早在2022年11月30日,OpenAI第一次发布人工智能聊天机器人ChatGPT,随后在全世界掀起了人工智能狂潮,颠覆了一个又一个行业。在过去的一年多的时间里,chatGPT的强大功能改变了越来越多人的工作和生活方式,成为了世界上用户增长最快的应用程序。
昨天,OpenAI发布了一款新的AI产品Sora,用户只需输入文本,即可生成一段极其逼真且富有想象力的视频,从而将战事正酣的AI竞赛引向好莱坞。如果说,OpenAI旗下的ChatGPT可以在不上法学院的情况下通过律师考试,而Sora则希望在不上电影学院的情况下拍摄电影。
OpenAI称,Sora能够根据文本指令生成一段60秒的视频,同时保持视觉质量。它对语言有深刻的理解,能够准确领会提示,生成令人信服的角色。Sora可生成具有多个角色、特定类型运动、精确主题和背景细节的复杂场景。还可以在单个生成视频中创建多个镜头,准确保留角色和视觉风格。
OpenAI今日还分享了几个样本视频,证明了通过文本生成视频的可能性。分析人士称,这是一个新的研究方向,也是2024年值得关注的一个趋势。OpenAI科学家Tim Brooks表示:“建立一套大模型,能够理解视频,理解我们世界中所有这些非常复杂的交互,是未来所有AI系统的重要一步。”

就在OpenAI发布Sora之前的几个小时,Google还刚刚推出了它最强的LLM Gemini1.5,并试图宣称自己终于杀死了GPT-4,然而,显然现在没人关注这个了。因为看完Sora你可能会发现,OpenAI自己可能要用它先杀死GPT-4了。
有了SORA,每个人都可以创造自己的世界了
自从OpenAI发布GPT-4以来,人们一直期待GPT-5,但Sora带来的轰动不亚于一次GPT-5的发布。
作为OpenAI 首推的文本转视频模型,Sora能够根据文本指令或静态图像生成长达 1分钟的视频,其中包含精细复杂的场景、生动的角色表情以及复杂的镜头运动。同时也接受现有视频扩展或填补缺失的帧。
每条提示60秒的视频长度与Pika Labs的3秒、Meta Emu Video的4秒、和Runway公司Gen-2的18秒相比,妥妥地铁赢了。并且从官方发布的演示来看,无论从视频流畅度还是细节表现能力上,Sora的效果都相当惊艳。
比如官推里这条14秒的东京雪景视频。
提示词:Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.
“美丽的,被雪覆盖的东京正繁忙着。镜头穿过繁忙的城市街道,跟随着几个享受雪景和在附近摊位购物的人。美丽的樱花瓣随风飘落,与雪花一同飞舞。”

穿着时尚的女性漫步在霓虹背景的东京街头,地面有积水倒影。

对于五官和皮肤的刻画十分真实,特别是痘印和法令纹,细节让人惊叹。

猛犸象自冰川雪原中缓步从来,背后升腾起雪雾。

烛火旁纯真顽皮的3D动画小怪物,光影、表情和毛茸茸的细节满分:

一名24岁女性的眼部特写,足以以假乱真:

无人机视角的海浪拍打着Big Sur加瑞角海岸崖壁,落日洒下金色光芒:

还有咱们中国的老百姓上街舞龙,庆祝中国农历春节:

目前Sora还在测试阶段,仅对部分评估人员、视觉艺术家、设计师和电影制作人们开放访问权限,拿到试用资格的人们已经开始想象力横飞。
OpenAI的首席执行官,Sam Altman就转发网友用Sora制作的“金光灿灿动物园”视频,玩起了自己的“What”梗:

