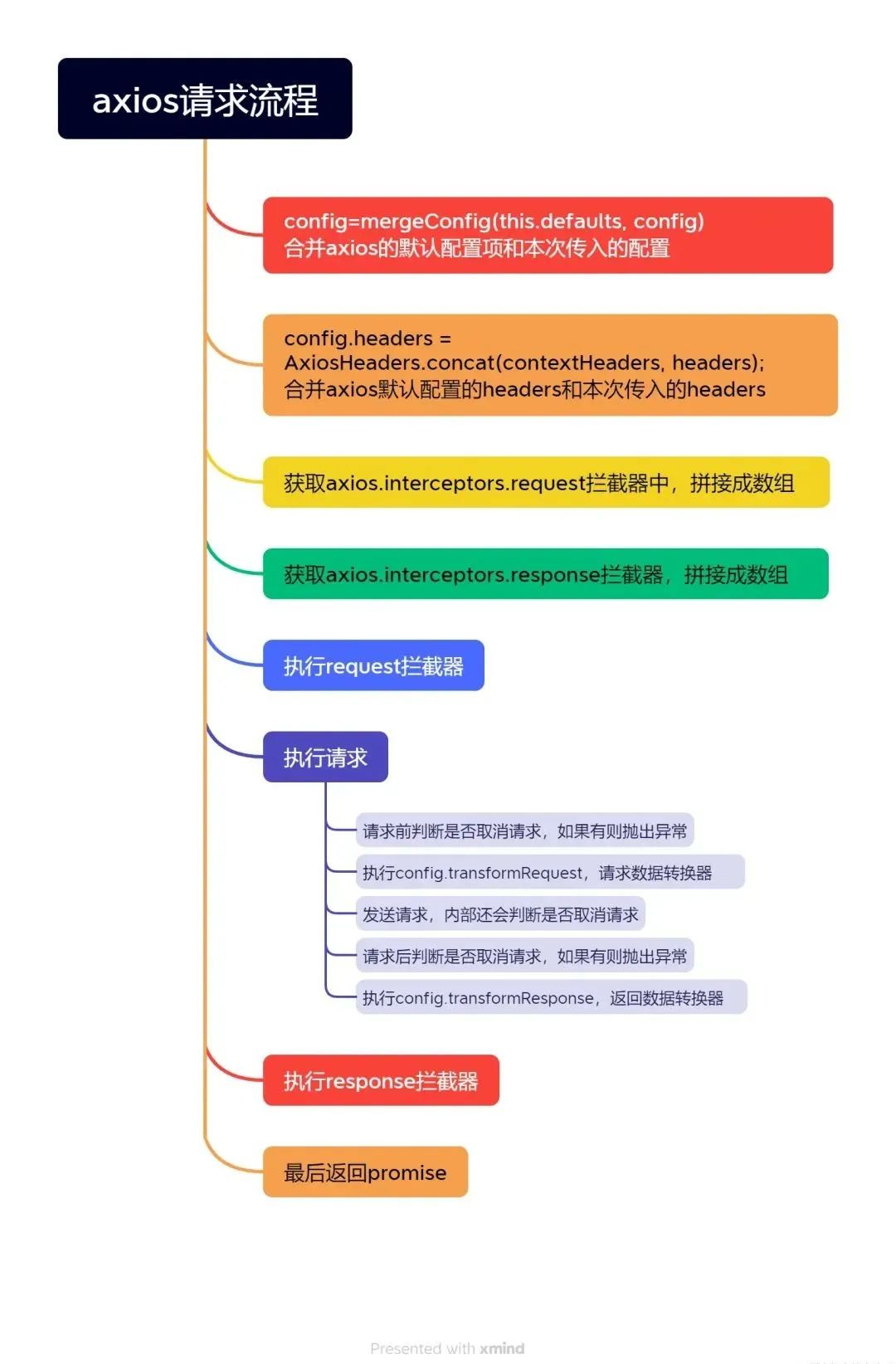
高并发系统实战课
场景
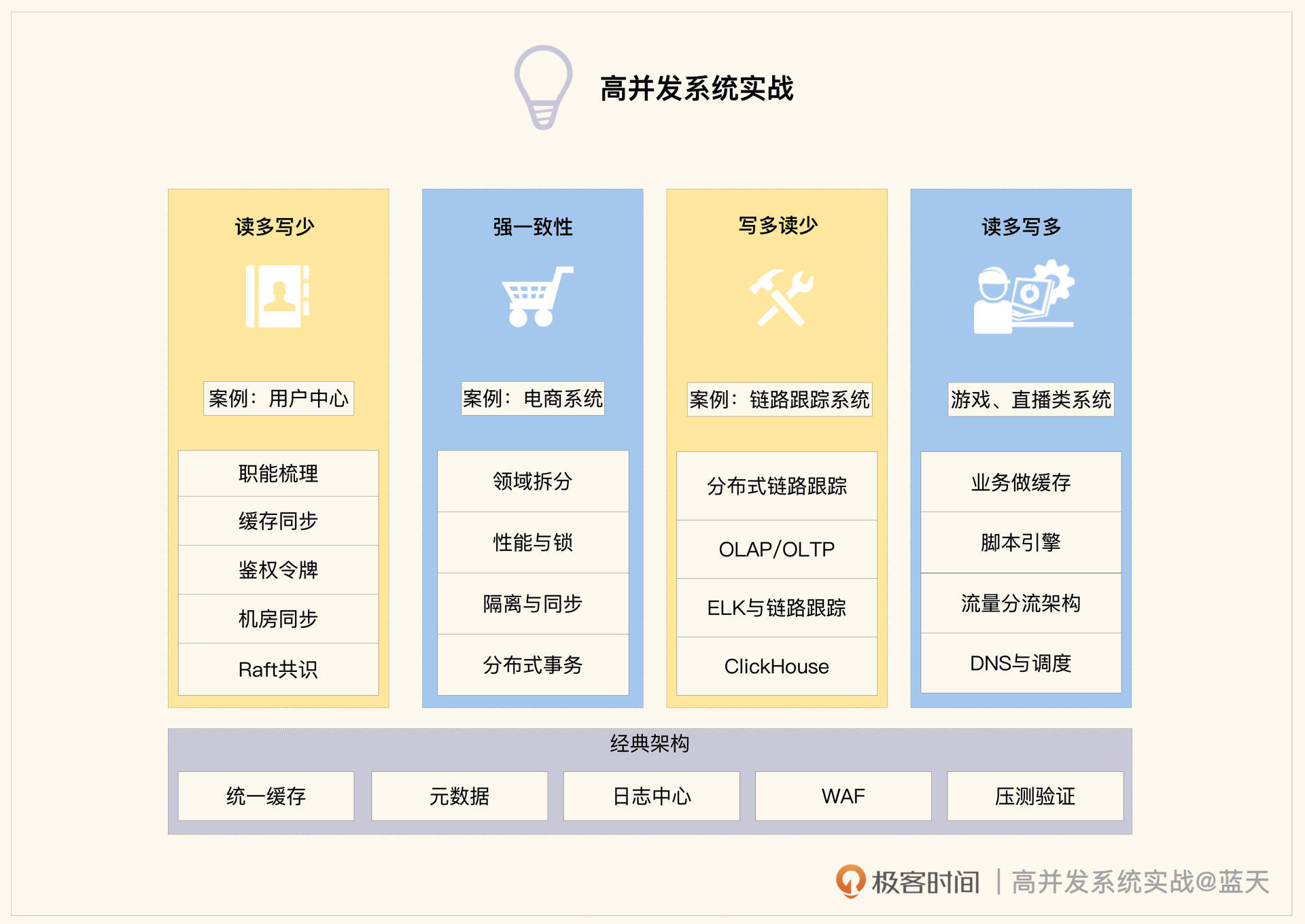
读多写少
我会以占比最高的“读多写少”系统带你入门,梳理和改造用户中心项目。这类系统的优化工作会聚焦于如何通过缓存分担数据库查询压力,所以我们的学习重点就是做好缓存,包括但不限于数据梳理、做数据缓存、加缓存后保证数据一致性等等工作。
另外,为了帮你从单纯的业务实现思想中“跳出来”,我们还会一起拓展下主从同步延迟和多机房同步的相关知识,为后续学习分布式和强一致打好基础。
强一致性
这类系统的主要挑战是承接高并发流量的同时,还要做好系统隔离性、事务一致性以及库存高并发争抢不超卖。我会和你详细讨论拆分实践的要点,让你加深对系统隔离、同步降级和库存锁等相关内容的认识,弄明白分布式事务组件的运作规律。了解这些,你会更容易看透一些基础架构组件的设计初衷。
写多读少
接下来是高并发写系统,它涉及大量数据如何落盘、如何传输、存储、压缩,还有冷热数据的切换备份、索引查询等多方面问题,我会一一为你展开分析。我还会给你分享一个全量日志分布式链路跟踪系统的完整案例,帮你熟悉并发写场景落地的方方面面。
读多写多
读多写多系统是最复杂的系统类型,就像最火热的游戏、直播服务都属于这个类型。其中很多技术都属于行业天花板级别,毕竟线上稍有点问题,都极其影响用户体验。
这类系统数据基本都是在内存中直接对外服务,同时服务都要拆成很小的单元,数据是周期落到磁盘或数据库,而不是实时更新到数据库。因此我们的学习重点是如何用内存数据做业务服务、系统无需重启热更新、脚本引擎集成、脚本与服务互动交换数据、直播场景高并发优化、一些关于网络优化 CDN 和 DNS、知识以及业务流量调度、客户端本地缓存等相关知识。
用户中心:读多写少的系统高并发优化实践
结构梳理:大并发下,你的数据库表可能成为性能隐患
因为老系统在使用数据库的时候存在很多问题,比如实体表字段过多、表查询维度和用途多样、表之间关系混乱且存在 m:n 情况……这些问题会让缓存改造十分困难,严重拖慢改造进度。
如果我们从数据结构出发,先对一些场景进行改造,然后再去做缓存,会让之后的改造变得简单很多。所以先梳理数据库结构,再对系统进行高并发改造是很有帮助的。
精简数据会有更好的性能
用户中心的主要功能是维护用户信息、用户权限和登录状态,它保存的数据大部分都属于读多写少的数据。用户中心常见的优化方式主要是将用户中心和业务彻底拆开,不再与业务耦合,并适当增加缓存来提高系统性能。
我举一个简单的例子:当时整表内有接近 2000 万的账号信息,我对表的功能和字段进行了业务解耦和精简,让用户中心的账户表里只会保留用户登陆所需的账号、密码:
CREATE TABLE `account` (`id` int(10) NOT NULL AUTO_INCREMENT,`account` char(32) COLLATE utf8mb4_unicode_ci NOT NULL,`password` char(32) COLLATE utf8mb4_unicode_ci NOT NULL,`salt` char(16) COLLATE utf8mb4_unicode_ci NOT NULL,`status` tinyint(3) NOT NULL DEFAULT '0',`update_time` int(10) NOT NULL,`create_time` int(10) NOT NULL,PRIMARY KEY (`id`),UNIQUE KEY `login_account` (`account`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
我们知道数据库是系统的核心,如果它缓慢,那么我们所有的业务都会受它影响,我们的服务很少能超过核心数据库的性能上限。而我们减少账号表字段的核心在于,长度小的数据在吞吐、查询、传输上都会很快,也会更好管理和缓存。
精简后的表拥有更少的字段,对应的业务用途也会比较单纯。其业务主要功能就是检测用户登陆账号密码是否正确,除此之外平时不会有其他访问,也不会被用于其他范围查询上。可想而知这种表的性能一定极好,虽然存储两千万账号,但是整体表现很不错。
不过你要注意,精简数据量虽然能换来更好的响应速度,但不提倡过度设计。因为表字段如果缺少冗余会导致业务实现更为繁琐,比如账户表如果把昵称和头像删减掉,我们每次登录就需要多读取一次数据库,并且需要一直关注账户表的缓存同步更新;但如果我们在账户表中保留用户昵称和头像,在登陆验证后直接就可以继续其他业务逻辑了,无需再查询一次数据库。
所以你看,有些查询往往会因为精简一两个字段就多查一次数据库,并且还要考虑缓存同步问题,实在是得不偿失,因此我们要在“更多的字段”和“更少的职能”之间找到平衡。
数据的归类及深入整理
除了通过精简表的职能来提高表的性能和维护性外,我们还可以针对不同类型的表做不同方向的缓存优化,如下图用户中心表例子:
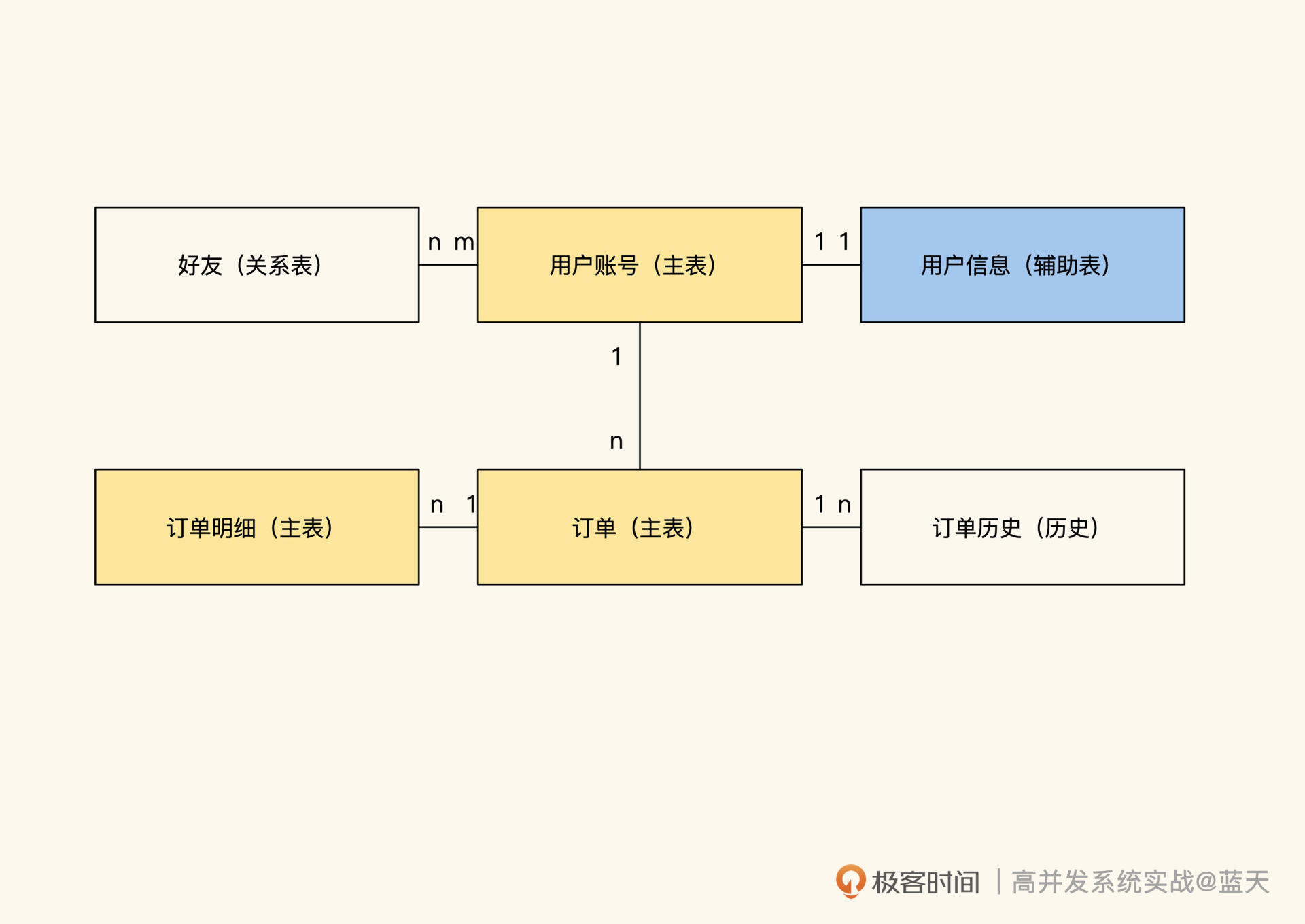
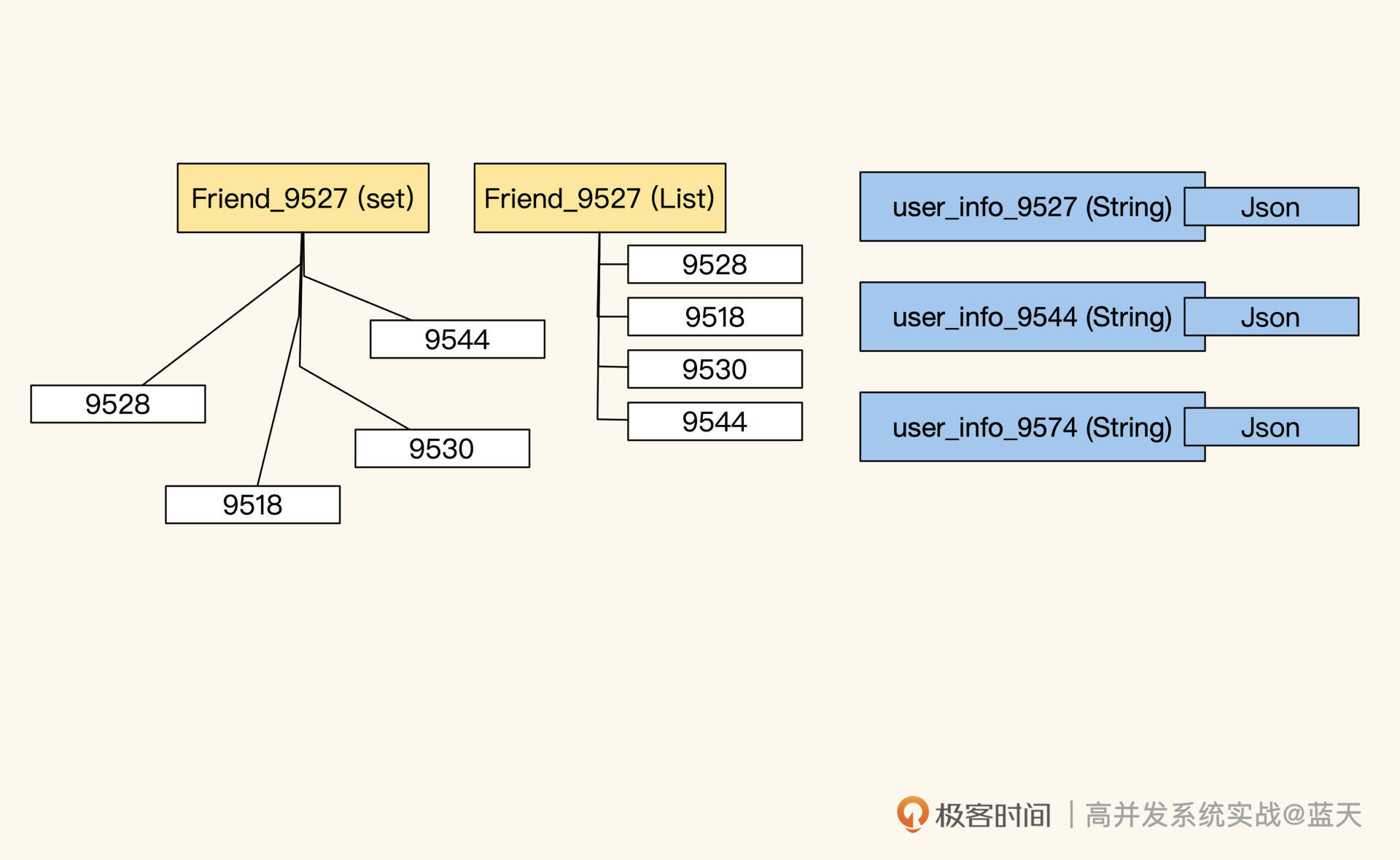
数据主要有四种:实体对象主表、辅助查询表、实体关系和历史数据,不同类型的数据所对应的缓存策略是不同的,如果我们将一些职能拆分不清楚的数据硬放在缓存中,使用的时候就会碰到很多烧脑的问题。
我之前就碰到过这样的错误做法——将用户来访记录这种持续增长的操作历史放到缓存里,这个记录的用途是统计有多少好友来访、有多少陌生人来访,但它同时保存着和用户是否是好友的标志。这也就意味着,一旦用户关系发生变化,这些历史数据就需要同步更新,否则里面的好友关系就“过时”了。
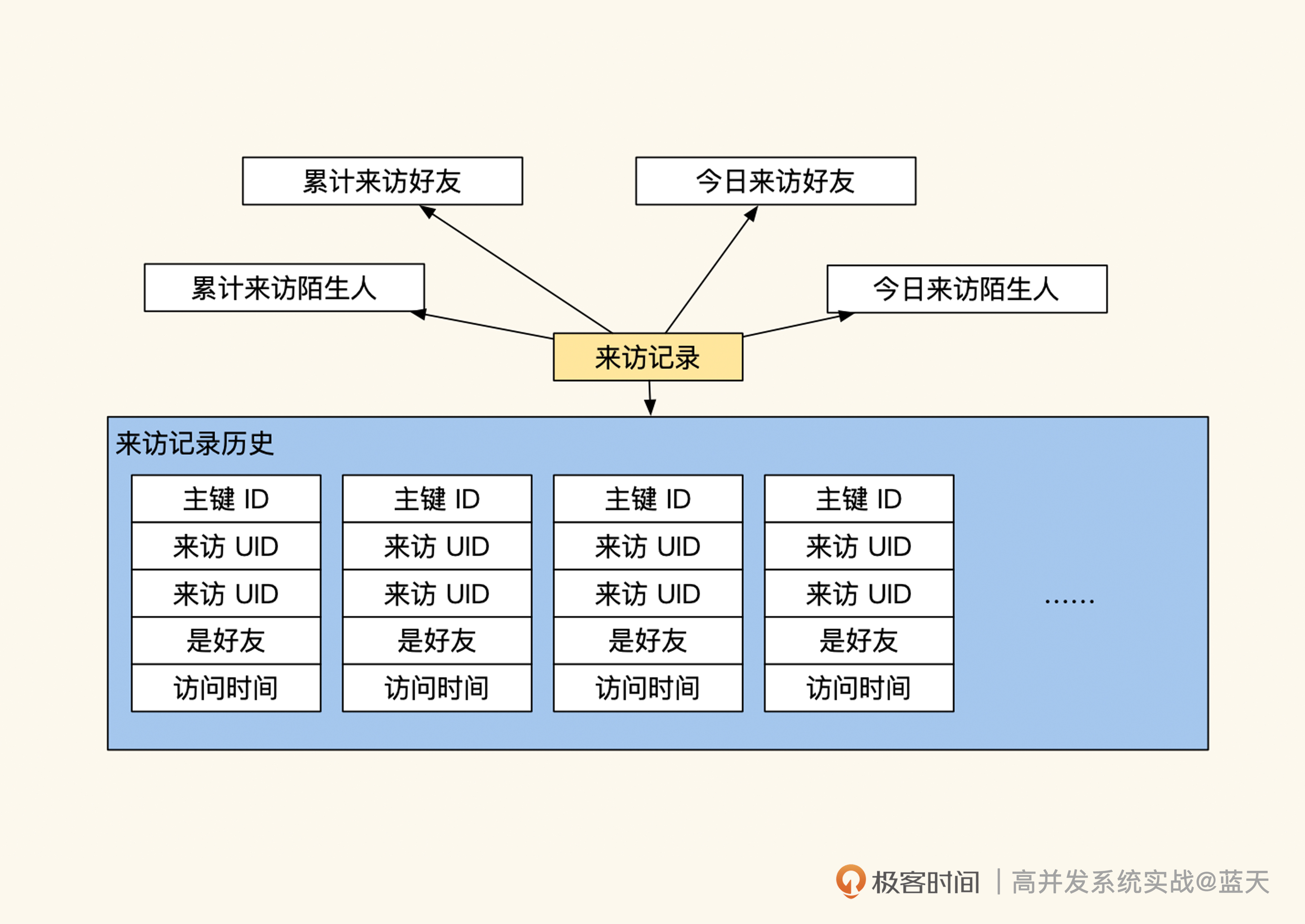
将历史记录和需要实时更新的好友状态混在一起,显然不合理。如果我们做归类梳理的话,应该拆分成三个职能表,分别进行管理:
- 历史记录表,不做缓存,仅展示最近几条,极端情况临时缓存;
- 好友关系(缓存关系,用于统计有几个好友);
- 来访统计数字(临时缓存)。
数据实体表
先看一下用户账号表,这个表是一个实体表,实体表一般会作为主表 ,它的一行数据代表一个实体,每个实体都拥有一个独立且唯一的 ID 作为标识。其中,“实体”代表一个抽象的事物,具体的字段表示的是当前实体实时的状态属性。
这个 ID 对于高并发环境下的缓存很重要,用户登录后就需要用自己账户的 ID 直接查找到对应的订单、昵称头像和好友列表信息。如果我们的业务都是通过这样的方式查找,性能肯定很好,并且很适合做长期缓存。
但是业务除了按 ID 查找外,还有一些需要通过组合条件查询的,比如:
- 在 7 月 4 日下单购买耳机的订单有哪些?
- 天津的用户里有多少新注册的用户?有多少老用户?
- 昨天是否有用户名前缀是 rick 账户注册?
这种根据条件查询统计的数据是不太容易做缓存的,因为高并发服务缓存的数据通常是能够快速通过 Hash 直接匹配的数据,而这种带条件查询统计的数据很容易出现不一致、数据量不确定导致的性能不稳定等问题,并且如果涉及的数据出现变化,我们很难通过数据确定同步更新哪些缓存。
因此,这类数据只适合存在关系数据库或提前预置计算好结果放在缓存中直接使用,做定期更新。
除了组合条件查询不好缓存外,像 count() 、sum() 等对数据进行实时计算也有更新不及时的问题,同样只能定期缓存汇总结果,不能频繁查询。所以,我们应该在后续的开发过程中尽量避免使用数据库做计算。
回到刚才的话题,我们继续讨论常见的数据实体表的设计。其实这类表是针对业务的主要查询需求而设计的,如果我们没有按照这个用途来查询表的时候,性能往往会很差。
比如前面那个用于账户登录的表,当我们拿它查询用户昵称中是否有“极客”两个字的时候,需要做很多额外的工作,需要对“用户昵称”这个字段增加索引,同时这种 like 查询会扫描全表数据进行计算。
如果这种查询的频率比较高,就会严重影响其他用户的登陆,而且新增的昵称索引还会额外降低当前表插入数据的性能,这也是为什么我们的后台系统往往会单独分出一个从库,做特殊索引。
一般来说,高并发用缓存来优化读取的性能时,缓存保存的基本都是实体数据。那常见的方法是先通过“key 前缀 + 实体 ID”获取数据(比如 user_info_9527),然后通过一些缓存中的关联关系再获取指定数据,比如我们通过 ID 就可以直接获取用户好友关系 key,并且拿到用户的好友 ID 列表。通过类似的方式,我们可以在 Redis 中实现用户常见的关联查询操作。
总体来说,实体数据是我们业务的主要承载体,当我们找到实体主体的时候,就可以根据这个主体在缓存中查到所有和它有关联的数据,来服务用户。现在我们来稍微总结一下,我们整理实体表的核心思路主要有以下几点:
- 精简数据总长度;
- 减少表承担的业务职能;
- 减少统计计算查询;
- 实体数据更适合放在缓存当中;
- 尽量让实体能够通过 ID 或关系方式查找;
- 减少实时条件筛选方式的对外服务。
实体辅助表
为了精简数据且方便管理,我们经常会根据不同用途对主表拆分,常见的方式是做纵向表拆分。
纵向表拆分的目的一般有两个,一个是**把使用频率不高的数据摘出来。**常见主表字段很多,经过拆分,可以精简它的职能,而辅助表的主键通常会保持和主表一致或通过记录 ID 进行关联,它们之间的常见关系为 1:1。
而放到辅助表的数据,一般是主要业务查询中不会使用的数据,这些数据只有在极个别的场景下才会取出使用,比如用户账号表为主体用于做用户登陆使用,而辅助信息表保存家庭住址、省份、微信、邮编等平时不会展示的信息。
辅助表的另一个用途是辅助查询,当原有业务数据结构不能满足其他维度的实体查询时,可以通过辅助表来实现。
比如有一个表是以“教师”为主体设计的,每次业务都会根据“当前教师 ID+ 条件”来查询学生及班级数据,但从学生的角度使用系统时,需要高频率以“学生和班级”为基础查询教师数据时,就只能先查出 “学生 ID”或“班级 ID”,然后才能查找出老师 ID”,这样不仅不方便,而且还很低效,这时候就可以把学生和班级的数据拆分出来,额外做一个辅助表包含所有详细信息,方便这种查询。
另外,我还要提醒一下,因为拆分的辅助表会和主体出现 1:n 甚至是 m:n 的数据关系,所以我们要定期地对数据整理核对,通过这个方式保证我们冗余数据的同步和完整。
不过,非 1:1 数据关系的辅助表维护起来并不容易,因为它容易出现数据不一致或延迟的情况,甚至在有些场景下,还需要刷新所有相关关系的缓存,既耗时又耗力。如果这些数据的核对通过脚本去定期执行,通过核对数据来找出数据差异,会更简单一些。
此外,在很多情况下我们为了提高查询效率,会把同一个数据冗余在多个表内,有数据更新时,我们需要同步更新冗余表和缓存的数据。
这里补充一点,行业里也会用一些开源搜索引擎,辅助我们做类似的关系业务查询,比如用 ElasticSearch 做商品检索、用 OpenSearch 做文章检索等。这种可横向扩容的服务能大大降低数据库查询压力,但唯一缺点就是很难实现数据的强一致性,需要人工检测、核对两个系统的数据。
实体关系表

在对 1:n 或 m:n 关系的数据做缓存时,我们建议提前预估好可能参与的数据量,防止过大导致缓存缓慢。同时,通常保存这个关系在缓存中会把主体的 ID 作为 key,在 value 内保存多个关联的 ID 来记录这两个数据的关联关系。而对于读取特别频繁的的业务缓存,才会考虑把数据先按关系组织好,然后整体缓存起来,来方便查询和使用。需要注意的是,这种关联数据很容易出现多级依赖,会导致我们整理起来十分麻烦。当相关表或条件更新的时候,我们需要及时同步这些数据在缓存中的变化。所以,这种多级依赖关系很难在并发高的系统中维护,很多时候我们会降低一致性要求来满足业务的高并发情况。总的来说,只有通过 ID 进行关联的数据的缓存是最容易管理的,其他的都需要特殊维护,我会在下节课给你介绍怎么维护缓存的更新和一致性,这里就不展开说了。现在我们简单总结一下,到底什么样的数据适合做缓存。一般来说,根据 ID 能够精准匹配的数据实体很适合做缓存;而通过 String、List 或 Set 指令形成的有多条 value 的结构适合做(1:1、1:n、m:n)辅助或关系查询;最后还有一点要注意,虽然 Hash 结构很适合做实体表的属性和状态,但是 Hgetall 指令性能并不好,很容易让缓存卡顿,建议不要这样做。
动作历史表
介绍到这里,我们已经完成了大部分的整理,同时对于哪些数据可以做缓存,你也有了较深理解。为了加深你的印象,我再介绍一些反例。一般来说,动作历史数据表记录的是数据实体的动作或状态变化过程,比如用户登陆日志、用户积分消费获取记录等。这类数据会随着时间不断增长,它们一般用于记录、展示最近信息,不建议用在业务的实时统计计算上。你可能对我的这个建议存有疑虑,我再给你举个简单的例子。如果我们要从一个有 2000 万条记录的积分领取记录表中,检测某个用户领取的 ID 为 15 的商品个数:
CREATE TABLE `user_score_history` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`uid` int(10) NOT NULL DEFAULT '',`action` varchar(32) NOT NULL,`action_id` char(16) NOT NULL,`status` tinyint(3) NOT NULL DEFAULT '0'`extra` TEXT NOT NULL DEFAULT '',`update_time` int(10) NOT NULL DEFAULT '0',`create_time` int(10) NOT NULL DEFAULT '0',PRIMARY KEY (`id`),KEY uid(`uid`,`action`),
) ENGINE=InnoDB AUTO_INCREMENT=1
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_unicode_ci;select uid, count(*) as action_count, product_id
from user_score_history
where uid = 9527 and action = "fetch_gift"
and action_id = 15 and status = 1
group by uid,action_id
不难看出,这个表数据量很大,记录了大量的实体动作操作历史,并且字段和索引不适合做这种查询。当我们要计算某个用户领取的 ID 为 15 的商品个数,只能先通过 UID 索引过滤数据,缩小范围。但是,这样筛选出的数据仍旧会很大。并且随着时间的推移,这个表的数据会不断增长,它的查询效率会逐渐降低。
所以,对于这种基于大量的数据统计后才能得到的结论数据,我不建议对外提供实时统计计算服务,因为这种查询会严重拖慢我们的数据库,影响服务稳定。即使使用缓存临时保存统计结果,这也属于临时方案,建议用其他的表去做类似的事情,比如实时查询领取记录表,效果会更好。
总结
在项目初期,数据表的职能设计往往都会比较简单,但随着时间的推移和业务的发展变化,表经过多次修改后,其使用方向和职能都会发生较大的变化,导致我们的系统越来越复杂。
所以,当流量超过数据库的承受能力需要做缓存改造时,我们建议先根据当前的业务逻辑对数据表进行职能归类,它能够帮你快速识别出,表中哪些字段和功能不适合在特定类型的表内使用,这会让数据在缓存中有更好的性价比。
一般来说,数据可分为四类:实体表、实体辅助表、关系表和历史表,而判断是否适合缓存的核心思路主要是以下几点:
- 能够通过 ID 快速匹配的实体,以及通过关系快速查询的数据,适合放在长期缓存当中;
- 通过组合条件筛选统计的数据,也可以放到临时缓存,但是更新有延迟;
- 数据增长量大或者跟设计初衷不一样的表数据,这种不适合、也不建议去做做缓存。

缓存一致:读多写少时,如何解决数据更新缓存不同步?
而对于用户中心的业务来说,这个比例会更大一些,毕竟用户不会频繁地更新自己的信息和密码,所以这种读多写少的场景特别适合做读取缓存。通过缓存可以大大降低系统数据层的查询压力,拥有更好的并发查询性能。但是,使用缓存后往往会碰到更新不同步的问题,下面我们具体看一看。
缓存性价比
就像刚才所说,我们认为用户信息放进缓存可以快速提高性能,所以在优化之初,我们第一个想到的就是将用户中心账号信息放到缓存。这个表有 2000 万条数据,主要用途是在用户登录时,通过用户提交的账号和密码对数据库进行检索,确认用户账号和密码是否正确,同时查看账户是否被封禁,以此来判定用户是否可以登录:
# 表结构
CREATE TABLE `accounts` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`account` varchar(15) NOT NULL DEFAULT '',`password` char(32) NOT NULL,`salt` char(16) NOT NULL,`status` tinyint(3) NOT NULL DEFAULT '0'`update_time` int(10) NOT NULL DEFAULT '0',`create_time` int(10) NOT NULL DEFAULT '0',PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;# 登录查询
select id, account, update_time from accounts
where account = 'user1'
and password = '6b9260b1e02041a665d4e4a5117cfe16'
and status = 1
这是一个很简单的查询,你可能会想:如果我们将 2000 万的用户数据放到缓存,肯定能提供性能很好的服务。
这个想法是对的,但不全对,因为它的性价比并不高:这个表查询的场景主要用于账号登录,用户即使频繁登录,也不会造成太大的流量冲击。因此,缓存在大部分时间是闲置状态,我们没必要将并发不高的数据放到缓存当中,浪费我们的预算。
这就牵扯到了一个很核心的问题,我们做缓存是要考虑性价比的。如果我们费时费力地把一些数据放到缓存当中,但并不能提高系统的性能,反倒让我们浪费了大量的时间和金钱,那就是不合适的。我们需要评估缓存是否有效,一般来说,只有热点数据放到缓存才更有价值。
临时热缓存
推翻将所有账号信息放到缓存这个想法后,我们把目标放到会被高频查询的信息上,也就是用户信息。
用户信息的使用频率很高,在很多场景下会被频繁查询展示,比如我们在论坛上看到的发帖人头像、昵称、性别等,这些都是需要频繁展示的数据,不过这些数据的总量很大,全部放入缓存很浪费空间。
对于这种数据,我建议使用临时缓存方式,就是在用户信息第一次被使用的时候,同时将数据放到缓存当中,短期内如果再次有类似的查询就可以快速从缓存中获取。这个方式能有效降低数据库的查询压力。常见方式实现的临时缓存的代码如下:
// 尝试从缓存中直接获取用户信息
userinfo, err := Redis.Get("user_info_9527")
if err != nil {return nil, err
}//缓存命中找到,直接返回用户信息
if userinfo != nil {return userinfo, nil
}//没有命中缓存,从数据库中获取
userinfo, err := userInfoModel.GetUserInfoById(9527)
if err != nil {return nil, err
}//查找到用户信息
if userinfo != nil {//将用户信息缓存,并设置TTL超时时间让其60秒后失效Redis.Set("user_info_9527", userinfo, 60)return userinfo, nil
}// 没有找到,放一个空数据进去,短期内不再问数据库
// 可选,这个是用来预防缓存穿透查询攻击的
Redis.Set("user_info_9527", "", 30)
return nil, nil
可以看到,我们的数据只是临时放到缓存,等待 60 秒过期后数据就会被淘汰,如果有同样的数据查询需要,我们的代码会将数据重新填入缓存继续使用。这种临时缓存适合表中数据量大,但热数据少的情况,可以降低热点数据的压力。
而之所以给缓存设置数据 TTL,是为了节省我们的内存空间。当数据在一段时间内不被使用后就会被淘汰,这样我们就不用购买太大的内存了。这种方式相对来说有极高的性价比,并且维护简单,很常用。
缓存更新不及时问题
临时缓存是有 TTL 的,如果 60 秒内修改了用户的昵称,缓存是不会马上更新的。最糟糕的情况是在 60 秒后才会刷新这个用户的昵称缓存,显然这会给系统带来一些不必要的麻烦。其实对于这种缓存数据刷新,可以分成几种情况,不同情况的刷新方式有所不同,接下来我给你分别讲讲。
1. 单条实体数据缓存刷新
单条实体数据缓存更新是最简单的一个方式,比如我们缓存了 9527 这个用户的 info 信息,当我们对这条数据做了修改,我们就可以在数据更新时同步更新对应的数据缓存:
Type UserInfo struct {Id int `gorm:"column:id;type:int(11);primary_key;AUTO_INCREMENT" json:"id"`Uid int `gorm:"column:uid;type:int(4);NOT NULL" json:"uid"`NickName string `gorm:"column:nickname;type:varchar(32) unsigned;NOT NULL" json:"nickname"`Status int16 `gorm:"column:status;type:tinyint(4);default:1;NOT NULL" json:"status"`CreateTime int64 `gorm:"column:create_time;type:bigint(11);NOT NULL" json:"create_time"`UpdateTime int64 `gorm:"column:update_time;type:bigint(11);NOT NULL" json:"update_time"`
}//更新用户昵称
func (m *UserInfo)UpdateUserNickname(ctx context.Context, name string, uid int) (bool, int64, error) {//先更新数据库ret, err := m.db.UpdateUserNickNameById(ctx, uid, name)if ret {//然后清理缓存,让下次读取时刷新缓存,防止并发修改导致临时数据进入缓存//这个方式刷新较快,使用很方便,维护成本低Redis.Del("user_info_" + strconv.Itoa(uid))}return ret, count, err
}整体来讲就是先识别出被修改数据的 ID,然后根据 ID 删除被修改的数据缓存,等下次请求到来时,再把最新的数据更新到缓存中,这样就会有效减少并发操作把脏数据带入缓存的可能性。
除此之外,我们也可以给队列发更新消息让子系统更新,还可以开发中间件把数据操作发给子系统,自行决定更新的数据范围。
不过,通过队列更新消息这一步,我们还会碰到一个问题——条件批量更新的操作无法知道具体有多少个 ID 可能有修改,常见的做法是:先用同样的条件把所有涉及的 ID 都取出来,然后 update,这时用所有相关 ID 更新具体缓存即可。
2. 关系型和统计型数据缓存刷新
首先是人工维护缓存方式。我们知道,关系型数据或统计结果缓存刷新存在一定难度,核心在于这些统计是由多条数据计算而成的。当我们对这类数据更新缓存时,很难识别出需要刷新哪些关联缓存。对此,我们需要人工在一个地方记录或者定义特殊刷新逻辑来实现相关缓存的更新。
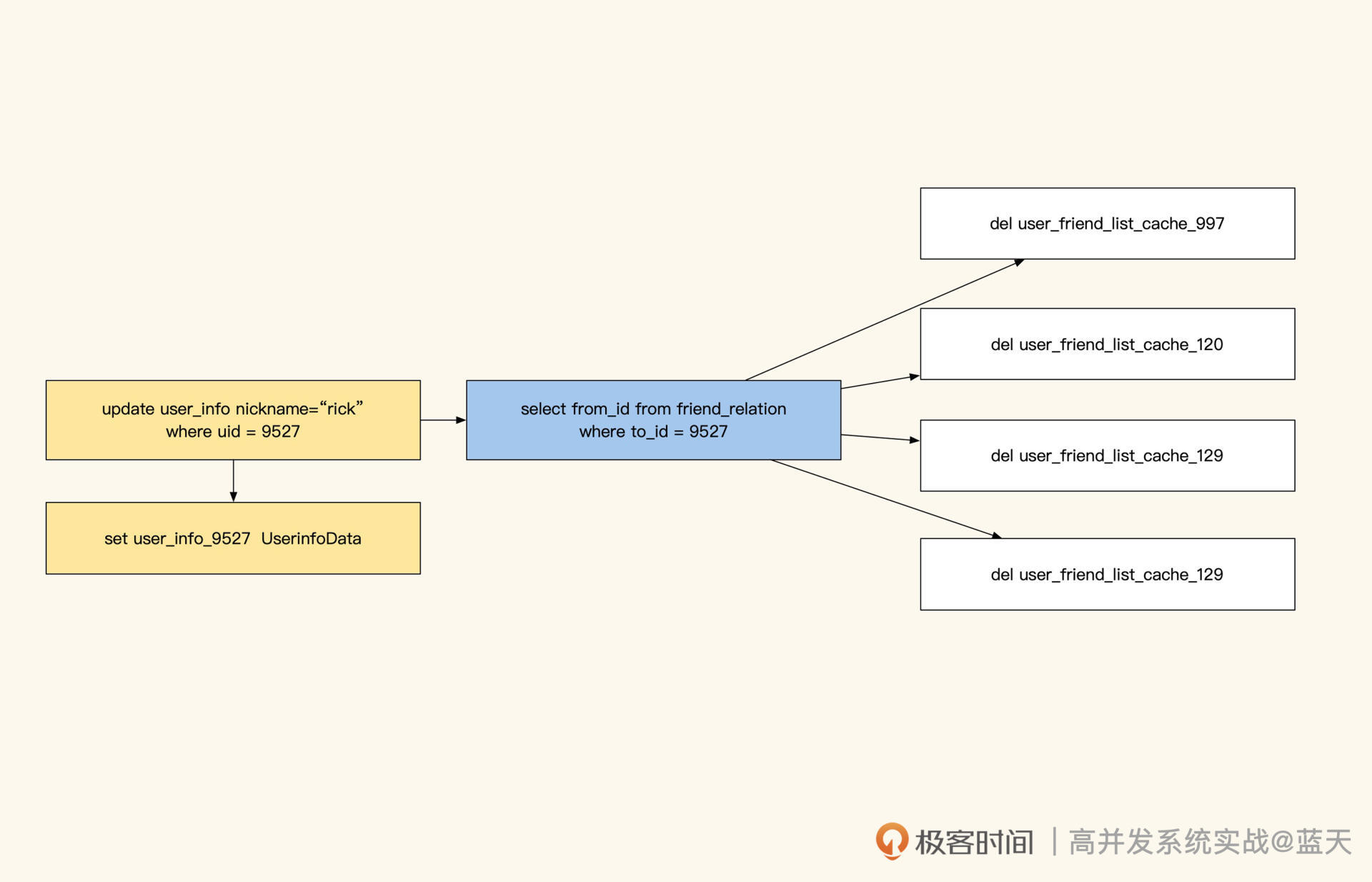
不过这种方式比较精细,**如果刷新缓存很多,那么缓存更新会比较慢,并且存在延迟。**而且人工书写还需要考虑如何查找到新增数据关联的所有 ID,因为新增数据没有登记在 ID 内,人工编码维护会很麻烦。
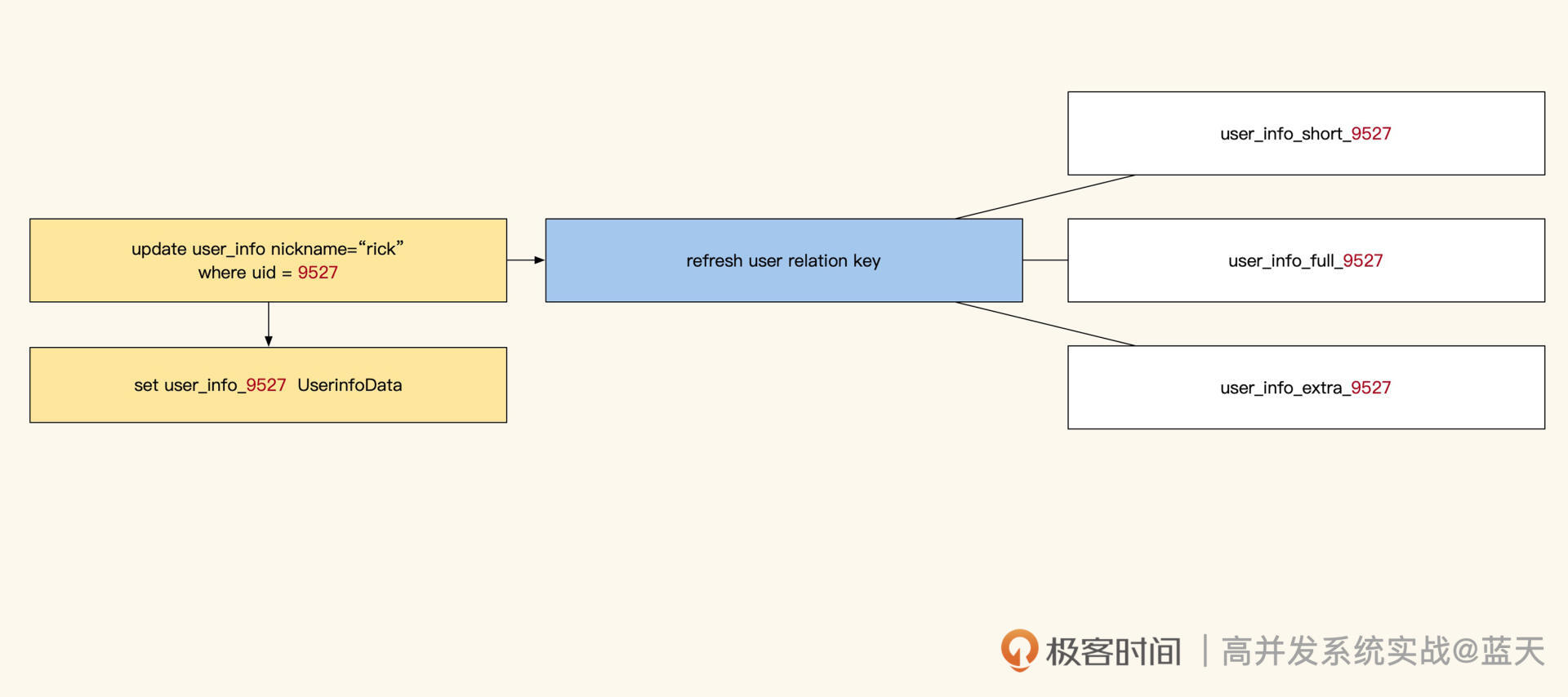
除了人工维护缓存外,还有一种方式就是通过**订阅数据库来找到 ID 数据变化。**如下图,我们可以使用 Maxwell 或 Canal,对 MySQL 的更新进行监控。
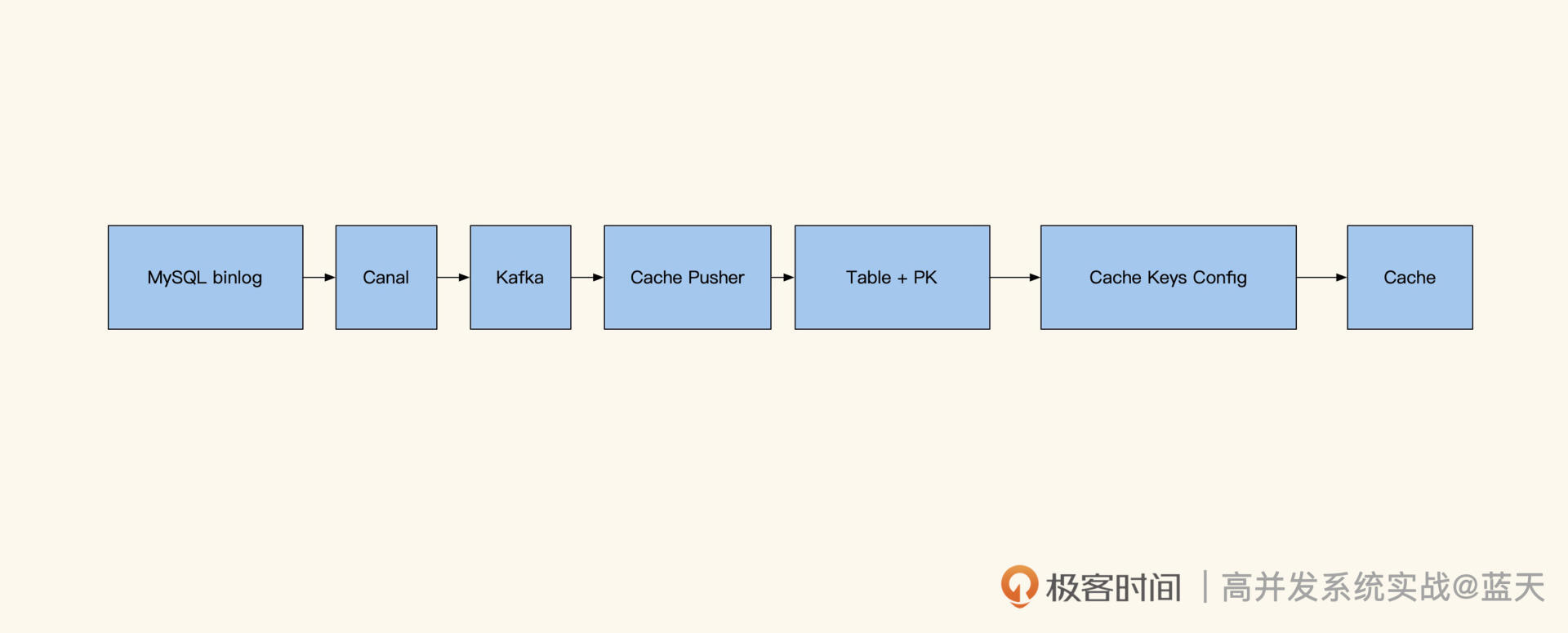
这样变更信息会推送到 Kafka 内,我们可以根据对应的表和具体的 SQL 确认更新涉及的数据 ID,然后根据脚本内设定好的逻辑对相 关 key 进行更新。例如用户更新了昵称,那么缓存更新服务就能知道需要更新 user_info_9527 这个缓存,同时根据配置找到并且删除其他所有相关的缓存。
很显然,这种方式的好处是能及时更新简单的缓存,同时核心系统会给子系统广播同步数据更改,代码也不复杂;缺点是复杂的关联关系刷新,仍旧需要通过人工写逻辑来实现。
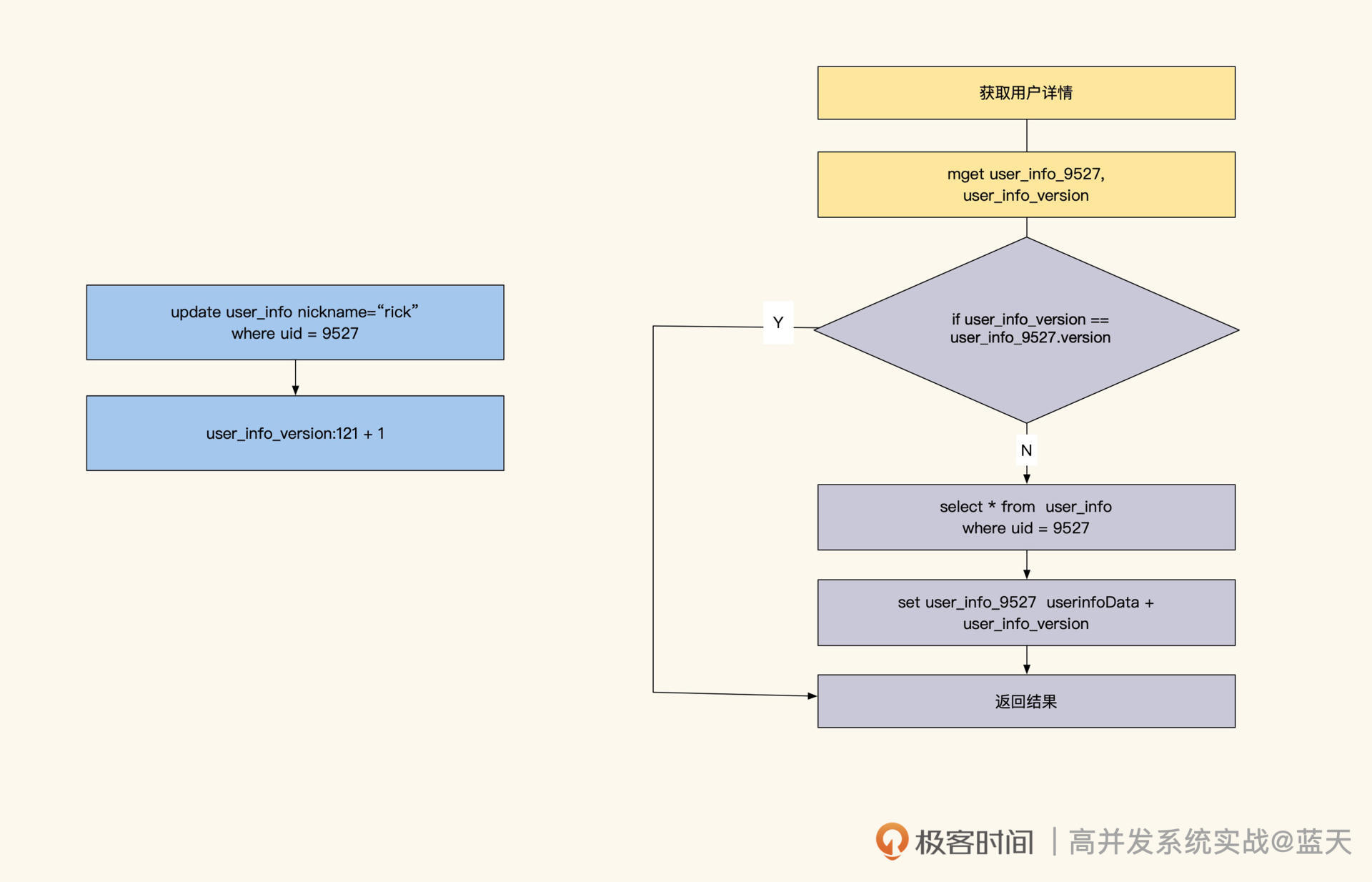
如果我们表内的数据更新很少,那么可以采用版本号缓存设计。
这个方式比较狂放:一旦有任何更新,整个表内所有数据缓存一起过期。比如对 user_info 表设置一个 key,假设是 user_info_version,当我们更新这个表数据时,直接对 user_info_version 进行 incr +1。而在写入缓存时,同时会在缓存数据中记录 user_info_version 的当前值。
当业务要读取 user_info 某个用户的信息的时候,业务会同时获取当前表的 version。如果发现缓存数据内的版本和当前表的版本不一致,那么就会更新这条数据。但如果 version 更新很频繁,就会严重降低缓存命中率,所以这种方案适合更新很少的表。
当然,我们还可以对这个表做一个范围拆分,比如按 ID 范围分块拆分出多个 version,通过这样的方式来减少缓存刷新的范围和频率
版本号方式刷新缓存
此外,关联型数据更新还可以通过识别主要实体 ID 来刷新缓存。这要保证其他缓存保存的 key 也是主要实体 ID,这样当某一条关联数据发生变化时,就可以根据主要实体 ID 对所有缓存进行刷新。这个方式的缺点是,我们的缓存要能够根据修改的数据反向找到它关联的主体 ID 才行。
通过主要实体id刷新缓存
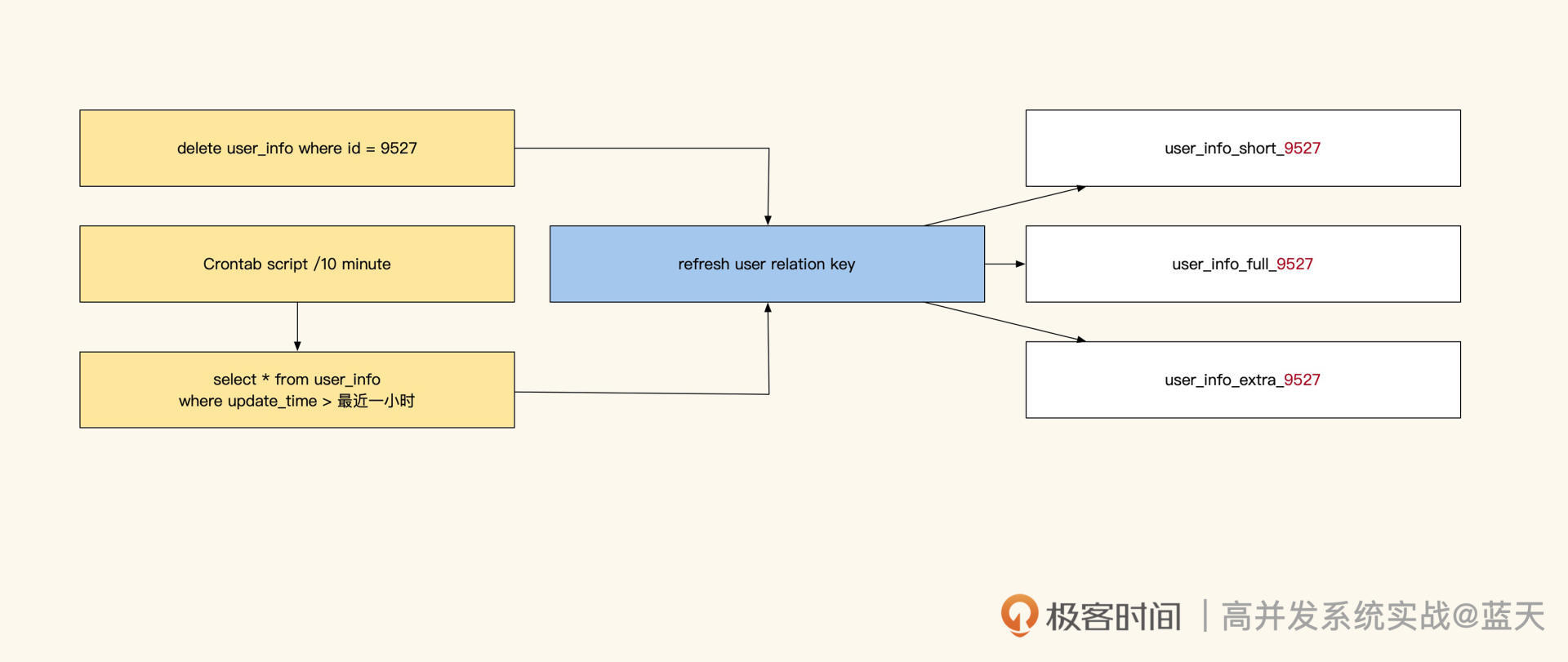
最后,我再给你介绍一种方式:**异步脚本遍历数据库刷新所有相关缓存。**这个方式适用于两个系统之间同步数据,能够减少系统间的接口交互;缺点是删除数据后,还需要人工删除对应的缓存,所以更新会有延迟。但如果能配合订阅更新消息广播的话,可以做到准同步。
遍历数据库刷新缓存
长期热数据缓存
到这里,我们再回过头看看之前的临时缓存伪代码,它虽然能解决大部分问题,但是请你想一想,当 TTL 到期时,**如果大量缓存请求没有命中,透传的流量会不会打沉我们的数据库?**这其实就是行业里常提到的缓存穿透问题,如果缓存出现大规模并发穿透,那么很有可能导致我们服务宕机。
所以,数据库要是扛不住平时的流量,我们就不能使用临时缓存的方式去设计缓存系统,只能用长期缓存这种方式来实现热点缓存,以此避免缓存穿透打沉数据库的问题。不过,要想实现长期缓存,就需要我们人工做更多的事情来保持缓存和数据表数据的一致性。
要知道,长期缓存这个方式自 NoSQL 兴起后才得以普及使用,主要原因在于长期缓存的实现和临时缓存有所不同,它要求我们的业务几乎完全不走数据库,并且服务运转期间所需的数据都要能在缓存中找到,同时还要保证使用期间缓存不会丢失。
由此带来的问题就是,我们需要知道缓存中具体有哪些数据,然后提前对这些数据进行预热。当然,如果数据规模较小,那我们可以考虑把全量数据都缓存起来,这样会相对简单一些。
为了加深理解,同时展示特殊技巧,下面我们来看一种“临时缓存 + 长期热缓存”的一个有趣的实现,这种方式会有小规模缓存穿透,并且代码相对复杂,不过总体来说成本是比较低的:
// 尝试从缓存中直接获取用户信息
userinfo, err := Redis.Get("user_info_9527")
if err != nil {return nil, err
}//缓存命中找到,直接返回用户信息
if userinfo != nil {return userinfo, nil
}//set 检测当前是否是热数据
//之所以没有使用Bloom Filter是因为有概率碰撞不准
//如果key数量超过千个,建议还是用Bloom Filter
//这个判断也可以放在业务逻辑代码中,用配置同步做
isHotKey, err := Redis.SISMEMBER("hot_key", "user_info_9527")
if err != nil {return nil, err
}//如果是热key
if isHotKey {//没有找到就认为数据不存在//可能是被删除了return "", nil
}//没有命中缓存,并且没被标注是热点,被认为是临时缓存,那么从数据库中获取
//设置更新锁set user_info_9527_lock nx ex 5
//防止多个线程同时并发查询数据库导致数据库压力过大
lock, err := Redis.Set("user_info_9527_lock", "1", "nx", 5)
if !lock {//没抢到锁的直接等待1秒 然后再拿一次结果,类似singleflight实现//行业常见缓存服务,读并发能力很强,但写并发能力并不好//过高的并行刷新会刷沉缓存time.sleep( time.second)//等1秒后拿数据,这个数据是抢到锁的请求填入的//通过这个方式降低数据库压力userinfo, err := Redis.Get("user_info_9527")if err != nil {return nil, err}return userinfo,nil
}//拿到锁的查数据库,然后填入缓存
userinfo, err := userInfoModel.GetUserInfoById(9527)
if err != nil {return nil, err
}//查找到用户信息
if userinfo != nil {//将用户信息缓存,并设置TTL超时时间让其60秒后失效Redis.Set("user_info_9527", userinfo, 60)return userinfo, nil
}// 没有找到,放一个空数据进去,短期内不再问数据库
Redis.Set("user_info_9527", "", 30)
return nil, nil
可以看到,这种方式是长期缓存和临时缓存的混用。当我们要查询某个用户信息时,如果缓存中没有数据,长期缓存会直接返回没有找到,临时缓存则直接走更新流程。此外,我们的用户信息如果属于热点 key,并且在缓存中找不到的话,就直接返回数据不存在。
在更新期间,为了防止高并发查询打沉数据库,我们将更新流程做了简单的 singleflight(请求合并)优化,只有先抢到缓存更新锁的线程,才能进入后端读取数据库并将结果填写到缓存中。而没有抢到更新锁的线程先 sleep 1 秒,然后直接读取缓存返回结果。这样可以保证后端不会有多个线程读取同一条数据,从而冲垮缓存和数据库服务(缓存的写并发没有读性能那么好)。
另外,hot_key 列表(也就是长期缓存的热点 key 列表)会在多个 Redis 中复制保存,如果要读取它,随机找一个分片就可以拿到全量配置。
这些热缓存 key,来自于统计一段时间内数据访问流量,计算得出的热点数据。那长期缓存的更新会异步脚本去定期扫描热缓存列表,通过这个方式来主动推送缓存,同时把 TTL 设置成更长的时间,来保证新的热数据缓存不会过期。当这个 key 的热度过去后,热缓存 key 就会从当前 set 中移除,腾出空间给其他地方使用。
当然,如果我们拥有一个很大的缓存集群,并且我们的数据都属于热数据,那么我们大可以脱离数据库,将数据都放到缓存当中直接对外服务,这样我们将获得更好的吞吐和并发。
最后,还有一种方式来缓解热点高并发查询,在每个业务服务器上部署一个小容量的 Redis 来保存热点缓存数据,通过脚本将热点数据同步到每个服务器的小 Redis 上,每次查询数据之前都会在本地小 Redis 查找一下,如果找不到再去大缓存内查询,通过这个方式缓解缓存的读取性能。
总结
通过这节课,我希望你能明白:不是所有的数据放在缓存就能有很好的收益,我们要从数据量、使用频率、缓存命中率三个角度去分析。读多写少的数据做缓存虽然能降低数据层的压力,但要根据一致性需求对其缓存的数据做更新。其中,单条实体数据最容易实现缓存更新,但是有条件查询的统计结果并不容易做到实时更新。
除此之外,如果数据库承受不了透传流量压力,我们需要将一些热点数据做成长期缓存,来防止大量请求穿透缓存,这样会影响我们的服务稳定。同时通过 singleflight 方式预防临时缓存被大量请求穿透,以防热点数据在从临时缓存切换成热点之前,击穿缓存,导致数据库崩溃。
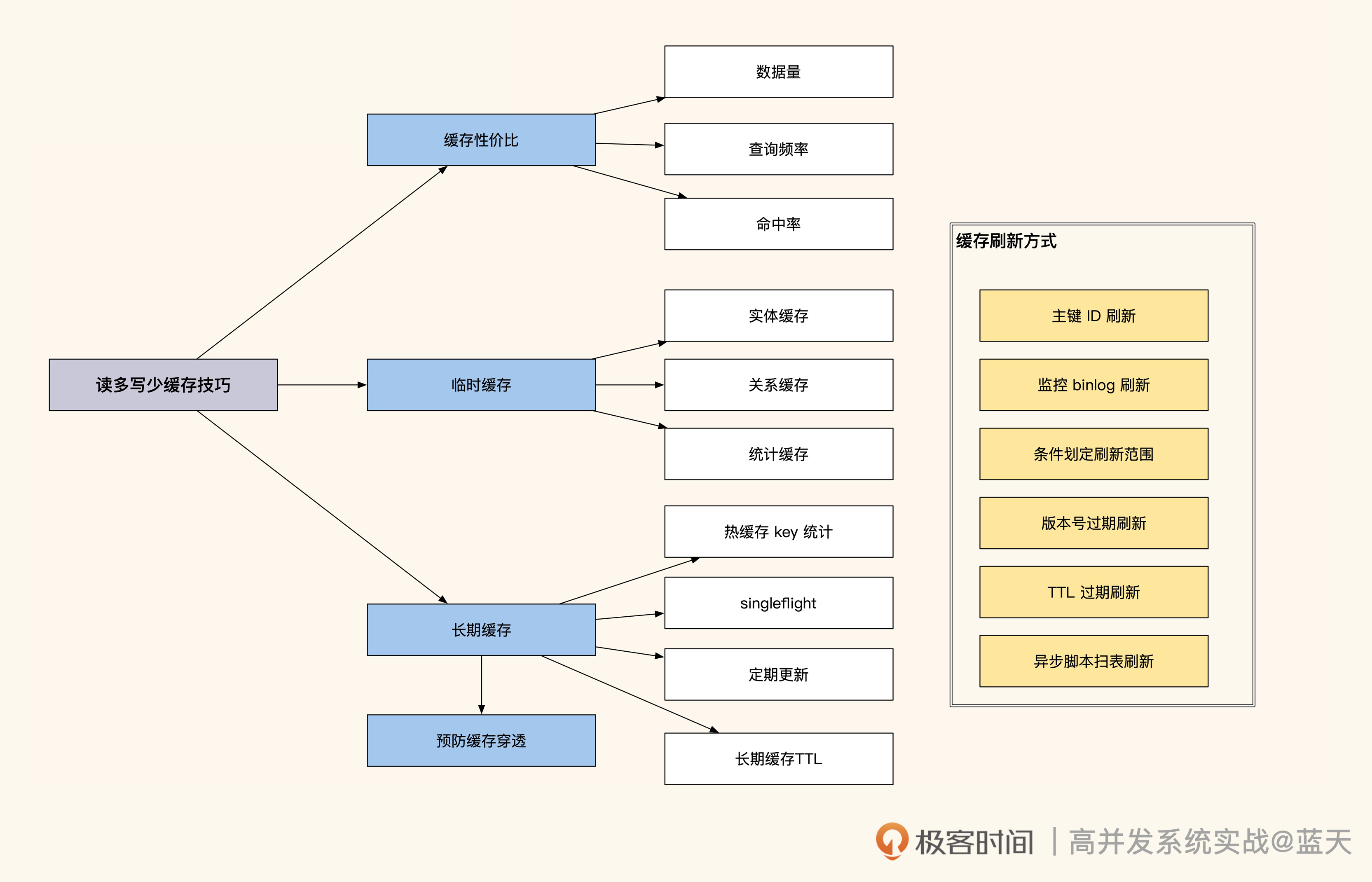
读多写少的缓存技巧我还画了一张导图,如下所示:
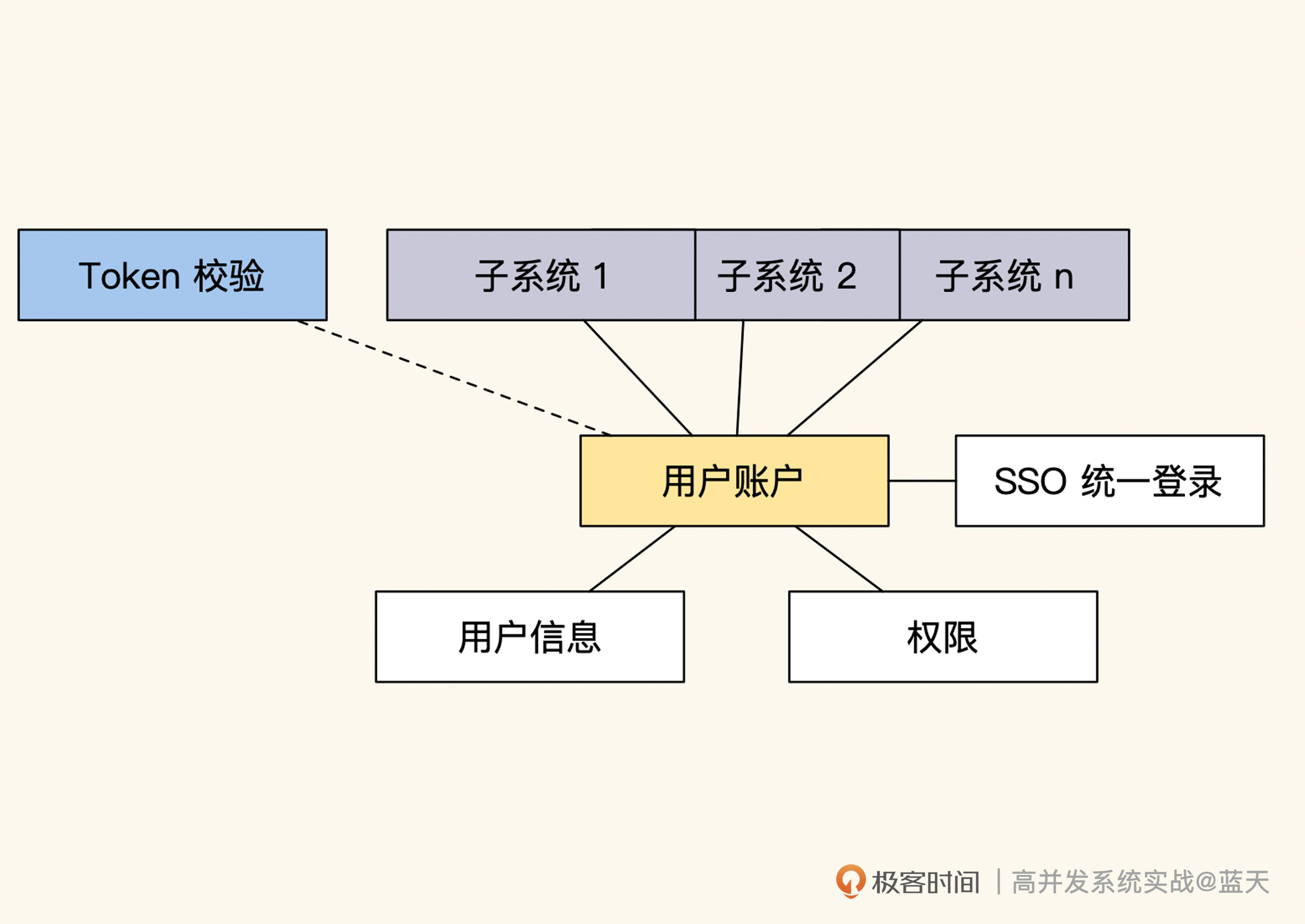
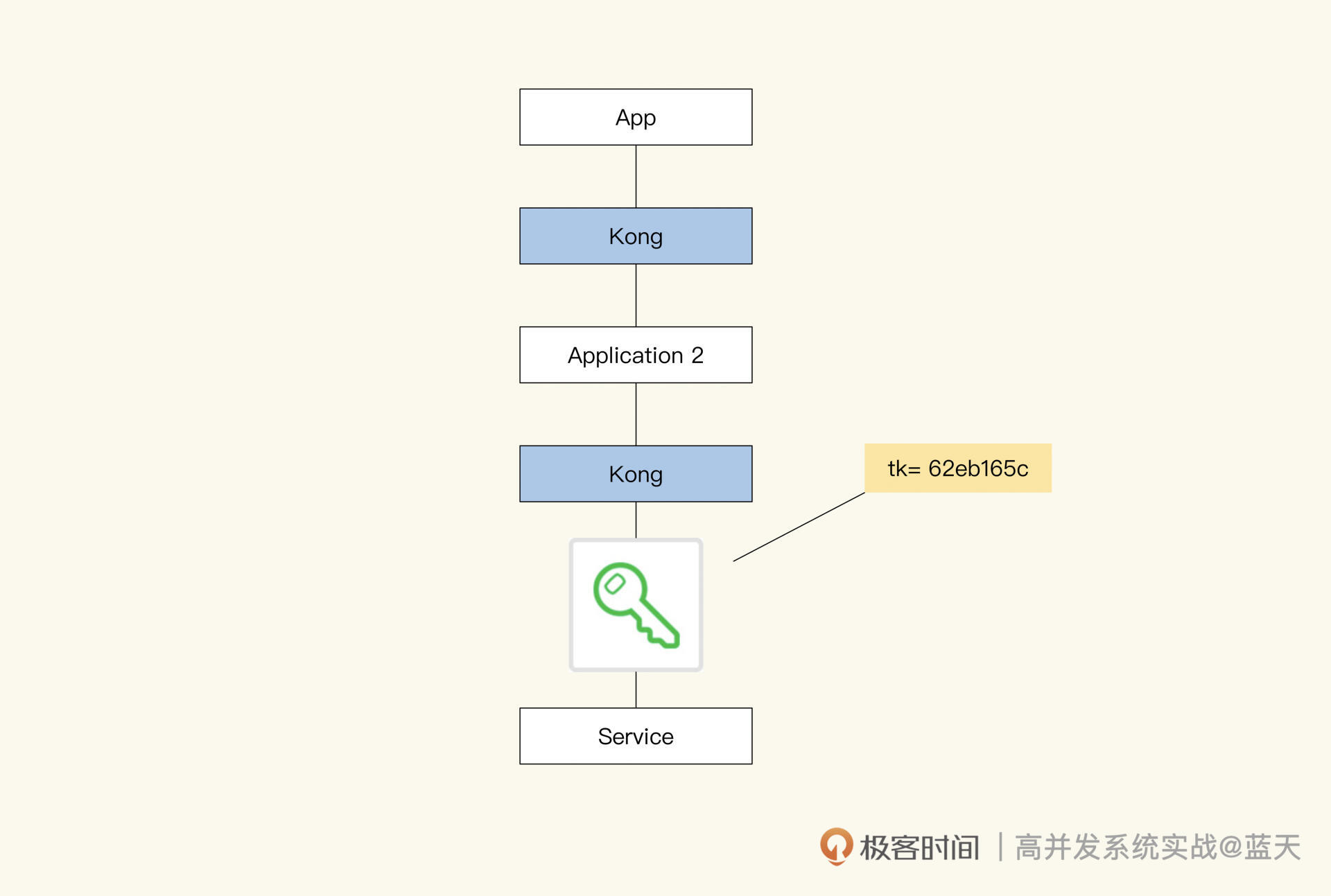
Token:如何降低用户身份鉴权的流量压力?
很多网站初期通常会用 Session 方式实现登录用户的用户鉴权,也就是在用户登录成功后,将这个用户的具体信息写在服务端的 Session 缓存中,并分配一个 session_id 保存在用户的 Cookie 中。该用户的每次请求时候都会带上这个 ID,通过 ID 可以获取到登录时写入服务端 Session 缓存中的记录。
流程图如下所示:
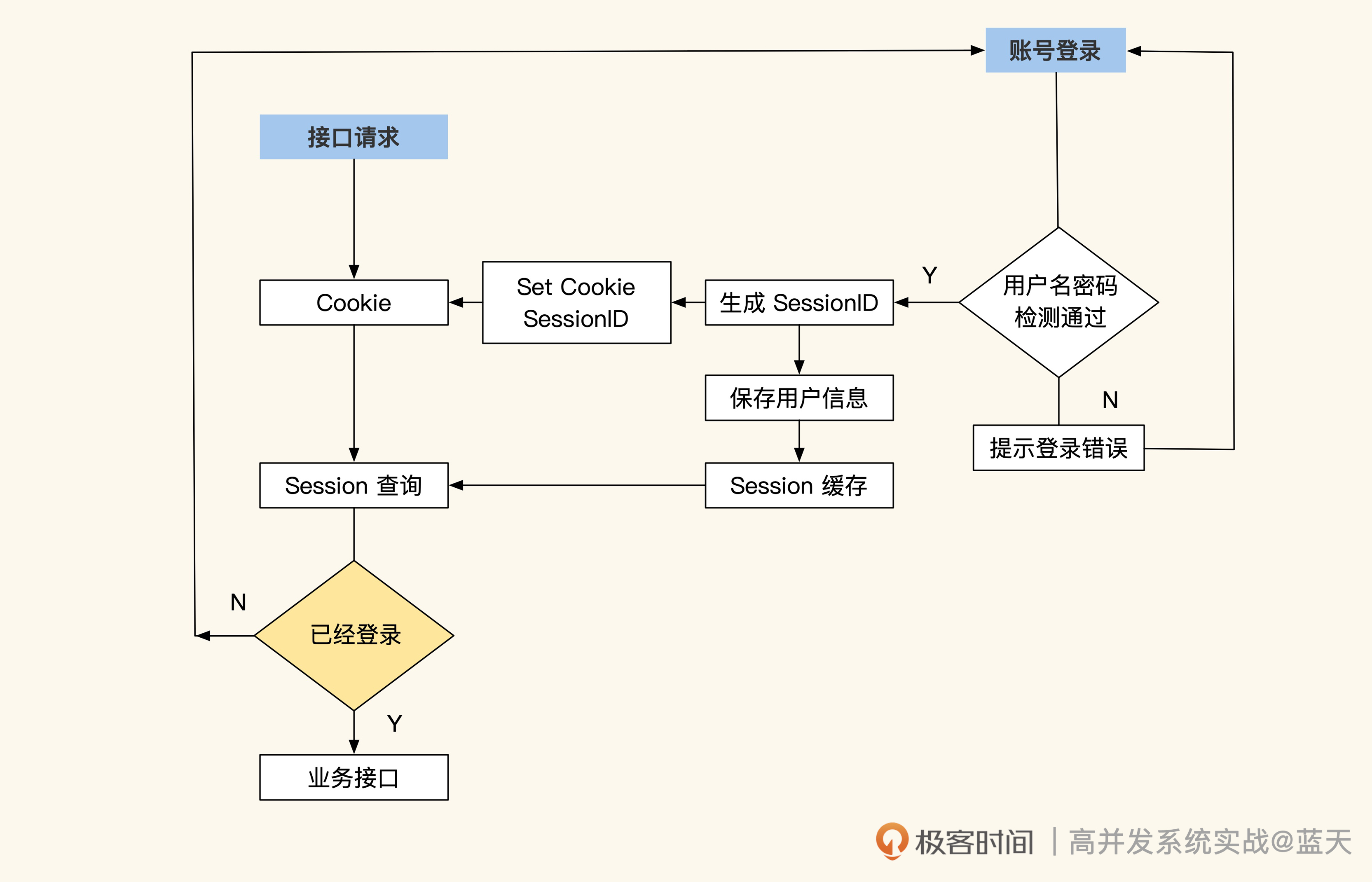
Session Cache实现的用户鉴权
种方式的好处在于信息都在服务端储存,对客户端不暴露任何用户敏感的数据信息,并且每个登录用户都有共享的缓存空间(Session Cache)。
但是随着流量的增长,这个设计也暴露出很大的问题——用户中心的身份鉴权在大流量下很不稳定。因为用户中心需要维护的 Session Cache 空间很大,并且被各个业务频繁访问,那么缓存一旦出现故障,就会导致所有的子系统无法确认用户身份,进而无法正常对外服务。
这主要是由于 Session Cache 和各个子系统的耦合极高,全站的请求都会对这个缓存至少访问一次,这就导致缓存的内容长度和响应速度,直接决定了全站的 QPS 上限,让整个系统的隔离性很差,各子系统间极易相互影响。
那么,如何降低用户中心与各个子系统间的耦合度,提高系统的性能呢?我们一起来看看。
JWT 登陆和 token 校验
常见方式是采用签名加密的 token,这是登录的一个行业标准,即 JWT(JSON Web Token):
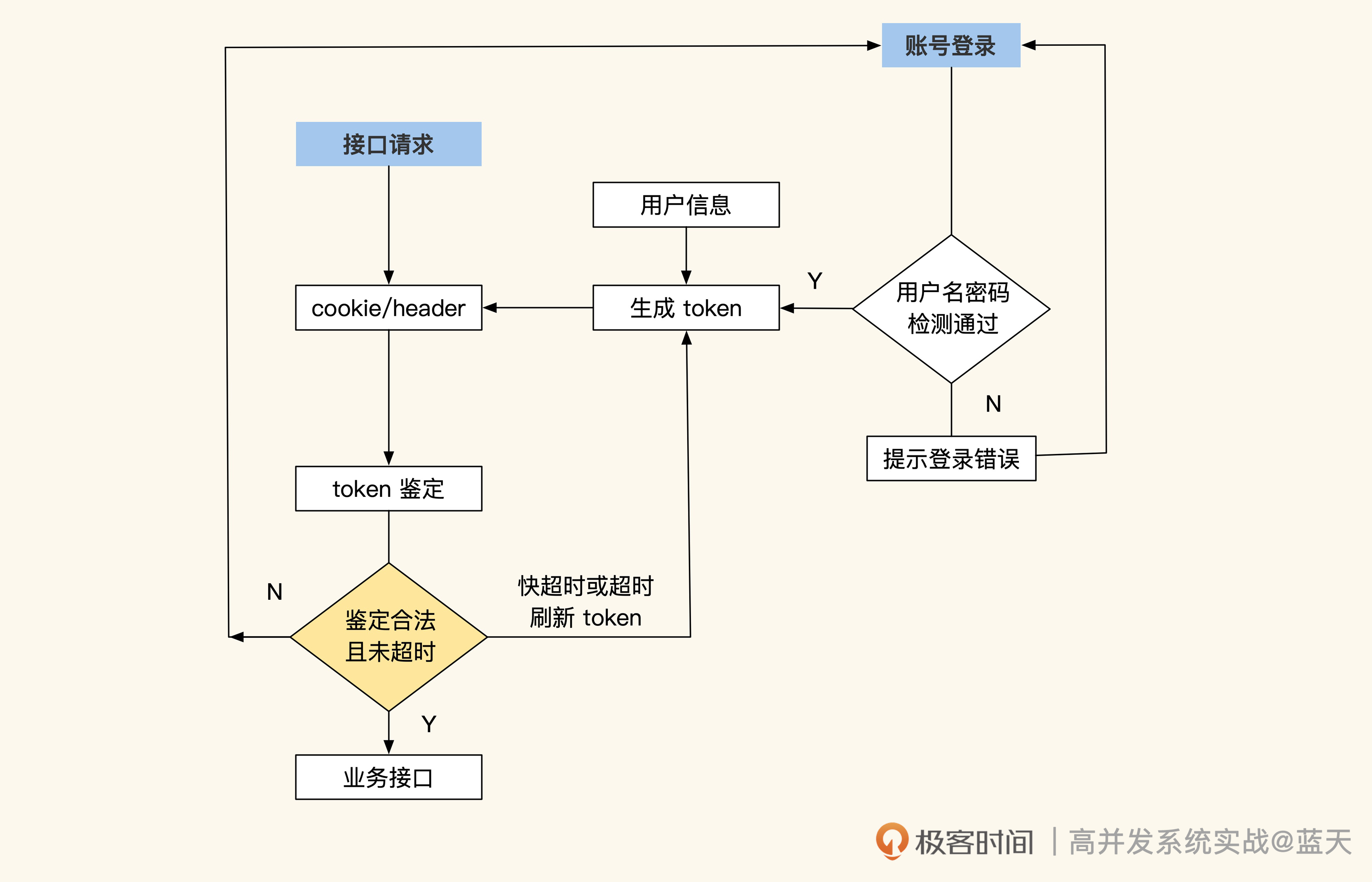
token流程上图就是 JWT 的登陆流程,用户登录后会将用户信息放到一个加密签名的 token 中,每次请求都把这个串放到 header 或 cookie 内带到服务端,服务端直接将这个 token 解开即可直接获取到用户的信息,无需和用户中心做任何交互请求。
token 生成代码如下:
import "github.com/dgrijalva/jwt-go"//签名所需混淆密钥 不要太简单 容易被破解
//也可以使用非对称加密,这样可以在客户端用公钥验签
var secretString = []byte("jwt secret string 137 rick") type TokenPayLoad struct {UserId uint64 `json:"userId"` //用户idNickName string `json:"nickname"` //昵称jwt.StandardClaims //私有部分
}// 生成JWT token
func GenToken(userId uint64, nickname string) (string, error) {c := TokenPayLoad{UserId: userId, //uidNickName: nickname, //昵称//这里可以追加一些其他加密的数据进来//不要明文放敏感信息,如果需要放,必须再加密//私有部分StandardClaims: jwt.StandardClaims{//两小时后失效ExpiresAt: time.Now().Add(2 * time.Hour).Unix(),//颁发者Issuer: "geekbang",},}//创建签名 使用hs256token := jwt.NewWithClaims(jwt.SigningMethodHS256, c)// 签名,获取token结果return token.SignedString(secretString)
}
可以看到,这个 token 内部包含过期时间,快过期的 token 会在客户端自动和服务端通讯更换,这种方式可以大幅提高截取客户端 token 并伪造用户身份的难度。
同时,服务端也可以和用户中心解耦,业务服务端直接解析请求带来的 token 即可获取用户信息,无需每次请求都去用户中心获取。而 token 的刷新可以完全由 App 客户端主动请求用户中心来完成,而不再需要业务服务端业务请求用户中心去更换。
JWT 是如何保证数据不会被篡改,并且保证数据的完整性呢,我们先看看它的组成。
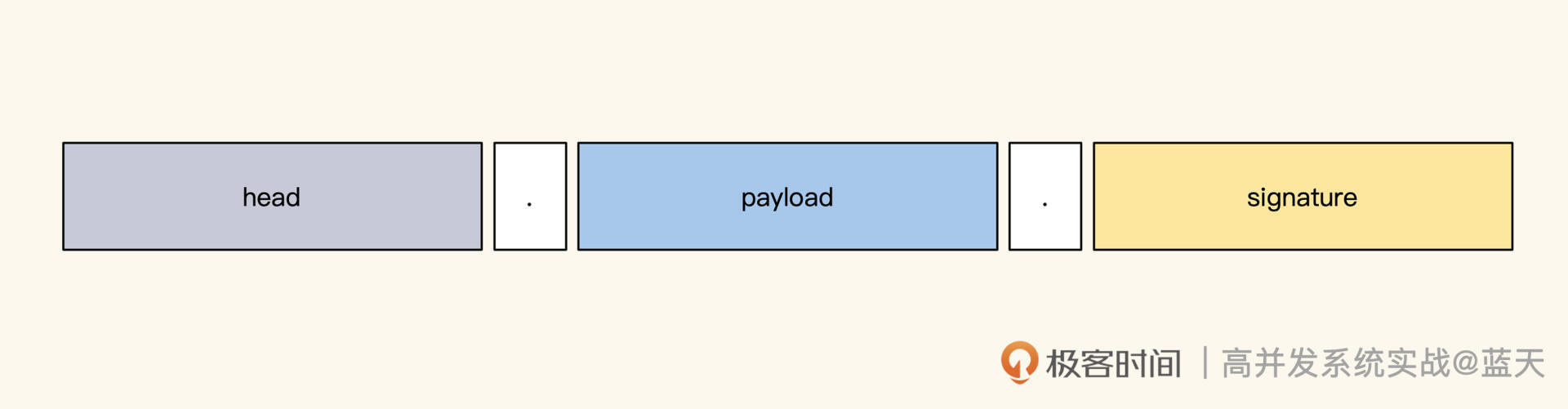
如上图所示,加密签名的 token 分为三个部分,彼此之间用点来分割,其中,Header 用来保存加密算法类型;PayLoad 是我们自定义的内容;Signature 是防篡改签名。
JWT token 解密后的数据结构如下图所示:
//header
//加密头
{"alg": "HS256", // 加密算法,注意检测个别攻击会在这里设置为none绕过签名"typ": "JWT" //协议类型
}//PAYLOAD
//负载部分,存在JWT标准字段及我们自定义的数据字段
{"userid": "9527", //我们放的一些明文信息,如果涉及敏感信息,建议再次加密"nickname": "Rick.Xu", // 我们放的一些明文信息,如果涉及隐私,建议再次加密"iss": "geekbang","iat": 1516239022, //token发放时间"exp": 1516246222, //token过期时间
}//签名
//签名用于鉴定上两段内容是否被篡改,如果篡改那么签名会发生变化
//校验时会对不上
JWT 如何验证 token 是否有效,还有 token 是否过期、是否合法,具体方法如下:
func DecodeToken(token string) (*TokenPayLoad, error) {token, err := jwt.ParseWithClaims(token, &TokenPayLoad{}, func(tk *jwt.Token) (interface{}, error) {return secret, nil})if err != nil {return nil, err}if decodeToken, ok := token.Claims.(*TokenPayLoad); ok && token.Valid {return decodeToken, nil}return nil, errors.New("token wrong")
}
JWT 的 token 解密很简单,第一段和第二段都是通过 base64 编码的。直接解开这两段数据就可以拿到 payload 中所有的数据,其中包括用户昵称、uid、用户权限和 token 过期时间。要验证 token 是否过期,只需将其中的过期时间和本地时间对比一下,就能确认当前 token 是不是有效。
而验证 token 是否合法则是通过签名验证完成的,任何信息修改都会无法通过签名验证。要是通过了签名验证,就表明 token 没有被篡改过,是一个合法的 token,可以直接使用。
这个过程如下图所示:
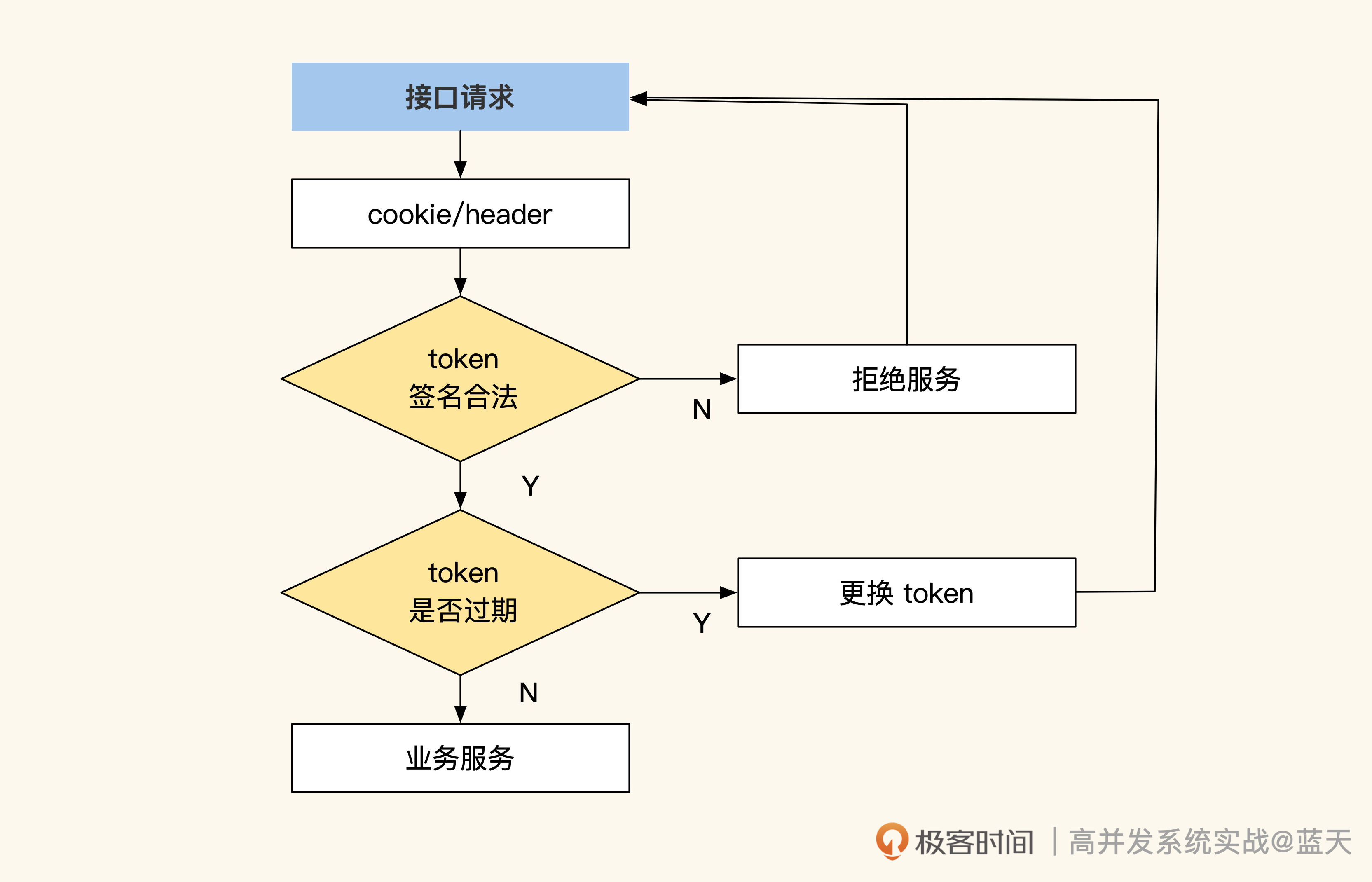 我们可以看到,通过 token 方式,用户中心压力最大的接口可以下线了,每个业务的服务端只要解开 token 验证其合法性,就可以拿到用户信息。不过这种方式也有缺点,就是用户如果被拉黑,客户端最快也要在 token 过期后才能退出登陆,这让我们的管理存在一定的延迟。
我们可以看到,通过 token 方式,用户中心压力最大的接口可以下线了,每个业务的服务端只要解开 token 验证其合法性,就可以拿到用户信息。不过这种方式也有缺点,就是用户如果被拉黑,客户端最快也要在 token 过期后才能退出登陆,这让我们的管理存在一定的延迟。
如果我们希望对用户进行实时管理,可以把新生成的 token 在服务端暂存一份,每次用户请求就和缓存中的 token 对比一下,但这样很影响性能,极少数公司会这么做。同时,为了提高 JWT 系统的安全性,token 一般会设置较短的过期时间,通常是十五分钟左右,过期后客户端会自动更换 token。
token 的更换和离线
那么如何对 JWT 的 token 进行更换和离线验签呢?
