python爬虫的BeautifulSoup4
- BeautifulSoup4
- 导入模块
- 解析文件
- 创建对象
- python解析器
- beautifulsoup对象的种类
- Tag获取整个标签
- 获取标签里的属性和属性值
- Navigablestring 获取标签里的内容
- BeautifulSoup获取整个文档
- Comment输出的内容不包含注释符号
- BeautifulSoup文档遍历
- BeautifulSoup文档搜索
BeautifulSoup4
导入模块
from bs4 import BeautifulSoup
解析文件
如果是本地文件,直接以写入权限打开,并用bs解析
with open('index.html', 'r', encoding='utf-8') as f:html = f.read()
如果是网页文件,则需要先用爬虫爬取,然后解析
response = requests.get(url=url, headers=headers)
html = response.text
创建对象
解析的第一步,是构建一个BeautifulSoup对象,基本用法:
response = requests.get(url=url, headers=headers)
html = response.text
soup = beautifulsoup(html,'html.parser') #处理html的解析器
python解析器
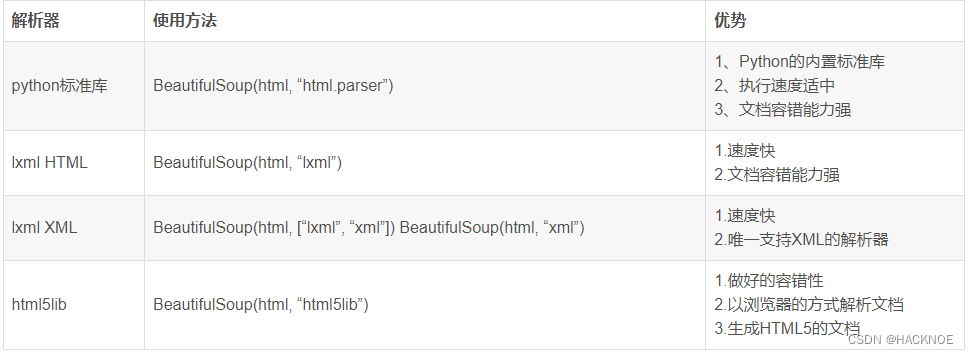
soup = beautifulsoup(html,'html.parser')
soup = beautifulsoup(html,'lxml')
soup = beautifulsoup(html,'xml')
beautifulsoup对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag获取整个标签
tag中最重要的属性:name和attributes
from bs4 import BeautifulSoup
# 逐一解析数据 把html使用html.parser进行解析
bs = BeautifulSoup(html,"html.parser")
print(bs.a) # 返回找到的第一个a标签,返回时的整个标签 Tag
print(bs.title)
<title>百度一下你就知道<title>
获取标签里的属性和属性值
bs = BeautifulSoup(html,"html.parser")
print(soup.head.name) # name 返回标签的名字#head
print(bs.a.attrs) # 返回找到的第一个title标签的属性和属性值,字典形式
{'href': 'https://accounts.douban.com/passport/login?source=movie', 'class': ['nav-login'], 'rel': ['nofollow']}
print(bs.a.attrs['href']) #查看某个属性的值
'https://accounts.douban.com/passport/login?source=movie'# 获取p标签的属性
bs.a.attrs(返回字典) or soup.p.attrs['class'](class返回列表,其余属性返回字符串)
bs.a.['class'](class返回列表,其余属性返回字符串)
bs.a.get('class')(class返回列表,其余属性返回字符串)
Navigablestring 获取标签里的内容
bs = BeautifulSoup(html,"html.parser")
print(bs.title.string) # 返回找到的第一个title标签的内容 字符串
百度一下你就知道
bs.title.string
bs.title.text
bs.title.get.text()
BeautifulSoup获取整个文档
bs = BeautifulSoup(html,"html.parser")
print(bs) # 返回整个文档的内容
Comment输出的内容不包含注释符号
soup = BeautifulSoup('<p class="t1"><!-- <div class="env">env的信息内容</div> --></p>', 'html.parser')
print(soup.p.string)
#如果标签内部的内容是注释,例如:<!-- -->;那么该NavigableSring对象会转换成Comment对象,并且会把注释符号去掉。
<div class="env">env的信息内容</div>
BeautifulSoup文档遍历
contens:获取所有子节点(仅仅获取子标签)
bs = BeautifulSoup(html,"html.parser")
print(bs.a.contens) # 返回a中的所有contens 列表形式 可以用列表遍历
print(bs.a.contens[2])
children:获取所有子节点(仅仅获取儿子),返回列表生成器,用于遍历
or child in soup.body.children:print(child)
descendants:获取所有子孙节点(获取全部子孙后代),返回列表生成器,用于遍历
for child in soup.body.descendants:print(child)
parent:返回某节点的直接父节点(仅仅获取父亲)
p = soup.p
print(p.parent.name)
#body
