Rust基础拾遗
- 前言
- 1.错误处理
- 1.1 panic
- 展开调用栈
- 中止
- Result
- 捕捉错误
- Result错误别名
- 打印错误
- 传播错误
- 处理多种Error类型
- 处理“不可能发生”的错误
- 处理main() 中的错误
- 声明自定义错误类型
- 为什么是 Result
- 2. create与模块
- 3. 宏
- 4. 不安全代码
- 5. 外部函数
前言
通过Rust程序设计-第二版笔记的形式对Rust相关重点知识进行汇总,读者通读此系列文章就可以轻松的把该语言基础捡起来。
1.错误处理
Rust 中的两类错误处理:panic 和 Result。
- 普通错误使用 Result 类型来处理。Result 通常用以表示由程序外部的事物引发的错误,比如错误的输入、网络中断或权限问题。
- panic 针对的是另一种错误,即那种永远不应该发生的错误。
1.1 panic
当程序遇到下列问题的时候,就可以断定程序自身存在 bug,故而会引发 panic:
- 数组越界访问;
- 整数除以 0;
- 在恰好为 Err 的 Result 上调用 .expect();
- 断言失败。
panic!() 是一种宏,用于处理程序中出现错误的情况。
如果panic真的发生了,那么该怎么办呢?
Rust 为你提供了一种选择。Rust 既可以在发生 panic 时展开调用栈,也可以中止进程。
展开调用栈
panic 是安全的,没有违反 Rust 的任何安全规则,即使你故意在标准库方法的中间引发 panic,它也永远不会在内存中留下悬空指针或半初始化的值。Rust 的设计理念是要在出现任何意外之前捕获诸如无效数组访问之类的错误。继续往下执行显然是不安全的,所以 Rust 会展开这个调用栈。但是进程的其余部分可以继续运行。
panic 是基于线程的。一个线程 panic 时,其他线程可以继续做自己的事。
为了使程序更加健壮,可以使用线程和 catch_unwind() 来处理 panic。
中止
如果 Rust 在试图清理第一个 panic 时,.drop() 方法触发了第二个 panic,那么这个 panic 就是致命的。Rust 会停止展开调用栈并中止整个进程。
Result
Rust 中没有异常。相反,函数执行失败时会有像下面这样的返回类型:
fn get_weather(location: LatLng) -> Result<WeatherReport, io::Error>
Result 类型会指示出可能的失败。当我们调用 get_weather() 函数时,它要么返回一个成功结果 Ok(weather),其中的 weather 是一个新的 WeatherReport 值;要么返回一个错误结果 Err(error_value),其中的 error_value 是一个 io::Error,用来解释出了什么问题。
每当调用此函数时,Rust 都会要求我们编写某种错误处理代码。如果不对 Result 执行某些操作,就无法获取 WeatherReport;如果未使用 Result 值,就会收到编译器警告。
本章将采用类似“食谱”的方式并专注于使用 Result 来实现你期望的错误处理行为。你将了解如何捕获错误、传播错误和报告错误,以及关于组织和使用 Result 类型的常见模式。
捕捉错误
Result 最彻底的处理方式:使用 match 表达式。
match get_weather(hometown) {Ok(report) => {display_weather(hometown, &report);}Err(err) => {println!("error querying the weather: {}", err);schedule_weather_retry();}
}
这相当于其他语言中的 try/catch。如果想直接处理错误而不是将错误传给调用者,就可以使用这种方式。
match 有点儿冗长,因此 Result 针对一些常见的特定场景提供了多个有用的方法,每个方法在其实现中都有一个 match 表达式。
返回一个 bool,告知此结果是成功了还是出错了。result.ok()(成功值)以 Option 类型返回成功值(如果有的话)。如果 result 是成功的结果,就返回 Some(success_value);否则,返回 None,并丢弃错误值。result.err()(错误值)以 Option 类型返回错误值(如果有的话)。result.unwrap_or(fallback)(解包或回退值)
如果 result 为成功结果,就返回成功值;否则,返回 fallback,丢弃错误值。