具体的服务端换签很简单,只要客户端检测到当前的 token 快过期了,就主动请求用户中心更换 token 接口,重新生成一个离当前还有十五分钟超时的 token。
但是期间如果超过十五分钟还没换到,就会导致客户端登录失败。为了减少这类问题,同时保证客户端长时间离线仍能正常工作,行业内普遍使用双 token 方式,具体你可以看看后面的流程图:
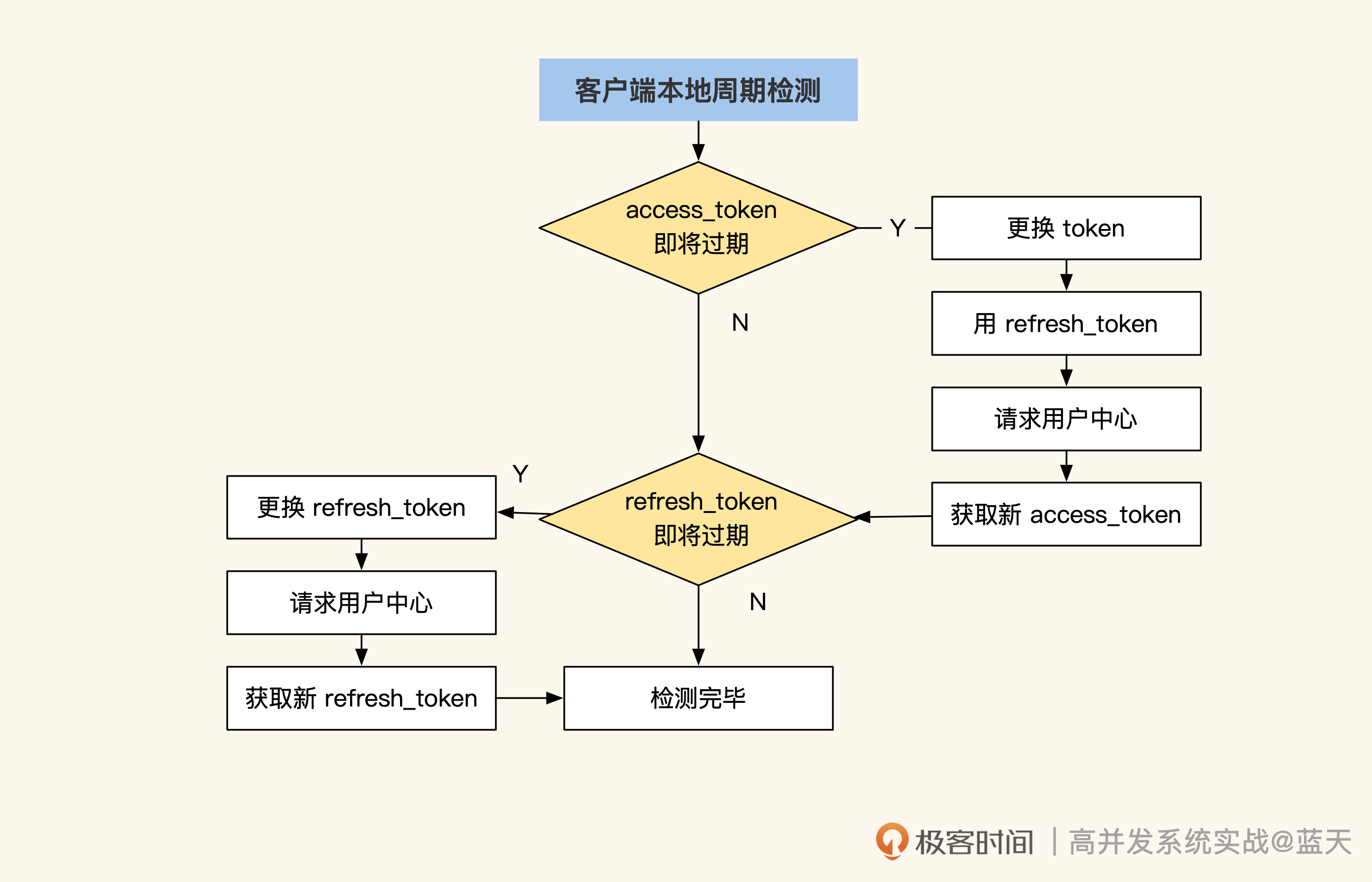
可以看到,这个方案里有两种 token:**一种是 refresh_token,用于更换 access_token,有效期是 30 天;另一种是 access_token,用于保存当前用户信息和权限信息,每隔 15 分钟更换一次。**如果请求用户中心失败,并且 App 处于离线状态,只要检测到本地 refresh_token 没有过期,系统仍可以继续工作,直到 refresh_token 过期为止,然后提示用户重新登陆。这样即使用户中心坏掉了,业务也能正常运转一段时间。
用户中心检测更换 token 的实现如下:
//如果还有五分钟token要过期,那么换token
if decodeToken.StandardClaims.ExpiresAt < TimestampNow() - 300 {//请求下用户中心,问问这个人禁登陆没//....略具体//重新发放tokentoken, err := GenToken(.....)if err != nil {return nil, err}//更新返回cookie中tokenresp.setCookie("xxxx", token)
}
这段代码只是对当前的 token 做了超时更换。JWT 对离线 App 端十分友好,因为 App 可以将它保存在本地,在使用用户信息时直接从本地解析出来即可。
安全建议
最后我再啰嗦几句,除了上述代码中的注释外,在使用 JWT 方案的时候还有一些关键的注意事项,这里分享给你。
第一,通讯过程必须使用 HTTPS 协议,这样才可以降低被拦截的可能。
第二,要注意限制 token 的更换次数,并定期刷新 token,比如用户的 access_token 每天只能更换 50 次,超过了就要求用户重新登陆,同时 token 每隔 15 分钟更换一次。这样可以降低 token 被盗取后给用户带来的影响。第三,Web 用户的 token 保存在 cookie 中时,建议加上 httponly、SameSite=Strict 限制,以防止 cookie 被一些特殊脚本偷走。
总结
传统的 Session 方式是把用户的登录信息通过 SessionID 统一缓存到服务端中,客户端和子系统每次请求都需要到用户中心去“提取”,这就会导致用户中心的流量很大,所有业务都很依赖用户中心。
为了降低用户中心的流量压力,同时让各个子系统与用户中心脱耦,我们采用信任“签名”的 token,把用户信息加密发放到客户端,让客户端本地拥有这些信息。而子系统只需通过签名算法对 token 进行验证,就能获取到用户信息。
这种方式的核心是**把用户信息放在服务端外做传递和维护,以此解决用户中心的流量性能瓶颈。**此外,通过定期更换 token,用户中心还拥有一定的用户控制能力,也加大了破解难度,可谓一举多得。
其实,还有很多类似的设计简化系统压力,比如文件 crc32 校验签名可以帮我们确认文件在传输过程中是否损坏;通过 Bloom Filter 可以确认某个 key 是否存在于某个数据集合文件中等等,这些都可以大大提高系统的工作效率,减少系统的交互压力。这些技巧在硬件能力腾飞的阶段,仍旧适用。
同城双活:如何实现机房之间的数据同步?
在业务初期,考虑到投入成本,很多公司通常只用一个机房提供服务。但随着业务发展,流量不断增加,我们对服务的响应速度和可用性有了更高的要求,这时候我们就要开始考虑将服务分布在不同的地区来提供更好的服务,这是互联网公司在流量增长阶段的必经之路。
之前我所在的公司,流量连续三年不断增长。一次,机房对外网络突然断开,线上服务全部离线,网络供应商失联。因为没有备用机房,我们经过三天紧急协调,拉起新的线路才恢复了服务。这次事故影响很大,公司损失达千万元。
经过这次惨痛的教训,我们将服务迁移到了大机房,并决定在同城建设双机房提高可用性。这样当一个机房出现问题无法访问时,用户端可以通过 HttpDNS 接口快速切换到无故障机房。
为了保证在一个机房损坏的情况下,另外一个机房能直接接手流量,这两个机房的设备必须是 1:1 采购。但让其中一个机房长时间冷备不工作过于浪费,因此我们期望两个机房能同时对外提供服务,也就是实现同城双机房双活。
对此,我们碰到的一个关键问题就是,如何实现同城双活的机房数据库同步?
核心数据中心设计
因为数据库的主从架构,全网必须只能有一个主库,所以我们只能有一个机房存放更新数据的主库,再由这个机房同步给其他备份机房。虽然机房之间有专线连接,但并不能保证网络完全稳定。如果网络出现故障,我们要想办法确保机房之间能在网络修复后快速恢复数据同步。
有人可能会说,直接采用分布式数据库不就得了。要知道改变现有服务体系,投入到分布式数据库的大流中需要相当长的时间,成本也非常高昂,对大部分公司来说是不切实际的。所以我们要看看怎么对现有系统进行改造,实现同城双活的机房数据库同步,这也是我们这节课的目标。
核心数据库中心方案是常见的实现方式,这种方案只适合相距不超过 50 公里的机房。
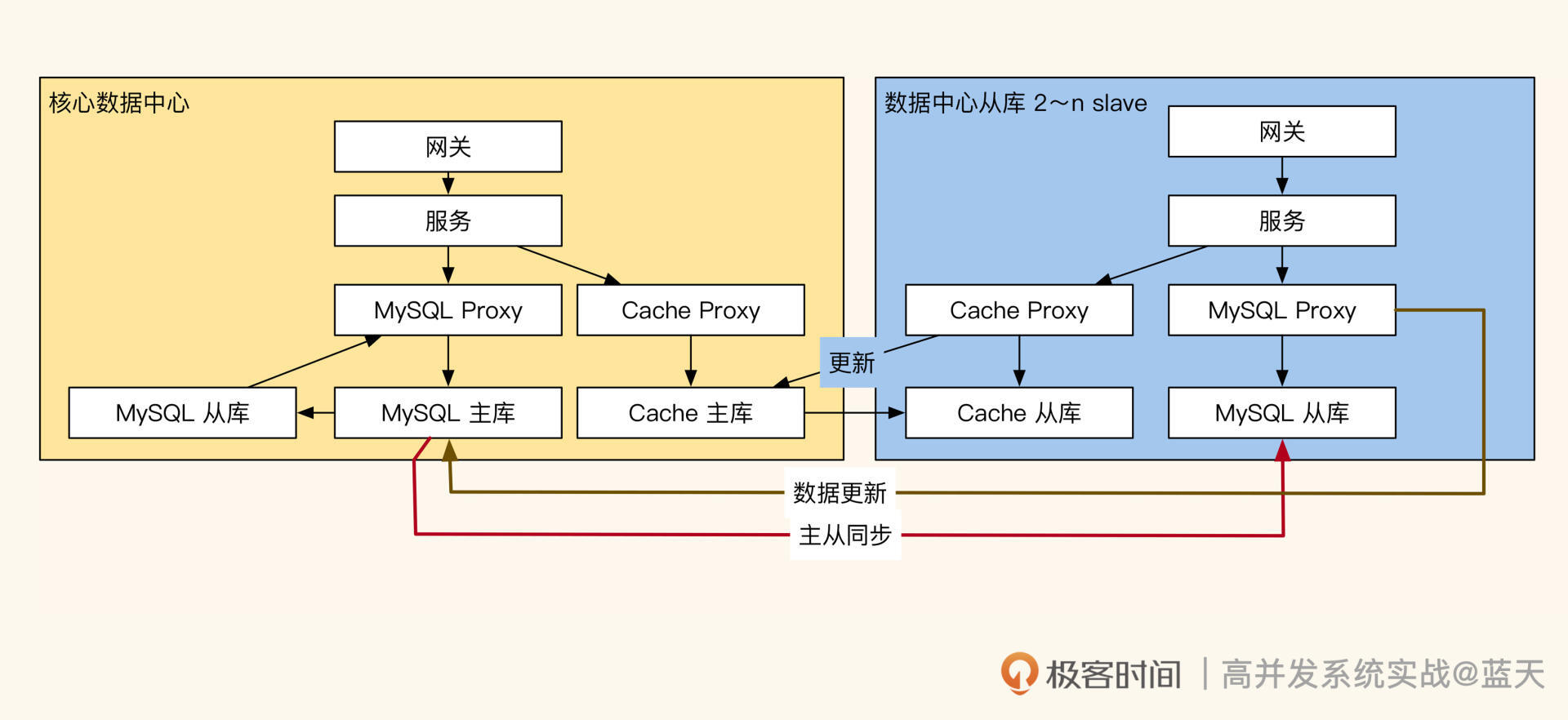
同城双活单向同步
在这个方案中,数据库主库集中在一个机房,其他机房的数据库都是从库。当有数据修改请求时,核心机房的主库先完成修改,然后通过数据库主从同步把修改后的数据传给备份机房的从库。由于用户平时访问的信息都是从缓存中获取的,为了降低主从延迟,备份机房会把修改后的数据先更新到本地缓存。
与此同时,客户端会在本地记录下数据修改的最后时间戳(如果没有就取当前时间)。当客户端请求服务端时,服务端会自动对比缓存中对应数据的更新时间,是否小于客户端本地记录的修改时间。
如果缓存更新时间小于客户端内的修改时间,服务端会触发同步指令尝试在从库中查找最新数据;如果没有找到,就把从主库获取的最新数据放到被访问机房的缓存中。这种方式可以避免机房之间用户数据更新不及时的问题。

客户端切换强迫服务端刷新本地缓存逻辑
除此之外,客户端还会通过请求调度接口,让一个用户在短期内只访问一个机房,防止用户在多机房间来回切换的过程中,数据在两个机房同时修改引发更新合并冲突。
总体来看,这是一个相对简单的设计,但缺点也很多。比如如果核心机房离线,其他机房就无法更新,故障期间需要人工切换各个 proxy 内的主从库配置才能恢复服务,并且在故障过后还需要人工介入恢复主从同步。
此外,因为主从同步延迟较大,业务中刚更新的数据要延迟一段时间,才能在备用机房查到,这会导致我们业务需要人工兼顾这种情况,整体实现十分不便。
这里我给你一个常见的网络延迟参考:
- 同机房服务器:0.1 ms
- 同城服务器(100 公里以内) :1ms(10 倍 同机房)
- 北京到上海: 38ms(380 倍 同机房)
- 北京到广州:53ms(530 倍 同机房)
注意,上面只是一次 RTT 请求,而机房间的同步是多次顺序地叠加请求。如果要大规模更新数据,主从库的同步延迟还会加大,所以这种双活机房的数据量不能太大,并且业务不能频繁更新数据。
此外还要注意,如果服务有强一致性的要求,所有操作都必须在主库“远程执行”,那么这些操作也会加大主从同步延迟。
除了以上问题外,双机房之间的专线还会偶发故障。我碰到过机房之间专线断开两小时的情况,期间只能临时用公网保持同步,但公网同步十分不稳定,网络延迟一直在 10ms~500ms 之间波动,主从延迟达到了 1 分钟以上。好在用户中心服务主要以长期缓存的方式存储数据,业务的主要流程没有出现太大问题,只是用户修改信息太慢了。
有时候,双机房还会偶发主从同步断开,对此建议做告警处理。一旦出现这种情况,就发送通知到故障警报群,由 DBA 人工修复处理。
另外,我还碰到过主从不同步期间,有用户注册自增 ID 出现重复,导致主键冲突这种情况。这里我推荐将自增 ID 更换为“由 SnowFlake 算法计算出的 ID”,这样可以减少机房不同步导致的主键冲突问题。
可以看到,核心数据库的中心方案虽然实现了同城双机房双活,但是人力投入很大。DBA 需要手动维护同步,主从同步断开后恢复起来也十分麻烦,耗时耗力,而且研发人员需要时刻关注主从不同步的情况,整体维护起来十分不便,所以我在这里推荐另外一个解决方案:数据库同步工具 Otter。
跨机房同步神器:Otter
Otter 是阿里开发的数据库同步工具,它可以快速实现跨机房、跨城市、跨国家的数据同步。如下图所示,其核心实现是通过 Canal 监控主库 MySQL 的 Row binlog,将数据更新并行同步给其他机房的 MySQL。
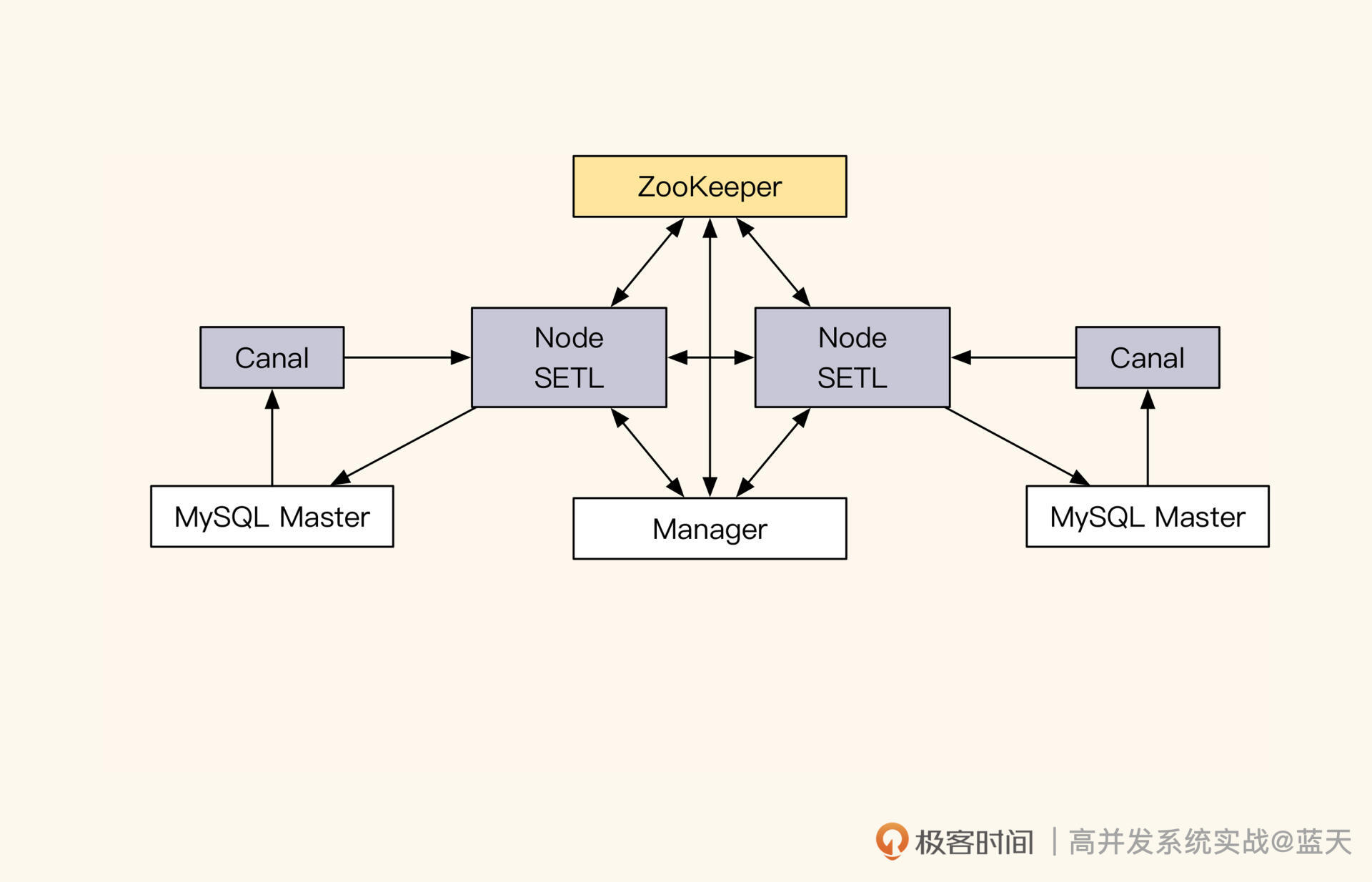
Otter主要部署结构
因为我们要实现同城双机房双活,所以这里我们用 Otter 来实现同城双主(注意:双主不通用,不推荐一致要求高的业务使用),这样双活机房可以双向同步:
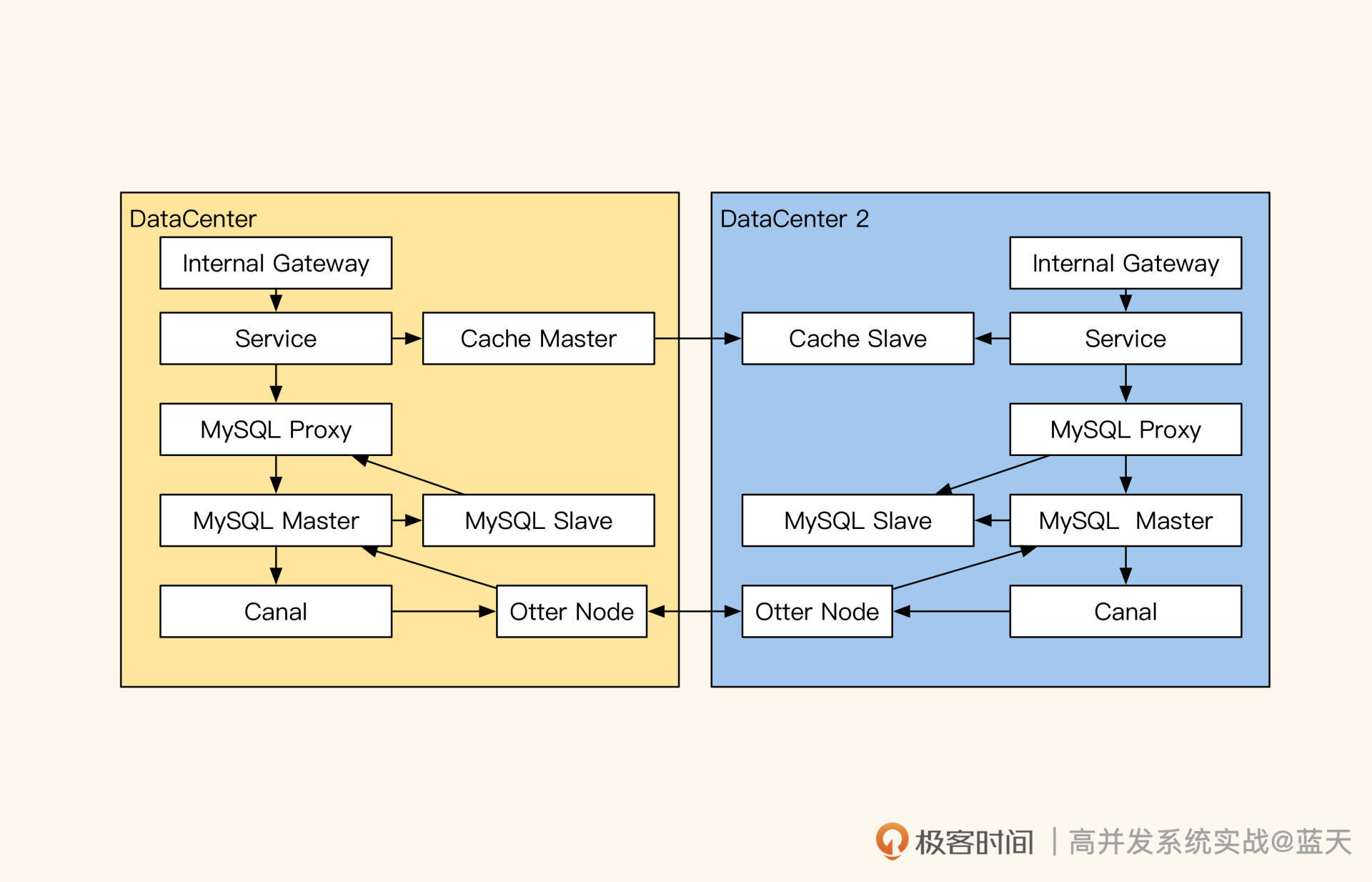
同城双活双向同步方案
如上图,每个机房内都有自己的主库和从库,缓存可以是跨机房主从,也可以是本地主从,这取决于业务形态。Otter 通过 Canal 将机房内主库的数据变更同步到 Otter Node 内,然后经由 Otter 的 SETL 整理后,再同步到对面机房的 Node 节点中,从而实现双机房之间的数据同步。
讲到这里不得不说一下,Otter 是怎么解决两个机房同时修改同一条数据所造成的冲突的。
在 Otter 中数据冲突有两种:一种是行冲突,另一种是字段冲突。行冲突可以通过对比数据修改时间来解决,或者是在冲突时回源查询覆盖目标库;对于字段冲突,我们可以根据修改时间覆盖或把多个修改动作合并,比如 a 机房 -1,b 机房 -1,合并后就是 -2,以此来实现数据的最终一致性。
但是请注意,这种合并方式并不适合库存一类的数据管理,因为这样会出现超卖现象。如果有类似需求,建议用长期缓存解决。
Otter 不仅能支持双主机房,还可以支持多机房同步,比如星形双向同步、级联同步(如下图)等。但是这几种方式并不实用,因为排查问题比较困难,而且当唯一决策库出现问题时,恢复起来很麻烦。所以若非必要,不推荐用这类复杂的结构。
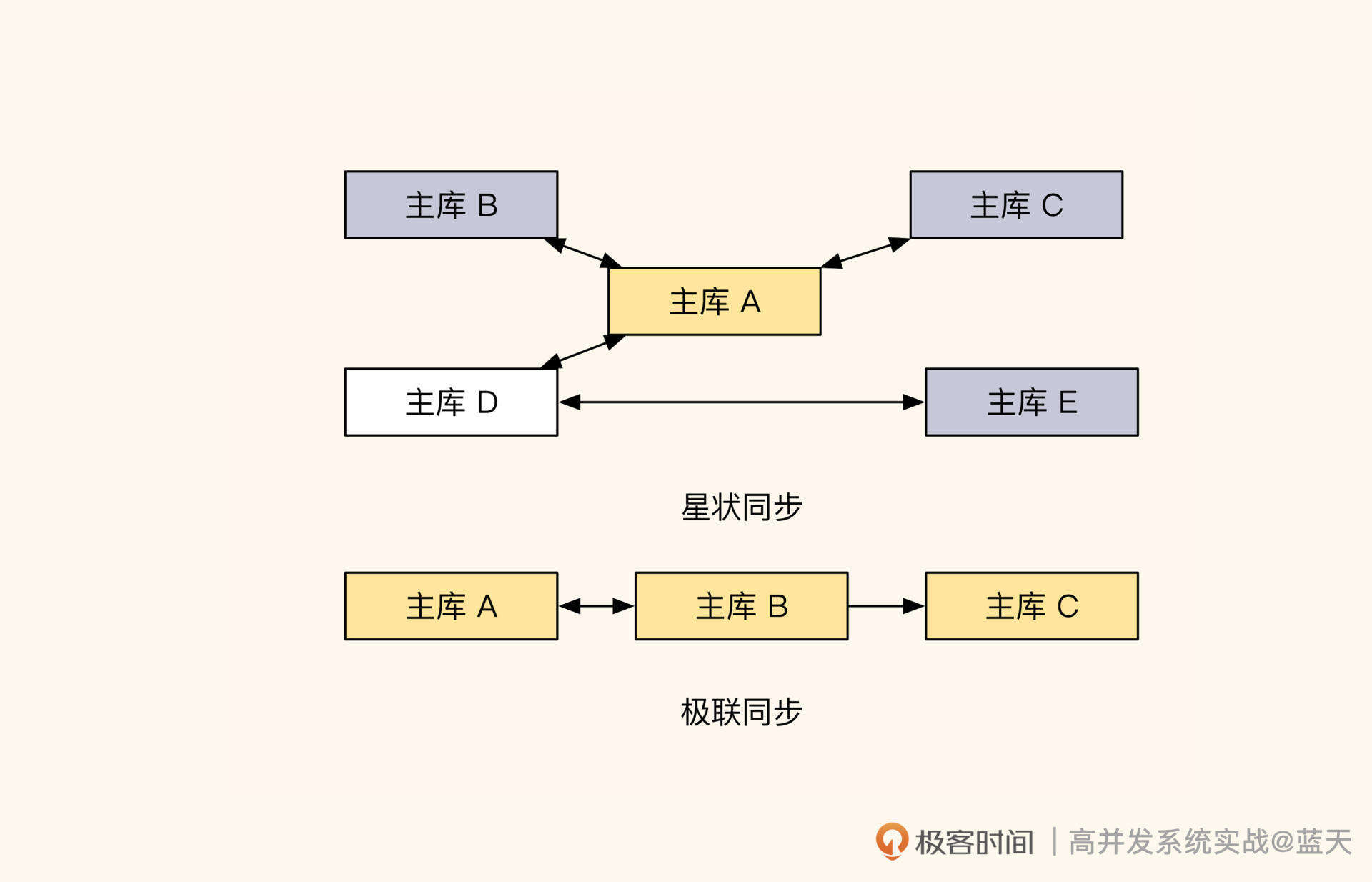
另外,我还要强调一点,我们讲的双活双向同步方案只适合同城。一般来说,50~100 公里以内的机房同步都属于同城内。
超过这个距离的话,建议只做数据同步备份,因为同步延迟过高,业务需要在每一步关注延迟的代价过大。如果我们的业务对一致性的要求极高,那么建议在设计时,把这种一致性要求限制在同一个机房内,其他数据库只用于保存结果状态。
那为什么机房间的距离必须是 100 公里以内呢?你看看 Otter 对于不同距离的同步性能和延迟参考,应该就能理解了。
具体表格如下所示:
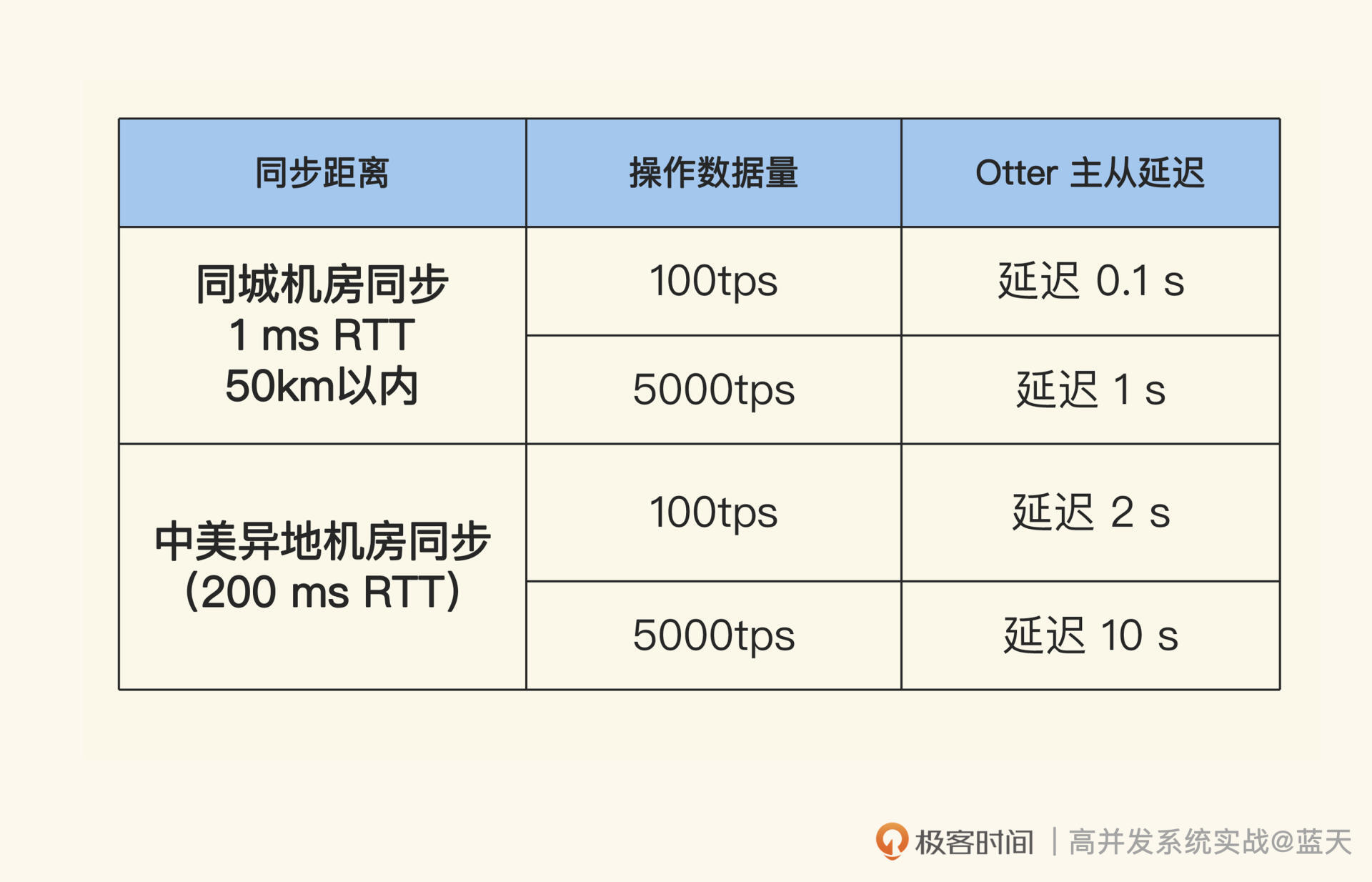
为了提高跨机房数据同步的效率,Otter 对用于主从同步的操作日志做了合并,把同一条数据的多次修改合并成了一条日志,同时对网络传输和同步策略做了滑窗并行优化。
对比 MySQL 的同步,Otter 有 5 倍的性能提升。通过上面的表格可以看到,通过 Otter 实现的数据同步并发性能好、延迟低,只要我们将用户一段时间内的请求都控制在一个机房内不频繁切换,那么相同数据的修改冲突就会少很多。
用 Otter 实现双向同步时,我们的业务不需要做太多改造就能适应双主双活机房。具体来说,业务只需要操作本地主库,把“自增主键”换成“snowflake 算法生成的主键”、“唯一索引互斥”换成“分布式互斥锁”,即可满足大部分需求。
但是要注意,采用同城双活双向同步方案时,数据更新不能过于频繁,否则会出现更大的同步延迟。当业务操作的数据量不大时,才会有更好的效果。
说到这里,我们再讲一讲 Otter 的故障切换。目前 Otter 提供了简单的主从故障切换功能,在 Manager 中点击“切换”,即可实现 Canal 和数据库的主从同步方式切换。如果是同城双活,那关于数据库操作的原有代码我们不需要做更改,因为这个同步是双向的。
当一个机房出现故障时,先将故障机房的用户流量引到正常运转的机房,待故障修复后再恢复数据同步即可,不用切换业务代码的 MySQL 主从库 IP。切记,如果双活机房有一个出现故障了,其他城市的机房只能用于备份或临时独立运行,不要跨城市做双活,因为同步延迟过高会导致业务数据损坏的后果。
最后,我再啰嗦一下使用 Otter 的注意事项:第一,为了保证数据的完整性,变更表结构时,我们一般会先从从库修改表结构,因此在设置 Otter 同步时,建议将 pipeline 同步设置为忽略 DDL 同步错误;第二,数据库表新增字段时,只能在表结尾新增,不能删除老字段,并且建议先把新增字段同步到目标库,然后再同步到主库,因为只有这样才不会丢数据;第三,双向同步的表在新增字段时不要有默认值,同时 Otter 不支持没有主键的表同步。
总结
机房之间的数据同步一直是行业里的痛,因为高昂的实现代价,如果不能做到双活,总是会有一个 1:1 机器数量的机房在空跑,而且发生故障时,没有人能保证冷备机房可以马上对外服务。
但是双活模式的维护成本也不低,机房之间的数据同步常常会因为网络延迟或数据冲突而停止,最终导致两个机房的数据不一致。好在 Otter 对数据同步做了很多措施,能在大多数情况下保证数据的完整性,并且降低了同城双活的实现难度。
即使如此,在业务的运转过程中,我们仍然需要人工梳理业务,避免多个机房同时修改同一条数据。对此,我们可以通过 HttpDNS 调度,让一个用户在某一段时间内只在一个机房内活跃,这样可以降低数据冲突的情况。
而对于修改频繁、争抢较高的服务,一般都会在机房本地做整体事务执行,杜绝跨机房同时修改导致同步错误的发生。
共识Raft:如何保证多机房数据的一致性?
如果机房 A 对某一条数据做了更改,B 机房同时修改,Otter 会用合并逻辑对冲突的数据行或字段做合并。为了避免类似问题,我们在上节课对客户端做了要求:用户客户端在一段时间内只能访问一个机房。
但如果业务对“事务 + 强一致”的要求极高,比如库存不允许超卖,那我们通常只有两种选择:一种是将服务做成本地服务,但这个方式并不适合所有业务;另一种是采用多机房,但需要用分布式强一致算法保证多个副本的一致性。
在行业里,最知名的分布式强一致算法要属 Paxos,但它的原理过于抽象,在使用过程中经过多次修改会和原设计产生很大偏离,这让很多人不确定自己的修改是不是合理的。而且,很多人需要一到两年的实践经验才能彻底掌握这个算法。
随着我们对分布式多副本同步的需求增多,过于笼统的 Paxos 已经不能满足市场需要,于是,Raft 算法诞生了。相比 Paxos,Raft 不仅更容易理解,还能保证数据操作的顺序,因此在分布式数据服务中被广泛使用,像 etcd、Kafka 这些知名的基础组件都是用 Raft 算法实现的。
那今天这节课我们就来探寻一下 Raft 的实现原理,可以说了解了 Raft,就相当于了解了分布式强一致性数据服务的半壁江山。几乎所有关于多个数据服务节点的选举、数据更新和同步都是采用类似的方式实现的,只是针对不同的场景和应用做了一些调整。
如何选举 Leader?
为了帮你快速熟悉 Raft 的实现原理,下面我会基于 Raft 官方的例子,对 Raft 进行讲解。
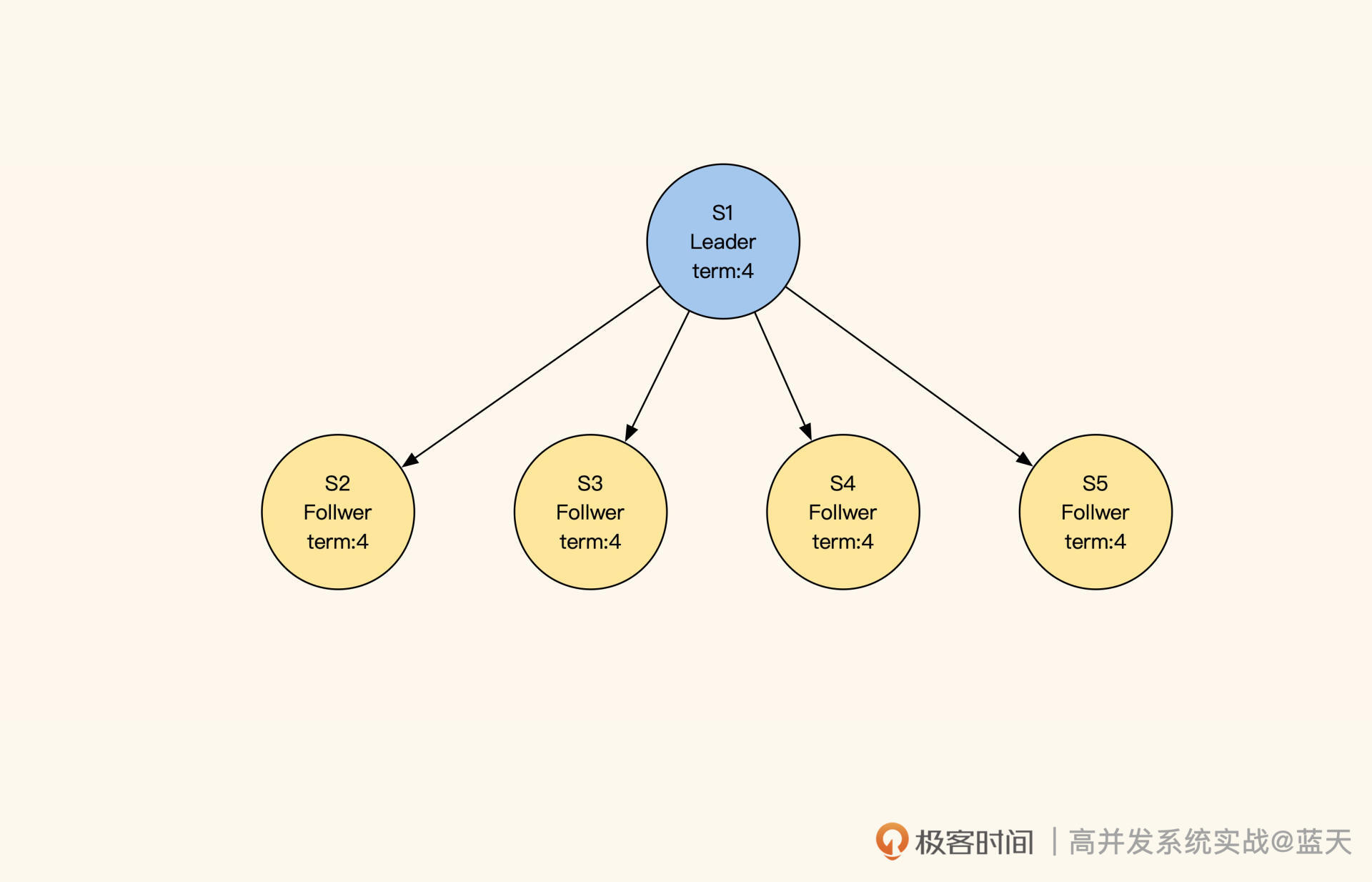
Raft服务状态角色、调用关系、日志
如图所示,我们启动五个 Raft 分布式数据服务:S1、S2、S3、S4、S5,每个节点都有以下三种状态:
- Leader:负责数据修改,主动同步修改变更给 Follower;
- Follower:接收 Leader 推送的变更数据;
- Candidate:集群中如果没有 Leader,那么进入选举模式。
如果集群中的 Follower 节点在指定时间内没有收到 Leader 的心跳,那就代表 Leader 损坏,集群无法更新数据。这时候 Follower 会进入选举模式,在多个 Follower 中选出一个 Leader,保证一组服务中一直存在一个 Leader,同时确保数据修改拥有唯一的决策进程。
那 Leader 服务是如何选举出来的呢?进入选举模式后,这 5 个服务会随机等待一段时间。等待时间一到,当前服务先投自己一票,并对当前的任期“term”加 1 (上图中 term:4 就代表第四任 Leader),然后对其他服务发送 RequestVote RPC(即请求投票)进行拉票。
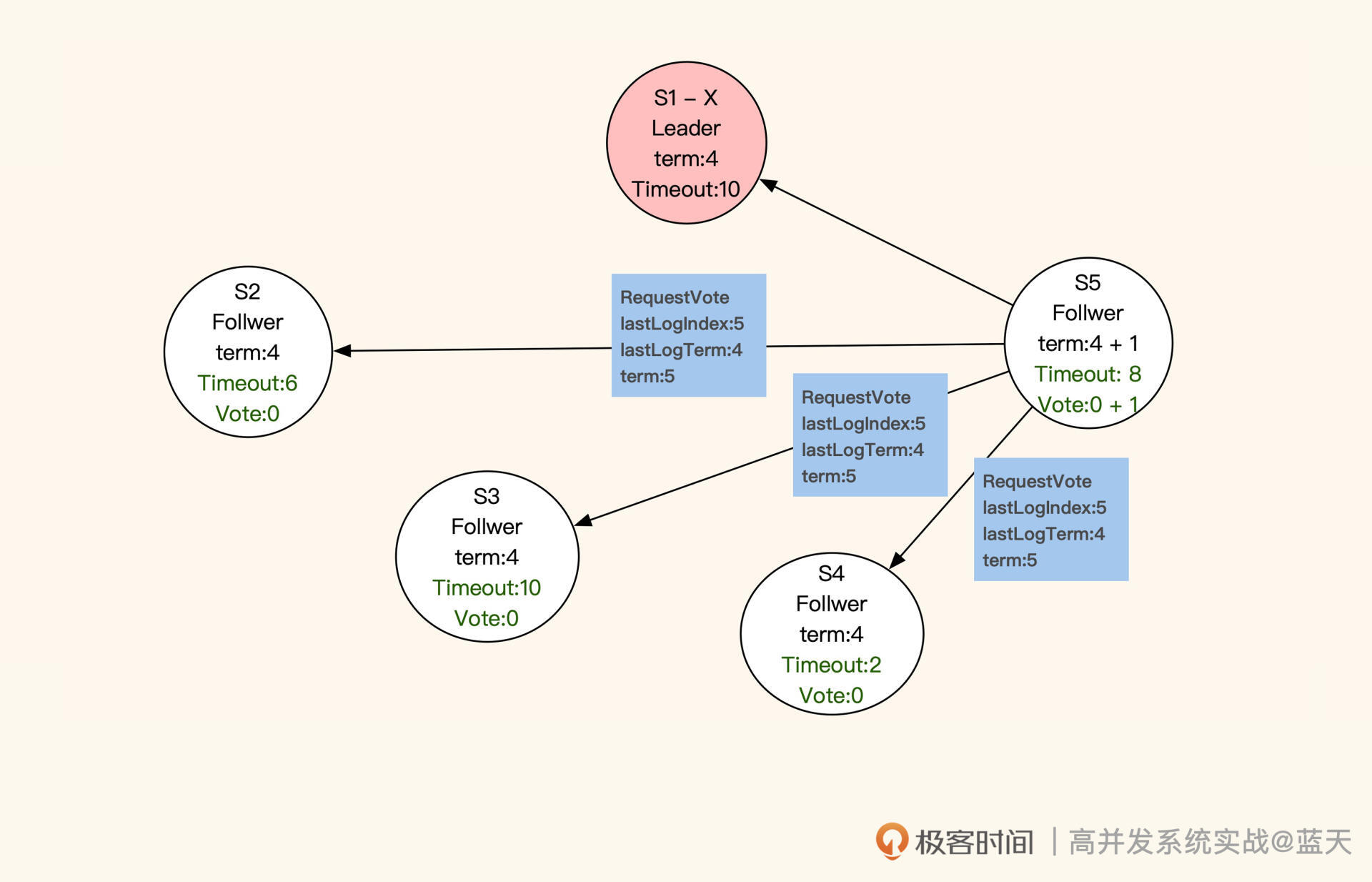
S1失去联系,S5最先超时发起选举
收到投票申请的服务,并且申请服务(即“发送投票申请的服务”)的任期和同步进度都比它超前或相同,那么它就会投申请服务一票,并把当前的任期更新成最新的任期。同时,这个收到投票申请的服务不再发起投票,会等待其他服务邀请。
注意,每个服务在同一任期内只投票一次。如果所有服务都没有获取到多数票(三分之二以上服务节点的投票),就会等当前选举超时后,对任期加 1,再次进行选举。最终,获取多数票且最先结束选举倒计时的服务会被选为 Leader。
被选为 Leader 的服务会发布广播通知其他服务,并向其他服务同步新的任期和其进度情况。同时,新任 Leader 会在任职期间周期性发送心跳,保证各个子服务(Follwer)不会因为超时而切换到选举模式。在选举期间,若有服务收到上一任 Leader 的心跳,则会拒绝(如下图 S1)。
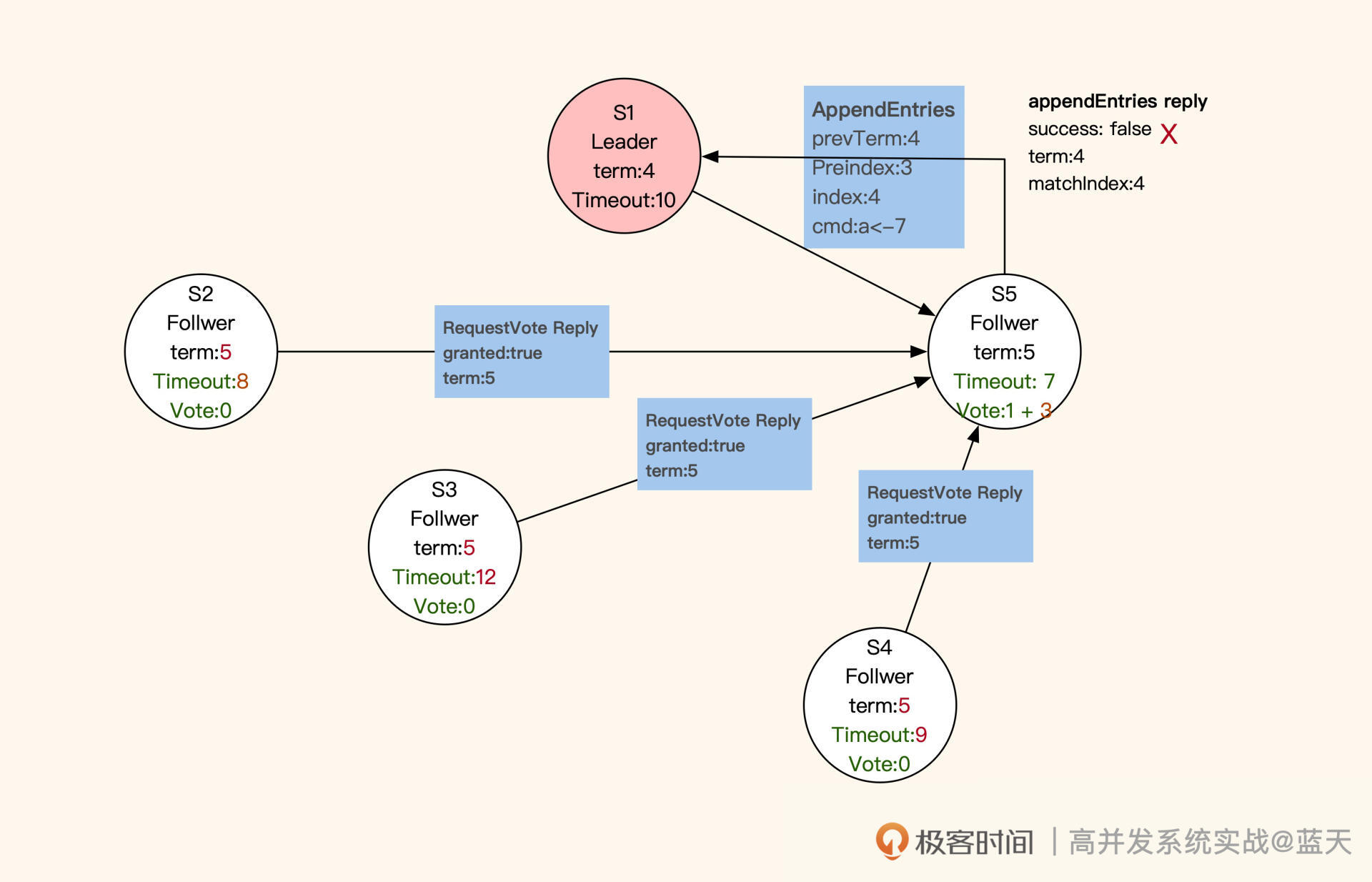
投票结果返回
选举结束后,所有服务都进入数据同步状态。
如何保证多副本写一致?
在数据同步期间,Follower 会与 Leader 的日志完全保持一致。不难看出,Raft 算法采用的也是主从方式同步,只不过 Leader 不是固定的服务,而是被选举出来的。
这样当个别节点出现故障时,是不会影响整体服务的。不过,这种机制也有缺点:如果 Leader 失联,那么整体服务会有一段时间忙于选举,而无法提供数据服务。
通常来说,客户端的数据修改请求都会发送到 Leader 节点(如下图 S1)进行统一决策,如果客户端请求发送到了 Follower,Follower 就会将请求重定向到 Leader。那么,Raft 是怎么实现同分区数据备份副本的强一致性呢?
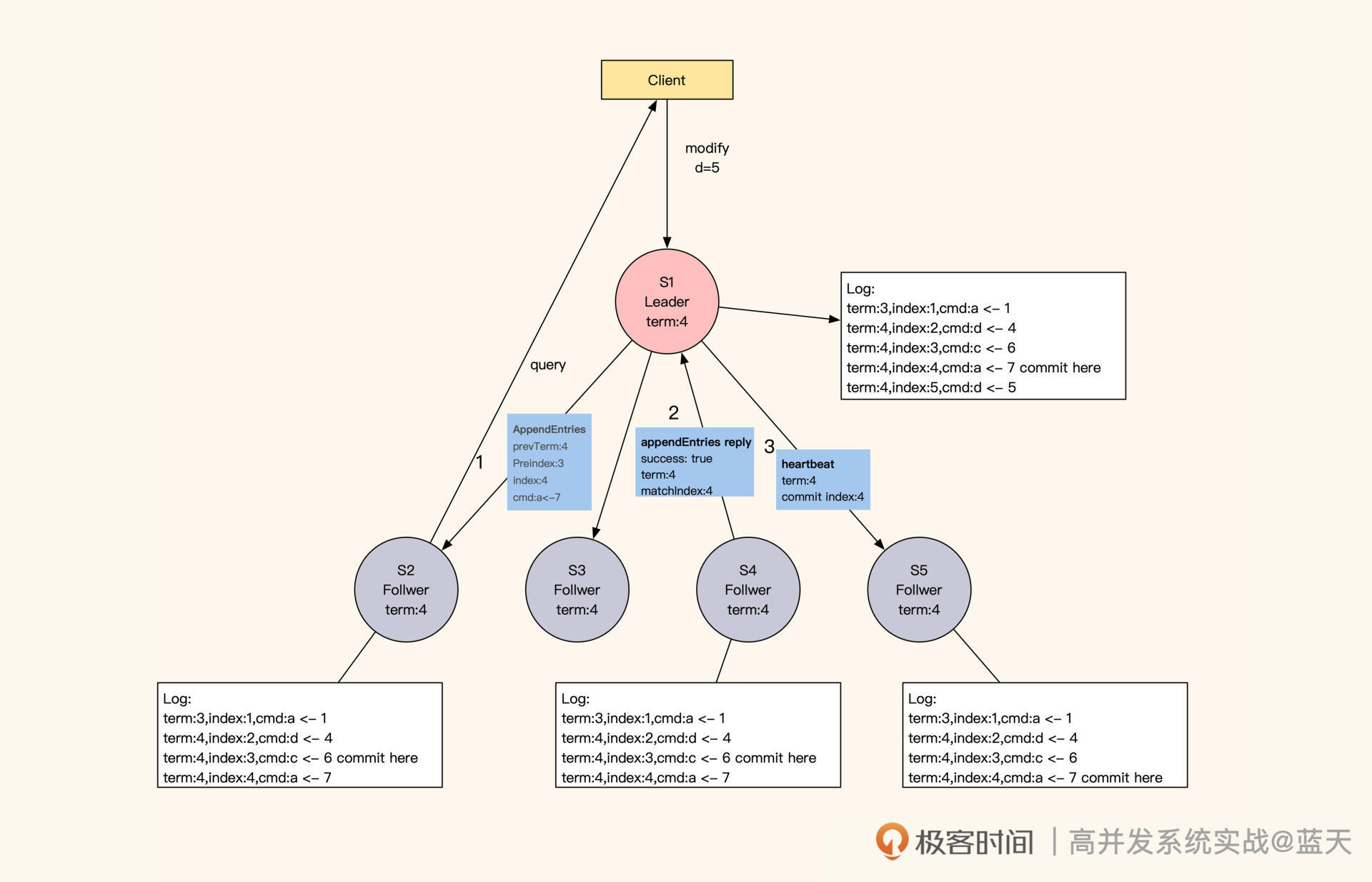
多副本同步
具体来讲,Leader 成功修改数据后,会产生对应的日志,然后 Leader 会给所有 Follower 发送单条日志同步信息。只要大多数 Follower 返回同步成功,Leader 就会对预提交的日志进行 commit,并向客户端返回修改成功。
接着,Leader 在下一次心跳时(消息中 leader commit 字段),会把当前最新 commit 的 Log index(日志进度)告知给各 Follower 节点,然后各 Follower 按照这个 index 进度对外提供数据,未被 Leader 最终 commit 的数据则不会落地对外展示。
如果在数据同步期间,客户端还有其他的数据修改请求发到 Leader,那么这些请求会排队,因为这时候的 Leader 在阻塞等待其他节点回应。
通过日志同步,同时同步Follower目前Leader 的commit index
不过,这种阻塞等待的设计也让 Raft 算法对网络性能的依赖很大,因为每次修改都要并发请求多个节点,等待大部分节点成功同步的结果。
最惨的情况是,返回的 RTT 会按照最慢的网络服务响应耗时(“两地三中心”的一次同步时间为 100ms 左右),再加上主节点只有一个,一组 Raft 的服务性能是有上限的。对此,我们可以减少数据量并对数据做切片,提高整体集群的数据修改性能。
请你注意,当大多数 Follower 与 Leader 同步的日志进度差异过大时,数据变更请求会处于等待状态,直到一半以上的 Follower 与 Leader 的进度一致,才会返回变更成功。当然,这种情况比较少见。
服务之间如何同步日志进度?
讲到这我们不难看出,在 Raft 的数据同步机制中,日志发挥着重要的作用。在同步数据时,Raft 采用的日志是一个有顺序的指令日志 WAL(Write Ahead Log),类似 MySQL 的 binlog。该日志中记录着每次修改数据的指令和修改任期,并通过 Log Index 标注了当前是第几条日志,以此作为同步进度的依据。

日志格式
其中,Leader 的日志永远不会删除,所有的 Follower 都会保持和 Leader 完全一致,如果存在差异也会被强制覆盖。同时,每个日志都有“写入”和“commit”两个阶段,在选举时,每个服务会根据还未 commit 的 Log Index 进度,优先选择同步进度最大的节点,以此保证选举出的 Leader 拥有最新最全的数据。
Leader 在任期内向各节点发送同步请求,其实就是按顺序向各节点推送一条条日志。如果 Leader 同步的进度比 Follower 超前,Follower 就会拒绝本次同步。
Leader 收到拒绝后,会从后往前一条条找出日志中还未同步的部分或者有差异的部分,然后开始一个个往后覆盖实现同步。
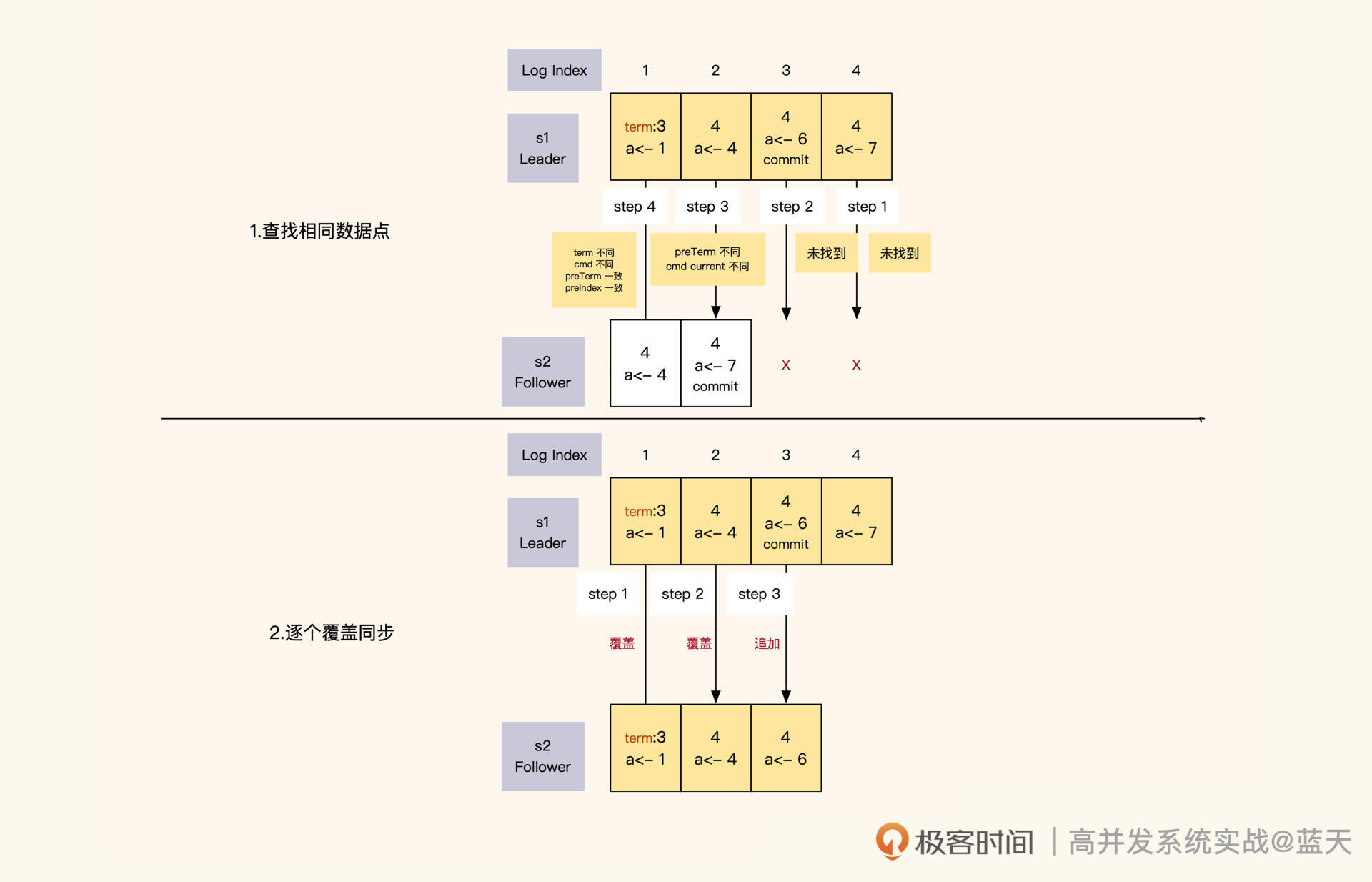
第一阶段找到共同进度点,第二阶段覆盖+追加同步进度
Leader 和 Follower 的日志同步进度是通过日志 index 来确认的。Leader 对日志内容和顺序有绝对的决策权,当它发现自己的日志和 Follower 的日志有差异时,为了确保多个副本的数据是完全一致的,它会强制覆盖 Follower 的日志。
那么 Leader 是怎么识别出 Follower 的日志与自己的日志有没有差异呢?实际上,Leader 给 Follower 同步日志的时候,会同时带上 Leader 上一条日志的任期和索引号,与 Follower 当前的同步进度进行对比。
对比分为两个方面:一方面是对比 Leader 和 Follower 当前日志中的 index、多条操作日志和任期;另一方面是对比 Leader 和 Follower 上一条日志的 index 和任期。
如果有任意一个不同,那么 Leader 就认为 Follower 的日志与自己的日志不一致,这时候 Leader 会一条条倒序往回对比,直到找到日志内容和任期完全一致的 index,然后从这个 index 开始正序向下覆盖。同时,在日志数据同步期间,Leader 只会 commit 其所在任期内的数据,过往任期的数据完全靠日志同步倒序追回。
你应该已经发现了,这样一条条推送同步有些缓慢,效率不高,这导致 Raft 对新启动的服务不是很友好。所以 Leader 会定期打快照,通过快照合并之前修改日志的记录,来降低修改日志的大小。而同步进度差距过大的 Follower 会从 Leader 最新的快照中恢复数据,按快照最后的 index 追赶进度。
如何保证读取数据的强一致性?
通过前面的讲解,我们知道了 Leader 和 Follower 之间是如何做到数据同步的,那从 Follower 的角度来看,它又是怎么保证自己对外提供的数据是最新的呢?
这里有个小技巧,就是 Follower 在收到查询请求时,会顺便问一下 Leader 当前最新 commit 的 log index 是什么。如果这个 log index 大于当前 Follower 同步的进度,就说明 Follower 的本地数据不是最新的,这时候 Follower 就会从 Leader 获取最新的数据返回给客户端。可见,保证数据强一致性的代价很大。
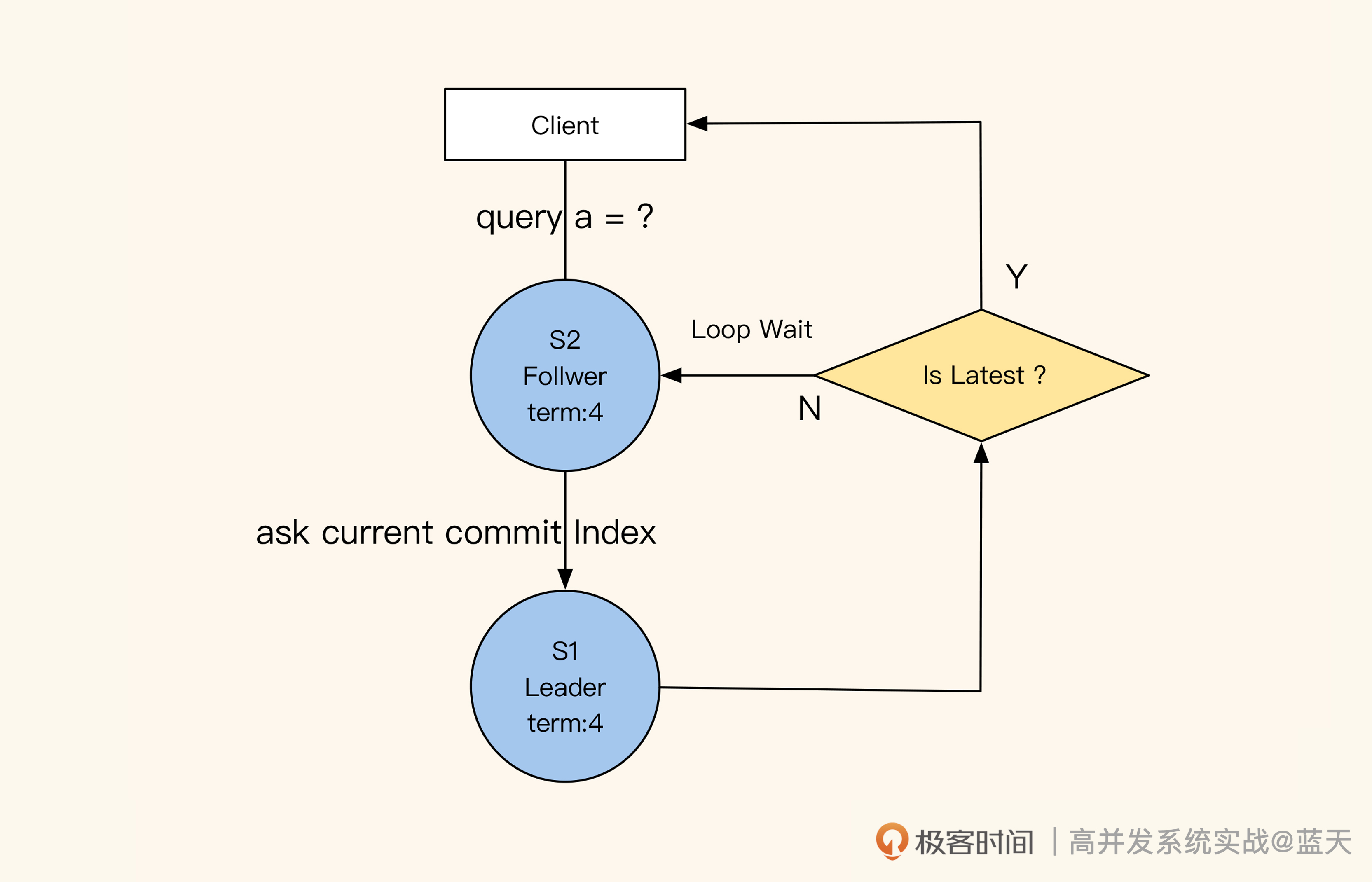
Follower保持与Leader进度一致的方式,保证读到的数据和Leader强一致
你可能会好奇:如何在业务使用时保证读取数据的强一致性呢?其实我们之前说的 Raft 同步等待 Leader commit log index 的机制,已经确保了这一点。我们只需要向 Leader 正常提交数据修改的操作,Follower 读取时拿到的就一定是最新的数据。
总结
很多人都说 Raft 是一个分布式一致性算法,但实际上 Raft 算法是一个共识算法(多个节点达成共识),它通过任期机制、随机时间和投票选举机制,实现了服务动态扩容及服务的高可用。
通过 Raft 采用强制顺序的日志同步实现多副本的数据强一致同步,如果我们用 Raft 算法实现用户的数据存储层,那么数据的存储和增删改查,都会具有跨机房的数据强一致性。这样一来,业务层就无需关心一致性问题,对数据直接操作,即可轻松实现多机房的强一致同步。
由于这种方式的同步代价和延迟都比较大,建议你尽量在数据量和修改量都比较小的场景内使用,行业里也有很多针对不同场景设计的库可以选择,如:parallel-raft、multi-paxos、SOFAJRaft 等,更多请参考 Raft 的底部开源列表。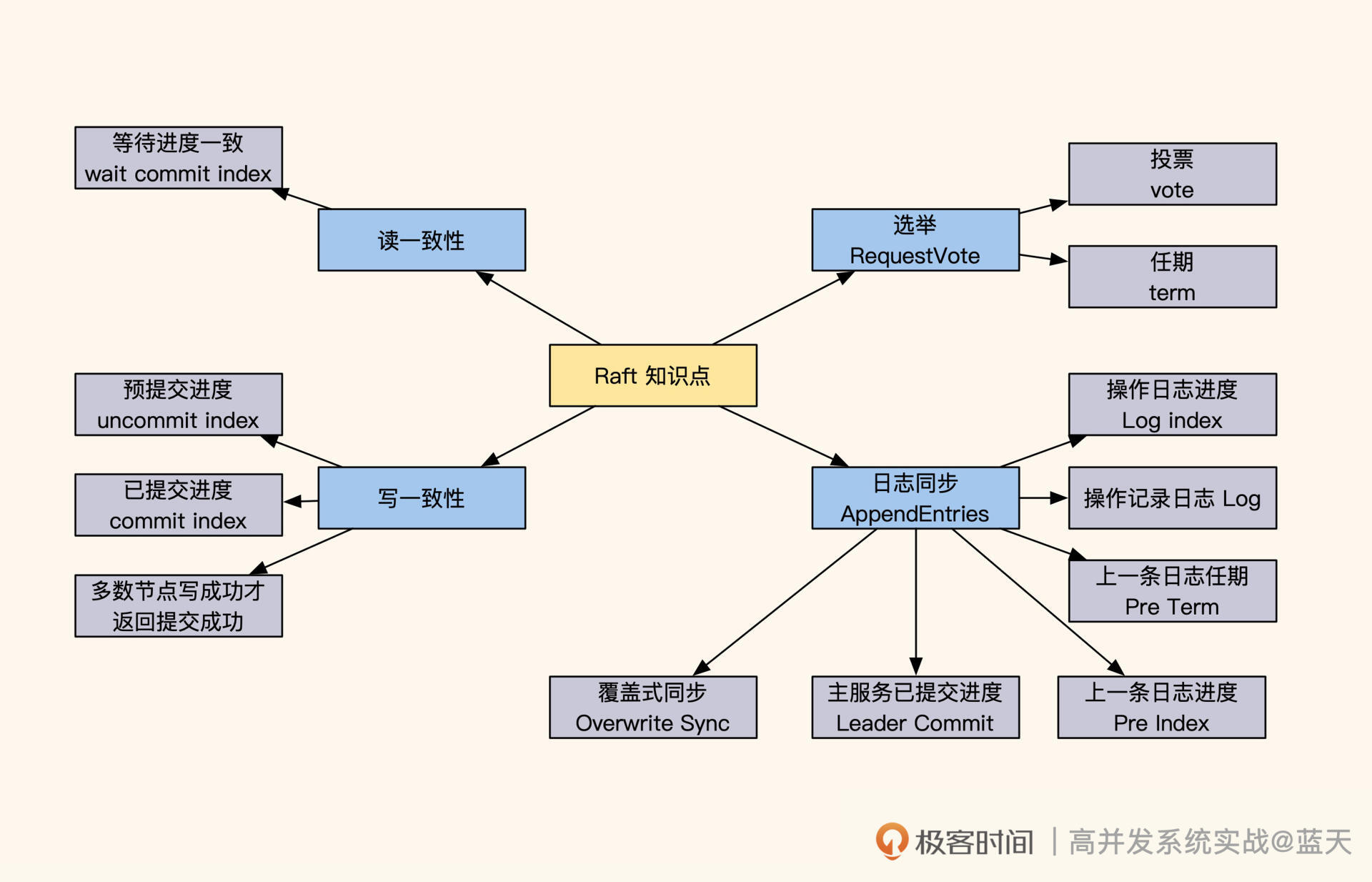
电商系统:强一致性系统如何改造
领域拆分:如何合理地拆分系统?
