简介高效的 CV 入门指南: 100 行实现 InceptionResNet 图像分类
- 概述
- InceptionResNet
- Inception 网络
- 基本原理
- 关键特征
- ResNet 网络
- 深度学习早期问题
- 残差学习
- InceptionResNet 网络
- InceptionResNet v1
- InceptionResNet v2
- 改进的 Inception 模块
- 更有效的残差连接设计
- 100 行实现 InceptionResNet
- InceptionResNet v2
- InceptionResNet v3
- 测试
概述
在当今快速发展的人工智能领域, 计算机视觉 (Computer Vision, CV) 已称为一个关键的研究和应用领域. CV 可以使计算机理解图像和视频内容. CV 的核心目标是模拟和扩展人类的数据额系统功能, 使得机器能从图像或视频中自动提取, 处理, 分析和理解有用信息.
随着深度学习 (Deep Learning) 和神经网络 (Neural Network) 的兴起, 计算机视觉领域已经取得了显著的进步. 这些技术使得计算机能够通过学习大量的图像数据, 来识别和分类对象, 场景和活动. 应用敢为广泛, 从简单的图像分类到复杂的场景理解, 计算机视觉正逐渐成为日常生活和工业应用中不可或缺的一部分.
CV 技术已广泛应用于医疗成像, 自动驾驶汽车, 监控系统, 人脸识别, VR 等领域. 举个栗子: 在医疗领域, CV 能够帮我们诊断疾病, 通过分析医学图像来辅助医生做出更准确的诊断.
InceptionResNet
Inception 和 ResNet 是两个在计算机视觉 (CV) 领域具有里程碑意义的网络架构. Inception 架构能够在不同尺度上捕获图像特征, 以提高模型的表现力和效率. 而 ResNet (残差网络) 则通过引入残差学习的概念, 提升了模型的表现力和效率. 而 ResNet (残差网络) 则通过引入残差学习的概念, 解决了深度网络训练过程中的梯度消失 (Vanishing Gradient) 问题, 使得网络能欧达到前所未有的深度.
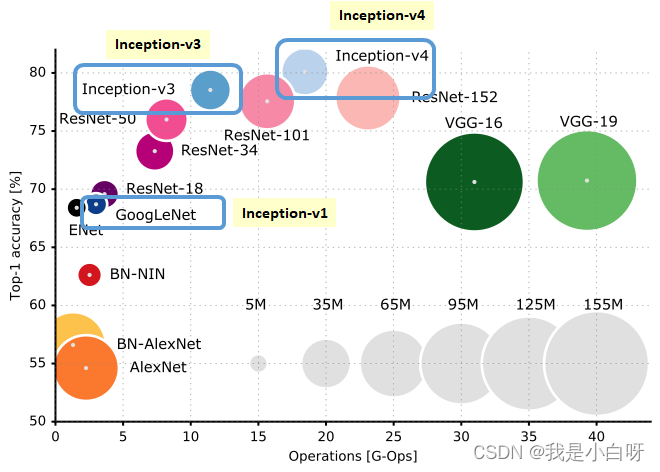
InceptionResNet 是一种融合了 Inception 架构和 ResNet (残差网络) 优点的深度学习模型 . 继承了 Inception 多尺度特征提取能力和 ResNet 的残差连接优势. InceptionResNet 的设计理念在于通过更加负责和深入的特征提取, 同时避免增加网络深度所带来的训练难度, 实现了在图像识别和分类等任务上的显著进步.
下面我们来介绍游戏 InceptionResNet 的架构设计, 关键技术, 以及应用案例.
Inception 网络
Inception 架构在 2014 年由谷歌提出的一个 27 层网络架构. 核心思想是在不同尺度上同时不好做图像特征, 以增强模型的表达能力.