// 对南加州而言,这是一则十拿九稳的天气预报
const THE_USUAL: WeatherReport = WeatherReport::Sunny(72);// 如果可能,就获取真实的天气预报;如果不行,就回退到常见状态
let report = get_weather(los_angeles).unwrap_or(THE_USUAL);
display_weather(los_angeles, &report);
这是 .ok() 的一个很好的替代方法,因为返回类型是 T,而不是 Option。当然,只有存在合适的回退值时,才能用这个方法。result.unwrap_or_else(fallback_fn)(解包,否则调用)
这个方法也一样,但不会直接传入回退值,而是传入一个函数或闭包。它针对的是大概率不会用到回退值且计算回退值会造成浪费的情况。只有在得到错误结果时才会调用 fallback_fn。
let report = get_weather(hometown) .unwrap_or_else(|_err| vague_prediction(hometown));
最后这两个方法之所以有用,是因为前面列出的所有其他方法,除了 .is_ok() 和 .is_err(),都在消耗 result。也就是说,它们会按值接受 self 参数。有时在不破坏 result 的情况下访问 result 中的数据是非常方便的,这就是 .as_ref() 和 .as_mut() 的用武之地。假设你想调用 result.ok(),但要让 result 保持不可变状态,那么就可以写成 result.as_ref().ok(),它只会借用 result,返回 Option<&T> 而非 Option。
Result错误别名
打印错误
传播错误
处理多种Error类型
处理“不可能发生”的错误
有时我们明确知道某个错误不可能发生。假设我们正在编写代码来解析配置文件,并且确信文件中接下来的内容肯定是一串数字:
if next_char.is_digit(10) {let start = current_index;current_index = skip_digits( &line, current_index);let digits = & line[start..current_index];...
}
我们想将这个数字串转换为实际的数值。有一个标准方法可以做到这一点:
let num = digits.parse::();
现在的问题是:str.parse:😦) 方法不返回 u64,而是返回了一个 Result。转换可能会失败,因为某些字符串不是数值:
"bleen".parse::() // ParseIntError: 无效的数字
但我们碰巧知道,在这种情况下,digits 一定完全由数字组成。那么应该怎么办呢?如果我们正在编写的代码已经返回了 GenericResult,那么就可以添加一个 ?,并且忽略这个错误。否则,我们将不得不为处理不可能发生的错误而烦恼。最好的选择是使用 Result 的 .unwrap() 方法。如果结果是 Err,就会 panic;但如果成功了,则会直接返回 Ok 中的成功值:
let num = digits.parse::().unwrap();
这和 ? 的用法很相似,但如果我们对这个错误有没有可能发生的理解是错误的,也就是说如果它其实有可能发生,那么这种情况就会报 panic。
事实上,对于刚才这个例子,我们确实理解错了。如果输入中包含足够长的数字串,则这个数值会因为太大而无法放入 u64 中:
"99999999999999999999".parse::() // 溢出错误
因此,在这种特殊情况下使用 .unwrap() 存在 bug。这种有 bug 的输入本不应该引发 panic。
话又说回来,确实会出现 Result 值不可能是错误的情况。例如,在第 18 章中,你会看到 Write 特型为文本和二进制输出定义了一组泛型方法(.write() 等)。所有这些方法都会返回 io::Result,但如果你碰巧正在写入 Vec,那么它们就不可能失败。在这种情况下,可以使用 .unwrap() 或 .expect(message) 来简化 Result 的处理。
当错误表明情况相当严重或异乎寻常,理当用 panic 对它进行处理时,这些方法也很有用:
fn print_file_age(filename: &Path, last_modified: SystemTime) {let age = last_modified.elapsed().expect("system clock drift");...