一般来说,强一致性的系统都会牵扯到“锁争抢”等技术点,有较大的性能瓶颈,而电商时常做秒杀活动,这对系统的要求更高。业内在对电商系统做改造时,通常会从三个方面入手:系统拆分、库存争抢优化、系统隔离优化。
今天这节课我们先来热个身,学习一些系统拆分的技巧。我们知道,电商系统有很多功能需要保持数据的强一致性,我们一般会用锁确保同一时间只有一个线程在修改。
但这种方式会让业务处理的并行效率很低,还很容易影响系统的性能。再加上这类系统经常有各种个性活动需求,相关功能支撑需要不断更新迭代,而这些变更往往会导致系统脱离原来的设计初衷,所以在开发新需求的同时,我们要对系统定期做拆分整理,避免系统越跑越偏。这时候,如何根据业务合理地拆分系统就非常重要了。
案例背景
他们是某行业知名电商的供货商,供应链比较长,而且供应品类和规格复杂。为确保生产计划平滑运转,系统还需要调配多个子工厂和材料商的生产排期。
原本调配订单需要电话沟通,但这样太过随机。为了保证生产链稳定供货,同时提高协调效率,朋友基于订单预订系统增加了排期协商功能,具体就是将 “排期” 作为下订单主流程里的一个步骤,并将协商出的排期按照日历样式来展示,方便上游供应商和各个工厂以此协调生产周期。
整个供货协商流程如下图所示:
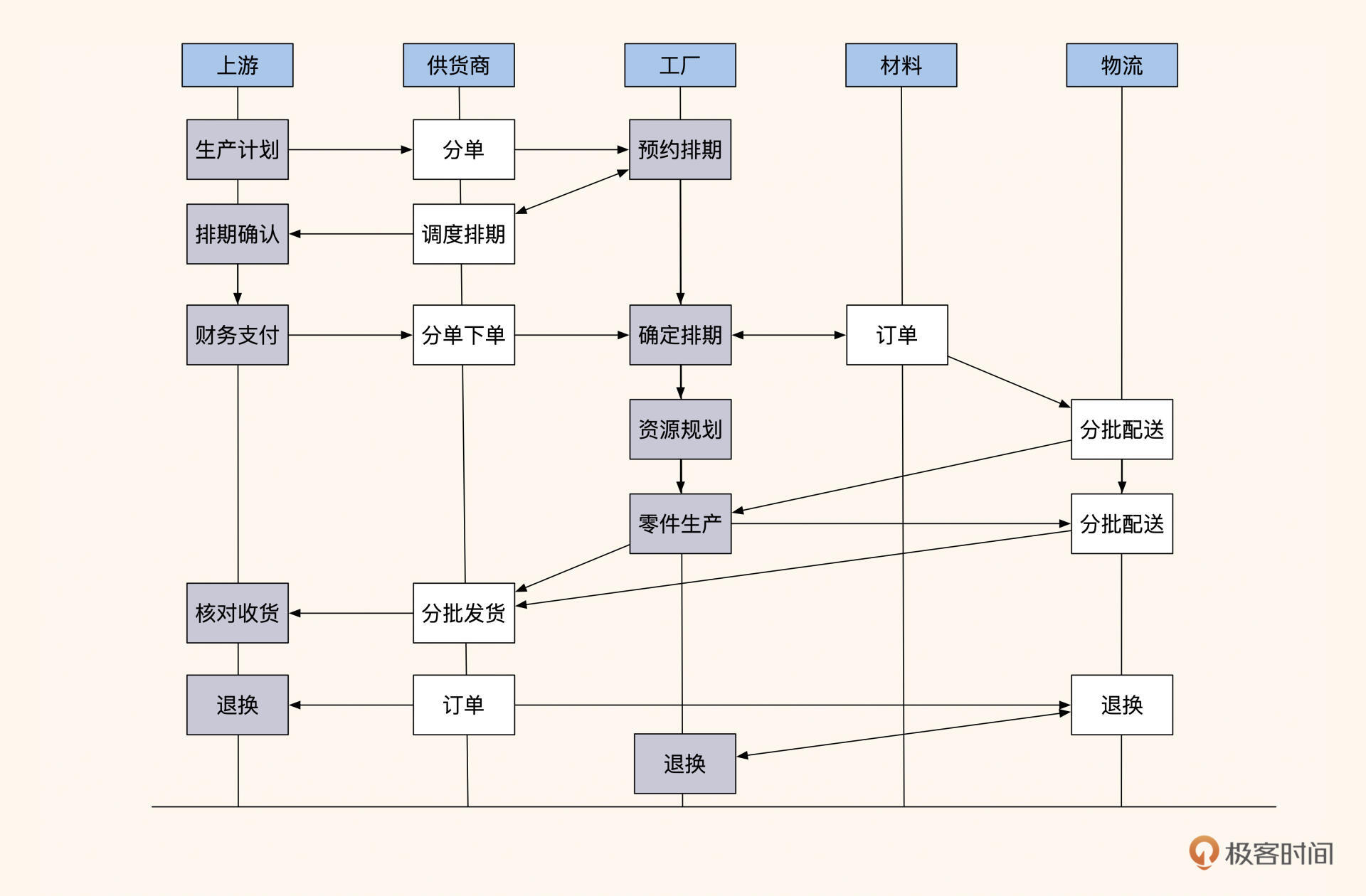
图1:供货商供货协商流程
如图,上游项目会先发布生产计划(或采购计划),供货商根据计划拆分采购列表(分单),并联系不同的工厂协调做预排期(预约排期)。之后,上游采购方对工厂产品进行质量审核,然后下单支付、确认排期。
工厂根据确认好的排期制定采购材料计划,并通知材料供货商分批供货,开始分批生产制造产品。每当制造好一批产品后,工厂就会通知物流按批次发货到采购方(即供货商),同时更新供货商系统内的分批订单信息。接着,上游对产品进行验收,将不合格的产品走退换流程。
但系统运行了一段时间后朋友发现,由于之前系统是以订单为主体的,增加排期功能后还是以主订单作为聚合根(即主要实体),这就导致上游在发布计划时需要创建主订单。
而主订单一直处于开启状态,随着排期不断调整和新排期的不断加入,订单数据就会持续增加,一年内订单数据量达到了一亿多条。因为数据过多、合作周期长,并且包含了售后环节,所以这些数据无法根据时间做归档,导致整个系统变得越来越慢。
考虑到这是核心业务,如果持续存在问题影响巨大,因此朋友找我取经,请教如何对数据进行分表拆分。但根据我的理解,这不是分表分库维护的问题,而是系统功能设计不合理导致了系统臃肿。于是经过沟通,我们决定对系统订单系统做一次领域拆分。流程分析整理。
流程分析整理
我先梳理了主订单的 API 和流程,从上到下简单绘制了流程和订单系统的关系,如下图所示:
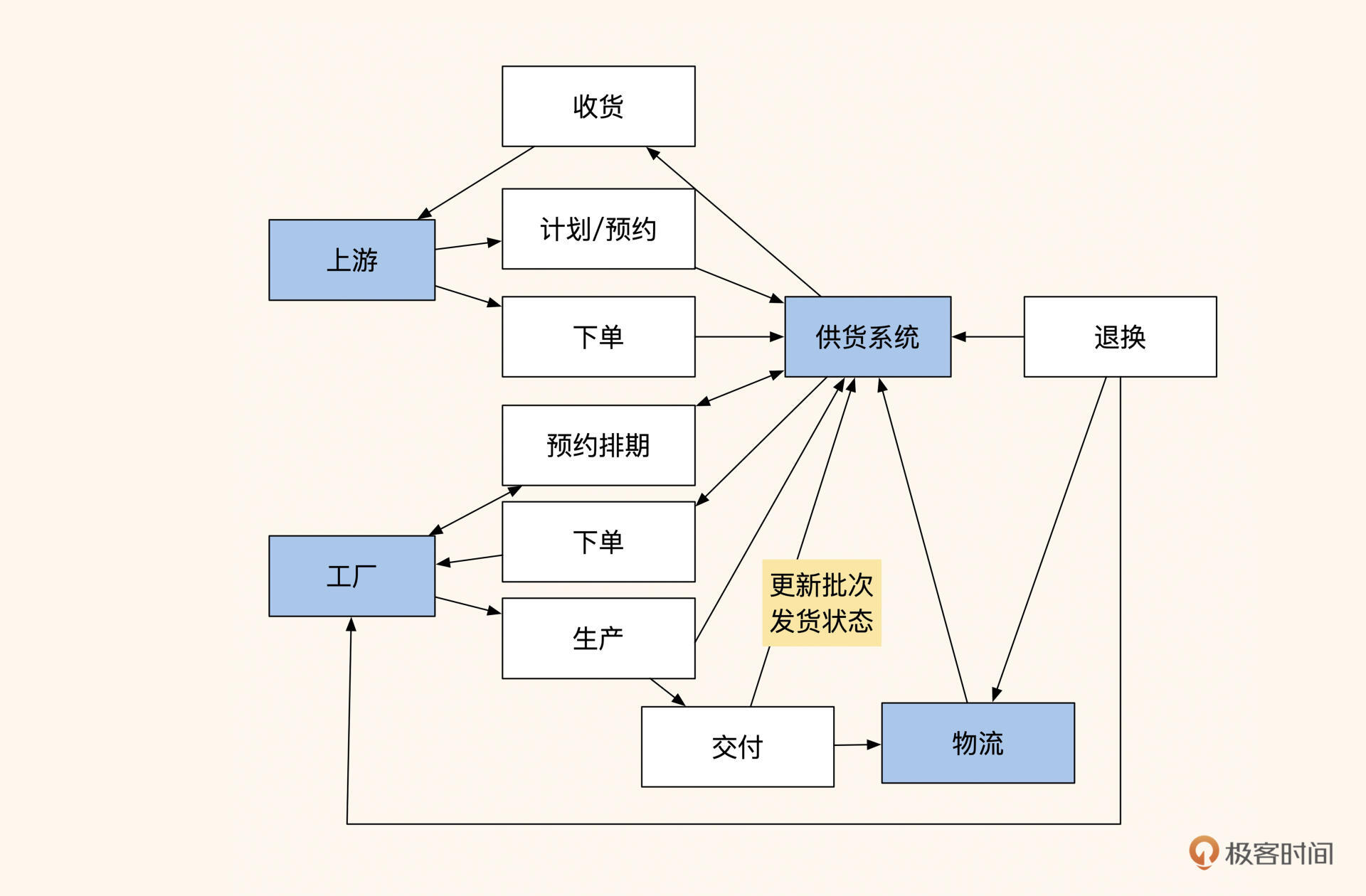
图2:角色动作与系统
可以看到,有多个角色在使用这个“订单排期系统”。通过这张图与产品、研发团队进行沟通,来确认我理解的主要流程的数据走向和系统数据依赖关系都没有问题。
接着我们将目光放在了订单表上,订单表承载的职能过多,导致多个流程依赖订单表无法做数据维护,而且订单存在多个和订单业务无关的状态,比如排期周期很长,导致订单一直不能关闭。我们在第 1 节课讲过,一个数据实体不要承担太多职能,否则很难管理,所以我们需要对订单和排期的主要实体职能进行拆分。
经过分析我们还发现了另一个问题,现在系统的核心并不是订单,而是计划排期。原订单系统在改造前是通过自动匹配功能实现上下游订单分单的,所以系统的主要模块都是围绕订单来流转的。而增加排期功能后,系统的核心就从围绕订单实现匹配分单,转变成了围绕排期产生订单的模式,这更符合业务需要。
排期和订单有关联关系,但职能上有不同的方向用途,排期只是计划,而订单只为工厂后续生产运输和上游核对结果使用。这意味着系统的模块和表的设计核心已经发生了偏移,我们需要拆分模块才能拥有更好的灵活性。
综上所述,我们总体的拆分思路是:要将排期流程和订单交付流程完全拆分开。要知道在创业公司,我们做的项目一开始的设计初衷常常会因为市场需求变化,逐渐偏离原有设计,这就需要我们不断重新审视我们的系统,持续改进,才能保证系统的完善。
因为担心研发团队摆脱不了原有系统的思维定势,拆分做得不彻底,导致改版失败,所以我对角色和流程做了一次梳理,明确了各个角色的职责和流程之间的关系。我按角色及其所需动作画出多个框,将他们需要做的动作和数据流穿插起来,如下图所示:
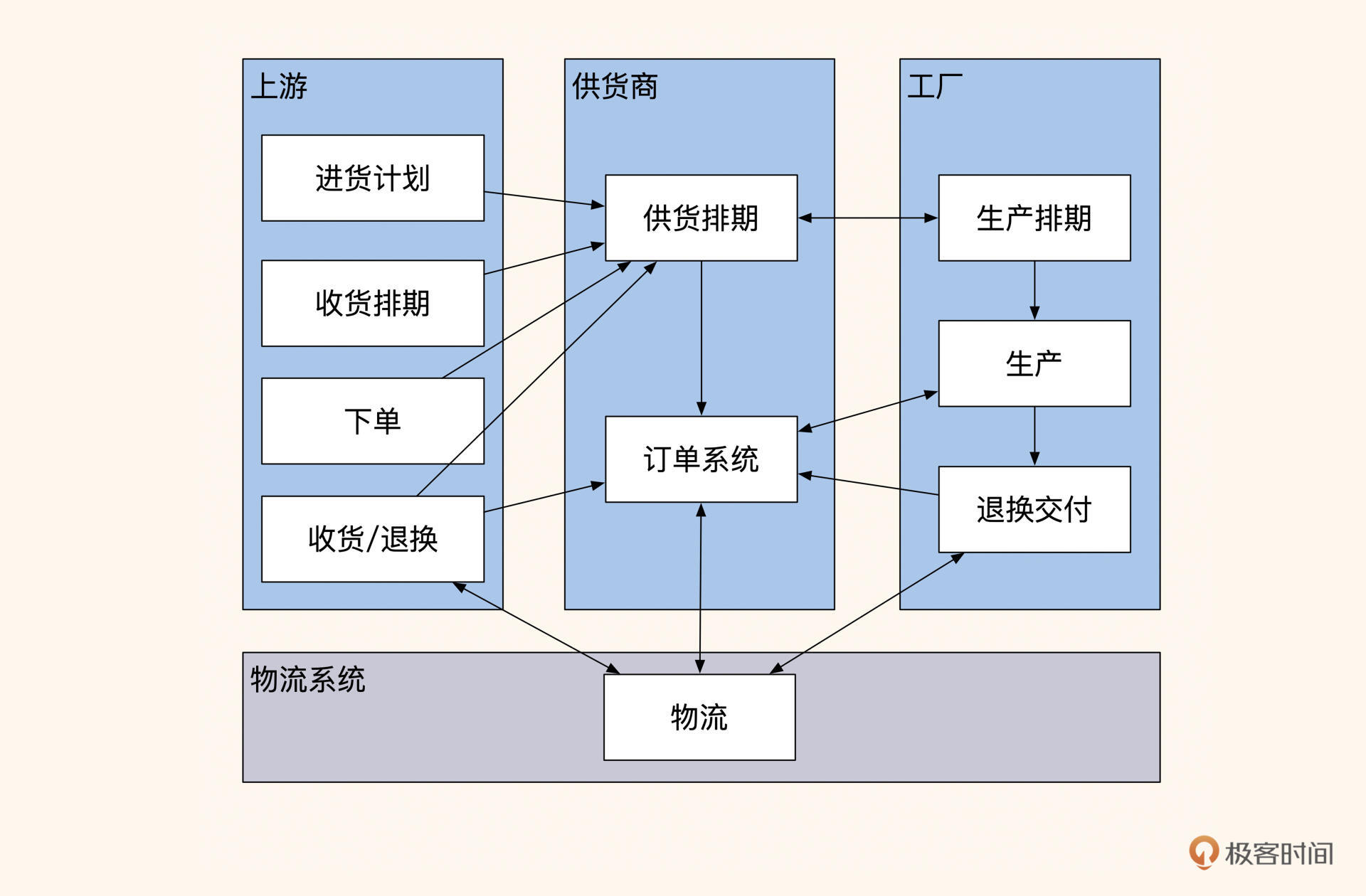
图3:按角色及其动作整理
基于这个图,我再次与研发、产品沟通,找出了订单与排期在功能和数据上的拆分点。具体来讲,就是将上游的职能拆分为:发布进货计划、收货排期、下单、收货 / 退换;而供货商主要做协调排期分单,同时提供订单相关服务;工厂则主要负责生产排期、生产和售后。这样一来,系统的流程就可以归类成几个阶段:
- 计划排期协调阶段
- 按排期生产供货 + 周期物流交付阶段
- 售后服务调换阶段
可以看到,第一个阶段不牵扯订单,主要是上游和多个工厂的排期协调;第二、三阶段是工厂生产供货和售后,这些服务需要和订单交互,而上游、工厂和物流的视角是完全不同的。
基于这个结论,我们完全可以根据数据的主要实体和主要业务流程(订单 ID 做聚合根,将流程分为订单和排期两个领域)将系统拆分成两个子系统:排期调度系统、订单交付系统。
在计划排期协调阶段,上游先在排期调度系统内提交进货计划和收货排期,然后供货商根据上游的排期情况和进货需求,与多家合作工厂协调分单和议价。多方达成一致后,上游对计划排期和工厂生产排期进行预占。
待上游正式签署协议、支付生产批次定金后,排期系统会根据排期和工厂下单在订单系统中产生对应的订单。同时,上游、供货商和工厂一旦达成合作,后续可以持续追加下单排期,而不是将合作周期限制在订单内。
在排期生产供货阶段,排期系统在调用订单系统的同时,会传递具体的主订单号和订单明细。订单明细内包含着计划生产的品类、个数以及每期的交付量,工厂可以根据自己的情况调整生产排期。产品生产完毕后,工厂分批次发送物流进行派送,并在订单系统内记录交付时间、货物量和物流信息。同时,订单系统会生成财务信息,与上游财务和仓库分批次地对账。
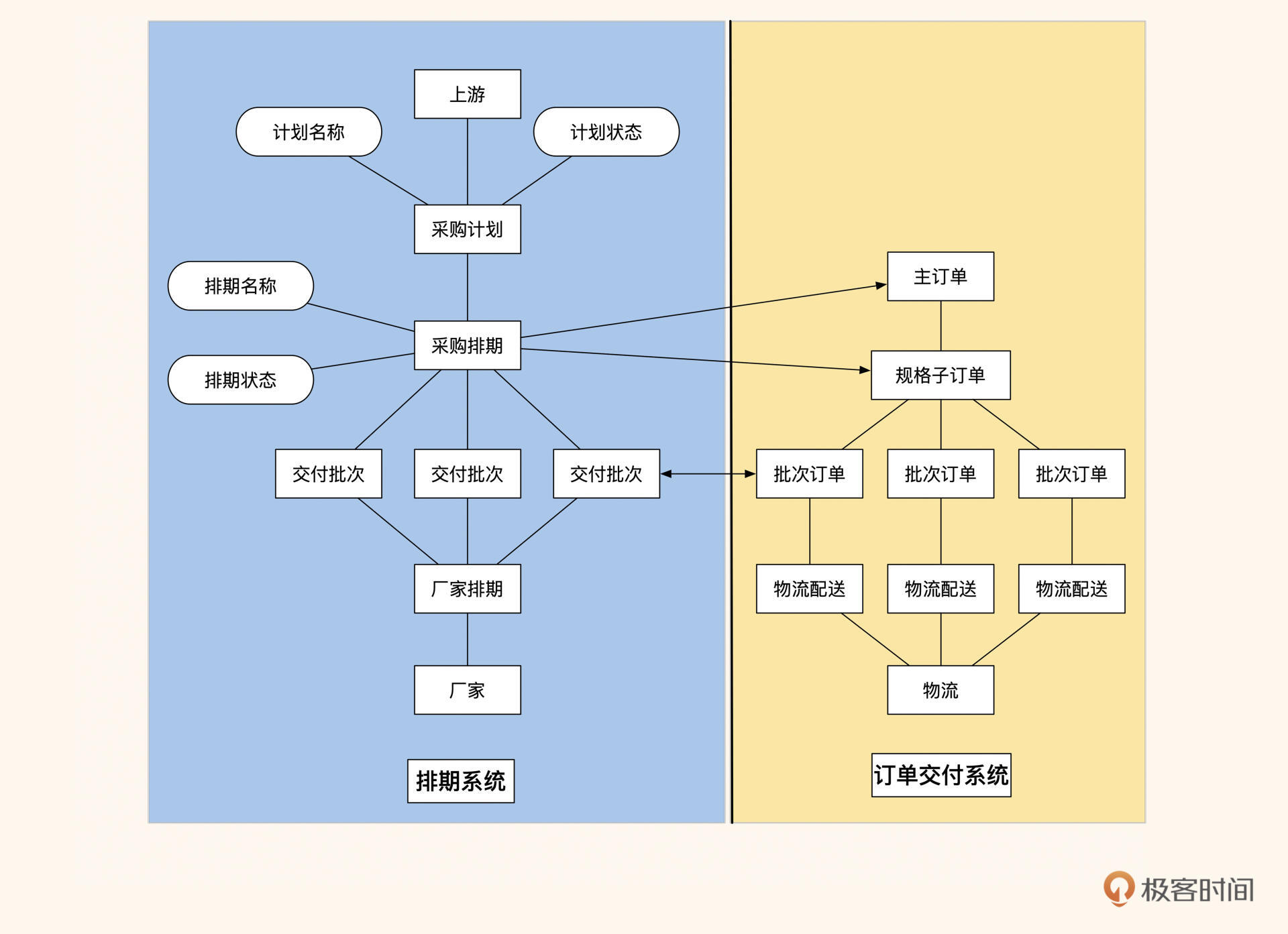
图4:拆分成两大流程后的系统
这么拆分后,两个系统把采购排期和交付批次作为聚合根,进行了数据关联,这样一来,整体的订单流程就简单了很多。
总体来讲,前面对业务的梳理都以流程、角色和关键动作这三个元素作为分析的切入点,然后将不同流程划分出不同阶段来归类分析,根据不同阶段拆分出两个业务领域:排期和订单,同时找出两个业务领域的聚合根。经过这样大胆的拆分后,再与产品和研发论证可行性。
系统拆分从表开始
经历了上面的过程,相信你对按流程和阶段拆分实体职责的方法,已经有了一定的感觉,这里我们再用代码和数据库表的视角复盘一下该过程。
一般来说,系统功能从表开始拆分,这是最容易实现的路径,因为我们的业务流程往往都会围绕一个主要的实体表运转,并关联多个实体进行交互。在这个案例中,我们将订单表内关于排期的数据和状态做了剥离,拆分之前的代码分层如下图所示:
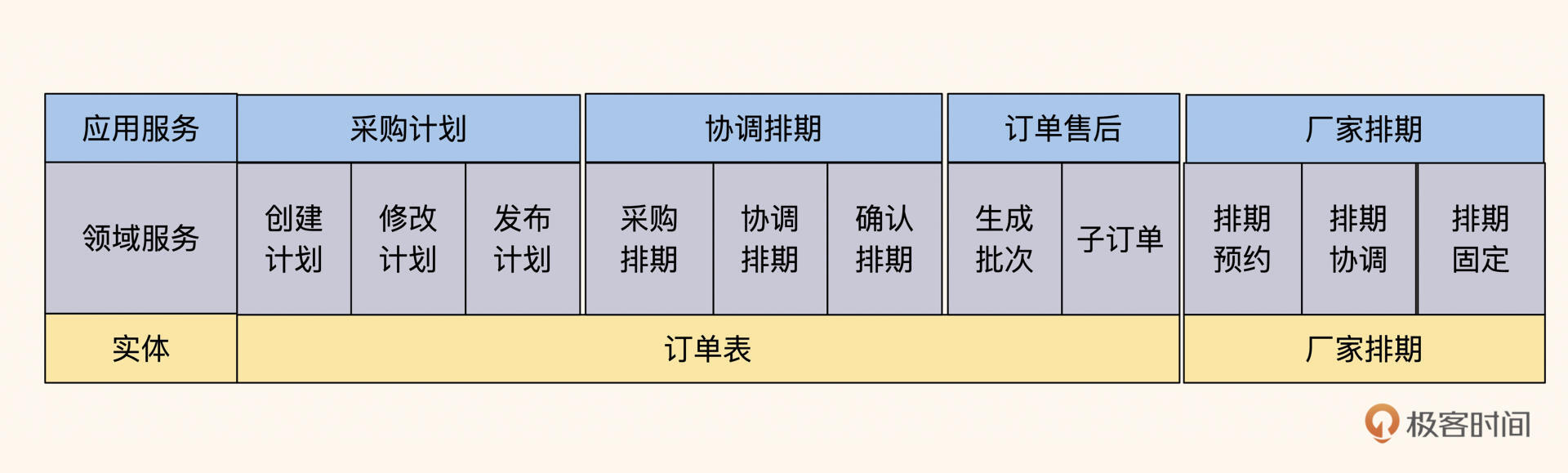
图5:拆分之前,订单表承担计划、排期协调、订单售后的职责
拆分之后,代码分层变成了这样:
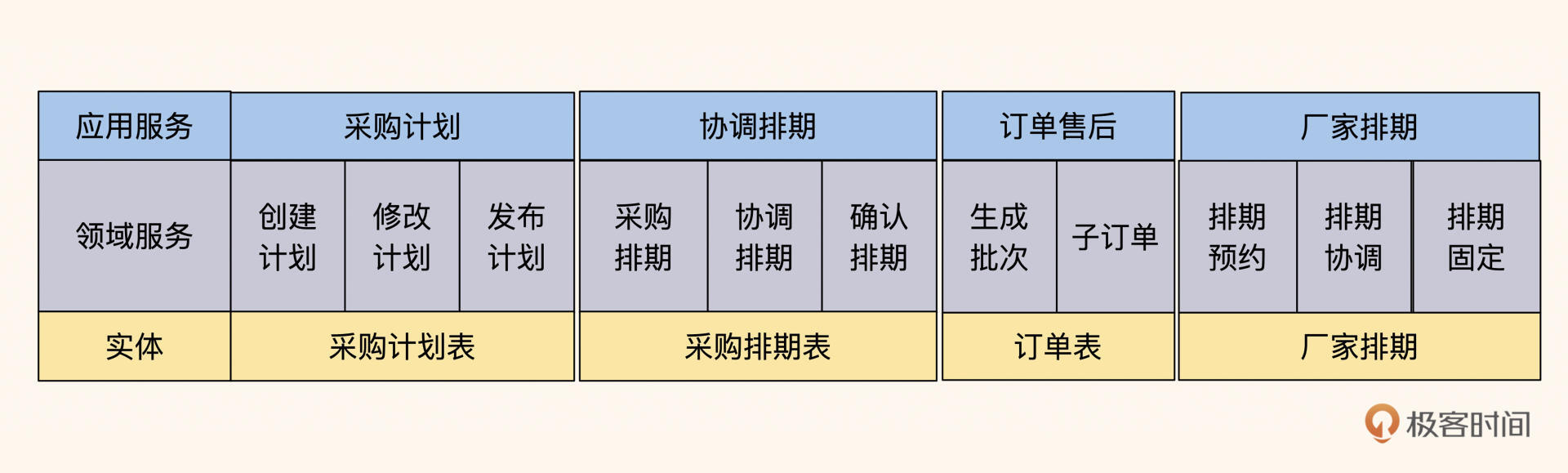
图6:拆分之后,分为计划表、排期协调表和订单售后表
可以看到,最大的变化就是订单实体表的职责被拆分了,我们的系统代码随之变得更加简单,而且同一个订单实体被多个角色交叉调用的情况也完全消失了。在拆分过程中,我们的依据有三个:
- 数据实体职能只做最核心的一件事,比如订单只管订单的生老病死(包括创建、流程状态更改、退货、订单结束);
- 业务流程归类按涉及实体进行归类,看能否分为多个阶段,比如“协调排期流程进行中”、“生产流程”、“售后服务阶段”;
- 由数据依赖交叉的频率决定把订单划分成几个模块,如果两个模块业务流程上交互紧密,并且有数据关联关系,比如 Join、调用 A 必然调用 B 这种,就把这两个模块合并,同时保证短期内不会再做更进一步的拆分。
图7:从下往上按数据实体设计和从流程往下按领域流程设计DDD
一个核心的系统,如果按实体表职责进行拆分整理,那么它的流程和修改难度都会大大降低。
而模块的拆分,也可以通过图 6,从下往上去看。如果它们之间的数据交互不是特别频繁,比如没有出现频繁的 Join,我们就将系统分成四个模块。如图 7 所示,可以看到这四个模块之间相对独立,各自承担一个核心的职责。同时,两个实体之间交互没有太大的数据关联,每个模块都维护着某个阶段所需的全部数据,这么划分比较清晰,也易于统一管理。
到这里,我们只需要将数据和流程关系都梳理一遍,确保它们之间的数据在后续的统计分析中没有频繁数据 Join,即可完成对表的拆分。
但如果要按业务划分模块,我还是建议从上到下去看业务流程,来决定数据实体拆分(领域模型设计 DDD)的领域范围,以及各个模块的职责范围。
越是底层服务越要抽象
除了系统的拆分外,我们还要注意一下服务的抽象问题。很多服务经常因业务细节变更需要经常修改,而越是底层服务,越要减少变更。如果服务的抽象程度不够,一旦底层服务变更,我们很难确认该变更对上游系统的影响范围。
所以,我们要搞清楚哪些服务可以抽象为底层服务,以及如何对这些服务做更好的抽象。
因为电商类系统经常对服务做拆分和抽象,所以我就以这类系统为例为你进行讲解。你可能感到疑惑:电商系统为什么要经常做系统拆分和服务抽象呢?
这是因为电商系统最核心且最复杂的地方就是订单系统,电商商品有多种品类(sku+spu),不同品类的筛选维度、服务、计量单位都不同,这就导致系统要记录大量的冗余品类字段,才能保存好用户下单时的交易快照。所以我们需要频繁拆分整理系统,避免这些独有特性影响到其他商品。
此外,电商系统不同业务的服务流程是不同的。比如下单购买食品,与下单定制一个柜子完全不同。在用户购买食品时,电商只需要通知仓库打包、打物流单、发货、签收即可;而用户定制柜子则需要厂家上门量尺寸、复尺、定做、运输、后续调整等。所以,我们需要做服务抽象,让业务流程更标准、更通用,避免变更过于频繁。
正是由于业务服务形态存在不同的差异,订单系统需要将自己的职能控制在“一定范围”内。对此,我们应该考虑如何在满足业务需求的情况下,让订单表的数据职能最小。
被动抽象法
如果两个或多个服务使用同一个业务逻辑,就把这个业务逻辑抽象成公共服务。比如业务 A 更新了逻辑 a,业务 B 也会同步使用新的逻辑 a,那么就将这个逻辑 a 放到底层抽象成一个公共服务供两个服务调用。这种属于比较被动的抽象方式,很常见,适合代码量不大、维护人员很少的系统。
对于创业初期主脉络不清晰的系统,利用被动抽象法很容易做抽象。不过,它的缺点是抽象程度不高,当业务需要大量变更时,需要一定规模的重构。
总的来说,虽然这种方式的代码结构很贴近业务,但是很麻烦,而且代码分层没有规律。所以,被动抽象法适用于新项目的探索阶段。
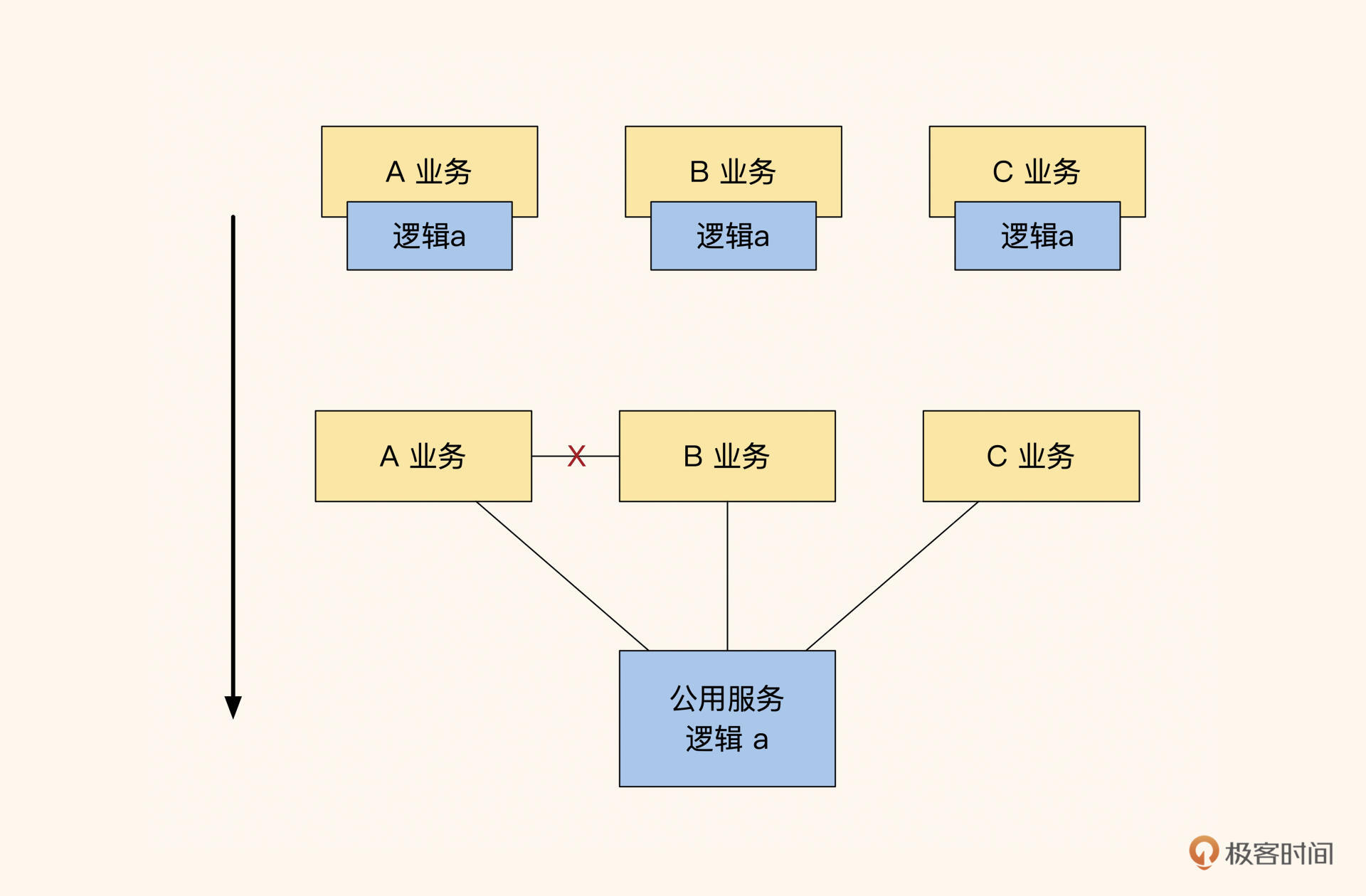
图8:都用的服务才抽象成服务,个性部分放自身,决策权在业务。
这里说一个题外话,同层级之间的模块是禁止相互调用的。如果调用了,就需要将两个服务抽象成公共服务,让上层对两个服务进行聚合,如上图中的红 X,拆分后如下图所示:
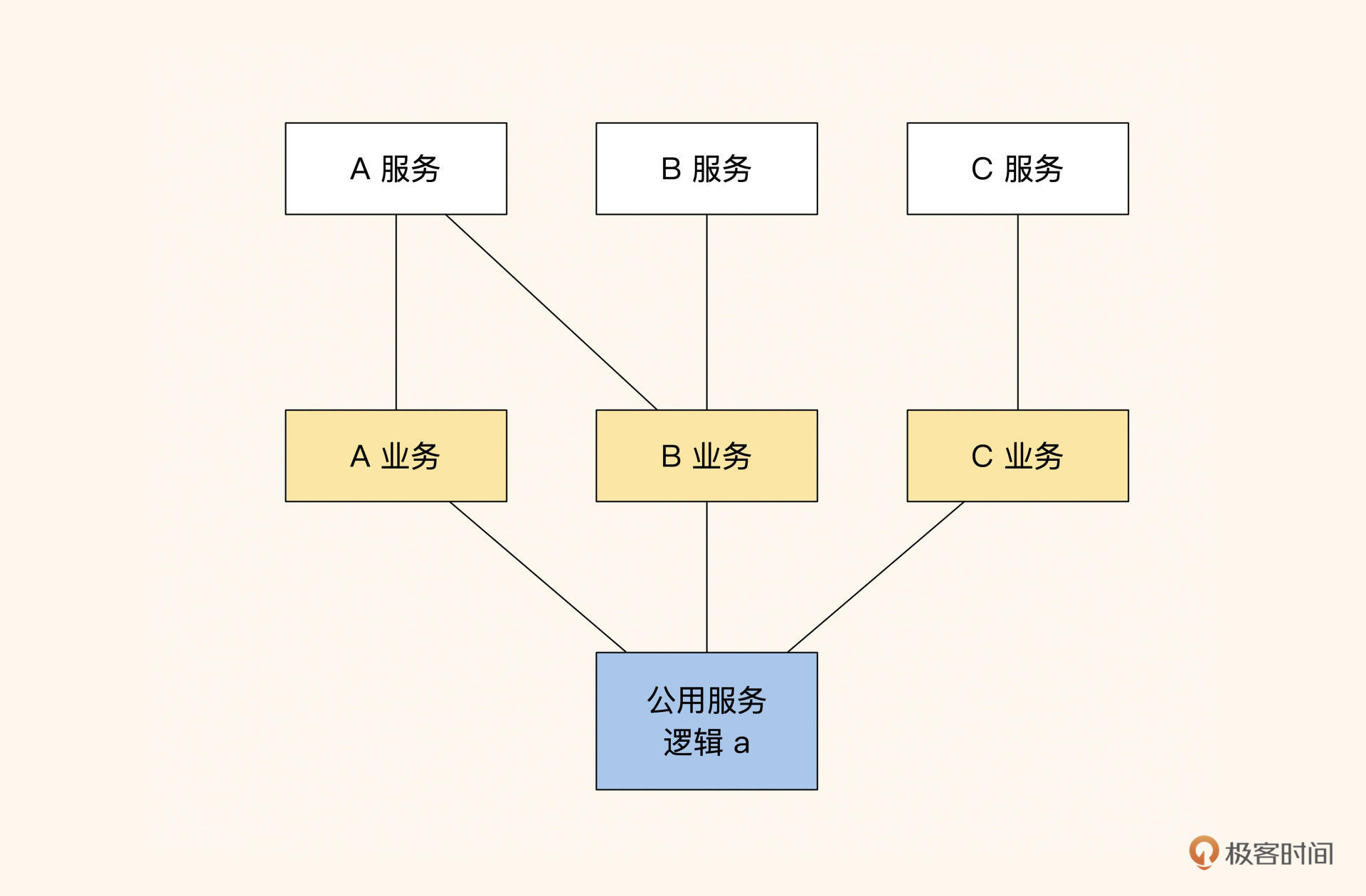
图9:同层有交叉调用的服务
这么做是为了让系统结构从上到下是一个倒置的树形,保证不会出现引用交叉循环的情况,否则会让项目难以排查问题,难以迭代维护,如果前期有大量这样的调用,当我们做系统改造优化时只能投入大量资源才能解决这个问题。
动态辅助表方式
这个方式适用于规模稍微大一点的团队或系统,它的具体实现是这样的:当订单系统被几个开发小组共同使用,而不同业务创建的主订单有不同的 type,不同的 type 会将业务特性数据存储在不同的辅助表内,比如普通商品保存在表 order 和表 order_product_extra 中,定制类商品的定制流程状态保存在 order_customize_extra 中。
这样处理的好处是更贴近业务,方便查询。但由于辅助表有其他业务数据,业务的隔离性比较差,所有依赖订单服务的业务常会受到影响,而且订单需要时刻跟着业务改版。所以,通过这种方式抽象出来的订单服务已经形同虚设,一般只有企业的核心业务才会做类似的定制。
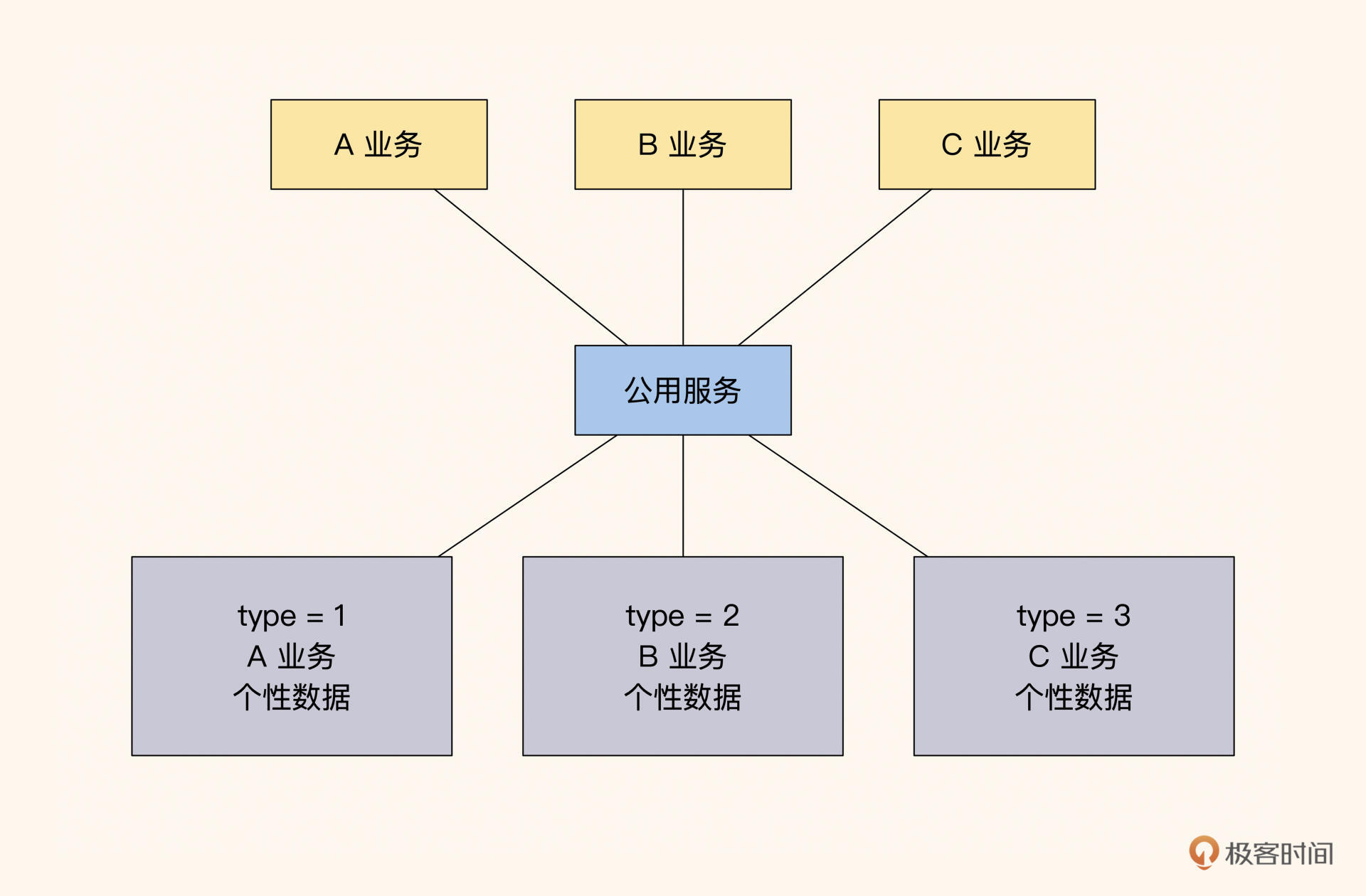
图10:动态辅助表方式
强制标准接口方式
这种方式在大型企业比较常见,其核心点在于:底层服务只做标准的服务,业务的个性部分都由业务自己完成,比如订单系统只有下单、等待支付、支付成功、发货和收货功能,展示的时候用前端对个性数据和标准订单做聚合。
用这种方式抽象出的公共服务订单对业务的耦合性是最小的,业务改版时不需要订单跟随改版,订单服务维护起来更容易。只是上层业务交互起来会很难受,因为需要在本地保存很多附加的信息,并且一些流转要自行实现。不过,从整体来看,对于使用业务多的系统来说,因为业务导致的修改会很少。
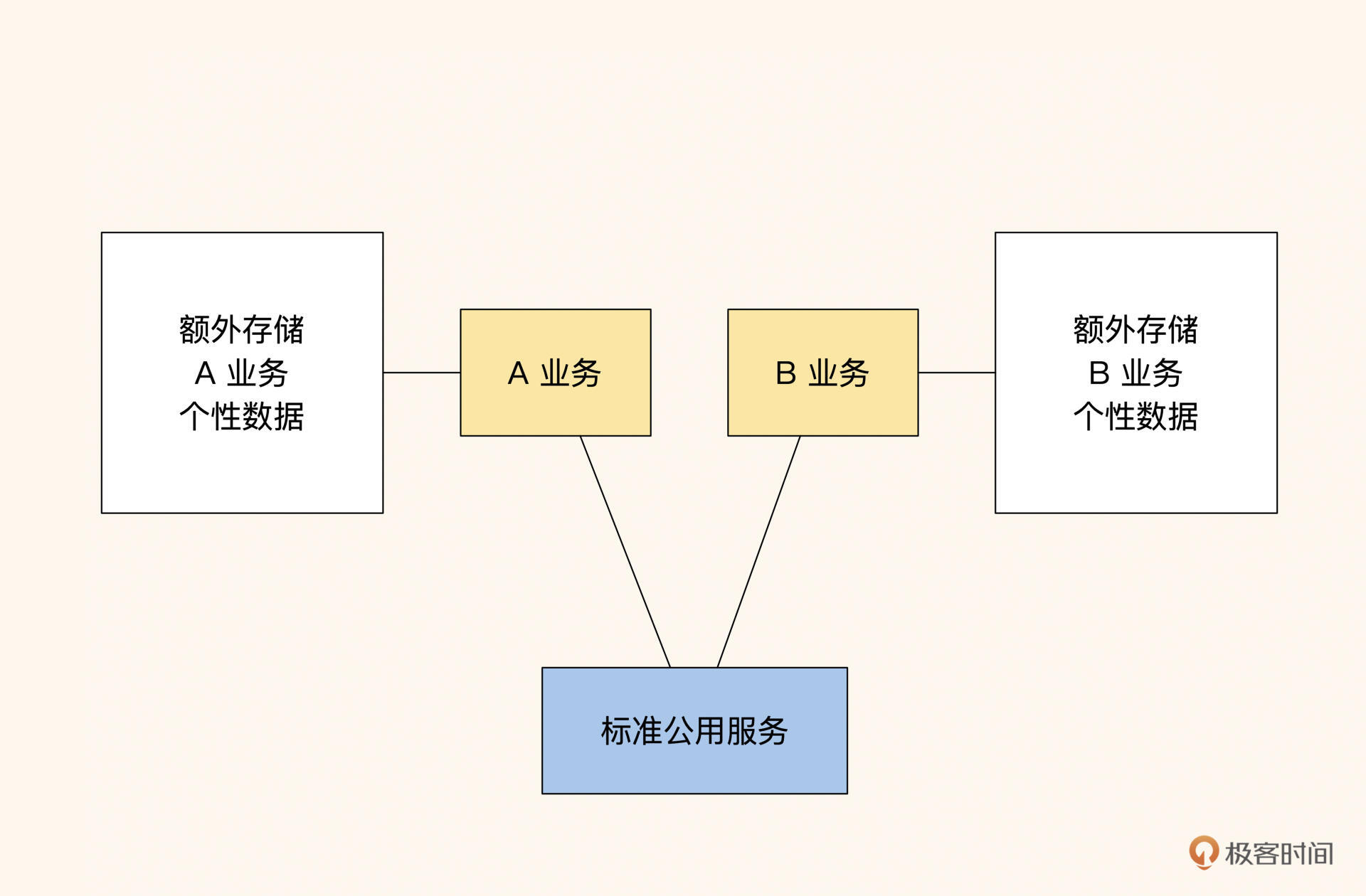
图11:只提供标准的公共服务,业务隔离性最好
通过上面三种方式可以看出,业务的稳定性取决于服务的抽象程度。如果底层经常更改,那么整个业务就需要不断修改,最终会导致业务混乱。所以,我个人还是推荐你使用强制标准接口方式,这也是很多公司的常见做法。虽然很难用,但比起经常重构整个系统总要好一些。
你可能很奇怪,为什么不把第一种方式一口气设计好呢?这是因为大部分的初创业务都不稳定,提前设计虽然能让代码结构保持统一,但是等两年后再回头看,你会发现当初的设计已经面目全非,我们最初信心满满的设计,最后会成为业务的绊脚石。
所以,这种拆分和架构设计需要我们不定期回看、自省、不断调整。毕竟技术是为业务服务的,业务更重要,没有人可以保证项目初期设计的个人中心不会被改成交友的个人门户。
总之,每一种方法并非绝对正确,我们需要根据业务需求来决策用哪一种方式。
总结
结业务拆分的方法有很多,最简单便捷的方式是:先从上到下做业务流程梳理,将流程归类聚合;然后从不同的领域聚合中找出交互所需主要实体,根据流程中主要实体之间的数据依赖程度决定是否拆分(从下到上看);把不同的实体和动作拆分成多个模块后,再根据业务流程归类,划分出最终的模块(最终汇总)。
这个拆分过程用一句话总结就是:从上往下看流程,从下往上看模块,最后综合考虑流程和模块的产出结果。用这种方式能快速拆出模块范围,拆分出的业务也会十分清晰。
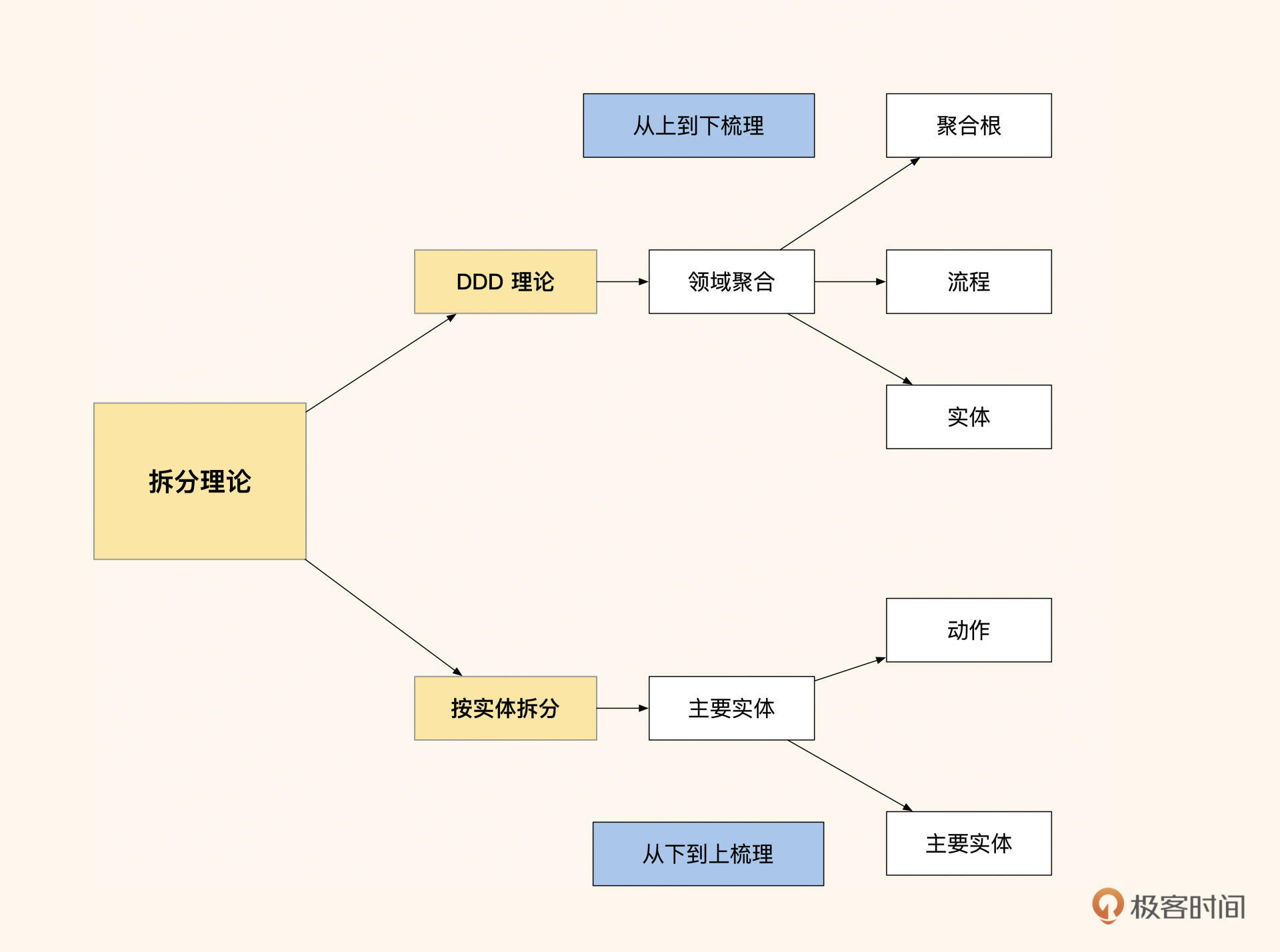
图12:拆分理论总结
除了拆分业务外,我们还要关注如何抽象服务。如果底层业务变更频繁,就会导致上层业务频繁修改,甚至出现变更遗漏的情况。所以,我们要确保底层服务足够抽象,具体有很多种办法,比如被动拆分法、动态辅助表方式、标准抽象方式。这几种方式各有千秋,需要我们根据业务来决策。
图13:系统在不断改进的同时,需要不断做核心修正
通常,我们的业务系统在初期都会按照一个特定的目标来设计,但是随着市场需求的变化,业务系统经过不断改版,往往会偏离原有的设计。
虽然我们每次改版都实现了既定需求,但也很容易带来许多不合理的问题。所以,在需求稳定后,一般都会做更合理的改造,保证系统的完整性,提高可维护性。很多时候,第一版本不用做得太过精细,待市场验证后明确了接下来的方向,再利用留出足够的空间改进,这样设计的系统才会有更好的扩展性。
强一致锁:如何解决高并发下的库存争抢问题?
这节课我会给你详细讲一讲高并发下的库存争抢案例,我相信很多人都看到过相关资料,但是在实践过程中,仍然会碰到具体的实现无法满足需求的情况,比如说有的实现无法秒杀多个库存,有的实现新增库存操作缓慢,有的实现库存耗尽时会变慢等等。
这是因为对于不同的需求,库存争抢的具体实现是不一样的,我们需要详细深挖,理解各个锁的特性和适用场景,才能针对不同的业务需要做出灵活调整。
由于秒杀场景是库存争抢非常经典的一个应用场景,接下来我会结合秒杀需求,带你看看如何实现高并发下的库存争抢,相信在这一过程中你会对锁有更深入的认识。
锁争抢的错误做法
在开始介绍库存争抢的具体方案之前,我们先来了解一个小知识——并发库存锁。还记得在我学计算机的时候,老师曾演示过一段代码:
public class ThreadCounter {private static int count = 0;public static void main(String[] args) throws Exception {Runnable task = new Runnable() {public void run() {for (int i = 0; i < 1000; ++i) {count += 1;}}};Thread t1 = new Thread(task);t1.start();Thread t2 = new Thread(task);t2.start();t1.join();t2.join();cout << "count = " << count << endl;}
}
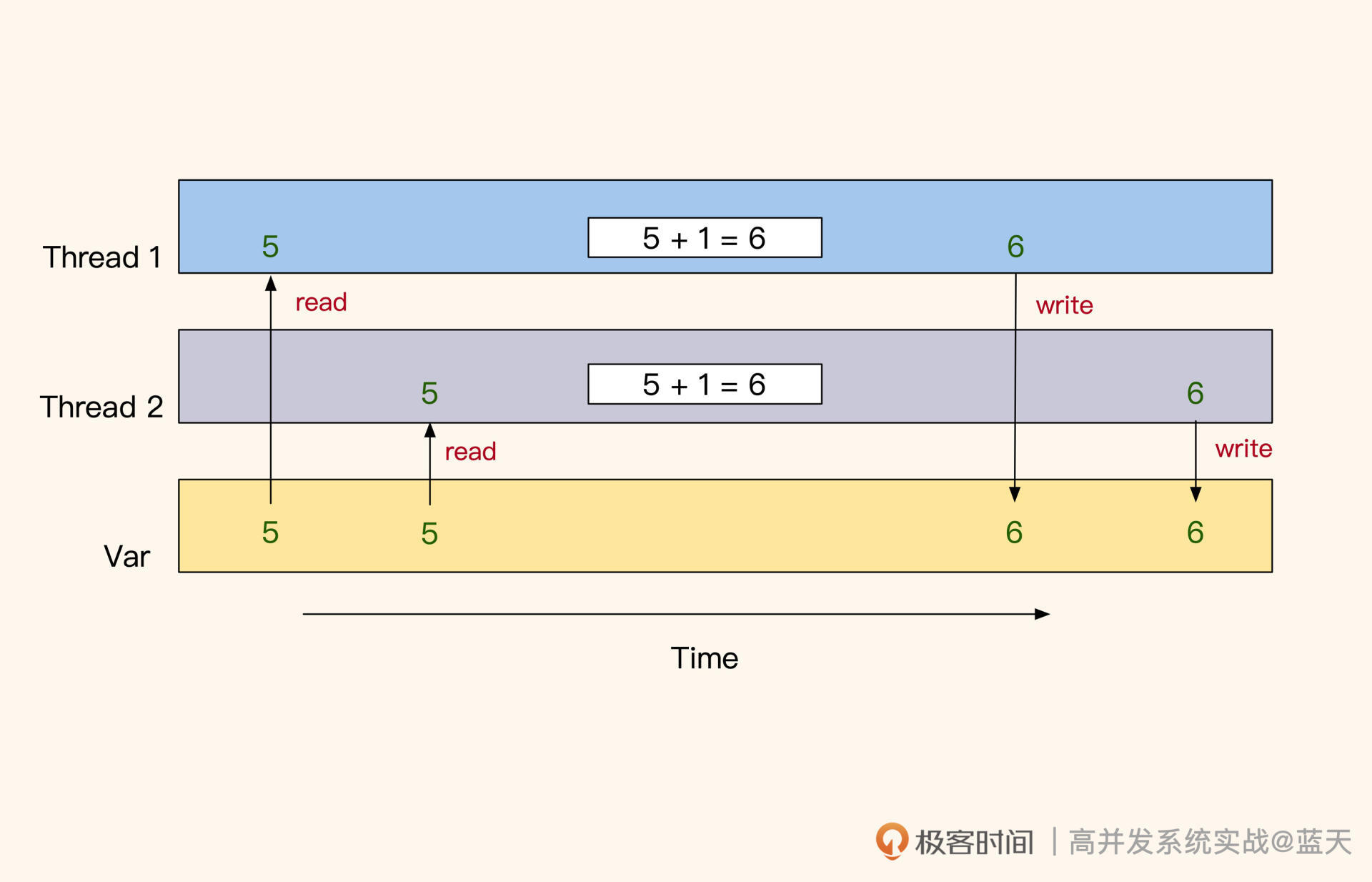
从代码来看,我们运行后结果预期是 2000,但是实际运行后并不是。为什么会这样呢?
当多线程并行对同一个公共变量读写时,由于没有互斥,多线程的 set 会相互覆盖或读取时容易读到其他线程刚写一半的数据,这就导致变量数据被损坏。反过来说,我们要想保证一个变量在多线程并发情况下的准确性,就需要这个变量在修改期间不会被其他线程更改或读取。
对于这个情况,我们一般都会用到锁或原子操作来保护库存变量:
- 如果是简单 int 类型数据,可以使用原子操作保证数据准确;
- 如果是复杂的数据结构或多步操作,可以加锁来保证数据完整性。
考虑到我们之前的习惯会有一定惯性,为了让你更好地理解争抢,这里我再举一个我们常会犯错的例子。因为扣库存的操作需要注意原子性,我们实践的时候常常碰到后面这种方式:
redis> get prod_1475_stock_1
15
redis> set prod_1475_stock_1 14
OK
也就是先将变量从缓存中取出,对其做 -1 操作,再放回到缓存当中,这是个错误做法。
如上图,原因是多个线程一起读取的时候,多个线程同时读到的是 5,set 回去时都是 6,实际每个线程都拿到了库存,但是库存的实际数值并没有累计改变,这会导致库存超卖。如果你需要用这种方式去做,一般建议加一个自旋互斥锁,互斥其他线程做类似的操作。
不过锁操作是很影响性能的,在讲锁方式之前,我先给你介绍几个相对轻量的方式。
原子操作
在高并发修改的场景下,用互斥锁保证变量不被错误覆盖性能很差。让一万个用户抢锁,排队修改一台服务器的某个进程保存的变量,这是个很糟糕的设计。
因为锁在获取期间需要自旋循环等待,这需要不断地循环尝试多次才能抢到。而且参与争抢的线程越多,这种情况就越糟糕,这期间的通讯过程和循环等待很容易因为资源消耗造成系统不稳定。
对此,我会把库存放在一个独立的且性能很好的内存缓存服务 Redis 中集中管理,这样可以减少用户争抢库存导致其他服务的抖动,并且拥有更好的响应速度,这也是目前互联网行业保护库存量的普遍做法。
同时,我不建议通过数据库的行锁来保证库存的修改,因为数据库资源很珍贵,使用数据库行锁去管理库存,性能会很差且不稳定。
前面我们提到当有大量用户去并行修改一个变量时,只有用锁才能保证修改的正确性,但锁争抢性能很差,那怎么降低锁的粒度、减少锁的争枪呢?
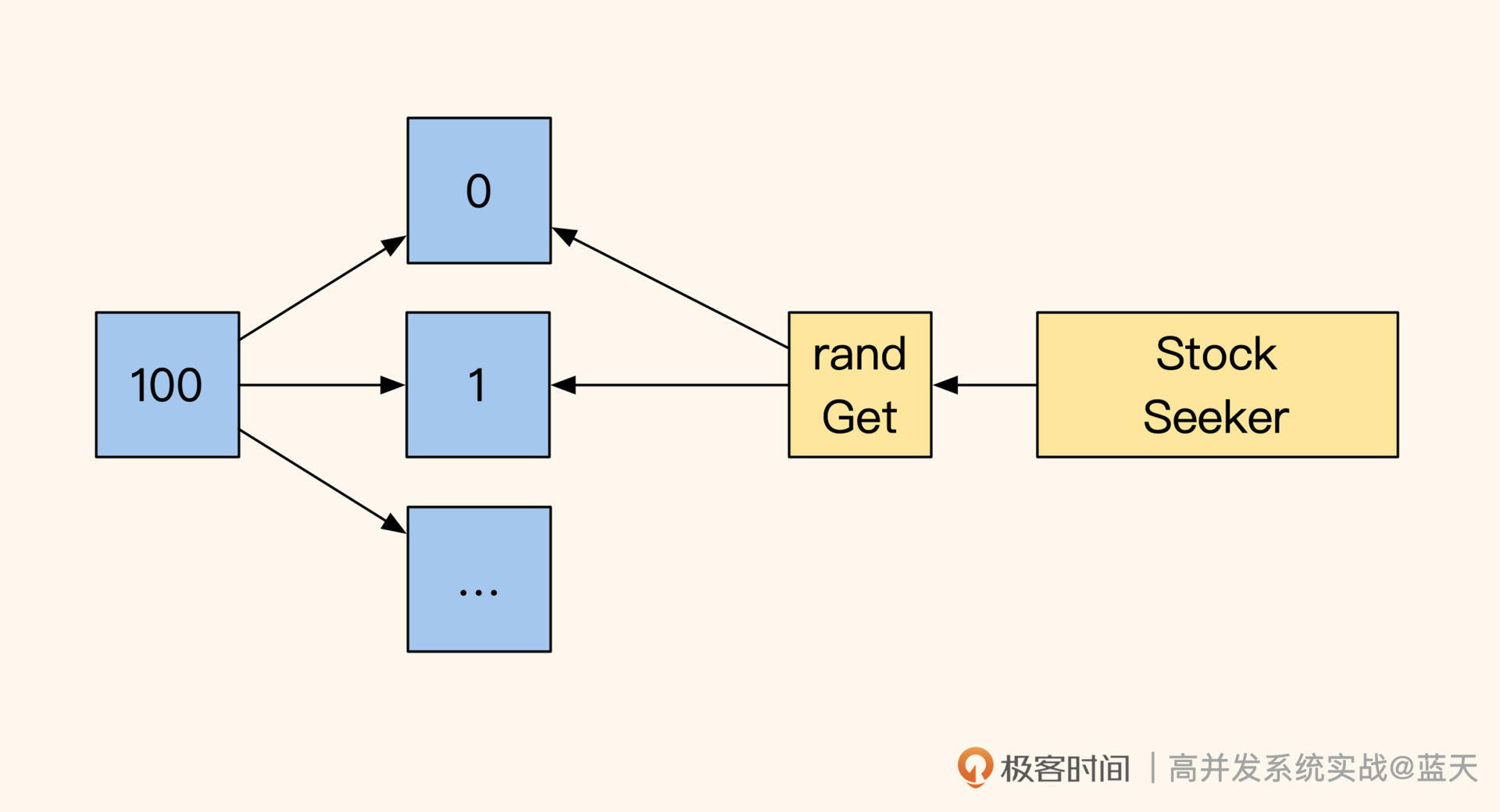
举个例子,当前商品库存有 100 个,我们可以把它放在 10 个 key 中用不同的 Redis 实例保存,每个 key 里面保存 10 个商品库存,当用户下单的时候可以随机找一个 key 进行扣库存操作。如果没库存,就记录好当前 key 再随机找剩下的 9 个 key,直到成功扣除 1 个库存。
除了这种方法以外,我个人更推荐的做法是使用 Redis 的原子操作,因为原子操作的粒度更小,并且是高性能单线程实现,可以做到全局唯一决策。而且很多原子操作的底层实现都是通过硬件实现的,性能很好,比如文稿后面这个例子:
redis> decr prod_1475_stock_1
14
incr、decr 这类操作就是原子的,我们可以根据返回值是否大于 0 来判断是否扣库存成功。但是这里你要注意,如果当前值已经为负数,我们需要考虑一下是否将之前扣除的补偿回来。并且为了减少修改操作,我们可以在扣减之前做一次值检测,整体操作如下:
//读取当前库存,确认是否大于零
//如大于零则继续操作,小于等于拒绝后续
redis> get prod_1475_stock_1
1//开始扣减库存、如返回值大于或等于0那么代表扣减成功,小于0代表当前已经没有库存
//可以看到返回-2,这可以理解成同时两个线程都在操作扣库存,并且都没拿到库存
redis> decr prod_1475_stock_1
-2//扣减失败、补偿多扣的库存
//这里返回0是因为同时两个线程都在做补偿,最终恢复0库存
redis> incr prod_1475_stock
0
这看起来是个不错的保护库存量方案,不过它也有缺点,相信你已经猜到了,这个库存的数值准确性取决于我们的业务是否能够返还恢复之前扣除的值。如果在服务运行过程中,“返还”这个操作被打断,人工修复会很难,因为你不知道当前有多少库存还在路上狂奔,只能等活动结束后所有过程都落地,再来看剩余库存量。
而要想完全保证库存不会丢失,我们习惯性通过事务和回滚来保障。但是外置的库存服务 Redis 不属于数据库的缓存范围,这一切需要通过人工代码去保障,这就要求我们在处理业务的每一处故障时都能处理好库存问题。
所以,很多常见秒杀系统的库存在出现故障时是不返还的,并不是不想返还,而是很多意外场景做不到。
提到锁,也许你会想到使用 Setnx 指令或数据库 CAS 的方式实现互斥排他锁,以此来解决库存问题。但是这个锁有自旋阻塞等待,并发高的时候用户服务需要循环多次做尝试才能够获取成功,这样很浪费系统资源,对数据服务压力较大,不推荐这样去做(这里附上锁性能对比参考)。
令牌库存
除了这种用数值记录库存的方式外,还有一种比较科学的方式就是“发令牌”方式,通过这个方式可以避免出现之前因为抢库存而让库存出现负数的情况。
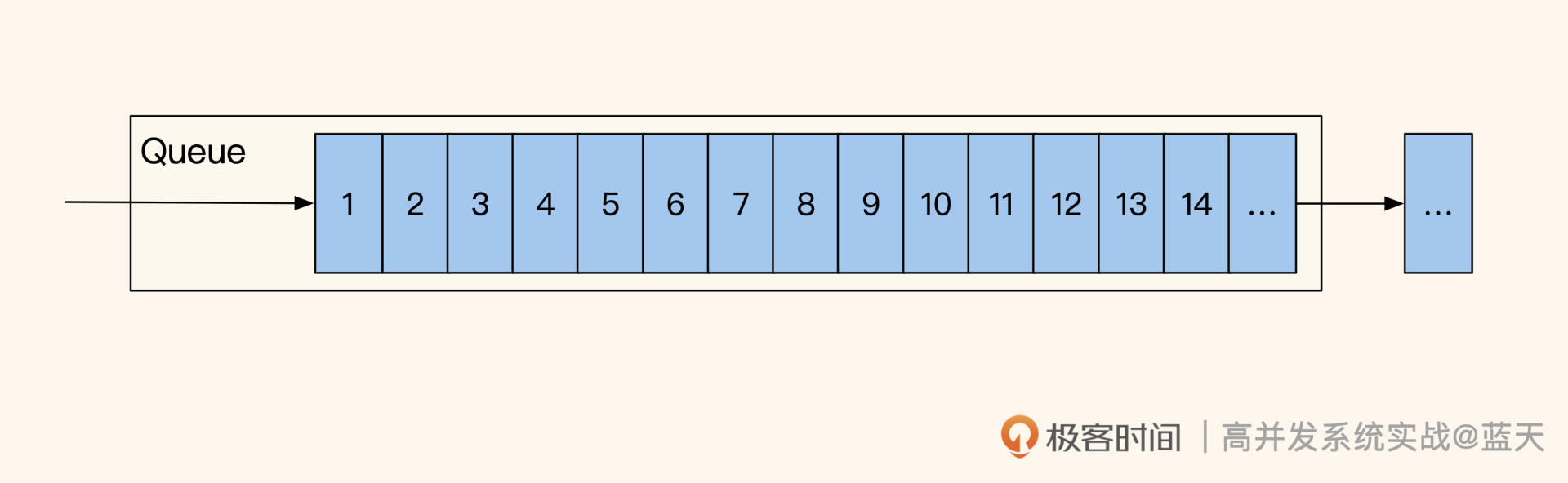
具体是使用 Redis 中的 list 保存多张令牌来代表库存,一张令牌就是一个库存,用户抢库存时拿到令牌的用户可以继续支付:
//放入三个库存
redis> lpush prod_1475_stock_queue_1 stock_1
redis> lpush prod_1475_stock_queue_1 stock_2
redis> lpush prod_1475_stock_queue_1 stock_3//取出一个,超过0.5秒没有返回,那么抢库存失败
redis> brpop prod_1475_stock_queue_1 0.5
在没有库存后,用户只会拿到 nil。当然这个实现方式只是解决抢库存失败后不用再补偿库存的问题,在我们对业务代码异常处理不完善时仍会出现丢库存情况。
同时,我们要注意 brpop 可以从 list 队列“右侧”中拿出一个令牌,如果不需要阻塞等待的话,使用 rpop 压测性能会更好一些。
不过,当我们的库存成千上万的时候,可能不太适合使用令牌方式去做,因为我们需要往 list 中推送 1 万个令牌才能正常工作来表示库存。如果有 10 万个库存就需要连续插入 10 万个字符串到 list 当中,入库期间会让 Redis 出现大量卡顿。
到这里,关于库存的设计看起来已经很完美了,不过请你想一想,如果产品侧提出“一个商品可以抢多个库存”这样的要求,也就是一次秒杀多个同种商品(比如一次秒杀两袋大米),我们利用多个锁降低锁争抢的方案还能满足吗?
多库存秒杀
其实这种情况经常出现,这让我们对之前的优化有了更多的想法。对于一次秒杀多个库存,我们的设计需要做一些调整。
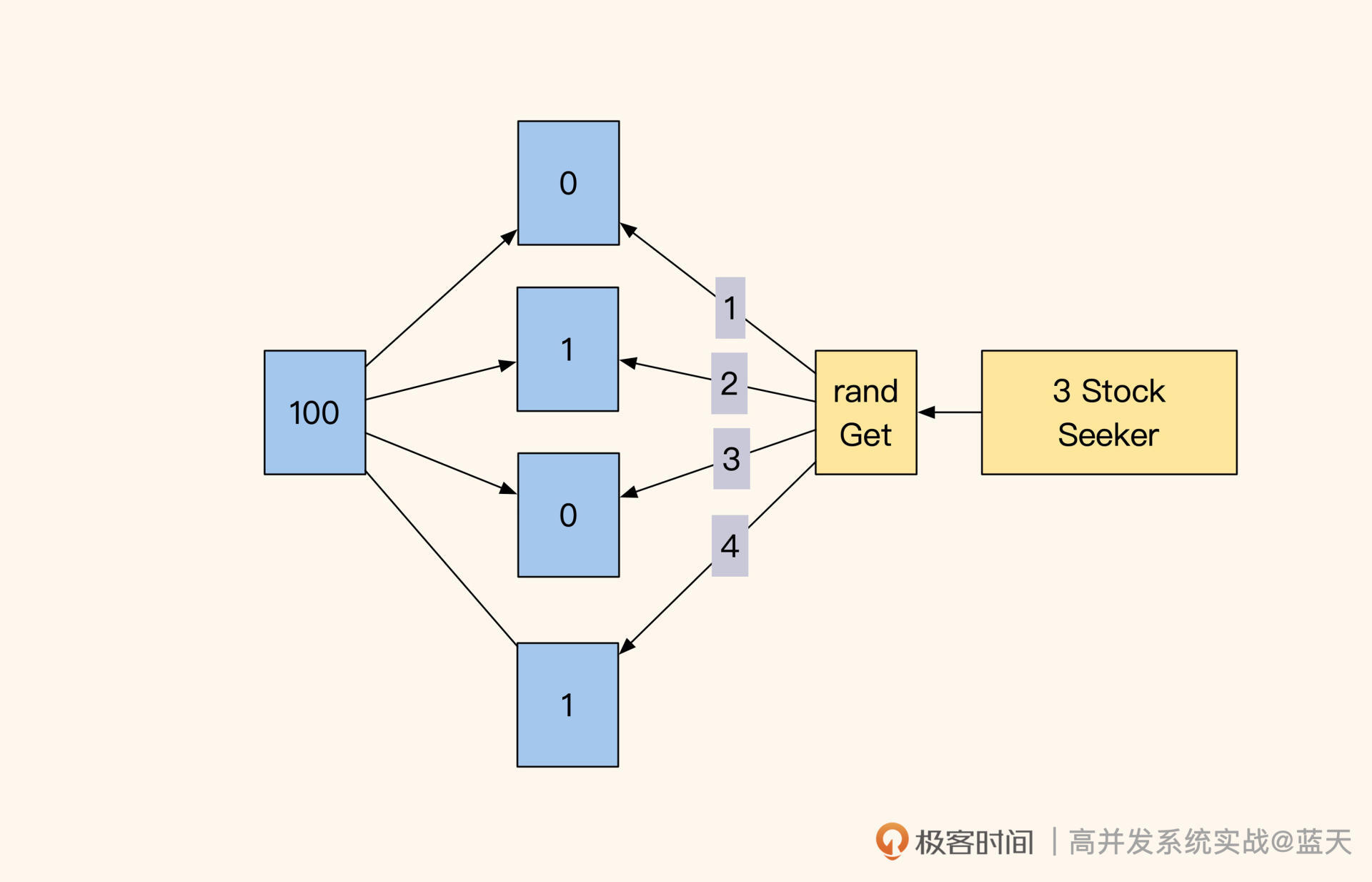
之前我们为了减少锁冲突把库存拆成 10 个 key 随机获取,我们设想一下,当库存剩余最后几个商品时,极端情况下要想秒杀三件商品(如上图),我们需要尝试所有的库存 key,然后在尝试 10 个 key 后最终只拿到了两个商品库存,那么这时候我们是拒绝用户下单,还是返还库存呢?
这其实就要看产品的设计了,同时我们也需要加一个检测:如果商品卖完了就不要再尝试拿 10 个库存 key 了,毕竟没库存后一次请求刷 10 次 Redis,对 Redis 的服务压力很大(Redis O(1) 指令性能理论可以达到 10w OPS,一次请求刷 10 次,那么理想情况下抢库存接口性能为 1W QPS,压测后建议按实测性能 70% 漏斗式限流)。
这时候你应该发现了,在“一个商品可以抢多个库存”这个场景下,拆分并没有减少锁争抢次数,同时还加大了维护难度。当库存越来越少的时候,抢购越往后性能表现越差,这个设计已经不符合我们设计的初衷(由业务需求造成我们底层设计不合适的情况经常会碰到,这需要我们在设计之初,多挖一挖产品具体的需求)。
那该怎么办呢?我们不妨将 10 个 key 合并成 1 个,改用 rpop 实现多个库存扣减,但库存不够三个只有两个的情况,仍需要让产品给个建议看看是否继续交易,同时在开始的时候用 LLEN(O(1))指令检查一下我们的 List 里面是否有足够的库存供我们 rpop,以下是这次讨论的最终设计:
//取之前看一眼库存是否空了,空了不继续了(llen O(1))
redis> llen prod_1475_stock_queue
3//取出库存3个,实际抢到俩
redis> rpop prod_1475_stock_queue 3
"stock_1"
"stock_2"//产品说数量不够,不允许继续交易,将库存返还
redis> lpush prod_1475_stock_queue stock_1
redis> lpush prod_1475_stock_queue stock_2通过这个设计,我们已经大大降低了下单系统锁争抢压力。要知道,Redis 是一个性能很好的缓存服务,其 O(1) 类复杂度的指令在使用长链接的情况下多线程压测,5.0 版本的 Redis 就能够跑到 10w OPS,而 6.0 版本的网络性能会更好。
这种利用 Redis 原子操作减少锁冲突的方式,对各个语言来说是通用且简单的。不过你要注意,不要把 Redis 服务和复杂业务逻辑混用,否则会影响我们的库存接口效率。
自旋互斥超时锁
如果我们在库存争抢时需要操作多个决策 key 才能够完成争抢,那么原子这种方式是不适合的。因为原子操作的粒度过小,无法做到事务性地维持多个数据的 ACID。
这种多步操作,适合用自旋互斥锁的方式去实现,但流量大的时候不推荐这个方式,因为它的核心在于如果我们要保证用户的体验,我们需要逻辑代码多次循环抢锁,直到拿到锁为止,如下:
//业务逻辑需要循环抢锁,如循环10次,每次sleep 10ms,10次失败后返回失败给用户
//获取锁后设置超时时间,防止进程崩溃后没有释放锁导致问题
//如果获取锁失败会返回nil
redis> set prod_1475_stock_lock EX 60 NX
OK//抢锁成功,扣减库存
redis> rpop prod_1475_stock_queue 1
"stock_1"//扣减数字库存,用于展示
redis> decr prod_1475_stock_1
3// 释放锁
redis> del prod_1475_stock_lock
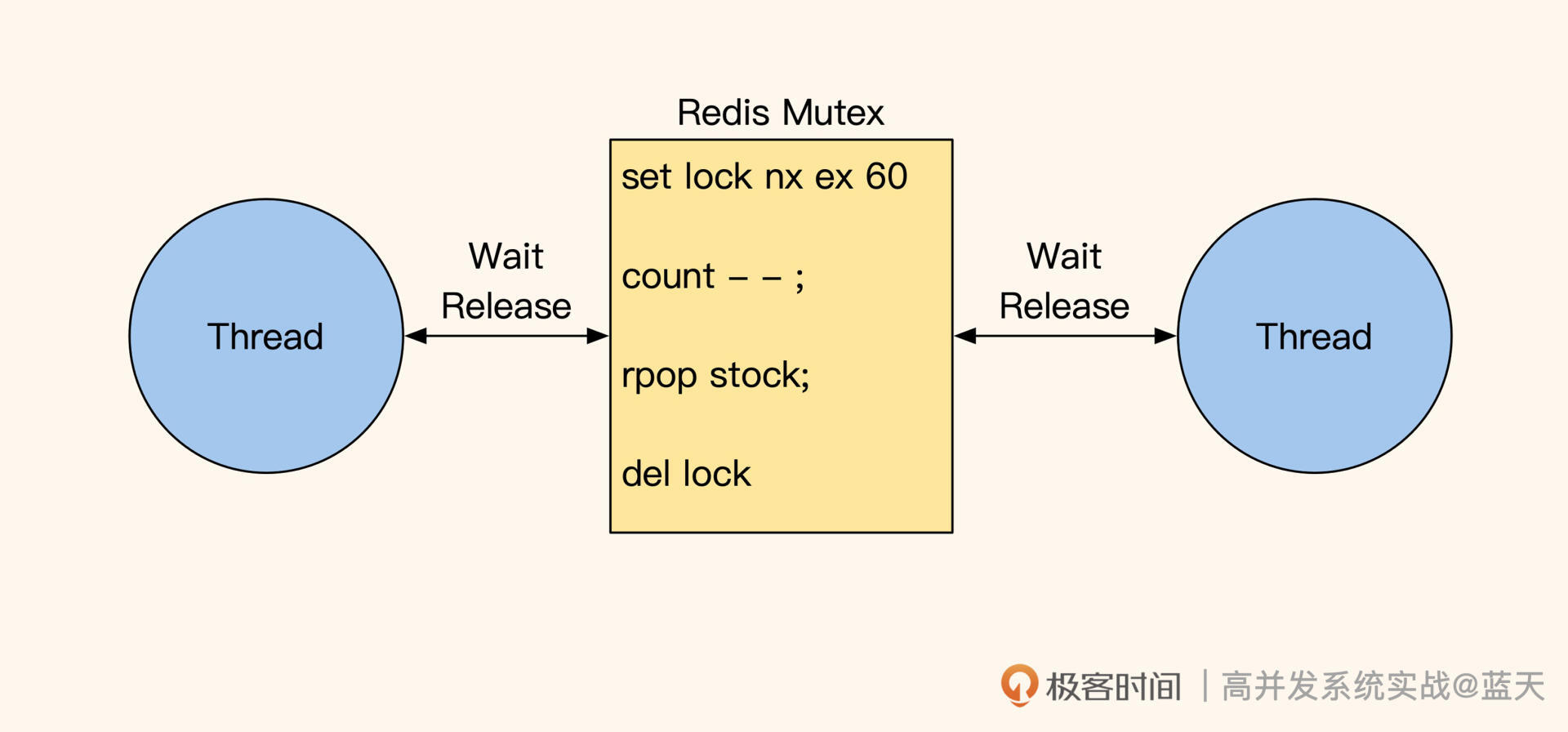
两个线程在等待锁
这种方式的缺点在于,在抢锁阶段如果排队抢的线程越多,等待时间就越长,并且由于多线程一起循环 check 的缘故,在高并发期间 Redis 的压力会非常大,如果有 100 人下单,那么有 100 个线程每隔 10ms 就会 check 一次,此时 Redis 的操作次数就是:
100线程×(1000ms÷10ms)次=10000ops
CAS 乐观锁:锁操作后置
除此之外我再推荐一个实现方式:CAS 乐观锁。相对于自旋互斥锁来说,它在并发争抢库存线程少的时候效率会更好。通常,我们用锁的实现方式是先抢锁,然后,再对数据进行操作。这个方式需要先抢到锁才能继续,而抢锁是有性能损耗的,即使没有其他线程抢锁,这个消耗仍旧存在。
CAS 乐观锁的核心实现为:记录或监控当前库存信息或版本号,对数据进行预操作。
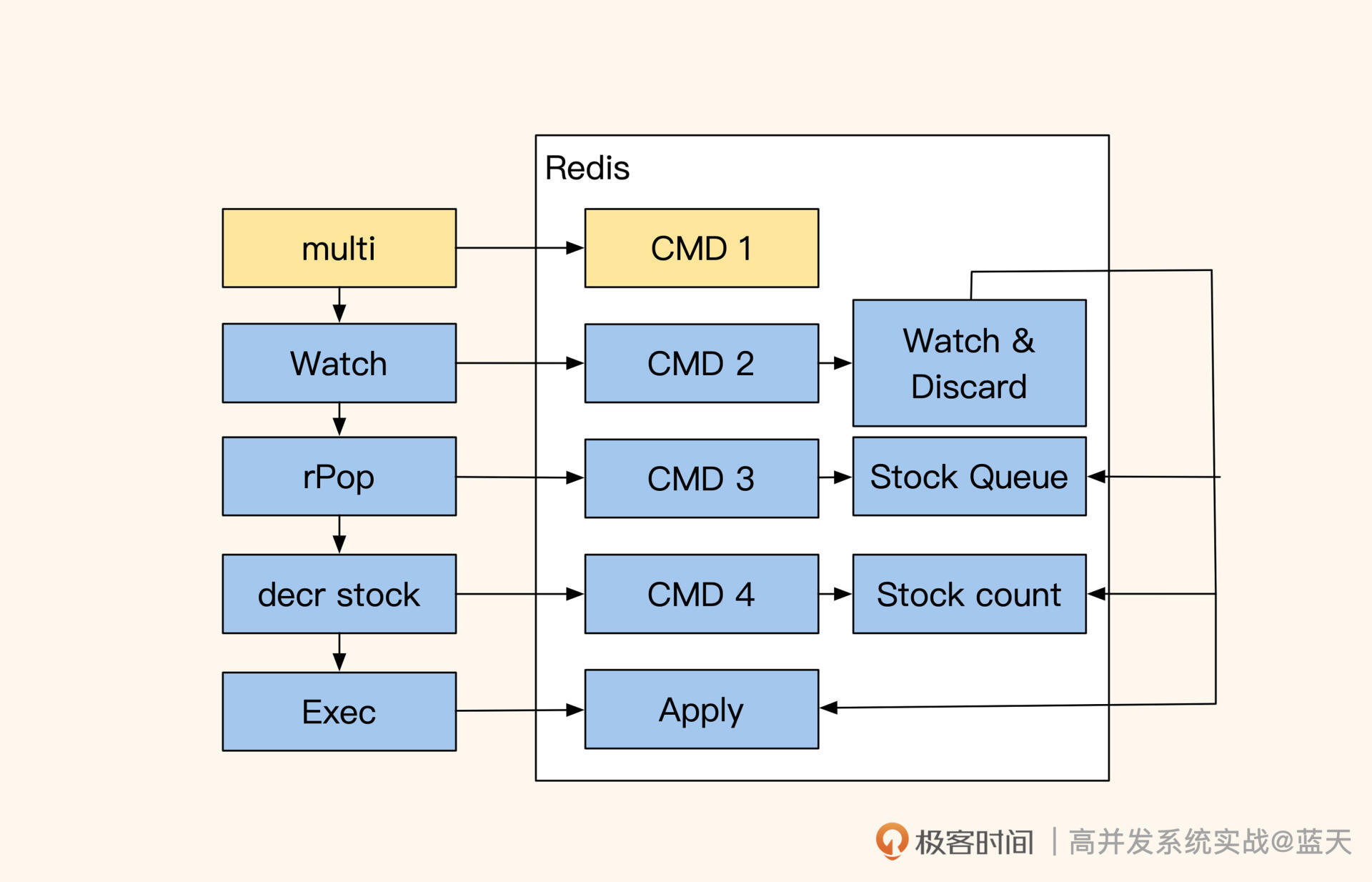
如上图,在操作期间如果发现监控的数值有变化,那么就回滚之前操作;如果期间没有变化,就提交事务的完成操作,操作期间的所有动作都是事务的。
//开启事务
redis> multi
OK// watch 修改值
// 在exec期间如果出现其他线程修改,那么会自动失败回滚执行discard
redis> watch prod_1475_stock_queue prod_1475_stock_1//事务内对数据进行操作
redis> rpop prod_1475_stock_queue 1
QUEUED//操作步骤2
redis> decr prod_1475_stock_1
QUEUED//执行之前所有操作步骤
//multi 期间 watch有数值有变化则会回滚
redis> exec
3
可以看到,通过这个方式我们可以批量地快速实现库存扣减,并且能大幅减少锁争抢时间。它的好处我们刚才说过,就是争抢线程少时效率特别好,但争抢线程多时会需要大量重试,不过即便如此,CAS 乐观锁也会比用自旋锁实现的性能要好。
当采用这个方式的时候,我建议内部的操作步骤尽量少一些。同时要注意,如果 Redis 是 Cluster 模式,使用 multi 时必须在一个 slot 内才能保证原子性。
Redis Lua 方式实现 Redis 锁
与“事务 + 乐观锁”类似的实现方式还有一种,就是使用 Redis 的 Lua 脚本实现多步骤库存操作。因为 Lua 脚本内所有操作都是连续的,这个操作不会被其他操作打断,所以不存在锁争抢问题。
而且、可以根据不同的情况对 Lua 脚本做不同的操作,业务只需要执行指定的 Lua 脚本传递参数即可实现高性能扣减库存,这样可以大幅度减少业务多次请求等待的 RTT。
为了方便演示怎么执行 Lua 脚本,我使用了 PHP 实现:
<?php
$script = <<<EOF
// 获取当前库存个数
local stock=tonumber(redis.call('GET',KEYS[1]));
//没找到返回-1
if stock==nil
then return -1;
end
//找到了扣减库存个数
local result=stock-ARGV[1];
//如扣减后少于指定个数,那么返回0
if result<0
then return 0;
else //如果扣减后仍旧大于0,那么将结果放回Redis内,并返回1redis.call('SET',KEYS[1],result); return 1;
end
EOF;$redis = new \Redis();
$redis->connect('127.0.0.1', 6379);
$result = $redis->eval($script, array("prod_stock", 3), 1);
echo $result;
通过这个方式,我们可以远程注入各种连贯带逻辑的操作,并且可以实现一些补库存的操作。
总结这节课,我们针对库存锁争抢的问题,通过 Redis 的特性实现了六种方案,不过它们各有优缺点
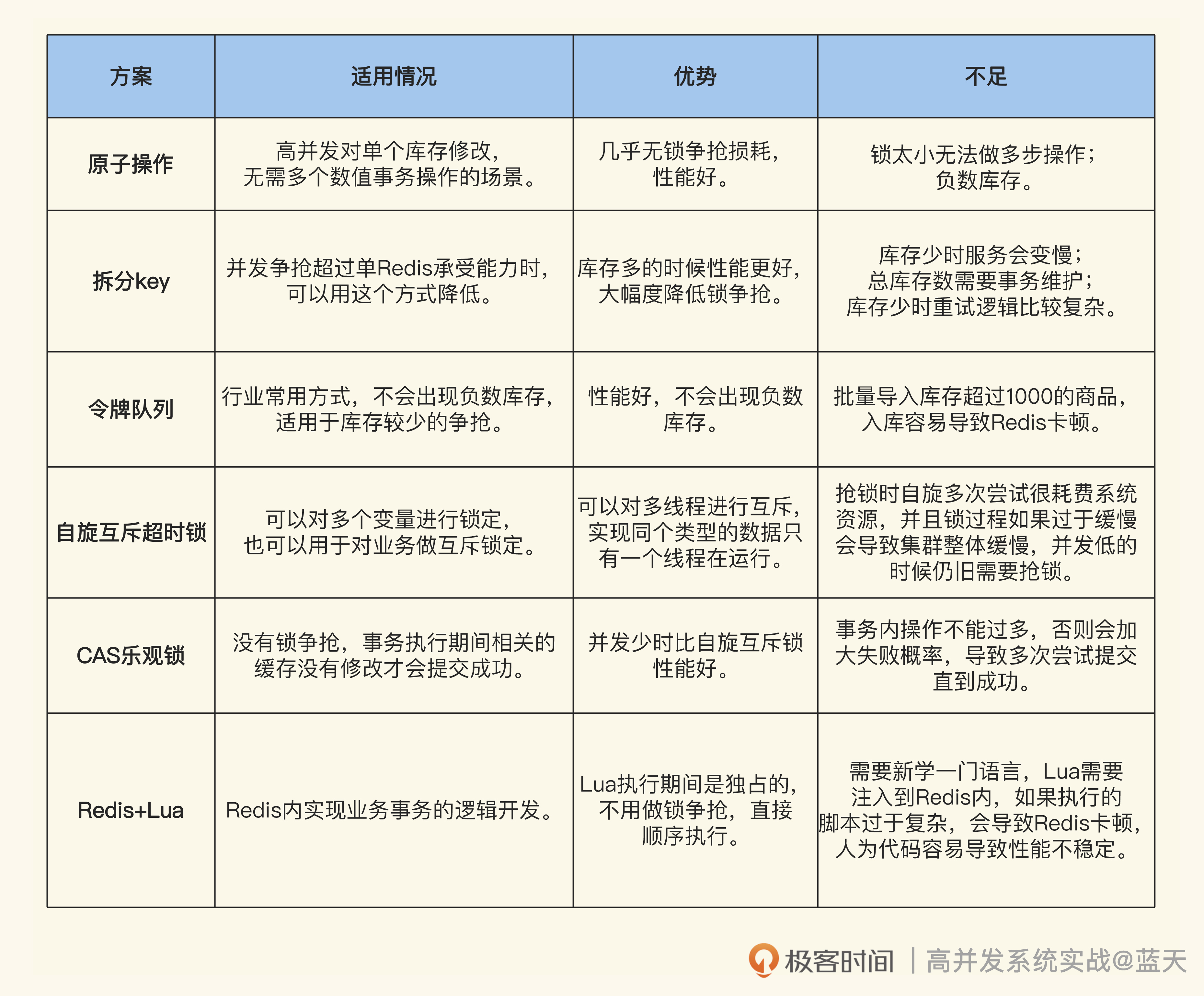
以上这些方法可以根据业务需要组合使用。
其实,我们用代码去实现锁定扣库存也能够实现库存争抢功能,比如本地 CAS 乐观锁方式,但是一般来说,我们自行实现的代码会和其他业务逻辑混在一起,会受到多方因素影响,业务代码会逐渐复杂,性能容易失控。而 Redis 是独立部署的,会比我们的业务代码拥有更好的系统资源去快速解决锁争抢问题。
你可能发现我们这节课讲的方案大多数只有一层“锁”,但很多业务场景实际存在多个锁的情况,并不是我不想介绍,而是十分不推荐,因为多层锁及锁重入等问题引入后会导致我们系统很难维护,一个小粒度的锁能解决我们大部分问题,何乐而不为呢?
系统隔离:如何应对高并发流量冲击?