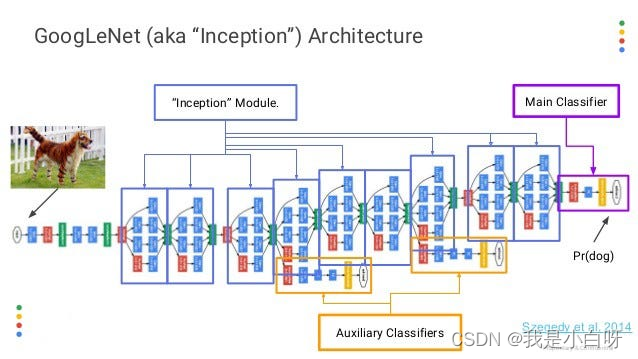
基本原理
Inception 将不同大小的卷积核应用于同意层输入, 从而在单个模块内并行捕获多尺度的图像特征. 相较于传统卷积网络 (Convolutional Neutral Network, CNN) 使用固定大小的卷积核 (Kernel), Inception 通过 ( 1 × 1 \ 1 \times 1 1×1, 3 × 3 \ 3 \times 3 3×3, 5 × 5 \ 5 \times 5 5×5) 不同大小的卷积核捕获图像从细节到全局的信息.
1 × 1 \ 1 \times 1 1×1 卷积核, 不仅作为降维工具减少参数和计算负担, 同时也作为网络深入的非线性增强层. 有效增加网络深度和宽度的同时, 避免计算资源的过度消耗.
关键特征
Inception 中的一个关键特征是尺度并行处理. 相较于 CNN 需要构建多个独立的网络分支来实现不同尺度的特征提取, Inception 在同一模块内使用不同大小的卷积核实现不同尺度特征的同时提取. 提高模型效率的同时也能使得模型能更全面的理解图像内容.
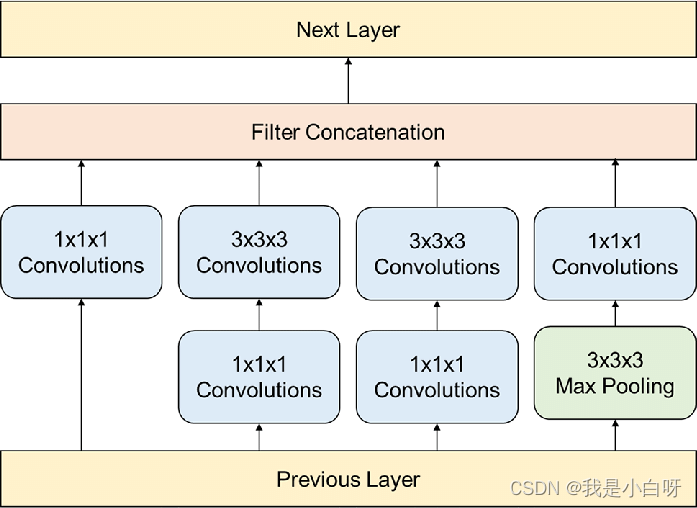
ResNet 网络
残差网络 ResNet (Residual network) 在 2015 年由何恺明等人提出. ResNet 的核心概念是残差学习 (Residual Learning), 用于解决深度神经网络训练中的梯度消失和梯度爆炸问题. ResNet 使得网络达到了前所未有的深度, 从而显著提高了模型的性能.

TensorFlow 版 Restnet 实现:
TensorFlow2 千层神经网络, 始步于此
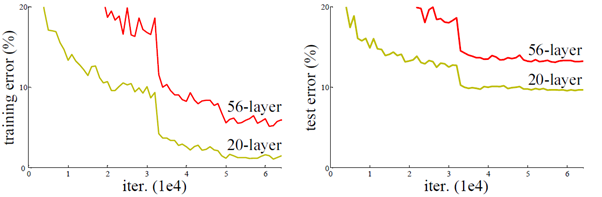
深度学习早期问题
当网络深度从 0 增加到 20 的时候, 结果会随着网络的深度而变好. 但当网络超过 20 层的时候, 结果会随着网络深度的增加而下降. 网络的层数越深, 梯度之间的相关性会越来越差, 模型也更难优化.
残差学习
残差学习的核心思想是引入一种直接连接输入和输出的 “捷径”, 使得网络可以学习到输入和输出之间的残差值.
举个例子, 如果我们将网络的输入设为 x \ x x, 理想的输出为 H ( x ) \ H(x) H(x), 那么网络层需要学习的映射就是 F ( x ) = H ( x ) − x \ F(x) = H(x) -x F(x)=H(x)−x. 通过这种方式在深层网络中, 梯度也可以通过这些捷径直接传播, 有效避免了梯度消失或爆炸的问题.