他还邀请大家踊跃提出想用Sora制作视频的提示词,团队马上为大家生成,瞬间8千多条回复。网友脑洞大开,要看海洋生物的自行车公开赛(如下图):
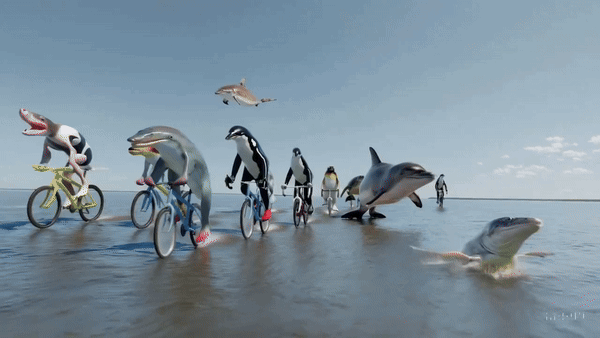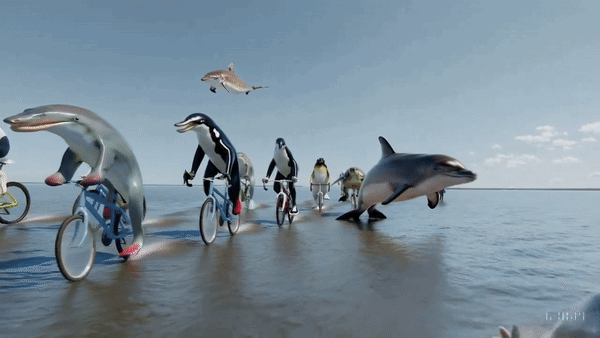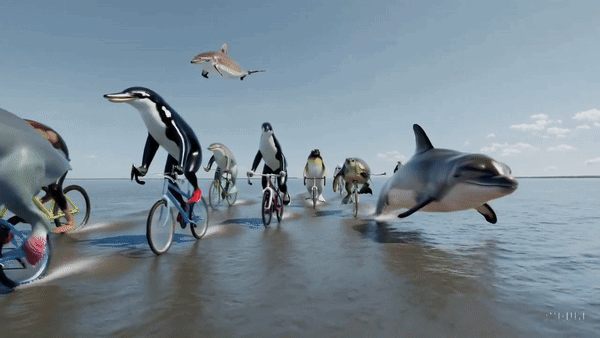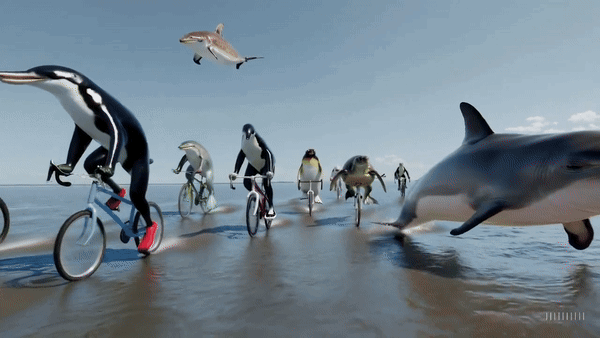
OpenAI公布的"并不全面"的SORA技术报告
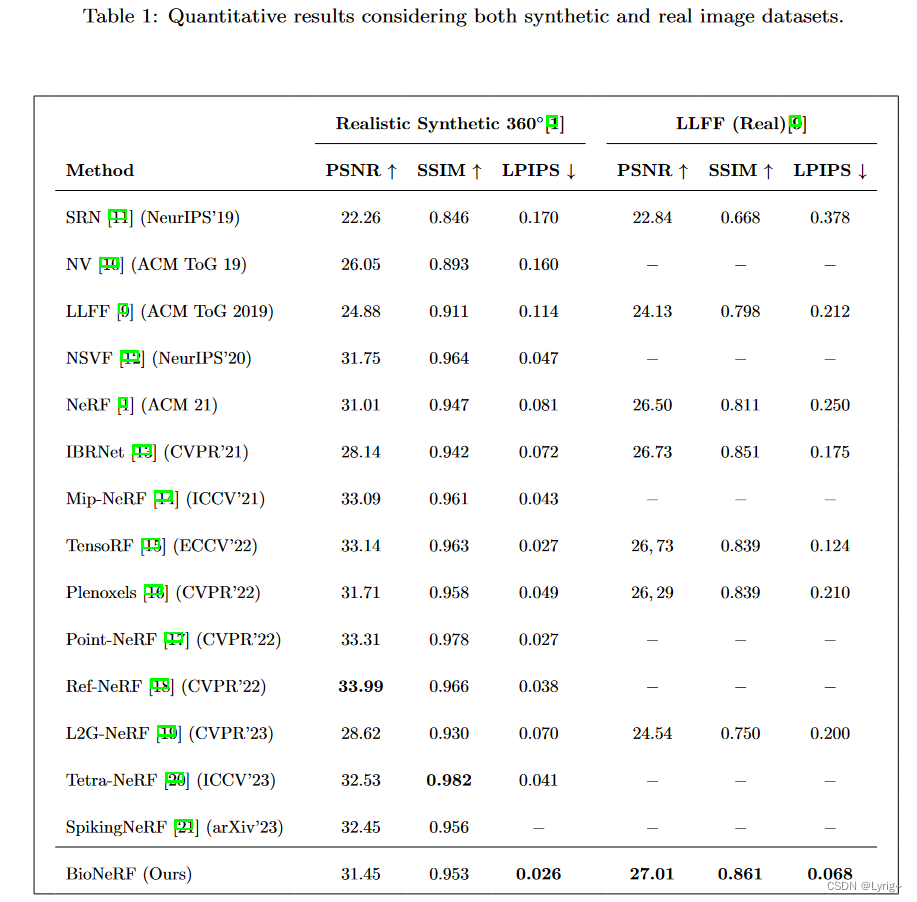
此前,我们已经见证过许多创业公司提出的视频生成模型。相比之下,OpenAI 提出的新模型不论是效果还是理念上,似乎都具有划时代的意义。
总的来讲,Sora 不是一个简单的视频生成器,它是一个数据驱动的物理引擎,其对于虚拟和现实世界进行模拟。在这个过程中,模拟器通过一些去噪和梯度数学方法来学习复杂的视觉渲染,构建出「直观」的物理效果,以及进行长期推理和语义基础。
在 Sora 推出后,OpenAI 很快公布了技术报告。OpenAI 探索了视频数据生成模型的大规模训练。具体来说,研究人员在可变持续时间、分辨率和宽高比的视频和图像上联合训练了一个文本条件扩散模型。作者利用对视频和图像潜在代码的时空补丁进行操作的 transformer 架构,其最大的模型 Sora 能够生成长达一分钟的高质量视频。
OpenAI 认为,新展示的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。