我曾经在一家教育培训公司做架构师,在一次续报活动中,我们的系统出现了大规模崩溃。在活动开始有五万左右的学员同时操作,大量请求瞬间冲击我们的服务器,导致服务端有大量请求堆积,最终系统资源耗尽停止响应。我们不得不重启服务,并对接口做了限流,服务才恢复正常。
究其原因,我们习惯性地将公用的功能和数据做成了内网服务,这种方式虽然可以提高服务的复用性,但也让我们的服务非常依赖内网服务。当外网受到流量冲击时,内网也会受到放大流量的冲击,过高的流量很容易导致内网服务崩溃,进而最终导致整个网站无法响应。
事故后我们经过详细复盘,最终一致认为这次系统大规模崩溃,核心还是在于系统隔离性做得不好,业务极易相互影响。
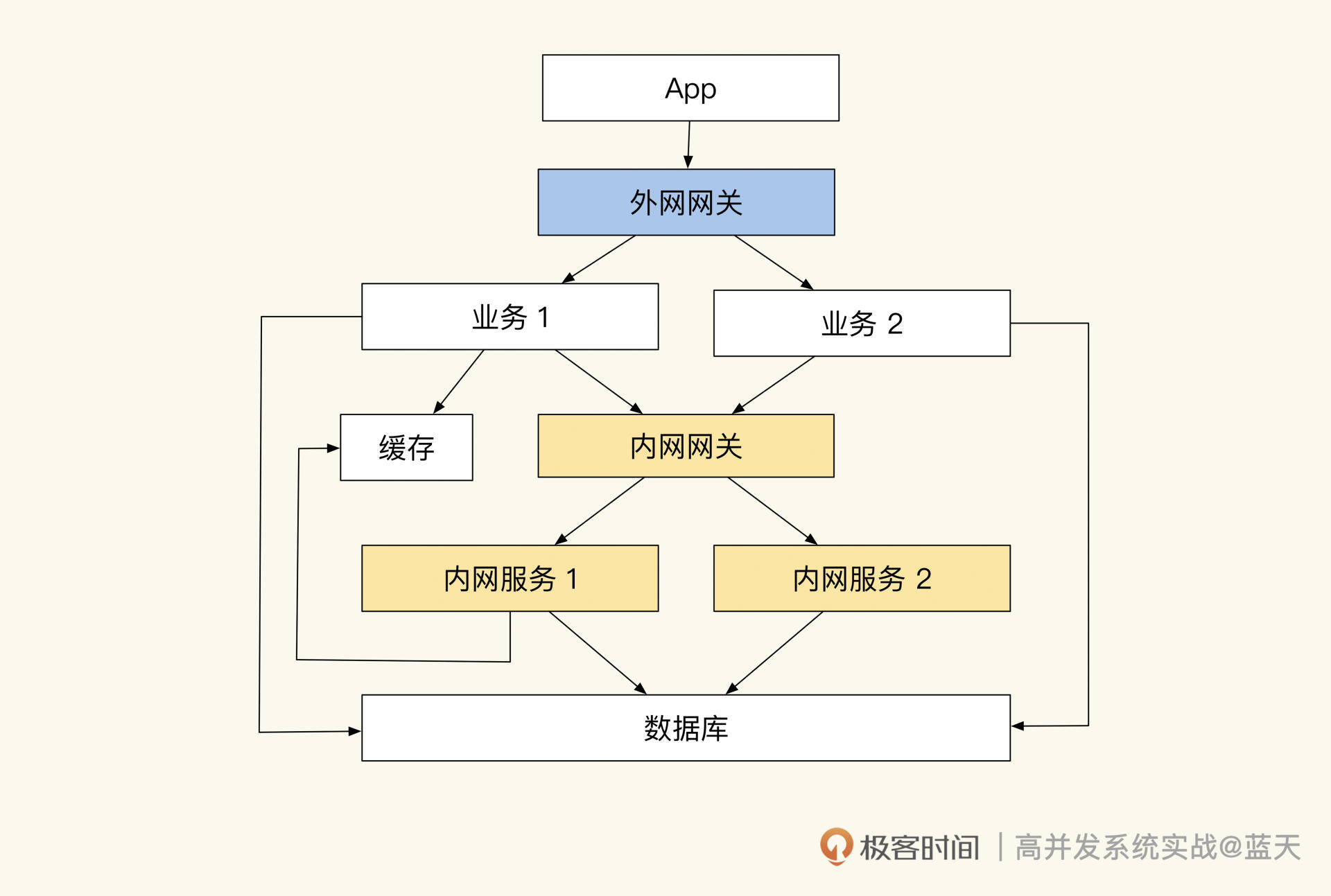
改造前的系统部署结构
如果系统隔离性做得好,在受到大流量冲击时,只会影响被冲击的应用服务,即使某个业务因此崩溃,也不会影响到其他业务的正常运转。这就要求我们的架构要有能力隔离多个应用,并且能够隔离内外网流量,只有如此才能够保证系统的稳定。
拆分部署和物理隔离
为了提高系统的稳定性,我们决定对系统做隔离改造,具体如下图:
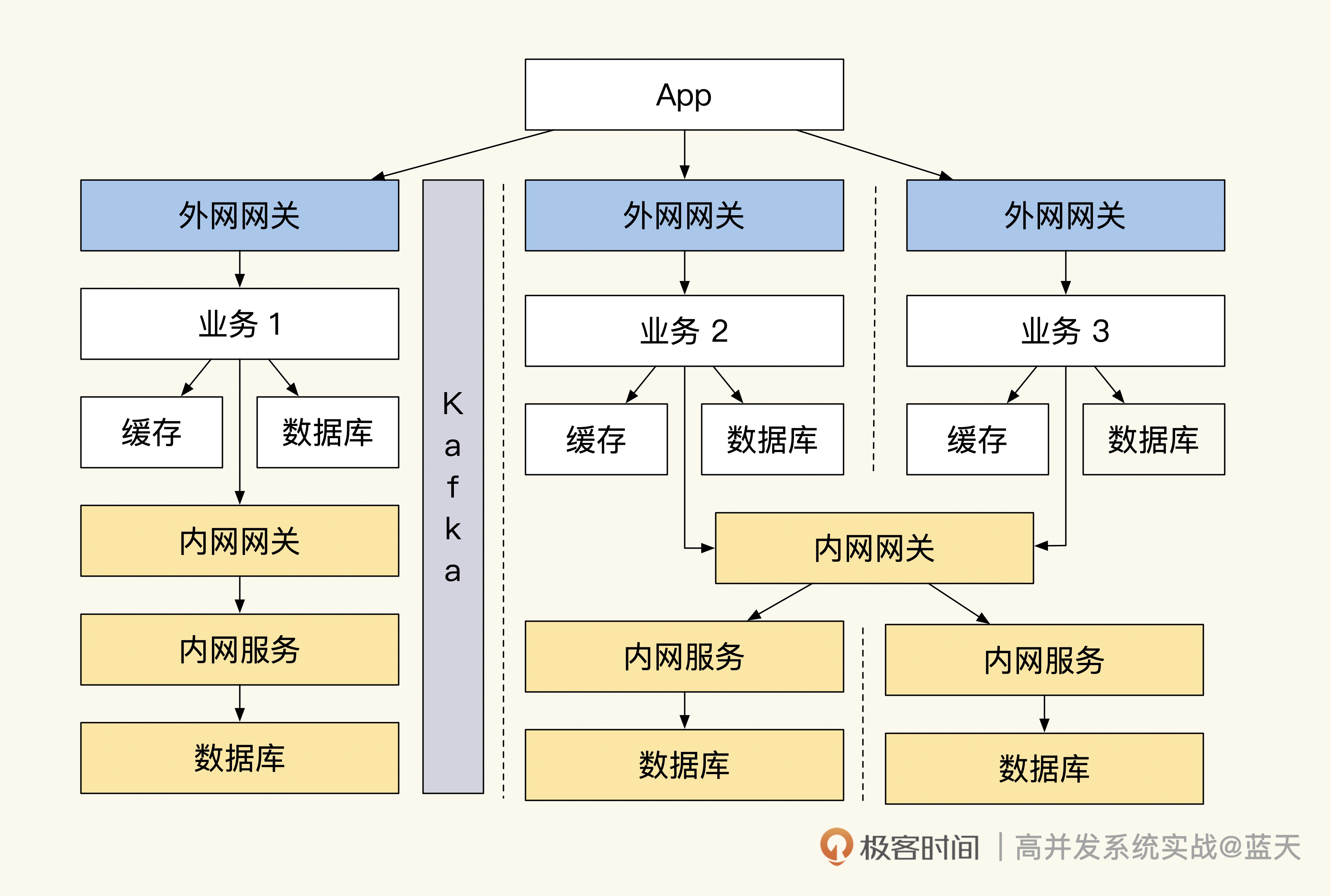
也就是说,每个内、外网服务都会部署在独立的集群内,同时每个项目都拥有自己的网关和数据库。而外网服务和内网必须通过网关才能访问,外网向内网同步数据是用 Kafka 来实现的。
网关隔离和随时熔断
在这个改造方案中有两种网关:外网网关和内网网关。每个业务都拥有独立的外网网关(可根据需要调整)来对外网流量做限流。当瞬时流量超过系统承受能力时,网关会让超编的请求排队阻塞一会儿,等服务器 QPS 高峰过后才会放行,这个方式比起直接拒绝客户端请求来说,可以给用户更好的体验。
外网调用内网的接口必须通过内网网关。外网请求内网接口时,内网网关会对请求的来源系统和目标接口进行鉴权,注册授权过的外网服务只能访问对其授权过的内网接口,这样可以严格管理系统之间的接口调用。
同时,我们在开发期间要时刻注意,内网网关在流量增大的时候要做熔断,这样可以避免外网服务强依赖内网接口,保证外网服务的独立性,确保内网不受外网流量冲击。并且外网服务要保证内网网关断开后,仍旧能正常独立运转一小时以上。
但是你应该也发现了,这样的隔离不能实时调用内网接口,会给研发造成很大的困扰。要知道常见外网业务需要频繁调用内网服务获取基础数据才能正常工作,而且内网、外网同时对同一份数据做决策的话,很容易出现混乱。
减少内网 API 互动
为了防止共享的数据被多个系统同时修改,我们会在活动期间把参与活动的数据和库存做推送,然后自动锁定,这样做可以防止其他业务和后台对数据做修改。若要禁售,则可以通过后台直接调用前台业务接口来操作;活动期间也可以添加新的商品到外网业务中,但只能增不能减。
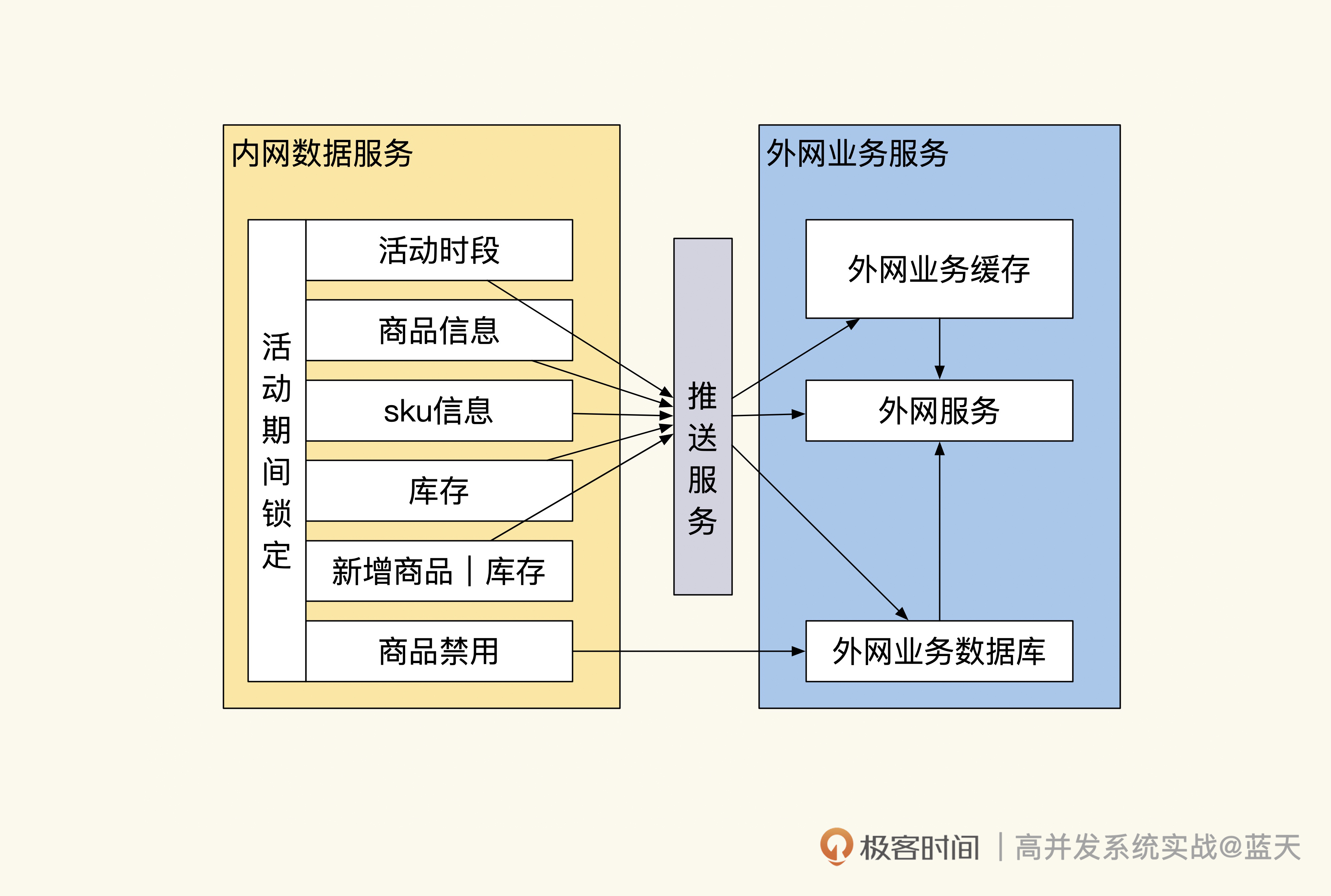
通过缓存推送实现商品数据的同步
这样的实现方式既可以保证一段时间内数据决策的唯一性,也可以保证内外网的隔离性。
不过你要注意,这里的锁定操作只是为了保证数据同步不出现问题,活动高峰过后数据不能一直锁定,否则会让我们的业务很不灵活。
因为我们需要把活动交易结果同步回内网,而同步期间外网还是能继续交易的。如果不保持锁定,数据的流向不小心会成为双向同步,这种双向同步很容易出现混乱,系统要是因此出现问题就很难修复,如下图:
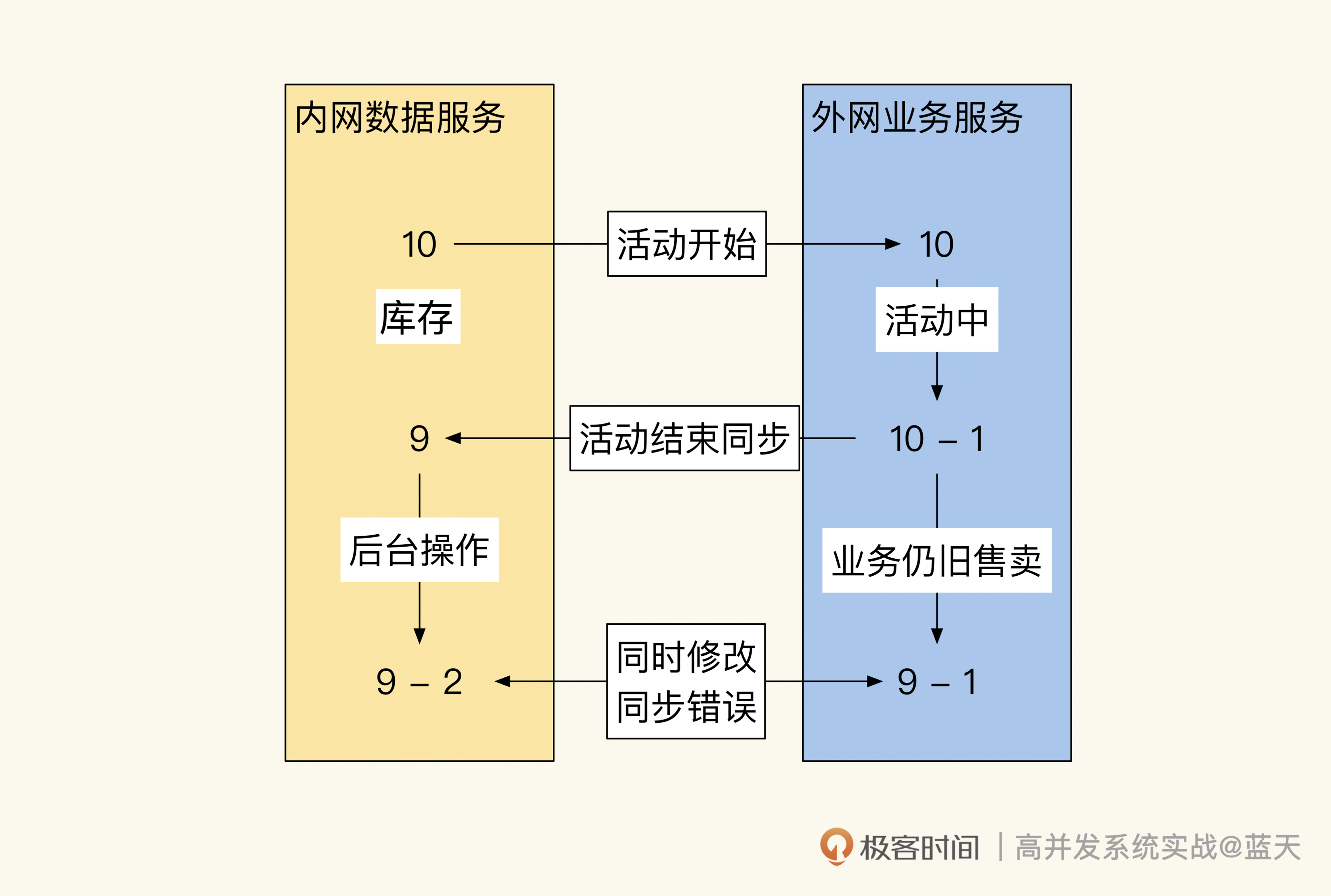
并发决策会导致数据无法决策同步
我们从图中可以看到,两个系统因为没有实时互动的接口,数据是完全独立的,但是在回传外网数据到内网时,库存如果在两个系统之间来回传递,就很容易出现同步冲突进而导致混乱。那怎么避免类似的问题呢?
其实只有保证数据同步是单向的,才能取消相互锁定操作。我们可以规定所有库存决策由外网业务服务决定,后台对库存操作时必须经过外网业务决策后才能继续操作,这样的方式比锁定数据更加灵活。而外网交易后要向内网同步交易结果,只能通过队列方式推送到内网。
事实上,使用队列同步数据并不容易,其中有很多流程和细节需要我们去打磨,以减少不同步的情况。好在我们使用的队列很成熟,提供了很多方便的特性帮助我们降低同步风险。
在我们来看下整体的数据流转,如下图:
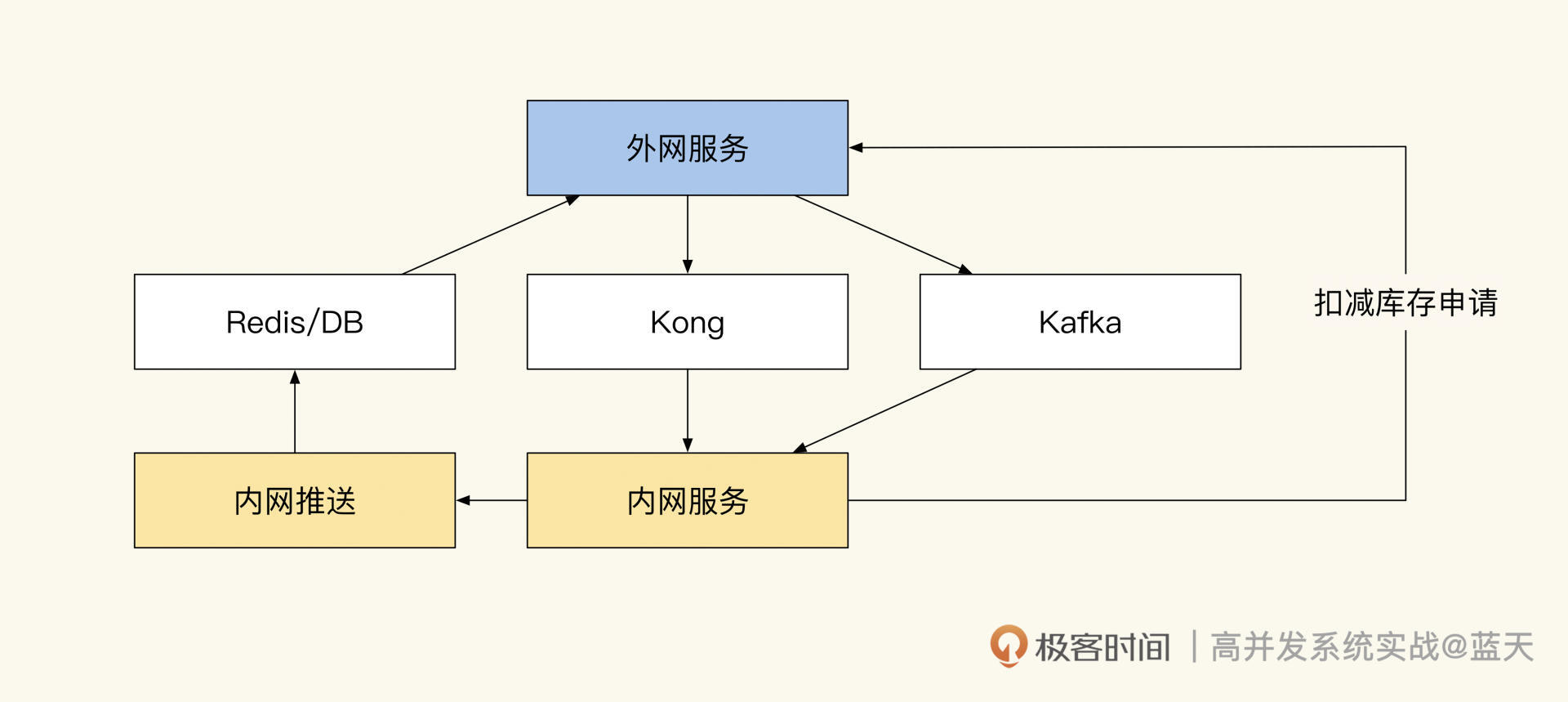
数据流转
后台系统推送数据到 Redis 或数据库中,外网服务通过 Kafka 把结果同步到内网,扣减库存需通知外网服务扣减成功后方可同步操作。
分布式队列控流和离线同步
我们刚才提到,外网和内网做同步用的是 Kafka 分布式队列,主要因为它有以下几个优点:
- 队列拥有良好吞吐并且能够动态扩容,可应对各种流量冲击场景;
- 可通过动态控制内网消费线程数,从而实现内网流量可控;
- 内网消费服务在高峰期可以暂时离线,内网服务可以临时做一些停机升级操作;
- 内网服务如果出现 bug,导致消费数据丢失,可以对队列消息进行回放实现重新消费;
- Kafka 是分区消息同步,消息是顺序的,很少会乱序,可以帮我们实现顺序同步;
- 消息内容可以保存很久,加入 TraceID 后查找方便并且透明,利于排查各种问题。
两个系统之间的数据同步是一件很复杂、很繁琐的事情,而使用 Kafka 可以把这个实时过程变成异步的,再加上消息可回放,流量也可控,整个过程变得轻松很多。
在“数据同步”中最难的一步就是保证顺序,接下来我具体介绍一下我们当时是怎么做的。
当用户在外网业务系统下单购买一个商品时,外网服务会扣减本地缓存中的库存。库存扣减成功后,外网会创建一个订单并发送创建订单消息到消息队列中。当用户在外网业务支付订单后,外网业务订单状态会更新为“已支付”,并给内网发送支付成功的消息到消息队列中,发送消息实现如下:
type ShopOrder struct {TraceId string `json:trace_id` // trace id 方便跟踪问题OrderNo string `json:order_no` // 订单号ProductId string `json:"product_id"` // 课程idSku string `json:"sku"` // 课程规格 skuClassId int32 `json:"class_id"` // 班级idAmount int32 `json:amount,string` // 金额,分Uid int64 `json:uid,string` // 用户uidAction string `json:"action"` // 当前动作 create:创建订单、pay:支付订单、refund:退费、close:关闭订单Status int16 `json:"status"` // 当前订单状态 0 创建 1 支付 2 退款 3 关闭Version int32 `json:"version"` // 版本,会用当前时间加毫秒生成一个时间版本,方便后端对比操作版本,如果收到消息的版本比上次操作的时间还小忽略这个事件UpdateTime int32 `json:"update_time"` // 最后更新时间CreateTime int32 `json:"create_time"` // 订单创建日期
}//发送消息到内网订单系统
resp, err := sendQueueEvent("order_event", shopOrder{...略}, 消息所在分区)
if err != nil {return nil, err
}return resp, nil
可以看到,我们在发送消息的时候已经通过某些依据(如订单号、uid)算出这条消息应该投放到哪个分区内,Kafka 同一个分区内的消息是顺序的。
那为什么要保证消费顺序呢?其实核心在于我们的数据操作必须按顺序执行,如果不按顺序,就会出现很多奇怪的场景。
比如“用户执行创建订单、支付订单、退费”这一系列操作,消费进程很有可能会先收到退费消息,但由于还没收到创建订单和支付订单的消息,退费操作在此时就无法进行。
当然,这只是个简单的例子,如果碰到更多步骤乱序的话,数据会更加混乱。所以我们如果想做好数据同步,就要尽量保证数据是顺序的。
不过,我们在前面讲 Kafka 的优点时也提到了,队列在大部分时间是能够保证顺序性的,但是在极端情况下仍会有乱序发生。为此,我们在业务逻辑上需要做兼容,即使无法自动解决,也要记录好相关日志以方便后续排查问题。
不难发现,因为这个“顺序”的要求,我们的数据同步存在很大难度,好在 Kafka 是能够长时间保存消息的。如果在同步过程中出现问题,除了通过日志对故障进行修复外,我们还可以将故障期间的流量进行重放(重放要保证同步幂等)。
这个特性让我们可以做很多灵活的操作,甚至可以在流量高峰期,暂时停掉内网消费服务,待系统稳定后再开启,落地用户的交易。
除了数据同步外,我们还需要对内网的流量做到掌控,我们可以通过动态控制线程数来实现控制内网流量的速度。好,今天这节课就讲到这里,相信你已经对“如何做好系统隔离”这个问题有了比较深入的理解,期望你在生产过程中能具体实践一下这个方案。
总结
系统的隔离需要我们投入大量的时间和精力去打磨,这节课讲了很多会对系统稳定性产生影响的关键特性,让我们整体回顾一下。
为了实现系统的隔离,我们在外网服务和内网服务之间设立了接口网关,只有通过网关才能调用内网接口服务。并且我们设定了在大流量冲击期间,用熔断内网接口的交互方式来保护内网。而外网所需的所有数据,在活动开始之前都要通过内网脚本推送到商城本地的缓存中,以此来保证业务的运转。
同时,外网成功成交的订单和同步信息通过分布式、可实时扩容和可回放的消息队列投递到了内网,内网会根据内部负载调整消费线程数来实现流量可控的消息消费。由此,我们实现了两个系统之间的同步互动。
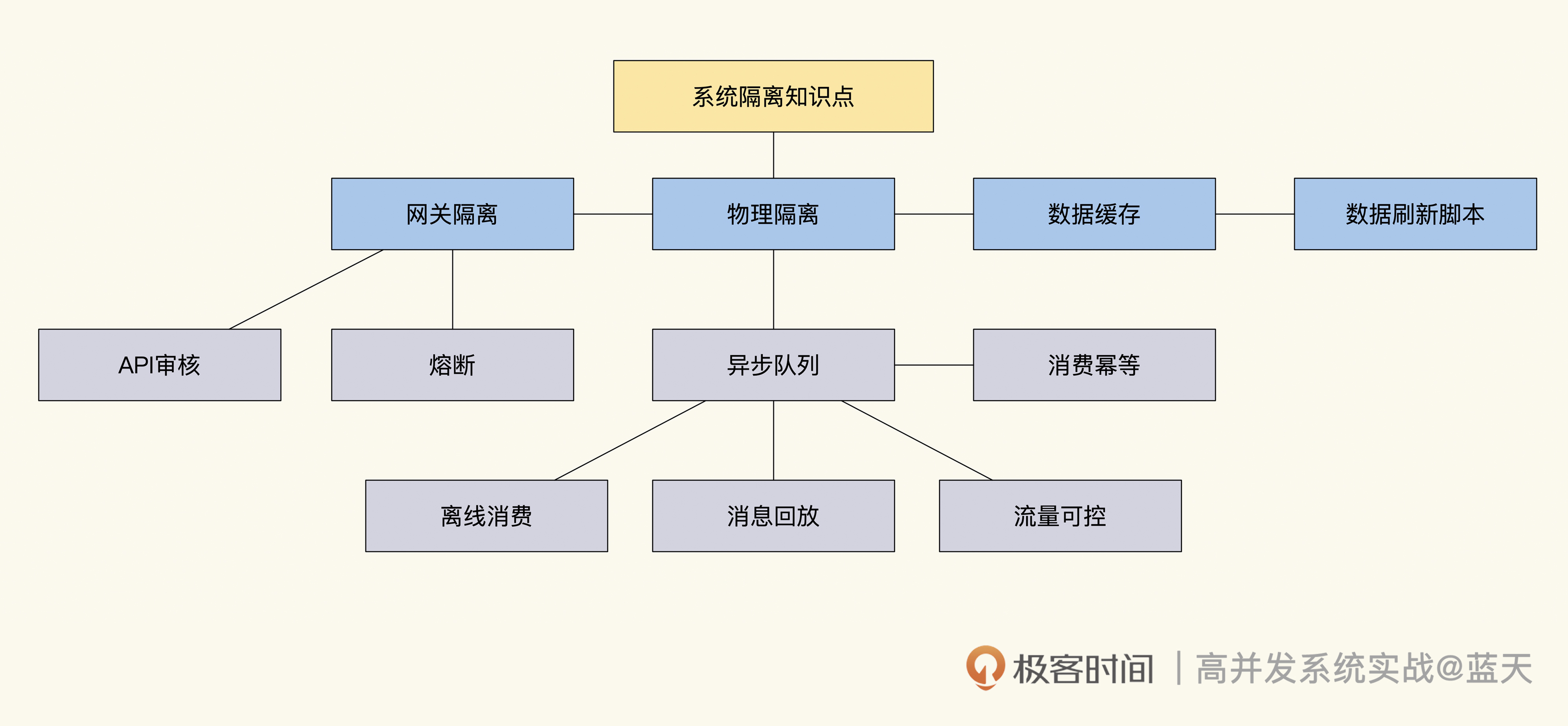
我把这节课的关键知识画成了导图,供你参考:
分布式事务:多服务的2PC、TCC都是怎么实现的?
目前业界流行微服务,DDD 领域驱动设计也随之流行起来。DDD 是一种拆分微服务的方法,它从业务流程的视角从上往下拆分领域,通过聚合根关联多个领域,将多个流程聚合在一起,形成独立的服务。相比由数据表结构设计出的微服务,DDD 这种方式更加合理,但也加大了分布式事务的实现难度。
在传统的分布式事务实现方式中,我们普遍会将一个完整的事务放在一个独立的项目中统一维护,并在一个数据库中统一处理所有的操作。这样在出现问题时,直接一起回滚,即可保证数据的互斥和统一性。
不过,这种方式的服务复用性和隔离性较差,很多核心业务为了事务的一致性只能聚合在一起。
为了保证一致性,事务在执行期间会互斥锁定大量的数据,导致服务整体性能存在瓶颈。而非核心业务要想在隔离要求高的系统架构中,实现跨微服务的事务,难度更大,因为核心业务基本不会配合非核心业务做改造,再加上核心业务经常随业务需求改动(聚合的业务过多),结果就是非核心业务没法做事务,核心业务也无法做个性化改造。
也正因为如此,多个系统要想在互动的同时保持事务一致性,是一个令人头疼的问题,业内很多非核心业务无法和核心模块一起开启事务,经常出现操作出错,需要人工补偿修复的情况。
尤其在微服务架构或用 DDD 方式实现的系统中,服务被拆分得更细,并且都是独立部署,拥有独立的数据库,这就导致要想保持事务一致性实现就更难了,因此跨越多个服务实现分布式事务已成为刚需。
好在目前业内有很多实现分布式事务的方式,比如 2PC、3PC、TCC 等,但究竟用哪种比较合适呢?这是我们需要重点关注的。因此,这节课我会带你对分布式事务做一些讨论,让你对分布式事务有更深的认识,帮你做出更好的决策。
XA 协议
XA 协议是一个很流行的分布式事务协议,可以很好地支撑我们实现分布式事务,比如常见的 2PC、3PC 等。这个协议适合在多个数据库中,协调分布式事务,目前 Oracle、DB2、MySQL 5.7.7 以上版本都支持它(虽然有很多 bug)。而理解了 XA 协议,对我们深入了解分布式事务的本质很有帮助。
支持 XA 协议的数据库可以在客户端断开的情况下,将执行好的业务结果暂存起来,直到另外一个进程确认才会最终提交或回滚事务,这样就能轻松实现多个数据库的事务一致性。
在 XA 协议里有三个主要的角色:
- 应用(AP):应用是具体的业务逻辑代码实现,业务逻辑通过请求事务协调器开启全局事务,在事务协调器注册多个子事务后,业务代码会依次给所有参与事务的子业务下发请求。待所有子业务提交成功后,业务代码根据返回情况告诉事务协调器各个子事务的执行情况,由事务协调器决策子事务是提交还是回滚(有些实现是事务协调器发请求给子服务)。
- 事务协调器(TM):用于创建主事务,同时协调各个子事务。事务协调器会根据各个子事务的执行情况,决策这些子事务最终是提交执行结果,还是回滚执行结果。此外,事务协调器很多时候还会自动帮我们提交事务;
- 资源管理器(RM):是一种支持事务或 XA 协议的数据资源,比如 MySQL、Redis 等。
另外,XA 还对分布式事务规定了两个阶段:Prepare 阶段和 Commit 阶段。
在 Prepare 阶段,事务协调器会通过 xid(事务唯一标识,由业务或事务协调器生成)协调多个资源管理器执行子事务,所有子事务执行成功后会向事务协调器汇报。
这时的子事务执行成功是指事务内 SQL 执行成功,并没有执行事务的最终 commit(提交),所有子事务是提交还是回滚,需要等事务协调器做最终决策。
接着分布式事务进入 Commit 阶段:当事务协调器收到所有资源管理器成功执行子事务的消息后,会记录事务执行成功,并对子事务做真正提交。如果 Prepare 阶段有子事务失败,或者事务协调器在一段时间内没有收到所有子事务执行成功的消息,就会通知所有资源管理器对子事务执行回滚的操作。
需要说明的是,每个子事务都有多个状态,每个状态的流转情况如下图所示:
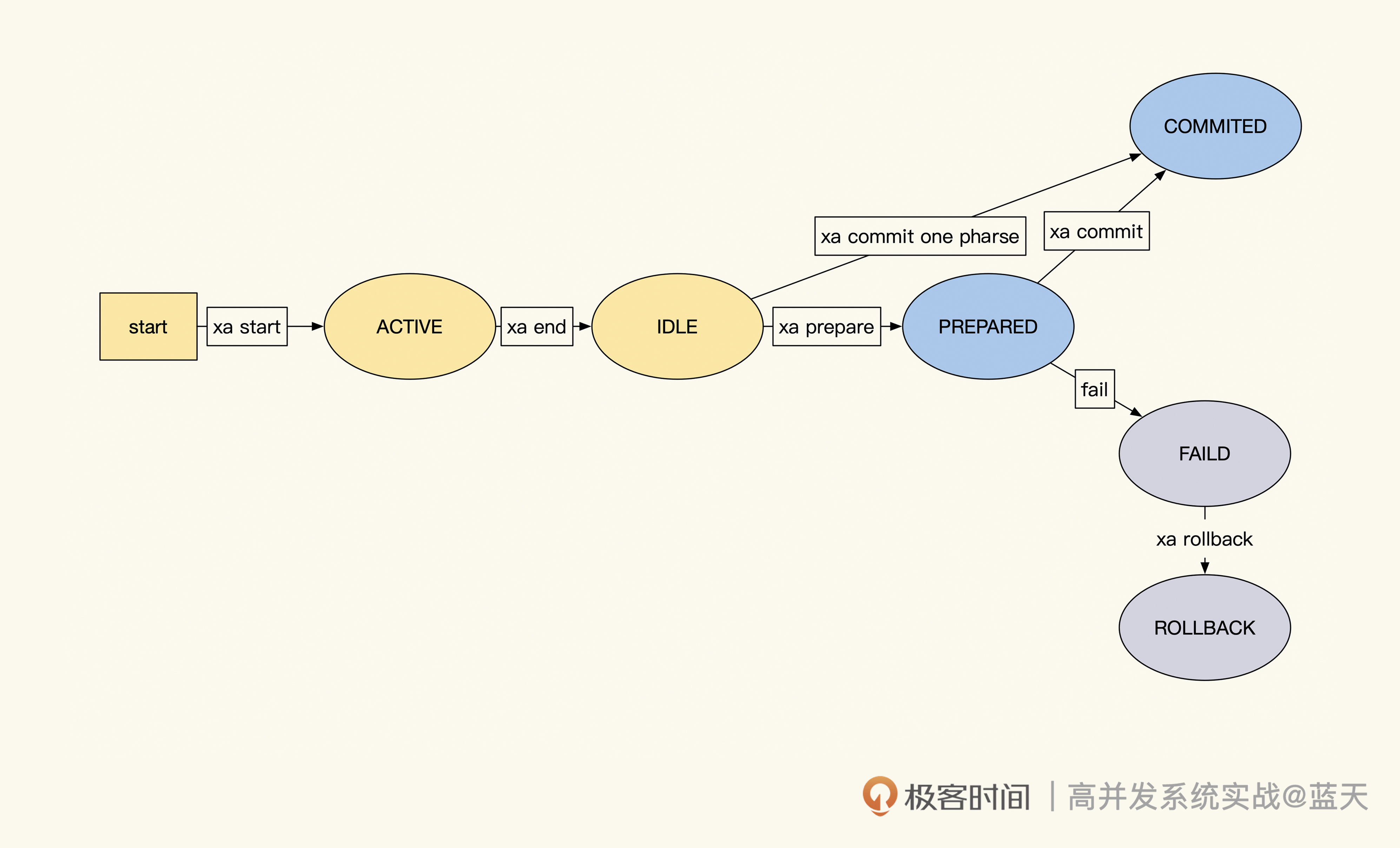
如上图,子事务有四个阶段的状态:
- ACTIVE:子事务 SQL 正在执行中;
- IDLE:子事务执行完毕等待切换 Prepared 状态,如果本次操作不参与回滚,就可以直接提交完成;
- PREPARED:子事务执行完毕,等待其他服务实例的子事务全部 Ready。
- COMMITED/FAILED:所有子事务执行成功 / 失败后,一起提交或回滚。
下面我们来看 XA 协调两个事务的具体流程,这里我拿最常见的 2PC 方式为例进行讲解。
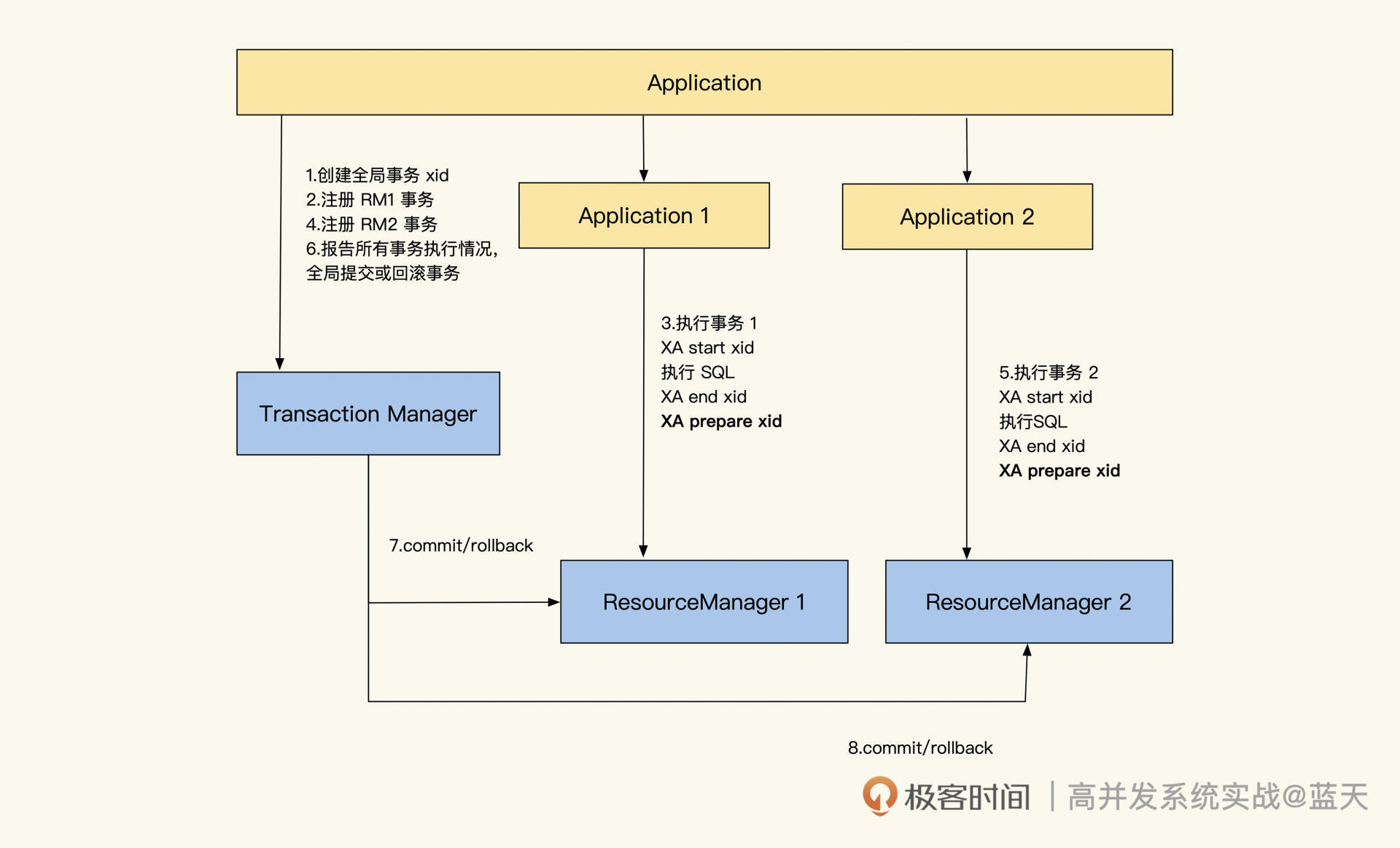
XA 协调两个服务的分布式事务过程
如上图所示,在协调两个服务 Application 1 和 Application 2 时,业务会先请求事务协调器创建全局事务,同时生成全局事务的唯一标识 xid,然后再在事务协调器里分别注册两个子事务,生成每个子事务对应的 xid。这里说明一下,xid 由 gtrid+bqual+formatID 组成,多个子事务的 gtrid 是相同的,但其他部分必须区分开,防止这些服务在一个数据库下。
那么有了子事务的 xid,被请求的服务会通过 xid 标识开启 XA 子事务,让 XA 子事务执行业务操作。当事务数据操作都执行完毕后,子事务会执行 Prepare 指令,将子事务标注为 Prepared 状态,然后以同样的方式执行 xid2 事务。
所有子事务执行完毕后,Prepared 状态的 XA 事务会暂存在 MySQL 中,即使业务暂时断开,事务也会存在。这时,业务代码请求事务协调器通知所有申请的子事务全部执行成功。与此同时,TM 会通知 RM1 和 RM2 执行最终的 commit(或调用每个业务封装的提交接口)。
至此,整个事务流程执行完毕。而在 Prepare 阶段,如果有子事务执行失败,程序或事务协调器,就会通知所有已经在 Prepared 状态的事务执行回滚。
以上就是 XA 协议实现多个子系统的事务一致性的过程,可以说大部分的分布式事务都是使用类似的方式实现的。下面我们通过一个案例,看看 XA 协议在 MySQL 中的指令是如何使用的。
MySQL XA 的 2PC 分布式事务
在进入案例之前,你可以先了解一下 MySQL 中,所有关 XA 协议的指令集,以方便接下来的学习:
# 开启一个事务Id为xid的XA子事务
# gtrid是事务主ID,bqual是子事务标识
# formatid是数据类型标注 类似format type
XA {START|BEGIN} xid[gtrid[,bqual[,format_id]]] [JOIN|RESUME] # 结束xid的子事务,这个事务会标注为IDLE状态
# 如果IDEL状态直接执行XA COMMIT提交那么就是 1PC
XA END xid [SUSPEND [FOR MIGRATE]] # 让子事务处于Prepared状态,等待其他子事务处理后,后续统一最终提交或回滚
# 另外 在这个操作之前如果断开链接,之前执行的事务都会回滚
XA PREPARE xid # 上面不同子事务 用不同的xid(gtrid一致,如果在一个实例bqual必须不同)# 指定xid子事务最终提交
XA COMMIT xid [ONE PHASE]
XA ROLLBACK xid 子事务最终回滚# 查看处于Prepared状态的事务
# 我们用这个来确认事务进展情况,借此决定是否整体提交
# 即使提交链接断开了,我们用这个仍旧能看到所有的PrepareD状态的事务
#
XA RECOVER [CONVERT XID]
言归正传,我们以购物场景为例,在购物的整个事务流程中,需要协调的服务有三个:用户钱包、商品库存和用户购物订单,它们的数据都放在私有的数据库中。
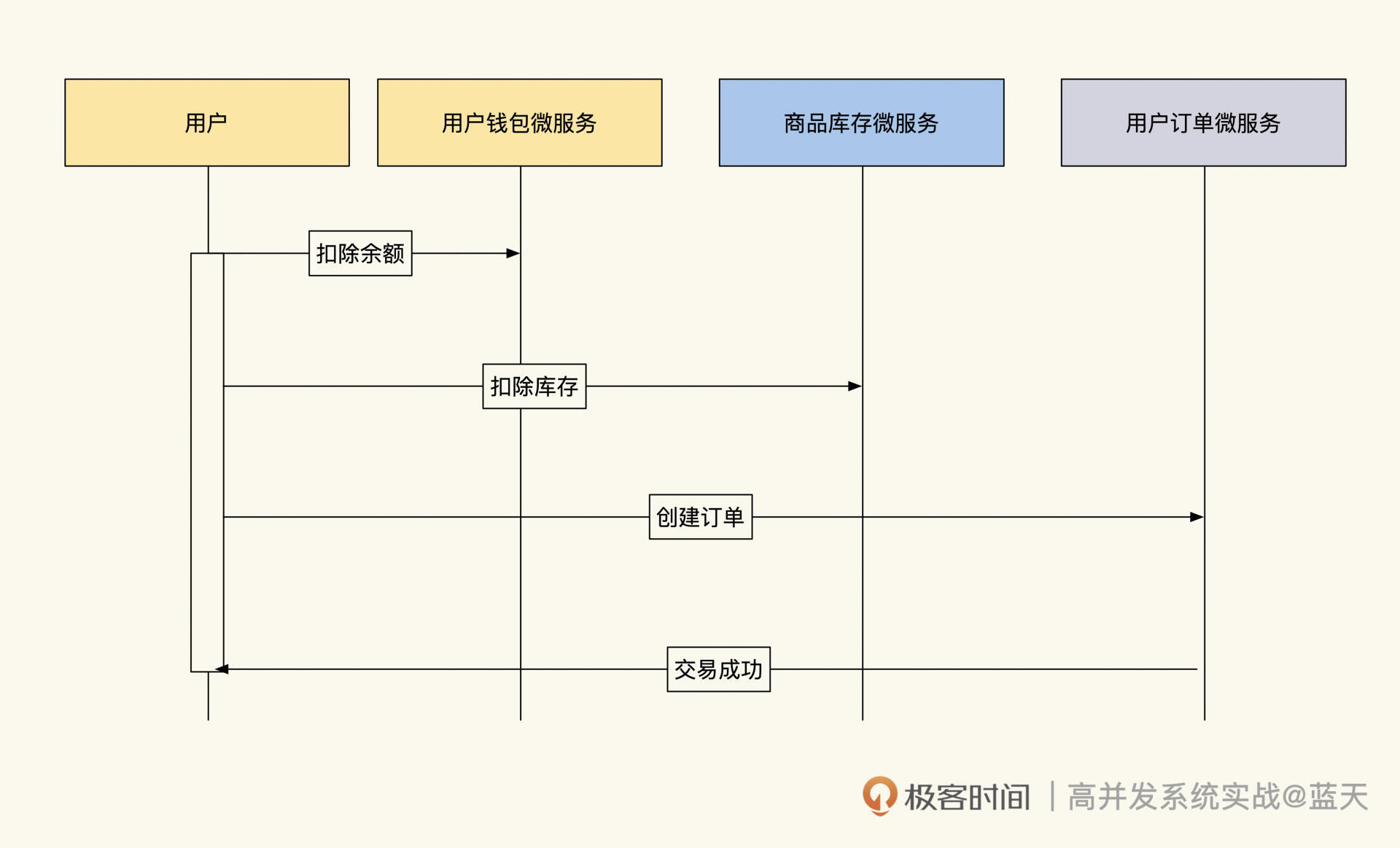
用户购物
按照业务流程,用户在购买商品时,系统需要执行扣库存、生成购物订单和扣除用户账户余额的操作 。其中,“扣库存”和“扣除用户账户余额”是为了保证数据的准确和一致性,所以扣减过程中,要在事务操作期间锁定互斥的其他线程操作保证一致性,然后通过 2PC 方式,对三个服务实现事务协调。
具体实现代码如下:
package main
import ("database/sql""fmt"_ "github.com/go-sql-driver/mysql""strconv""time"
)
func main() {// 库存的连接stockDb, err := sql.Open("mysql", "root:paswd@tcp(127.0.0.1:3306)/shop_product_stock")if err != nil {panic(err.Error())}defer stockDb.Close()//订单的连接orderDb, err := sql.Open("mysql", "root:paswd@tcp(127.0.0.1:3307)/shop_order")if err != nil {panic(err.Error())}defer orderDb.Close()//钱包的连接moneyDb, err := sql.Open("mysql", "root:paswd@tcp(127.0.0.1:3308)/user_money_bag")if err != nil {panic(err.Error())}defer moneyDb.Close()// 生成xid(如果在同一个数据库,子事务不能使用相同xid)xid := strconv.FormatInt(time.Now().UnixMilli(), 10)//如果后续执行过程有报错,那么回滚所有子事务defer func() {if err := recover(); err != nil {stockDb.Exec("XA ROLLBACK ?", xid)orderDb.Exec("XA ROLLBACK ?", xid)moneyDb.Exec("XA ROLLBACK ?", xid)}}()// 第一阶段 Prepare// 库存 子事务启动if _, err = stockDb.Exec("XA START ?", xid); err != nil {panic(err.Error())}//扣除库存,这里省略了数据行锁操作if _, err = stockDb.Exec("update product_stock set stock=stock-1 where id =1"); err != nil {panic(err.Error())}//事务执行结束if _, err = stockDb.Exec("XA END ?", xid); err != nil {panic(err.Error())}//设置库存任务为Prepared状态if _, err = stockDb.Exec("XA PREPARE ?", xid); err != nil {panic(err.Error())}// 订单 子事务启动if _, err = orderDb.Exec("XA START ?", xid); err != nil {panic(err.Error())}//创建订单if _, err = orderDb.Exec("insert shop_order(id,pid,xx) value (1,2,3)"); err != nil {panic(err.Error())}//事务执行结束if _, err = orderDb.Exec("XA END ?", xid); err != nil {panic(err.Error())}//设置任务为Prepared状态if _, err = orderDb.Exec("XA PREPARE ?", xid); err != nil {panic(err.Error())}// 钱包 子事务启动if _, err = moneyDb.Exec("XA START ?", xid); err != nil {panic(err.Error())}//扣减用户账户现金,这里省略了数据行锁操作if _, err = moneyDb.Exec("update user_money_bag set money=money-1 where id =9527"); err != nil {panic(err.Error())}//事务执行结束if _, err = moneyDb.Exec("XA END ?", xid); err != nil {panic(err.Error())}//设置任务为Prepared状态if _, err = moneyDb.Exec("XA PREPARE ?", xid); err != nil {panic(err.Error())}// 在这时,如果链接断开、Prepared状态的XA事务仍旧在MySQL存在// 任意一个链接调用XA RECOVER都能够看到这三个没有最终提交的事务// --------// 第二阶段 运行到这里没有任何问题// 那么执行 commit// --------if _, err = stockDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}if _, err = orderDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}if _, err = moneyDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}//到这里全部流程完毕
}
可以看到,MySQL 通过 XA 指令轻松实现了多个库或多个服务的事务一致性提交。
可能你会想,为什么在上面的代码中没有看到事务协调器的相关操作?这里我们不妨去掉子业务的具体实现,用 API 调用的方式看一下是怎么回事:
package main
import ("database/sql""fmt"_ "github.com/go-sql-driver/mysql""strconv""time"
)
func main() {// 库存的连接stockDb, err := sql.Open("mysql", "root:123456@tcp(127.0.0.1:3306)/shop_product_stock")if err != nil {panic(err.Error())}defer stockDb.Close()//订单的连接orderDb, err := sql.Open("mysql", "root:123456@tcp(127.0.0.1:3307)/shop_order")if err != nil {panic(err.Error())}defer orderDb.Close()//钱包的连接moneyDb, err := sql.Open("mysql", "root:123456@tcp(127.0.0.1:3308)/user_money_bag")if err != nil {panic(err.Error())}defer moneyDb.Close()// 生成xidxid := strconv.FormatInt(time.Now().UnixMilli(), 10)//如果后续执行过程有报错,那么回滚所有子事务defer func() {if err := recover(); err != nil {stockDb.Exec("XA ROLLBACK ?", xid)orderDb.Exec("XA ROLLBACK ?", xid)moneyDb.Exec("XA ROLLBACK ?", xid)}}()//调用API扣款,api内执行xa start、sql、xa end、xa prepareif _, err = API.Call("UserMoneyBagPay", uid, price, xid); err != nil {panic(err.Error())}//调用商品库存扣库存if _, err = API.Call("ShopStockDecr", productId, 1, xid); err != nil {panic(err.Error())}//调用API生成订单if _, err = API.Call("ShopOrderCreate",productId, uid, price, xid); err != nil {panic(err.Error())}// --------// 第二阶段 运行到这里没有任何问题// 那么执行 commit// --------if _, err = stockDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}if _, err = orderDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}if _, err = moneyDb.Exec("XA COMMIT ?", xid); err != nil {panic(err.Error())}//到这里全部流程完毕
}
我想你已经知道了,当前程序本身就已经实现了事务协调器的功能。其实一些开源的分布式事务组件,比如 seata或 dtm 等,对事务协调器有一个更好的抽象封装,如果你感兴趣的话可以体验测试一下。
而上面两个演示代码的具体执行过程如下图所示:
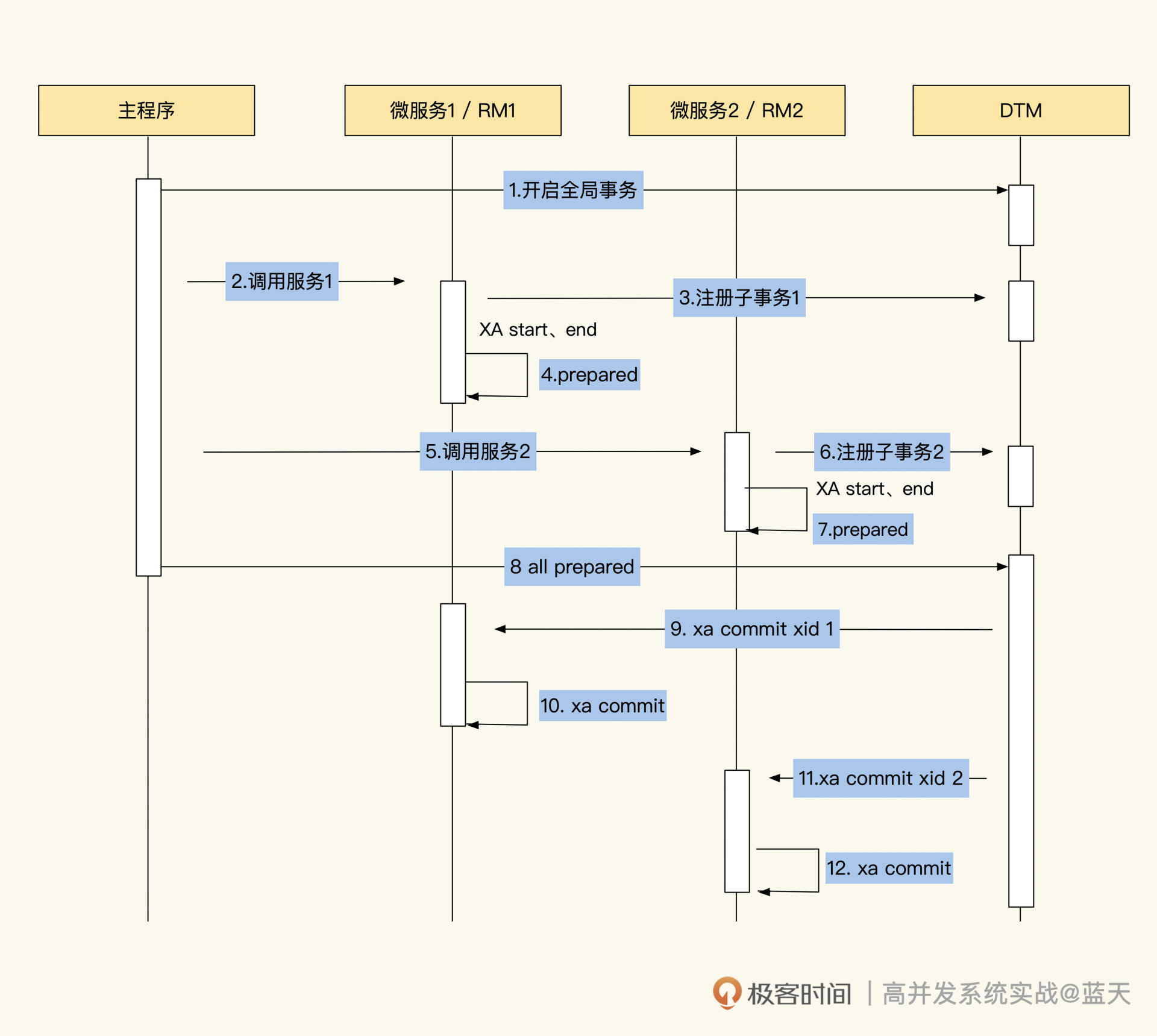
整体流程图
通过流程图你会发现,2PC 事务不仅容易理解,实现起来也简单。
不过它最大的缺点是在 Prepare 阶段,很多操作的数据需要先做行锁定,才能保证数据的一致性。并且应用和每个子事务的过程需要阻塞,等整个事务全部完成才能释放资源,这就导致资源锁定时间比较长,并发也不高,常有大量事务排队。
除此之外,在一些特殊情况下,2PC 会丢数据,比如在 Commit 阶段,如果事务协调器的提交操作被打断了,XA 事务就会遗留在 MySQL 中。
而且你应该已经发现了,2PC 的整体设计是没有超时机制的,如果长时间不提交遗留在 MySQL 中的 XA 子事务,就会导致数据库长期被锁表。
在很多开源的实现中,2PC 的事务协调器会自动回滚或强制提交长时间没有提交的事务,但是如果进程重启或宕机,这个操作就会丢失了,此时就需要人工介入修复了。
3PC 简述
另外提一句,分布式事务的实现除了 2PC 外,还有 3PC。与 2PC 相比,3PC 主要多了事务超时、多次重复尝试,以及提交 check 的功能。但因为确认步骤过多,很多业务的互斥排队时间会很长,所以 3PC 的事务失败率要比 2PC 高很多。
为了减少 3PC 因资源锁定等待超时导致的重复工作,3PC 做了预操作,整体流程分成三个阶段:
- CanCommit 阶段:为了减少因等待锁定数据导致的超时情况,提高事务成功率,事务协调器会发送消息确认资源管理器的资源锁定情况,以及所有子事务的数据库锁定数据的情况。
- PreCommit 阶段:执行 2PC 的 Prepare 阶段;
- DoCommit 阶段:执行 2PC 的 Commit 阶段。
总体来说,3PC 步骤过多,过程比较复杂,整体执行也更加缓慢,所以在分布式生产环境中很少用到它,这里我就不再过多展开了。
TCC 协议
事实上,2PC 和 3PC 都存在执行缓慢、并发低的问题,这里我再介绍一个性能更好的分布式事务 TCC。
TCC 是 Try-Confirm-Cancel 的缩写,从流程上来看,它比 2PC 多了一个阶段,也就是将 Prepare 阶段又拆分成了两个阶段:Try 阶段和 Confirm 阶段。TCC 可以不使用 XA,只使用普通事务就能实现分布式事务。
首先在 Try 阶段,业务代码会预留业务所需的全部资源,比如冻结用户账户 100 元、提前扣除一个商品库存、提前创建一个没有开始交易的订单等,这样可以减少各个子事务锁定的数据量。业务拿到这些资源后,后续两个阶段操作就可以无锁进行了。
在 Confirm 阶段,业务确认所需的资源都拿到后,子事务会并行执行这些业务。执行时可以不做任何锁互斥,也无需检查,直接执行 Try 阶段准备的所有资源就行。
请注意,协议要求所有操作都是幂等的,以支持失败重试,因为在一些特殊情况下,比如资源锁争抢超时、网络不稳定等,操作要尝试执行多次才会成功。
最后在 Cancel 阶段:如果子事务在 Try 阶段或 Confirm 阶段多次执行重试后仍旧失败,TM 就会执行 Cancel 阶段的代码,并释放 Try 预留的资源,同时回滚 Confirm 期间的内容。注意,Cancel 阶段的代码也要做幂等,以支持多次执行。
上述流程图如下:
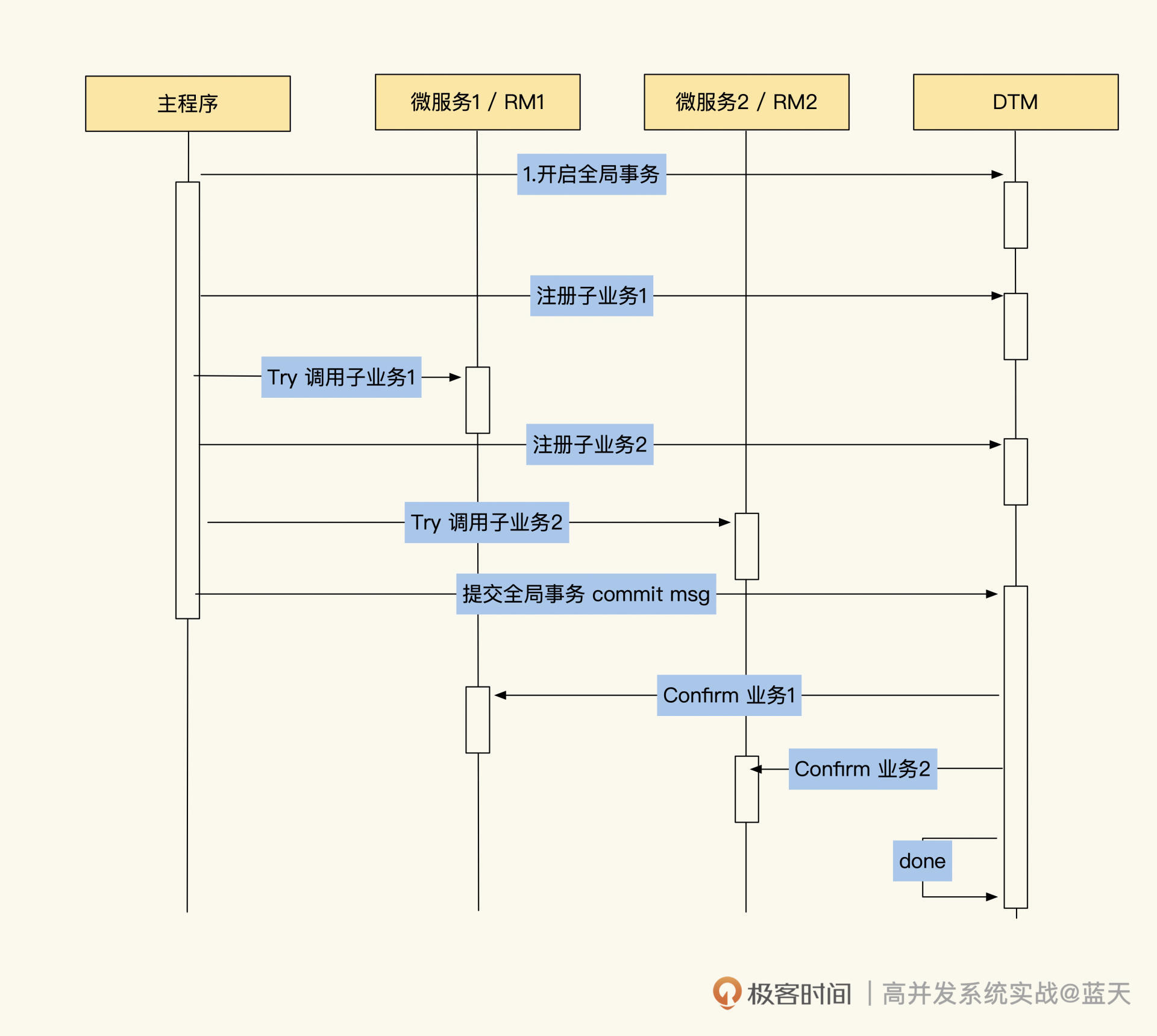
TCC的实现
最后,我们总结一下 TCC 事务的优点:
- 并发能力高,且无长期资源锁定;
- 代码入侵实现分布式事务回滚,开发量较大,需要代码提供每个阶段的具体操作;
- 数据一致性相对来说较好;
- 适用于订单类业务,以及对中间状态有约束的业务。
当然,它的缺点也很明显:
- 只适合短事务,不适合多阶段的事务;
- 不适合多层嵌套的服务;
- 相关事务逻辑要求幂等;
- 存在执行过程被打断时,容易丢失数据的情况。
总结
通常来讲,实现分布式事务要耗费我们大量的精力和时间,硬件上的投入也不少,但当业务真的需要分布式事务时,XA 协议可以给我们提供强大的数据层支撑。
分布式事务的实现方式有多种,常见的有 2PC、3PC、TCC 等。其中,2PC 可以实现多个子事务统一提交回滚,但因为要保证数据的一致性,所以它的并发性能不好。而且 2PC 没有超时的机制,经常会将很多 XA 子事务遗漏在数据库中。
3PC 虽然有超时的机制,但是因为交互过多,事务经常会出现超时的情况,导致事务的性能很差。如果 3PC 多次尝试失败超时后,它会尝试回滚,这时如果回滚也超时,就会出现丢数据的情况。
TCC 则可以提前预定事务中需要锁定的资源,来减少业务粒度。它使用普通事务即可完成分布式事务协调,因此相对地 TCC 的性能很好。但是,提交最终事务和回滚逻辑都需要支持幂等,为此需要人工要投入的精力也更多。
目前,市面上有很多优秀的中间件,比如 DTM、Seata,它们对分布式事务协调做了很多的优化,比如过程中如果出现打断情况,它们能够自动重试、AT 模式根据业务修改的 SQL 自动生成回滚操作的 SQL,这个相对来说会智能一些。
此外,这些中间件还能支持更复杂的多层级、多步骤的事务协调,提供的流程机制也更加完善。所以在实现分布式事务时,建议使用成熟的开源加以辅助,能够让我们少走弯路。
基础服务:写多读少的链路跟踪系统
稀疏索引:为什么高并发写不推荐关系数据库?
从这一章起,我们来学习如何优化写多读少的系统。说到高并发写,就不得不提及新分布式数据库 HTAP,它实现了 OLAP 和 OLTP 的融合,可以同时提供数据分析挖掘和关系查询。
事实上,HTAP 的 OLAP 并不是大数据,或者说它并不是我们印象中每天拿几 T 的日志过来用于离线分析计算的那个大数据。这里更多的是指数据挖掘的最后一环,也就是数据挖掘结果对外查询使用的场景。
对于这个范围的服务,在行业中比较出名的实时数据统计分析的服务有 ElasticSearch、ClickHouse,虽然它们的 QPS 不高,但是能够充分利用系统资源,对大量数据做统计、过滤、查询。但是,相对地,为什么 MySQL 这种关系数据库不适合做类似的事情呢?这节课我们一起分析分析。
B+Tree 索引与数据量
MySQL 我们已经很熟悉了,我们常常用它做业务数据存储查询以及信息管理的工作。相信你也听过“一张表不要超过 2000 万行数据”这句话,为什么会有这样的说法呢?
核心在于 MySQL 数据库的索引,实现上和我们的需求上有些冲突。具体点说,我们对外的服务基本都要求实时处理,在保证高并发查询的同时,还需要在一秒内找出数据并返回给用户,这意味着对数据大小以及数据量的要求都非常高高。
MySQL 为了达到这个效果,几乎所有查询都是通过索引去缩小扫描数据的范围,然后再回到表中对范围内数据进行遍历加工、过滤,最终拿到我们的业务需要的数据。
事实上,并不是 MySQL 不能存储更多的数据,而限制我们的多数是数据查询效率问题。
那么 MySQL 限制查询效率的地方有哪些?请看下图:
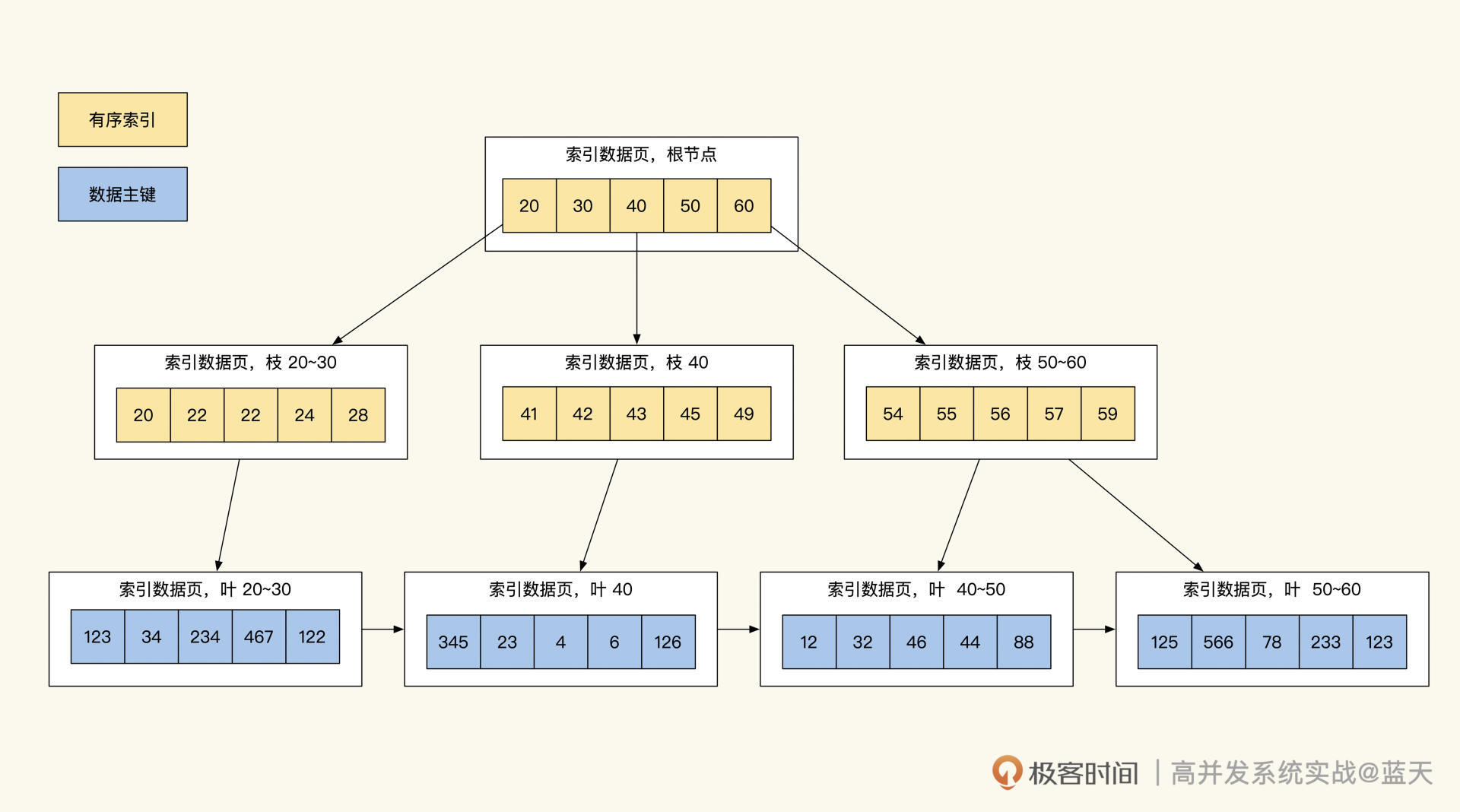
众所周知,MySQL 的 InnoDB 数据库的索引是 B+Tree,B+Tree 的特点在于只有在最底层才会存储真正的数据 ID,通过这个 ID 就可以提取到数据的具体内容,同时 B+Tree 索引最底层的数据是按索引字段顺序进行存储的。
通过这种设计方式,我们只需进行 1~3 次 IO(树深度决定了 IO 次数)就能找到所查范围内排序好的数据,而树形的索引最影响查询效率的是树的深度以及数据量(数据越独特,筛选的数据范围就越少)。
数据量我么很好理解,只要我们的索引字段足够独特,筛选出来的数据量就是可控的。
但是什么会影响到索引树的深度个数呢?这是因为 MySQL 的索引是使用 Page 作为单位进行存储的,而每页只能存储 16KB(innodb_page_size)数据。如果我们每行数据的索引是 1KB,那么除去 Page 页的一些固定结构占用外,一页只能放 16 条数据,这导致树的一些分支装不下更多数据时,我么就需要对索引的深度再加一层。
我们从这个 Page 就可以推导出:索引第一层放 16 条,树第二层大概能放 2 万条,树第三层大概能放 2400 万条,三层的深度 B+Tree 按主键查找数据每次查询需要 3 次 IO(一层索引在内存,IO 两次索引,最后一次是拿数据)。
不过这个 2000 万并不是绝对的,如果我们的每行数据是 0.5KB,那么大概在 4000 万以后才会出现第四层深度。而对于辅助索引,一页 Page 能存放 1170 个索引节点(主键 bigint8 字节 + 数据指针 6 字节),三层深度的辅助索引大概能记录 10 亿条索引记录。
可以看到,我们的数据存储数量超过三层时,每次数据操作需要更多的 IO 操作来进行查询,这样做的后果就是查询数据返回的速度变慢。所以,很多互联网系统为了保持服务的高效,会定期整理数据。
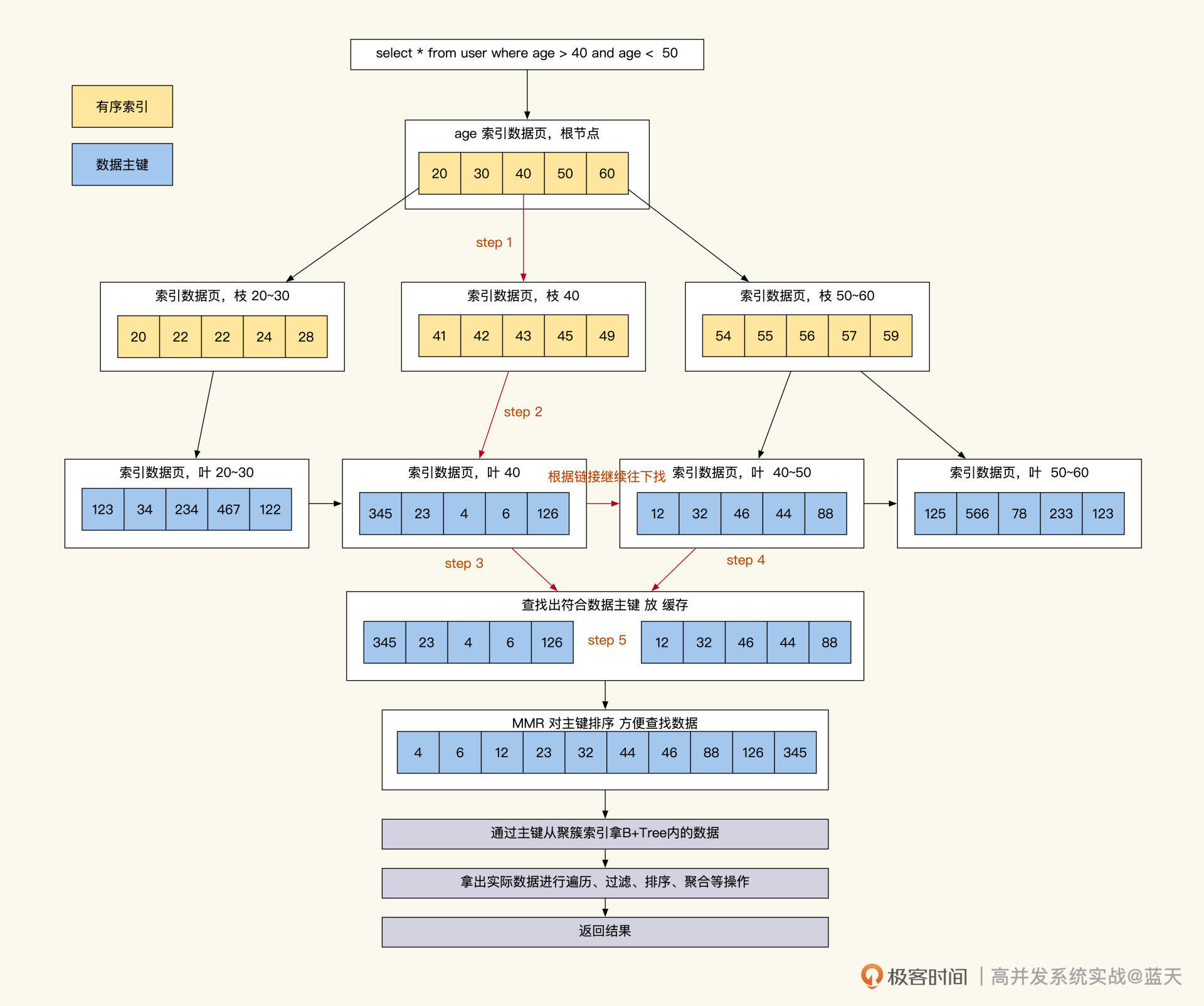
通过上面的讲解,相信你已经对整个查询有画面感了:当我们查询时,通过 1~3 次 IO 查找辅助索引,从而找到一批数据主键 ID。然后,通过 MySQL 的 MMR 算法将这些 ID 做排序,再回表去聚簇索引按取值范围提取在子叶上的业务数据,将这些数据边取边算或一起取出再进行聚合排序后,之后再返回结果。
可以看到,我们常用的数据库之所以快,核心在于索引用得好。由于加工数据光用索引是无法完成的,我们还需要找到具体的数据进行再次加工,才能得到我们业务所需的数据,这也是为什么我们的字段数据长度和数据量会直接影响我们对外服务的响应速度。
同时请你注意,我们一个表不能增加过多的索引,因为索引太多会影响到表插入的性能。并且我们的查询要遵循左前缀原则来逐步缩小查找的数据范围,而不能利用多个 CPU 并行去查询索引数据。这些大大限制了我们对大数据的处理能力。
另外,如果有数据持续高并发插入数据库会导致 MySQL 集群工作异常、主库响应缓慢、主从同步延迟加大等问题。从部署结构上来说,MySQL 只有主从模式,大批量的数据写操作只能由主库承受,当我们数据写入缓慢时客户端只能等待服务端响应,严重影响数据写入效率。
看到这里,相信你已经理解为什么关系型数据库并不适合太多的数据,其实 OLAP 的数据库也不一定适合大量的数据,正如我提到的 OLAP 提供的服务很多也需要实时响应,所以很多时候这类数据库对外提供服务的时候,计算用的数据也是做过深加工的。但即使如此,OLAP 和 OLTP 底层实现仍旧有很多不同。
我们先来分析索引的不同。OLTP 常用的是 B+Tree,我们知道,B+tree 索引是一个整体的树,当我们的数据量大时会影响索引树的深度,如果深度过高就会严重影响其工作效率。对于大量数据,OLAP 服务会用什么类型的索引呢?
稀疏索引 LSM Tree 与存储
这里重点介绍一下 LSM 索引。我第一次见到 LSM Tree 还是从 RocksDB(以及 LevelDB)上看到的,RocksDB 之所以能够得到快速推广并受到欢迎,主要是因为它利用了磁盘顺序写性能超绝的特性,并以较小的性能查询代价提供了写多读少的 KV 数据存储查询服务,这和关系数据库的存储有很大的不同。
为了更好理解,我们详细讲讲 Rocksdb 稀疏索引是如何实现的,如下图所示:
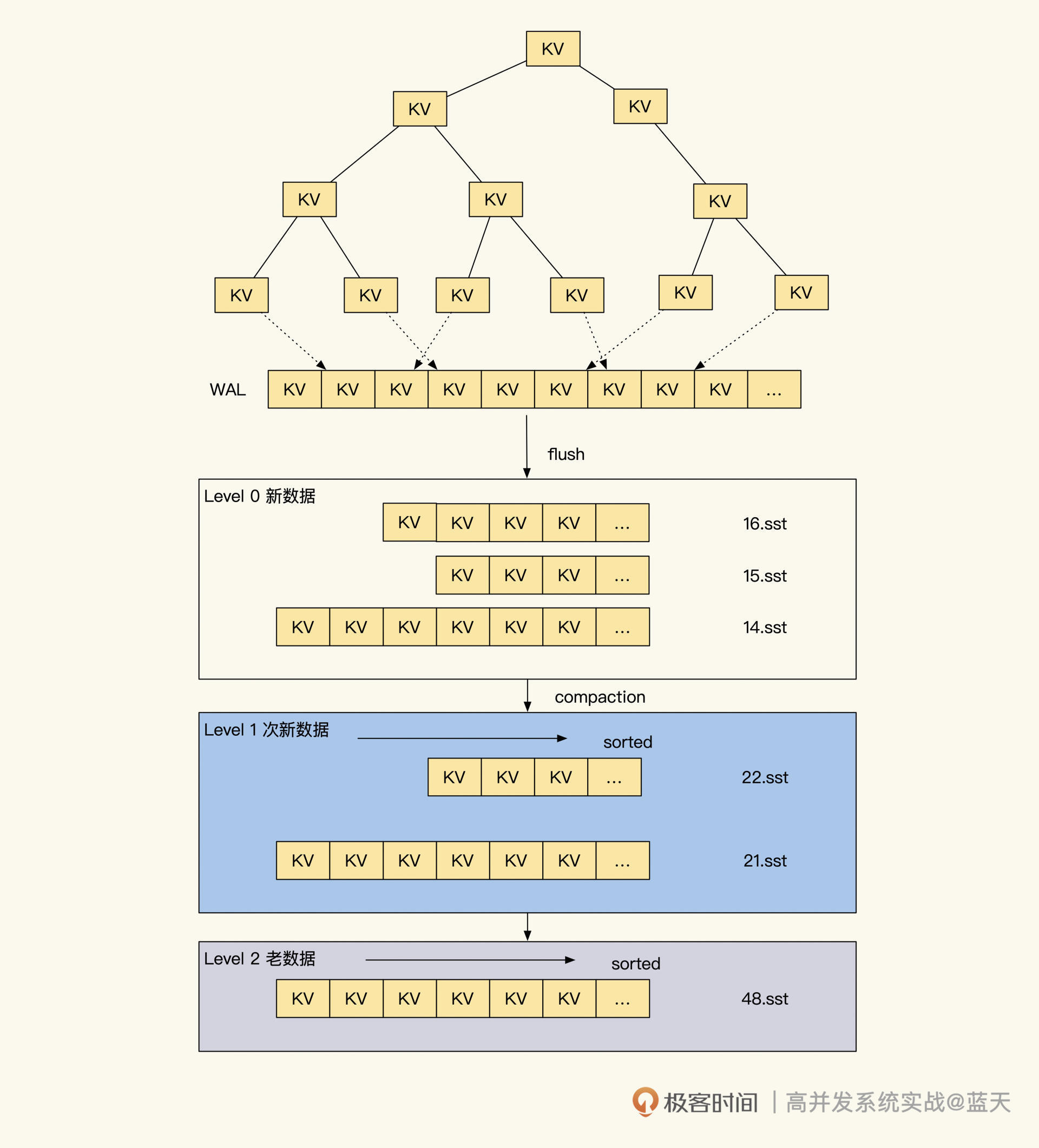
我们前面讲过,B+Tree 是一个大树,它是一个聚合的完整整体,任何数据的增删改都是在这个整体内进行操作,这就导致了大量的随机读写 IO。
RocksDB LSM 则不同,它是由一棵棵小树组成,当我们新数据写入时会在内存中暂存,这样能够获得非常大的写并发处理能力。而当内存中数据积累到一定程度后,会将内存中数据和索引做顺序写,落地形成一个数据块。
这个数据块内保存着一棵小树和具体的数据,新生成的数据块会保存在 Level 0 层(最大有几层可配置),Level 0 层会有多个类似的数据块文件。结构如下图所示:
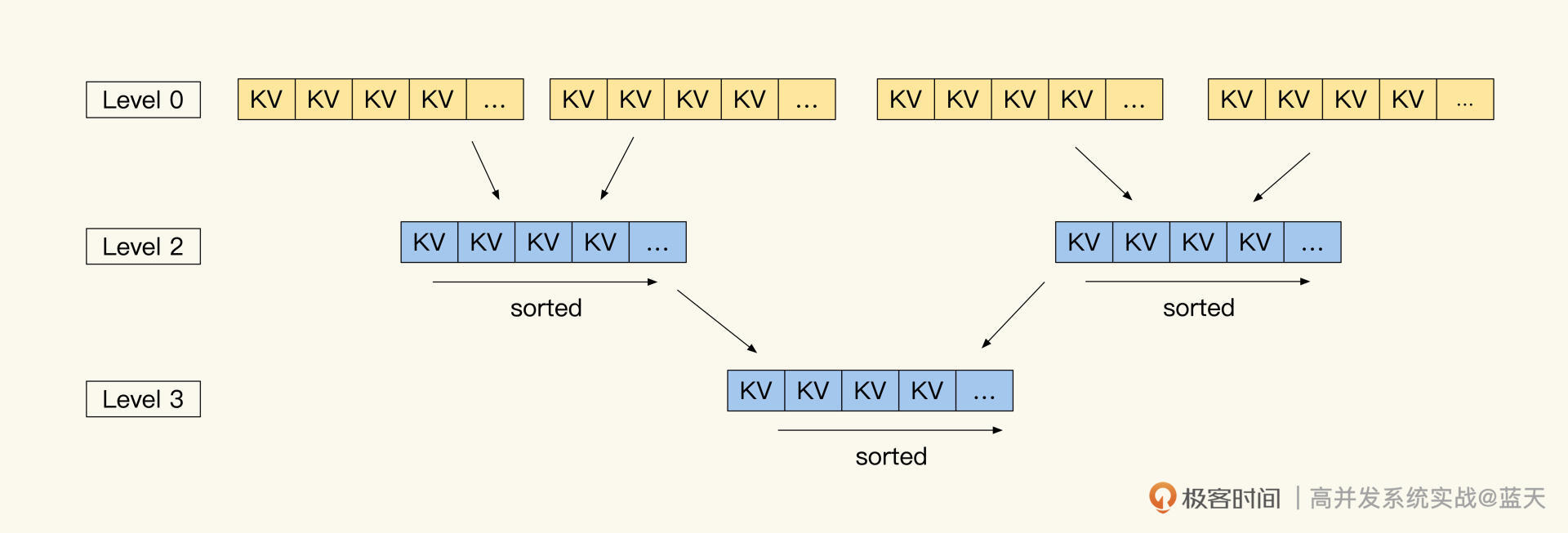
每一层的数据块和数据量超过一定程度时,RocksDB 合并不同 Level 的数据,将多个数据块内的数据和索引合并在一起,并推送到 Level 的下一层。通过这个方式,每一层的数据块个数和数据量就能保持一定的数量,合并后的数据会更紧密、更容易被找到。
这样的设计,可以让一个 Key 存在于多个 Level 或者数据块中,但是最新的常用的数据肯定是在 Level 最顶部或内存(0~4 层,0 为顶部)中最新的数据块内。
bloomfilter 能辅助确认数据的绝对没有
而当我们查询一个 key 的时候,RocksDB 会先查内存。如果没找到,会从 Level 0 层到下层,每层按生成最新到最老的顺序去查询每层的数据块。同时为了减少 IO 次数,每个数据块都会有一个 BloomFIlter 辅助索引,来辅助确认这个数据块中是否可能有对应的 Key;如果当前数据块没有,那么可以快速去找下一个数据块,直到找到为止。当然,最惨的情况是遍历所有数据块。
可以看到,这个方式虽然放弃了整体索引的一致性,却换来了更高效的写性能。在读取时通过遍历所有子树来查找,减少了写入时对树的合并代价。
LSM 这种方式的数据存储在 OLAP 数据库中很常用,因为 OLAP 多数属于写多读少,而当我们使用 OLAP 对外提供数据服务的时候,多数会通过缓存来帮助数据库承受更大的读取压力。
列存储数据库
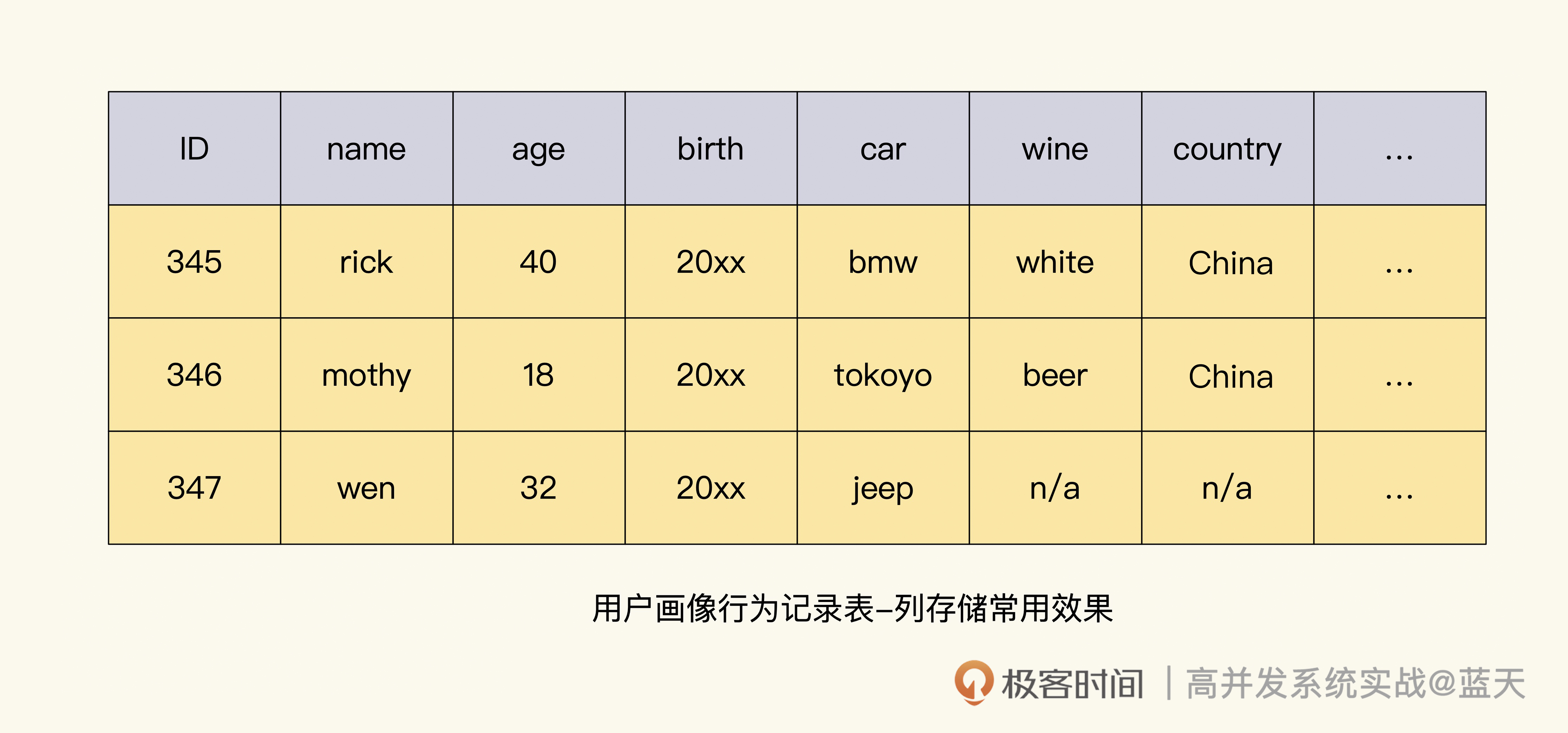
说到这里,不得不提 OLAP 数据库和 OLTP 数据之间的另一个区别。我们常用的关系型数据库,属于行式存储数据库 Row-based,表数据结构是什么样,它就会按表结构的字段顺序进行存储;而大数据挖掘使用的数据库普遍使用列式存储(Column-based),原因在于我们用关系数据库保存的多数是实体属性和实体关系,很多查询每一列都是不可或缺的。

但是,实时数据分析则相反,很多情况下常用一行表示一个用户或主要实体(聚合根),而列保存这个用户或主要实体是否买过某物、使用过什么 App、去过哪里、开什么车、点过什么食品、哪里人等等。
这样组织出来的数据,做数据挖掘、分析对比很方便,不过也会导致一个表有成百上千个字段,如果用行存储的数据引擎,我们对数据的筛选是一行行进行读取的,会浪费大量的 IO 读取。
而列存储引擎可以指定用什么字段读取所需字段的数据,并且这个方式能够充分利用到磁盘顺序读写的性能,大大提高这种列筛选式的查询,并且列方式更好进行数据压缩,在实时计算领域做数据统计分析的时候,表现会更好。
到了这里相信你已经发现,使用场景不同,数据底层的实现也需要不同的方式才能换来更好的性能和性价比。随着行业变得更加成熟,这些需求和特点会不断挖掘、总结、合并到我们的底层服务当中,逐渐降低我们的工作难度和工作量。
HTAP
通过前面的讲解,我么可以看到 OLAP 和 OLTP 数据库各有特点,并且有不同的发展方向,事实上它们对外提供的数据查询服务都是期望实时快速的,而不同在于如何存储和查找索引。
最近几年流行将两者结合成一套数据库集群服务,同时提供 OLAP 以及 OLTP 服务,并且相互不影响,实现行数据库与列数据库的互补。
2022 年国产数据库行业内 OceanBase、PolarDB 等云厂商提供的分布式数据库都在紧锣密鼓地开始支持 HTAP。这让我们可以保存同一份数据,根据不同查询的范围触发不同的引擎,共同对外提供数据服务。
可以看到,未来的某一天,我们的数据库既能快速地实时分析,又能快速提供业务数据服务。逐渐地,数据服务底层会出现多套存储、索引结构来帮助我们更方便地实现数据库。
而目前常见的 HTAP 实现方式,普遍采用一个服务集群内同一套数据支持多种数据存储方式(行存储、列存储),通过对数据提供不同的索引来实现 OLAP 及 OLTP 需求,而用户在查询时,可以指定或由数据库查询引擎根据 SQL 和数据情况,自动选择使用哪个引擎来优化查询。
总结
这节课,我们讨论了 OLAP 和 OLTP 数据库的索引、存储、数据量以及应用的不同场景。
OLAP 相对于关系数据库的数据存储量会更多,并且对于大量数据批量写入支持很好。很多情况下,高并发批量写数据很常见,其表的字段会更多,数据的存储多数是用列式方式存储,而数据的索引用的则是列索引,通过这些即可实现实时大数据计算结果的查询和分析。
相对于离线计算来说,这种方式更加快速方便,唯一的缺点在于这类服务都需要多台服务器做分布式,成本高昂。
可以看出,我们使用的场景不同决定了我们的数据底层如何去做更高效,HTAP 的出现,让我们在不同的场景中有了更多的选择,毕竟大数据挖掘是一个很庞大的数据管理体系,如果能有一个轻量级的 OLAP,会让我们的业务拥有更多的可能。
链路追踪:如何定制一个分布式链路跟踪系统 ?