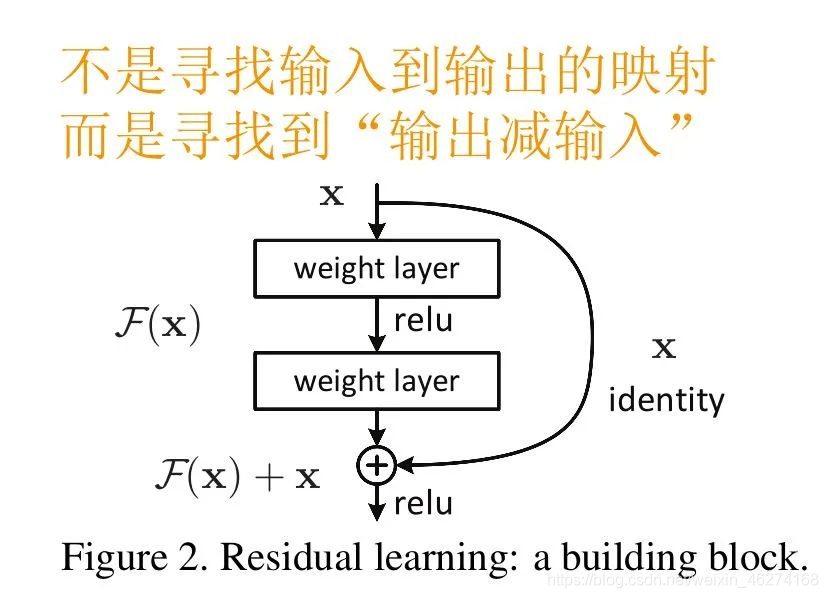
ResNet 中的跳跃连接实现了恒等映射, 即直接将输入传递到后面的层. 跳跃连接将块的输入直接添加到其输出, 这种设计不会增加额外的参数和计算负担.
InceptionResNet 网络
InceptionResNet 结合了 Inception 网络的多尺度特征提取能力和 ResNet 的残差学习机制.
InceptionResNet v1
使用原始 Inception 网络, 引入残差学习的概念, 通过在 Inception 模块后添加残差连接来促进梯度的反向传播.
InceptionResNet v2
在 v1 的基础上 v2 进行了进一步的优化, 包括对 Inception 模块的调整以及更有效的残差连接.
改进的 Inception 模块
InceptionResNet v2 中的 Inception 模块使用了更多的分解卷积 (Factorized Convolution), 即将较大的卷积核分解为更小的卷积核序列. 例如一个 7 × 7 \ 7 \times 7 7×7 的卷积可能被分解为一系列 1 × 7 \ 1 \times 7 1×7 和 7 × 1 \ 7 \times 1 7×1 的卷积. 这种分解不仅减少了模型的参数数量, 降低了计算复杂度, 还保持了捕获图像特征的能力.
更有效的残差连接设计
相较于 v1, v2 在残差连接的设计上进行了优化, 以提高梯度流动的效率. v2 采用了预激活 (Pre-activation) 的策略, 即在每个残差块的输入之前应用批量归一化 (Batch Normalization) 和 ReLU 激活函数. 这种设计有助于改善网络的训练动态, 减少过拟合的风险, 并提高模型的收敛速度.