OpenAI 在技术报告中重点展示了:(1)将所有类型的视觉数据转化为统一表示,从而能够大规模训练生成模型的方法;以及(2)对 Sora 的能力和局限性进行定性评估。
令人遗憾的是,OpenAI 的报告不包含模型和训练的细节。
最近一段时间,视频生成是 AI 领域的重要方向,先前的许多工作研究了视频数据的生成建模方向,包括循环网络、生成对抗网络、自回归 transformer 和扩散模型。这些工作通常关注一小类视觉数据、较短的视频或固定大小的视频。
与之不同的是,OpenAI 的 Sora 是视觉数据的通用模型,它可以生成不同时长、长宽比和分辨率的视频和图像,而且最多可以输出长达一分钟的高清视频。
(1)视觉数据转为 Patches
大型语言模型通过在互联网规模的数据上进行训练,获得了出色的通用能力中,OpenAI 从这一点汲取了灵感。LLM 得以确立新范式,部分得益于创新了 token 使用的方法。研究人员们巧妙地将文本的多种模态 —— 代码、数学和各种自然语言统一了起来。
在这项工作中,OpenAI 考虑了生成视觉数据的模型如何继承这种方法的好处。大型语言模型有文本 token,而 Sora 有视觉 patches。此前的研究已经证明 patches 是视觉数据模型的有效表示。OpenAI 发现 patches 是训练生成各种类型视频和图像的模型的可扩展且有效的表示。
在更高层面上,OpenAI 首先将视频压缩到较低维的潜在空间,然后将表示分解为时空 patches,从而将视频转换为 patches。