}
在这里,仅当系统时间早于文件创建时间时,.elapsed() 方法才会失败。如果文件是最近创建的,并且在程序运行期间系统时钟往回调整过,就会发生这种情况。根据这段代码的使用方式,在这种情况下,调用 panic 是一个合理的选择,而不必处理该错误或将该错误传播给调用者。
处理main() 中的错误
在大多数生成 Result 的地方,让错误冒泡到调用者通常是正确的行为。这就是为什么 ? 在 Rust 中会设计成单字符语法。正如我们所见,在某些程序中,它曾连续用于多行代码。但是,如果你传播错误的距离足够远,那么最终它就会抵达 main(),后者必须对其进行处理。通常来说,main() 不能使用 ?,因为它的返回类型不是 Result:处理 main() 中错误的最简单方式是使用 .expect():
fn main() {
calculate_tides().expect(“error”); // 责任止于此
}
如果 calculate_tides() 返回错误结果,那么 .expect() 方法就会 panic。主线程中的 panic 会打印出一条错误消息,然后以非零的退出码退出,大体上,这就是我们期望的行为。
声明自定义错误类型
编写一个新的 JSON 解析器,并且希望它有自己的错误类型。
// json/src/error.rs
#[derive(Debug, Clone)]
pub struct JsonError {
pub message: String,
pub line: usize,
pub column: usize,
}
这个结构体叫作 json::error::JsonError。当你想引发这种类型的错误时,可以像下面这样写:
return Err(JsonError {
message: “expected ‘]’ at end of array”.to_string(),
line: current_line,
column: current_column
});
但是,如果你希望达到你的库用户的预期,确保这个错误类型像标准错误类型一样工作,那么还有一点儿额外的工作要做:
use std::fmt;
// 错误应该是可打印的
impl fmt::Display for JsonError {
fn fmt(&self, f: &mut fmt::Formatter) -> Result<(), fmt::Error> {
write!(f, “{} ({}:{})”, self.message, self.line, self.column)
}
}
// 错误应该实现std::error::Error特型,但使用Error各个方法的默认定义就够了
impl std::error::Error for JsonError { }
与 Rust 语言的许多方面一样,各种 crate 的存在是为了让错误处理更容易、更简洁。crate 种类繁多,但最常用的一个是 thiserror,它会帮你完成之前的所有工作,让你像下面这样编写错误定义:
use thiserror::Error;
#[derive(Error, Debug)]
#[error(" (, )")]
pub struct JsonError {
message: String,
line: usize,
column: usize,
}
#[derive(Error)] 指令会让 thiserror 生成前面展示过的代码,这可以节省大量的时间和精力。
为什么是 Result
现在我们已经足够了解为何 Rust 会优先选择 Result 而非异常了。以下是此设计的几个要点。
-
Rust 要求程序员在每个可能发生错误的地方做出某种决策,并将其记录在代码中。这样做很好,否则容易因为疏忽而无法正确处理错误。
-
最常见的决策是让错误继续传播,而这用单个字符 ? 就可以实现。因此,错误处理管道不会像在 C 和 Go 中那样让你的代码混乱不堪,而且它还具有可见性:在浏览一段代码时,你一眼就能看出错误是从哪里传出来的。
-
是否可能出错是每个函数的返回类型的一部分,因此哪些函数会失败、哪些不会失败非常清晰。如果你将一个函数改为可能出错的,那么就要同时更改它的返回类型,而编译器会让你随之修改该函数的各个下游使用者。
-
Rust 会检查 Result 值是否被用过了,这样你就不会意外地让错误悄悄溜过去。
-
由于 Result 是一种与任何其他数据类型没有本质区别的数据类型,因此很容易将成功结果和错误结果存储在同一个集合中,也很容易对“部分成功”的情况进行模拟。
2. create与模块
3. 宏
Rust 支持宏。宏是一种扩展语言的方式,它能做到单纯用函数无法做到的一些事。例如,我们已经见过 assert_eq! 宏,它是用于测试的好工具:
assert_eq!(gcd(6, 10), 2);
这也可以写成泛型函数,但是 assert_eq! 宏能做到一些无法用函数做到的事。一是当断言失败时,assert_eq! 会生成一条错误消息,其中包含断言的文件名和行号。函数无法获取这些信息,而宏可以,因为它们的工作方式完全不同。宏是一种简写形式。在编译期间,在检查类型并生成任何机器码之前,每个宏调用都会被展开。也就是说,每个宏调用都会被替换成一些 Rust 代码。前面的宏调用展开后大致如下所示:
3.1 宏基础
assert_eq! 宏的部分源代码。
 macro_rules! 是在 Rust 中定义宏的主要方式。请注意,这个宏定义中的 assert_eq 之后没有 !:只有调用宏时才要用到 !,定义宏时不用。
macro_rules! 是在 Rust 中定义宏的主要方式。请注意,这个宏定义中的 assert_eq 之后没有 !:只有调用宏时才要用到 !,定义宏时不用。
但并非所有的宏都是这样定义的:有一些宏是内置于编译器中的,比如 file!、line! 和 macro_rules!。本章会在结尾处讨论另一种方法,称为过程宏。但在本章的大部分内容里,我们会聚焦于 macro_rules!,这是迄今为止编写宏的最简单方式。
使用 macro_rules! 定义的宏完全借助“模式匹配”方式发挥作用。宏的主体只是一系列规则:
(pattern1)=>(template1);
(pattern2)=>(template3);
...