100 行实现 InceptionResNet
InceptionResNet v2
import logging
import numpy as np
import tensorflow as tffrom load_image import ImageDataGenerator3, ImageDataGenerator2# 定义超参数
EPOCHS = 20 # 迭代次数
BATCH_SIZE = 16 # 一次训练的样本数目
learning_rate = 5e-4
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.BinaryCrossentropy() # 损失
logging.basicConfig(filename='../model/inception_v2/training_log.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')class TrainingLoggingCallback(tf.keras.callbacks.Callback):def on_epoch_end(self, epoch, logs=None):if logs is not None:logging.info(f"Epoch {epoch + 1}/{EPOCHS}")logging.info(f"loss: {logs['loss']} - accuracy: {logs['accuracy']}")logging.info(f"val_loss: {logs['val_loss']} - val_accuracy: {logs['val_accuracy']}")logging.info(f"lr: {self.model.optimizer.lr.numpy()}")class inception_resnet(tf.keras.Model):def __init__(self):super(inception_resnet, self).__init__()self.base_model = tf.keras.applications.inception_resnet_v2.InceptionResNetV2(input_shape=(512, 512, 3), include_top=False, weights="imagenet")self.average_pooling_layer = tf.keras.layers.GlobalAveragePooling2D()self.output_layer = tf.keras.layers.Dense(1, activation="sigmoid")def call(self, inputs):x = self.base_model(inputs)x = self.average_pooling_layer(x)output = self.output_layer(x)return outputdef main():# 获取数据image_generator = ImageDataGenerator3('../final_dataset-5_turns_chusai/train-metadata.json', batch_size=BATCH_SIZE)# 分割数据集,假设image_generator可以处理分割train_generator, val_generator = image_generator.split_data(test_size=0.2)# 建立模型inception = inception_resnet()# 调试输出 summaryinception.build(input_shape=[None, 512, 512, 3])print(inception.summary())# 配置模型inception.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])# 保存checkpoint = tf.keras.callbacks.ModelCheckpoint("model/inception_v2/inception_v2.ckpt", monitor='val_accuracy',verbose=1, save_best_only=True, mode='max')# 训练inception.fit(train_generator, validation_data=val_generator, epochs=EPOCHS,callbacks=[TrainingLoggingCallback(), checkpoint])if __name__ == '__main__':main()
InceptionResNet v3
import logging
import numpy as np
import tensorflow as tffrom load_image import ImageDataGenerator3, ImageDataGenerator2# 定义超参数
EPOCHS = 20 # 迭代次数
BATCH_SIZE = 16 # 一次训练的样本数目
learning_rate = 5e-4
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 优化器
loss = tf.losses.BinaryCrossentropy() # 损失
logging.basicConfig(filename='../model/inception_v3/training_log.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')class TrainingLoggingCallback(tf.keras.callbacks.Callback):def on_epoch_end(self, epoch, logs=None):if logs is not None:logging.info(f"Epoch {epoch + 1}/{EPOCHS}")logging.info(f"loss: {logs['loss']} - accuracy: {logs['accuracy']}")logging.info(f"val_loss: {logs['val_loss']} - val_accuracy: {logs['val_accuracy']}")logging.info(f"lr: {self.model.optimizer.lr.numpy()}")class inception_resnet(tf.keras.Model):def __init__(self):super(inception_resnet, self).__init__()self.base_model = tf.keras.applications.inception_v3.InceptionV3(input_shape=(512, 512, 3), include_top=False, weights="imagenet")self.average_pooling_layer = tf.keras.layers.GlobalAveragePooling2D()self.output_layer = tf.keras.layers.Dense(1, activation="sigmoid")def call(self, inputs):x = self.base_model(inputs)x = self.average_pooling_layer(x)output = self.output_layer(x)return outputdef main():# 获取数据image_generator = ImageDataGenerator3('../final_dataset-5_turns_chusai/train-metadata.json', batch_size=BATCH_SIZE)# 分割数据集,假设image_generator可以处理分割train_generator, val_generator = image_generator.split_data(test_size=0.2)# 建立模型inception = inception_resnet()# 调试输出 summaryinception.build(input_shape=[None, 512, 512, 3])print(inception.summary())# 配置模型inception.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])# 保存checkpoint = tf.keras.callbacks.ModelCheckpoint("model/inception_v3/inception_v3.ckpt", monitor='val_accuracy',verbose=1, save_best_only=True, mode='max')# 训练inception.fit(train_generator, validation_data=val_generator, epochs=EPOCHS,callbacks=[TrainingLoggingCallback(), checkpoint])if __name__ == '__main__':main()
测试
import json