分布式链路跟踪服务属于写多读少的服务,是我们线上排查问题的重要支撑。我经历过的一个系统,同时支持着多条业务线,实际用上的服务器有两百台左右,这种量级的系统想排查故障,难度可想而知。
因此,我结合 ELK 特性设计了一套十分简单的全量日志分布式链路跟踪,把日志串了起来,大大降低了系统排查难度。
目前市面上开源提供的分布式链路跟踪都很抽象,当业务复杂到一定程度的时候,为核心系统定制一个符合自己业务需要的链路跟踪,还是很有必要的。
事实上,实现一个分布式链路跟踪并不难,而是难在埋点、数据传输、存储、分析上,如果你的团队拥有这些能力,也可以很快制作出一个链路跟踪系统。所以下面我们一起看看,如何实现一个简单的定制化分布式链路跟踪。
监控行业发展现状
在学习如何制作一个简单的分布式链路跟踪之前,为了更好了解这个链路跟踪的设计特点,我们先简单了解一下监控行业的现状。
最近监控行业有一次大革新,现代的链路跟踪标准已经不拘泥于请求的链路跟踪,目前已经开始进行融合,新的标准和我们定制化的分布式链路跟踪的设计思路很相似,即 Trace、Metrics、日志合并成一套系统进行建设。
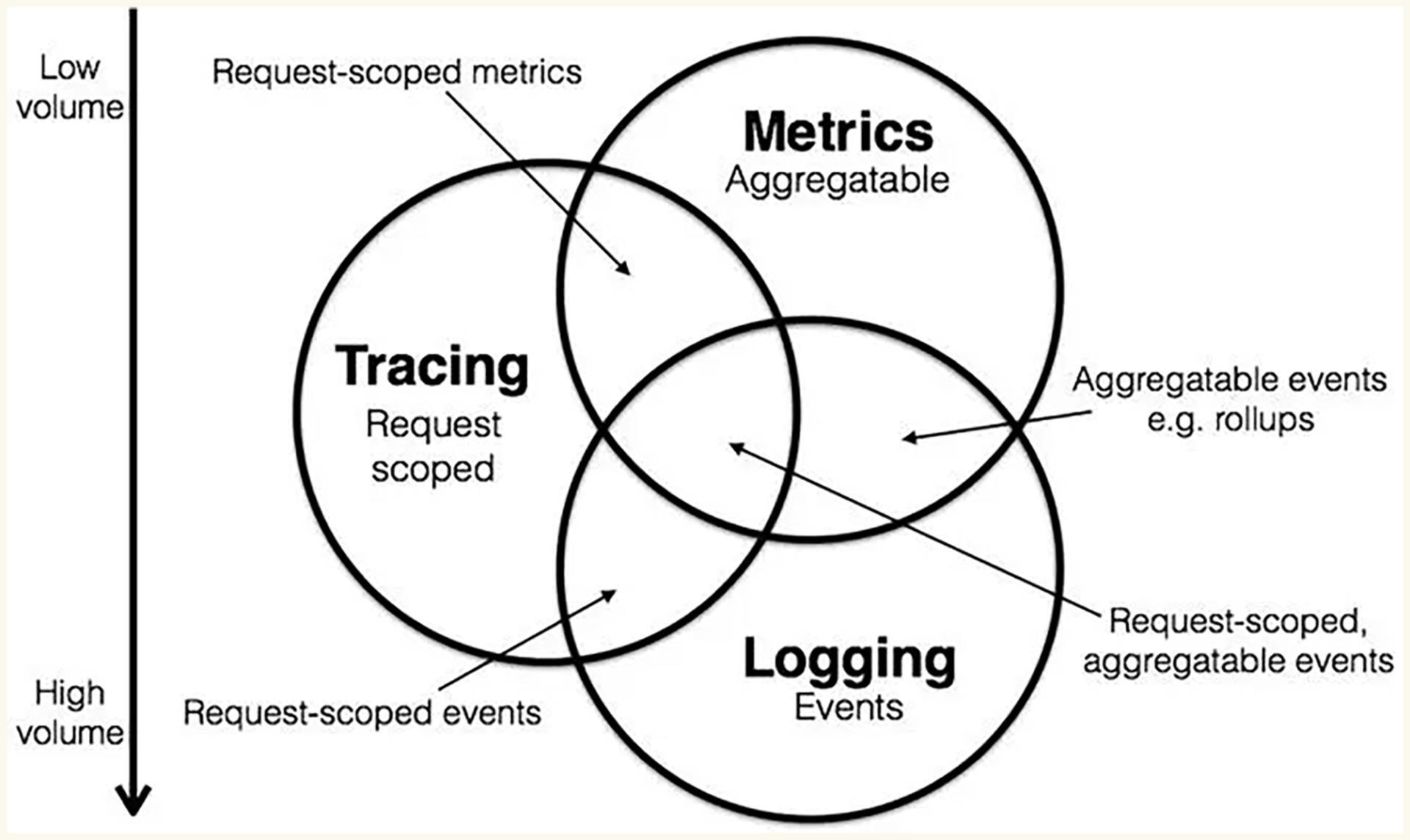
在此之前,常见监控系统主要有三种类型:Metrics、Tracing 和 Logging。
常见的开源 Metrics 有 Zabbix、Nagios、Prometheus、InfluxDb、OpenFalcon,主要做各种量化指标汇总统计,比如监控系统的容量剩余、每秒请求量、平均响应速度、某个时段请求量多少。
常见的开源链路跟踪有 **Jaeger、Zipkin、Pinpoint、Skywalking,**主要是通过分析每次请求链路监控分析的系统,我么可以通过 TraceID 查找一次请求的依赖及调用链路,分析故障点和传导过程的耗时。
Skywalking官方trace界面
kibana(ELK)官网,日志查找
而常见的开源 Logging 有 ELK、Loki、Loggly,主要是对文本日志的收集归类整理,可以对错误日志进行汇总、警告,并分析系统错误异常等情况。
这三种监控系统可以说是大服务集群监控的主要支柱,它们各有优点,但一直是分别建设的。这让我们的系统监控存在一些割裂和功能重复,而且每一个标准都需要独立建设一个系统,然后在不同界面对同一个故障进行分析,排查问题时十分不便。
随着行业发展,三位一体的标准应运而生,这就是 OpenTelemetry 标准(集成了 OpenCensus、OpenTracing 标准)。这个标准将 Metrics+Tracing+Logging 集成一体,这样我们监控系统的时候就可以通过三个维度综合观测系统运转情况。
常见 OpenTelemetry 开源项目中的 Prometheus、Jaeger 正在遵循这个标准逐步改进实现 OpenTelemetry 实现的结构如下图所示:
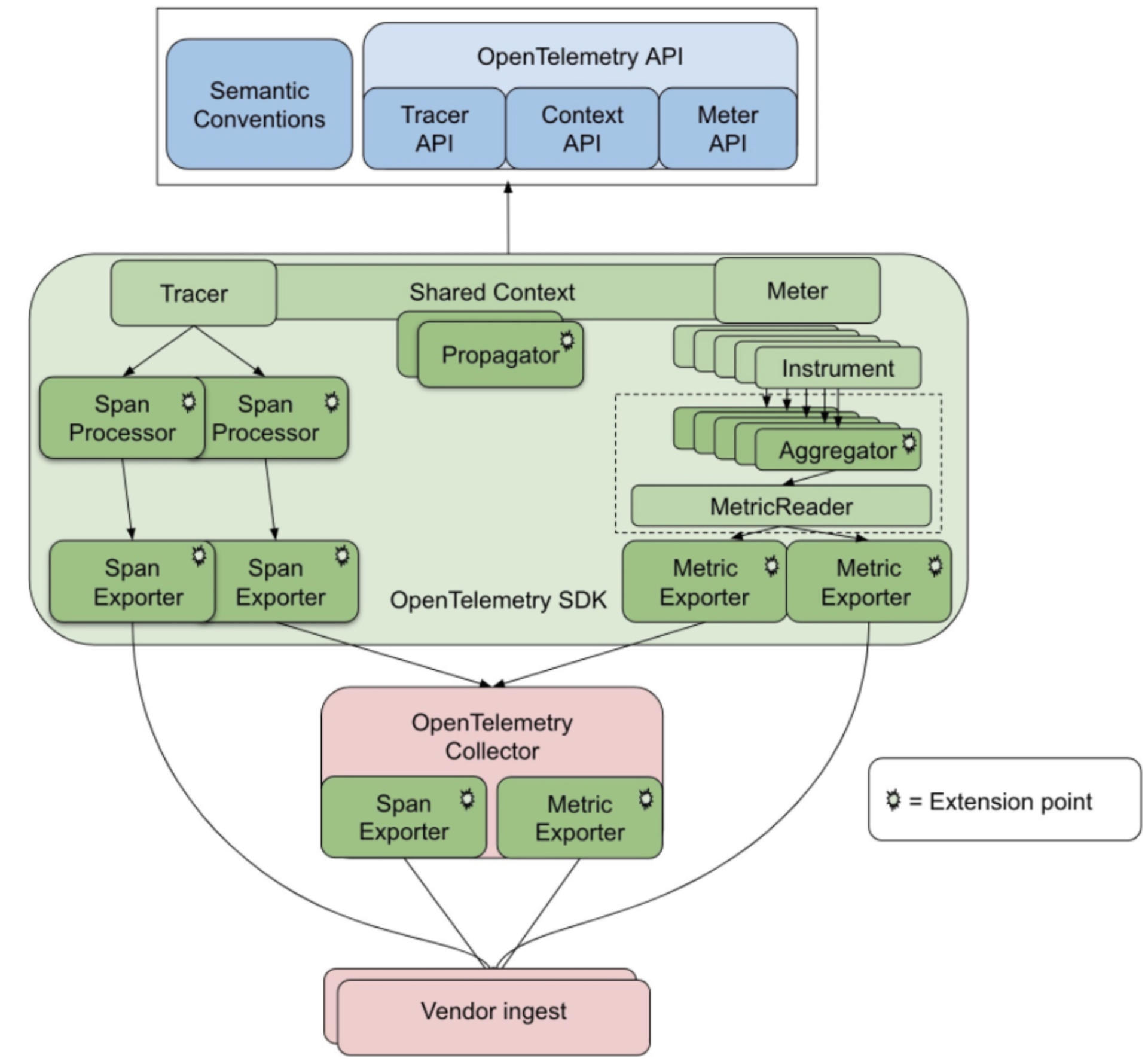
OpenTelemetry标准架构
事实上,分布式链路跟踪系统及监控主要提供了以下支撑服务:
- 监控日志标准
- 埋点 SDK(AOP 或侵入式)
- 日志收集
- 分布式日志传输
- 分布式日志存储
- 分布式检索计算
- 分布式实时分析
- 个性化定制指标盘
- 系统警告
我建议使用 ELK 提供的功能去实现分布式链路跟踪系统,因为它已经完整提供了如下功能:
- 日志收集(Filebeat)
- 日志传输(Kafka+Logstash)
- 日志存储(Elasticsearch)
- 检索计算(Elasticsearch + Kibana)
- 实时分析(Kibana)
- 个性定制表格查询(Kibana)
这样一来,我只需要制定日志格式、埋点 SDK,即可实现一个具有分布式链路跟踪、Metrics、日志分析系统。
事实上,Log、Metrics、trace 三种监控体系最大的区别就是日志格式标准,底层实现其实是很相似的。既然 ELK 已提供我们需要的分布式相关服务,下面我简单讲讲日志格式和 SDK 埋点,通过这两个点我们就可以窥见分布式链路跟踪的全貌。
TraceID 单次请求标识
可以说,要想构建一个简单的 Trace 系统,我们首先要做的就是生成并传递 TraceID。
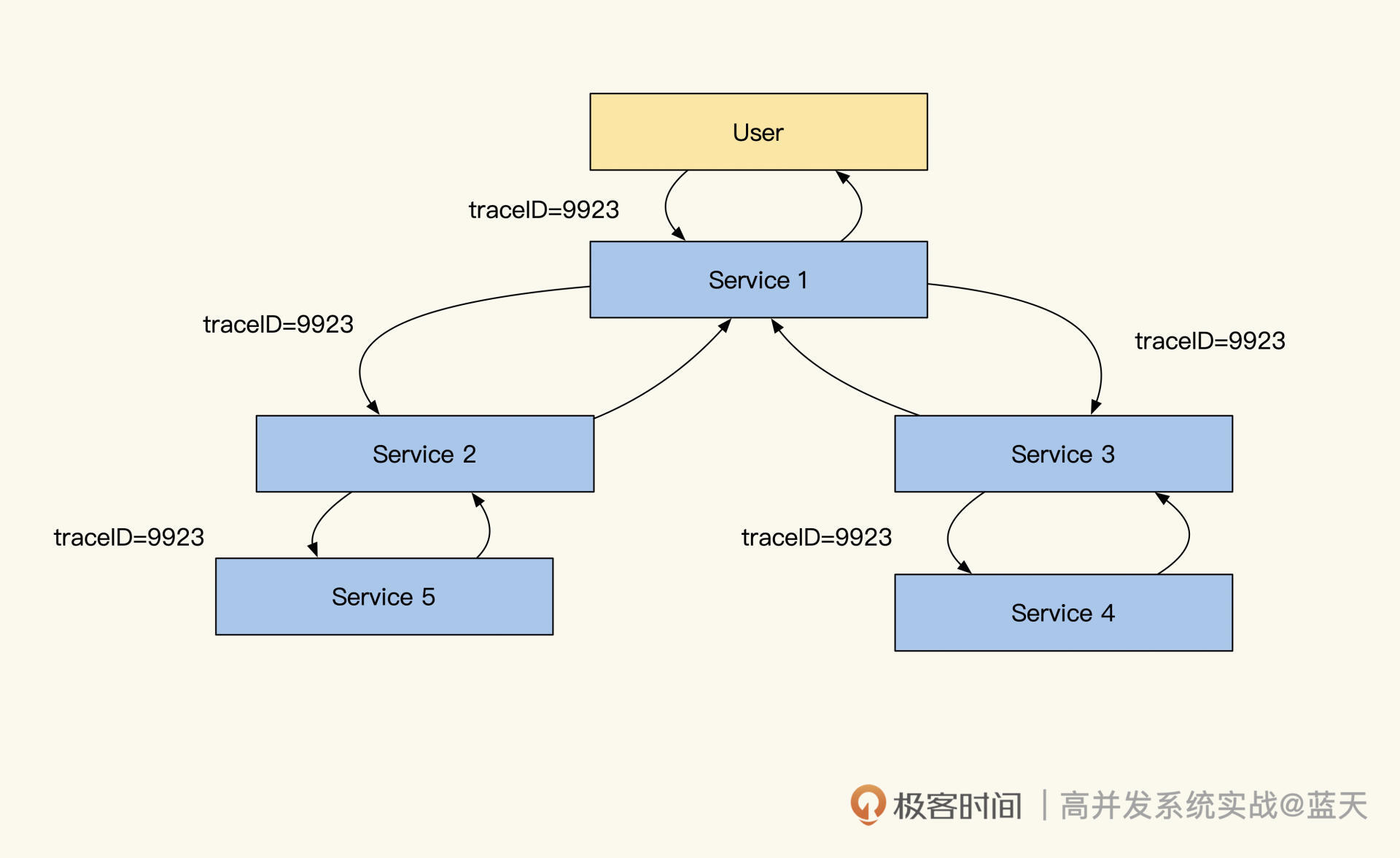
TraceID在各个服务中的传递
分布式链路跟踪的原理其实很简单,就是在请求发起方发送请求时或服务被请求时生成一个 UUID,被请求期间的业务产生的任何日志(Warning、Info、Debug、Error)、任何依赖资源请求(MySQL、Kafka、Redis)、任何内部接口调用(Restful、Http、RPC)都会带上这个 UUID。
这样,当我们把所有拥有同样 UUID 的日志收集起来时,就可以根据时间(有误差)、RPCID(后续会介绍 RPCID)或 SpanID,将它们按依赖请求顺序串起来。
只要日志足够详细,我们就能监控到系统大部分的工作状态,比如用户请求一个服务会调用多少个接口,每个数据查询的 SQL 以及具体耗时调用的内网请求参数是什么、调用的内网请求返回是什么、内网被请求的接口又做了哪些操作、产生了哪些异常信息等等。
同时,我们可以通过对这些日志做归类分析,分析项目之间的调用关系、项目整体健康程度、对链路深挖自动识别出故障点等,帮助我们主动、快速地查找问题。
“RPCID” VS “SpanID 链路标识”
那么如何将汇总起来的日志串联起来呢?有两种方式:span(链式记录依赖)和 RPCID(层级计数器)。我们在记录日志带上 UUID 的同时,也带上 RPCID 这个信息,通过它帮我们把日志关联关系串联起来,那么这两种方式有什么区别呢?
我们先看看 span 实现,具体如下图:
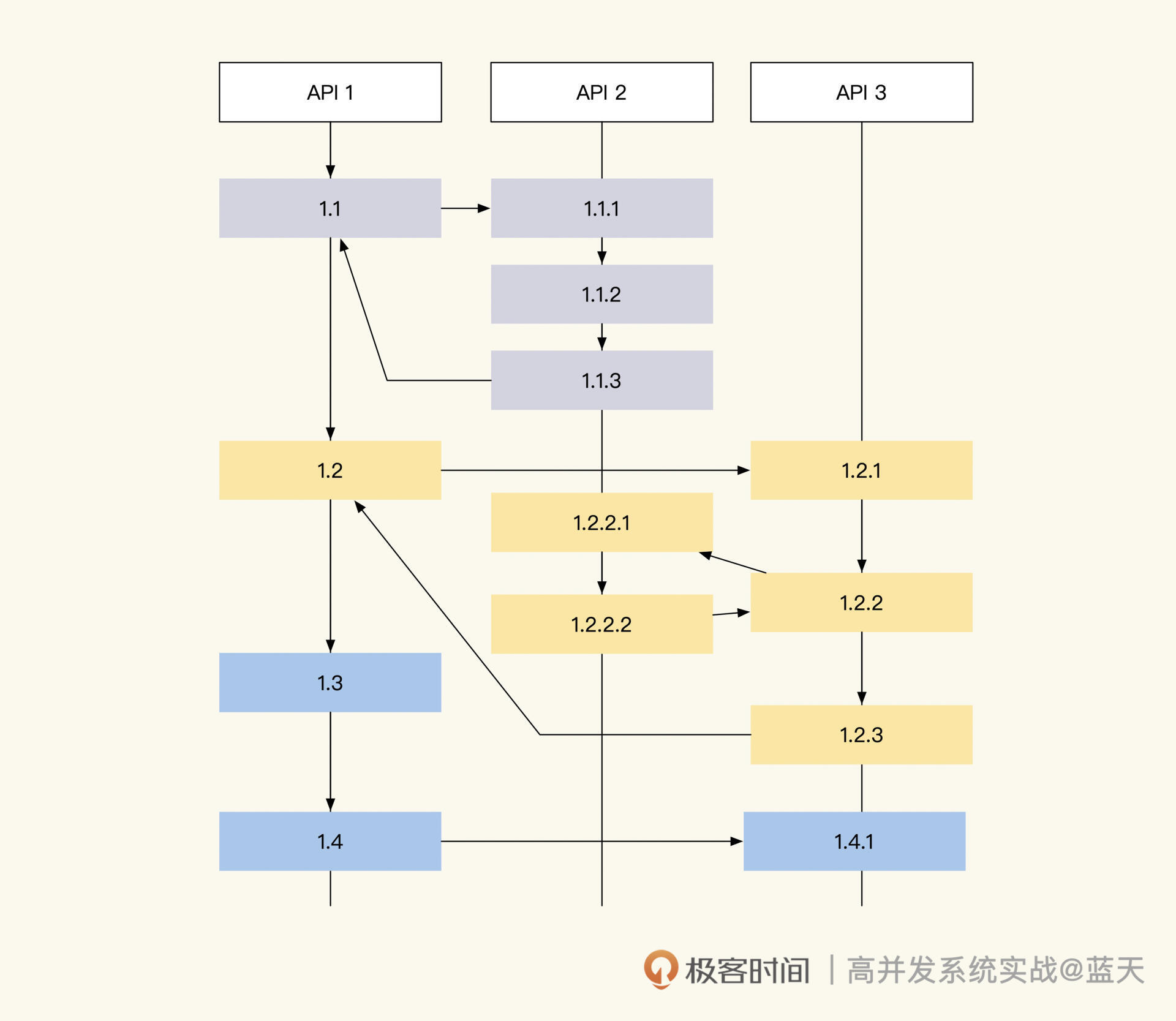
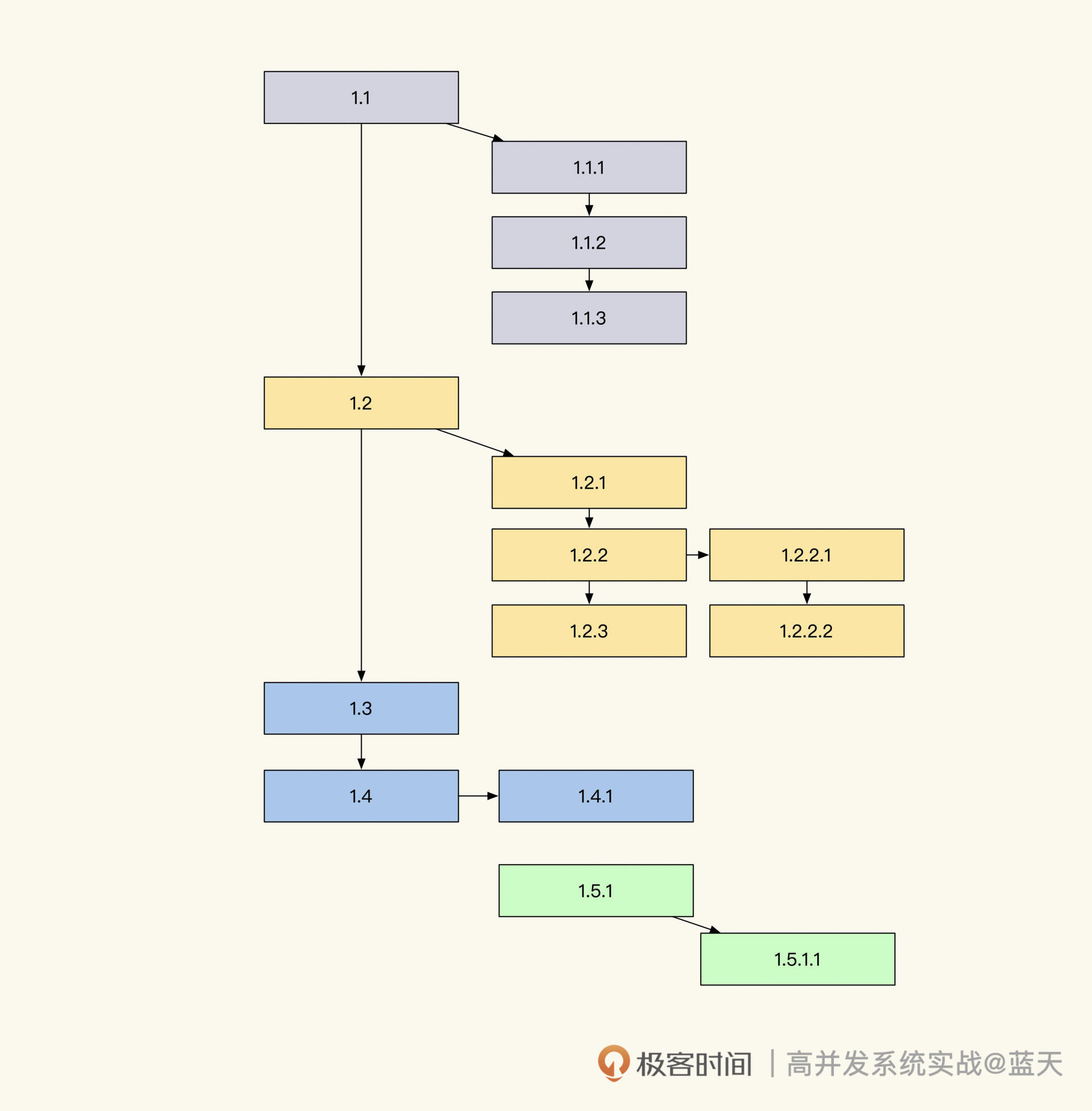
结合上图,我们分析一下 span 的链式依赖记录方式。对于代码来说,写的很多功能会被封装成功能模块(Service、Model),我们通过组合不同的模块实现业务功能,并且记录这两个模块、两个服务间或是资源的调用依赖关系。
span 这个设计会通过记录自己上游依赖服务的 SpanID 实现上下游关系关联(放在 Parent ID 中),通过整理 span 之间的依赖关系就能组合成一个调用链路树。
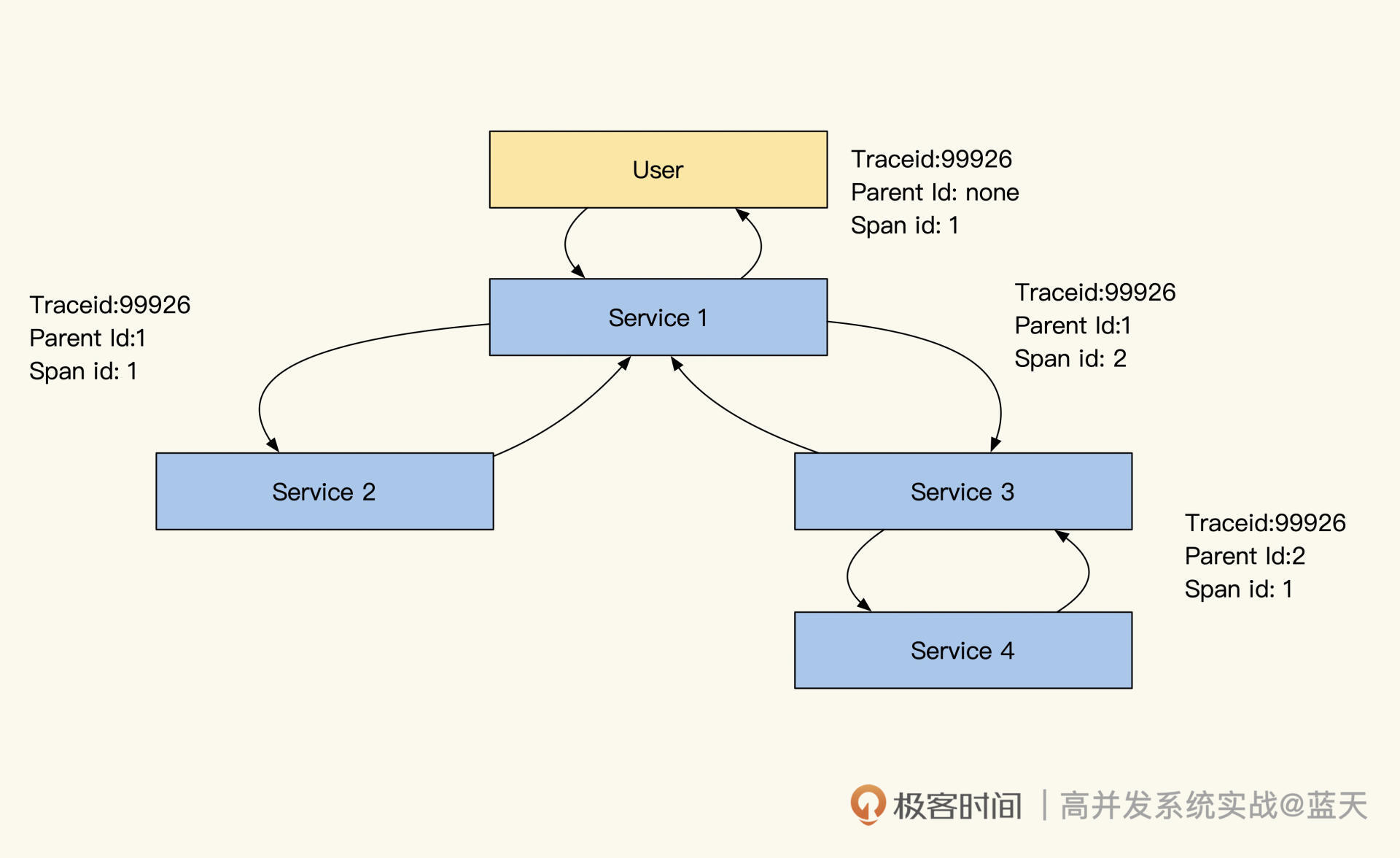
那 RPCID 方式是什么样的呢?RPCID 也叫层级计数器,我在微博和好未来时都用过,为了方便理解,我们来看下面这张图:
RPCID层级依赖计数器
你看,RPCID 的层级计数器实现很简单,第一个接口生成 RPCID 为 1.1 ,RPCID 的前缀是 1,计数器是 1(日志记录为 1.1)。
当所在接口请求其他接口或数据服务(MySQL、Redis、API、Kafka)时,计数器+1,并在请求当中带上 1.2 这个数值(因为当前的前缀 + “.” + 计数器值 = 1.2),等到返回结果后,继续请求下一个资源时继续 +1,期间产生的任何日志都会记录当前 前缀+“.”+计数器值。
每一层收到了前缀后,都在后面加了一个累加的计数器,实际效果如下图所示:
而被请求的接口收到请求时,如果请求传递了 TraceID,那么被请求的服务会继续使用传递过来的 TraceID,如果请求没有 TraceID 则自己生成一个。同样地,如果传递了 RPCID,那么被请求的服务会将传递来的 RPCID 当作前缀,计数器从 1 开始计数。
相对于 span,通过这个层级计数器做出来的 RPCID 有两个优点。
第一个优点是我们可以记录请求方日志,如果被请求方没有记录日志,那么还可以通过请求方日志观测分析被调用方性能(MySQL、Redis)。
另一个优点是哪怕日志收集得不全,丢失了一些,我们还可以通过前缀有几个分隔符,判断出日志所在层级进行渲染。举个例子,假设我们不知道上图的 1.5.1 是谁调用的,但是根据它的 UUID 和层级 1.5.1 这些信息,渲染的时候,我们仍旧可以渲染它大概的链路位置。
除此之外,我们可以利用 AOP 顺便将各个模块做一个 Metrics 性能统计分析,分析各个模块的耗时、调用次数做周期统计。
同时,通过这个维度采样统计数据,能够帮助我们分析这个模块的性能和错误率。由于 Metrics 这个方式产生的日志量很小,有些统计是每 10 秒才会产生一条 Metrics 统计日志,统计的数值很方便对比,很有参考价值。
但是你要注意,对于一个模块内有多个分支逻辑时,Metrics 很多时候取的是平均数,偶发的超时在平均数上看不出来,所以我们需要另外记录一下最大最小的延迟,才可以更好地展现。同时,这种统计只是让我们知道这个模块是否有性能问题,但是无法帮助我们分析具体的原因。
回到之前的话题,我们前面提到,请求和被请求方通过传递 TraceID 和 RPCID(或 SpanID)来实现链路的跟踪,我列举几个常见的方式供你参考:
- HTTP 协议放在 Header;
- RPC 协议放在 meta 中传递;
- 队列可以放在消息体的 Header 中,或直接在消息体中传递;
- 其他特殊情况下可以通过网址请求参数传递。
那么应用内多线程和多协程之间如何传递 TraceID 呢?一般来说,我们会通过复制一份 Context 传递进入线程或协程,并且如果它们之前是并行关系,我们复制之后需要对下发之前的 RPCID 计数器加 1,并把前缀和计数器合并成新的前缀,以此区分并行的链路。
除此之外,我们还做了一些特殊设计,当我们的请求中带一个特殊的密语,并且设置类似 X-DEBUG Header 等于 1 时,我们可以开启在线 debug 模式,在被调用接口及所有依赖的服务都会输出 debug 级别的日志,这样我们临时排查线上问题会更方便。
日志类型定义
可以说,只要让日志输出当前的 TraceId 和 RPCID(SpanID),并在请求所有依赖资源时把计数传递给它们,就完成了大部分的分布式链路跟踪。下面是我定制的一些日志类型和日志格式,供你参考:
## 日志类型* request.info 当前被请求接口的相关信息,如被请求接口,耗时,参数,返回值,客户端信息
* mysql.connect mysql连接时长
* mysql.connect.error mysql链接错误信息
* mysql.request mysql执行查询命令时长及相关信息
* mysql.request.error mysql操作时报错的相关信息
* redis.connect redis 链接时长
* redis.connect.error redis链接错误信息
* redis.request redis执行命令
* redis.request.error redis操作时错误
* memcache.connect
* memcache.connect.error
* memcache.request.error
* http.get 另外可以支持restful操作get put delete
* http.post
* http.*.error## Metric日志类型* metric.counter
...略## 分级日志类型
* log.debug: debug log
* log.trace: trace log
* log.notice: notice log
* log.info: info log
* log.error: application error log
* log.alarm: alarm log
* log.exception: exception log
你会发现,所有对依赖资源的请求都有相关日志,这样可以帮助我们分析所有依赖资源的耗时及返回内容。此外,我们的分级日志也在 trace 跟踪范围内,通过日志信息可以更好地分析问题。而且,如果我们监控的是静态语言,还可以像之前说的那样,对一些模块做 Metrics,定期产生日志。
日志格式样例
日志建议使用 JSON 格式,所有字段除了标注为 string 的都建议保存为字符串类型,每个字段必须是固定数据类型,选填内容如果没有内容就直接不输出。
这样设计其实是为了适配 Elasticsearch+Kibana,Kibana 提供了日志的聚合、检索、条件检索和数值聚合,但是对字段格式很敏感,不是数值类型就无法聚合对比。
下面我给你举一个例子用于链路跟踪和监控,你主要关注它的类型和字段用途。
{"name": "string:全量字段介绍,必填,用于区分日志类型,上面的日志列表内容写这里","trace_id": "string:traceid,必填","rpc_id": "string:RPCID,服务端链路必填,客户端非必填","department":"部门缩写如client_frontend 必填","version": "string:当前服务版本 cpp-client-1.1 php-baseserver-1.4 java-rti-1.9,建议都填","timestamp": "int:日志记录时间,单位秒,必填","duration": "float:消耗时间,浮点数 单位秒,能填就填","module": "string:模块路径,建议格式应用名称_模块名称_函数名称_动作,必填","source": "string:请求来源 如果是网页可以记录ref page,选填","uid": "string:当前用户uid,如果没有则填写为 0长度字符串,可选填,能够帮助分析用户一段时间行为","pid": "string:进程pid,如果没有填写为 0长度字符串,如果有线程可以为pid-tid格式,可选填","server_ip": "string 当前服务器ip,必填","client_ip": "string 客户端ip,选填","user_agent": "string curl/7.29.0 选填","host": "string 链接目标的ip及端口号,用于区分环境12.123.23.1:3306,选填","instance_name": "string 数据库连接配置的标识,比如rti的数据库连接,选填","db": "string 数据库名称如:peiyou_stastic,选填","code": "string:各种驱动或错误或服务的错误码,选填,报错误必填","msg": "string 错误信息或其他提示信息,选填,报错误必填","backtrace": "string 错误的backtrace信息,选填,报错误必填","action": "string 可以是url、sql、redis命令、所有让远程执行的命令,必填","param": "string 通用参数模板,用于和script配合,记录所有请求参数,必填","file": "string userinfo.php,选填","line": "string 232,选填","response": "string:请求返回的结果,可以是本接口或其他资源返回的数据,如果数据太长会影响性能,选填","response_length": "int:相应内容结果的长度,选填","dns_duration": "float dns解析时间,一般http mysql请求域名的时候会出现此选项,选填","extra": "json 放什么都可以,用户所有附加数据都扔这里"
}## 样例
被请求日志
{"x_name": "request.info","x_trace_id": "123jiojfdsao","x_rpc_id": "0.1","x_version": "php-baseserver-4.0","x_department":"tal_client_frontend","x_timestamp": 1506480162,"x_duration": 0.021,"x_uid": "9527","x_pid": "123","x_module": "js_game1_start","x_user_agent": "string curl/7.29.0","x_action": "http://testapi.speiyou.com/v3/user/getinfo?id=9527","x_server_ip": "192.168.1.1:80","x_client_ip": "192.168.1.123","x_param": "json string","x_source": "www.baidu.com","x_code": "200","x_response": "json:api result","x_response_len": 12324
}### mysql 链接性能日志
{"x_name": "mysql.connect","x_trace_id": "123jiojfdsao","x_rpc_id": "0.2","x_version": "php-baseserver-4","x_department":"tal_client_frontend","x_timestamp": 1506480162,"x_duration": 0.024,"x_uid": "9527","x_pid": "123","x_module": "js_mysql_connect","x_instance_name": "default","x_host": "12.123.23.1:3306","x_db": "tal_game_round","x_msg": "ok","x_code": "1","x_response": "json:****"
}### Mysql 请求日志
{"x_name": "mysql.request","x_trace_id": "123jiojfdsao","x_rpc_id": "0.2","x_version": "php-4","x_department":"tal_client_frontend","x_timestamp": 1506480162,"x_duration": 0.024,"x_uid": "9527","x_pid": "123","x_module": "js_game1_round_sigup","x_instance_name": "default","x_host": "12.123.23.1:3306","x_db": "tal_game_round","x_action": "select * from xxx where xxxx","x_param": "json string","x_code": "1","x_msg": "ok","x_response": "json:****"
}### http 请求日志
{"x_name": "http.post","x_trace_id": "123jiojfdsao","x_department":"tal_client_frontend","x_rpc_id": "0.3","x_version": "php-4","x_timestamp": 1506480162,"x_duration": 0.214,"x_uid": "9527","x_pid": "123","x_module": "js_game1_round_win_report","x_action": "http://testapi.speiyou.com/v3/game/report","x_param": "json:","x_server_ip": "192.168.1.1","x_msg": "ok","x_code": "200","x_response_len": 12324,"x_response": "json:responsexxxx","x_dns_duration": 0.001
}### level log info日志
{"x_name": "log.info","x_trace_id": "123jiojfdsao","x_department":"tal_client_frontend","x_rpc_id": "0.3","x_version": "php-4","x_timestamp": 1506480162,"x_duration": 0.214,"x_uid": "9527","x_pid": "123","x_module": "game1_round_win_round_end","x_file": "userinfo.php","x_line": "232","x_msg": "ok","x_code": "201","extra": "json game_id lesson_num xxxxx"
}### exception 异常日志
{"x_name": "log.exception","x_trace_id": "123jiojfdsao","x_department":"tal_client_frontend","x_rpc_id": "0.3","x_version": "php-4","x_timestamp": 1506480162,"x_duration": 0.214,"x_uid": "9527","x_pid": "123","x_module": "game1_round_win","x_file": "userinfo.php","x_line": "232","x_msg": "exception:xxxxx call stack","x_code": "hy20001","x_backtrace": "xxxxx.php(123) gotError:..."
}### 业务自发告警日志
{"x_name": "log.alarm","x_trace_id": "123jiojfdsao","x_department":"tal_client_frontend","x_rpc_id": "0.3","x_version": "php-4","x_timestamp": 1506480162,"x_duration": 0.214,"x_uid": "9527","x_pid": "123","x_module": "game1_round_win_round_report","x_file": "game_win_notify.php","x_line": "123","x_msg": "game report request fail! retryed three time..","x_code": "201","x_extra": "json game_id lesson_num xxxxx"
}### matrics 计数器{"x_name": "metrix.count","x_trace_id": "123jiojfdsao","x_department":"tal_client_frontend","x_rpc_id": "0.3","x_version": "php-4","x_timestamp": 1506480162,"x_uid": "9527","x_pid": "123","x_module": "game1_round_win_click","x_extra": "json curl invoke count"
}
这个日志不仅可以用在服务端,还可以用在客户端。客户端每次被点击或被触发时,都可以自行生成一个新的 TraceID,在请求服务端时就会带上它。通过这个日志,我们可以分析不同地域访问服务的性能,也可以用作用户行为日志,仅仅需添加我们的日志类型即可。
上面的日志例子基本把我们依赖的资源情况描述得很清楚了。另外,我补充一个技巧,性能记录日志可以将被请求的接口也记录成一个日志,记录自己的耗时等信息,方便之后跟请求方的请求日志对照,这样可分析出两者之间是否有网络延迟等问题。
除此之外,这个设计还有一个核心要点:研发并不一定完全遵守如上字段规则生成日志,业务只要保证项目范围内输出的日志输出所有必填项目(TraceID,RPCID/SpanID,TimeStamp),同时保证数值型字段功能及类型稳定,即可实现 trace。
我们完全可以汇总日志后,再对不同的日志字段做自行解释,定制出不同业务所需的统计分析,这正是 ELK 最强大的地方。
为什么大部分设计都是记录依赖资源的日志呢?原因在于在没有 IO 的情况下,程序大部分都是可控的(侧重计算的服务除外)。只有 IO 类操作容易出现不稳定因素,并且日志记录过多也会影响系统性能,通过记录对数据源的操作能帮助我们排查业务逻辑的错误。
我们刚才提到日志如果过多会影响接口性能,那如何提高日志的写吞吐能力呢?这里我为你归纳了几个注意事项和技巧:
- 提高写线程的个数,一个线程写一个日志,也可以每个日志文件单独放一个磁盘,但是你要注意控制系统的 IOPS 不要超过 100;
- 当写入日志长度超过 1kb 时,不要使用多个线程高并发写同一个文件。原因参考 append is not Atomic,简单来说就是文件的 append 操作对于写入长度超过缓冲区长度的操作不是原子性的,多线程并发写长内容到同一个文件,会导致日志乱序;
- 日志可以通过内存暂存,汇总达到一定数据量或缓存超过 2 秒后再落盘,这样可以减少过小日志写磁盘系统的调用次数,但是代价是被强杀时会丢日志;
- 日志缓存要提前 malloc 使用固定长度缓存,不要频繁分配回收,否则会导致系统整体缓慢;
- 服务被 kill 时,记得拦截信号,快速 fsync 内存中日志到磁盘,以此减少日志丢失的可能。
“侵入式埋点 SDK”VS“AOP 方式埋点”
最后,我们再说说 SDK。事实上,使用“ELK+ 自定义的标准”基本上已经能实现大多数的分布式链路跟踪系统,使用 Kibana 可以很快速地对各种日志进行聚合分析统计。
虽然行业中出现过很多链路跟踪系统服务公司,做了很多 APM 等类似产品,但是能真正推广开的服务实际占少数,究其原因,我认为是以下几点:
- 分布式链路跟踪的日志吞吐很大,需要耗费大量的资源,成本高昂;
- 通用分布式链路跟踪服务很难做贴近业务的个性化,不能定制的第三方服务不如用开源;
- 分布式链路跟踪的埋点库对代码的侵入性大,需要研发手动植入到业务代码里,操作很麻烦,而且不够灵活。
- 另外,这种做法对语言也有相关的限制,因为目前只有 Java 通过动态启动注入 agent,才实现了静态语言 AOP 注入。我之前推广时,也是统一了内网项目的开源框架,才实现了统一的链路跟踪。
那么如果底层代码不能更新,如何简单暴力地实现链路跟踪呢?
这时候我们可以改造分级日志,让它每次在落地的时候都把 TraceId 和 RPCID(或 SpanID)带上,就会有很好的效果。如果数据底层做了良好的封装,我们可以在发起请求部分中写一些符合标准性能的日志,在框架的统一异常处理中也注入我们的标准跟踪,即可实现关键点的监控。
当然如果条件允许,我们最好提供一个标准的 SDK,让业务研发伙伴按需调用,这能帮助我们统一日志结构。毕竟手写很容易格式错乱,需要人工梳理,不过即使混乱,也仍旧有规律可言,这是 ELK 架构的强大之处,它的全文检索功能其实不在乎你的输入格式,但是数据统计类却需要我们确保各个字段用途固定。
最后再讲点其他日志的注意事项,可能你已经注意到了,这个设计日志是全量的。很多链路跟踪其实都是做的采样方式,比如 Jaeger 在应用本地会部署一个 Agent,对数据暂存汇总,统计出每个接口的平均响应时间,对具有同样特征的请求进行归类汇总,这样可以大大降低服务端压力。
但这么做也有缺点,当我们有一些小概率的业务逻辑错误,在采样中会被遗漏。所以很多核心系统会记录全量日志,周边业务记录采样日志。
由于我们日志结构很简单,如有需要可以自行实现一个类似 Agent 的功能,降低我们存储计算压力。甚至我们可以在服务端本地保存原始日志 7 天,当我们查找某个 Trace 日志的时候,直接请求所有服务器在本地查找。事实上,在写多读少的情况下,为了追一个 Trace 详细过程而去请求 200 个服务器,这时候即使等十秒钟都是可以接受的。
总结
系统监控一直是服务端重点关注的功能,我们常常会根据链路跟踪和过程日志,去分析排查线上问题。也就是说,监控越是贴近业务、越定制化,我们对线上业务运转情况的了解就越直观。
不过,实现一个更符合业务的监控系统并不容易,因为基础运维监控只会监控线上请求流量、响应速度、系统报错、系统资源等基础监控指标,当我们要监控业务时,还需要人工在业务系统中嵌入大量代码。而且,因为这些服务属于开源,还要求我们必须对监控有较深的了解,投入大量精力才可以。
好在技术逐渐成熟,通用的简单日志传输索引统计服务开始流行,其中最强的组合就是 ELK。通过这类分布式日志技术,能让我们轻松实现个性化监控需求。日志格式很杂乱也没关系,只要将 TraceID 和 RPCID(或 SpanID)在请求依赖资源时传递下去,并将沿途的日志都记录对应的字段即可。也正因如此,ELK 流行起来,很多公司的核心业务,都会依托 ELK 自定义一套自己的监控系统。
不过这么做,只能让我们建立起一个粗旷的跟踪系统,后续分析的难度和投入成本依然很大,因为 ELK 需要投入大量硬件资源来帮我们处理海量数据.
引擎分片:Elasticsearch如何实现大数据检索?
为什么 ELK 功能这么强大?这需要我们了解 ELK 中储存、索引等关键技术点的架构实现才能想清楚。相信你学完今天的内容,你对大数据分布式的核心实现以及大数据分布式统计服务,都会有更深入的理解。
Elasticsearch 架构
我们先分析分析 ELK 的架构长什么样,事实上,它和 OLAP 及 OLTP 的实现区别很大,我们一起来看看。Elasticsearch 架构如下图:
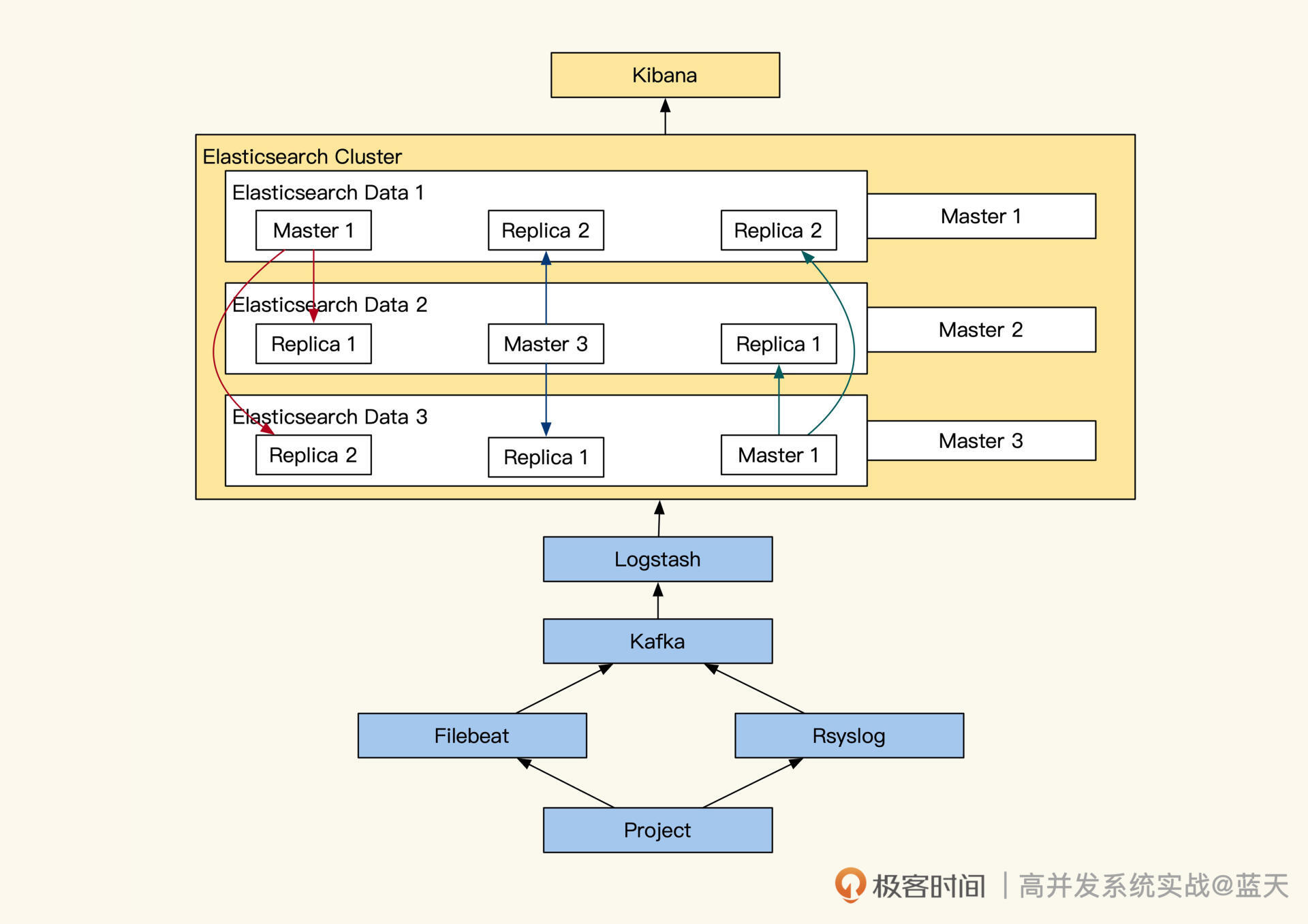
整体的数据流向图
我们对照架构图,梳理一下整体的数据流向,可以看到,我们项目产生的日志,会通过 Filebeat 或 Rsyslog 收集将日志推送到 Kafka 内。然后由 LogStash 消费 Kafka 内的日志、对日志进行整理,并推送到 ElasticSearch 集群内。
接着,日志会被分词,然后计算出在文档的权重后,放入索引中供查询检索, Elasticsearch 会将这些信息推送到不同的分片。每个分片都会有多个副本,数据写入时,只有大部分副本写入成功了,主分片才会对索引进行落地(需要你回忆下分布式写一致知识)。
Elasticsearch 集群中服务分多个角色,我带你简单了解一下:
- Master 节点:负责集群内调度决策,集群状态、节点信息、索引映射、分片信息、路由信息,Master 真正主节点是通过选举诞生的,一般一个集群内至少要有三个 Master 可竞选成员,防止主节点损坏(回忆下之前 Raft 知识,不过 Elasticsearch 刚出那会儿还没有 Raft 标准)。
- Data 存储节点:用于存储数据及计算,分片的主从副本,热点节点,冷数据节点;
- Client 协调节点:协调多个副本数据查询服务,聚合各个副本的返回结果,返回给客户端;
- Kibana 计算节点:作用是实时统计分析、聚合分析统计数据、图形聚合展示。
实际安装生产环境时,Elasticsearch 最少需要三台服务器,三台中有一台会成为 Master 节点负责调配集群内索引及资源的分配,而另外两个节点会用于 Data 数据存储、数据检索计算,当 Master 出现故障时,子节点会选出一个替代故障的 Master 节点(回忆下分布式共识算法中的选举)。
如果我们的硬件资源充裕,我们可以另外增加一台服务器将 Kibana 计算独立部署,这样会获得更好的数据统计分析性能。如果我们的日志写入过慢,可以再加一台服务器用于 Logstash 分词,协助加快 ELK 整体入库的速度。
要知道最近这几年大部分云厂商提供的日志服务都是基于 ELK 实现的,Elasticsearch 已经上市,可见其市场价值。
Elasticsearch 的写存储机制
下图是 Elasticsearch 的索引存储具体的结构,看起来很庞大,但是别担心,我们只需要关注分片及索引部分即可:
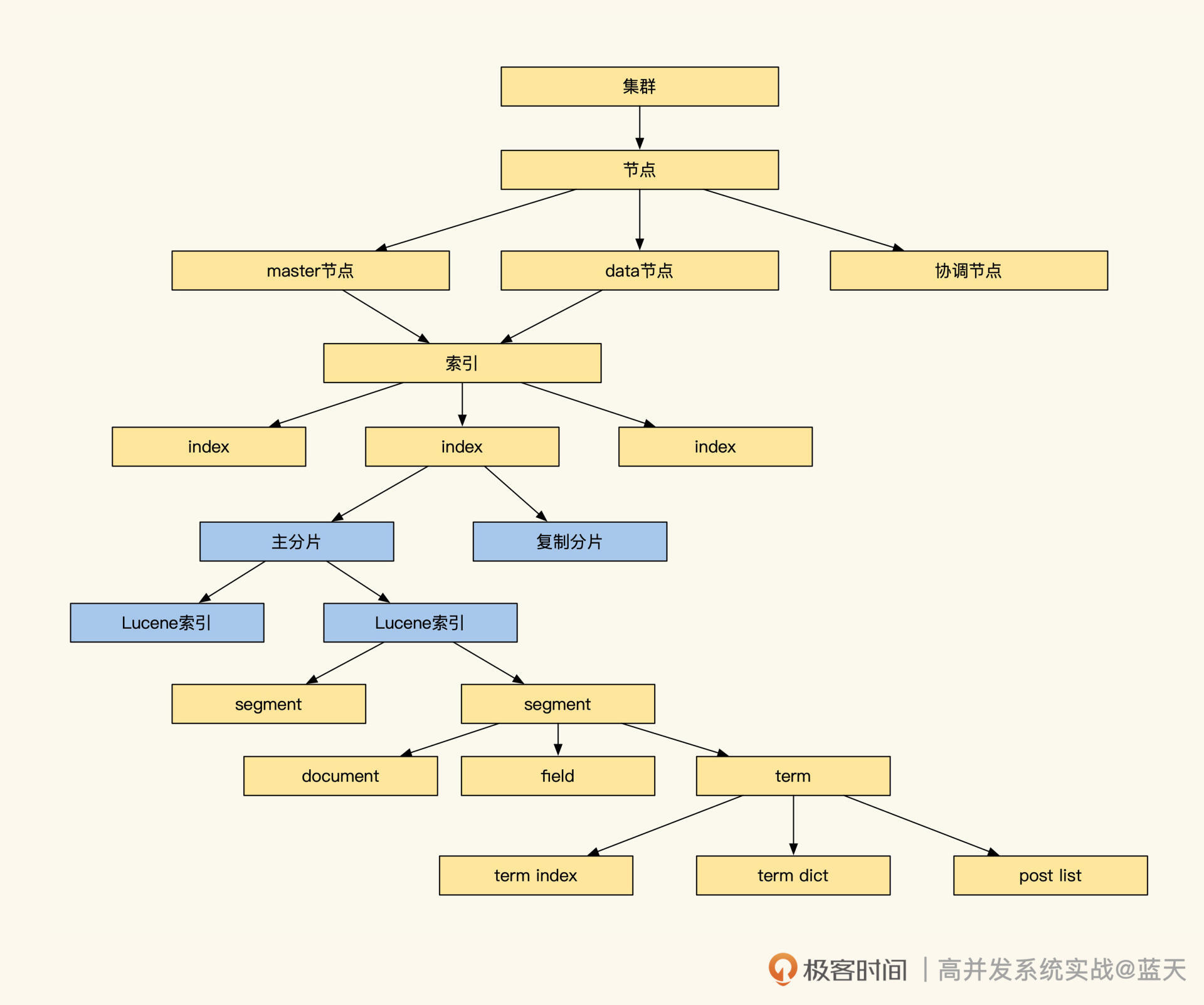
我们再持续深挖一下,Elasticsearch 是如何实现分布式全文检索服务的写存储的。其底层全文检索使用的是 Lucene 引擎,事实上这个引擎是单机嵌入式的,并不支持分布式,分布式功能是基础分片来实现的。
为了提高写效率,常见分布式系统都会先将数据先写在缓存,当数据积累到一定程度后,再将缓存中的数据顺序刷入磁盘。Lucene 也使用了类似的机制,将写入的数据保存在 Index Buffer 中,周期性地将这些数据落盘到 segment 文件。
再来说说存储方面,Lucene 为了让数据能够更快被查到,基本一秒会生成一个 segment 文件,这会导致文件很多、索引很分散。而检索时需要对多个 segment 进行遍历,如果 segment 数量过多会影响查询效率,为此,Lucene 会定期在后台对多个 segment 进行合并。
更多索引细节,我稍后再给你介绍,可以看到 Elasticsearch 是一个 IO 频繁的服务,将新数据放在 SSD 上能够提高其工作效率。
但是 SSD 很昂贵,为此 Elasticsearch 实现了冷热数据分离。我们可以将热数据保存在高性能 SSD,冷数据放在大容量磁盘中。
同时官方推荐我们按天建立索引,当我们的存储数据量达到一定程度时,Elasticsearch 会把一些不经常读取的索引挪到冷数据区,以此提高数据存储的性价比。而且我建议你创建索引时按天创建索引,这样查询时。我们可以通过时间范围来降低扫描数据量。
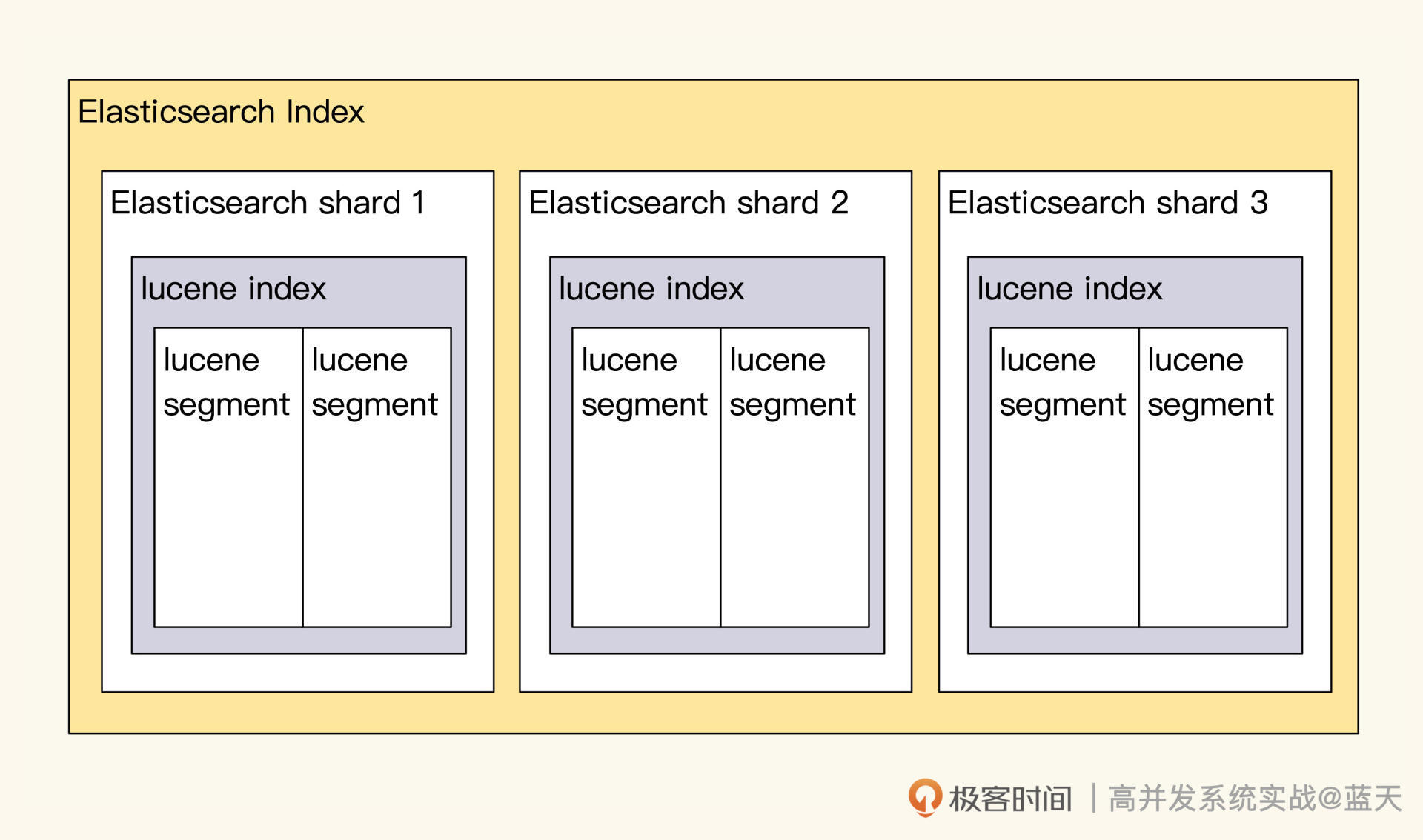
ES索引组成
另外,Elasticsearch 服务为了保证读写性能可扩容,Elasticsearch 对数据做了分片,分片的路由规则默认是通过日志 DocId 做 hash 来保证数据分布均衡,常见分布式系统都是通过分片来实现读写性能的线性提升。
你可以这样理解:单个节点达到性能上限,就需要增加 Data 服务器节点及副本数来降低写压力。但是,副本加到一定程度,由于写强一致性问题反而会让写性能下降。具体加多少更好呢?这需要你用生产日志实测,才能确定具体数值。
Elasticsearch 的两次查询
前面提到多节点及多分片能够提高系统的写性能,但是这会让数据分散在多个 Data 节点当中,Elasticsearch 并不知道我们要找的文档,到底保存在哪个分片的哪个 segment 文件中。
所以, 为了均衡各个数据节点的性能压力,Elasticsearch 每次查询都是请求所有索引所在的 Data 节点,查询请求时协调节点会在相同数据分片多个副本中,随机选出一个节点发送查询请求,从而实现负载均衡。
而收到请求的副本会根据关键词权重对结果先进行一次排序,当协调节点拿到所有副本返回的文档 ID 列表后,会再次对结果汇总排序,最后才会用 DocId 去各个副本 Fetch 具体的文档数据将结果返回。
可以说,Elasticsearch 通过这个方式实现了所有分片的大数据集的全文检索,但这种方式也同时加大了 Elasticsearch 对数据查询请求的耗时。下图是协调节点和副本的通讯过程:
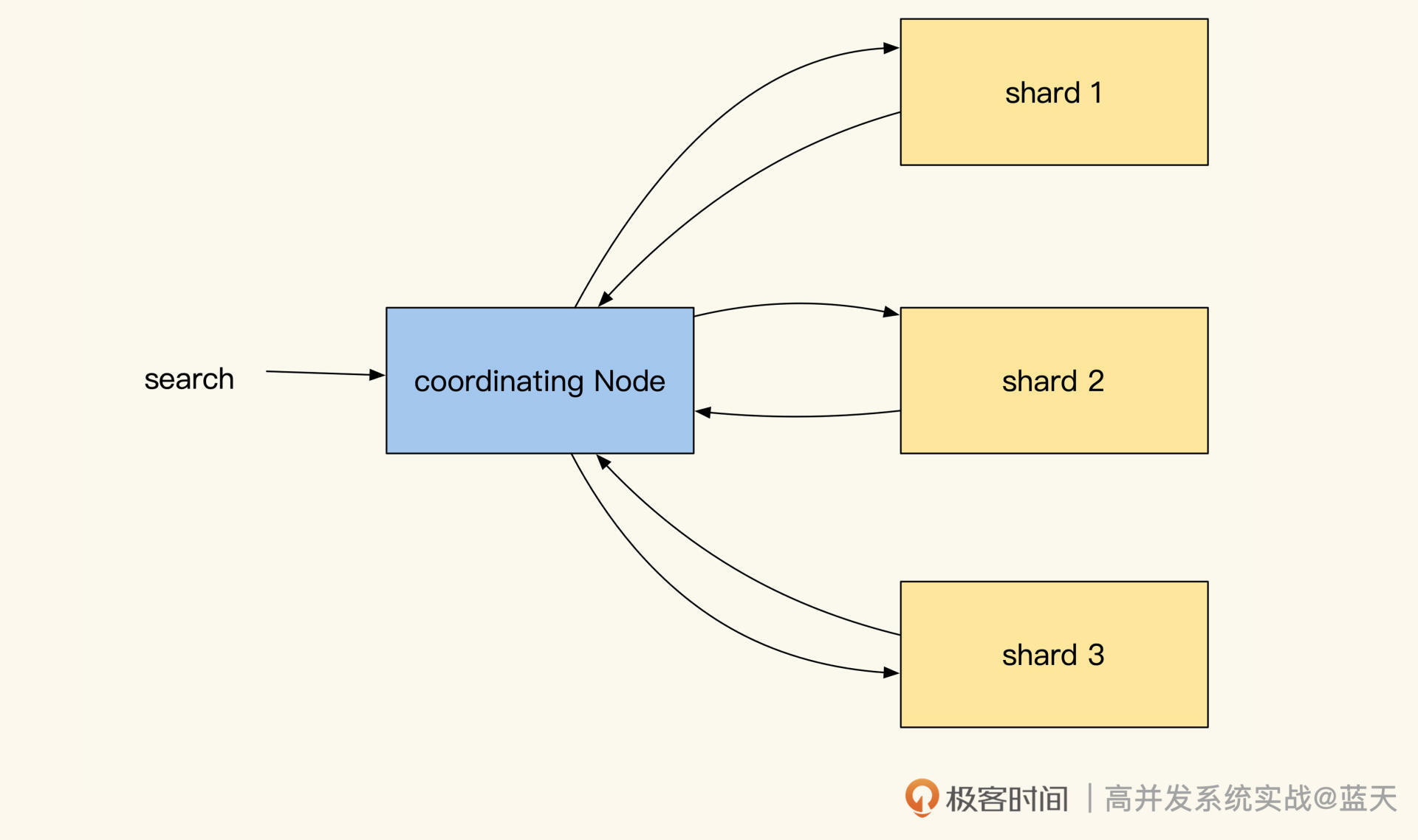
除了耗时,这个方式还有很多缺点,比如查询 QPS 低;网络吞吐性能不高;协助节点需要每次查询结果做分页;分页后,如果我们想查询靠后的页面,要等每个节点先搜索和排序好该页之前的所有数据,才能响应,而且翻页跨度越大,查询就越慢……
为此,ES 限制默认返回的结果最多 1w 条,这个限制也提醒了我们不能将 Elasticsearch 的服务当作数据库去用。还有一点实践的注意事项,这种实现方式也导致了小概率个别日志由于权重太低查不到的问题。为此,ES 提供了 search_type=dfs_query_then_fetch 参数来应对特殊情况,但是这种方式损耗系统资源严重,非必要不建议开启。
除此之外,Elasticsearch 的查询有 query and fetch、dfs query and fetch、dfs query then fetch 三种,不过它们和这节课主线关联不大,有兴趣的话你可以课后自己了解一下。
Elasticsearch 的倒排索引
Elasticsearch 支持多种查询方式不仅仅是全文检索,如数值类使用的是 BKD Tree,Elasticsearch 的全文检索查询是通过 Lucene 实现的,索引的实现原理和 OLAP 的 LSM 及 OLTP 的 B+Tree 完全不同,它使用的是倒排索引(Inverted Index)。
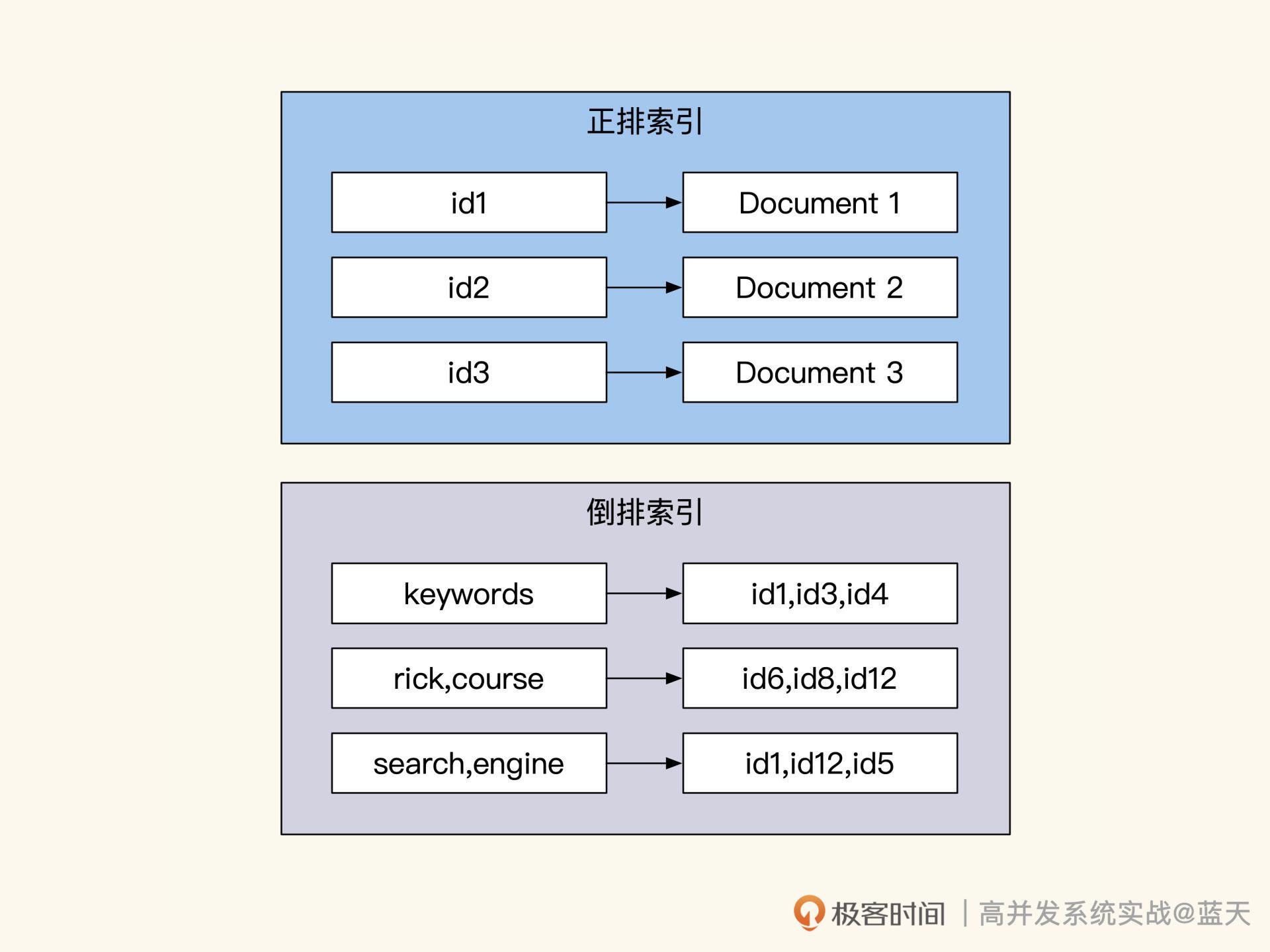
正排索引及倒排索引
查询时多个分词的合并交集
一般来说,倒排索引常在搜索引擎内做全文检索使用,其不同于关系数据库中的 B+Tree 和 B-Tree 。B+Tree 和 B-Tree 索引是从树根往下按左前缀方式来递减缩小查询范围,而倒排索引的过程可以大致分四个步骤:分词、取出相关 DocId、计算权重并重新排序、展示高相关度的记录。
首先,对用户输入的内容做分词,找出关键词;然后,通过多个关键词对应的倒排索引,取出所有相关的 DocId;接下来,将多个关键词设计索引 ID 做交集后,再根据关键词在每个文档的出现次数及频率,以此计算出每条结果的权重,进而给列表排序,并实现基于查询匹配度的评分;然后就可以根据匹配评分来降序排序,列出相关度高的记录。
下面,我们简单看一下 Lucene 具体实现。
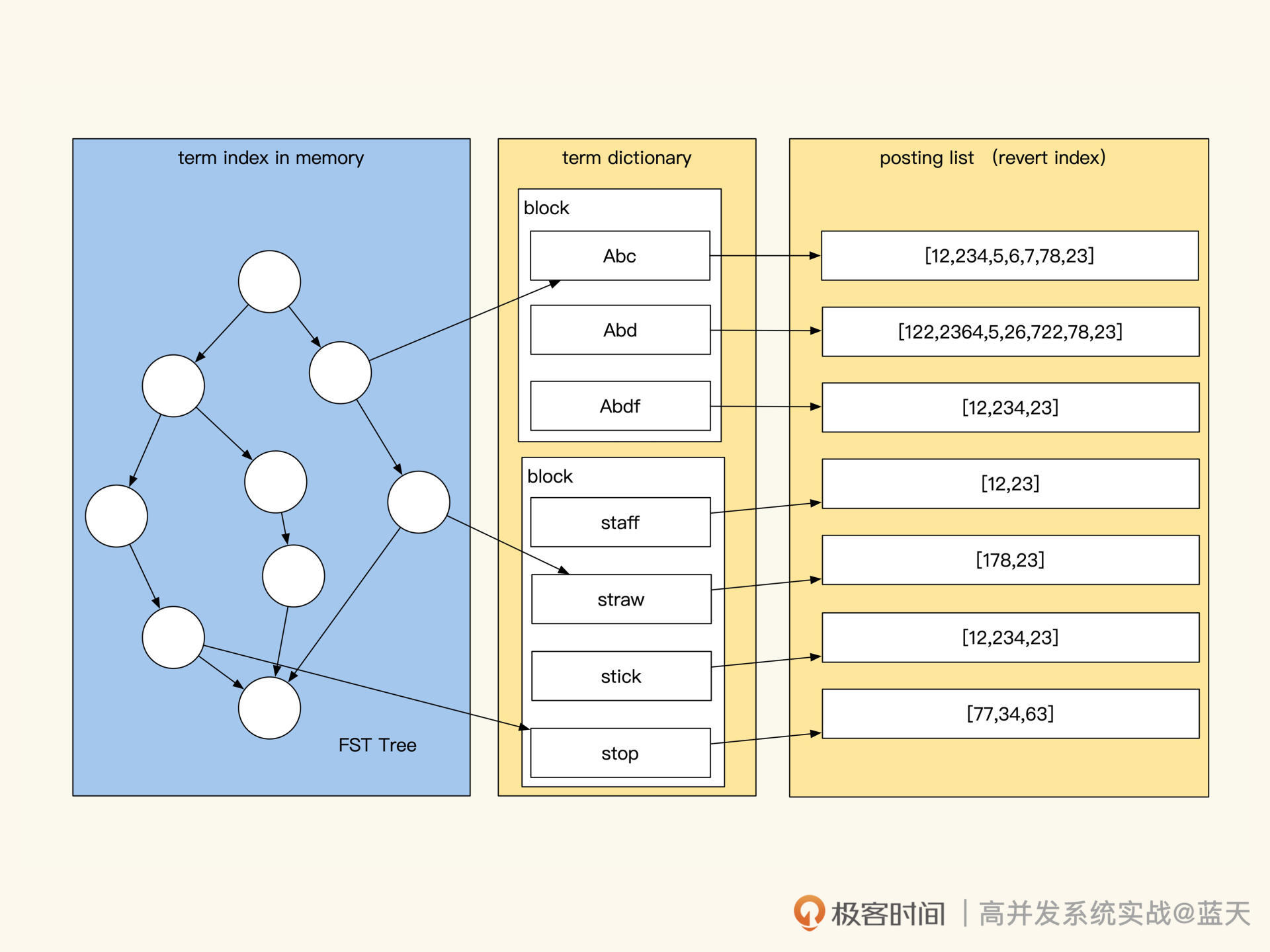
ES的倒排索引原理
如上图,Elasticsearch 集群的索引保存在 Lucene 的 segment 文件中,segment 文件格式相关信息你可以参考 segment 格式,其中包括行存、列存、倒排索引。
为了节省空间和提高查询效率,Lucene 对关键字倒排索引做了大量优化,segment 主要保存了三种索引:
- Term Index(单词词典索引):用于关键词(Term)快速搜索,Term index 是基础 Trie 树改进的 FST(Finite State Transducer 有限状态传感器,占用内存少)实现的二级索引。平时这个树会放在内存中,用于减少磁盘 IO 加快 Term 查找速度,检索时会通过 FST 快速找到 Term Dictionary 对应的词典文件 block。
- Term Dictionary(单词词典):单词词典索引中保存的是单词(Term)与 Posting List 的关系,而这个单词词典数据会按 block 在磁盘中排序压缩保存,相比 B-Tree 更节省空间,其中保存了单词的前缀后缀,可以用于近似词及相似词查询,通过这个词典可以找到相关的倒排索引列表位置。
- Posting List(倒排列表):倒排列表记录了关键词 Term 出现的文档 ID,以及其所在文档中位置、偏移、词频信息,这是我们查找的最终文档列表,我们拿到这些就可以拿去排序合并了。
一条日志在入库时,它的具体内容并不会被真实保存在倒排索引中。
在日志入库之前,会先进行分词,过滤掉无用符号等分隔词,找出文档中每个关键词(Term)在文档中的位置及频率权重;然后,将这些关键词保存在 Term Index 以及 Term Dictionary 内;最后,将每个关键词对应的文档 ID 和权重、位置等信息排序合并到 Posting List 中进行保存。通过上述三个结构就实现了一个优化磁盘 IO 的倒排索引。
而查询时,Elasticsearch 会将用户输入的关键字通过分词解析出来,在内存中的 Term Index 单词索引查找到对应 Term Dictionary 字典的索引所在磁盘的 block。接着,由 Term Dictionary 找到对关键词对应的所有相关文档 DocId 及权重,并根据保存的信息和权重算法对查询结果进行排序返回结果。
总结
不得不感叹,Elasticsearch 通过组合一片片小 Lucene 的服务,就实现了大型分布式数据的全文检索。这无论放到当时还是现在,都很不可思议。可以说了,Elasticsearch 几乎垄断了所有日志实时分析、监控、存储、查找、统计的市场,其中用到的技术有很多地方可圈可点。
现在市面上新生代开源虽然很多,但是论完善性和多样性,能够彻底形成平台性支撑的开源仍然很少见。而 Elasticsearch 本身是一个十分庞大的分布式检索分析系统,它对数据的写入和查询做了大量的优化。
我希望你关注的是,Elasticsearch 用到了大量分布式设计思路和有趣的算法,比如:分布式共识算法(那时还没有 Raft)、倒排索引、词权重、匹配权重、分词、异步同步、数据一致性检测等。这些行业中的优秀设计,值得我们做拓展了解,推荐你课后自行探索。
实时统计:链路跟踪实时计算中的实用算法
如果我们的数据量很大,需要投入的服务器资源就更多,之前我们最大一次的规模,投入了大概 2000 台服务器做 ELK。但如果我们的服务器资源很匮乏,这种情况下,要怎样实现性能分析统计和监控呢?
当时我只有两台 4 核 8G 服务器,所以我用了一些巧妙的算法,实现了本来需要大量服务器并行计算,才能实现的功能。这节课,我就给你分享一下这些算法。
我先把实时计算的整体结构图放出来,方便你建立整体印象。
实时计算的整体结构图
从上图可见,我们实时计算的数据是从 Kafka 拉取的,通过进程实时计算统计 Kafka 的分组消费。接下来,我们具体看看这些算法的思路和功用。URL 去参数聚合。
URL 去参数聚合
做链路跟踪的小伙伴都会很头疼 URL 去参数这个问题,主要原因是很多小伙伴会使用 RESTful 方式来设计内网接口。而做链路跟踪或针对 API 维度进行统计分析时,如果不做整理,直接将这些带参数的网址录入到统计分析系统中是不行的。
同一个 API 由于不同的参数无法归类,最终会导致网址不唯一,而成千上万个“不同”网址的 API 汇总在一起,就会造成统计系统因资源耗尽崩掉。除此之外,同一网址不同的 method 操作在 RESTful 中实际也是不同的实现,所以同一个网址并不代表同一个接口,这更是给归类统计增加了难度。
为了方便你理解,这里举几个 RESTful 实现的例子:
- GET geekbang.com/user/1002312/info 获取用户信息
- PUT geekbang.com/user/1002312/info 修改用户信息
- DELETE geekbang.com/user/1002312/friend/123455 删除用户好友
可以看到我们的网址中有参数,虽然是同样的网址,但是 GET 和 PUT 方法代表的意义并不一样,这个问题在使用 Prometheus、Trace 等工具时都会出现。
一般来说,碰到这种问题,我们都会先整理数据,再录入到统计分析系统当中。我们有两种常用方式来对 URL 去参数。
第一种方式是人工配置替换模板,也就是人工配置出一个 URL 规则,用来筛选出符合规则的日志并替换掉关键部分的参数。
我一般会用一个类似 Trier Tree 保存这个 URL 替换的配置列表,这样能够提高查找速度。但是这个方式也有缺点,需要人工维护。如果开发团队超过 200 人,列表需要时常更新,这样维护起来会很麻烦。
类Radix tree效果:
/user- /*- - /info- - - :GET- - - :PUT- - /friend- - - /*- - - - :DELETE
具体实现是将网址通过 / 进行分割,逐级在前缀搜索树查找。
我举个例子,比如我们请求 GET /user/1002312/info,使用树进行检索时,可以先找到 /user 根节点。然后在 /user 子节点中继续查找,发现有元素 /(代表这里替换) 而且同级没有其他匹配,那么会被记录为这里可替换。然后需要继续查找 / 下子节点 /info。到这里,网址已经完全匹配。在网址更深一层是具体请求 method,我们找到 GET 操作,即可完成这个网址的配置匹配。
然后,直接把 /* 部分的 1002312 替换成固定字符串即可,替换的效果如下所示:
GET /user/1002312/info 替换成 /user/replaced/info
另一种方式是数据特征筛选,这种方式虽然会有误差,但是实现简单,无需人工维护。这个方法是我推崇的方式,虽然这种方式有可能有失误,但是确实比第一种方式更方便。
具体请看后面的演示代码:
//根据数据特征过滤网址内参数
function filterUrl($url)
{$urlArr = explode("/", $url);foreach ($urlArr as $urlIndex => $urlItem) {$totalChar = 0; //有多少字母$totalNum = 0; //有多少数值$totalLen = strlen($urlItem); //总长度for ($index = 0; $index < $totalLen; $index++) {if (is_numeric($urlItem[$index])) {$totalNum++;} else {$totalChar++;}}//过滤md5 长度32或64 内容有数字 有字符混合 直接认为是md5if (($totalLen == 32 || $totalLen == 64) && $totalChar > 0 && $totalNum > 0) {$urlArr[$urlIndex] = "*md*";continue;}//字符串 data 参数是数字和英文混合 长度超过3(回避v1/v2一类版本)if ($totalLen > 3 && $totalChar > 0 && $totalNum > 0) {$urlArr[$urlIndex] = "*data*";continue;}//全是数字在网址中认为是id一类, 直接进行替换if ($totalChar == 0 && $totalNum > 0) {$urlArr[$urlIndex] = "*num*";continue;}}return implode("/", $urlArr);
}
通过这两种方式,可以很方便地将我们的网址替换成后面这样:
- GET geekbang.com/user/1002312/info => geekbang.com/user/num/info_GET
- PUT geekbang.com/user/1002312/info => geekbang.com/user/num/info_PUT
- DELETE geekbang.com/user/1002312/friend/123455 => geekbang.com/user/num/friend/num_DEL
经过过滤,我们的 API 列表是不是清爽了很多?这时再做 API 进行聚合统计分析的时候,就会更加方便了。
时间分块统计
将 URL 去参数后,我们就可以对不同的接口做性能统计了,这里我用的是时间块方式实现。这么设计,是因为我的日志消费服务可用内存是有限的(只有 8G),而且如果保存太多数据到数据库的话,实时更新效率会很低。
考虑再三,我选择分时间块来保存周期时间块内的统计,将一段时间内的请求数据在内存中汇总统计。
为了更好地展示,我将每天 24 小时,按 15 分钟一个时间块来划分,而每个时间块内都会统计各自时间段内的接口数据,形成数据统计块。
这样,一天就会有 96 个数据统计块(计算公式是:86400 秒 / (15 分钟 * 60 秒) = 96)。如果 API 有 200 个,那么我们内存中保存的一天的数据量就是 19200 条(96X200 = 19200)。
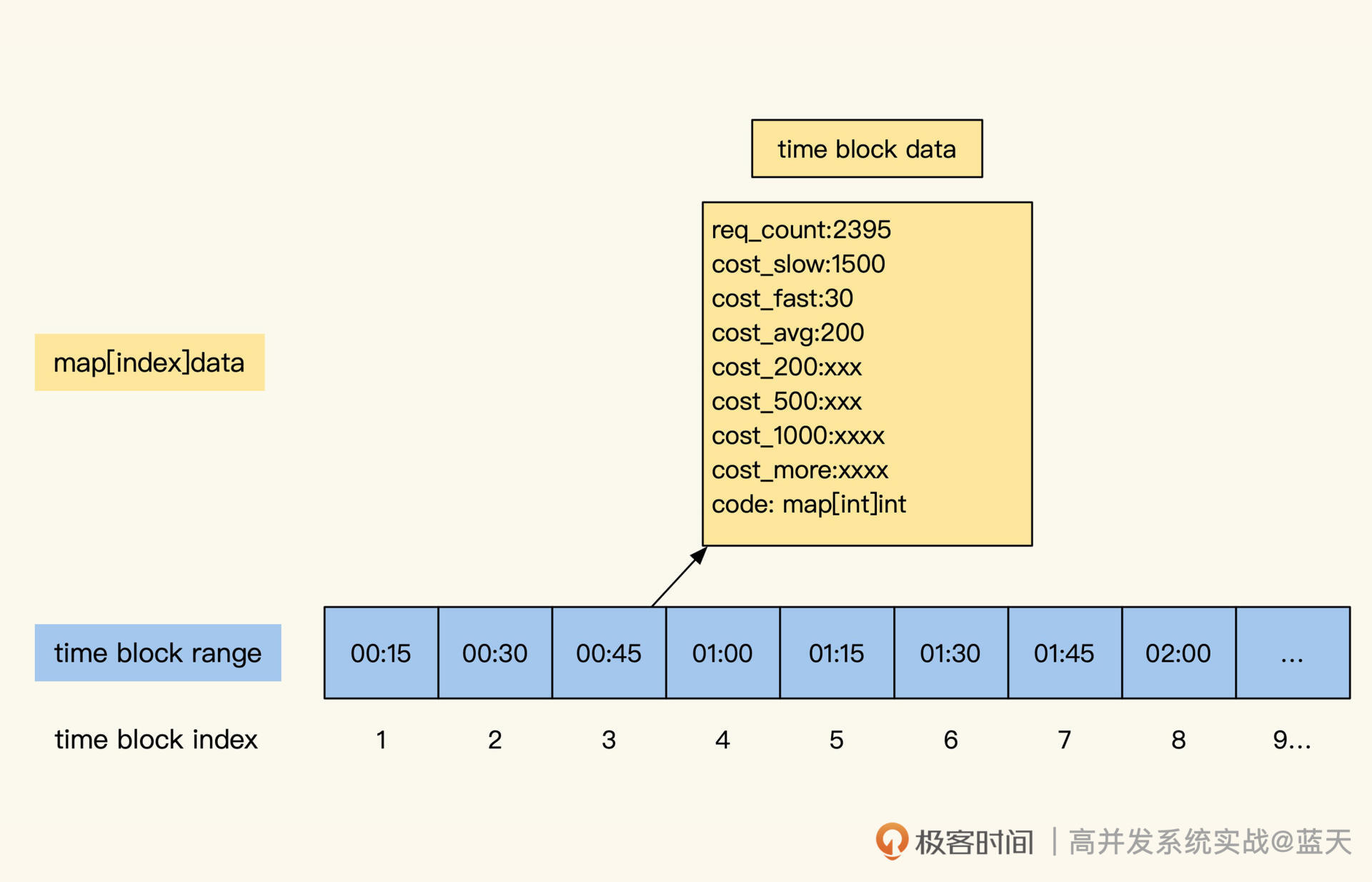
时间块结构
假设我们监控的系统有 200 个接口,就能推算出一年的统计数据量为 700w 条左右。如果有需要,我们可以让这个粒度更小一些。
事实上,市面上很多 metrics 监控的时间块粒度是 3~5 秒一个,直到最近几年出现 OLAP 和时序数据库后,才出现秒级粒度性能统计。而粒度越小监控越细致,粒度过大只能看到时段内的平均性能表现。
我还想说一个题外话,近两年出现了 influxDB 或 Prometheus,用它们来保存数据也可以,但这些方式都需要硬件投入和运维成本,你可以结合自身业务情况来权衡。
我们看一下,在 15 分钟为一段的时间块里,统计了 URL 的哪些内容?
如上图,每个数据统计块内聚合了以下指标:
- 累计请求次数
- 最慢耗时
- 最快耗时
- 平均耗时
- 耗时个数,图中使用的是 ELK 提供的四分位数分析(如果拿不到全量数据来计算四分位数,也可以设置为:小于 200ms、小于 500ms、小于 1000ms、大于 1 秒的请求个数统计)
- 接口响应 http code 及对应的响应个数(如:{“200”:1343,“500”:23,“404”: 12, “301”:14})
把这些指标展示出来,主要是为了分析这个接口的性能表现。看到这里,你是不是有疑问,监控方面我们大费周章去统计这些细节,真的有意义么?
的确,大多数情况下我们 API 的表现都很好,个别的特殊情况才会导致接口响应很慢。不过监控系统除了对大范围故障问题的监控,细微故障的潜在问题也不能忽视。尤其是大吞吐量的服务器,更难发现这种细微的故障。
我们只有在监控上支持对细微问题的排查,才能提前发现这些小概率的故障。这些小概率的故障在极端情况下会导致集群的崩溃。因此提前发现、提前处理,才能保证我们线上系统面对大流量并发时不至于突然崩掉。
错误日志聚类
监控统计请求之后,我们还要关注错误的日志。说到故障排查的难题,还得说说错误日志聚类这个方式。
我们都知道,平时常见的线上故障,往往伴随着大量的错误日志。在海量警告面前,我们一方面要获取最新的错误消息,同时还不能遗漏个别重要但低频率出现的故障。
因为资源有限,内存里无法存放太多的错误日志,所以日志聚类的方案是个不错的选择,通过日志聚合,对错误进行分类,给用户排查即可。这样做,在发现错误的同时,还能够提供错误的范本来加快排查速度。
我是这样实现日志错误聚合功能的:直接对日志做近似度对比计算,并加上一些辅助字段作为修正。这个功能可以把个别参数不同、但同属一类错误的日志聚合到一起,方便我们快速发现的低频故障。
通过这种方式实现的错误监控还有额外的好处,有了它,无需全站统一日志格式标准,就能轻松适应各种格式的日志,这大大方便了我们对不同系统的监控。
说到这,你是不是挺好奇实现细节的?下面是 github.com/mfonda/simhash 提供的 simhash 文本近似度样例:
package main
import ("fmt""github.com/mfonda/simhash"
)
func main() {var docs = [][]byte{[]byte("this is a test phrass"), //测试字符串1[]byte("this is a test phrass"), //测试字符串2[]byte("foo bar"), //测试字符串3}hashes := make([]uint64, len(docs))for i, d := range docs {hashes[i] = simhash.Simhash(simhash.NewWordFeatureSet(d)) //计算出测试字符串对应的hash值fmt.Printf("Simhash of %s: %x\n", d, hashes[i])}//测试字符串1 对比 测试字符串2fmt.Printf("Comparison of 0 1 : %d\n", simhash.Compare(hashes[0], hashes[1]))//测试字符串1 对比 测试字符串3fmt.Printf("Comparison of 0 2 : %d\n", simhash.Compare(hashes[0], hashes[2]))
}我们可以用一个常驻进程,持续做 group consumer 消费 Kafka 日志信息,消费时每当碰到错误日志,就需要通过 simhash 将其转换成 64 位 hash。然后,通过和已有错误类型的列表进行遍历对比,日志长度相近且海明距离(simhash.compare 计算结果)差异不超过 12 个 bit 差异,就可以归为一类。
请注意,由于算法的限制,simhash 对于小于 100 字的文本误差较大,所以需要我们实际测试下具体的运行情况,对其进行微调。文本特别短时,我们需要一些其他辅助来去重。注意,同时 100 字以下要求匹配度大于 80%,100 字以上则要大于 90% 匹配度。
最后,除了日志相似度检测以外,也可以通过生成日志的代码文件名、行数以及文本长度来辅助判断。由于是模糊匹配,这样能够减少失误。
具体步骤是这样的:如果匹配到当前日志属于已有某个错误类型时,就保存错误第一次出现的日志内容,以及错误最后三次出现的日志内容。
我们需要在归类界面查看错误的最近发生时间、次数、开始时间、开始错误日志,同时可以通过 Trace ID 直接跳转到 Trace 过程渲染页面。(这个做法对排查问题很有帮助,你可以看看我在Java 单机开源版中的实现,体验下效果。)
事实上,错误去重还有很多的优化空间。比方说我们内存中已经统计出上千种错误类型,那么每次新进的错误日志的 hash,就需要和这 1000 个类型挨个做对比,这无形浪费了我们大量的 CPU 资源。
对于这种情况,网上有一些简单的小技巧,比如将 64 位 hash 分成两段,先对比前半部分,如果近似度高的话再对比后半部分。
这类技巧叫日志聚合,但行业里应用得比较少。
云厂商也提供了类似功能,但是很少应用于错误去重这个领域,相信这里还有潜力可以挖掘,算力充足的情况下行业常用 K-MEANS 或 DBSCAN 算法做日志聚合,有兴趣的小伙伴可以再深挖下。
bitmap 实现频率统计
我们虽然统计出了错误归类,但是这个错误到底发生了多久、线上是否还在持续产生报错?这些问题还是没解决。若是在平时,我们会将这些日志一个个记录在 OLAP 类的统计分析系统中,按时间分区来汇总聚合这些统计。但是,这个方式需要大量的算力支撑,我们没有那么多资源,还有别的方式来表示么?