(2)视频压缩网络
OpenAI 训练了一个降低视觉数据维度的网络。该网络将原始视频作为输入,并输出在时间和空间上压缩的潜在表示。Sora 在这个压缩的潜在空间中接受训练,而后生成视频。OpenAI 还训练了相应的解码器模型,将生成的潜在表示映射回像素空间。
(3) 时空潜在 patches
给定一个压缩的输入视频,OpenAI 提取一系列时空 patches,充当 Transformer 的 tokens。该方案也适用于图像,因为图像可视为单帧视频。OpenAI 基于 patches 的表示使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时,OpenAI 可以通过在适当大小的网格中排列随机初始化的 patches 来控制生成视频的大小。
(4)用于视频生成的缩放 Transformer
Sora 是个扩散模型;给定输入噪声 patches(以及文本提示等调节信息),训练出的模型来预测原始的「干净」patches。重要的是,Sora 是一个扩散 Transformer。Transformer 在各个领域都表现出了卓越的缩放特性,包括语言建模、计算机视觉、和图像生成。

在这项工作中,OpenAI 发现扩散 Transformers 也可以有效地缩放为视频模型。下面,OpenAI 展示了训练过程中具有固定种子和输入的视频样本的比较。随着训练计算的增加,样本质量显着提高。

(5)可变的持续时间,分辨率,宽高比
过去的图像和视频生成方法通常需要调整大小、进行裁剪或者是将视频剪切到标准尺寸,例如 4 秒的视频分辨率为 256x256。相反,该研究发现在原始大小的数据上进行训练,可以提供以下好处:
首先是采样的灵活性:Sora 可以采样宽屏视频 1920x1080p,垂直视频 1920x1080p 以及两者之间的视频。这使 Sora 可以直接以其天然纵横比为不同设备创建内容。Sora 还允许在生成全分辨率的内容之前,以较小的尺寸快速创建内容原型 —— 所有内容都使用相同的模型。

其次是改进帧和内容组成:研究者通过实证发现,使用视频的原始长宽比进行训练可以提升内容组成和帧的质量。将 Sora 在与其他模型的比较中,后者将所有训练视频裁剪成正方形,这是训练生成模型时的常见做法。经过正方形裁剪训练的模型(左侧)生成的视频,其中的视频主题只是部分可见。相比之下,Sora 生成的视频(右侧)具有改进的帧内容。

(6) 语言理解
训练文本到视频生成系统需要大量带有相应文本字幕的视频。研究团队将 DALL・E 3 中的重字幕(re-captioning)技术应用于视频。
具体来说,研究团队首先训练一个高度描述性的字幕生成器模型,然后使用它为训练集中所有视频生成文本字幕。研究团队发现,对高度描述性视频字幕进行训练可以提高文本保真度以及视频的整体质量。
与 DALL・E 3 类似,研究团队还利用 GPT 将简短的用户 prompt 转换为较长的详细字幕,然后发送到视频模型。这使得 Sora 能够生成准确遵循用户 prompt 的高质量视频。
(7) 以图像和视频作为提示
我们已经看到了文本到视频的诸多生成示例。实际上,Sora 还可以使用其他输入,如已有的图像或视频。这使 Sora 能够执行各种图像和视频编辑任务 — 创建完美的循环视频、静态图像动画、向前或向后延长视频时间等。
(8) 为 DALL-E 图像制作动画
只要输入图像和提示,Sora 就能生成视频。下面展示了根据 DALL-E 2 和 DALL-E 3 图像生成的视频示例 (狗戴着贝雷帽、穿着黑色高领毛衣):