assert_eq! 版本只有一个模式和一个模板。
可以在模式或模板周围随意使用方括号或花括号来代替圆括号,这对 Rust 没有影响。同样,在调用宏时,下面这些都是等效的:
assert_eq!(gcd(6, 10), 2);
assert_eq![gcd(6, 10), 2];
assert_eq!{gcd(6, 10), 2}
唯一的区别是花括号后面的分号通常是可选的。按照惯例,在调用 assert_eq! 时使用圆括号,在调用 vec! 时使用方括号,而在调用 macro_rules! 时使用花括号。
3.1.1 宏展开的基础
Rust 在编译期间的很早阶段就展开了宏。编译器会从头到尾阅读你的源代码,定义并展开宏。你不能在定义宏之前就调用它,因为 Rust 在查看程序的其余部分之前就已经展开了每个宏调用。
Rust 展开 assert_eq! 宏调用的过程与对 match 表达式求值很像。Rust 会首先将参数与模式进行匹配,如图 21-2 所示。
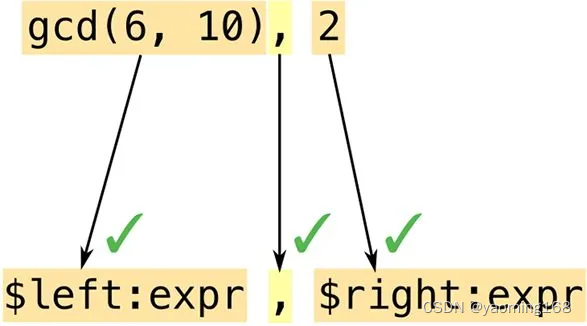
宏模式是 Rust 中的一种迷你语言。它们本质上是用来匹配代码的正则表达式。不过正则表达式操作的是字符,而模式操作的是语法标记(Token,包括数值、名称、标点符号等),这些语法标记是 Rust 程序的基础构造块。这意味着可以在宏模式中自由使用注释和空白字符,以尽量提高模式的可读性。因为注释和空白字符不是语法标记,所以不会影响匹配。
正则表达式和宏模式之间的另一个重要区别是圆括号、方括号和花括号在 Rust 中总是成对出现。Rust 会在展开宏之前进行检查,不仅仅在宏模式中检查,而且会贯穿整个语言。
在此示例中,我们的模式包含片段 $left:expr,它告诉 Rust 要匹配一个表达式(在本例中是 gcd(6, 10))并将其命名为 $left。然后 Rust 会将模式中的逗号与 gcd 的参数后面的逗号进行匹配。就像正则表达式一样,模式中只有少数特殊字符会触发有意义的匹配行为;其他字符,比如逗号,则必须逐字匹配,否则匹配就会失败。最后,Rust 会匹配表达式 2 并将其命名为 $right。
这个模式中的两个代码片段都是 expr 类型的,表示它们期待表达式。21.4.1 节会展示其他类型的代码片段。因为这个模式已经匹配到了所有的参数,所以 Rust 展开了相应的模板,如图 21-3 所示。
 Rust 会将 $left 和 $right 替换为它在匹配过程中找到的代码片段。
Rust 会将 $left 和 $right 替换为它在匹配过程中找到的代码片段。
在输出模板中包含片段类型(比如写成 $left:expr 而不仅是 $left)是一个常见的错误。Rust 不会立即检测到这种错误。它会将 $left 视为替代品,然后将 :expr 视为模板中的其他内容——要包含在宏输出中的语法标记。所以宏在被调用之前不会发生错误,然而它将生成实际无法编译的伪输出。如果在使用新宏时收到像 cannot find type ‘expr’ in this scope 和 help: maybe you meant to use a path separator here 这样的错误消息,请检查是否存在这种错误。
3.1.2 意外后果
3.1.3 重复
3.2 内置宏
3.3 调试宏
3.4 构建json!宏
3.4.1 片段类型
3.4.2 宏中的递归
3.4.3 将特型与宏一起使用
3.4.4 作用域界定与卫生宏
3.4.5 导入宏和导出宏
3.5 在匹配过程中避免语法错误