Python算法题集_环形链表
- 题234:环形链表
- 1. 示例说明
- 2. 题目解析
- - 题意分解
- - 优化思路
- - 测量工具
- 3. 代码展开
- 1) 标准求解【集合检索】
- 2) 改进版一【字典检测】
- 3) 改进版二【双指针】
- 4. 最优算法
本文为Python算法题集之一的代码示例
题234:环形链表
1. 示例说明
-
给你一个链表的头节点
head,判断链表中是否有环。如果链表中有某个节点,可以通过连续跟踪
next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos不作为参数进行传递 。仅仅是为了标识链表的实际情况。如果链表中存在环 ,则返回
true。 否则,返回false。示例 1:
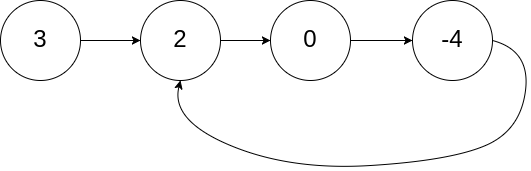
输入:head = [3,2,0,-4], pos = 1
输出:true解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
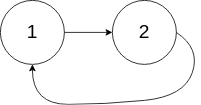
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 104] -105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。
**进阶:**你能用 O(1)(即,常量)内存解决此问题吗?
2. 题目解析
- 题意分解
- 本题为链表的值查重
- 本题的主要计算有2处,1是链表遍历,2是值比较
- 基本的解法是单层循环,必须读取链表数据后进行检测,所以基本的时间算法复杂度为O(n)
- 优化思路
-
通常优化:减少循环层次
-
通常优化:增加分支,减少计算集
-
通常优化:采用内置算法来提升计算速度
-
分析题目特点,分析最优解
-
链表需要遍历中进行值检查,为提高检索速度,可以采用哈希检索,采用
set、dict等数据结构 -
空间复杂度为O(1)的算法,一般是需要用到快慢双指针
-
- 测量工具
- 本地化测试说明:LeetCode网站测试运行时数据波动很大,因此需要本地化测试解决这个问题
CheckFuncPerf(本地化函数用时和内存占用测试模块)已上传到CSDN,地址:Python算法题集_检测函数用时和内存占用的模块- 本题很难超时,本地化超时测试用例自己生成,详见【最优算法章节】
3. 代码展开
1) 标准求解【集合检索】
采用集合set进行值检索
性能优良,超过88
import CheckFuncPerf as cfpdef hasCycle_base(head):set_checked = set() while head: if head in set_checked:return Trueset_checked.add(head) head = head.next return Falseresult = cfp.getTimeMemoryStr(hasCycle_base, head1)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 hasCycle_base 的运行时间为 27.01 ms;内存使用量为 996.00 KB 执行结果 = True
2) 改进版一【字典检测】
采用字典dict进行值检索,由于字典分配内存远大于集合,因此哈希检索的效率要低一些
马马虎虎,超过64%
import CheckFuncPerf as cfpdef hasCycle_ext1(head):dict_checked = {} while head: dict_checked[head] = dict_checked.get(head, 0)if dict_checked[head] == 1:return Truedict_checked[head] = 1head = head.next return Falseresult = cfp.getTimeMemoryStr(hasCycle_ext1, head1)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 hasCycle_ext1 的运行时间为 58.00 ms;内存使用量为 128.00 KB 执行结果 = True
3) 改进版二【双指针】
没有很多内存分配的事,空间复杂度好的算法,时间复杂度也很好
表现优异,超越95%
import CheckFuncPerf as cfpdef hasCycle_ext2(head):slownode , fastnode = head, headwhile fastnode and fastnode.next:slownode = slownode.nextfastnode = fastnode.next.nextif slownode == fastnode:breakif fastnode and fastnode.next:while head != slownode:head = head.nextslownode = slownode.nextreturn Trueelse:return Falseresult = cfp.getTimeMemoryStr(hasCycle_ext2, head1)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 hasCycle_ext2 的运行时间为 30.01 ms;内存使用量为 0.00 KB 执行结果 = True
4. 最优算法
根据本地日志分析,最优算法为第1种hasCycle_base
# 超时测试
nums = [x for x in range(200000)]
def generateOneLinkedList(data):head = ListNode(-100)iPos = 0current_node = headfor num in data:iPos += 1if iPos == 190000:CycleNode = new_nodenew_node = ListNode(num)current_node.next = new_nodecurrent_node = new_nodenew_node.next = CycleNodereturn head.next, new_node
head1, tail1 = generateOneLinkedList(nums)result = cfp.getTimeMemoryStr(hasCycle_base, head1)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 算法本地速度实测比较
函数 hasCycle_base 的运行时间为 27.01 ms;内存使用量为 996.00 KB 执行结果 = True
函数 hasCycle_ext1 的运行时间为 58.00 ms;内存使用量为 128.00 KB 执行结果 = True
函数 hasCycle_ext2 的运行时间为 30.01 ms;内存使用量为 0.00 KB 执行结果 = True
一日练,一日功,一日不练十日空
may the odds be ever in your favor ~





![[C++]继承(续)](https://img-blog.csdnimg.cn/direct/362d3f06ef344ae4be6a0042dead03a1.png)