这里我用了一个小技巧,就是在错误第一次产生后,每一秒用一个 bit 代表在 bitmap 中记录。
如果这个分钟内产生了同类错误,那么就记录为 1,以此类推,一天会用 86400 个 bit =1350 个 uint64 来记录日志出现的频率周期。这样排查问题时,就可以根据 bit 反推什么时间段内有错误产生,这样用少量的内存就能快速实现频率周期的记录。
不过这样做又带来了一个新的问题——内存浪费严重。这是由于错误统计是按错误归类类型放在内存中的。一个新业务平均每天会有上千种错误,这导致我需要 1350x1000 个 int64 保存在内存中。
为了节省内存的使用,我将 bitmap 实现更换成 Roraing bitmap。它可以压缩 bitmap 的空间,对于连续相似的数据压缩效果更明显。事实上 bitmap 的应用不止这些,我们可以用它做很多有趣的标注,相对于传统结构可以节省更多的内存和存储空间。
总结
这节课我给你分享了四种实用的算法,这些都是我实践验证过的。你可以结合后面这张图来复习记忆。
为了解决参数不同给网址聚类造成的难题,可以通过配置或数据特征过滤方式对 URL 进行整理,还可以通过时间块减少统计的结果数据量。
为了梳理大量的错误日志,simhash 算法是一个不错的选择,还可以搭配 bitmap 记录错误日志的出现频率。有了这些算法的帮助,用少量系统资源,即可实现线上服务的故障监控聚合分析功能,将服务的工作状态直观地展示出来。
学完这节课,你有没有觉得,在资源匮乏的情况下,用一些简单的算法,实现之前需要几十台服务器的分布式服务才能实现的服务,是十分有趣的呢?
即使是现代,互联网发展这几年,仍旧有很多场景需要一些特殊的设计来帮助我们降低资源的损耗,比如:用 Bloom Filter 减少扫描次数、通过 Redis 的 hyperLogLog 对大量数据做大致计数、利用 GEO hash 实现地图分块分区统计等。如果你有兴趣,课后可以拓展学习一下Redis 模块的内容。
跳数索引:后起新秀ClickHouse
通过前面的学习,我们见识到了 Elasticsearch 的强大功能。不过在技术选型的时候,价格也是重要影响因素。Elasticsearch 虽然用起来方便,但却有大量的硬件资源损耗,再富有的公司,看到每月服务器账单的时候也会心疼一下。
而 ClickHouse 是新生代的 OLAP,尝试使用了很多有趣的实现,虽然仍旧有很多不足,比如不支持数据更新、动态索引较差、查询优化难度高、分布式需要手动设计等问题。但由于它架构简单,整体相对廉价,逐渐得到很多团队的认同,很多互联网企业加入社区,不断改进 ClickHouse。
ClickHouse 属于列式存储数据库,多用于写多读少的场景,它提供了灵活的分布式存储引擎,还有分片、集群等多种模式,供我们搭建的时候按需选择。
这节课我会从写入、分片、索引、查询的实现这几个方面带你重新认识 ClickHouse。在学习过程中建议你对比一下 Elasticsearch、MySQL、RocksDB 的具体实现,想想它们各有什么优缺点,适合什么样的场景。相信通过对比,你会有更多收获。
并行能力 CPU 吞吐和性能
我们先选个熟悉的参照物——MySQL,MySQL 在处理一个 SQL 请求时只能利用一个 CPU。但是 ClickHouse 则会充分利用多核,对本地大量数据做快速的计算,因此 ClickHouse 有更高的数据处理能力(2~30G/s,未压缩数据),但是这也导致它的并发不高,因为一个请求就可以用光所有系统资源。
我们刚使用 ClickHouse 的时候,常常碰到查几年的用户行为时,一个 SQL 就会将整个 ClickHouse 卡住,几分钟都没有响应的情况。
官方建议 ClickHouse 的查询 QPS 限制在 100 左右,如果我们的查询索引设置得好,几十上百亿的数据可以在 1 秒内将数据统计返回。作为参考,如果换成 MySQL,这个时间至少需要一分钟以上;而如果 ClickHouse 的查询设计得不好,可能等半小时还没有计算完毕,甚至会出现卡死的现象。
所以,你使用 ClickHouse 的场景如果是对用户服务的,最好对这种查询做缓存。而且,界面在加载时要设置 30 秒以上的等待时间,因为我们的请求可能在排队等待别的查询。
如果我们的用户量很大,建议多放一些节点用分区、副本、相同数据子集群来分担查询计算的压力。不过,考虑到如果想提供 1w QPS 查询,极端的情况下需要 100 台 ClickHouse 存储同样的数据,所以建议还是尽量用脚本推送数据结果到缓存中对外服务。
但是,如果我们的集群都是小数据,并且能够保证每次查询都可控,ClickHouse 能够支持每秒上万 QPS 的查询,这取决于我们投入多少时间去做优化分析。
对此,我推荐的优化思路是:基于排序字段做范围查询过滤后,再做聚合查询。你还要注意,需要高并发查询数据的服务和缓慢查询的服务需要隔离开,这样才能提供更好的性能。
分享了使用体验,我们还是按部就班来分析分析 ClickHouse 在写入、储存、查询等方面的特性,这样你才能更加全面深入地认识它。
批量写入优化
ClickHouse 的客户端驱动很有意思,客户端会有多个写入数据缓存,当我们批量插入数据时,客户端会将我们要 insert 的数据先在本地缓存一段时间,直到积累足够配置的 block_size 后才会把数据批量提交到服务端,以此提高写入的性能。
如果我们对实时性要求很高的话,这个 block_size 可以设置得小一点,当然这个代价就是性能变差一些。
为优化高并发写服务,除了客户端做的合并,ClickHouse 的引擎 MergeTree 也做了类似的工作。为此单个 ClickHouse 批量写性能能够达到 280M/s(受硬件性能及输入数据量影响)。
MergeTree 采用了批量写入磁盘、定期合并方式(batch write-merge),这个设计让我们想起写性能极强的 RocksDB。其实,ClickHouse 刚出来的时候,并没有使用内存进行缓存,而是直接写入磁盘。
最近两年 ClickHouse 做了更新,才实现了类似内存缓存及 WAL 日志。所以,如果你使用 ClickHouse,建议你搭配使用高性能 SSD 作为写入磁盘存储。
事实上,OLAP 有两种不同数据来源:一个是业务系统,一个是大数据。来自业务系统的数据,属性字段比较多,但平时更新量并不大。这种情况下,使用 ClickHouse 常常是为了做历史数据的筛选和属性共性的计算。而来自大数据的数据通常会有很多列,每个列代表不同用户行为,数据量普遍会很大。
两种情况数据量不同,那优化方式自然也不同,具体 ClickHouse 是怎么对这这两种方式做优化的呢?我们结合后面的图片继续分析:
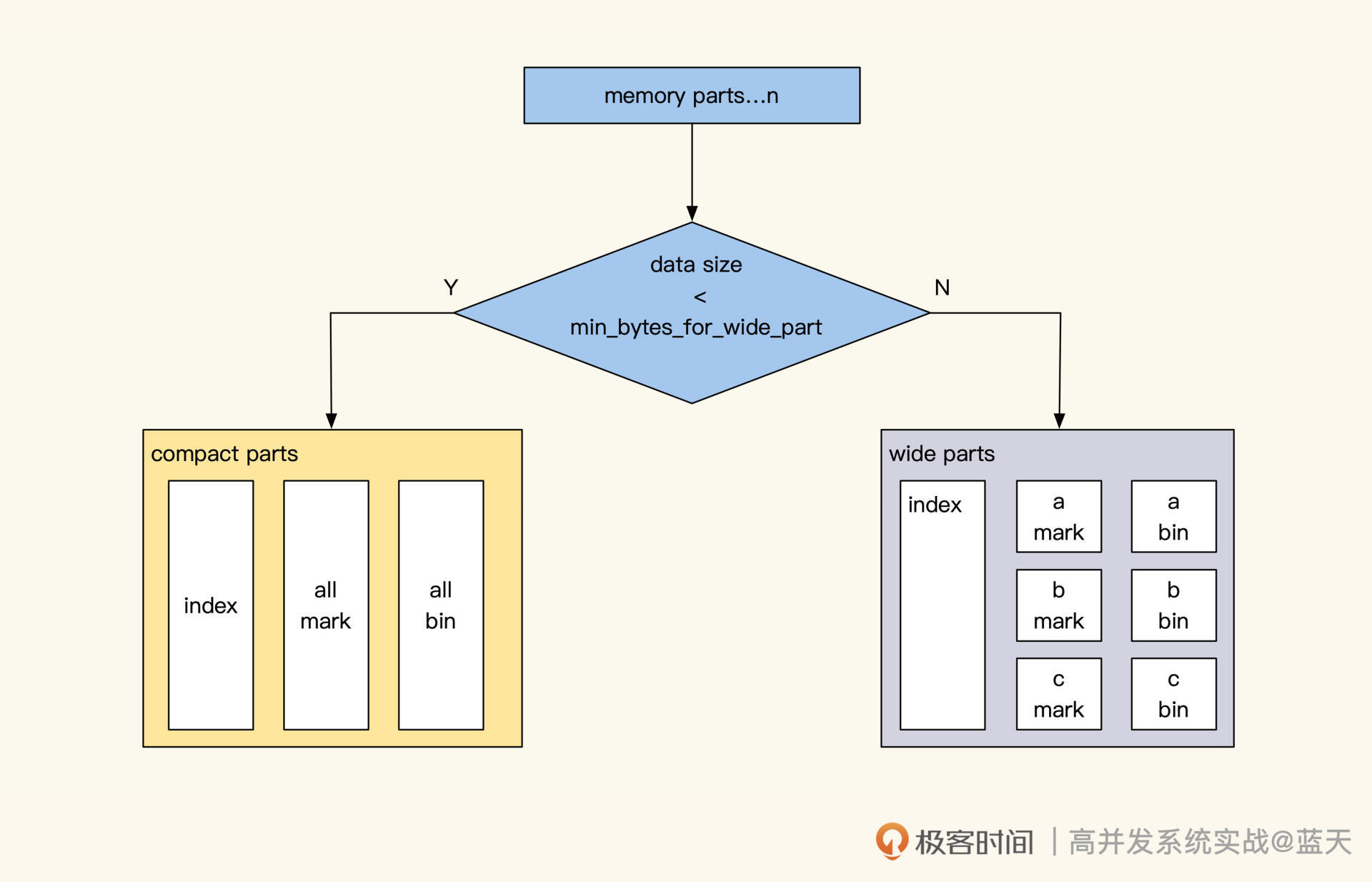
当我们批量输入的数据量小于 min_bytes_for_wide_part 设置时,会按 compact part 方式落盘。这种方式会将落盘的数据放到一个 data.bin 文件中,merge 时会有很好的写效率,这种方式适合于小量业务数据筛选使用。当我们批量输入的数据量超过了配置规定的大小时,会按 wide part 方式落盘,落盘数据的时候会按字段生成不同的文件。这个方式适用于字段较多的数据,merge 相对会慢一些,但是对于指定参与计算列的统计计算,并行吞吐写入和计算能力会更强,适合分析指定小范围的列计算。可以看到,这两种方式对数据的存储和查询很有针对性,可见字段的多少、每次的更新数据量、统计查询时参与的列个数,这些因素都会影响到我们服务的效率。当我们大部分数据都是小数据的时候,一条数据拆分成多个列有一些浪费磁盘 IO,因为是小量数据,我们也不会给他太多机器,这种情况推荐使用 compact parts 方式。当我们的数据列很大,需要对某几个列做数据统计分析时,wide part 的列存储更有优势。
ClickHouse 如何提高查询效率
可以看到,数据库的存储和数据如何使用、如何查询息息相关。不过,这种定期落盘的操作虽然有很好的写性能,却产生了大量的 data part 文件,这会对查询效率很有影响。那么 ClickHouse 是如何提高查询效率呢?我们再仔细分析下,新写入的 parts 数据保存在了 data parts 文件夹内,数据一旦写入数据内容,就不会再进行更改。一般来说,data part 的文件夹名格式为 partition(分区)_min_block_max_block_level,并且为了提高查询效率,ClickHouse 会对 data part 定期做 merge 合并。
data part 同分区 merge 合并
如上图所示,merge 操作会分层进行,期间会减少要扫描的文件夹个数,对数据进行整理、删除、合并操作。你还需要注意,不同分区无法合并,所以如果我们想提高一个表的写性能,多分几个分区会有帮助。如果写入数据量太大,而且数据写入速度太快,产生文件夹的速度会超过后台合并的速度,这时 ClickHouse 就会报 Too many part 错误,毕竟 data parts 文件夹的个数不能无限增加。面对这种报错,调整 min_bytes_for_wide_part 或者增加分区都会有改善。如果写入数据量并不大,你可以考虑多生成 compact parts 数据,这样可以加快合并速度。此外,因为分布式的 ClickHouse 表是基于 ZooKeeper 做分布式调度的,所以表数据一旦写并发过高,ZooKeeper 就会成为瓶颈。遇到类似问题,建议你升级 ClickHouse,新版本支持多组 ZooKeeper,不过这也意味着我们要投入更多资源。
稀疏索引与跳数索引
ClickHouse 的查询功能离不开索引支持。Clickhouse 有两种索引方式,一种是主键索引,这个是在建表时就需要指定的;另一种是跳表索引,用来跳过一些数据。这里我更推荐我们的查询使用主键索引来查询。
主键索引
ClickHouse 的表使用主键索引,才能让数据查询有更好的性能,这是因为数据和索引会按主键进行排序存储,用主键索引查询数据可以很快地处理数据并返回结果。ClickHouse 属于“左前缀查询”——通过索引和分区先快速缩小数据范围,然后再遍历计算,只不过遍历计算是多节点、多 CPU 并行处理的。那么 ClickHouse 如何进行数据检索?这需要我们先了解下 data parts 文件夹内的主要数据组成,如下图:
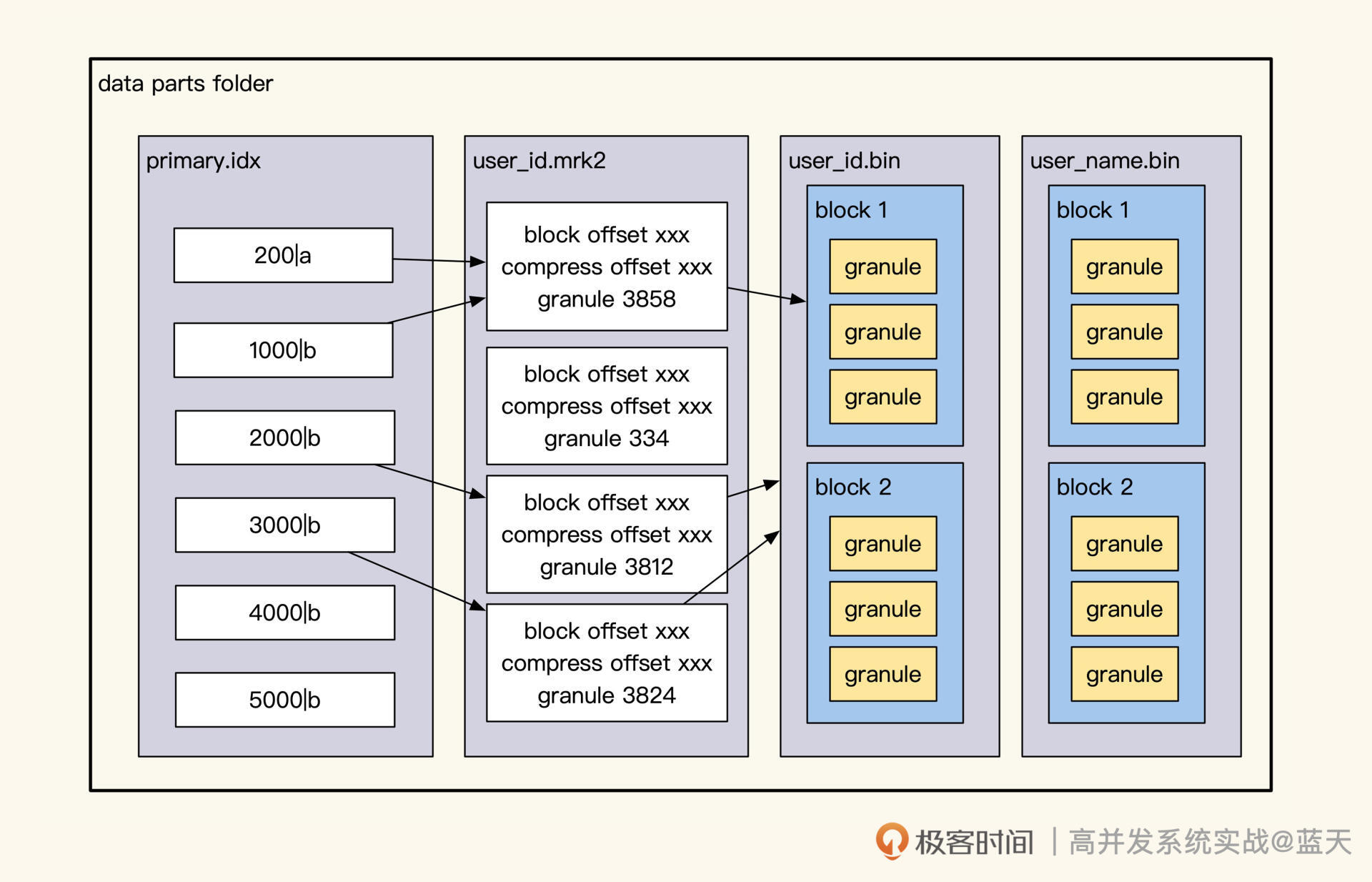
data part 目录结构
结合图示,我们按从大到小的顺序看看 data part 的目录结构。在 data parts 文件夹中,bin 文件里保存了一个或多个字段的数据。继续拆分 bin 文件,它里面是多个 block 数据块,block 是磁盘交互读取的最小单元,它的大小取决于 min_compress_block_size 设置。我们继续看 block 内的结构,它保存了多个 granule(颗粒),这是数据扫描的最小单位。每个 granule 默认会保存 8192 行数据,其中第一条数据就是主键索引数据。data part 文件夹内的主键索引,保存了排序后的所有主键索引数据,而排序顺序是创建表时就指定好的。为了加快查询的速度,data parts 内的主键索引(即稀疏索引)会被加载在内存中,并且为了配合快速查找数据在磁盘的位置,ClickHouse 在 data part 文件夹中,会保存多个按字段名命名的 mark 文件,这个文件保存的是 bin 文件中压缩后的 block 的 offset,以及 granularity 在解压后 block 中的 offset,整体查询效果如下图:
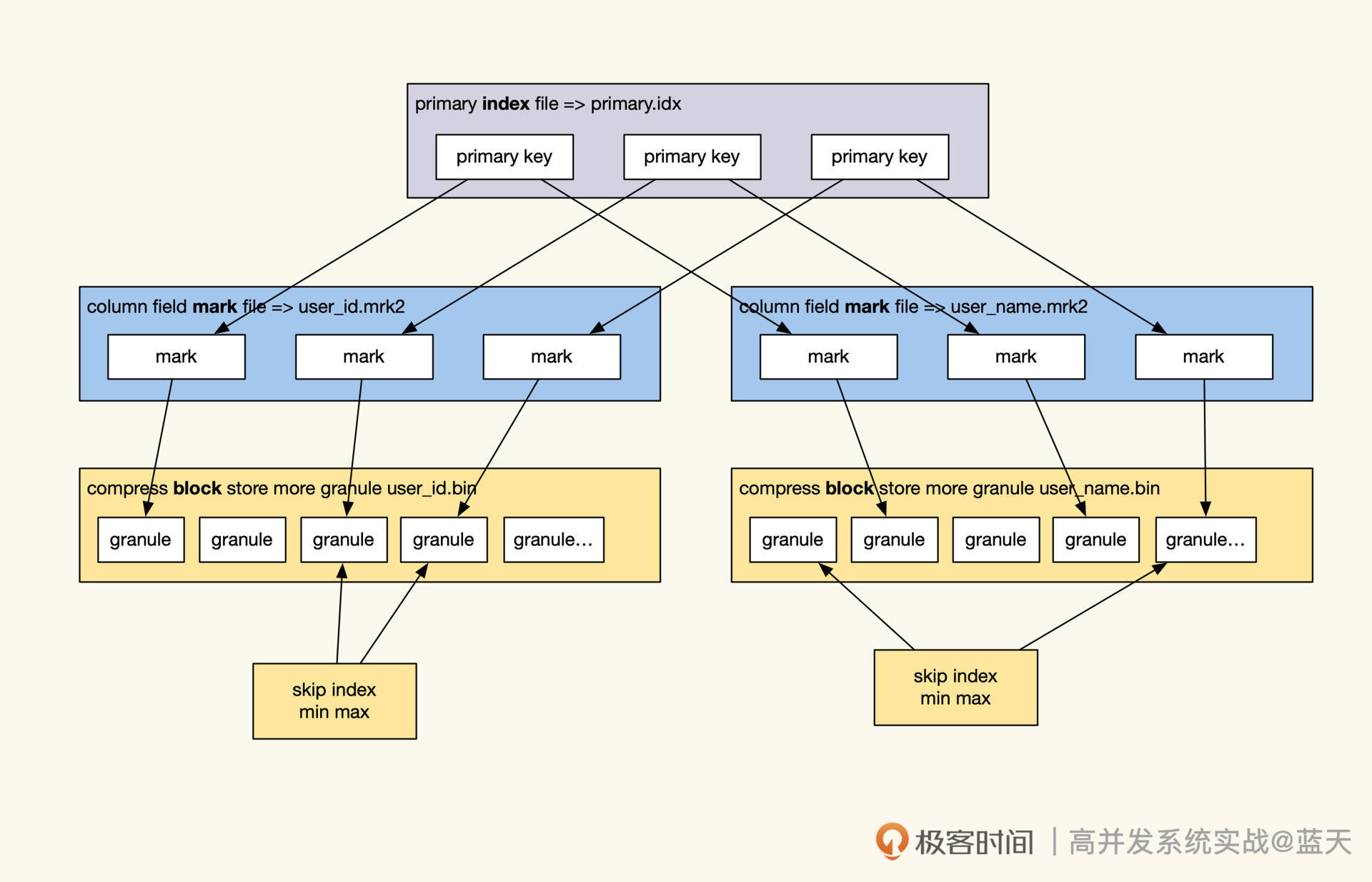
具体查询过程是这样的,我们先用二分法查找内存里的主键索引,定位到特定的 mark 文件,再根据 mark 查找到对应的 block,将其加载到内存,之后在 block 里找到指定的 granule 开始遍历加工,直到查到需要的数据。同时由于 ClickHouse 允许同一个主键多次 Insert 的,查询出的数据可能会出现同一个主键数据出现多次的情况,需要我们人工对查询后的结果做去重。
跳数索引
你可能已经发现了,ClickHouse 除了主键外,没有其他的索引了。这导致无法用主键索引的查询统计,需要扫全表才能计算,但数据库通常每天会保存几十到几百亿的数据,这么做性能就很差了。因此在性能抉择中,ClickHouse 通过反向的思维,设计了跳数索引来减少遍历 granule 的资源浪费,常见的方式如下:
- min_max:辅助数字字段范围查询,保存当前矩阵内最大最小数;
- set:可以理解为列出字段内所有出现的枚举值,可以设置取多少条;
- Bloom Filter:使用 Bloom Filter 确认数据有没有可能在当前块;
- func:支持很多 where 条件内的函数,具体你可以查看 官网。
跳数索引会按上面提到的类型和对应字段,保存在 data parts 文件夹内,跳数索引并不是减少数据搜索范围,而是排除掉不符合筛选条件的 granule,以此加快我们查询速度。好,我们回头来整体看看 ClickHouse 的查询工作流程:
- 根据查询条件,查询过滤出要查询需要读取的 data part 文件夹范围;
- 根据 data part 内数据的主键索引、过滤出要查询的 granule;
- 使用 skip index 跳过不符合的 granule;
- 范围内数据进行计算、汇总、统计、筛选、排序;
- 返回结果。
在实际用上 ClickHouse 之后,你会发现很难对它做索引查询优化,动不动就扫全表,这是为什么呢?主要是我们大部分数据的特征不是很明显、建立的索引区分度不够。这导致我们写入的数据,在每个颗粒内区分度不大,通过稀疏索引的索引无法排除掉大多数的颗粒,所以最终 ClickHouse 只能扫描全表进行计算。另一方面,因为目录过多,有多份数据同时散落在多个 data parts 文件夹内,ClickHouse 需要加载所有 date part 的索引挨个查询,这也消耗了很多的资源。这两个原因导致 ClickHouse 很难做查询优化,当然如果我们的输入数据很有特征,并且特征数据插入时,能够按特征排序顺序插入,性能可能会更好一些。
实时统计
前面我们说了 ClickHouse 往往要扫全表才做统计,这导致它的指标分析功能也不是很友好,为此官方提供了另一个引擎,我们来看看具体情况。类似我们之前讲过的内存计算,ClickHouse 能够将自己的表作为数据源,再创建一个 Materialized View 的表,View 表会将数据源的数据通过聚合函数实时统计计算,每次我们查询这个表,就能获得表规定的统计结果。下面我给你举个简单例子,看看它是如何使用的:
-- 创建数据源表
CREATE TABLE products_orders
(prod_id UInt32 COMMENT '商品',type UInt16 COMMENT '商品类型',name String COMMENT '商品名称',price Decimal32(2) COMMENT '价格'
) ENGINE = MergeTree()
ORDER BY (prod_id, type, name)
PARTITION BY prod_id;--创建 物化视图表
CREATE MATERIALIZED VIEW product_total
ENGINE = AggregatingMergeTree()
PARTITION BY prod_id
ORDER BY (prod_id, type, name)
AS
SELECT prod_id, type, name, sumState(price) AS price
FROM products_orders
GROUP BY prod_id, type, name;-- 插入数据
INSERT INTO products_orders VALUES
(1,1,'过山车玩具', 20000),
(2,2,'火箭',10000);-- 查询结果
SELECT prod_id,type,name,sumMerge(price)
FROM product_total
GROUP BY prod_id, type, name;
当数据源插入 ClickHouse 数据源表,生成 data parts 数据时,就会触发 View 表。View 表会按我们创建时设置的聚合函数,对插入的数据做批量的聚合。每批数据都会生成一条具体的聚合统计结果并写入磁盘。当我们查询统计数据时,ClickHouse 会对这些数据再次聚合汇总,才能拿到最终结果对外做展示。这样就实现了指标统计,这个实现方式很符合 ClickHouse 的引擎思路,这很有特色。
分布式表
最后,我额外分享一个 ClicHouse 的新特性。不过这部分实现还不成熟,所以我们把重点放在这个特性支持什么功能上。ClickHouse 的分布式表,不像 Elasticsearch 那样全智能地帮我们分片调度,而是需要研发手动设置创建,虽然官方也提供了分布式自动创建表和分布式表的语法,但我不是很推荐,因为资源的调配目前还是偏向于人工规划,ClickHouse 并不会自动规划,使用类似的命令会导致 100 台服务器创建 100 个分片,这有些浪费。使用分布式表,我们就需要先在不同服务器手动创建相同结构的分片表,同时在每个服务器创建分布式表映射,这样在每个服务上都能访问这个分布式表。我们通常理解的分片是同一个服务器可以存储多个分片,而 ClickHouse 并不一样,它规定一个表在一个服务器里只能存在一个分片。ClickHouse 的分布式表的数据插入,一般有两种方式。一种是对分布式表插入数据,这样数据会先在本地保存,然后异步转发到对应分片,通过这个方式实现数据的分发存储。第二种是由客户端根据不同规则(如随机、hash),将分片数据推送到对应的服务器上。这样相对来说性能更好,但是这么做,客户端需要知道所有分片节点的 IP。显然,这种方式不利于失败恢复。为了更好平衡高可用和性能,还是推荐你选择前一种方式。但是由于各个分片为了保证高可用,会先在本地存储一份,然后再同步推送,这很浪费资源。面对这种情况,我们比较推荐的方式是通过类似 proxy 服务转发一层,用这种方式解决节点变更及直连分发问题。我们再说说主从分片的事儿。ClickHouse 的表是按表设置副本(主从同步),副本之间支持同步更新或异步同步。主从分片通过分布式表设置在 ZooKeeper 内的相同路径来实现同步,这种设置方式导致 ClickHouse 的分片和复制有很多种组合方式,比如:一个集群内多个子集群、一个集群整体多个分片、客户端自行分片写入数据、分布式表代理转发写入数据等多种方式组合。简单来说,就是 ClickHouse 支持人为做资源共享的多租户数据服务。当我们扩容服务器时,需要手动修改新加入集群分片,创建分布式表及本地表,这样的配置才可以实现数据扩容,但是这种扩容数据不会自动迁移。
总结
ClickHouse 作为 OLAP 的新秀代表,拥有很多独特的设计,它引起了 OLAP 数据库的革命,也引发很多云厂商做出更多思考,参考它的思路来实现 HTAP 服务。通过今天的讲解,相信你也明白 ClickHouse 的关键特性了。我们来回顾一下:ClickHouse 通过分片及内存周期顺序落盘,提高了写并发能力;通过后台定期合并 data parts 文件,提高了查询效率;在索引方面,通过稀疏索引缩小了检索数据的颗粒范围,对于不在主键的查询,则是通过跳数索引来减少遍历数据的数据量;另外,ClickHouse 还有多线程并行读取筛选的设计。这些特性,共同实现了 ClickHouse 大吞吐的数据查找功能。而最近选择 Elasticsearch 还是 ClickHouse 更好的话题,讨论得非常火热,目前来看还没有彻底分出高下。个人建议如果硬件资源丰富,研发人员少的话,就选择 Elasticsearch;硬件资源少,研发人员多的情况,可以考虑试用 ClickHouse;如果硬件和人员都少,建议买云服务的云分布式数据库去做,需要根据团队具体情况来合理地决策。我还特意为你整理了一张评估表格,贴在了文稿里。
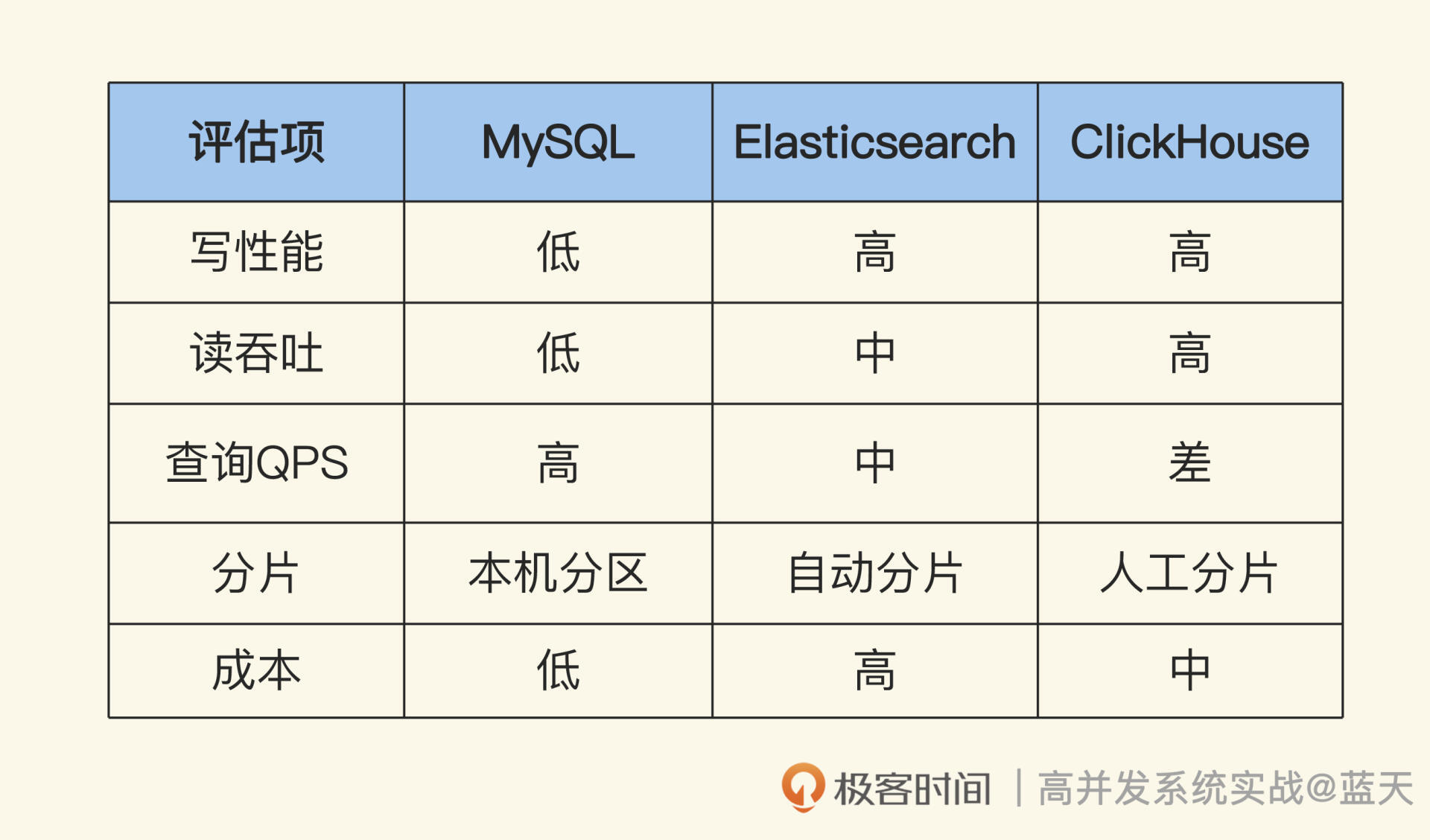
实践方案:如何用C++自实现链路跟踪?
案例背景
2016 年我在微博任职,那时微博有很多重要但复杂的内部系统,由于相互依赖较为严重,并且不能登陆公用集群,每次排查问题的时候都很痛苦。很多问题需要不断加日志试探,三天左右才能摸出眉目。为了更高效地排查线上故障,我们需要一些工具辅助提高排查问题效率,于是我和几个伙伴合作实现了一个分布式链路跟踪的系统。由于那时候,我只有两台 4 核 8G 内存服务器,可用硬件资源不多,所以分布式链路跟踪的存储和计算的功能是通过 C++ 11 实现的。这个项目最大的挑战就是如何在有限的资源下,记录下所有请求过程,并能够实时统计监控线上故障,辅助排查问题。要想做一个这样的系统,主要分为几个关键功能:日志采集、日志传输、日志存储、日志查询、实时性能统计展示以及故障线索收集。经过讨论,我们确定了具体项目实现思路,如下图所示:
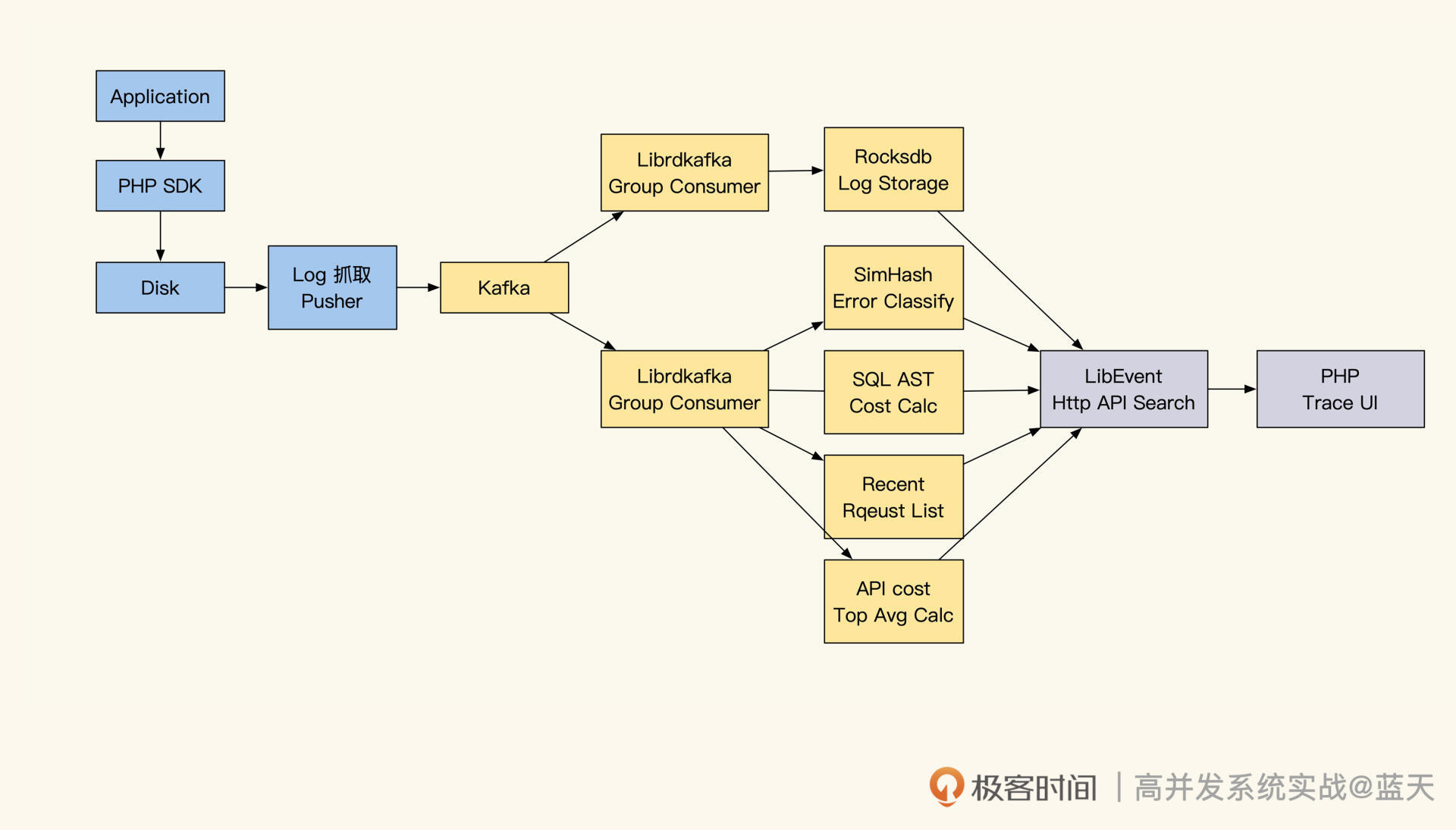
链路跟踪的第一步就是收集日志。当时我看了链路跟踪的相关资料后,决定按分布式链路跟踪思路去设计实现。因为这样做,可以通过每次请求入口产生的的 TraceID,汇集一次请求的所有相关日志。但是具体收集什么日志,才对排查问题更有帮助呢?如果链路跟踪只记录接口的性能,实际就只能辅助我们分析性能问题,对排查逻辑问题意义并不大。经过进一步讨论,我们决定给分级日志和异常日志都带上 TraceID,方便我们获取更多业务过程状态。另外,我们在请求其他服务的请求 Header 内也加上 TraceID 和 RPCID,并且记录了 API、SQL 请求的参数、返回内容和性能数据。综合这些,就能实现完整的全量日志监控跟踪系统,性能问题和逻辑缺陷都能排查。接下来,我们就看看这里的主要功能是怎样实现的。
抓取、采集与传输
日志采集在我们的系统里怎么实现呢?相信你多少能猜到大致做法:一般来说,我们需要在接口被请求时,接收传递过来的 TraceID 以及 RPCID,如果没有传递过来的 TraceID,那么自己可以用 UUID 生成一个,用于标识后续在请求期间所有的日志。
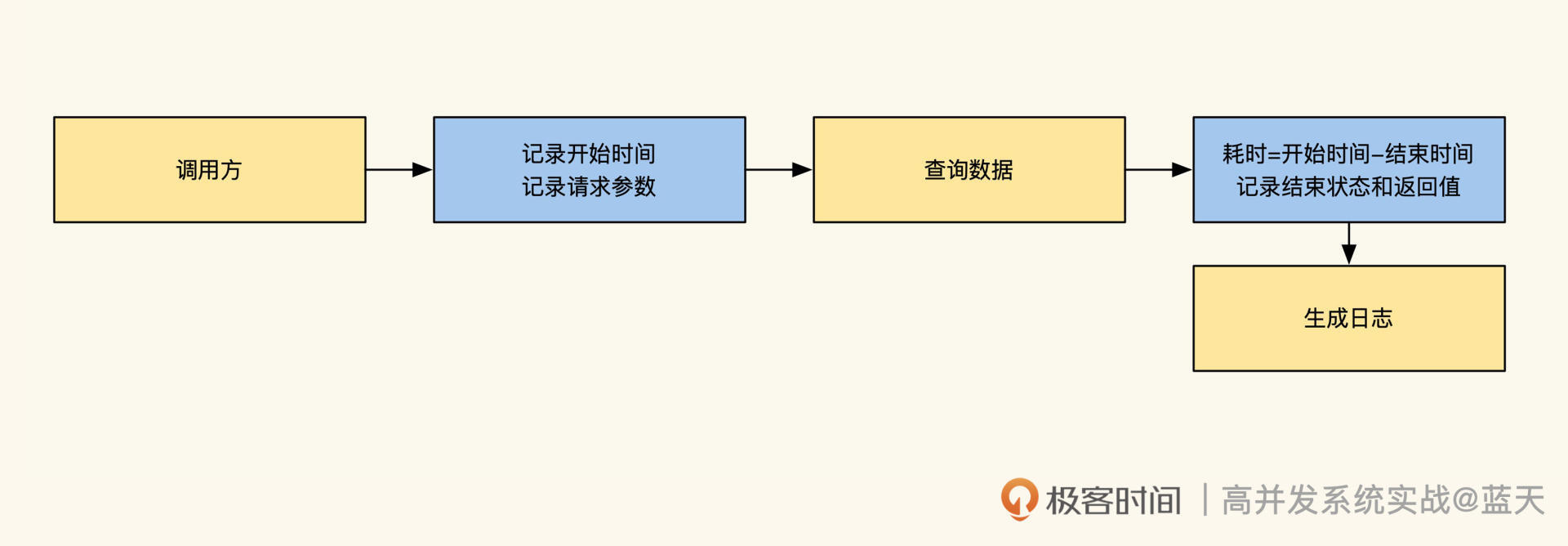
埋点监控示意图
服务被请求时,建议记录一条被调用的访问日志,具体可以记录当前被请求的参数以及接口最后返回的结果、httpcode、耗时。通过这个日志,后续可以方便我们分析服务的性能和故障。
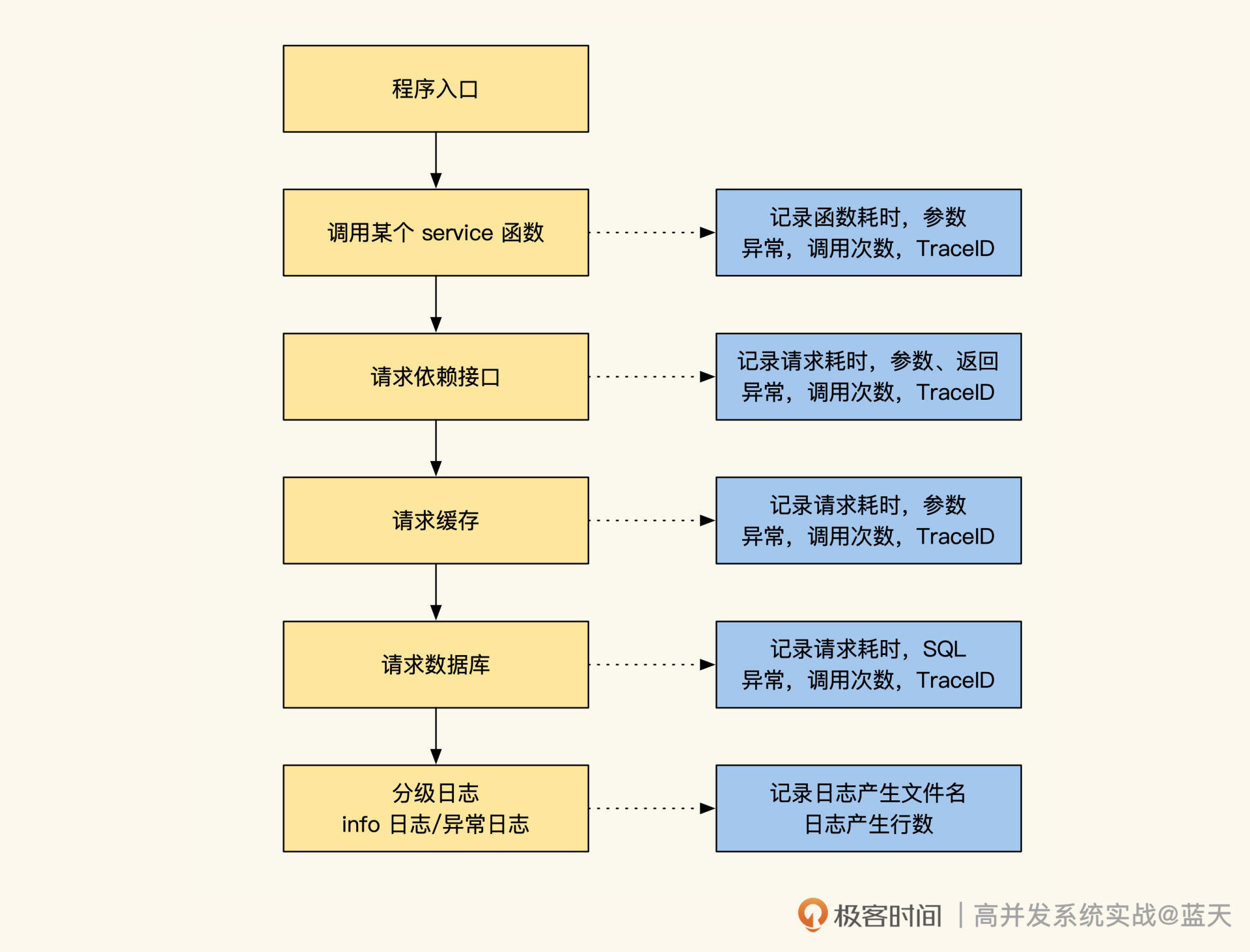
所有非本地的依赖资源都要记录日志
而对于被请求期间的业务所产生的业务日志、错误日志,以及请求其他资源的日志,都需要做详细记录,比如 SQL 查询记录、API 请求记录以及这些请求的参数、返回、耗时。
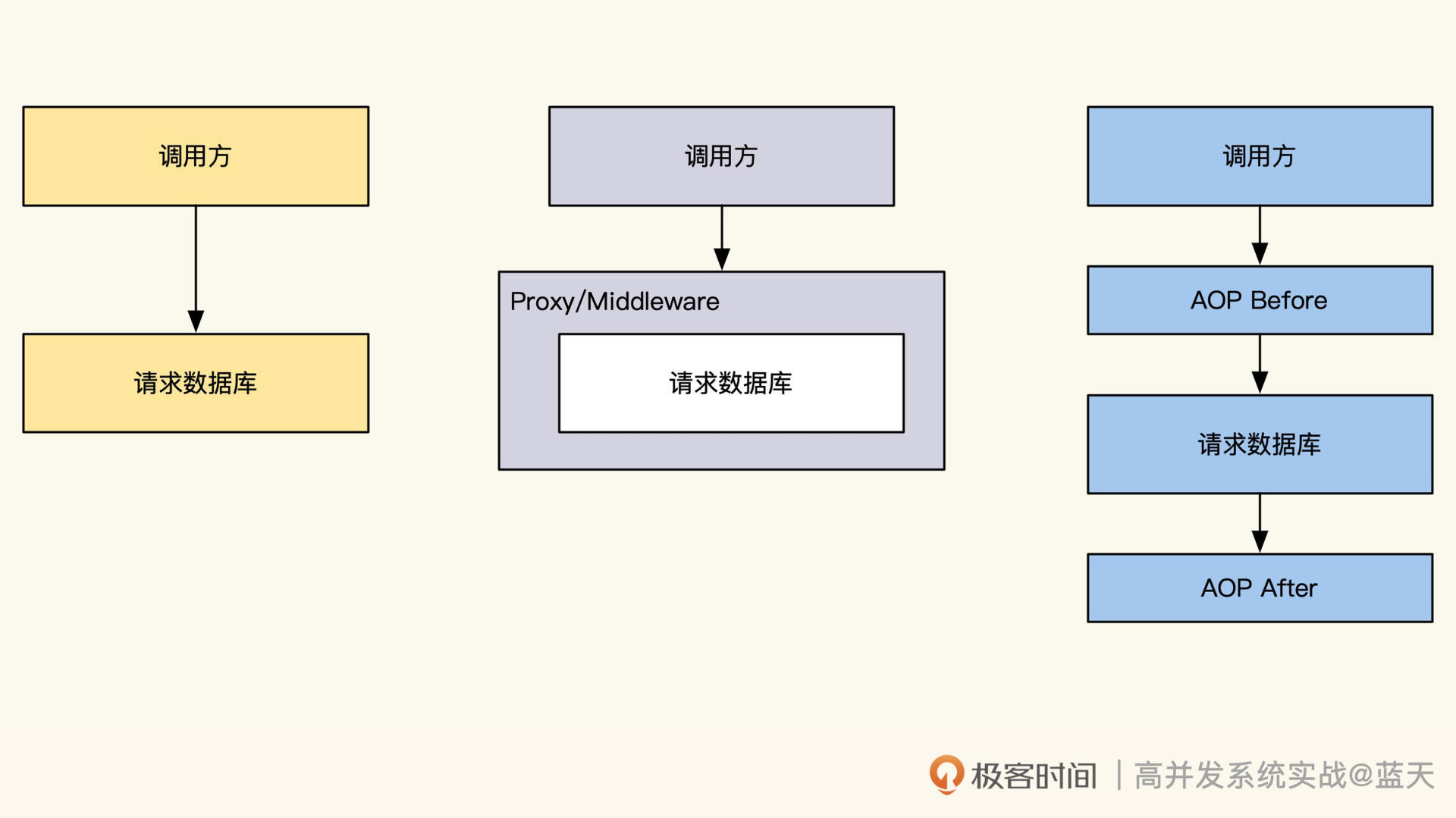
直接请求、中间件以及 AOP 的切面效果
无论我们想做链路跟踪还是统计系统服务状态,都需要做类似 AOP 切面拦截,通过切面编程抓取所有操作数据库或 API 请求前后的数据。为了更好理解这里给你提供一个 AOP 的实现样例,这是我之前在生产环境中使用的。记录了项目的请求依赖资源部分之后,我用了两个传输方式来传输生成的日志:一个是通过 memcache 的长链接协议,将日志推送到我们日志收集服务上,这种推送日志请求超时超过 200ms 就会丢弃,这样能避免拖慢接口的性能。另外一个方式是落地到本地磁盘,通过 Filebeat 实时抓取推送,将日志收集汇总起来。当然,第二种方式最稳定,但是由于我们公共服务器集群不让登录的限制,有一部分系统只能使用第一种方式来传递日志。前面提到,由于跟踪的都是核心系统,并且业务都很复杂,所以我们对所有的请求过程和参数返回都做了记录。可以预见,这样的方式产生的日志量很大,而且日志的写并发吞吐很高,甚至支付系统在某次服务高峰时会出现日志写 100MB/s 的情况。因此我们的日志写入及传输都需要有很好的性能服务支持,同时还要保证日志不会丢失。为此,我们选择了用 Kafka 来传输日志,Kafka 通过对同一个 topic 数据做多个分区动态调配来实现负载均衡及动态扩容,当我们流量超过其承受能力时,可以随时通过给服务器群组增加服务器来扩容,从而提供更好的吞吐量。可以说多系统之间的实时高吞吐传输同步,几乎都是使用 Kafka 实现的。
可动态扩容的分组消费
那么 Kafka 是如何帮助业务动态扩容消费性能的呢?
Kafka 分组消费,不同的进程个数,分配的消费分区不同
在 Kafka 消费这里使用的是 Consumer Group 分组消费,分组消费是一个很棒的实现,我们可以让多个服务同时消费一组数据,比如:启动两个进程消费 20 个分区的数据,也就是一个服务负责消费 10 个区的数据。如果服务运转期间消费能力不够了,消息出现堆积,我们可以找两台服务器新启动 2 个消费进程,此时 Kafka 会对 consumer 进程自动重新调度(rebalance),让四个消费进程平分 20 个分区,即自动调度成每个消费进程消费 5 个分区的数据。通过这个功能,我们可以动态扩容消费服务器的能力,比如随时增加消费进程数来提高消费能力,甚至一些消费服务可以随时重启。这个功能可以让我们动态扩容变得更容易,对于写并发大的数据流传输或同步的服务帮助很大,几乎大部分最终一致性的数据服务,最终都是靠分布式队列来实现的。微博内部很多系统间的数据同步,最后都改成了使用 kafka 去做同步。基于 Kafka 的分组特性,我们将服务做成了两组消费服务,一组用于数据的统计,一组用于存储,通过这个方式隔离存储和实时统计服务。
写多读少的 RocksDB
接下来,我们重点说说分布式存储怎么处理,因为这是自实现最有特色的地方。另外,计算部分的实现和第十三节课的情况大同小异,你可以点这里回看。考虑到只有两台存储服务器,我需要提供一个写性能很好并支持“检索”的日志存储检索服务,经过查找和对比,最终我选择了 RocksDB。RocksDB 是 Facebook 做实验出来的产品,后经不断完善,最终被大量用户使用。它提供了超越 LevelDB 写性能的服务,能够在 Flash、磁盘、HDFS 媒介上存储,并且能够充分利用多核以及 SSD 提供更高性能的高负载数据存储服务。由于 Rocksdb 是嵌入式的,所以我们实现的服务和存储引擎之间没有网络消耗,性能会更好,再配合上 Kafka 分组消费,就可以实现一个无副本的分布式存储。我首先看中的是 RocksDB 这个引擎的写性能。回想一下我们第十节课讲过的内容,RocksDB 利用了内存做缓存,同时利用磁盘顺序写性能最强的特性,能够提供接近单机 300M/s 的写数据能力,理想情况下,两台存储服务器就可以提供 600M/s 的写入能力。再加上 Kafka 缓解写高峰压力,这个设计已经能满足大部分业务需求了。其次,RocksDB 的接入非常简单,想要在项目中引入它的库,只要保证它的写操作只有一个线程写,其他线程可以实例化 Secondary 只读即可。此外,RocksDB 还支持内存和磁盘冷热数据的自动管理、存储数据压缩等功能,而且单个库就能存储上 TB 的数据、单个 Value 长度能够达到 3G,这非常适合在分布式链路跟踪的系统里存储和查找大量的文本日志。接下来要解决的问题就是,如何在 RocksdDB 分配管理我们的 Trace 日志。为了提高查询效率,并且只保留 7 天日志,我们选择了按天保存日志,一天一个 RocksDB 库,过期的数据库可以删除或归档到 HDFS 内。汇总保存日志的时候,我们利用了 RocksDB 的这两个方面的特性。一方面通过 Trace 日志的 TraceID 作为 key 来存储,这样我们直接通过 TraceID 就可以查到所有相关日志。另一方面,是利用 Merge 操作对 KV 中的 value 实现 string append。Merge 是 RocksDB 里很少有人提到的一个功能,但用起来还不错,可以帮我们把所有日志高性能地追加到一个 Key内。Merge 操作的官方 demo 代码你可以从这里获取,如果对于实现原理感兴趣,还可以参考下 rocksdb-merge-operators。
分布式查询与计算
数据存储好后,如何查询呢?事实上很简单,我们的 Trace SDK 会让每个接口返回响应内容的同时,在 header 中包含了 TraceID,debug 的时候使用返回 traceId 进行查询时,界面会对所有存储节点发送查询请求,通过 TraceID 从 RocksDB 拿出所有按回车分割的日志后,汇总排序即可。另外,日志存储服务集成了 Libevent,通过它实现了 HTTP 和 Memcache 协议的查询接口服务,由于这里比较复杂有多个模式,这里不对这个做详细介绍了,如果你想了解如何用 epoll 和 Socket 实现一个简单的 HTTP 服务,具体可以看看我闲暇时写的小 demo 。我再补充说一下,怎么对多节点数据进行查询。由于读操作很少,我们可以通过异步请求多个存储实例直接问询查询内容,再到协调节点进行汇总排序即可。说完了数据查询,我们再聊聊分布式计算。想要实现服务器状态统计计算,核心还是利用 Kafka 的分组消费,另外启动一组服务消费日志内容,在内存中对日志进行汇总计算。如果想采样服务器的请求情况,可以定期按时间块索引随机采 1000 个 TraceID 到 RocksDB 的时间块索引内,需要展示的时候,将它们取出聚合展示即可。关于实时计算的算法和思路,我在第十三节课中已经讲过了,你可以去回顾一下。关于自实现的整体思路我们聊完了。看完以后你可能会好奇,现在硬件资源已经很充裕了,我还用学习这些吗?事实上,在硬件资源充裕的时代我们还是要考虑成本。我们推算一下,比如 2000 台服务器性能提升一倍,就能节省 1000 台服务器。如果一台每年 1w 维护费用,那么就是每年能节省 1000w。架构师除了解决业务问题外,大部分时间都是在思考如何在保证服务稳定的情况下降低成本。另外,我再说说选择开源的一些建议。由于市面很多开源是共建的,并且有一些开源属于个人的习作,没有在生产环境验证过。我们要尽量选择在生产环境验证过的、活跃的社区功能。虽然之前我使用 C++ 实现链路跟踪,但现在技术发展得很快,如果放在今天,我是不推荐你也用同样方法做这个服务的。实践的时候,你可以考虑使用 Java、GO、Rust 等语言去尝试,相信这样会让你节省大量的时间。
总结
这节课我和你分享了我用 C++ 实现链路跟踪的实践方案,其中的技术要点你可以参考下图。
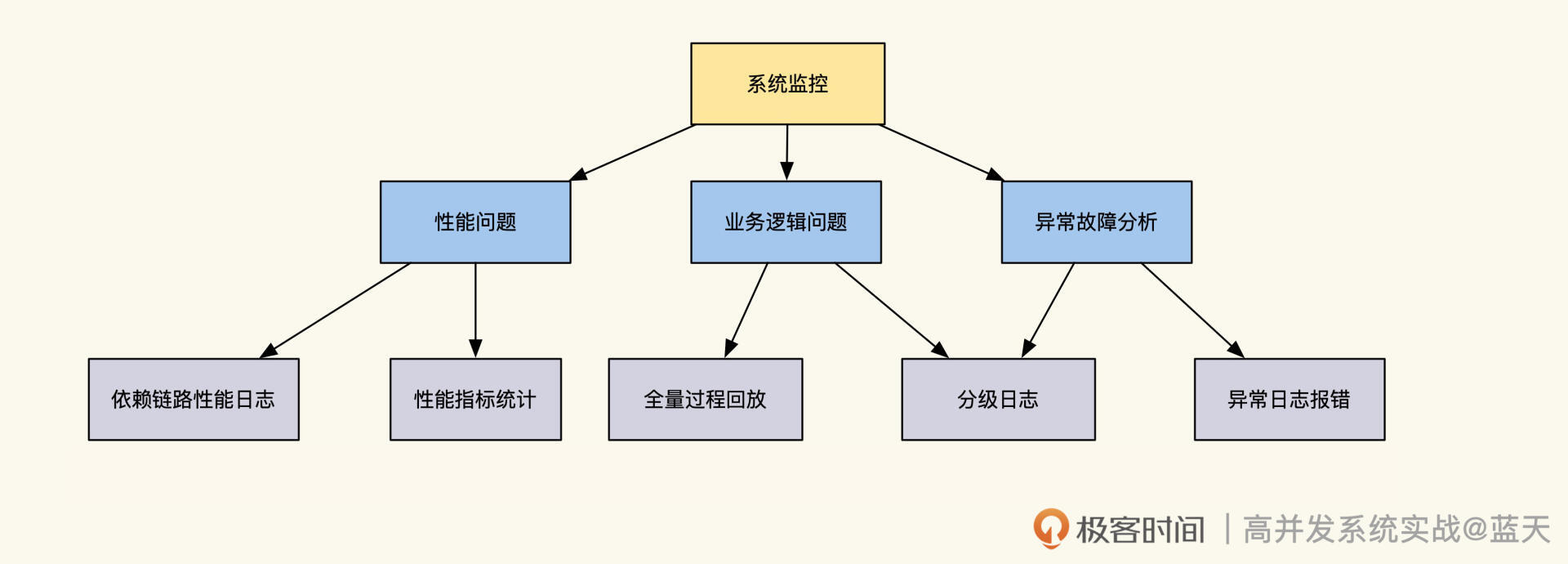
监控跟踪的对应思路
写多读少的系统,普遍会用分布式的队列服务(类似 Kafka)汇总数据,配合多台服务器或分片来消费加工数据,通过这样的架构来应对数据洪流。这一章我们详细分析了写多读少系统的几种方案,你会发现它们各有千秋。为了方便你对比学习,我引入了 MySQL 作为参考。你也可以参考后面这张表格的思路,把技术实现的关键点(比如数据传输、写入、分片、扩容、查询等等)列出来,通过这种方式,可以帮你快速分析出哪种技术实现更匹配自己项目的业务需要。
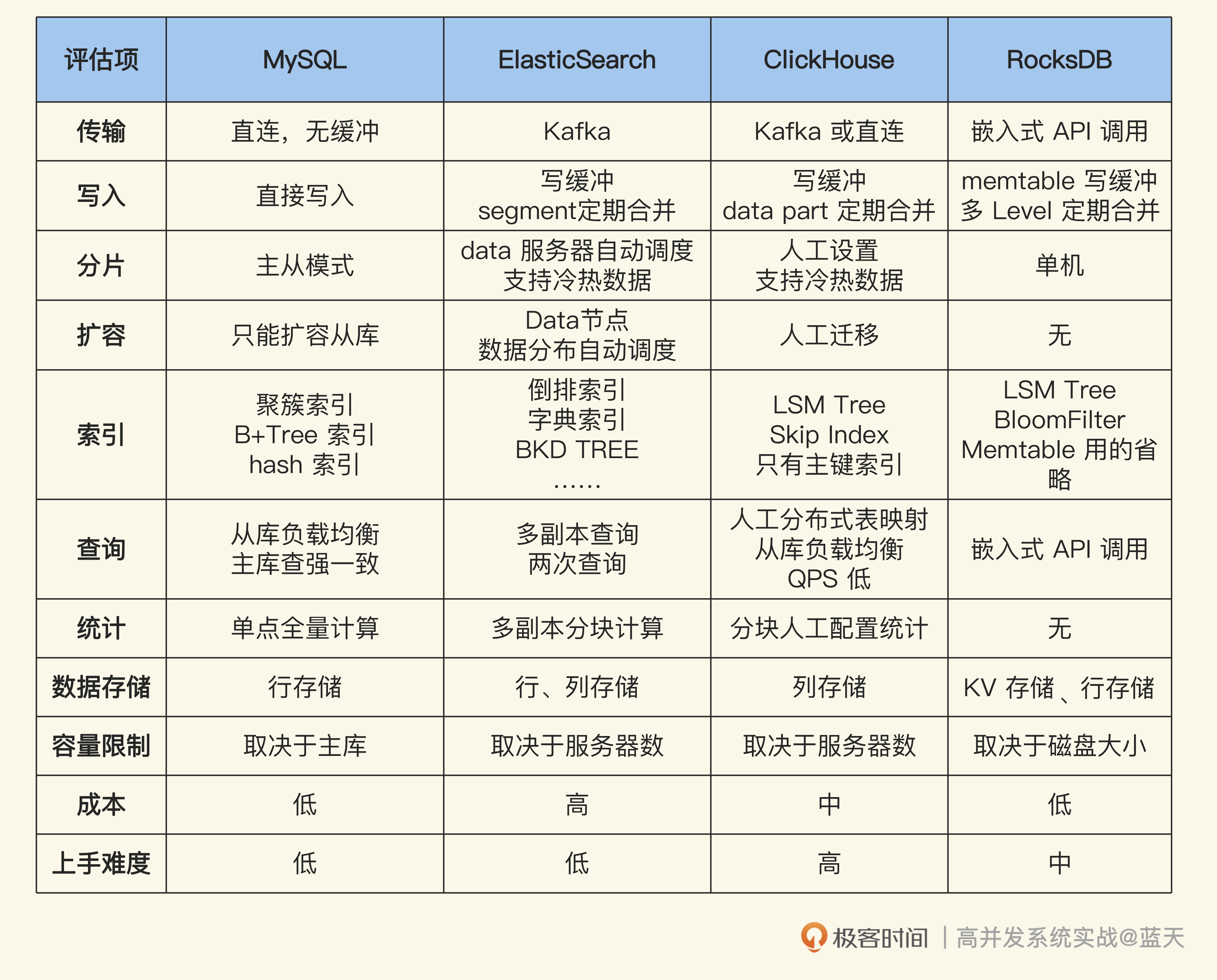
直播互动:读多写多系统如何实现
本地缓存:用本地缓存做服务会遇到哪些坑?
这一章我们来学习如何应对读多写多的系统。微博 Feed、在线游戏、IM、在线课堂、直播都属于读多写多的系统,这类系统里的很多技术都属于行业天花板级别,毕竟线上稍有点问题,都极其影响用户体验。说到读多写多不得不提缓存,因为目前只有缓存才能够提供大流量的数据服务,而常见的缓存架构,基本都会使用集中式缓存方式来对外提供服务。但是,集中缓存在读多写多的场景中有上限,当流量达到一定程度,集中式缓存和无状态服务的大量网络损耗会越来越严重,这导致高并发读写场景下,缓存成本高昂且不稳定。为了降低成本、节省资源,我们会在业务服务层再增加一层缓存,放弃强一致性,保持最终一致性,以此来降低核心缓存层的读写压力。
虚拟内存和缺页中断
想做好业务层缓存,我们需要先了解一下操作系统底层是如何管理内存的。对照后面这段 C++ 代码,你可以暂停思考一下,这个程序如果在环境不变的条件下启动多次,变量内存地址输出是什么样的?
int testvar = 0;
int main(int argc, char const *argv[])
{testvar += 1;sleep(10);printf("address: %x, value: %d\n", &testvar, testvar );return 0;
}
答案可能出乎你的意料,试验一下,你就会发现变量内存地址输出一直是固定的,这证明了程序见到的内存是独立的。如果我们的服务访问的是物理内存,就不会发生这种情况。为什么结果是这样呢?这就要说到 Linux 的内存管理方式,它用虚拟内存的方式管理内存,因此每个运行的进程都有自己的虚拟内存空间。回过头来看,我们对外提供缓存数据服务时,如果想提供更高效的并发读写服务,就需要把数据放在本地内存中,一般会实现为一个进程内的多个线程来共享缓存数据。不过在这个过程中,我们还会遇到缺页问题,我们一起来看看。
虚拟内存及 page fault
如上图所示,我们的服务在 Linux 申请的内存不会立刻从物理内存划分出来。系统数据修改时,才会发现物理内存没有分配,此时 CPU 会产生缺页中断,操作系统才会以 page 为单位把物理内存分配给程序。系统这么设计,主要是为了降低系统的内存碎片,并且减少内存的浪费。不过系统分配的页很小,一般是 4KB,如果我们一次需要把 1G 的数据插入到内存中,写入数据到这块内存时就会频繁触发缺页中断,导致程序响应缓慢、服务状态不稳定的问题。所以,当我们确认需要高并发读写内存时,都会先申请一大块内存并填 0,然后再使用,这样可以减少数据插入时产生的大量缺页中断。我额外补充一个注意事项,这种申请大内存并填 0 的操作很慢,尽量在服务启动时去做。前面说的操作虽然立竿见影,但资源紧张的时候还会有问题。现实中很多服务刚启动就会申请几 G 的内存,但是实际运行过程中活跃使用的内存不到 10%,Linux 会根据统计将我们长时间不访问的数据从内存里挪走,留出空间给其他活跃的内存使用,这个操作叫 Swap Out。为了降低 Swap Out 的概率,就需要给内存缓存服务提供充足的内存空间和系统资源,让它在一个相对专用的系统空间对外提供服务。但我们都知道内存空间是有限的,所以需要精心规划内存中的数据量,确认这些数据会被频繁访问。我们还需要控制缓存在系统中的占用量,因为系统资源紧张时 OOM 会优先杀掉资源占用多的服务,同时为了防止内存浪费,我们需要通过 LRU 淘汰掉一些不频繁访问的数据,这样才能保证资源不被浪费。即便这样做还可能存在漏洞,因为业务情况是无法预测的。所以建议对内存做定期扫描续热,以此预防流量突增时触发大量缺页中断导致服务卡顿、最终宕机的情况。
程序容器锁粒度
除了保证内存不放冷数据外,我们放在内存中的公共数据也需要加锁,如果不做互斥锁,就会出现多线程修改不一致的问题。如果读写频繁,我们常常会对相应的 struct 增加单条数据锁或 map 锁。但你要注意,锁粒度太大会影响到我们的服务性能。因为实际情况往往会和我们预计有一些差异,建议你在具体使用时,在本地多压测测试一下。就像我之前用 C++ 11 写过一些内存服务,就遇到过读写锁性能反而比不上自旋互斥锁,还有压缩传输效率不如不压缩效率高的情况。那么我们再看一下业务缓存常见的加锁方式。
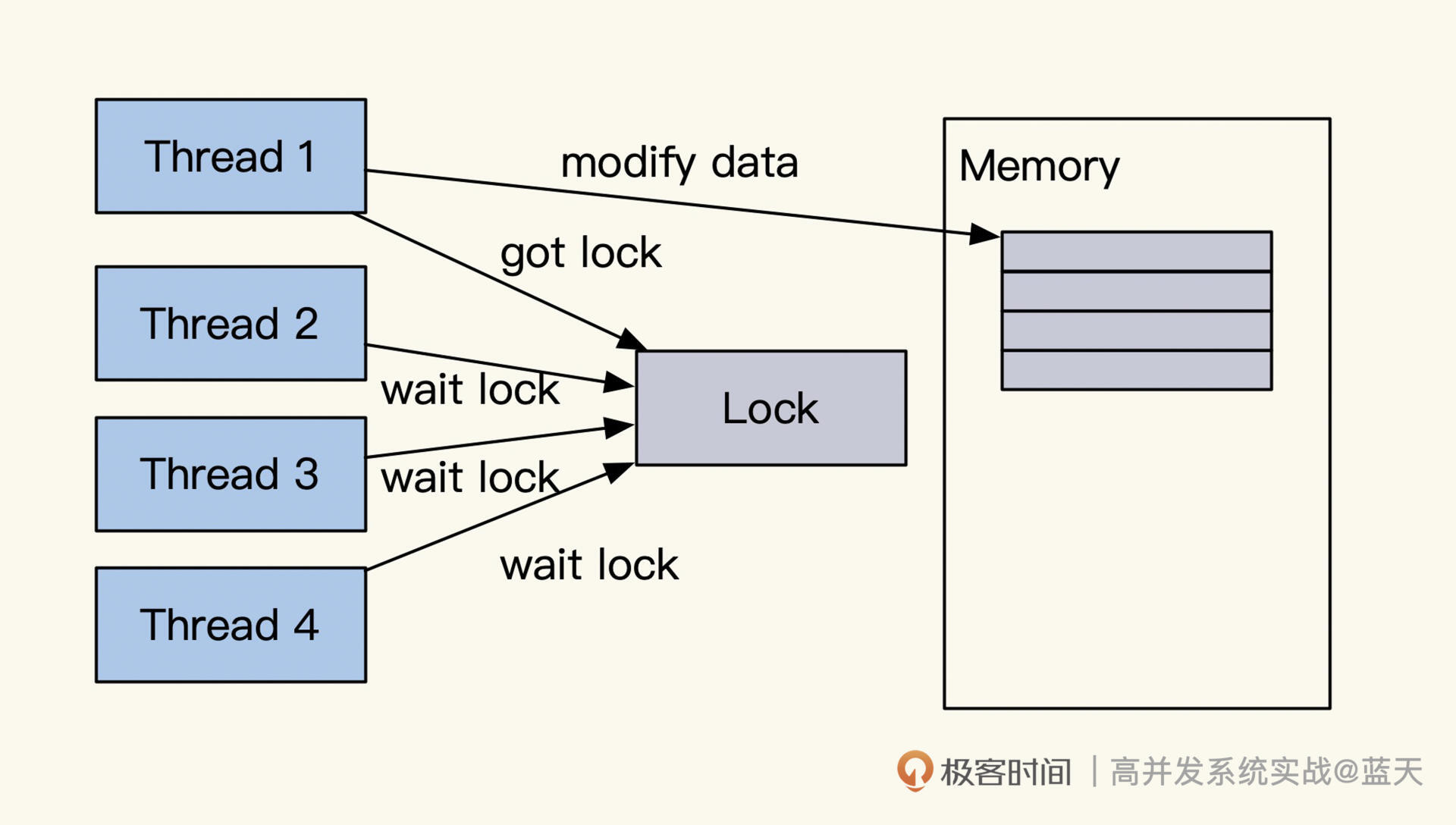
多线程修改一个数据,配一个锁
为了减少锁冲突,我常用的方式是将一个放大量数据的经常修改的 map 拆分成 256 份甚至更多的分片,每个分片会有一个互斥锁,以此方式减少锁冲突,提高并发读写能力。
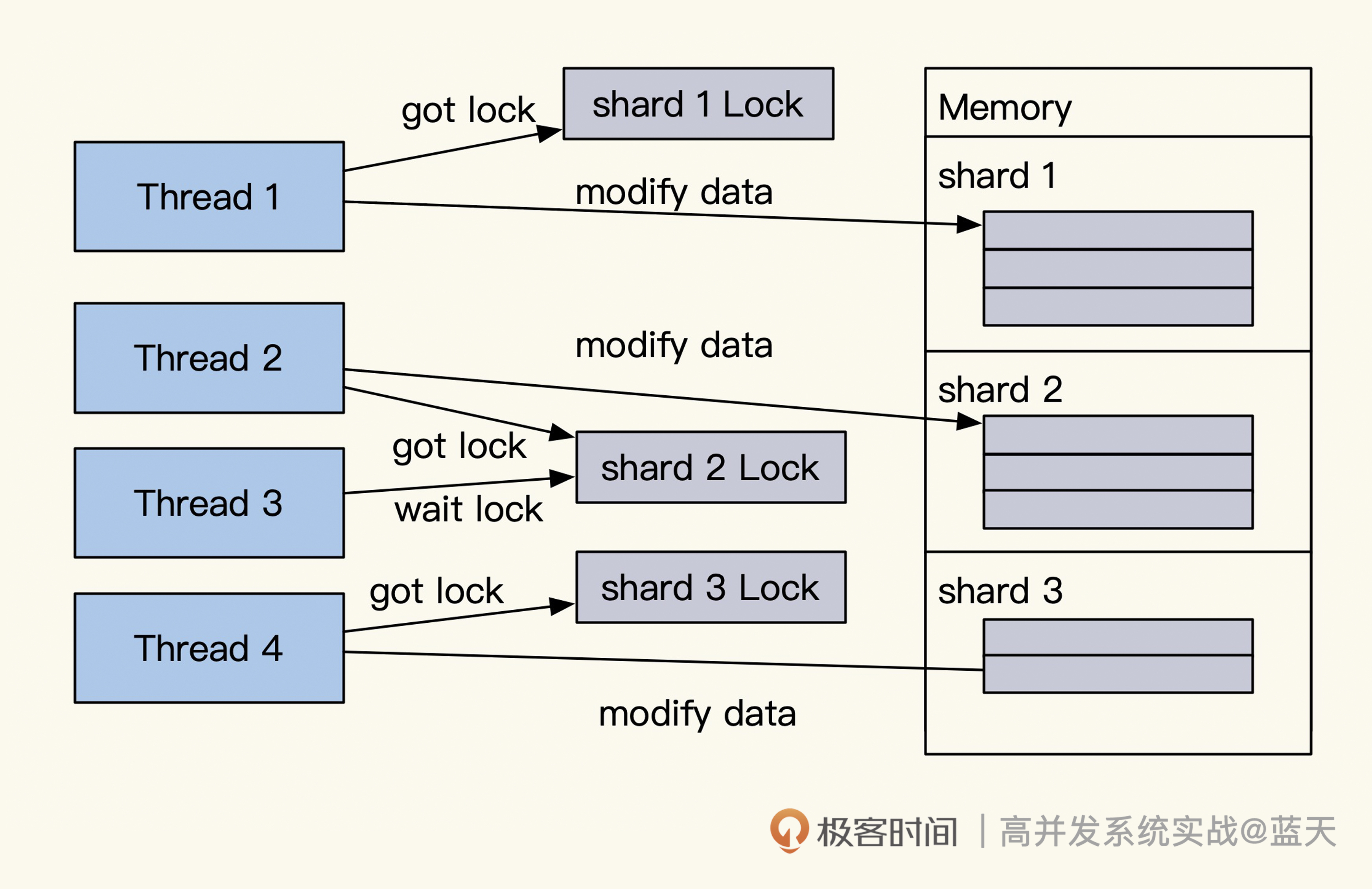
多线程 多个分块锁
除此之外还有一种方式,就是将我们的修改、读取等变动只通过一个线程去执行,这样能够减少锁冲突加强执行效率,我们常用的 Redis 就是使用类似的方式去实现的,如下图所示:
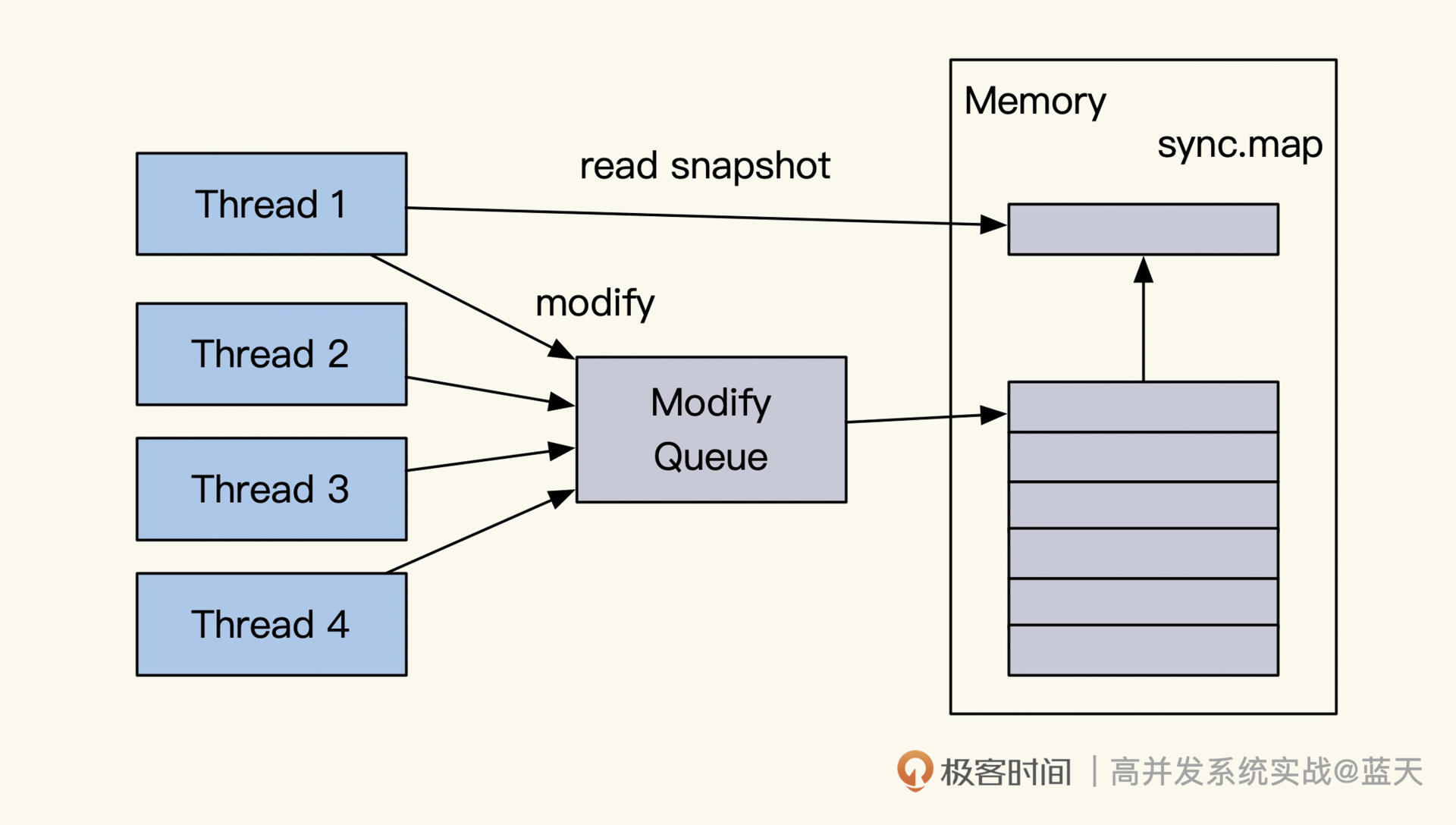
单线程更新,配合 sync.map
如果我们接受半小时或一小时全量更新一次,可以制作 map,通过替换方式实现数据更新。具体的做法是用两个指针分别指向两个 map,一个 map 用于对外服务,当拿到更新数据离线包时,另一个指针指向的 map 会加载离线全量数据。加载完毕后,两个 map 指针指向互换,以此实现数据的批量更新。这样实现的缓存我们可以不加互斥锁,性能会有很大的提升。
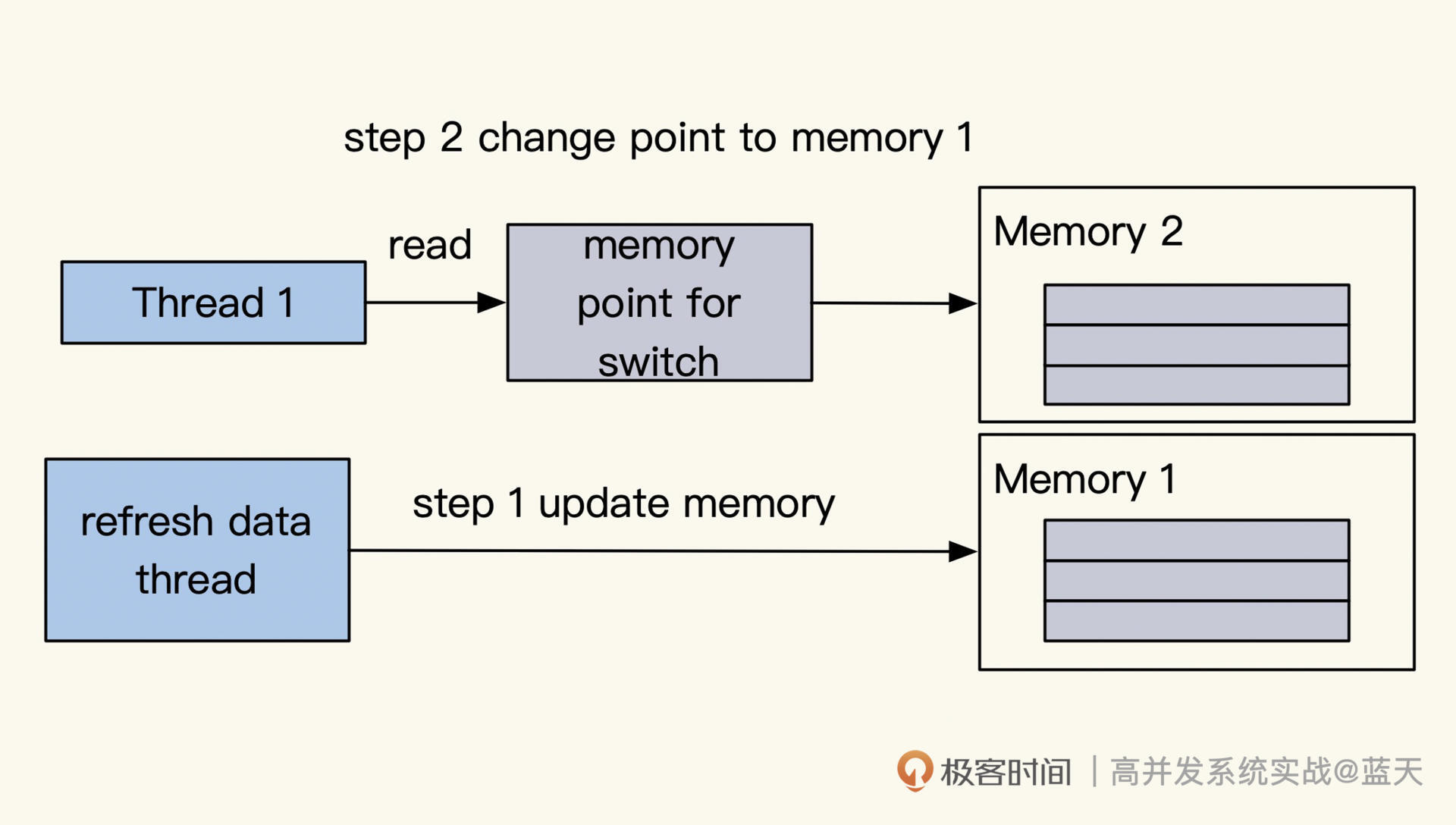
第一步,更新内存 1,并切换阅读指针
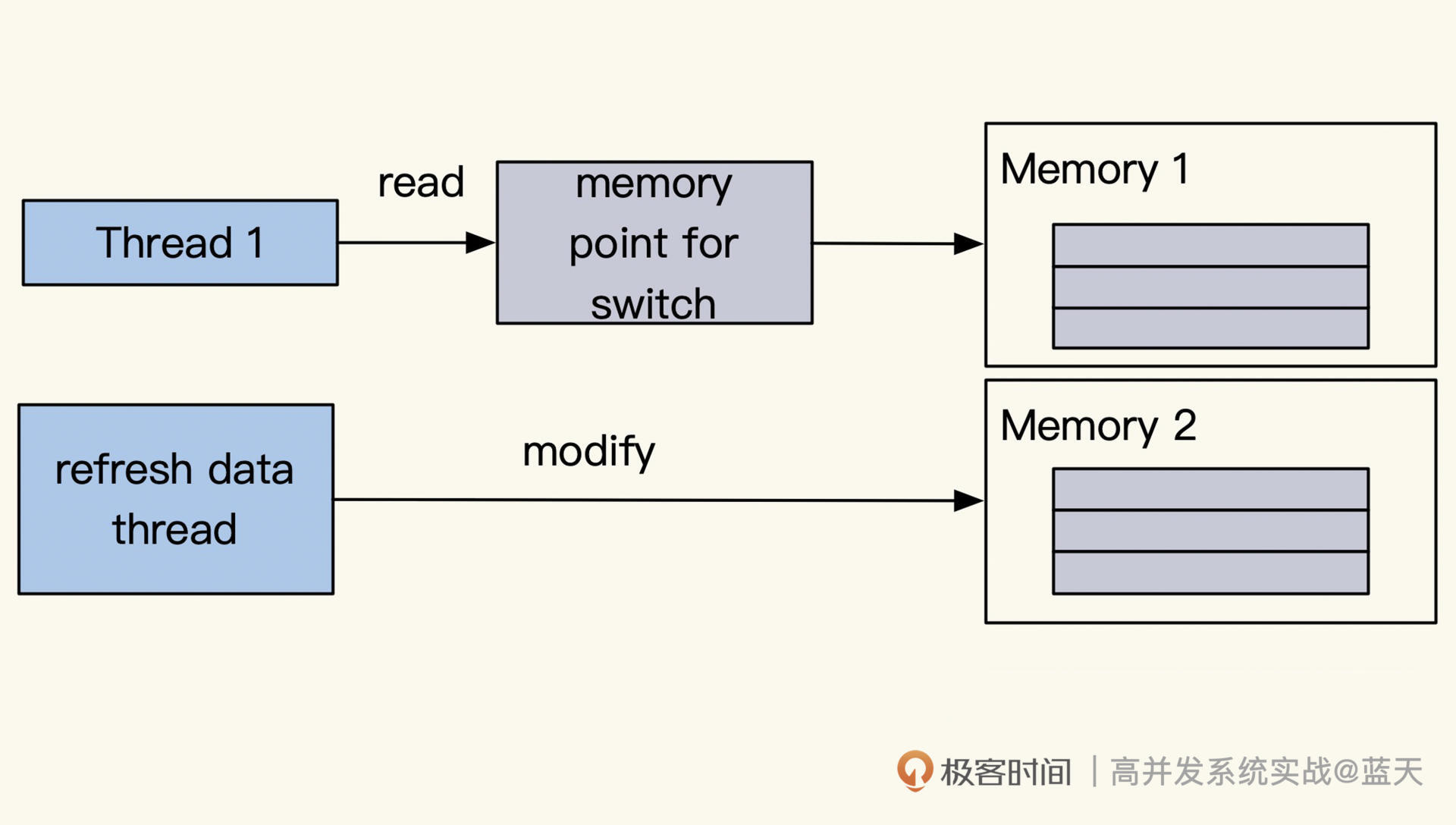
切换后效果,对外提供 memory 1 的数据,开始更新内存 2
当然行业也存在一些无锁的黑科技,这些方法都可以减少我们的锁争抢,比如 atomic、Go 的 sync.Map、sync.Pool、Java 的 volidate。感兴趣的话,你可以找自己在用的语言查一下相关知识。除此之外,无锁实现可以看看 MySQL InnoDB 的 MVCC。
GC 和数据使用类型
当做缓存时,我们的数据 struct 直接放到 map 一类的容器中就很完美了吗?事实上我并不建议这么做。这个回答可能有些颠覆你的认知,但看完后面的分析你就明白了。当我们将十万条数据甚至更多的数据放到缓存中时,编程语言的 GC 会定期扫描这些对象,去判断这些对象是否能够回收。这个机制导致 map 中的对象越多,服务 GC 的速度就会越慢。因此,很多语言为了能够将业务缓存数据放到内存中,做了很多特殊的优化,这也是为什么高级语言做缓存服务时,很少将数据对象放到一个大 map 中。这里我以 Go 语言为例带你看看。为了减少扫描对象个数,Go 对 map 做了一个特殊标记,如果 map 中没有指针,则 GC 不会遍历它保存的对象。为了方便理解举个例子:我们不再用 map 保存具体的对象数据,只是使用简单的结构作为查询索引,如使用 map[int]int,其中 key 是 string 通过 hash 算法转成的 int,value 保存的内容是数据所在的 offset 和长度。对数据做了序列化后,我们会把它保存在一个很长的 byte 数组中,通过这个方式缓存数据,但是这个实现很难删除修改数据,所以删除的一般只是 map 索引记录。
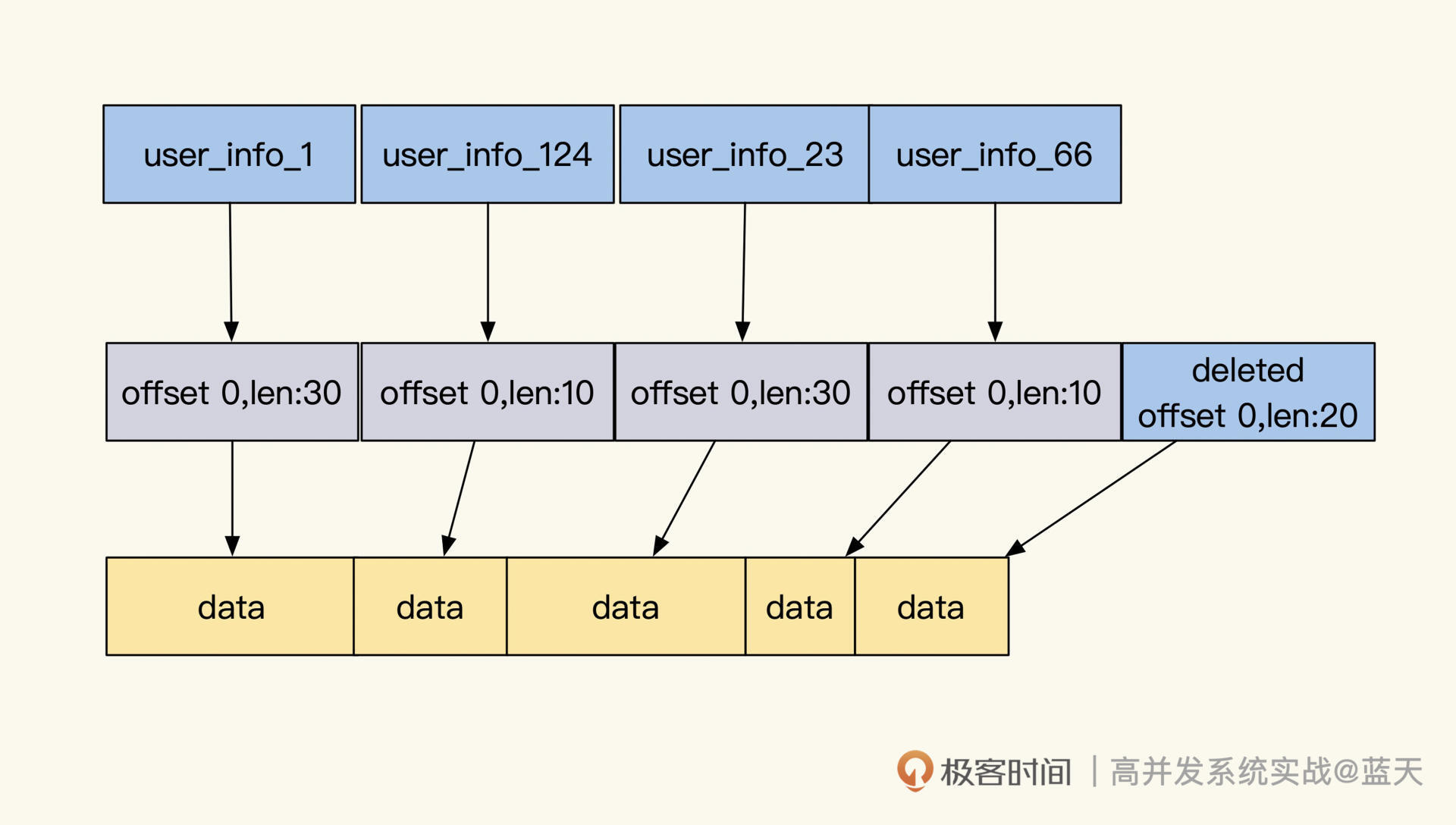
索引、位置映射和保存在数组的数据关系
这也导致了我们做缓存时,要根据缓存的数据特点分情况处理。如果我们的数据量少,且特点是读多写多(意味着会频繁更改),那么将它的 struct 放到 map 中对外服务更合理;如果我们的数据量大,且特点是读多写少,那么把数据放到一个连续内存中,通过 offset 和 length 访问会更合适。分析了 GC 的问题之后,相信你已经明白了很多高级语言宁可将数据放到公共的基础服务中,也不在本地做缓存的原因。如果你仍旧想这么做,这里我推荐一个有趣的项目 XMM供你参考,它是一个能躲避 Golang GC 的内存管理组件。事实上,其他语言也存在类似的组件,你可以自己探索一下。
内存对齐
前面提到,数据放到一块虚拟地址连续的大内存中,通过 offse 和 length 来访问不能修改的问题,这个方式其实还有一些提高的空间。在讲优化方案前,我们需要先了解一下内存对齐,在计算机中很多语言都很关注这一点,究其原因,内存对齐后有很多好处,比如我们的数组内所有数据长度一致的话,就可以快速对其定位。举个例子,如果我想快速找到数组中第 6 个对象,可以用如下方式来实现:sizeof(obj) * index => offset使用这个方式,要求我们的 struct 必须是定长的,并且长度要按 2 的次方倍数做对齐。另外,也可以把变长的字段,用指针指向另外一个内存空间

通过这个方式,我们可以通过索引直接找到对象在内存中的位置,并且它的长度是固定的,无需记录 length,只需要根据 index 即可找到数据。这么设计也可以让我们在读取内存数据时,能快速拿到数据所在的整块内存页,然后就能从内存快速查找要读取索引的数据,无需读取多个内存页,毕竟内存也属于外存,访问次数少一些更有效率。这种按页访问内存的方式,不但可以快速访问,还更容易被 CPU L1、L2 缓存命中。
SLAB 内存管理
除了以上的方式外,你可能好奇过,基础内存服务是怎么管理内存的。我们来看后面这个设计。
如上图,主流语言为了减少系统内存碎片,提高内存分配的效率,基本都实现了类似 Memcache 的伙伴算法内存管理,甚至高级语言的一些内存管理库也是通过这个方式实现的。我举个例子,Redis 里可以选择用 jmalloc 减少内存碎片,我们来看看 jmalloc 的实现原理。jmalloc 会一次性申请一大块儿内存,然后将其拆分成多个组,为了适应我们的内存使用需要,会把每组切分为相同的 chunk size,而每组的大小会逐渐递增,如第一组都是 32byte,第二组都是 64byte。需要存放数据的时候,jmalloc 会查找空闲块列表,分配给调用方,如果想放入的数据没找到相同大小的空闲数据块,就会分配容量更大的块。虽然这么做有些浪费内存,但可以大幅度减少内存的碎片,提高内存利用率。很多高级语言也使用了这种实现方式,当本地内存不够用的时候,我们的程序会再次申请一大块儿内存用来继续服务。这意味着,除非我们把服务重启,不然即便我们在业务代码里即使释放了临时申请的内存,编程语言也不会真正释放内存。所以,如果我们使用时遇到临时的大内存申请,务必想好是否值得这样做。
总结学完这节课,你应该明白,为什么行业中,我们都在尽力避免业务服务缓存应对高并发读写的情况了。因为我们实现这类服务时,不但要保证当前服务能够应对高并发的网络请求,还要减少内部修改和读取导致的锁争抢,并且要关注高级语言 GC 原理、内存碎片、缺页等多种因素,同时我们还要操心数据的更新、一致性以及内存占用刷新等问题。
即便特殊情况下我们用上了业务层缓存的方式,在业务稳定后,几乎所有人都在尝试把这类服务做降级,改成单纯的读多写少或写多读少的服务。更常见的情况是,如果不得不做,我们还可以考虑在业务服务器上启动一个小的 Redis 分片去应对线上压力。当然这种方式,我们同样需要考虑清楚如何做数据同步。
业务脚本:为什么说可编程订阅式缓存服务更有用?