(9) 视频内容拓展
Sora 还能够在开头或结尾扩展视频内容。以下是 Sora 从一段生成的视频向后拓展出的三个新视频。新视频的开头各不相同,拥有相同的结尾。不妨使用这种方法无限延长视频的内容,实现「视频制作永动机」。

(10) 视频到视频编辑
扩散模型激发了多种根据文本 prompt 编辑图像和视频的方法。OpenAI 的研究团队将其中一种方法 ——SDEdit 应用于 Sora,使得 Sora 能够在零样本(zero-shot)条件下改变输入视频的风格和环境。
输入视频如下:

输出结果:

(11) 连接视频
我们还可以使用 Sora 在两个输入视频之间逐渐进行转场,从而在具有完全不同主题和场景构成的视频之间创建无缝过渡。


(12) 图像生成能力
Sora 还能生成图像。为此,OpenAI 将高斯噪声 patch 排列在空间网格中,时间范围为一帧。该模型可生成不同大小的图像,最高分辨率可达 2048x2048。
(13) 涌现模拟能力
OpenAI 发现,视频模型在经过大规模训练后,会表现出许多有趣的新能力。这些能力使 Sora 能够模拟物理世界中的人、动物和环境的某些方面。这些特性的出现没有任何明确的三维、物体等归纳偏差 — 它们纯粹是规模现象。
三维一致性。Sora 可以生成动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中的移动是一致的。
长序列连贯性和目标持久性。视频生成系统面临的一个重大挑战是在对长视频进行采样时保持时间一致性。OpenAI 发现,虽然 Sora 并不总是能有效地模拟短距离和长距离的依赖关系,但它在很多时候仍然能做到这一点。例如,即使人、动物和物体被遮挡或离开画面,Sora 模型也能保持它们的存在。同样,它还能在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。
与世界互动。Sora 有时可以模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而持续,或者一个人可以吃汉堡并留下咬痕。
模拟数字世界。Sora 还能模拟人工进程,视频游戏就是一个例子。Sora 可以通过基本策略同时控制 Minecraft 中的玩家,同时高保真地呈现世界及其动态。只需在 Sora 的提示字幕中提及 「Minecraft」,就能零样本激发这些功能。
这些功能表明,视频模型的持续扩展是开发物理和数字世界以及其中的物体、动物和人的高能力模拟器的一条大有可为的道路。
SORA的弱点
虽然Sora 对自然语言有着深入的理解,能够准确洞悉提示词,生成表达丰富的内容,并可以创建多个镜头、保持角色和视觉风格的一致性,但是OpenAI也表示,SORA仍不可避免地存在一些弱点。
例如,它在准确模拟复杂场景的物理现象方面存在困难,也可能不理解特定的因果关系。比方说“一个人咬一口饼干后,饼干上可能并没有咬痕。” 另外,它不能准确模拟许多基本交互的物理现象,如玻璃碎裂。其他交互,如吃食物,并不总能产生正确的物体状态变化。官方主页列举了该模型的其他常见失效模式,例如长时间样本中出现的不一致性或物体的自发出现。