parents:返回某节点的所有父辈及以上辈的节点(父亲的父亲的父亲…都获取)
content = soup.head.title.string
for parent in content.parents:print(parent.name)
## 结果
title
head
html
[document]
next_sibling:获取该节点的下一个兄弟节点,结果通常是字符串或空白,因为空白或者换行也可以被视作一个节点。
previous_sibling:获取该节点的上一个兄弟节点。
print(soup.p.next_sibling)
# 实际该处为空白
print(soup.p.prev_sibling)
#None 没有前一个兄弟节点,返回 None
next_siblings:迭代获取该节点之前的全部兄弟节点。
next_siblings:迭代获取该节点之后的全部兄弟节点。
BeautifulSoup文档搜索
1.find()
查找第一个与字符串完全匹配的内容
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a") # 查找第一个的a标签
返回一个对象
a_list = bs.find('a')
a_list = bs.find('a', class_='xxx') # 注意class后的下划线
a_list = bs.find('a', title='xxx')
a_list = bs.find('a', id='xxx')
a_list = bs.find('a', id=compile(r'xxx'))
2.find_all()
字符串过滤,会查找所有与字符串完全匹配的内容
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find_all("a") # 查找所有的a标签
a_list = bs.find_all('a')
a_list = bs.find_all(['a','span']) #返回所有的a和span标签
a_list = bs.find_all('a', class_='xxx')
a_list = bs.find_all('a', id=compile(r'xxx'))
# 提取出前两个符合要求的
soup.find_all('a', limit=3)
3.find_parent
查找当前标签的父标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_parent('div') # 查找当前a标签的父div标签
4.find_next_sibling
查找当前标签的下一个兄弟标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_next_sibling('div') # 查找当前a标签的下一个div标签
5.find_previous_sibling
查找当前标签的前一个兄弟标签
bs = BeautifulSoup(html,"html.parser")
a_list = bs.find("a").find_previous_sibling('div') # 查找当前a标签的前一个div标签
2.search()
正则表达式搜索:使用search()方法来匹配内容
a_list = bs.find_all(re.compile("a"))
3.get_text()
获取标签内的文本内容
a_list = bs.find("a").get_text()
3.prettify()
格式化解析文本 自动为标签间添加换行符
soup = BeautifulSoup(ht, 'lxml')
soup.prettify()
3.自己写方法查询
def name_is_exists(tag):return tag.has_attr("name") # 查询标签中属性的名字为name的t_list = bs.find_all(name_is_exists)
for tag in t_list:print(tag)
4.kwargs 参数
t_list = bs.find_all(id="head") # 查找所有的id=head的标签
t_list = bs.find_all(class=True)
t_list = bs.find_all(herf="http://news.baidu.com")
5.text参数
t_list = bs.find_all(text="hao123") # 查找所有的id=head的标签
t_list = bs.find_all(text=["hao123","新闻","贴吧"])
for tag in t_list:print(tag)
t_list = bs.find_all(text = re.compile("\d")) # 应用正则表达式来查找包含特定文本的内容
6.limit参数
t_list = bs.find_all("a",limit=3) # 查找前三个a标签
7.css选择器
t_list = bs.select("a") # 查找所有的a标签
t_list = bs.select(".mnav") # 查找所有的类名为.mnav标签
t_list = bs.select("#u1") # 查找所有的id为#u1的标签
t_list = bs.select("a[class='bri']") # 查找属性为bri的标签
t_list = bs.select("head>title") # 查找head标签下的title标签
t list = bs.select(".mnav ~ .bri") # 查找.mnav的兄弟标签.bri的text
print(t_list[0].get_text())