我们已经习惯了使用缓存集群对数据做缓存,但是这种常见的内存缓存服务有很多不方便的地方,比如集群会独占大量的内存、不能原子修改缓存的某一个字段、多次通讯有网络损耗。很多时候我们获取数据并不需要全部字段,但因为缓存不支持筛选,批量获取数据的场景下性能就会下降很多。这些问题在读多写多的场景下,会更加明显。有什么方式能够解决这些问题呢?这节课,我就带你了解另外一种有趣的数据缓存方式——可编程订阅式缓存服务。学完今天的内容,相信你会对缓存服务如何做产生新的思考。
缓存即服务
可编程订阅式缓存服务的意思是,我们可以自行实现一个数据缓存服务直接提供给业务服务使用,这种实现能够根据业务的需要,主动缓存数据并提供一些数据整理和计算的服务。自实现的数据缓存服务虽然繁琐,但同时也有很多优势,除去吞吐能力的提升,我们还可以实现更多有趣的定制功能,还有更好的计算能力,甚至可以让我们的缓存直接对外提供基础数据的查询服务。
自实现缓存功能结构图
上图是一个自实现的缓存功能结构,可以说这种缓存的性能和效果更好,这是因为它对数据的处理方式跟传统模式不同。传统模式下,缓存服务不会对数据做任何加工,保存的是系列化的字符串,大部分的数据无法直接修改。当我们使用这种缓存对外进行服务时,业务服务需要将所有数据取出到本地内存,然后进行遍历加工方可使用。而可编程缓存可以把数据结构化地存在 map 中,相比传统模式序列化的字符串,更节省内存。更方便的是,我们的服务无需再从其他服务取数据来做计算,这样会节省大量网络交互耗时,适合用在实时要求极高的场景里。如果我们的热数据量很大,可以结合 RocksDB 等嵌入式引擎,用有限的内存提供大量数据的服务。除了常规的数据缓存服务外,可编程缓存还支持缓存数据的筛选过滤、统计计算、查询、分片、数据拼合。关于查询服务, 我补充说明一下,对外的服务建议通过类似 Redis 的简单文本协议提供服务,这样会比 HTTP 协议性能会更好。
Lua 脚本引擎
虽然缓存提供业务服务能提高业务灵活度,但是这种方式也有很多缺点,最大的缺点就是业务修改后,我们需要重启服务才能够更新我们的逻辑。由于内存中保存了大量的数据,重启一次数据就需要繁琐的预热,同步代价很大。为此,我们需要给设计再次做个升级。这种情况下,lua 脚本引擎是个不错的选择。lua 是一个小巧的嵌入式脚本语言,通过它可以实现一个高性能、可热更新的脚本服务,从而和嵌入的服务高效灵活地互动。我画了一张示意图,描述了如何通过 lua 脚本来具体实现可编程缓存服务:
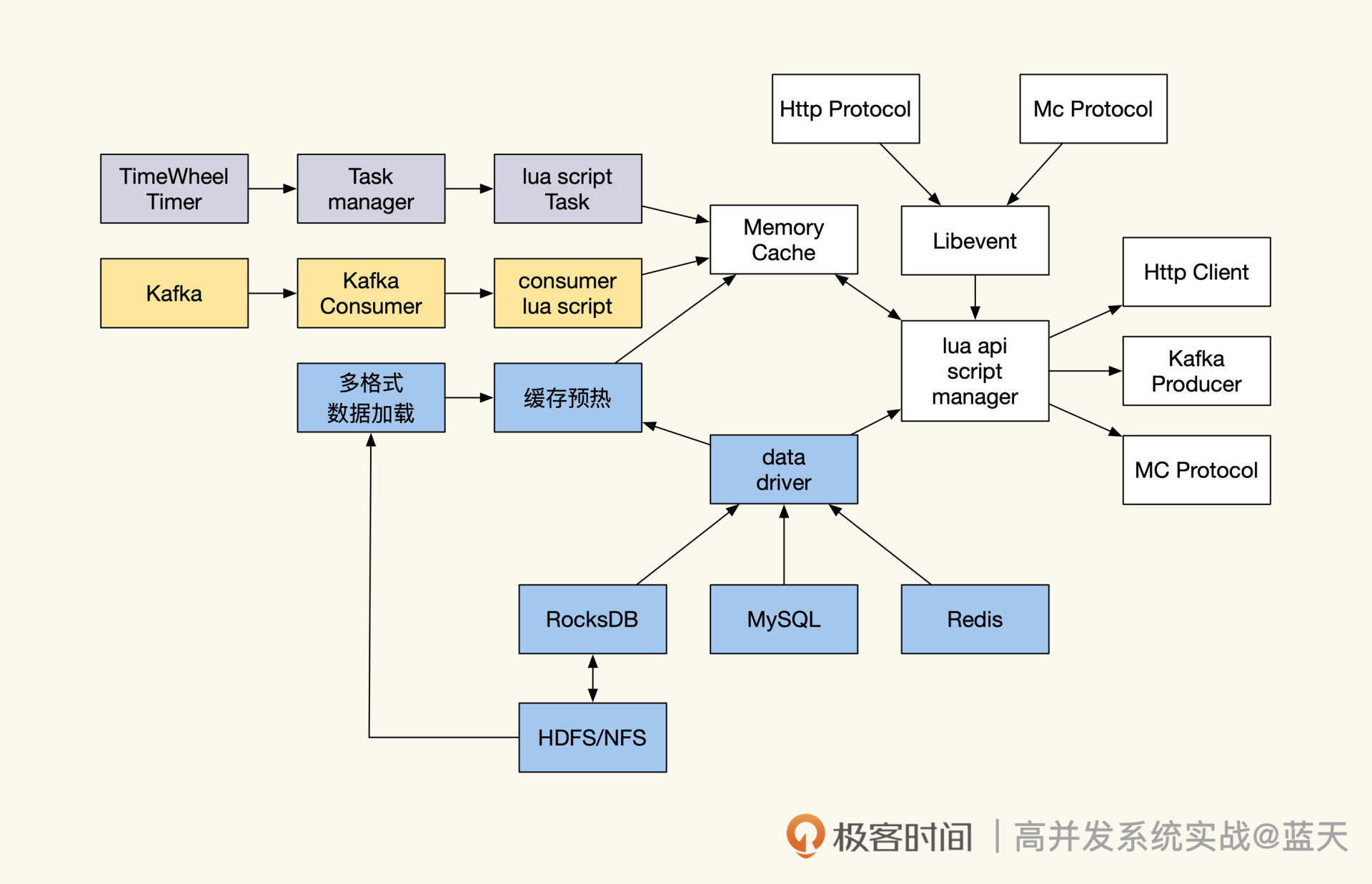
可编程缓存服务结构图
如上图所示,可以看到我们提供了 Kafka 消费、周期任务管理、内存缓存、多种数据格式支持、多种数据驱动适配这些服务。不仅仅如此,为了减少由于逻辑变更导致的服务经常重启的情况,我们还以性能损耗为代价,在缓存服务里嵌入了 lua 脚本引擎,借此实现动态更新业务的逻辑。lua 引擎使用起来很方便,我们结合后面这个实现例子看一看,这是一个 Go 语言写的嵌入 lua 实现,代码如下所示:
package mainimport "github.com/yuin/gopher-lua"// VarChange 用于被lua调用的函数
func VarChange(L *lua.LState) int {lv := L.ToInt(1) //获取调用函数的第一个参数,并且转成intL.Push(lua.LNumber(lv * 2)) //将参数内容直接x2,并返回结果给luareturn 1 //返回结果参数个数
}func main() {L := lua.NewState() //新lua线程defer L.Close() //程序执行完毕自动回收// 注册lua脚本可调用函数// 在lua内调用varChange函数会调用这里注册的Go函数 VarChangeL.SetGlobal("varChange", L.NewFunction(VarChange))//直接加载lua脚本//脚本内容为:// print "hello world"// print(varChange(20)) # lua中调用go声明的函数if err := L.DoFile("hello.lua"); err != nil {panic(err)}// 或者直接执行string内容if err := L.DoString(`print("hello")`); err != nil {panic(err)}
}// 执行后输出结果:
//hello world
//40
//hello
从这个例子里我们可以看出,lua 引擎是可以直接执行 lua 脚本的,而 lua 脚本可以和 Golang 所有注册的函数相互调用,并且可以相互传递交换变量。回想一下,我们做的是数据缓存服务,所以需要让 lua 能够获取修改服务内的缓存数据,那么,lua 是如何和嵌入的语言交换数据的呢?我们来看看两者相互调用交换的例子:
package mainimport ("fmt""github.com/yuin/gopher-lua"
)func main() {L := lua.NewState()defer L.Close()//加载脚本err := L.DoFile("vardouble.lua")if err != nil {panic(err)}// 调用lua脚本内函数err = L.CallByParam(lua.P{Fn: L.GetGlobal("varDouble"), //指定要调用的函数名NRet: 1, // 指定返回值数量Protect: true, // 错误返回error}, lua.LNumber(15)) //支持多个参数if err != nil {panic(err)}//获取返回结果ret := L.Get(-1)//清理下,等待下次用L.Pop(1)//结果转下类型,方便输出res, ok := ret.(lua.LNumber)if !ok {panic("unexpected result")}fmt.Println(res.String())
}// 输出结果:
// 30
其中 vardouble.lua 内容为:
function varDouble(n)return n * 2
end
通过这个方式,lua 和 Golang 就可以相互交换数据和相互调用。对于这种缓存服务普遍要求性能很好,这时我们可以统一管理加载过 lua 的脚本及 LState 脚本对象的实例对象池,这样会更加方便,不用每调用一次 lua 就加载一次脚本,方便获取和使用多线程、多协程。
Lua 脚本统一管理
通过前面的讲解我们可以发现,在实际使用时,lua 会在内存中运行很多实例。为了更好管理并提高效率,我们最好用一个脚本管理系统来管理所有 lua 的实运行例子,以此实现脚本的统一更新、编译缓存、资源调度和控制单例。lua 脚本本身是单线程的,但是它十分轻量,一个实例大概是 144kb 的内存损耗,有些服务平时能跑成百上千个 lua 实例。为了提高服务的并行处理能力,我们可以启动多协程,让每个协程独立运行一个 lua 线程。为此,gopher-lua 库提供了一个类似线程池的实现,通过这个方式我们不需要频繁地创建、关闭 lua,官方例子具体如下:
//保存lua的LState的池子
type lStatePool struct {m sync.Mutexsaved []*lua.LState
}
// 获取一个LState
func (pl *lStatePool) Get() *lua.LState {pl.m.Lock()defer pl.m.Unlock()n := len(pl.saved)if n == 0 {return pl.New()}x := pl.saved[n-1]pl.saved = pl.saved[0 : n-1]return x
}//新建一个LState
func (pl *lStatePool) New() *lua.LState {L := lua.NewState()// setting the L up here.// load scripts, set global variables, share channels, etc...//在这里我们可以做一些初始化return L
}//把Lstate对象放回到池中,方便下次使用
func (pl *lStatePool) Put(L *lua.LState) {pl.m.Lock()defer pl.m.Unlock()pl.saved = append(pl.saved, L)
}//释放所有句柄
func (pl *lStatePool) Shutdown() {for _, L := range pl.saved {L.Close()}
}
// Global LState pool
var luaPool = &lStatePool{saved: make([]*lua.LState, 0, 4),
}//协程内运行的任务
func MyWorker() {//通过pool获取一个LStateL := luaPool.Get()//任务执行完毕后,将LState放回pooldefer luaPool.Put(L)// 这里可以用LState变量运行各种lua脚本任务//例如 调用之前例子中的的varDouble函数err = L.CallByParam(lua.P{Fn: L.GetGlobal("varDouble"), //指定要调用的函数名NRet: 1, // 指定返回值数量Protect: true, // 错误返回error}, lua.LNumber(15)) //这里支持多个参数if err != nil {panic(err) //仅供演示用,实际生产不推荐用panic}
}
func main() {defer luaPool.Shutdown()go MyWorker() // 启动一个协程go MyWorker() // 启动另外一个协程/* etc... */
}
通过这个方式我们可以预先创建一批 LState,让它们加载好所有需要的 lua 脚本,当我们执行 lua 脚本时直接调用它们,即可对外服务,提高我们的资源复用率。
变量的交互
事实上我们的数据既可以保存在 lua 内,也可以保存在 Go 中,通过相互调用来获取对方的数据。个人习惯将数据放在 Go 中封装,供 lua 调用,主要是因为这样相对规范、比较好管理,毕竟脚本会有损耗。前面提到过,我们会将一些数据用 struct 和 map 组合起来,对外提供数据服务。那么 lua 和 Golang 如何交换 struct 一类数据呢?这里我选择了官方提供的例子,但额外加上了大量注释,帮助你理解这个交互过程。
// go用于交换的 struct
type Person struct {Name string
}//为这个类型定义个类型名称
const luaPersonTypeName = "person"// 在LState对象中,声明这种类型,这个只会在初始化LState时执行一次
// Registers my person type to given L.
func registerPersonType(L *lua.LState) {//在LState中声明这个类型mt := L.NewTypeMetatable(luaPersonTypeName)//指定 person 对应 类型type 标识//这样 person在lua内就像一个 类声明L.SetGlobal("person", mt)// static attributes// 在lua中定义person的静态方法// 这句声明后 lua中调用person.new即可调用go的newPerson方法L.SetField(mt, "new", L.NewFunction(newPerson))// person new后创建的实例,在lua中是table类型,你可以把table理解为lua内的对象// 下面这句主要是给 table定义一组methods方法,可以在lua中调用// personMethods是个map[string]LGFunction // 用来告诉lua,method和go函数的对应关系L.SetField(mt, "__index", L.SetFuncs(L.NewTable(), personMethods))
}
// person 实例对象的所有method
var personMethods = map[string]lua.LGFunction{"name": personGetSetName,
}
// Constructor
// lua内调用person.new时,会触发这个go函数
func newPerson(L *lua.LState) int {//初始化go struct 对象 并设置name为 1person := &Person{L.CheckString(1)}// 创建一个lua userdata对象用于传递数据// 一般 userdata包装的都是go的struct,table是lua自己的对象ud := L.NewUserData() ud.Value = person //将 go struct 放入对象中// 设置这个lua对象类型为 person typeL.SetMetatable(ud, L.GetTypeMetatable(luaPersonTypeName))// 将创建对象返回给luaL.Push(ud)//告诉lua脚本,返回了数据个数return 1
}
// Checks whether the first lua argument is a *LUserData
// with *Person and returns this *Person.
func checkPerson(L *lua.LState) *Person {//检测第一个参数是否为其他语言传递的userdataud := L.CheckUserData(1)// 检测是否转换成功if v, ok := ud.Value.(*Person); ok {return v}L.ArgError(1, "person expected")return nil
}
// Getter and setter for the Person#Name
func personGetSetName(L *lua.LState) int {// 检测第一个栈,如果就只有一个那么就只有修改值参数p := checkPerson(L)if L.GetTop() == 2 {//如果栈里面是两个,那么第二个是修改值参数p.Name = L.CheckString(2)//代表什么数据不返回,只是修改数据return 0}//如果只有一个在栈,那么是获取name值操作,返回结果L.Push(lua.LString(p.Name))//告诉会返回一个参数return 1
}
func main() {// 创建一个lua LStateL := lua.NewState()defer L.Close()//初始化 注册registerPersonType(L)// 执行lua脚本if err := L.DoString(`//创建person,并设置他的名字p = person.new("Steven")print(p:name()) -- "Steven"//修改他的名字p:name("Nico")print(p:name()) -- "Nico"`); err != nil {panic(err)}
}
可以看到,我们通过 lua 脚本引擎就能很方便地完成相互调用和交换数据,从而实现很多实用的功能,甚至可以用少量数据直接写成 lua 脚本的方式来加载服务。
缓存预热与数据来源
了解了 lua 后,我们再看看服务如何加载数据。服务启动时,我们需要将数据缓存加载到缓存中,做缓存预热,待数据全部加载完毕后,再开放对外的 API 端口对外提供服务。加载过程中如果用上了 lua 脚本,就可以在服务启动时对不同格式的数据做适配加工,这样做也能让数据来源更加丰富。常见的数据来源是大数据挖掘周期生成的全量数据离线文件,通过 NFS 或 HDFS 挂载定期刷新、加载最新的文件。这个方式适合数据量大且更新缓慢的数据,缺点则是加载时需要整理数据,如果情况足够复杂,800M 大小的数据要花 1~10 分钟方能加载完毕。除了使用文件方式外,我们也可以在程序启动后扫数据表恢复数据,但这么做数据库要承受压力,建议使用专用的从库。但相对磁盘离线文件的方式,这种方式加载速度更慢。上面两种方式加载都有些慢,我们还可以将 RocksDB 嵌入到进程中,这样做可以大幅度提高我们的数据存储容量,实现内存磁盘高性能读取和写入。不过代价就是相对会降低一些查询性能。RocksDB 的数据可以通过大数据生成 RocksDB 格式的数据库文件,拷贝给我们的服务直接加载。这种方式可以大大减少系统启动中整理、加载数据的时间,实现更多的数据查询。另外,如果我们对于本地有关系数据查询需求,也可以嵌入 SQLite 引擎,通过这个引擎可以做各种关系数据查询,SQLite 的数据的生成也可以通过工具提前生成,给我们服务直接使用。但你要注意这个数据库不要超过 10w 条数据,否则很可能导致服务卡顿。最后,对于离线文件加载,最好做一个 CheckSum 一类的文件,用来在加载文件之前检查文件的完整性。由于我们使用的是网络磁盘,不太确定这个文件是否正在拷贝中,需要一些小技巧保证我们的数据完整性,最粗暴的方式就是每次拷贝完毕后生成一个同名的文件,内部记录一下它的 CheckSum,方便我们加载前校验。离线文件能够帮助我们快速实现多个节点的数据共享和统一,如果我们需要多个节点数据保持最终一致性,就需要通过离线 + 同步订阅方式来实现数据的同步。
订阅式数据同步及启动同步
那么,我们的数据是如何同步更新的呢?正常情况下,我们的数据来源于多个基础数据服务。如果想实时同步数据的更改,我们一般会通过订阅 binlog 将变更信息同步到 Kafka,再通过 Kafka 的分组消费来通知分布在不同集群中的缓存。收到消息变更的服务会触发 lua 脚本,对数据进行同步更新。通过 lua 我们可以触发式同步更新其他相关缓存,比如用户购买一个商品,我们要同步刷新他的积分、订单和消息列表个数。
周期任务
提到任务管理,不得不提一下周期任务。周期任务一般用于刷新数据的统计,我们通过周期任务结合 lua 自定义逻辑脚本,就能实现定期统计,这给我们提供了更多的便利。定期执行任务或延迟刷新的过程中,常见的方式是用时间轮来管理任务,用这个方式可以把定时任务做成事件触发,这样能轻松地管理内存中的待触发任务列表,从而并行多个周期任务,无需使用 sleep 循环方式不断查询。对时间轮感兴趣的话,你可以点击这里查看具体实现。另外,前面提到我们的很多数据都是通过离线文件做批量更新的,如果是一小时更新一次,那么一小时内新更新的数据就需要同步。一般要这样处理:在我们服务启动加载的离线文件时,保存离线文件生成的时间,通过这个时间来过滤数据更新队列中的消息,等到我们的队列任务进度追到当前时间附近时,再开启对外数据的服务。
总结
读多写多的服务中,实时交互类服务非常多,对数据的实时性要求也很高,用集中型缓存很难满足服务所需。为此,行业里多数会通过服务内存数据来提供实时交互服务,但这么做维护起来十分麻烦,重启后需要恢复数据。为了实现业务逻辑无重启的更新,行业里通常会使用内嵌脚本的热更新方案。常见的通用脚本引擎是 lua,这是一个十分流行且方便的脚本引擎,在行业中,很多知名游戏及服务都使用 lua 来实现高性能服务的定制化业务功能,比如 Nginx、Redis 等。把 lua 和我们的定制化缓存服务结合起来,即可制作出很多强大的功能来应对不同的场景。由于 lua 十分节省内存,我们在进程中开启成千上万的 lua 小线程,甚至一个用户一个 LState 线程对客户端提供状态机一样的服务。用上面的方法,再结合 lua 和静态语言交换数据相互调用,并配合上我们的任务管理以及各种数据驱动,就能完成一个几乎万能的缓存服务。推荐你在一些小项目中亲自实践一下,相信会让你从不同视角看待已经习惯的服务,这样会有更多收获。
流量拆分:如何通过架构设计缓解流量压力?
一般来说,这种服务多数属于实时互动服务,因为时效性要求很高,导致很多场景下,我们无法用读缓存的方式来降低核心数据的压力。所以,为了降低这类互动服务器的压力,我们可以从架构入手,做一些灵活拆分的设计改造。事实上这些设计是混合实现对外提供服务的,为了让你更好地理解,我会针对直播互动里的特定的场景进行讲解。一般来说,直播场景可以分为可预估用户量和不可预估用户量的场景,两者的设计有很大的不同,我们分别来看看。
可预估用户量的服务:游戏创建房间
相信很多玩对战游戏的伙伴都有类似经历,就是联网玩游戏要先创建房间。这种设计主要是通过设置一台服务器可以开启的房间数量上限,来限制一台服务器能同时服务多少用户。我们从服务器端的资源分配角度分析一下,创建房间这个设计是如何做资源调配的。创建房间后,用户通过房间号就可以邀请其他伙伴加入游戏进行对战,房主和加入的伙伴,都会通过房间的标识由调度服务统一分配到同一服务集群上进行互动。这里我提示一下,开房间这个动作不一定需要游戏用户主动完成,可以设置成用户开启游戏就自动分配房间,这样做不但能提前预估用户量,还能很好地规划和掌控我们的服务资源。如何评估一个服务器支持多少人同时在线呢?我们可以通过压测测出单台服务器的服务在线人数,以此精确地预估带宽和服务器资源,算出一个集群(集群里包括若干服务器)需要多少资源、可以承担多少人在线进行互动,再通过调度服务分配资源,将新来的房主分配到空闲的服务集群。
最后的实现效果如下所示:
如上图所示,在创建房间阶段,我们的客户端在进入区域服务器集群之前,都是通过请求调度服务来进行调度的。调度服务器会定期接收各组服务器的服务用户在线情况,以此来评估需要调配多少用户进入到不同区域集群;同时客户端收到调度后,会拿着调度服务给的 token 去不同区域申请创建房间。房间创建后,调度服务会在本地集群内维护这个房间的列表和信息,提供给其他要加入游戏的玩家展示。而加入的玩家同样会接入对应房间的区域服务器,与房主及同房间玩家进行实时互动。这种通过配额房间个数来做服务器资源调度的设计,不光是对战游戏里,很多场景都用了类似设计,比如在线小课堂这类教学互动的。我们可以预见,通过这个设计能够对资源做到精准把控,用户不会超过我们服务器的设计容量。
不可预估用户量的服务
但是,有很多场景是随机的,我们无法把控有多少用户会进入这个服务器进行互动。全国直播就无法确认会有多少用户访问,为此,很多直播服务首先按主播过往预测用户量。通过预估量,提前将他们的直播安排到相对空闲的服务器群组里,同时提前准备一些调度工具,比如通过控制曝光度来延缓用户进入直播,通过这些为服务器调度争取更多时间来动态扩容。由于这一类的服务无法预估会有多少用户,所以之前的服务器小组模式并不适用于这种方式,需要更高一个级别的调度。我们分析一下场景,对于直播来说,用户常见的交互形式包括聊天、答题、点赞、打赏和购物,考虑到这些形式的特点不同,我们针对不同的关键点依次做分析。
聊天:信息合并
聊天的内容普遍比较短,为了提高吞吐能力,通常会把用户的聊天内容放入分布式队列做传输,这样能延缓写入压力。另外,在点赞或大量用户输入同样内容的刷屏情境下,我们可以通过大数据实时计算分析用户的输入,并压缩整理大量重复的内容,过滤掉一些无用信息。
压缩整理后的聊天内容会被分发到多个聊天内容分发服务器上,直播间内用户的聊天长连接会收到消息更新的推送通知,接着客户端会到指定的内容分发服务器群组里批量拉取数据,拿到数据后会根据时间顺序来回放。请注意,这个方式只适合用在疯狂刷屏的情况,如果用户量很少可以通过长链接进行实时互动。
答题:瞬时信息拉取高峰
除了交互流量极大的聊天互动信息之外,还有一些特殊的互动,如做题互动。直播间老师发送一个题目,题目消息会广播给所有用户,客户端收到消息后会从服务端拉取题目的数据。如果有 10w 用户在线,很有可能导致瞬间有 10w 人在线同时请求服务端拉取题目。这样的数据请求量,需要我们投入大量的服务器和带宽才能承受,不过这么做这个性价比并不高。理论上我们可以将数据静态化,并通过 CDN 阻挡这个流量,但是为了避免出现瞬时的高峰,推荐客户端拉取时加入随机延迟几秒,再发送请求,这样可以大大延缓服务器压力,获得更好的用户体验。切记对于客户端来说,这种服务如果失败了,就不要频繁地请求重试,不然会将服务端打沉。如果必须这样做,那么建议你对重试的时间做退火算法,以此保证服务端不会因为一时故障收到大量的请求,导致服务器崩溃。如果是教学场景的直播,有两个缓解服务器压力的技巧。第一个技巧是在上课当天,把抢答题目提前交给客户端做预加载下载,这样可以减少实时拉取的压力。第二个方式是题目抢答的情况,老师发布题目的时候,提前设定发送动作生效后 5 秒再弹出题目,这样能让所有直播用户的接收端“准时”地收到题目信息,而不至于出现用户题目接收时间不一致的情况。至于非抢答类型的题目,用户回答完题目后,我们可以先在客户端本地先做预判卷,把正确答案和解析展示给用户,然后在直播期间异步缓慢地提交用户答题结果到服务端,以此保证服务器不会因用户瞬时的流量被冲垮。
点赞:客户端互动合并
对于点赞的场景,我会分成客户端和服务端两个角度带你了解。先看客户端,很多时候,客户端无需实时提交用户的所有交互,因为有很多机械的重复动作对实时性要求没那么高。举个例子,用户在本地狂点了 100 下赞,客户端就可以合并这些操作为一条消息(例如用户 3 秒内点赞 10 次)。相信聪明如你,可以把互动动作合并这一招用在更多情景,比如用户连续打赏 100 个礼物。通过这个方式可以大幅度降低服务器压力,既可以保证直播间的火爆依旧,还节省了大量的流量资源,何乐而不为。
点赞:服务端树形多层汇总架构
我们回头再看看点赞的场景下,如何设计服务端才能缓解请求压力。如果我们的集群 QPS 超过十万,服务端数据层已经无法承受这样的压力时,如何应对高并发写、高并发读呢?微博做过一个类似的案例,用途是缓解用户的点赞请求流量,这种方式适合一致性要求不高的计数器,如下图所示:
树形读写缓存
这个方式可以将用户点赞流量随机压到不同的写缓存服务上,通过第一层写缓存本地的实时汇总来缓解大量用户的请求,将更新数据周期性地汇总后,提交到二级写缓存。之后,二级汇总所在分片的所有上层服务数值后,最终汇总同步给核心缓存服务。接着,通过核心缓存把最终结果汇总累加起来。最后通过主从复制到多个子查询节点服务,供用户查询汇总结果。另外,说个题外话,微博是 Redis 重度用户,后来因为点赞数据量太大,在 Redis 中缓存点赞数内存浪费严重(可以回顾上一节课 jmalloc 兄弟算法的内容),改为自行实现点赞服务来节省内存。
打赏 & 购物:服务端分片及分片实时扩容
前面的互动只要保证最终一致性就可以,但打赏和购物的场景下,库存和金额需要提供事务一致性的服务。因为事务一致性的要求,这种服务我们不能做成多层缓冲方式提供服务,而且这种服务的数据特征是读多写多,所以我们可以通过数据分片方式实现这一类服务,如下图:
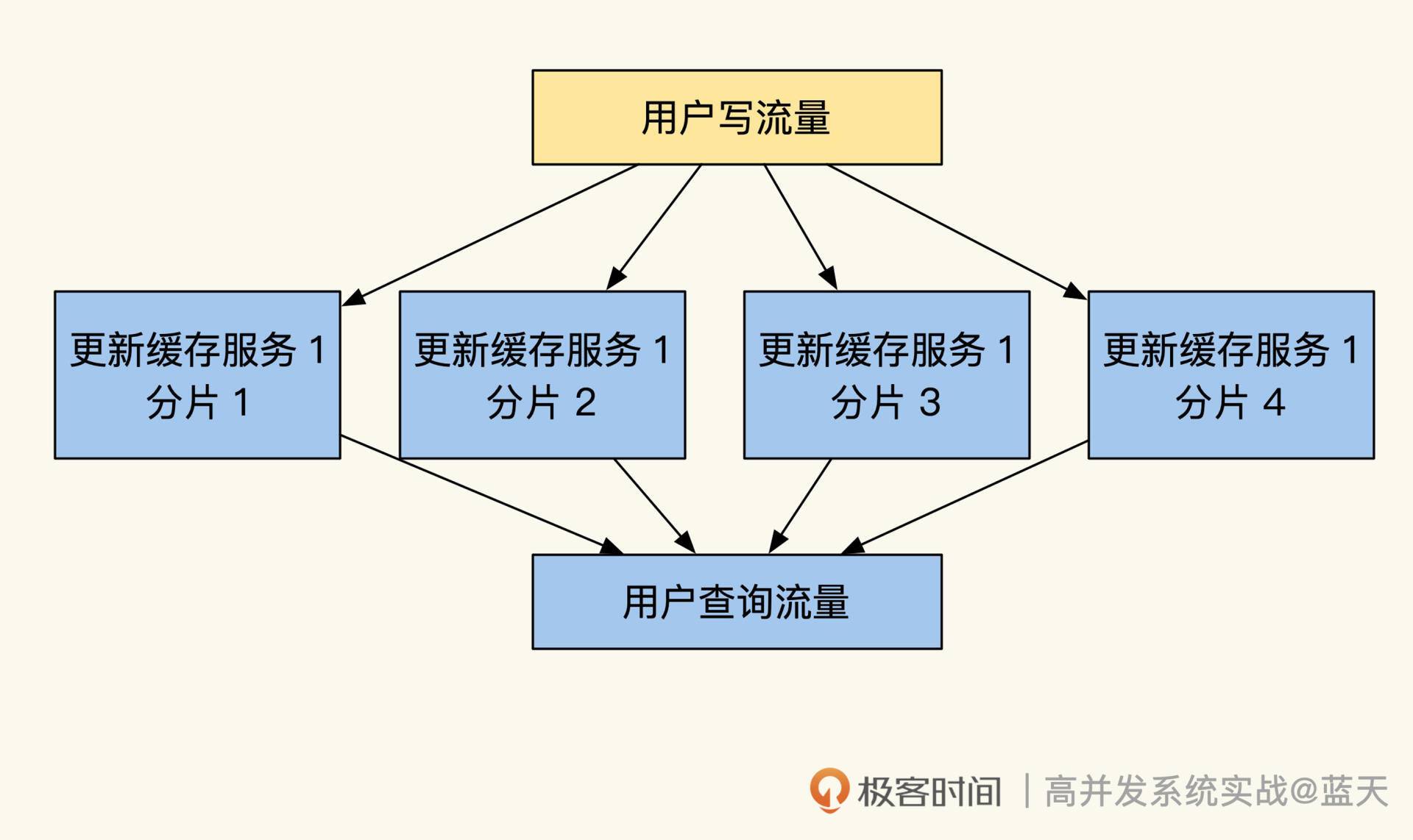
hash 分片方式缓解流量
看了图是不是很好理解?我们可以按用户 id 做了 hash 拆分,通过网关将不同用户 uid 取模后,根据范围分配到不同分片服务上,然后分片内的服务对类似的请求进行内存实时计算更新。通过这个方式,可以快速方便地实现负载切分,但缺点是 hash 分配容易出现个别热点,当我们流量扛不住的时候需要扩容。但是 hash 这个方式如果出现个别服务器故障的话,会导致 hash 映射错误,从而请求到错误的分片。类似的解决方案有很多,如一致性 hash 算法,这种算法可以对局部的区域扩容,不会影响整个集群的分片,但是这个方法很多时候因为算法不通用,无法人为控制,使用起来很麻烦,需要开发配套工具。除此之外,我给你推荐另外一个方式——树形热迁移切片法,这是一种类似虚拟桶的方式。比如我们将全量数据拆分成 256 份,一份代表一个桶,16 个服务器每个分 16 个桶,当我们个别服务器压力过大的时候,可以给这个服务器增加两个订阅服务器去做主从同步,迁移这个服务器的 16 个桶的数据。待同步迁移成功后,将这个服务器的请求流量拆分转发到两个 8 桶服务器,分别请求这两个订阅服务器继续对外服务,原服务器摘除回收即可。服务切换成功后,由于是全量迁移,这两个服务同时同步了不属于自己的 8 个桶数据,这时新服务器遍历自己存储的数据,删除掉不属于自己的数据即可。当然也可以在同步 16 桶服务的数据时,过滤掉这些数据,这个方法适用于 Redis、MySQL 等所有有状态分片数据服务。这个服务的难点在于请求的客户端不直接请求分片,而是通过代理服务去请求数据服务,只有通过代理服务才能够动态更新调度流量,实现平滑无损地转发流量。最后,如何让客户端知道请求哪个分片才能找到数据呢?我给你分享两个常见的方式:第一种方式是,客户端通过算法找到分片,比如:用户 hash(uid) % 100 = 桶 id,在配置中通过桶 id 找到对应分片。第二种方式是,数据服务端收到请求后,将请求转发到有数据的分片。比如客户端请求 A 分片,再根据数据算法对应的分片配置找到数据在 B 分片,这时 A 分片会转发这个请求到 B,待 B 处理后返回给客户端数据(A 返回或 B 返回,取决于客户端跳转还是服务端转发)。
服务降级:分布式队列汇总缓冲
即使通过这么多技术来优化架构,我们的服务仍旧无法完全承受过高的瞬发流量。对于这种情况,我们可以做一些服务降级的操作,通过队列将修改合并或做网关限流。虽然这会牺牲一些实时性,但是实际上,很多数字可能没有我们想象中那么重要。像微博的点赞统计数据,如果客户端点赞无法请求到服务器,那么这些数据会在客户端暂存一段时间,在用户看数据时看到的只是短期历史数字,不是实时数字。十万零五的点赞数跟十万零三千的点赞数,差异并不大,等之后服务器有空闲了,结果追上来最终是一致的。但作为降级方案,这么做能节省大量的服务器资源,也算是个好方法。
总结
这节课我们学习了如何通过架构以及设计去缓解流量冲击。场景不同,拆分的技巧各有不同。我们依次了解了如何用房间方式管理用户资源调配、如何对广播大量刷屏互动进行分流缓冲、如何规避答题的瞬时拉题高峰、如何通过客户端合并多次点赞动作、如何通过多个服务树形结构合并点赞流量压力,以及如何对强一致实现分片、调度等。因为不同场景对一致性要求不同,所以延伸出来的设计也是各有不同的。为了实现可动态调配的高并发的直播系统,我们还需要良好的基础建设,具体包括以下方面的支撑:分布式服务:分布式队列、分布式实时计算、分布式存储。动态容器:服务器统一调度系统、自动化运维、周期压力测试、Kubernetes 动态扩容服务。调度服务:通过 HttpDNS 临时调度用户流量等服务,来实现动态的资源调配。
流量调度:DNS、全站加速及机房负载均衡
上节课我们学习了如何从架构设计上应对流量压力,像直播这类的服务不容易预估用户流量,当用户流量增大到一个机房无法承受的时候,就需要动态调度一部分用户到多个机房中。同时,流量大了网络不稳定的可能性也随之增加,只有让用户能访问就近的机房,才能让他们的体验更好。综合上述考量,这节课我们就重点聊聊流量调度和数据分发的关键技术,帮你弄明白怎么做好多个机房的流量切换。直播服务主要分为两种流量,一个是静态文件访问,一个是直播流,这些都可以通过 CDN 分发降低我们的服务端压力。对于直播这类读多写多的服务来说,动态流量调度和数据缓存分发是解决大量用户在线互动的基础,但是它们都和 DNS 在功能上有重合,需要一起配合实现,所以在讲解中也会穿插 CDN 的介绍。
DNS 域名解析及缓存
服务流量切换并没有想象中那么简单,因为我们会碰到一个很大的问题,那就是 DNS 缓存。DNS 是我们发起请求的第一步,如果 DNS 缓慢或错误解析的话,会严重影响读多写多系统的交互效果。那 DNS 为什么会有刷新缓慢的情况呢?这需要我们先了解 DNS 的解析过程,你可以对照下图听我分析:
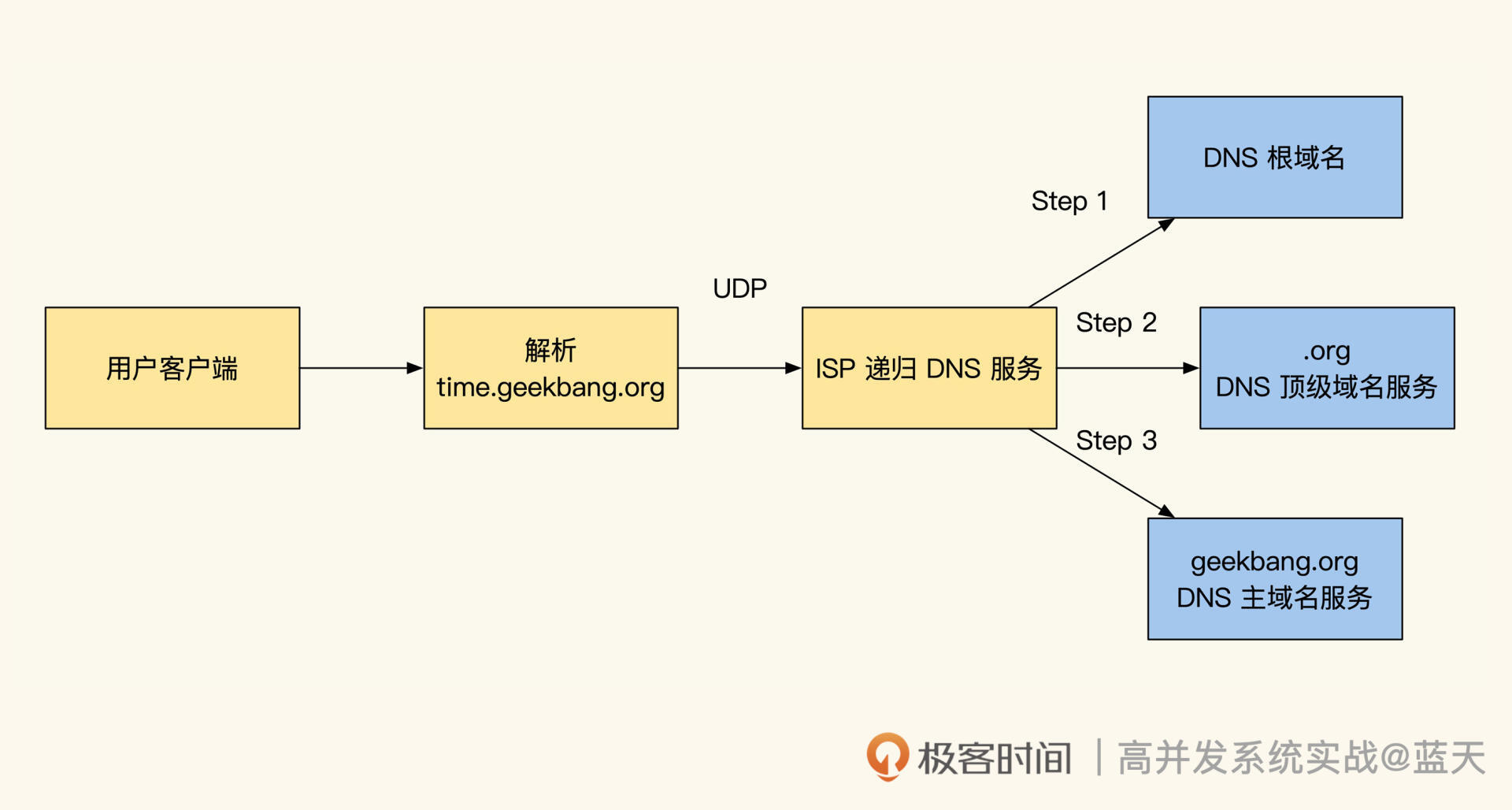
DNS 查找过程
客户端或浏览器发起请求时,第一个要请求的服务就是 DNS,域名解析过程可以分成下面三个步骤:1. 客户端会请求 ISP 商提供的 DNS 解析服务,而 ISP 商的 DNS 服务会先请求根 DNS 服务器;2. 通过根 DNS 服务器找到.org顶级域名 DNS 服务器;3. 再通过顶级域名服务器找到域名主域名服务器(权威 DNS)。找到主域名服务器后,DNS 就会开始解析域名。一般来说主域名服务器是我们托管域名的服务商提供的,而域名具体解析规则和 TTL 时间都是我们在域名托管服务商管理系统里设置的。当请求主域名解析服务时,主域名服务器会返回服务器所在机房的入口 IP 以及建议缓存的 TTL 时间,这时 DNS 解析查询流程才算完成。在主域名服务返回结果给 ISP DNS 服务时,ISP 的 DNS 服务会先将这个解析结果按 TTL 规定的时间缓存到服务本地,然后才会将解析结果返回给客户端。在 ISP DNS 缓存 TTL 有效期内,同样的域名解析请求都会从 ISP 缓存直接返回结果。可以预见,客户端会把 DNS 解析结果缓存下来,而且实际操作时,很多客户端并不会按 DNS 建议缓存的 TTL 时间执行,而是优先使用配置的时间。同时,途经的 ISP 服务商也会记录相应的缓存,如果我们域名的解析做了改变最快也需要服务商刷新自己服务器的时间(通常需要 3 分钟)+TTL 时间,才能获得更新。
事实上比较糟糕的情况是下面这样:
// 全网刷新域名解析缓存时间
客户端本地解析缓存时间30分钟 + 市级 ISP DNS缓存时间 30分钟 + 省级 ISP DNS缓存时间 30分钟 + 主域名服务商 刷新解析服务器配置耗时 3分钟 + ... 后续ISP子网情况 略
= 域名解析实际更新时间 93分钟以上
为此,很多域名解析服务建议我们的 TTL 设置在 30 分钟以内,而且很多大型互联网公司会在客户端的缓存上,人为地减少缓存时间。如果你设置的时间过短,虽然刷新很快,但是会导致服务请求很不稳定。当然 93 分钟是理想情况,根据经验,正常域名修改后全国 DNS 缓存需要 48 小时,才能大部分更新完毕,而刷全世界缓存需要 72 小时,所以不到万不得已不要变更主域名解析。如果需要紧急刷新,我建议你购买强制推送解析的服务去刷新主干 ISP 的 DNS 缓冲,但是,这个服务不光很贵,而且只能覆盖主要城市主干线,个别地区还是会存在刷新缓慢的情况(取决于宽带服务商)。不过整体来说,确实会加快 DNS 缓存的刷新速度。DNS 刷新缓慢这个问题,给我们带来了很多困扰,如果我们做故障切换,需要三天时间才能够彻底切换,显然这会给系统的可用性带来毁灭性打击。好在近代有很多技术可以弥补这个问题,比如 CDN、GTM、HttpDNS 等服务,我们依次来看看。
CDN 全网站加速
可能你会奇怪“为什么加快刷新 DNS 缓存和 CDN 有关系?”在讲如何实现 CDN 加速之前,我们先了解下 CDN 和它的网站加速技术是怎么回事。网站加速对于读多写多的系统很重要,一般来说,常见的 CDN 提供了静态文件加速功能,如下图:
静态缓存
当用户请求 CDN 服务时,CDN 服务会优先返回本地缓存的静态资源。如果 CDN 本地没有缓存这个资源或者这个资源是动态内容(如 API 接口)的话,CDN 就会回源到我们的服务器,从我们的服务器获取资源;同时,CDN 会按我们服务端返回的资源超时时间来刷新本地缓存,这样可以大幅度降低我们机房静态数据服务压力,节省大量带宽和硬件资源的投入。除了加速静态资源外,CDN 还做了区域化的本地 CDN 网络加速服务,具体如下图:
本地域名解析 + 本地机房
CDN 会在各大主要省市中部署加速服务机房,而且机房之间会通过高速专线实现互通。当客户端请求 DNS 做域名解析时,所在省市的 DNS 服务会通过 GSLB 返回当前用户所在省市最近的 CDN 机房 IP,这个方式能大大减少用户和机房之间的网络链路节点数,加快网络响应速度,还能减少网络请求被拦截的可能。客户端请求服务的路径效果如下图所示:
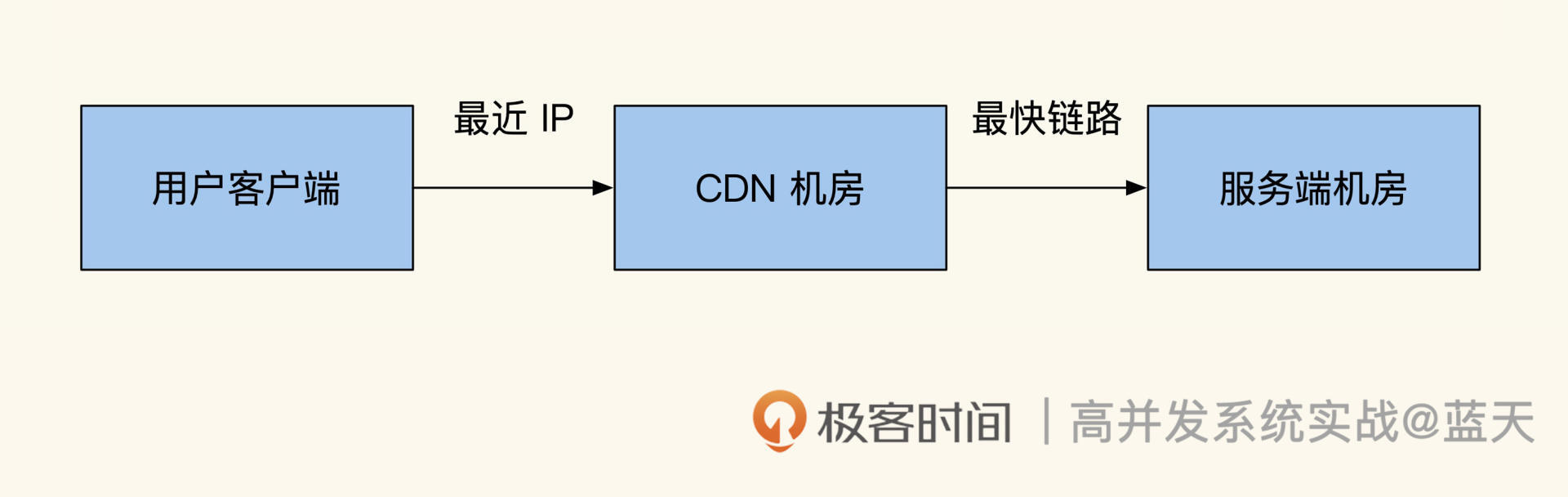
全站加速网站 动态接口 CDN 网络链路优化
如果用户请求的是全站加速网站的动态接口,CDN 节点会通过 CDN 内网用最短最快的网络链路,将用户请求转发到我们的机房服务器。相比客户端从外省经由多个 ISP 服务商网络转发,然后才能请求到服务器的方式,这样做能更好地应对网络缓慢的问题,给客户端提供更好的用户体验。而网站做了全站加速后,所有的用户请求都会由 CDN 转发,而客户端请求的所有域名也都会指向 CDN,再由 CDN 把请求转到我们的服务端。在此期间,如果机房变更了 CDN 提供服务的 IP,为了加快 DNS 缓存刷新,可以使用 CDN 内网 DNS 的服务(该服务由 CDN 供应商提供)去刷新 CDN 中的 DNS 缓存。这样做客户端的 DNS 解析是不变的,不用等待 48 小时,域名刷新会更加方便。由于 48 小时刷新缓存的问题,大多数互联网公司切换机房时,都不会采用改 DNS 解析配置的方式去做故障切换,而是依托 CDN 去做类似的功能。但 CDN 入口出现故障的话,对网站服务影响也是很大的。国外为了减少入口故障问题,配合使用了 anycast 技术。通过 anycast 技术,就能让多个机房服务入口拥有同样的 IP,如果一个入口发生故障,运营商就会将流量转发到另外的机房。但是,国内因为安全原因,并不支持 anycast 技术。除了 CDN 入口出现故障的风险外,请求流量进入 CDN 后,CDN 本地没有缓存回源而且本地网站服务也发生故障时,也会出现不能自动切换源到多个机房的问题。所以,为了加强可用性,我们可以考虑在 CDN 后面增加 GTM。
GTM 全局流量管理
在了解 GTM 和 CDN 的组合实现之前,我先给你讲讲 GTM 的工作原理和主要功能。GTM 是全局流量管理系统的简称。我画了一张工作原理图帮你加深理解:
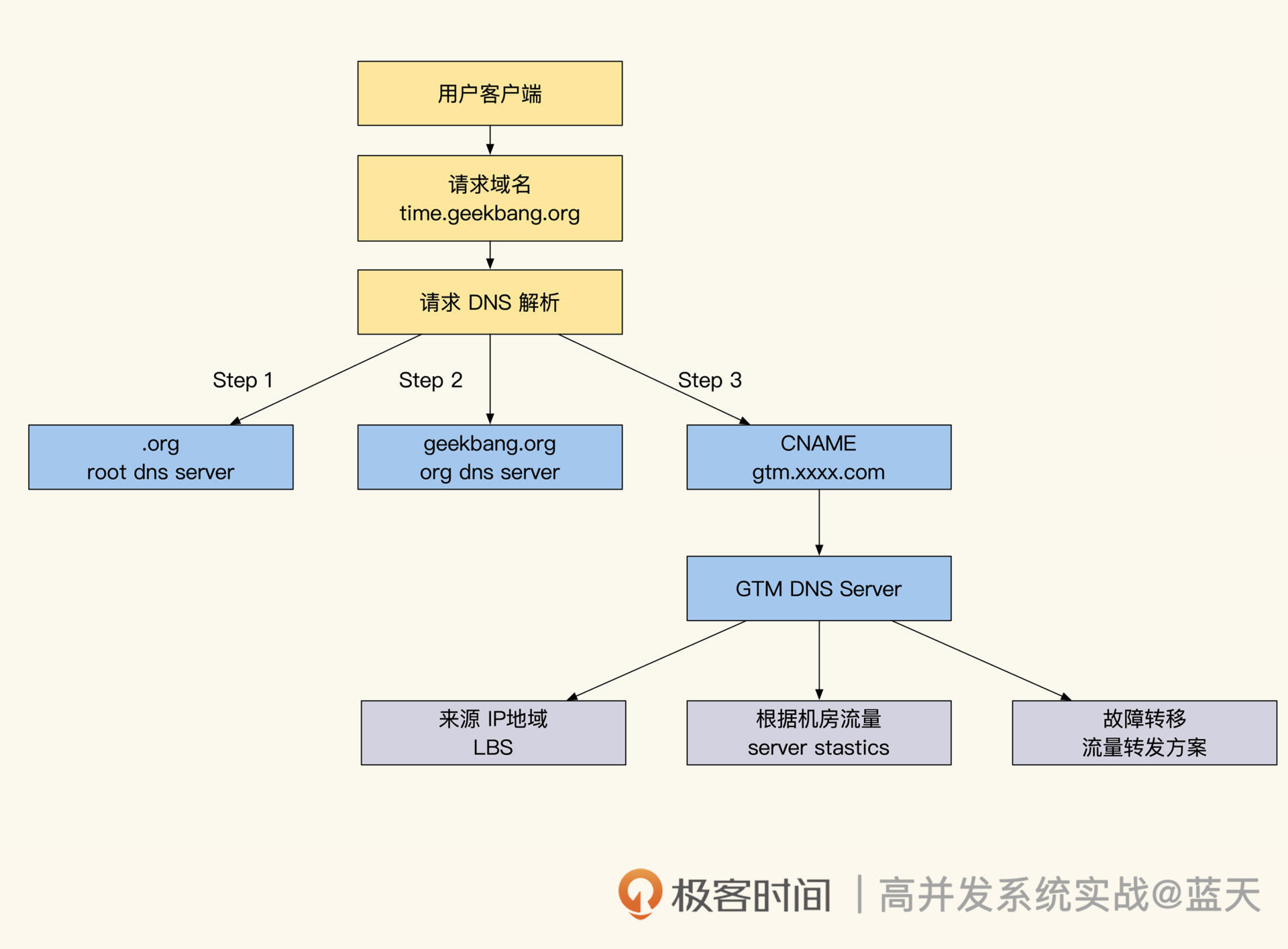
GTM 智能 DNS 解析
当客户端请求服务域名时,客户端先会请求 DNS 服务解析请求的域名。而客户端请求主域名 DNS 服务来解析域名时,会请求到 GTM 服务的智能解析 DNS。相比传统技术,GTM 还多了三个功能:服务健康监控、多线路优化和流量负载均衡。首先是服务健康监控功能。GTM 会监控服务器的工作状态,如果发现机房没有响应,就自动将流量切换到健康的机房。在此基础上,GTM 还提供了故障转移功能,也就是根据机房能力和权重,将一些用户流量转移到其他机房。其次是多线路优化功能,国内宽带有不同的服务提供商(移动、联通、电信、教育宽带),不同的宽带的用户访问同提供商的网站入口 IP 性能最好,如果跨服务商访问会因为跨网转发会加大请求延迟。因此,使用 GTM 可以根据不同机房的 CDN 来源,找到更快的访问路径。GTM 还提供了流量负载均衡功能,即根据监控服务的流量及请求延迟情况来分配流量,从而实现智能地调度客户端的流量。
当 GTM 和 CDN 网站加速结合后会有更好的效果,具体组合方式如下图所示:
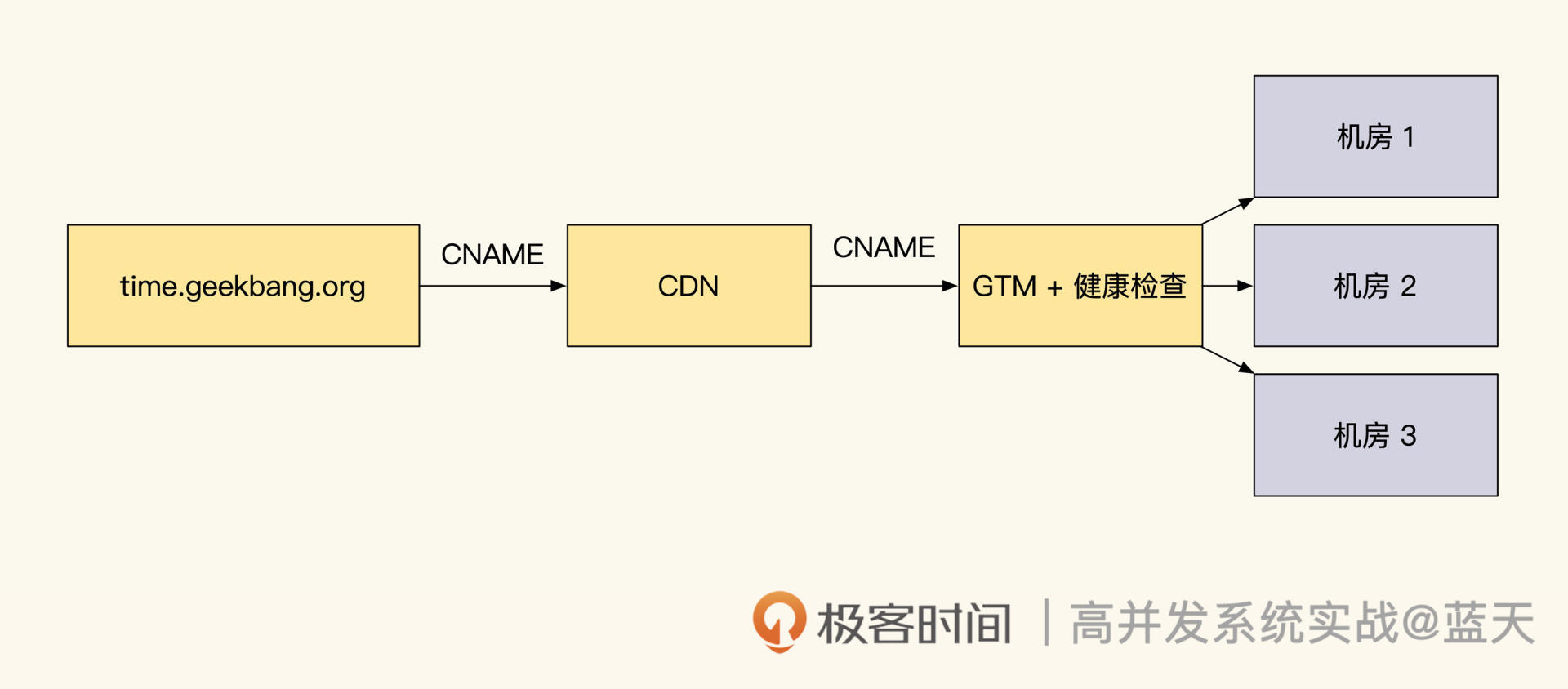
CDN + GTM 网络加速及故障转移
由于 GTM 和 CDN 加速都是用了 CNAME 做转发,我们可以先将域名指向 CDN,通过 CDN 的 GSLB 和内网为客户端提供网络加速服务。而在 CDN回源时请求会转发到 GTM 解析,经过 GTM 解析 DNS 后,将 CDN 的流量转发到各个机房做负载均衡。当我们机房故障时,GTM 会从负载均衡列表快速摘除故障机房,这样既满足了我们的网络加速,又实现了多机房负载均衡及更快的故障转移。不过即使使用了 CDN+GTM,还是会有一批用户出现网络访问缓慢现象,这是因为很多 ISP 服务商提供的 DNS 服务并不完美,我们的用户会碰到 DNS 污染、中间人攻击、DNS 解析调度错区域等问题。为了缓解这些问题,我们需要在原有的服务基础上,强制使用 HTTPS 协议对外服务,同时建议再配合 GPS 定位在客户端 App 启用 HttpDNS 服务。
HttpDNS 服务
HttpDNS 服务能够帮助我们绕过本地 ISP 提供的 DNS 服务,防止 DNS 劫持,并且没有 DNS 域名解析刷新的问题。同样地,HttpDNS 也提供了 GSLB 功能。HttpDNS 还能够自定义解析服务,从而实现灰度或 A/B 测试。一般来说,HttpDNS 只能解决 App 端的服务调度问题。因此客户端程序如果用了 HttpDNS 服务,为了应对 HttpDNS 服务故障引起的域名解析失败问题,还需要做备选方案。这里我提供一个解析服务的备选参考顺序:一般会优先使用 HttpDNS,然后使用指定 IP 的 DNS 服务,再然后才是本地 ISP 商提供的 DNS 服务,这样可以大幅度提高客户端 DNS 的安全性。当然,我们也可以开启 DNS Sec 进一步提高 DNS 服务的安全性,但是上述所有服务都要结合我们实际的预算和时间精力综合决策。不过 HttpDNS 这个服务不是免费的,尤其对大企业来说成本更高,因为很多 HttpDNS 服务商提供的查询服务会按请求次数计费。所以,为了节约成本我们会设法减少请求量,建议在使用 App 时,根据客户端链接网络的 IP 以及热点名称(Wifi、5G、4G)作为标识,做一些 DNS 缓存。业务自实现流量调度
业务自实现流量调度
HttpDNS 服务只能解决 DNS 污染的问题,但是它无法参与到我们的业务调度中,所以当我们需要根据业务做管控调度时,它能够提供的支持有限。为了让用户体验更好,互联网公司结合 HttpDNS 的原理实现了流量调度,比如很多无法控制用户流量的直播服务,就实现了类似 HttpDNS 的流量调度服务。调度服务常见的实现方式是通过客户端请求调度服务,调度服务调配客户端到附近的机房。这个调度服务还能实现机房故障转移,如果服务器集群出现故障,客户端请求机房就会出现失败、卡顿、延迟的情况,这时客户端会主动请求调度服务。如果调度服务收到了切换机房的命令,调度服务给客户端返回健康机房的 IP,以此提高服务的可用性。调度服务本身也需要提高可用性,具体做法就是把调度服务部署在多个机房,而多个调度机房会通过 Raft 强一致来同步用户调度结果策略。我举个例子,当一个用户请求 A 机房的调度时,被调度到了北京机房,那么这个用户再次请求 B 机房调度服务时,短期内仍旧会被调度到北京机房。除非客户端切换网络或我们的服务机房出现故障,才会做统一的流量变更。为了提高客户端的用户体验,我们需要给客户端调配到就近的、响应性能最好的机房,为此我们需要一些辅助数据来支撑调度服务分配客户端,这些辅助数据包括 IP、GPS 定位、网络服务商、ping 网速、实际播放效果。客户端会定期收集这些数据,反馈给大数据中心做分析计算,提供参考建议,帮助调度服务更好地决策当前应该链接哪个机房和对应的线路。其实这么做就相当于自实现了 GSLB 功能。但是自实现 GSLB 功能的数据不是绝对正确的,因为不同省市的 DNS 服务解析的结果不尽相同,同时如果客户端无法联通,需要根据推荐 IP 挨个尝试来保证服务高可用。此外,为了验证调度是否稳定,我们可以在客户端暂存调度结果,每次客户端请求时在 header 中带上当前调度的结果,通过这个方式就能在服务端监控有没有客户端错误请求到其他机房的情况。如果发现错误的请求,可以通过机房网关做类似 CDN 全站加速一样的反向代理转发,来保证客户端稳定。对于直播和视频也需要做类似调度的功能,当我们播放视频或直播时出现监控视频的卡顿等情况。如果发现卡顿过多,客户端应能够自动切换视频源,同时将情况上报到大数据做记录分析,如果发现大规模视频卡顿,大数据会发送警报给我们的运维和研发伙伴。
总结
多机房故障切换知识图谱
域名是我们的服务的主要入口,请求一个域名时,首先需要通过 DNS 将域名解析成 IP。但是太频繁请求 DNS 的话,会影响服务响应速度,所以很多客户端、ISP 服务商都会对 DNS 做缓存,不过这种多层级缓存,直接导致了刷新域名解析变得很难。即使花钱刷新多个带宽服务商的缓存,我们个别区域仍旧需要等待至少 48 小时,才能完成大部分用户的缓存刷新。如果我们因为网站故障等特殊原因必须切换 IP 时,带来的影响将是灾难性的,好在近几年我们可以通过 CDN、GTM、HttpDNS 来强化我们多机房的流量调度。但 CDN、GTM 都是针对机房的调度,对业务方是透明的。所以,在更重视用户体验的高并发场景中,我们会自己实现一套调度系统。在这种自实现方案中,你会发现自实现里的思路和 HttpDNS 和 GSLB 的很类似,区别在于之前的服务只是基础服务,我们自实现的服务还可以快速地帮助我们调度用户流量。而通过 HttpDNS 来实现用户切机房,切视频流的实现无疑是十分方便简单的,只需要在我们 App 发送请求的封装上更改链接的 IP,即可实现业务无感的机房切换。
内网建设:系统如何降低业务复杂度
数据引擎:统一缓存数据平台
任何一个互联网公司都会有几个核心盈利的业务,我们经常会给基础核心业务做一些增值服务,以此来扩大我们的服务范围以及构建产业链及产业生态,但是这些增值服务需要核心项目的数据及交互才能更好地提供服务。但核心系统如果对增值业务系统做太多的耦合适配,就会导致业务系统变得十分复杂,如何能既让增值服务拿到核心系统的资源,又能减少系统之间的耦合?这节课我会重点带你了解一款内网主动缓存支撑的中间件,通过这个中间件,可以很方便地实现高性能实体数据访问及缓存更新。
回顾临时缓存的实现
我们先回顾下之前展示的临时缓存实现,这个代码摘自之前的第二节课
// 尝试从缓存中直接获取用户信息
userinfo, err := Redis.Get("user_info_9527")
if err != nil {return nil, err
}//缓存命中找到,直接返回用户信息
if userinfo != nil {return userinfo, nil
}//没有命中缓存,从数据库中获取
userinfo, err := userInfoModel.GetUserInfoById(9527)
if err != nil {return nil, err
}//查找到用户信息
if userinfo != nil {//将用户信息缓存,并设置TTL超时时间让其60秒后失效Redis.Set("user_info_9527", userinfo, 60)return userinfo, nil
}// 没有找到,放一个空数据进去,短期内不再访问数据库
// 可选,这个是用来预防缓存穿透查询攻击的
Redis.Set("user_info_9527", "", 30)
return nil, nil
上述代码演示了临时缓存提高读性能的常用方式:即查找用户信息时直接用 ID 从缓存中进行查找,如果在缓存中没有找到,那么会从数据库中回源查找数据,找到数据后,再将数据写入缓存方便下次查询。相对来说这个实现很简单,但是如果我们所有业务代码都需要去这么写,工作量还是很大的。即便我们会对这类实现做一些封装,但封装的功能在静态语言中并不是很通用,性能也不好。那有没有什么方式能统一解决这类问题,减少我们的重复工作量呢?
实体数据主动缓存
之前我们在第二节课讲过实体数据最容易做缓存,实体数据的缓存 key 可以设计为前缀 + 主键 ID 这种形式 。通过这个设计,我们只要拥有实体的 ID,就可以直接在缓存中获取到实体的数据了。为了降低重复的工作量,我们对这个方式做个提炼,单独将这个流程做成中间件,具体实现如下图:
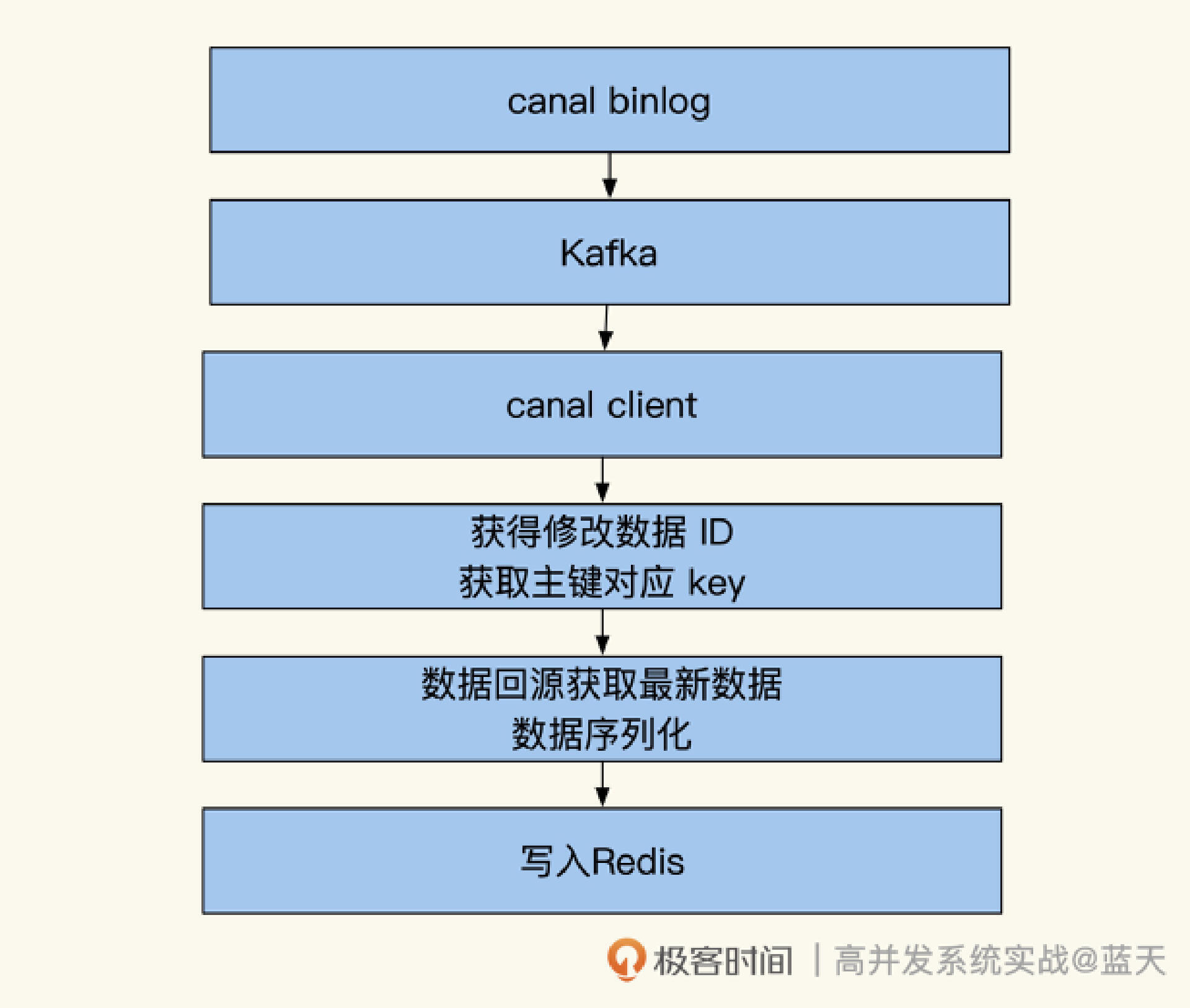
通过canal 监控 实现 简单的主动推送数据缓存
结合上图,我们分析一下这个中间件的工作原理。我们通过 canal 来监控 MySQL 数据库的 binlog 日志,当有数据变更时,消息监听端会收到变更通知。因为变更消息包含变更的表名和所有变更数据的所有主键 ID,所以这时我们可以通过主键 ID,回到数据库主库查询出最新的实体数据,再根据需要来加工这个数据,并将其推送数据到缓存当中。而从过往经验来看,很多刚变动的数据有很大概率会被马上读取。所以,这个实现会有较好的缓存命中率。同时,当我们的数据被缓存后会根据配置设置一个 TTL,缓存在一段时间没有被读取的话,就会被 LRU 策略淘汰掉,这样还能节省缓存空间。如果你仔细思考一下,就会发现这个设计还是有缺陷:如果业务系统无法从缓存中拿到所需数据,还是要回数据库查找数据,并且再次将数据放到缓存当中。这和我们设计初衷不一致。为此,我们还需要配套一个缓存查询服务,请看下图:
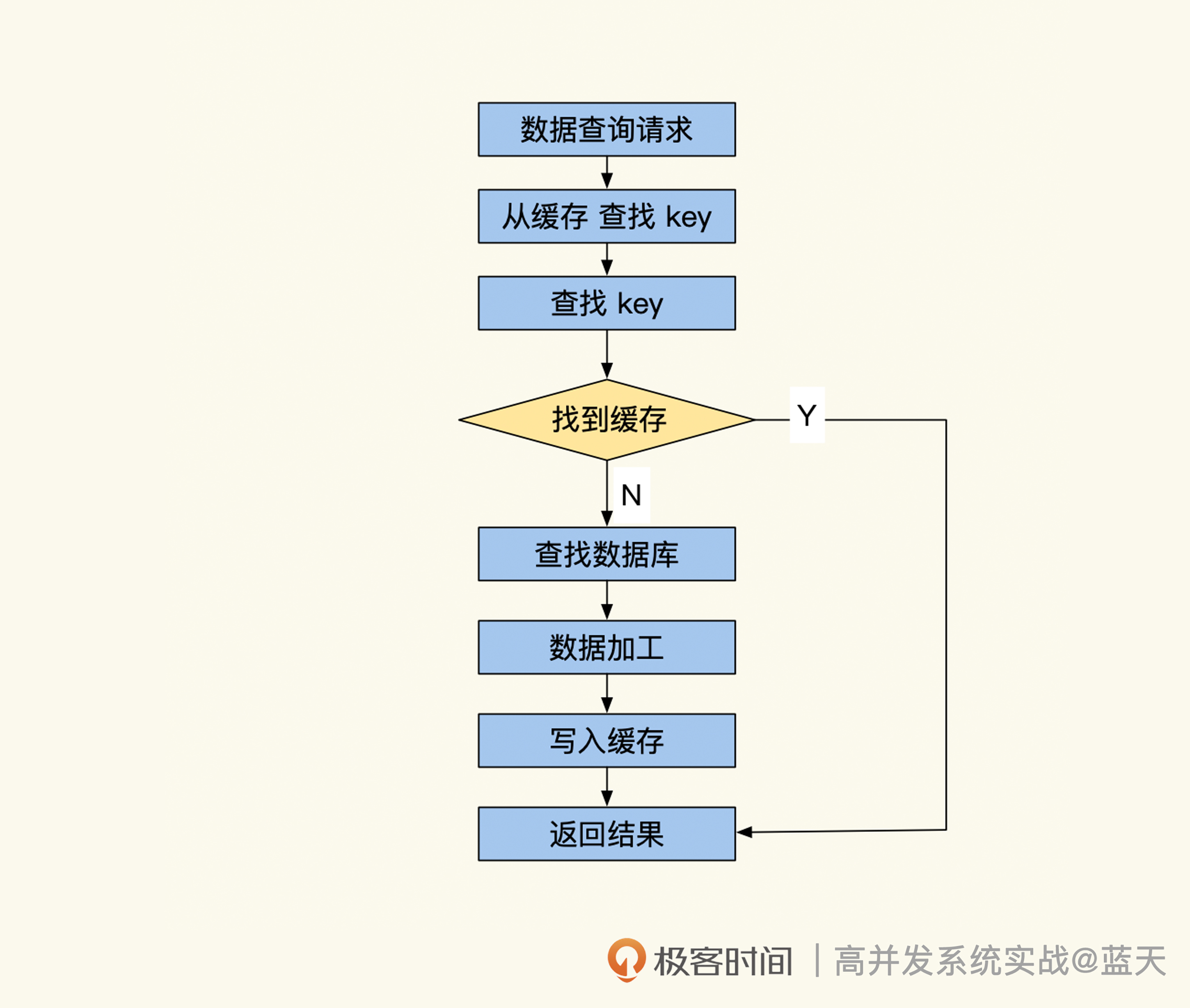
缓存查询及数据缓存服务
如上图所示,当我们查找缓存时如果没找到数据,中间件就会通过 Key 识别出待查数据属于数据库的哪个表和处理脚本,再按配置执行脚本查询数据库做数据加工,然后中间件将获取的数据回填到缓存当中,最后再返回结果。为了提高查询效率,建议查询服务使用类似 Redis 的纯文本长链接协议,同时还需要支持批量获取功能,比如 Redis 的 mget 实现。如果我们的数据支撑架构很复杂,并且一次查询的数据量很大,还可以做成批量并发处理来提高系统吞吐性能。落地缓存服务还有一些实操的技巧,我们一起看看。如果查询缓存时数据不存在,会导致请求缓存穿透的问题,请求量很大核心数据库就会崩溃。为了预防这类问题我们需要在缓存中加一个特殊标志,这样查询服务查不到数据时,就会直接返回数据不存在。我们还要考虑到万一真的出现缓存穿透问题时,要如何限制数据库的并发数,建议使用 SingleFlight 合并并行请求,无需使用全局锁,只要在每个服务范围内实现即可。有时要查询的数据分布在数据库的多个表内,我们需要把多个表的数据组合起来或需要刷新多个缓存,所以这要求我们的缓存服务能提供定制脚本,这样才能实现业务数据的刷新。另外,由于是数据库和缓存这两个系统之间的同步,为了更好的排查缓存同步问题,建议在数据库中和缓存中都记录数据最后更新的时间,方便之后对比。到这里,我们的服务就基本完整了。当业务需要按 id 查找数据时,直接调用数据中间件即可获取到最新的数据,而无需重复实现,开发过程变得简单很多。
L1 缓存及热点缓存延期
上面我们设计的缓存中间件已经能够应付大部分临时缓存所需的场景。但如果碰到大并发查询的场景,缓存出现缺失或过期的情况,就会给数据库造成很大压力,为此还需要继续改进这个服务。改进方式就是统计查询次数,判断被查询的 key 是否是热点缓存。举个例子,比如通过时间块异步统计 5 分钟内缓存 key 被访问的次数,单位时间内超过设定次数(根据业务实现设定)就是热点缓存。
具体的热点缓存统计和续约流程如下图所示:
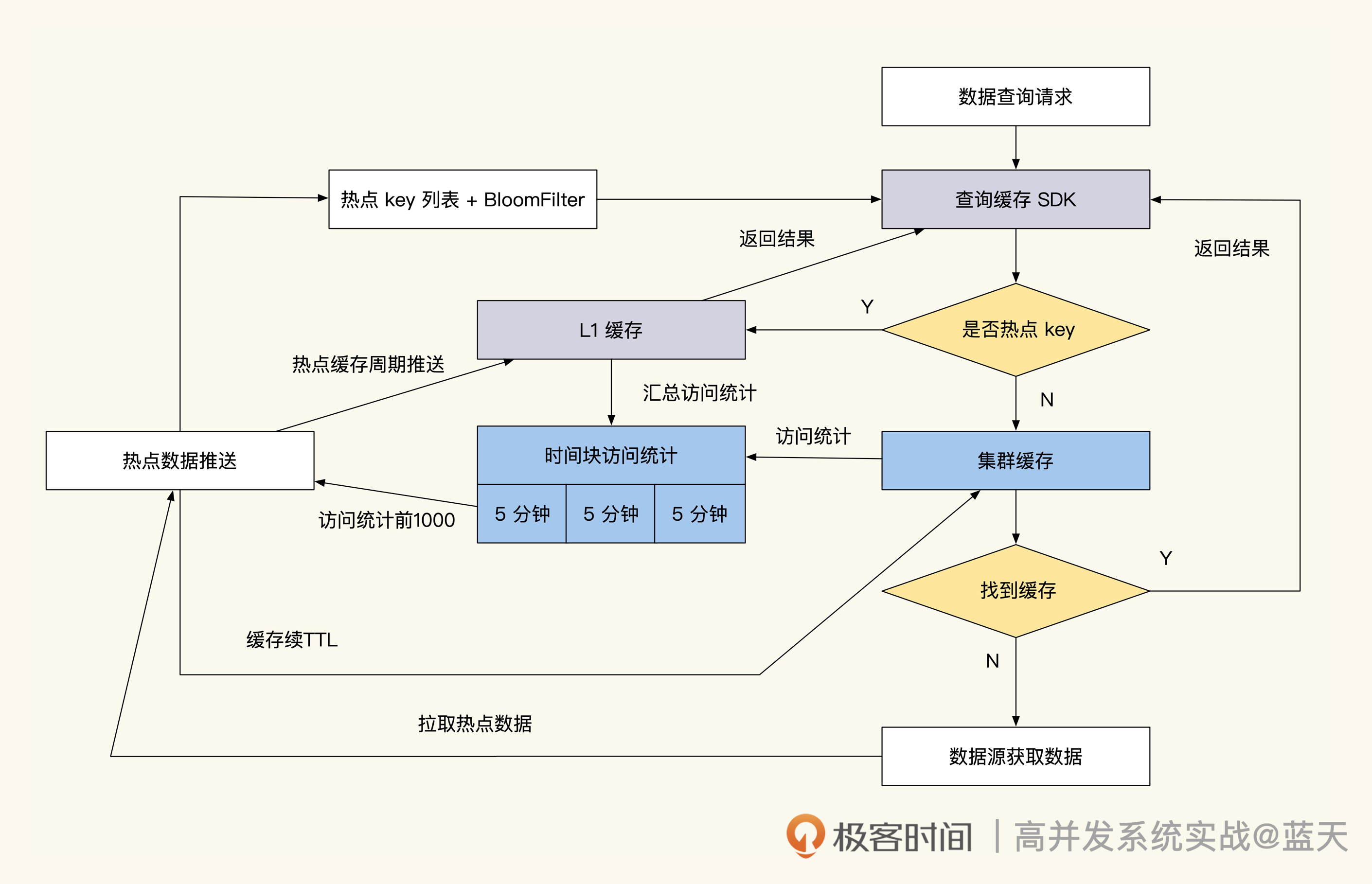
热点缓存及续约
对照流程图可以看到,热点统计服务获取了被认定是热点的 key 之后,会按统计次数大小做区分。如果是很高频率访问的 key 会被定期从脚本推送到 L1 缓存中(L1 缓存可以部署在每台业务服务器上,或每几台业务服务器共用一个 L1 缓存)。当业务查询数据时,业务的查询 SDK 驱动会通过热点 key 配置,检测当前 key 是否为热点 key,如果是会去 L1 缓存获取,如果不是热点缓存会去集群缓存获取数据。而相对频率较高的 key 热点缓存服务,只会定期通知查询服务刷新对应的 key,或做 TTL 刷新续期的操作。当我们被查询的数据退热后,我们的数据时间块的访问统计数值会下降,这时 L1 热点缓存推送或 TTL 续期会停止继续操作,不久后数据会 TTL 过期。增加这个功能后,这个缓存中间件就可以改名叫做数据缓存平台了,不过它和真正的平台还有一些差距,因为这个平台只能提供实体数据的缓存,无法灵活加工推送的数据,一些业务结构代码还要人工实现。
关系数据缓存
可以看到,目前我们的缓存还仅限于实体数据的缓存,并不支持关系数据库的缓存。为此,我们首先需要改进消息监听服务,将它做成 Kafka Group Consumer 服务,同时实现可动态扩容,这能提升系统的并行数据处理能力,支持更大量的并发修改。其次,对于量级更高的数据缓存系统,还可以引入多种数据引擎共同提供不同的数据支撑服务,比如:lua 脚本引擎(具体可以回顾第十七节课)是数据推送的“发动机”,能帮我们把数据动态同步到多个数据源;Elasticsearch 负责提供全文检索功能;Pika 负责提供大容量 KV 查询功能;ClickHouse 负责提供实时查询数据的汇总统计功能;MySQL 引擎负责支撑新维度的数据查询。你有没有发现这几个引擎我们在之前的课里都有涉及?唯一你可能感到有点陌生的就是 Pika,不过它也没那么复杂,可以理解成 RocksDB 的加强版。这里我没有把每个引擎一一展开,但概括了它们各自擅长的方面。如果你有兴趣深入研究的话,可以自行探索,看看不同引擎适合用在什么业务场景中。
多数据引擎平台
一个理想状态的多数据引擎平台是十分庞大的,需要投入很多人力建设,它能够给我们提供强大的数据查询及分析能力,并且接入简单方便,能够大大促进我们的业务开发效率。
为了让你有个整体认知,这里我特意画了一张多数据引擎平台的架构图,帮助你理解数据引擎和缓存以及数据更新之间的关系,如下图所示:
多数据引擎平台架构图
可以看到,这时基础数据服务已经做成了一个平台。MySQL 数据更新时,会通过我们订阅的变更消息,根据数据加工过滤进程,将数据推送到不同的引擎当中,对外提供数据统计、大数据 KV、内存缓存、全文检索以及 MySQL 异构数据查询的服务。具体业务需要用到核心业务基础数据时,需要在该平台申请数据访问授权。如果还有特殊需要,可以向平台提交数据加工 lua 脚本。高流量的业务甚至可以申请独立部署一套数据支撑平台。
总结
这节课我们一起学习了统一缓存数据平台的实现方案,有了这个中间件,研发效率会大大提高。在使用数据支撑组件之前,是业务自己实现的缓存以及多数据源的同步,需要我们业务重复写大量关于缓存刷新的逻辑,如下图:
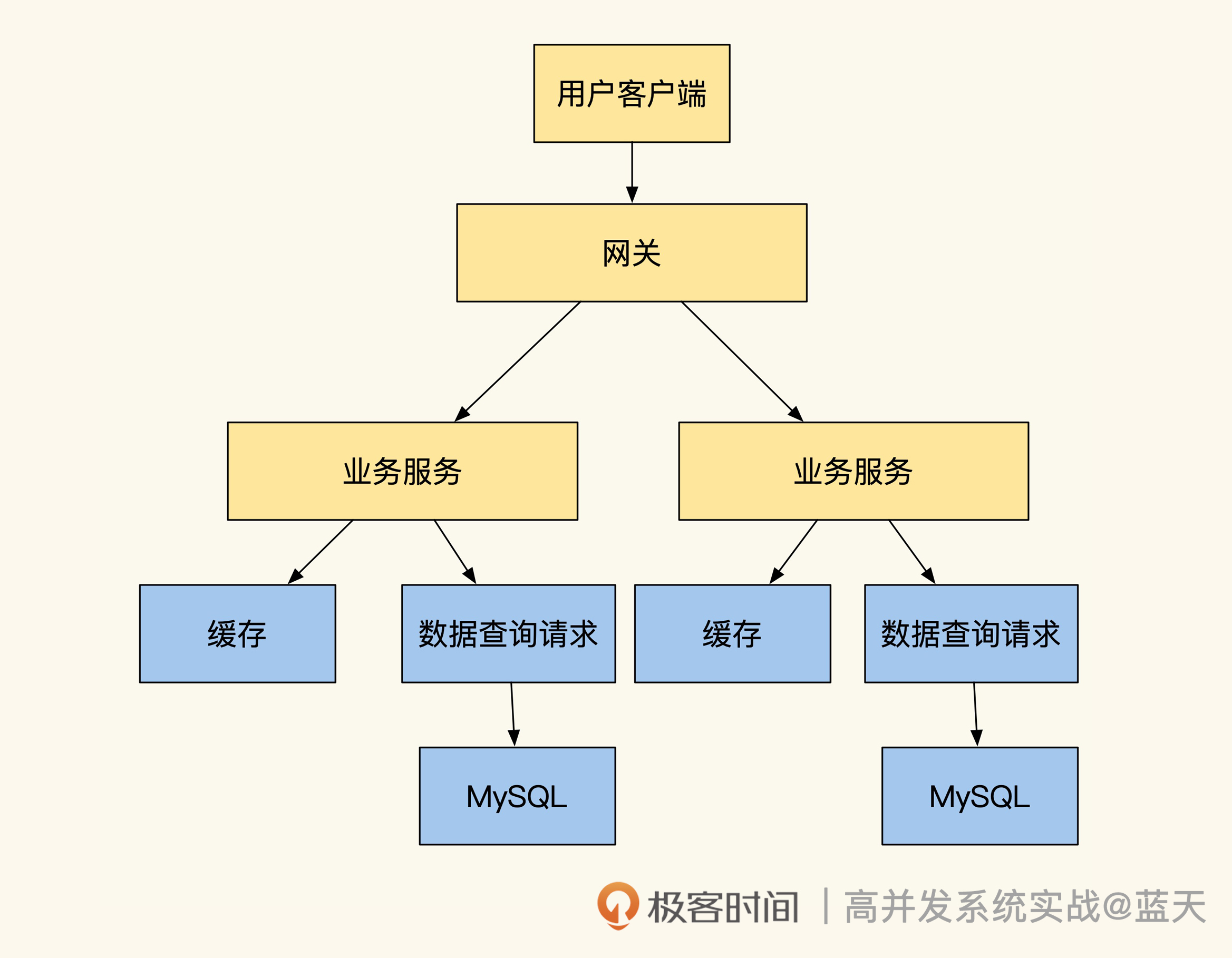
自实现多数据引擎同步及多级缓存而使用数据缓存平台后,我们省去了很多人工实现的工作量,研发同学只需要在平台里做好配置,就能坐享中间件提供的强大多级缓存功能、多种数据引擎提供的数据查询服务,如下图所示:
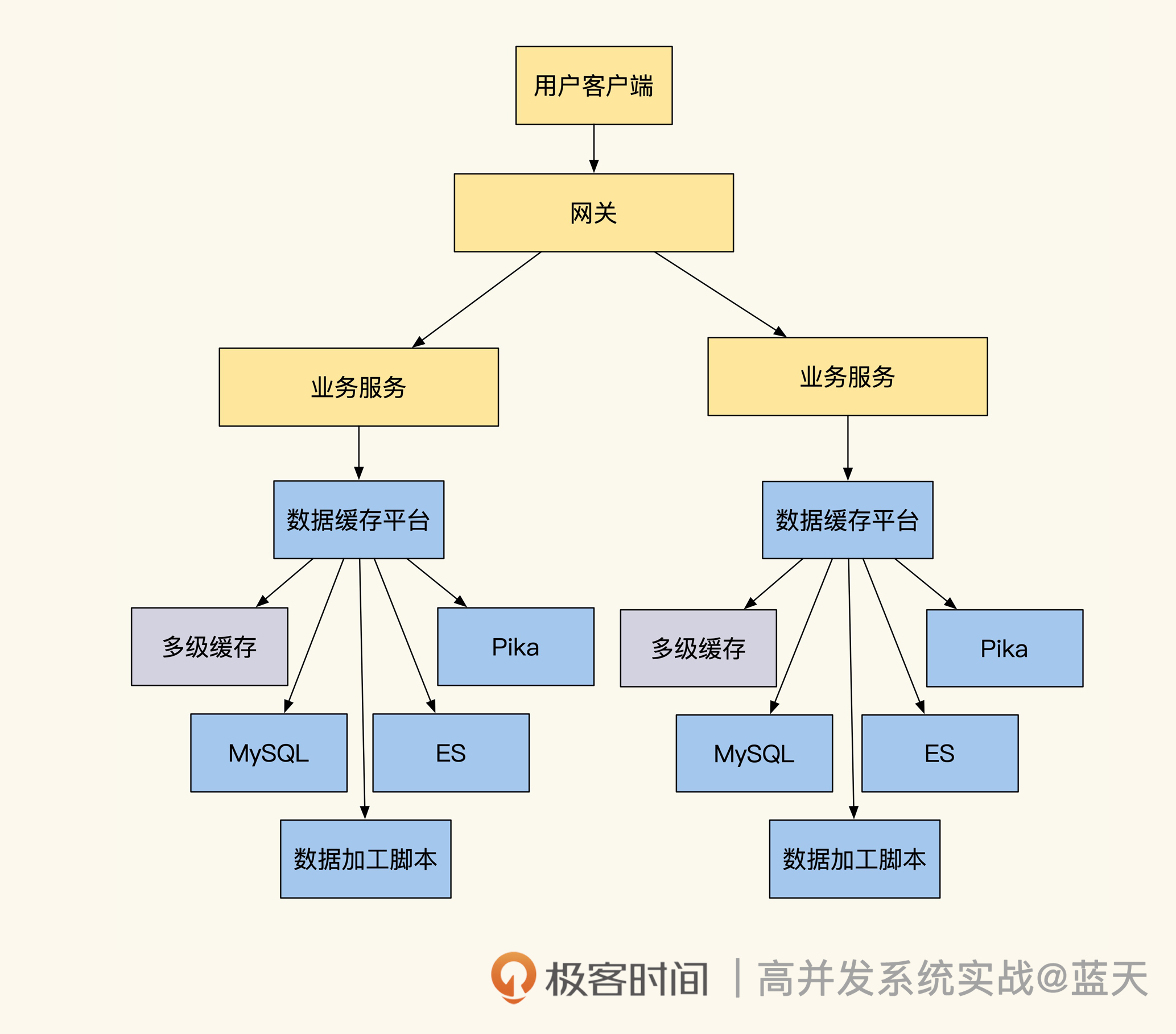
通过数据缓存平台对外服务
我们回顾下中间件的工作原理。首先我们通过 Canal 订阅 MySQL 数据库的 binlog,获取数据的变更消息。然后,缓存平台根据订阅变更信息实现触发式的缓存更新。另外,结合客户端 SDK 及缓存查询服务实现热点数据的识别,即可实现多级缓存服务。可以说, 数据是我们系统的心脏,如数据引擎能力足够强大,能做的事情会变得更多。数据支撑平台最大的特点在于,将我们的数据和各种数据引擎结合起来,从而实现更强大的数据服务能力。大公司的核心系统通常会用多引擎组合的方式,共同提供数据支撑数据服务,甚至有些服务的服务端只需做配置就可以得到这些功能,这样业务实现更轻量,能给业务创造更广阔的增值空间。
业务缓存:元数据服务如何实现?