import loggingimport cv2
import numpy as np
import tensorflow as tflabel_dict = {'carol': 0, 'chandler': 1, 'chloe': 2, 'frank jr': 3, 'gunther': 4,'joey': 5, 'monica': 6, 'phoebe': 7, 'rachel': 8, 'richard': 9, 'ross': 10
}label_dict_reverse = {0:'carol', 1:'chandler', 2:'chloe', 3:'frank jr', 4:'gunther',5:'joey', 6:'monica', 7:'phoebe', 8:'rachel', 9:'richard', 10:'ross'
}def calculate_area(bbox):return (bbox[2] - bbox[0]) * (bbox[3] - bbox[1])def main():test_metadata = json.load(open('../final_dataset-5_turns_chusai/test-metadata.json'))test_hard_metadata = json.load(open('../final_dataset-5_turns_chusai/test-hard-metadata.json'))print(len(test_metadata))print(len(test_hard_metadata))# # 测试test_metadata = test_metadata[:5]test_hard_metadata = test_hard_metadata[:5]# 存放结果result_list = []# 建立模型inception = tf.keras.models.load_model(r'model/inception_v2/inception_v2.tf')print(inception.summary())for dialog_data in test_metadata:# 遍历每一帧for frame_data in dialog_data:# 存放概率label_prob = [0] * 11faces = frame_data['faces'] # [(bbox, id), (bbox, id), ...]for bbox, face_label in faces:if face_label not in label_dict.keys():continuebbox = [max(i, 0) for i in bbox]bbox = [min(bbox[0], 1280), min(bbox[1], 720), min(bbox[2], 1280), min(bbox[3], 720)]if calculate_area(bbox) <= 0:continueimage = cv2.imread('images/' + frame_data['frame'] + '.jpg')image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = image[bbox[1]:bbox[3], bbox[0]:bbox[2]]image = cv2.resize(image, (512, 512), interpolation=cv2.INTER_AREA)image = np.expand_dims(image, axis=0) # 增加批次维度# print(image.shape)probability = inception.predict(image)[0][0]label_prob[label_dict[face_label]] = probabilityprint(label_prob)# 处理预测概率if label_prob != [0] * 11:label_index = np.argmax(label_prob)result_list.append(label_dict_reverse[label_index])else:result_list.append('richard')print(len(result_list))print(result_list)combine_predict = [result_list[i:i + 5] for i in range(0, len(result_list), 5)]print(len(combine_predict))# 将预测结果转换为JSON格式predictions_json = json.dumps(combine_predict)# 如果需要将结果保存到文件with open('submit.json', 'w') as file:file.write(predictions_json)def predict_batch(inception_model, images, labels):if len(images) == 0:return 'richard'images = np.array([np.expand_dims(img, axis=0) for img in images])pred = inception_model.predict(images)print(pred)returndef main2():test_metadata = json.load(open('../final_dataset-5_turns_chusai/test-metadata.json'))test_hard_metadata = json.load(open('../final_dataset-5_turns_chusai/test-hard-metadata.json'))print(len(test_metadata))print(len(test_hard_metadata))# # 测试test_metadata = test_metadata[:5]test_hard_metadata = test_hard_metadata[:5]# 存放结果result_list = []# 建立模型inception = tf.keras.models.load_model(r'model/inception_v2/inception_v2.tf')print(inception.summary())for dialog_data in test_metadata:# 遍历每一帧for frame_data in dialog_data:# 存放概率label_prob = [0] * 11faces = frame_data['faces'] # [(bbox, id), (bbox, id), ...]image_list = []label_list = []for bbox, face_label in faces:if face_label not in label_dict.keys():continuebbox = [max(i, 0) for i in bbox]bbox = [min(bbox[0], 1280), min(bbox[1], 720), min(bbox[2], 1280), min(bbox[3], 720)]if calculate_area(bbox) <= 0:continueimage = cv2.imread('images/' + frame_data['frame'] + '.jpg')image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = image[bbox[1]:bbox[3], bbox[0]:bbox[2]]image = cv2.resize(image, (512, 512), interpolation=cv2.INTER_AREA)# image = np.expand_dims(image, axis=0) # 增加批次维度image_list.append(image)label_list.append(face_label)result_list.append(predict_batch(inception, image_list, label_list))print(label_prob)# 处理预测概率if label_prob != [0] * 11:label_index = np.argmax(label_prob)result_list.append(label_dict_reverse[label_index])else:result_list.append('richard')print(len(result_list))print(result_list)combine_predict = [result_list[i:i + 5] for i in range(0, len(result_list), 5)]print(len(combine_predict))# 将预测结果转换为JSON格式predictions_json = json.dumps(combine_predict)# 如果需要将结果保存到文件with open('submit.json', 'w') as file:file.write(predictions_json)if __name__ == '__main__':main()main2()