分割为标记,并将这些标记转换为它们在词汇表中的索引。
- 在序列的开始和结束添加特殊标记(如 BOS(开始标记)和 EOS(结束标记))。
- 如果必要,使用 PAD(填充标记)将序列长度扩充至
seq_len。 - 返回一个包含输入和输出序列的字典。
-
fetch方法:- 公开方法,用于获取一个或多个样本。
- 如果未指定
batch,则获取单个样本;如果指定了batch,则获取指定数量的样本。 - 将样本数据转换为 PyTorch 张量。
-
where方法:- 返回当前文件读取位置的信息。
- 这对于记录和恢复数据读取位置很有用。
-
assign方法:- 设置文件读取位置。
- 通过
where方法得到的位置信息可以用来恢复读取位置。
import torch
from gpt2.data import Dataset, Vocab
from typing import Dict, Any, List, Optionalclass TokenizedCorpus(Dataset):def __init__(self,corpus_path: str,vocab: Vocab,seq_len: int,repeat: bool = True):self.corpus_fp = open(corpus_path, 'r', encoding='utf-8')self.vocab = vocabself.seq_len = seq_lenself.repeat = repeatdef skip(self, count: int):for _ in range(count):if not self.corpus_fp.readline():# Raise error when all sequences are fetched.if not self.repeat:raise StopIteration()# Or, move to the first of the corpus.self.corpus_fp.seek(0)self.corpus_fp.readline()def _fetch_one(self) -> Dict[str, List[int]]:while True:# Read subword-tokenized sequence from corpus.line = self.corpus_fp.readline()if not line:# Raise error when all sequences are fetched.if not self.repeat:raise StopIteration()# Or, move to the first of the corpus.self.corpus_fp.seek(0)continue# Use token indices rather than the token names directly.indices = [self.vocab[t] for t in line.split()]if len(indices) + 2 > self.seq_len:continue# Decorate the sequence with additional tokens.indices = [self.vocab.bos_idx] + indices + [self.vocab.eos_idx]indices += [self.vocab.pad_idx] * (self.seq_len - len(indices) + 1)return {'input': indices[:-1], 'output': indices[1:]}def fetch(self, batch: Optional[int] = None) -> Dict[str, torch.Tensor]:if batch is None:data = self._fetch_one()else:data = [self._fetch_one() for _ in range(batch)]data = {k: [d[k] for d in data] for k in data[0]}return {k: torch.tensor(v, dtype=torch.long) for k, v in data.items()}def where(self) -> Dict[str, Any]:return {'offset': self.corpus_fp.tell()}def assign(self, where: Dict[str, Any]):self.corpus_fp.seek(where['offset'])










![[香橙派开发系列]使用蓝牙和手机进行信息的交换](https://img-blog.csdnimg.cn/img_convert/9cf17e1b539011f9b7f24231fd7bab17.png)