题目信息
 In this little training challenge, you are going to learn about the Robots_exclusion_standard.
In this little training challenge, you are going to learn about the Robots_exclusion_standard.
The robots.txt file is used by web crawlers to check if they are allowed to crawl and index your website or only parts of it.
Sometimes these files reveal the directory structure instead protecting the content from being crawled.
Enjoy!
在这个小小的训练挑战中,您将学习机器人排除标准。
robots.txt文件被网络爬虫用来检查他们是否被允许对您的网站或仅对其部分进行爬网和索引。
有时,这些文件会显示目录结构,而不是保护内容不被爬网。
享受
相关知识
- robots协议也称爬虫协议、爬虫规则等,是指网站建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。 robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
- disallow 用法
"Disallow"是一个常用于网站 robots.txt 文件中的指令,用于告诉搜索引擎爬虫哪些页面不应该被爬取。robots.txt文件是一个位于网站根目录的文本文件;用于控制搜索引擎爬虫对网站内容的访问。
在 robots.txt 文件中,"Disallow"用于指定不允许爬虫访问的页面或目录。其基本语法如下:
User-agent:[爬虫代理名称]
Disallow:[不允许访问的路径]
解题过程
在网址后根据提示输入robots.txt,跳转如下页面:
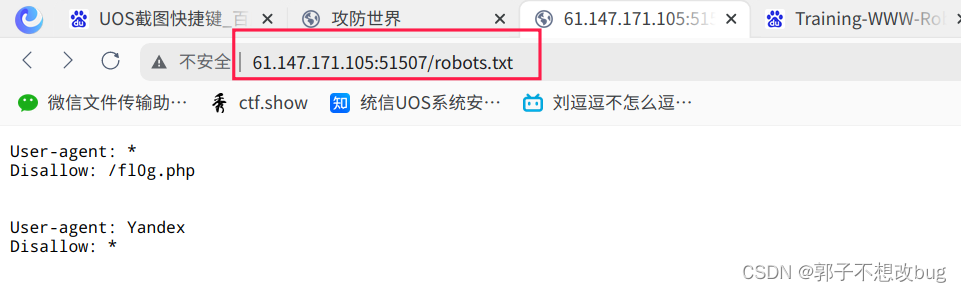
根据disallow,发现并访问fl0g.php
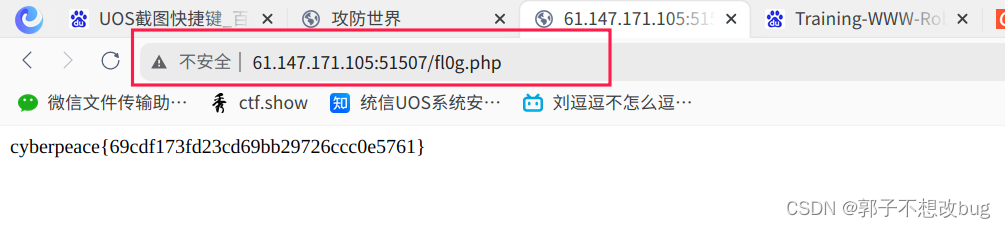
可以发现flag,输入即可得到正确答案
![[word] 如何将word文本转换成表格? #知识分享#学习方法#媒体](https://img-blog.csdnimg.cn/img_convert/15e34d6cccf36d654d05b70e2535a6a7.gif)









![[计算机网络]---UDP协议](https://img-blog.csdnimg.cn/direct/0ae9c96e2be34572b3f51203ac4bc6bf.png)