模型也可能混淆提示的空间细节,像是弄错左右。或者“在准确体现随时间发生的事件方面遇到困难,比如遵循特定的摄像机轨迹”。

Sora也使用了DALL·E 3的recaptioning技术,该技术涉及为视觉训练数据生成高度描述性的标题。因此模型能够更忠实地按照用户在生成视频中的文本指令进行操作。
它能够一次性生成整个视频,或是扩展已生成的视频使其变长。通过让模型一次性预见多帧,解决了即使主体暂时离开视线也能保持不变的挑战性问题。
不过,Sora 目前所展现的能力证明了持续扩大视频模型的规模是一个充满希望的方向,这也将助力物理和数字世界及其中的物体、动物和人类能够有更加精确的模拟。
关于安全性,OpenAI表示正与错误信息、仇恨内容和偏见等领域的专家合作,对模型进行对抗性测试。同时也在开发帮助检测误导性内容的工具,识别视频是否由Sora生成。对于违反使用政策的文本提示,例如暴力、仇恨和侵犯他人知识产权等内容,将拒绝显示给用户。
除此以外,为DALL·E 3产品构建的现有安全方法也同样适用于Sora。
“尽管进行了广泛的研究和测试,我们仍无法预测人们将如何利用我们的技术,也无法预见人们如何滥用它。这就是为什么我们相信,从真实世界的用例中学习,是随时间构建越来越安全的AI系统的关键组成部分。”
OpenAI对 Sora信心满满,认为这为模型理解和模拟真实世界奠定了基础,是“实现AGI的重要里程碑”。
哪些行业会受到SORA的冲击?
有人说,Sora一出,所有的视频人、电影人都下岗!
网友们也纷纷哀悼起相关赛道的公司们:
“OpenAI就是不能停止杀死创业公司。”
“天哪,现在起我们要弄清什么是真的,什么是假的。”
“我的工作没了。”
“整个影像素材行业被血洗,安息吧。”

北京大学人工智能博士、上市公司产业基金投资人@北大AI鱼博士,在微博上总结了Sora背后的训练思路和详细的技术特性。他表示,Sora模型不仅展现了三维空间的连贯性、模拟数字世界的能力、长期连续性和物体持久性,还能与世界互动,如同真实存在。其训练过程获得了大语言模型的灵感,采用扩散型变换器模型,通过将视频转换为时空区块的方式,实现了在压缩的潜在空间上的训练和视频生成。这种独特的训练方法使得Sora能够创造出质量显著提升的视频内容,无需对素材进行裁切,直接为不同设备以其原生纵横比创造内容。Sora的推出,无疑为视频生成领域带来了革命性的进步。
胡锡进也表达了自己对Sora的看法。他表示,这的确是爆炸性进展。到今天中午,在贾玲现实主义电影《热辣滚烫》的引领下,中国今年春节档的票房突破70亿。但是Sora在点亮AI影像制作未来的同时,也给全球现实主义电影的前途抹上了阴影。“让老胡接着看春节档电影都有些心神不宁了。”
正如此前OpenAI推出的ChatGPT为全球科技界带来的震动,福建华策品牌定位咨询创始人、福州公孙策公关合伙人詹军豪接受新浪科技采访时表示,AI视频大模型Sora的诞生也将对多个行业产生影响,包括但不限于广告、影视、游戏、教育、新闻等领域。
它可以帮助企业和个人更快速地创作和制作视频内容,提高效率。但同时,这也可能导致部分视频从业者面临失业的风险。然而,人工智能在很多领域也可以为人类提供更多便利和支持,因此不一定会造成失业潮。相反,它可能促使视频行业朝着更高端、更创新的方向发展。
小结
技术上来讲,SORA最吸引我们注意的第一个点,就是它对数据的处理。Sora是一个扩散模型(diffusion model),采用类似GPT的Transformer架构。而在解决训练中文本资料与视频数据之间的统一方面,OpenAI表示,他们在处理图像和视频数据时,把对它们进行分割后得到的最小单元,称为小块(patches),也就是对应LLM里的基本单元tokens。
这是一个很重要的技术细节。把它作为模型处理的基本单元,使得深度学习算法能够更有效地处理各种视觉数据,涵盖不同的持续时间、分辨率和宽高比。从最终的震撼效果看,你很难不得出这样一个结论:对语言的理解能力,是可以迁移到对更多形态的数据的理解方法上去的。
此前的Dalle-3的效果就被公认很大程度来自OpenAI在GPT上积累的领先N代的语言能力,哪怕是个图像为输出的模型,语言能力提升也是至关重要的。而今天的视频模型,同样如此。业内普遍认为,Sora能力的提升,主要来自高质量的数据集,以及准确的语言理解能力。OpenAI 没有透露训练视频的大小、来源,只声称训练的是公开有版权的视频。前述从业者认为,Sora无疑有巨大的数据量,因此能够支持多大的调用量,视频加载和渲染有多少延迟,都将是后续挑战。“真正投入使用会是什么样?能不能达到官方演示的效果?”还是一个未知数。
至于它是如何做到的,有不少行业内的专家给出了相同的猜测:它的训练数据里使用了游戏领域最前端的物理引擎Unreal Engine5,简单粗暴的理解,就是语言能力足够强大之后,它带来的泛化能力直接可以学习引擎生成的图像视频数据和它体现出的模式,然后还可以直接用学习来的,引擎最能理解的方式给这些利用了引擎的强大技术的视觉模型模块下指令,生成我们看到的逼真强大的对物理世界体现出“理解”的视频。基于这个猜测,OpenAI简短的介绍中的这句话似乎就更加重要了:“Sora 是能够理解和模拟现实世界的模型的基础,OpenAI相信这一功能将成为实现AGI的重要里程碑。”
理解,现实,世界。这不就是人们总在争论的那个唯一有可能“干掉”GPT-4的世界模型。现在,OpenAI搞出来了它的雏形,摆在了你的面前。看起来,这个模型学会了关于 3D 几何形状和一致性的知识,而且并非OpenAI训练团队预先设定的,而是完全是通过观察大量数据自然而然地学会的。负责Sora训练的OpenAI科学家Tim Brooks表示,AGI将能够模拟物理世界,而Sora就是迈向这个方向的关键一步。
值得注意的是,Sora目前定性为初期研究成果,不面向公众使用,因为公司担心深度伪造视频的滥用问题。现在只有一部分视觉艺术家、设计师和电影制作人有内部试用机会。此外,OpenAI 还在与第三方安全测试人员共享该模型,进行红队测试。
在安全问题上,Sora已经包含了一个过滤器,阻止暴力、色情、仇恨,以及特定人物的视频输出。公司还将借鉴去年在DALL-E 3 上实验的图像探测器,把C2PA技术标准——一种内容追溯方式,也可以理解为内容水印——嵌入到Sora的输出视频中,以鉴别视频是否为AI深度伪造视频。
小知识:
OpenAI是一家位于美国旧金山的人工智能研究公司,由营利性公司OpenAI LP及非营利性母公司OpenAI Inc组成。OpenAI的核心宗旨在于“创建造福全人类的安全通用人工智能(AGI)”。使命是确保通用人工智能造福全人类。OpenAI最初选择了在业内不看好的新兴技术路线上发展,作为一度面临资金链断裂风险的后发企业,逆袭成为引领通用人工智能浪潮的领军企业。OpenAI以排名第一上榜福布斯发布的2023云计算100强榜单。
OpenAI最早作为非营利组织,于2015年底,由包括萨姆·奥尔特曼(Sam Altman)、彼得·泰尔(Peter Thiel)、里德·霍夫曼(Reid Hoffman)和埃隆·马斯克(Elon Musk)等人创办。自2019年起,微软与OpenAI建立了合作伙伴关系,截至2023年12月微软是OpenAI最大的投资者,拥有49%的股份。在新初始董事会获得一个“无投票权观察员”席位。 2016年发布首个产品;2022年11月30日OpenAI的全新聊天机器人模型ChatGPT问世,给AIGC(Artificial Intelligence Generated Content,人工智能生成内容)的应用带来了更多的希望,ChatGPT上线仅5天用户数量就已突破100万。
2023年11月公司董事会发生人事变动事件:11月17日公司董事会宣布,萨姆·奥尔特曼(Sam Altman)将辞去首席执行官(CEO)并离开公司,首席技术官米拉·穆拉蒂将担任临时CEO,立即生效;11月22日,OpenAI发表声明称:萨姆·奥尔特曼将回归OpenAI担任CEO,并组建由Bret Taylor(主席)、Larry Summers和Adam D’Angelo组成的新初始董事会。

萨姆·奥尔特曼(Sam Altman),OpenAI公司的创始人和CEO
参考文献
https://openai.com/research/video-generation-models-as-world-simulators