当你随手打开微博或者一个综合的新闻网站,可以看到丰富的媒体文件,图片、文本、音频、视频应有尽有,一个页面甚至可能是由成百上千个文件组合而成。那这些文件都存在哪里呢?通常来说,低于 1KB 的少量文本数据,我们会保存在数据库中,而比较大的文本或者多媒体文件(比如 MP4、TS、MP3、JPG、JS、CSS 等等)我们通常会保存在硬盘当中,这些文件的管理并不复杂。不过如果文件数量达到百万以上,用硬盘管理文件的方式就比较麻烦了,因为用户请求到服务器时,有几十台服务器需要从上百块硬盘中找到文件保存在哪里,还得做好定期备份、统计访问记录等工作,这些给我们的研发工作带来了很大的困扰。直到出现了对象存储这种技术,帮我们屏蔽掉了很多细节,这大大提升了研发效率。这节课,我们就聊聊存储的演变过程,让你对服务器存储和对象存储的原理和实践有更深的认识。
分布式文件存储服务
在讲解对象存储之前,我们先了解一下支撑它的基础——分布式文件存储服务,这也是互联网媒体资源的数据支撑基础。我们先来具体分析一下,分布式文件存储提供了什么功能,以及数据库管理文件都需要做哪些事儿。因为数据库里保存的是文件路径,在迁移、归档以及副本备份时,就需要同步更新这些记录。当文件数量达到百万以上,为了高性能地响应文件的查找需求,就需要为文件索引信息分库分表,而且还需要提供额外的文件检索、管理、访问统计以及热度数据迁移等服务。那么这些索引和存储具体是如何工作的呢?请看下图:
通过数据库管理文件
我们从上图也能看出,光是管理好文件的索引这件事,研发已经疲于奔命了,更不要说文件存储、传输和副本备份工作,这些工作更加复杂。在没有使用分布式存储服务之前,实现静态文件服务时,我们普遍采用 Nginx + NFS 挂载 NAS 这个方式实现,但是该方式缺点很明显,文件只有一份而且还需要人工定期做备份。为了在存储方面保证数据完整性,提高文件服务的可用性,并且减少研发的重复劳动,业内大多数选择了用分布式存储系统来统一管理文件分发和存储。通过分布式存储,就能自动实现动态扩容、负载均衡、文件分片或合并、文件归档,冷热点文件管理加速等服务,这样管理大量的文件的时候会更方便。为了帮助你理解常见的分布式存储服务是如何工作的,我们以 FastDFS 分布式存储为例做个分析,请看下图:
常见分布式存储内部机制
其实,分布式文件存储的方案也并不是十全十美的。就拿 FastDFS 来说,它有很多强制规范,比如新保存文件的访问路径是由分布式存储服务生成的,研发需要维护文件和实际存储的映射。这样每次获取要展示的图片时,都需要查找数据库,或者为前端提供一个没有规律的 hash 路径,这样一来,如果文件丢失的话前端都不知道这个文件到底是什么。FastDFS 生成的文件名很难懂,演示路径如下所示:
# 在网上找的FastDFS生成的演示路径
/group1/M00/03/AF/wKi0d1QGA0qANZk5AABawNvHeF0411.png
相信你一定也发现了,这个地址很长很难懂,这让我们管理文件的时候很不方便,因为我们习惯通过路径层级归类管理各种图片素材信息。如果这个路径是 /active/img/banner1.jpg,相对就会更好管理。虽然我只是举了一种分布式存储系统,但其他分布式存储系统也会有这样那样的小问题。这里我想提醒你注意的是,即便用了分布式存储服务,我们的运维和研发工作也不轻松。为什么这么说呢?根据我的实践经验,我们还需要关注以下五个方面的问题:1. 磁盘监控:监控磁盘的寿命、容量、inode 剩余,同时我们还要故障监控警告及日常维护;2. 文件管理:使用分布式存储控制器对文件做定期、冷热转换、定期清理以及文件归档等工作。3. 确保服务稳定:我们还要关注分布式存储副本同步状态及服务带宽。如果服务流量过大,运维和研发还需要处理好热点访问文件缓存的问题。4. 业务定制化:一些稍微个性点的需求,比如在文件中附加业务类型的标签、增加自动 TTL 清理,现有的分布式存储服务可能无法直接支持,还需要我们阅读相关源码,进一步改进代码才能实现功能。5. 硬件更新:服务器用的硬盘寿命普遍不长,特别是用于存储服务的硬盘,需要定期更换(比如三年一换)。
对象存储
自从使用分布式存储后,再回想过往的经历做总结时,突然觉得磁盘树形的存储结构,给研发带来很多额外的工作。比如,挂载磁盘的服务,需要在上百台服务器和磁盘上提供相对路径和绝对路径,还要有能力提供文件检索、遍历功能以及设置文件的访问权限等。这些其实属于管理功能,并不是我们对外业务所需的高频使用的功能,这样的设计导致研发投入很重,已经超出了研发本来需要关注的范围。这些烦恼在使用对象存储服务后,就会有很大改善。对象存储完美解决了很多问题,这个设计优雅地屏蔽了底层的实现细节,隔离开业务和运维的工作,让我们的路径更优雅简单、通俗易懂,让研发省下更多时间去关注业务。对象存储的优势具体还有哪些?我主要想强调后面这三个方面。首先,从文件索引来看。在对象存储里,树形目录结构被弱化,甚至可以说是被省略了。之所以说弱化,意思是对象存储里树形目录结构仍然可以保留。当我们需要按树形目录结构做运维操作的时候,可以利用前缀检索对这些 Key 进行前缀检索,从而实现目录的查找和管理。整体使用起来很方便,不用担心数据量太大导致索引查找缓慢的问题。我想强调一下,对象存储并不是真正按照我们指定的路径做存储的,实际上文件的路径只是一个 key。当我们查询文件对象时,实际上是做了一次 hash 查询,这比在数据库用字符串做前缀匹配查询快得多。而且由于不用维护整体树索引,KV 方式在查询和存储上都快了很多,还更容易做维护。其次,读写管理也从原先的通过磁盘文件管理,改成了通过 API 方式管理文件对象,经过这种思路简化后的接口方式会让数据读写变得简单,使用起来更灵活方便,不用我们考虑太多磁盘相关的知识。另外,对象存储还提供了文件的索引管理与映射,管理数据和媒体文件有了更多可能。在之前我们的文件普遍是图片、音频、视频文件,这些文件普遍对于业务系统来说属于独立的存在,结合对象存储后,我们就可以将一些数据当作小文件管理起来。但是,如果把数据放到存储中,会导致有大量的小文件需要管理,而且这些小文件很碎,需要更多的管理策略和工具。我们这就来看看对象存储的思路下,如何管理小文件。
对象存储如何管理小文件
前面我提过对象存储里,实际的存储路径已经变成了 hash 方式存储。为此我们可以用一些类似 RESTful 的思路去设计我们的对象存储路径,如:user\info\9527.json 保存的是用户的公共信息user\info\head\9527.jpg 是我们的对应用户的头像product\detail\4527.json 直接获取商品信息可以看到,通过这个设计,我们无需每次请求都访问数据库,就可以获取特定对象的信息,前端只需要简单拼接路径就能拿到所有所需文件,这样的方式能帮我们减少很多缓存的维护成本。看到这里,你可能有疑问:既然这个技巧十分好用,那么为什么这个技巧之前没有普及?这是因为以前的实现中,请求访问的路径就是文件实际物理存储的路径,而对于 Linux 来说,一个目录下文件无法放太多文件,如果放太多文件会导致很难管理。就拿上面的例子来说,如果我们有 300W 个用户。把 300W 个头像文件放在同一个目录,这样哪怕是一个 ls 命令都能让服务器卡住十分钟。为了避免类似的问题,很多服务器存储这些小文件时,会用文件名做 hash 后,取 hash 结果最后四位作为双层子目录名,以此来保证一个目录下不会存在太多文件。但是这么做需要通过 hash 计算,前端用起来十分不便,而且我们平时查找、管理磁盘数据也十分痛苦,所以这个方式被很多人排斥。不过,即使切换到了分布式存储服务,小文件存储这个问题还是让我们困扰,因为做副本同步和存储时都会以文件为单位来进行。如果文件很小,一秒上传上千个,做副本同步时会因为大量的分配调度请求出现延迟,这样也很难管理副本同步的流量。为了解决上述问题,对象存储和分布式存储服务对这里做了优化,小文件不再独立地保存,而是用文件块方式压缩存储多个文件。文件块管理示意图如下所示:
文件块合并小文件
比如把 100 个文件压缩存储到一个 10M 大小的文件块里统一管理,比直接管理文件简单很多。不过可以预见这样数据更新会麻烦,为此我们通常会在小文件更新数据时,直接新建一个文件来更新内容。定期整理数据的时候,才会把新老数据合并写到新的块里,清理掉老数据。这里顺便提示一句,大文件你也可以使用同样的方式,切成多个小文件块来管理,这样更方便。
对象存储如何管理大文本
前面我们讲了对象存储在管理小文件管理时有什么优势,接下来我们就看看对象存储如何管理大文本,这个方式更抽象地概括,就是用对象存储取代缓存。什么情况下会有大文本的管理需求呢?比较典型的场景就是新闻资讯网站,尤其是资讯量特别丰富的那种,常常会用对象存储直接对外提供文本服务。这样设计,主要是因为 1KB 大小以上的大文本,其实并不适合放在数据库或者缓存里,这是为什么呢?我们结合后面的示意图分析一下。
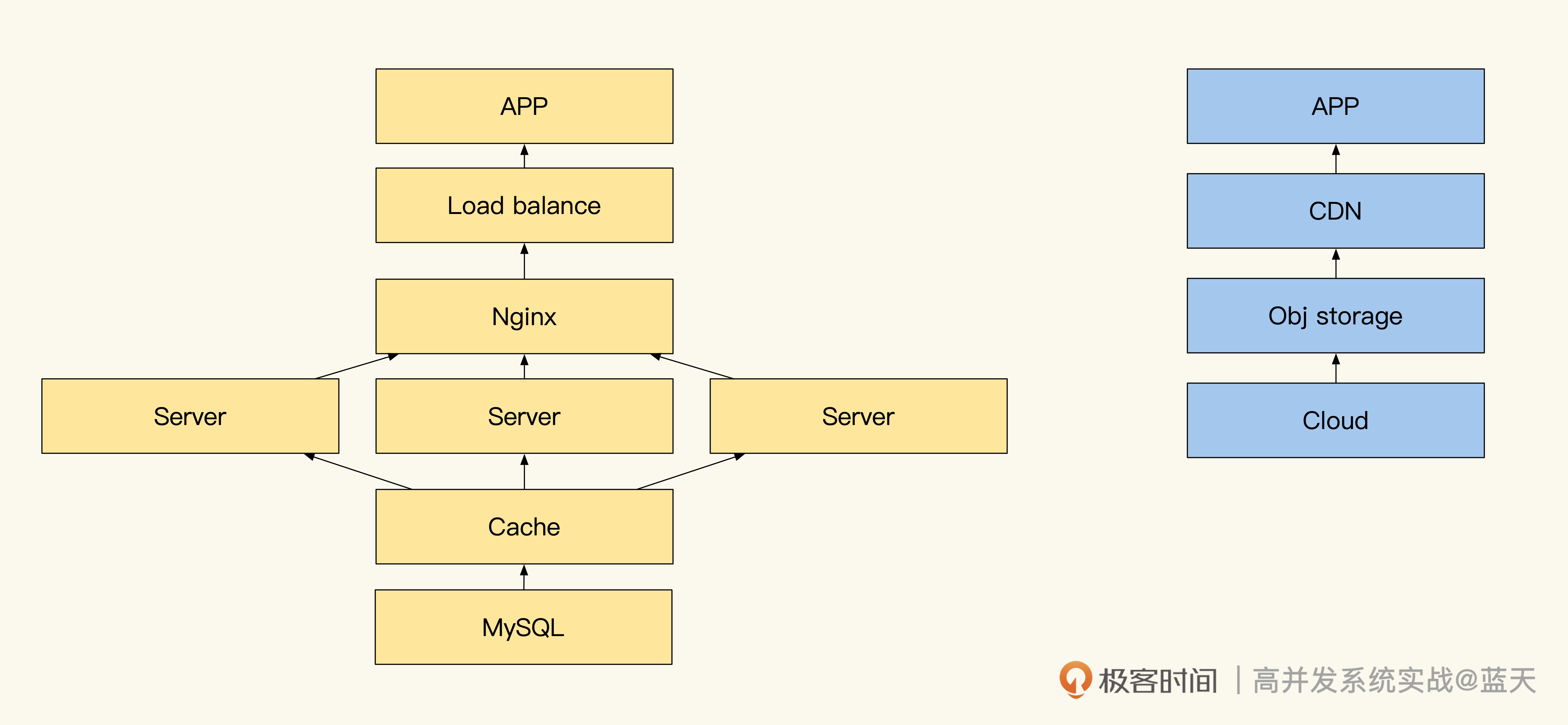
数据缓存与对象存储服务实现区别
如上图,左边是我们通过缓存提供数据查询服务的常见方式,右图则是通过对象存储的方式,从结构上看,对象存储使用及维护更方便简单。我们来估算一下成本。先算算带宽需求,假定我们的请求访问量是 1W QPS,那么 1KB 的数据缓存服务就需要 1KB X 10000 QPS 约等于 10MB X 8(网卡单位转换 bit)= 80MB/s (网络带宽单位)的外网带宽。为了稍微留点余地,这样我们大概需要 100MB/s 大小的带宽。另外,我们还需要多台高性能服务器和一个大容量的缓存集群,才能实现我们的服务。这么一算是不是感觉成本挺高的?像资讯类网站这种读多写少的系统,不能降低维护成本,就意味着更多的资源投入。我们常见的解决方法就是把资讯内容直接生成静态文件,不过这样做流量成本是控制住了,但运维和开发成本又增高了,还有更好的方法么?相比之下,用对象存储来维护资源的具体页面这个方式更胜一筹。我们具体分析一下主要过程:所有的流量会请求到云厂商的对象存储服务,并且由 CDN 实现缓存及加速。一旦 CDN 找不到待查文件时,就会回源到对象存储查找,如果对象存储也找不到,则回源到服务端生成。这样可以大大降低网络流量压力,如果配合版本控制功能,还能回退文件的历史版本,提高服务可用性。这里我再稍微补充一下实践细节。如果资讯有阅读权限限制,比如只有会员才能阅读。我们可以对特定对象设置权限,只有用短期会失效的 token 才可以读取文件的内容。
文件的云中转
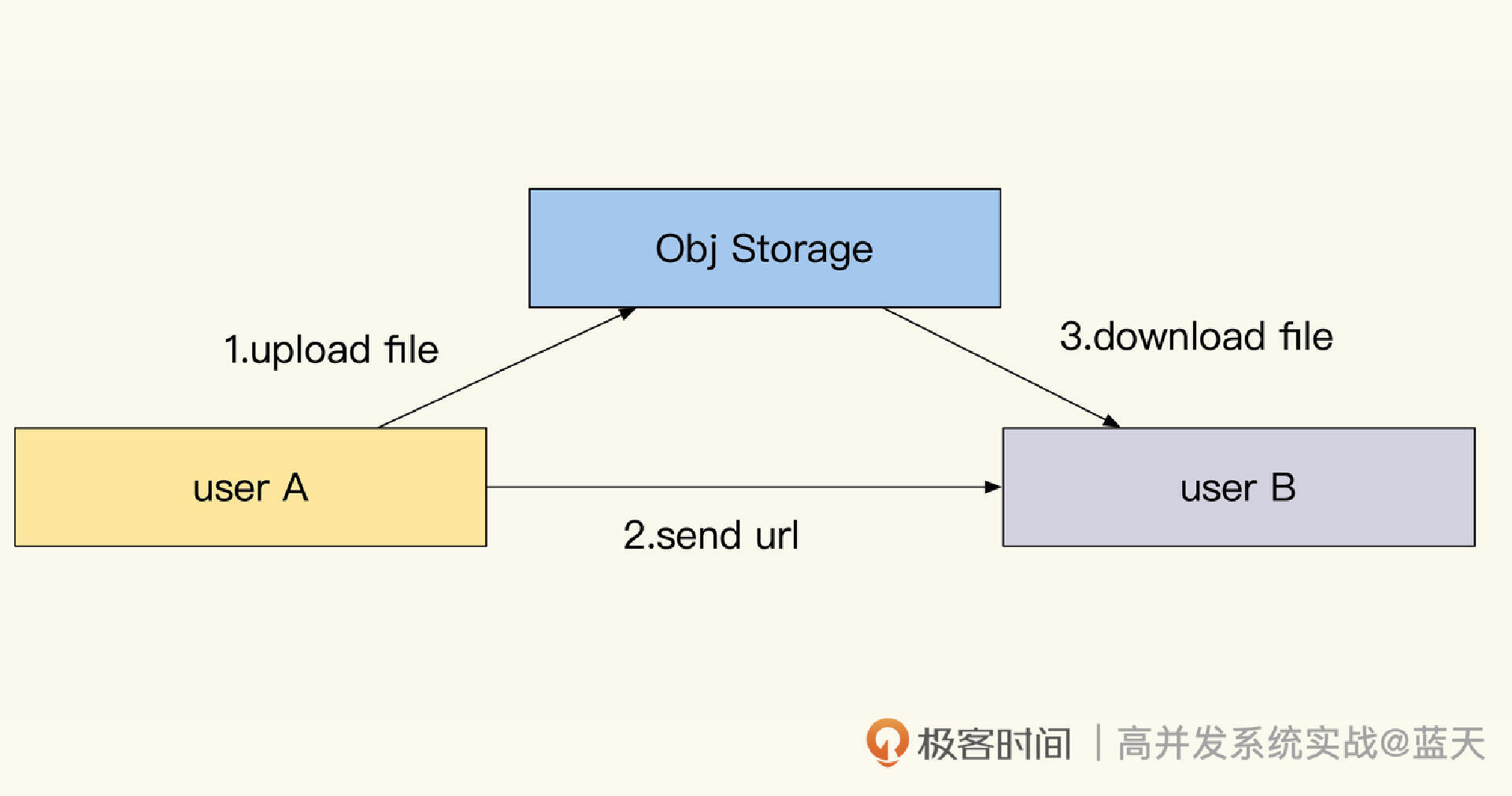
通过云中转传数据
除了服务端提供数据供用户下载的方式以外,还有一种实现比较普遍,就是用户之间交换数据。比如 A 用户传递给 B 用户一个文件,正常流程是通过 TCP 将两个客户端链接或通过服务端中转,但是这样的方式传输效率都很低。而使用对象存储的话,就能快速实现文件的传输交换。主要过程是这样的:文件传输服务给文件发送方生成一个临时授权 token,再将这个文件上传到对象存储,上传成功后,接收方通过地址即可获取到授权 token,进行多线程下载,而临时文件过期后就会自动清除。事实上,这个方式不仅仅可以给用户交换数据,我们的业务也可以通过对象存储,实现跨机房数据交换和数据备份存储。很多提供对象服务的厂商,已经在客户端 SDK 内置了多线程分片上传下载、GSLB 就近 CDN 线路优化上传加速的功能,使用这类服务能大大加快数据传输的速度。最后,再提一句容灾,可以说大部分对象存储服务的服务商都提供了容灾服务,我们所有的数据都可以开启同城做双活备份、全球加速、灾难调度、主备切换等功能。
总结这节课我们一起学习了对象存储。通过和传统存储方式的对比,不难发现对象存储的优势所在。首先它的精简设计彻底屏蔽了底层实现细节,降低了磁盘维护的运维投入和维护成本。我们可以把一些经常读取的数据从数据库挪到对象存储中,通过 CDN 和本地缓存实现来降低成本,综合应用这些经典设计会帮我们节约大量的时间和资源。希望这节课激发你对对象存储的探索兴趣。行业里常用的对象存储项目包括:阿里云的 OSS,腾讯的 COS,华为云的 OBS,开源方面有 Ceph、MinIO 等项目。通过了解这些项目,你会对存储行业的未来发展趋势有更深入的认识。事实上,这个行业开始专注于为大型云服务厂商提供大型高速存储的服务,这样的集中管理会更加节省成本。最后,我还为你整理了一个表格,帮你从多个维度审视不同存储技术的特点:
可以看到,它们的设计方向和理念不同,NFS 偏向服务器的服务,分布式存储偏向存储文件的管理,而对象存储偏向业务的应用。
存储成本:如何推算日志中心的实现成本?
前面我们比较过很多技术,细心的你应该发现了,比较时我们常常会考虑实现成本这一项。这是因为技术选型上的“斤斤计较”,能够帮我们省下真金白银。那么你是否系统思考过,到底怎么计算成本呢?这节课,我会结合日志中心的例子带你计算成本。之所以选日志中心,主要有这两方面的考虑:一方面是因为它重要且通用,作为系统监控的核心组件,几乎所有系统监控和故障排查都依赖日志中心,大部分的系统都用得上;另一方面日志中心是成本很高的项目,计算也比较复杂,如果你跟着我把课程里的例子拿下了,以后用类似思路去计算其他组件也会容易很多。
根据流量推算存储容量及投入成本
在互联网服务中,最大的变数就在用户流量上。相比普通的服务,高并发的系统需要同时服务的在线人数会更多,所以对这类系统做容量设计时,我们就需要根据用户请求量和同时在线人数,来推算系统硬件需要投入多少成本。很多系统在初期会用云服务实现日志中心,但核心接口流量超过 10W QPS 后,很多公司就会考虑自建机房去实现,甚至后期还会持续改进日志中心,自己制作一些个性化的服务。其实,这些优化和实现本质上都和成本息息相关。这么说你可能不太理解,所以我们结合例子,实际算算一个网站的日志中心存储容量和成本要怎么计算。通常来说,一个高并发网站高峰期核心 API 的 QPS 在 30W 左右,我们按每天 8 个小时来计算,并且假定每次核心接口请求都会产生 1KB 日志,这样的话每天的请求量和每天的日志数据量就可以这样计算:每天请求量 =3600 秒 X 8 小时 X 300000 QPS = 8 640 000 000 次请求 / 天 = 86 亿次请求 / 天每天日志数据量:8 640 000 000 X 1KB => 8.6TB/ 天你可能奇怪,这里为什么要按每天 8 小时 计算?这是因为大多数网站的用户访问量都很有规律,有的网站集中在上下班时间和夜晚,有的网站访问量集中在工作时间。结合到一人一天只有 8 小时左右的专注时间,就能推导出一天按 8 小时计算比较合理。当然这个数值仅供参考,不同业务表现会不一样,你可以根据这个思路,结合自己的网站用户习惯来调整这个数值。我们回到刚才的话题,根据上面的算式可以直观看到,如果我们的单次请求产生 1KB 日志的话,那么每天就有 8T 的日志需要做抓取、传输、整理、计算、存储等操作。为了方便追溯问题,我们还需要设定日志保存的周期,这里按保存 30 天计算,那么一个月日志量就是 258TB 大小的日志需要存储,计算公式如下:8.6TB X 30 天 = 258 TB /30 天
从容量算硬盘的投入
算完日志量,我们就可以进一步计算购买硬件需要多少钱了。我要提前说明的是,硬件价格一直是动态变化的,而且不同商家的价格也不一样,所以具体价格会有差异。这里我们把重点放在理解整个计算思路上,学会以后,你就可以结合自己的实际情况做估算了。目前常见的服务器硬盘(8 TB、7200 转、3.5 寸)的单价是 2300 元 ,8 TB 硬盘的实际可用内存为 7.3 TB,结合前面每月的日志量,就能算出需要的硬盘个数。计算公式如下:258 TB/7.3 TB = 35.34 块因为硬盘只能是整数,所以需要 36 块硬盘。数量和单价相乘,就得到了购入硬件的金额,即:2300 元 X 36 = 82800 元为了保证数据的安全以及加强查询性能,我们常常会通过分布式存储服务将数据存三份,那么分布式存储方案下,用单盘最少需要 108 块硬盘,那么可以算出我们需要的投入成本是:82800 X 3 个数据副本 = 24.8W 元如果要保证数据的可用性,硬盘需要做 Raid5。该方式会把几个硬盘组成一组对外服务,其中一部分用来提供完整容量,剩余部分用于校验。不过具体的比例有很多种,为了方便计算,我们选择的比例是这样的:按四个盘一组,且四个硬盘里有三个提供完整容量,另外一个做校验。Raid5 方式中计算容量的公式如下:单组 raid5 容量 =((n-1)/n) * 总磁盘容量,其中 n 为硬盘数我们把硬盘数代入到公式里,就是:((4-1)/4) X (7.3T X 4) = 21.9 T = 三块 8T 硬盘容量这个结果表示一组 Raid5 四个硬盘,有三个能提供完整容量,由此不难算出我们需要的容量还要再增加 1/4,即:108 / 3 = 36 块校验盘最终需要的硬盘数量就是 108 块 + 36 块 Raid5 校验硬盘 = 144 块硬盘,每块硬盘 2300 元,总成本是:144 X 2300 元 = 331200 元为了计算方便,之后我们取整按 33W 元来计算。除了可用性,还得考虑硬盘的寿命。因为硬盘属于经常坏的设备,一般连续工作两年到三年以后,会陆续出现坏块,由于有时出货缓慢断货等原因以及物流问题,平时需要常备 40 块左右的硬盘(大部分公司会常备硬盘总数的三分之一)用于故障替换,大致需要的维护成本是 2300 元 X 40 = 92000 元。到目前为止。我们至少需要投入的硬成本,就 T 是一次性硬盘购买费用加上维护费用,即 33 + 9.2 = 42W 元。
根据硬盘推算服务器投入
接下来,我们还需要计算服务器的相关成本。由于服务器有多个规格,不同规格服务器能插的硬盘个数是不同的,情况如下面列表所示:普通 1u 服务器 能插 4 个 3.5 硬盘 、SSD 硬盘 2 个普通 2u 服务器 能插 12 个 3.5 硬盘 、SSD 硬盘 6 个上一环节我们计算过了硬盘需求,做 Raid5 的情况下需要 144 块硬盘。这里如果使用 2u 服务器,那么需要的服务器数量就是 12 台(144 块硬盘 /12 = 12 台)。我们按一台服务器 3W 元的费用来计算,服务器的硬件投入成本就是 36W 元,计算过程如下:12 台服务器 X 3W = 36W 元这里说个题外话,同样数据的副本要分开在多个机柜和交换机分开部署,这么做的目的是提高可用性。
根据服务器托管推算维护费用
好,咱们回到计算成本的主题上。除了购买服务器,我们还得算算维护费用。把 2u 服务器托管在较好的机房里, 每台服务器托管的费用每年大概是 1W 元。前面我们算过服务器需要 12 台,那么一年的托管费用就是 12W 元。现在我们来算算第一年的投入是多少,这个投入包括硬盘的投入及维护费用、服务器的硬件费用和托管费用,以及宽带费用。计算公式如下:第一年投入费用 = 42W(硬盘新购与备用盘)+ 36W(服务器一次性投入)+ 12W(服务器托管费)+ 10W(宽带费用)= 100W 元而后续每年维护费用,包括硬盘替换费用(假设都用完)、服务器的维护费用和宽带费用。计算过程如下:9.2W(备用硬盘)+12W(一年托管)+10W(一年宽带)=31.2W 元根据第一年投入费用和后续每年的维护费用,我们就可以算出核心服务(30W QPS 的)网站服务运转三年所需要的成本,计算过程如下:31.2W X 2 年 = 62.4W + 第一年投入 100W = 162.4W 元当然,这里的价格并没有考虑大客户购买硬件的折扣、服务容量的冗余以及一些网络设备、适配卡等费用以及人力成本。但即便忽略这些,算完前面这笔账,再想想用 2000 台服务器跑 ELK 的场景,相信你已经体会到,多写一行日志有多么贵了。
服务器采购冗余
接下来,我们再聊聊采购服务器要保留冗余的事儿,这件事儿如果没亲身经历过,你可能很容易忽略。如果托管的是核心机房,我们就需要关注服务器采购和安装周期。因为很多核心机房常常缺少空余机柜位,所以为了给业务后几年的增长做准备,很多公司都是提前多买几台备用。之前有的公司是按评估出结果的四倍来准备服务器,不过不同企业增速不一样,冗余比例无法统一。我个人习惯是根据当前流量增长趋势,评估出的 3 年的服务器预购数量。所以,回想之前我们计算的服务器费用,只是算了系统计算刚好够用的流量,这么做其实是已经很节俭了。实际你做估算的时候一定要考虑好冗余。
如何节省存储成本?
一般来说,业务都有成长期,当我们业务处于飞速发展、快速迭代的阶段,推荐前期多投入硬件来支撑业务。当我们的业务形态和市场稳定后,就要开始琢磨如何在保障服务的前提下降低成本的问题。
临时应对流量方案
如果在服务器购买没有留冗余的情况下,服务流量增长了,我们有什么暂时应对的方式呢?我们可以从节省服务器存储量或者降低日志量这两个思路入手,比如后面这些方式:减少我们保存日志的周期,从保存 30 天改为保存 7 天,可以节省四分之三的空间;非核心业务和核心业务的日志区分开,非核心业务只存 7 天,核心业务则存 30 天;减少日志量,这需要投入人力做分析。可以适当缩减稳定业务的排查日志的输出量;如果服务器多或磁盘少,服务器 CPU 压力不大,数据可以做压缩处理,可以节省一半磁盘;上面这些临时方案,确实可以解决我们一时的燃眉之急。不过在节约成本的时候,建议不要牺牲业务服务,尤其是核心业务。接下来,我们就来讨论一种特殊情况。如果业务高峰期的流量激增,远超过 30W QPS,就有更多流量瞬间请求尖峰,或者出现大量故障的情况。这时甚至没有报错服务的日志中心也会被影响,开始出现异常。高峰期日志会延迟半小时,甚至是一天,最终后果就是系统报警不及时,即便排查问题,也查不到实时故障情况,这会严重影响日志中心的运转。出现上述情况,是因为日志中心普遍采用共享的多租户方式,隔离性很差。这时候个别系统的日志会疯狂报错,占用所有日志中心的资源。为了规避这种风险,一些核心服务通常会独立使用一套日志服务,和周边业务分离开,保证对核心服务的及时监控。
高并发写的存储冷热分离
为了节省成本,我们还可以从硬件角度下功夫。如果我们的服务周期存在高峰,平时流量并不大,采购太多服务器有些浪费,这时用一些高性能的硬件去扛住高峰期压力,这样更节约成本。举例来说,单个磁盘的写性能差不多是 200MB/S,做了 Raid5 后,单盘性能会折半,这样的话写性能就是 100MB/S x 一台服务器可用 9 块硬盘 =900MB/S 的写性能。如果是实时写多读少的日志中心系统,这个磁盘吞吐量勉强够用。不过。要想让我们的日志中心能够扛住极端的高峰流量压力,常常还需要多做几步。所以这里我们继续推演,如果实时写流量激增,超过我们的预估,如何快速应对这种情况呢?一般来说,应对这种情况我们可以做冷热分离,当写需求激增时,大量的写用 SSD 扛,冷数据存储用普通硬盘。如果一天有 8 TB 新日志,一个副本 4 台服务器,那么每台服务器至少要承担 2 TB/ 天 存储。一个 1TB 实际容量为 960G、M.2 口的 SSD 硬盘单价是 1800 元,顺序写性能大概能达到 3~5GB/s(大致数据)。每台服务器需要买两块 SSD 硬盘,总计 24个 1 TB SSD (另外需要配适配卡,这里先不算这个成本了)。算下来初期购买 SSD 的投入是 43200 元,计算过程如下:1800 元 X 12 台服务器 X 2 块 SSD = 43200 元同样地,SSD 也需要定期更换,寿命三年左右,每年维护费是 1800 X 8 = 14400 元这里我额外补充一个知识,SSD 除了可以提升写性能,还可以提升读性能,一些分布式检索系统可以提供自动冷热迁移功能。
需要多少网卡更合算
通过加 SSD 和冷热数据分离,就能延缓业务高峰日志的写压力。不过当我们的服务器磁盘扛住了流量的时候,还有一个瓶颈会慢慢浮现,那就是网络。一般来说,我们的内网速度并不会太差,但是有的小的自建机房内网带宽是万兆的交换机,服务器只能使用千兆的网卡。理论上,千兆网卡传输文件速度是 1000mbps/8bit= 125MB/s,换算单位为 8 mbps = 1MB/s。不过,实际上无法达到理论速度,千兆的网卡实际测试传输速度大概是 100MB/s 左右,所以当我们做一些比较大的数据文件内网拷贝时,网络带宽往往会被跑满。更早的时候,为了提高网络吞吐,会采用诸如多网卡接入交换机后,服务器做 bond 的方式提高网络吞吐。后来光纤网卡普及后,现在普遍会使用万兆光接口网卡,这样传输性能更高能达到 1250MB/s(10000mbps/8bit = 1250MB/s),同样实际速度无法达到理论值,实际能跑到 900MB/s 左右,即 7200 mbps。再回头来看,之前提到的高峰期日志的数据吞吐量是多少呢?是这样计算的:30W QPS * 1KB = 292.96MB/s刚才说了,千兆网卡速度是 100MB/s,这样四台服务器分摊勉强够用。但如果出现多倍的流量高峰还是不够用,所以还是要升级下网络设备,也就是换万兆网卡。不过万兆网卡要搭配更好的三层交换机使用,才能发挥性能,最近几年已经普及这种交换机了,也就是基础建设里就包含了交换机的成本,所以这里不再专门计算它的投入成本。先前计算硬件成本时,我们说过每组服务器要存三个副本,这样算起来有三块万兆光口网卡就足够了。但是为了稳定,我们不会让网卡跑满来对外服务,最佳的传输速度大概保持在 300~500 MB/s 就可以了,其他剩余带宽留给其他服务或应急使用。这里推荐一个限制网络流量的配置——QoS,你有兴趣可以课后了解下。12 台服务器分 3 组副本(每个副本存一份全量数据),每组 4 台服务器,每台服务器配置 1 块万兆网卡,那么每台服务器平时的网络吞吐流量就是:292.96MB/s (高峰期日志的数据吞吐量) / 4 台服务器 = 73MB/S可以说用万兆卡只需十分之一,即可满足日常的日志传输需求,如果是千兆网卡则不够。看到这你可能有疑问,千兆网卡速度不是 100MB/s,刚才计算吞吐流量是 73MB/s,为什么说不够呢?这是因为我们估算容量必须留有弹性,如果用千兆网卡,其实是接近跑满的状态,一旦稍微有点波动就会卡顿,严重影响到系统的稳定性。另一方面,实际使用的时候,日志中心不光是满足基础的业务使用,承担排查问题的功能,还要用来做数据挖掘分析,否则投入这么大的成本建设日志中心,就有些得不偿失了。我们通常会利用日志中心的闲置资源,用做限速的大数据挖掘。联系这一点,相信你也就明白了,我们为什么要把日志保存三份。其实目的就是通过多个副本来提高并发计算能力。不过,这节课我们的重点是演示如何计算成本,所以这里就点到为止了,有兴趣的话,你可以课后自行探索。
总结
这节课我们主要讨论了如何通过请求用户量评估出日志量,从而推导计算出需要多少服务器和费用。
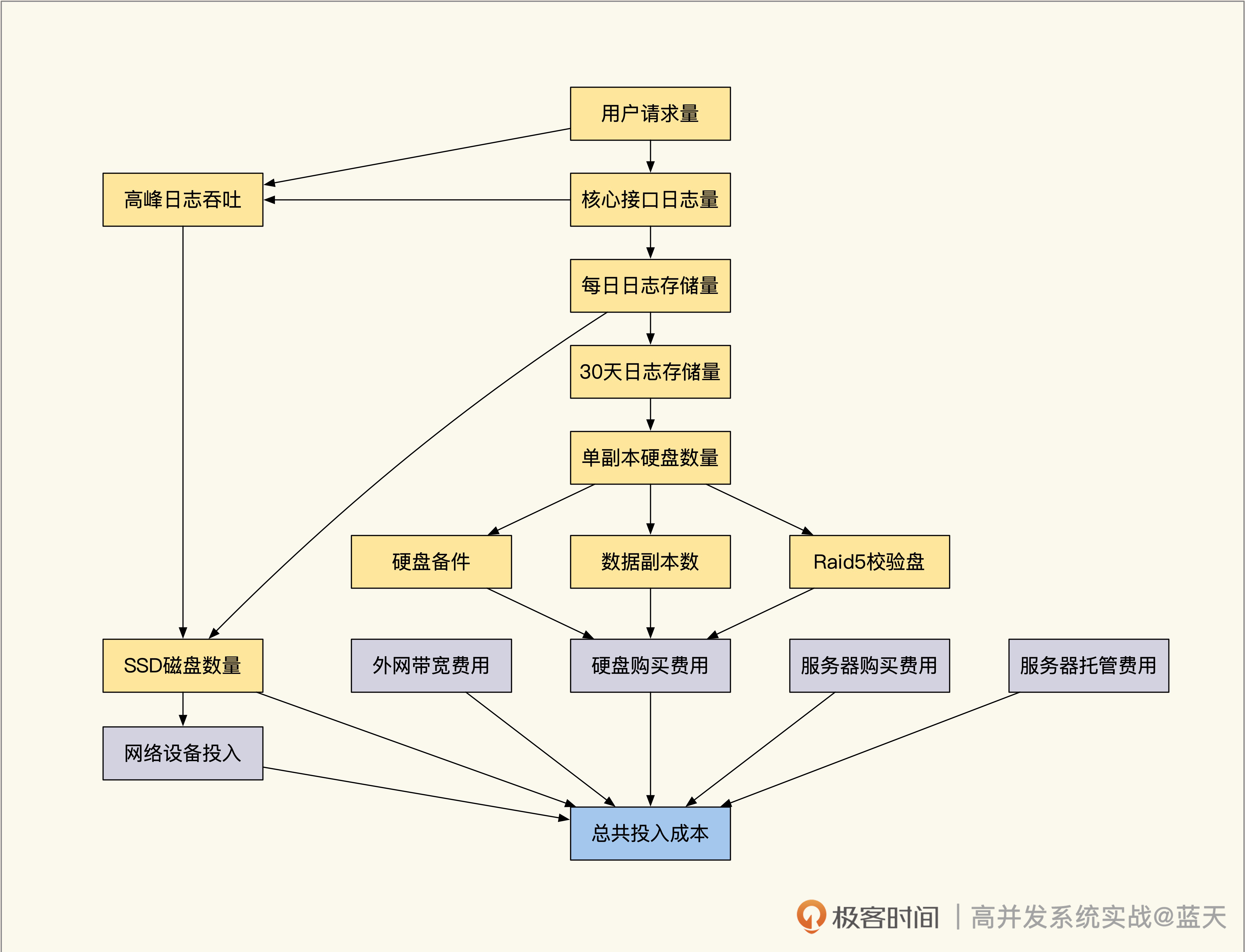
推导过程
你可以先自己思考一下,正文里的计算过程还有什么不足。其实,这个计算只是满足了业务现有的流量。现实中做估算会更加严谨,综合更多因素,比如我们在拿到当前流量的计算结果后,还要考虑后续的增长。这是因为机房的空间有限,如果我们不能提前半年规划出服务器资源情况,之后一旦用户流量增长了,却没有硬件资源,就只能“望洋兴叹”,转而用软件优化方式去硬扛突发 de 情况。当然了,根据流量计算硬盘和服务器的投入, 只是成本推算的一种思路。如果是大数据挖掘,我们还需要考虑 CPU、内存、网络的投入以及系统隔离的成本。不同类型的系统,我们的投入侧重点也是不一样的。比如读多写少的服务要重点“堆“内存和网络;强一致服务更关注系统隔离和拆分;写多读少的系统更加注重存储性能优化;读多写多的系统更加关注系统的调度和系统类型的转变。尽管技术决策要考虑的因素非常多,我们面临的业务和团队情况也各有不同。但通过这节课,我希望能让你掌握成本推算的思维,尝试结合计算来指导我们的计算决策。当你建议团队自建机房,或者建议选择云服务的时候,如果有一套这样的计算做辅助,相信方案通过的概率也会有所提升。
网关编程:如何通过用户网关和缓存降低研发成本?
如果说用户的流量就像波涛汹涌的海浪,那网关就是防御冲击的堤坝。在大型的互联网项目里,网关必不可少,是我们目前最好用的防御手段。通过网关,我们能把大量的流量分流到各个服务上,如果配合使用 Lua 脚本引擎提供的一些能力,还能大大降低系统的耦合度和性能损耗,节约我们的成本。一般来说,网关分为外网网关和内网网关。外网网关主要负责做限流、入侵预防、请求转发等工作,常见方式是使用 Nginx + Lua 做类似的工作;而最近几年,内网网关发展出现了各种定制功能的网关,比如 ServiceMesh、SideCar 等方式,以及类似 Kong、Nginx Unit 等,它们的用途虽然有差异,但是主要功能还是做负载均衡、流量管理调度和入侵预防这些工作。那么网关到底提供了哪些至关重要的功能支持呢?这节课我们就来分析分析。
外网网关功能
我们先从外网网关的用法说起,我会给你分享两类外网网关的实用设计,两个设计可以帮助我们预防入侵和接触业务的依赖。
蜘蛛嗅探识别
流量大一些的网站都有过网站被攻击、被蜘蛛抓取,甚至被黑客入侵的经历。有了网关,我们就能实现限速和入侵检测功能,预防一些常见的入侵。这里我主要想和你分享一下,非法引用和机器人抓取这两类最常见、也最严重的问题要如何应对。一般来说,常见的非法使用,会大量引用我们的网络资源。对此,可以用检测请求 refer 方式来预防,如果 refer 不是本站域名就拒绝用户请求,这种方式可以降低我们的资源被非法使用的风险。另一类问题就是机器人抓取。识别机器人抓取我们需要一些小技巧。首先是划定范围,一般这类用户有两种:一种是匿名的用户请求,我们需要根据 IP 记录统计请求排行时间块,分析请求热点 IP,请求频率过高的 IP 会被筛选关注;另外一种是登录用户,这种我们用时间块统计记录单个用户的请求次数及频率,超过一定程度就拒绝请求,同时将用户列入怀疑名单,方便后续进一步确认。想要确认怀疑名单中用户的行为。具体怎么实现呢?这里我给你分享一个误判概率比较低的技巧。我们可以在被怀疑用户请求时,通过网关对特定用户或 IP 动态注入 JS 嗅探代码,这个代码会在 Cookie 及 LocalStorage 内写入特殊密文。我们的前端 JS 代码检测到密文后,就会进入反机器人模式。反机器人模式可以识别客户端是否有鼠标移动及点击动作,以此判断用户是否为机器人。确认用户没问题以后,才会对服务端发送再次签名的密文请求解锁。如果客户端一直没有回馈,就自动将怀疑用户列为准备封禁的用户,并封禁该请求,当一个 IP 被封禁的请求达到一定程度就会进行封禁。不过这种设计有一个缺点——对 SEO 很不友好,各大搜索引擎的机器人都会被拒绝。我们之前的做法是用白名单方式避免机器人被阻拦,具体会根据机器人的 UserAgent 放行各大引擎的机器人,并定期人工审核确认搜索引擎机器人的 IP。除此之外,对于一些核心重要的接口,我们可以增加“必须增加带时间的签名,方可请求,否则拒绝服务”这样的规则,来避免一些机器人抓取。
网关鉴权与用户中心解耦
刚才我分享了如何利用网关来阻挡一些非法用户骚扰的技巧,其实网关除了防御攻击、避免资源被恶意消耗的作用外,还能帮我们解除一些业务依赖。还记得我们第三节课提到的用户登陆设计么?每个业务可以不依赖用户中心来验证用户合法性,用户鉴权普遍会通过每个子业务集成用户中心的 SDK 来实现校验逻辑统一。不过这也牵扯到一个问题,那就是 SDK 同步依赖升级问题。基础公共组件通常会提供 SDK,这样做业务开发更加方便,而仅仅通过 API 提供服务的话,有一些特殊的操作就需要重复实现,但是这个 SDK 一旦放出,我们后续就要做好同时维护多个版本 SDK 在线工作的心理准备。下图是第三节课用 SDK 鉴权 token 方式,以及通过用户中心接口鉴权的效果:
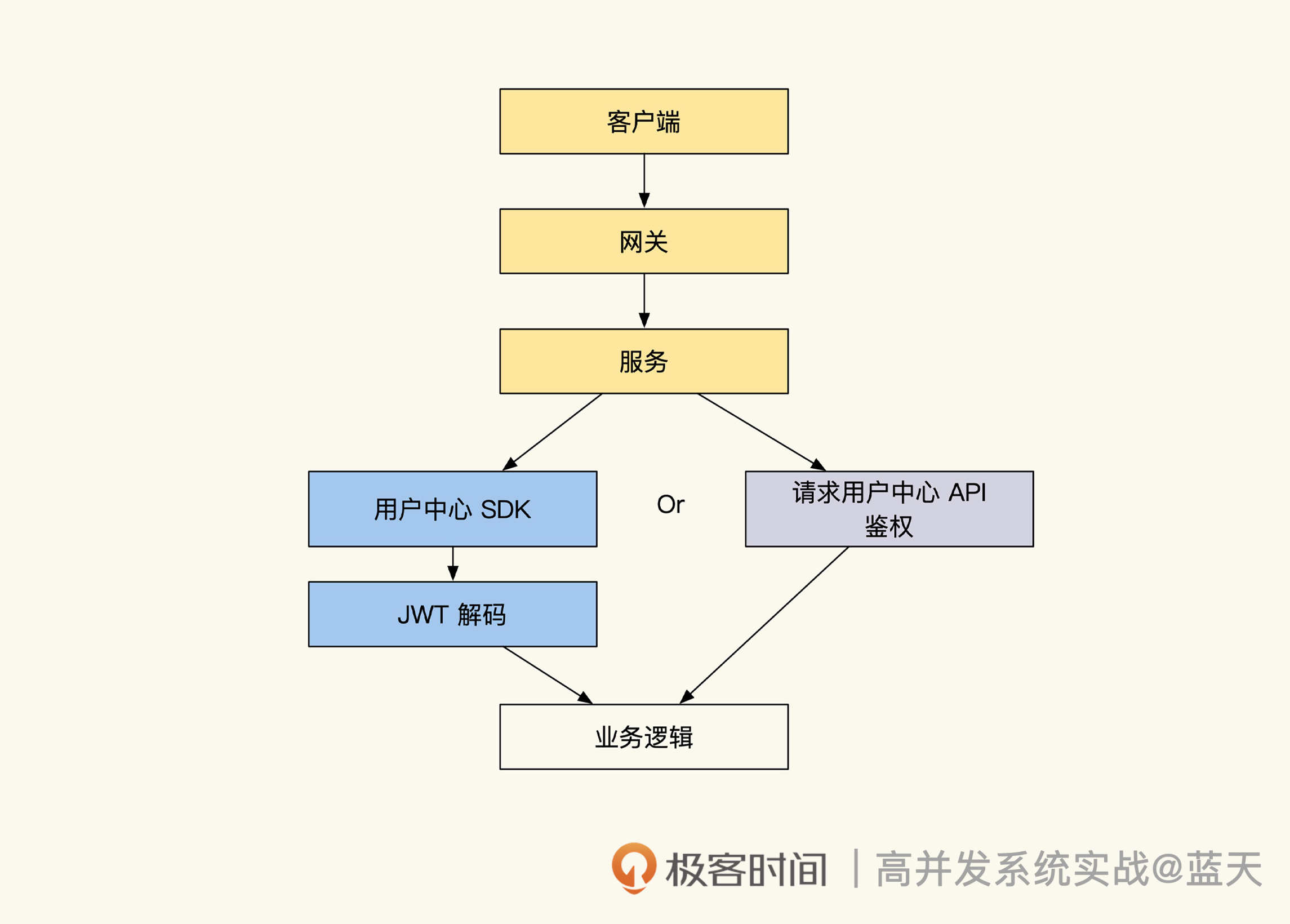 请求用户中心 API 鉴权方式和 SDK 实现自解方式对比
请求用户中心 API 鉴权方式和 SDK 实现自解方式对比
如上图,集成 SDK 可以让业务自行校验用户身份而无需请求用户中心,但是 SDK 会有多个版本,后续用户中心升级会碰到很大阻力,因为要兼顾我们所有的“用户”业务。SDK 属于植入对方项目内的组件,为了确保稳定性,很多项目不会频繁升级修改组件的版本,这导致了用户中心很难升级。每一次基础服务的大升级,都需要大量的人力配合同步更新服务的 SDK,加大了项目的维护难度。那么除了使用 SDK 以外,还有什么方式能够避免这种组件的耦合呢?这里我分享一种有趣的设计,那就是把用户登陆鉴权的功能放在网关。我用画图的方式描述了请求过程,你可以对照示意图听我继续分析。
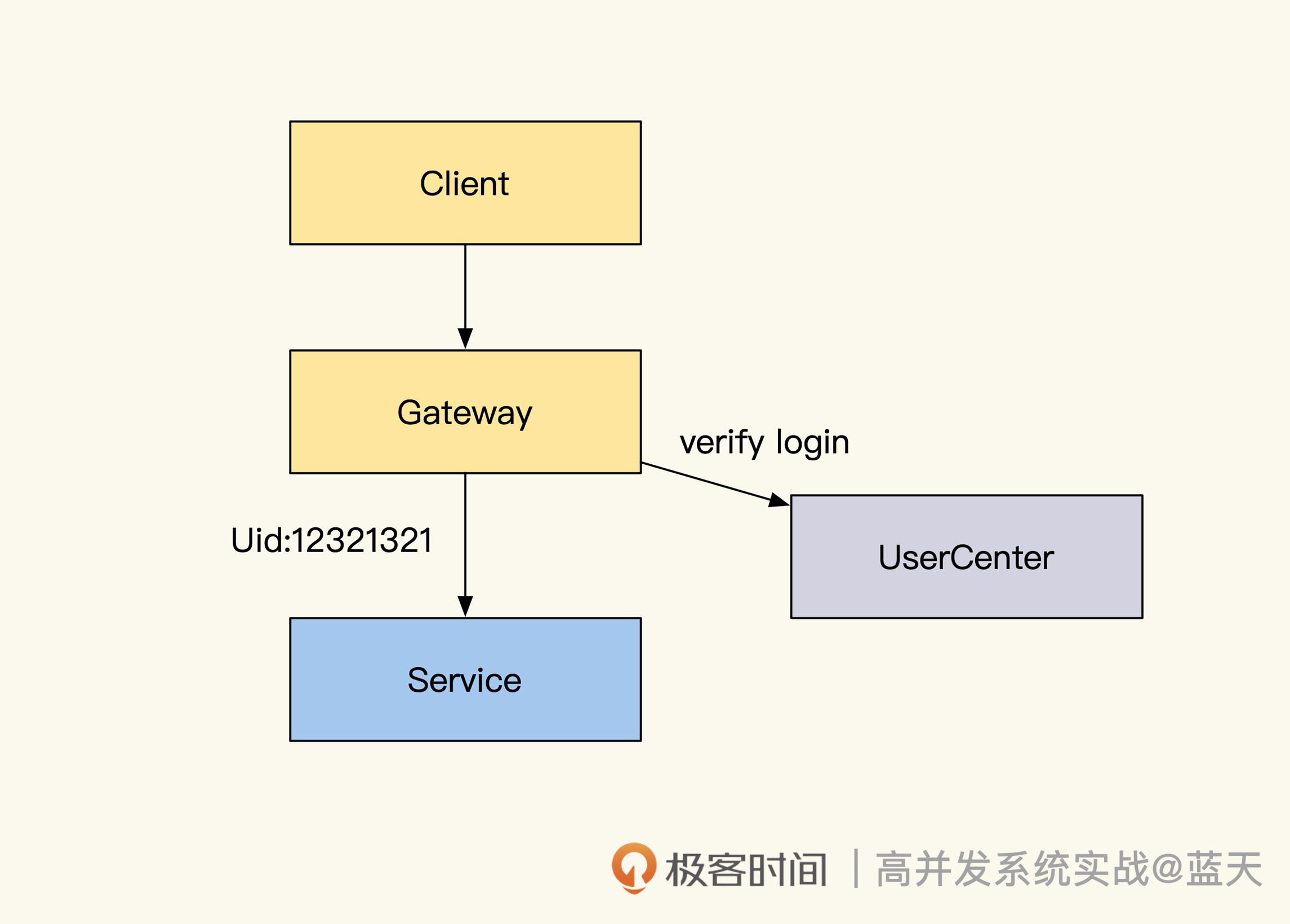
用户网关
结合上图,我们来看看这个实现的工作流程。用户业务请求发到业务接口时,首先会由网关来鉴定请求用户的身份。如果鉴定通过,用户的信息就会通过 header 传递给后面的服务,而业务的 API 无需关注用户中心的实现细节,只需接收 header 中附带的用户信息即可直接工作。如果业务上还要求用户必须登录才能使用,我们可以在业务中增加一个对请求 header 是否有 uid 的判断。如果没有 uid,则给前端返回统一的错误码,提醒用户需要先登陆。不难看出,这种鉴权服务的设计,解耦了业务和用户中心这两个模块。用户中心如果有逻辑变更,也不需要业务配合升级。除了常见的登陆鉴权外,我们可以对一些域名开启 RBAC 服务,根据不同业务的需要定制不同的 RBAC、ABAC 服务,并且通过网关对不同的用户开启不同的权限以及灰度测试等功能。
内网网关服务
了解了外网的两种妙用,我们再看看内网的功能。它可以提供失败重试服务和平滑重启机制,我们分别来看看。
失败重试
当我们的项目发布升级期间需要重启,或者发生崩溃的故障,服务会短暂不可用。这时如果有用户发出服务请求,会因为后端没有响应返回 504 错误,这样用户体验很不好。面对这种情况,我们可以利用内网网关的自动重试功能,这样在请求发到后端,并且服务返回 500、403 或 504 错误时,网关不会马上返回错误,而是让请求等待一会儿后,再次重试,或者直接返回上次的缓存内容。这样就能实现业务热更新的平滑升级,让服务看起来更稳定,用户也不会对线上升级产生明显感知。
平滑重启
接下来,我再说说平滑重启的机制。在我们的服务升级时,可以不让服务进程收到 kill 信号后直接退出,而是制作平滑重启功能,即先让服务停止接收新的请求,等待之前的请求处理完成,如果等待超过 10 秒则直接退出。
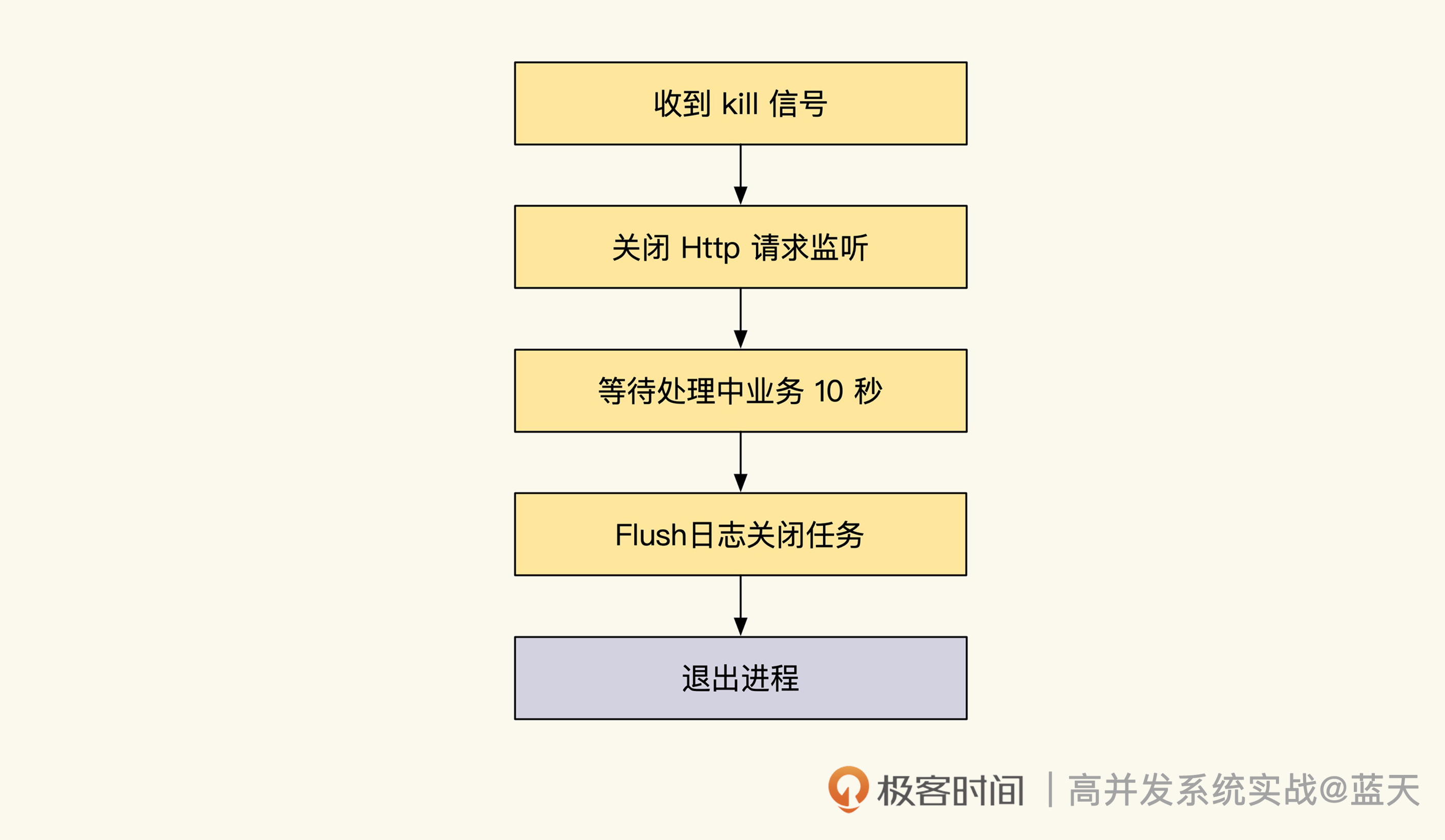
服务平滑重启
通过这个机制,用户请求处理就不会被中断,这样就能保证正在处理中的业务事务是完整的,否则很有可能会导致业务事务不一致,或只做了一半的情况。有了这个重试和平滑重启的机制后,我们可以随时在线升级发布我们的代码,发布新的功能。不过开启这个功能后,可能会屏蔽一些线上的故障,这时候可以配合网关服务的监控,来帮我们检测系统的状态。
内外网关综合应用
服务接口缓存
首先来看网关接口缓存功能,也就是利用网关实现一些接口返回内容的缓存,适合用在服务降级场景,用它短暂地缓解用户流量的冲击,或者用于降低内网流量的冲击。具体实现如下图所示:
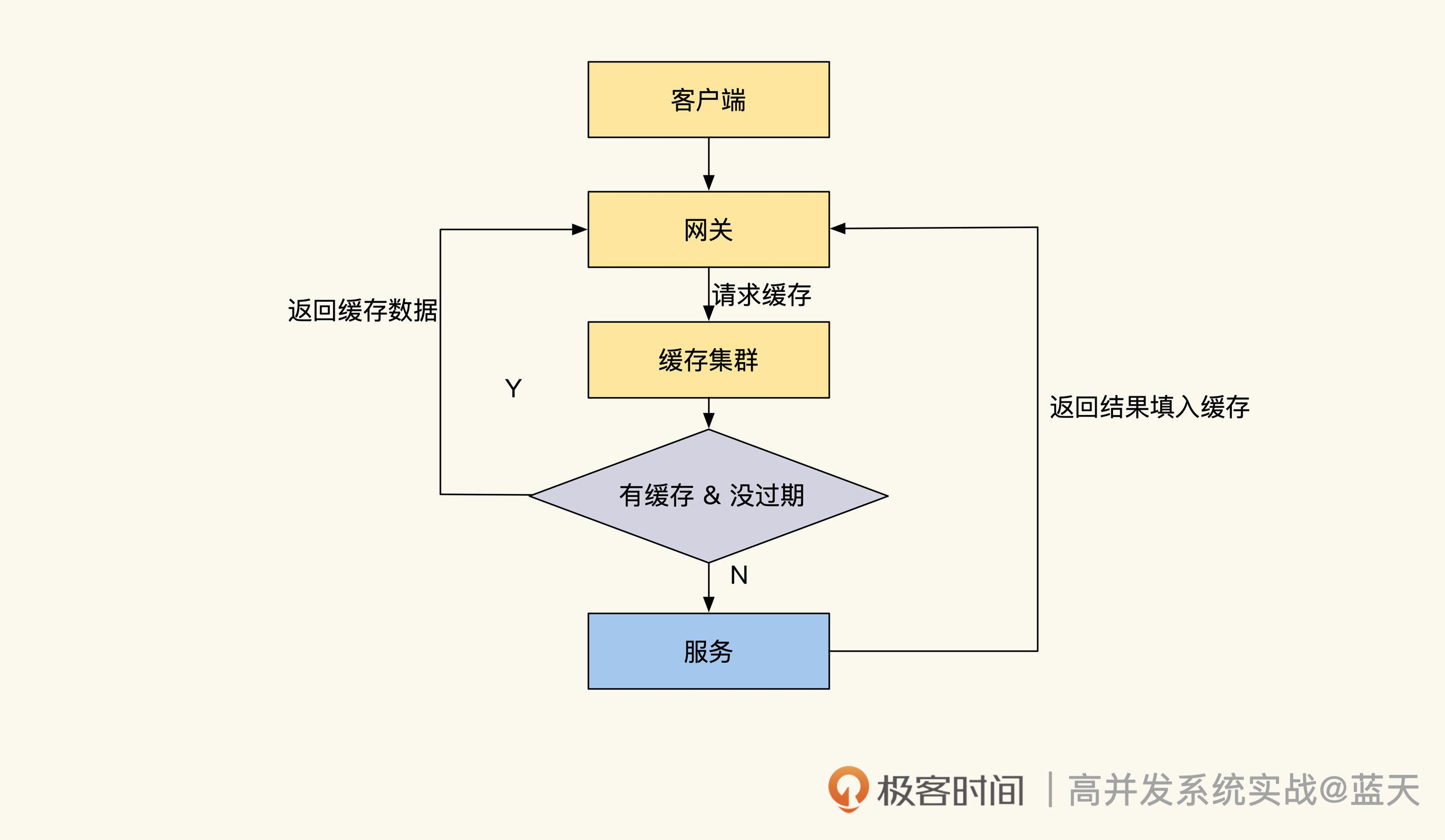
网关数据缓存
结合上图,我们可以看到,网关实现的缓存基本都是用临时缓存 + TTL 方式实现的。当用户请求服务端时,被缓存的 API 如果之前已经被请求过,并且缓存还没有过期的话,就会直接返回缓存内容给客户端。这个方式能大大降低后端的数据服务压力。不过每一种技术选择,都是反复权衡的结果,这个方式是牺牲了数据的强一致性才实现的。另外,这个方式对缓存能力的性能要求比较高,必须保证网关缓存可以扛得住外网流量的 QPS。如果想预防穿透流量过多,也可以通过脚本定期刷新缓存数据,网关查到相关缓存就直接返回,如果没有命中,才会将真正请求到服务器后端服务上并缓存结果。这样实现的方式更加灵活,数据的一致性会更好,只是实现起来需要人力去写好维护代码。
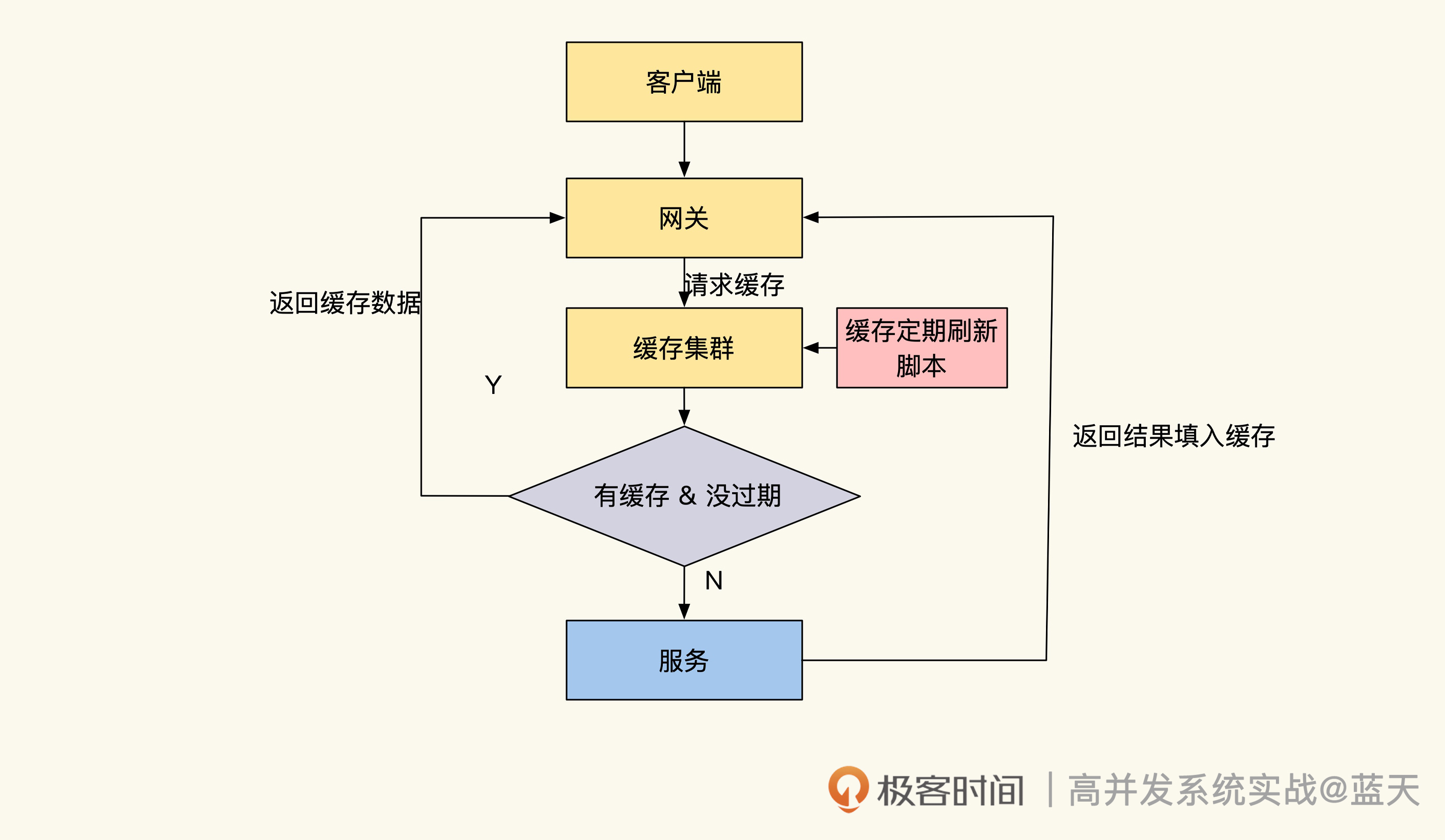
通过脚本主动刷新缓存
当然这种缓存的数据长度建议不超过 5KB(10w QPS X 5KB = 488MB/s),因为数据太长,会拖慢我们的缓存服务响应速度。
服务监控
最后我们再说说利用网关做服务监控的问题。我们先思考这样一个问题,在没有链路跟踪之前,通常会怎么做监控呢?事实上,大部分系统都是通过网关的日志做监控的。我们可以通过网关访问日志中的 Http Code 来判断业务是否正常。配合不同请求的耗时信息,就能完成简单的系统监控功能。为了帮助你进一步理解,下面这张图画的是如何通过网关监控服务,你可以对照图片继续听我分析。
通过网关日志监控服务状态及告警
为了方便判断线上情况,我们需要先统计信息。具体方法就是周期性地聚合访问日志中的错误,将其汇总起来,通过聚合汇总不同接口的请求的错误个数,格式类似“30 秒内出现 500 错误 20 个,504 报错 15 个,某域名接口响应速度大于 1 秒的情况有 40 次”来分析服务状态。和其他监控不同,网关监控的方式可以监控到所有业务,只是粒度会大一些,不失为一个好方法。如果我们结合 Trace,还可以将访问日志中落地 Traceid,这样就能根据 Traceid 进一步排查问题原因,操作更方便,在好未来、极客时间都有类似的实现。
总结
这节课我给你分享了网关的很多巧妙用法,包括利用网关预防入侵、解除业务依赖、辅助系统平滑升级、提升用户体验、缓解流量冲击以及实现粒度稍大一些的服务监控。我画了一张导图帮你总结要点,如下所示:
相信学到这里,你已经体会到了网关的重要性。没错,在我们的系统里,网关有着举足轻重的地位,现在的技术趋势也证明了这一点。随着发展,网关开始区分内网网关和外网网关,它们的功能和发展方向也开始出现差异化。这里我想重点再聊聊内网网关的发展。最近几年,微服务、Sidecar 技术逐渐流行,和内网网关一样,它们解决的都是内网流量调度和高可用问题。当然了,传统的内网网关也在更新换代,出现了很多优秀的开源项目,比如 Kong、Apisix、OpenResty,这些网关可以支持 Http2.0 长链接双工通讯和 RPC 协议。业界对于到底选择 Sidecar Agent 还是用内网网关,一直处于激烈讨论的阶段。而在我看来,随着容器化的流行,内网网关会迎来新的变革。服务发现、服务鉴权、流量调度、数据缓存、服务高可用、服务监控这些服务,最终会统一成一套标准。如果现有的内网网关能降低复杂度,未来会更胜一筹。
性能压测:压测不完善,效果减一半
高并发的系统很复杂,所以对这样的系统做并发优化也相当有挑战。很多服务的局部优化,不见得能真正优化整体系统的服务效果,甚至有的尝试还会适得其反,让服务变得不稳定。在这种情况下,压测就显得更加重要了。通常来说,通过压测可以帮我们做很多事儿,比如确认单个接口、单台服务器、单组服务集群甚至是整个机房整体的性能,方便我们判断服务系统的瓶颈在哪里。而且根据压测得出的结果,也能让我们更清晰地了解系统能够承受多少用户同时访问,为限流设置提供决策依据。这节课,我们就专门聊聊性能压测里,需要考虑哪些关键因素。
压测与架构息息相关
在压测方面,我们很容易踩的一个坑就是盲目相信 QPS 结果,误以为“接口并发高就等同于系统稳定”,但却忽视了系统业务架构的形态。所以在讲压测之前,我们需要先了解一些关于性能与业务架构的相关知识,这能让我们在压测中更清醒。
并行优化
前面我说过,不能盲目相信 QPS 结果,优化的时候要综合分析。为了让你理解这一点,我们结合一个例子来看看。我们常见的业务会请求多个依赖的服务处理数据,这些都是串行阻塞等待的。当一个服务请求过多其他服务时,接口的响应速度和 QPS 就会变得很差。这个过程,你可以结合后面的示意图看一下:
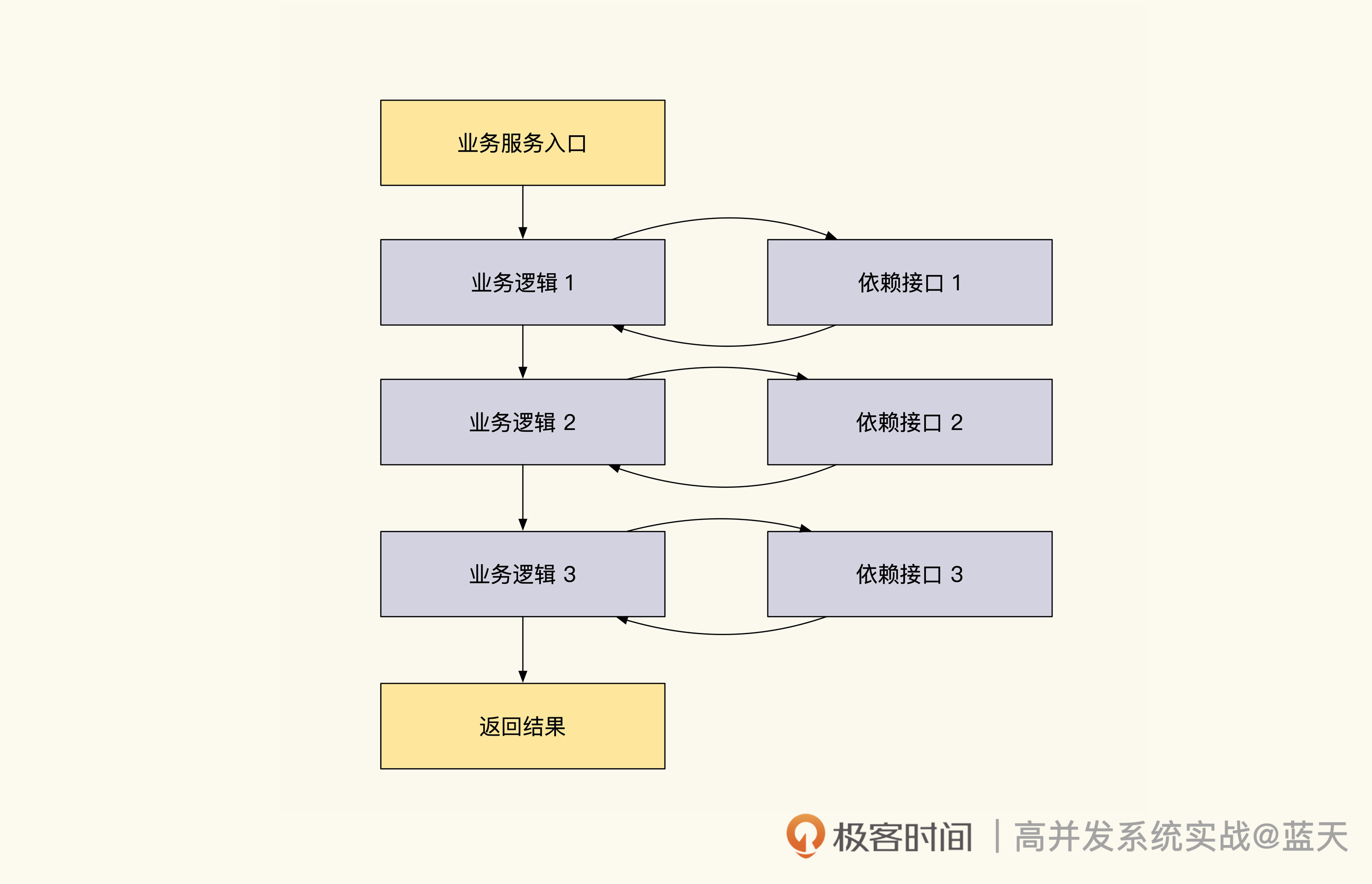
为了提高性能,有些业务对依赖资源做了优化,通过并行请求依赖资源的方式提高接口响应速度。具体的实现请看下图:
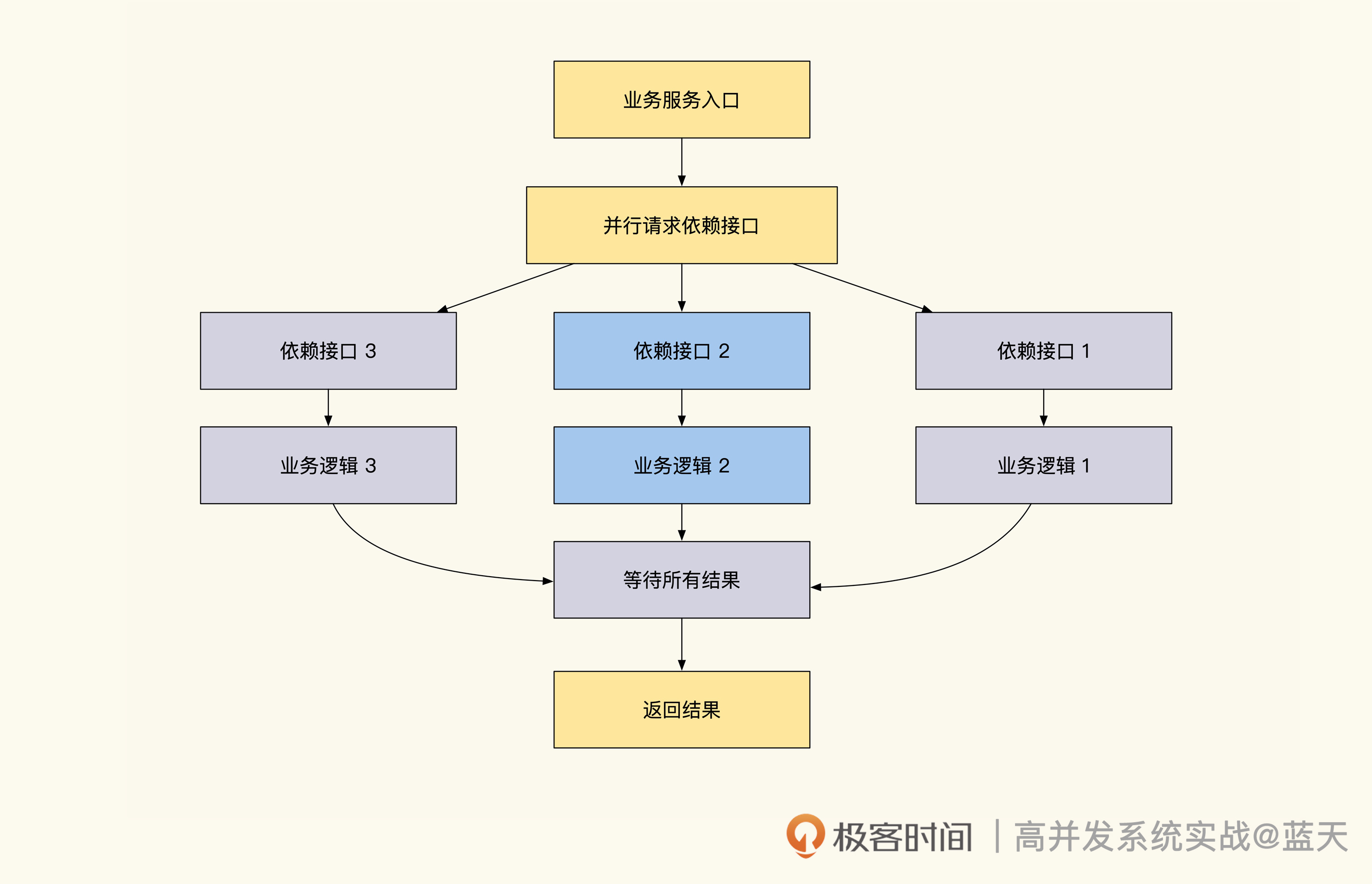
并行请求依赖资源
如上图,业务请求依赖接口的时候不再是串行阻塞等待处理,而是并行发起请求获取所有结果以后,并行处理业务逻辑,最终合并结果返回给客户端。这个设计会大大提高接口的响应速度,特别是依赖多个资源的服务。但是,这样优化的话有一个副作用,这会加大内网依赖服务的压力,导致内网的服务收到更多的瞬时并发请求。如果我们大规模使用这个技巧,流量大的时候会导致内网请求放大,比如外网是 1WQPS,而内网流量放大后可能会有 10W QPS,而内网压力过大,就会导致网站整体服务不稳定。所以,并行请求依赖技巧并不是万能的,我们需要注意依赖服务的承受能力,这个技巧更适合用在读多写少的系统里。对于很多复杂的内网服务,特别是事务一致性的服务,如果并发很高,这类服务反而会因为锁争抢超时,无法正常响应。那问题来了,像刚才例子里这种依赖较多的业务系统,什么样的压测思路才更合理呢?我的建议是先做内网服务的压测,确认了内网可以稳定服务的 QPS 上限之后,我们再借此反推外网的 QPS 应该限制在多少。
临时缓存服务
临时缓存优化也是压测里需要特殊应对的一种情况,其实我们早在第二节课就提到过。临时缓存通常会这样实现,示意图如下所示:
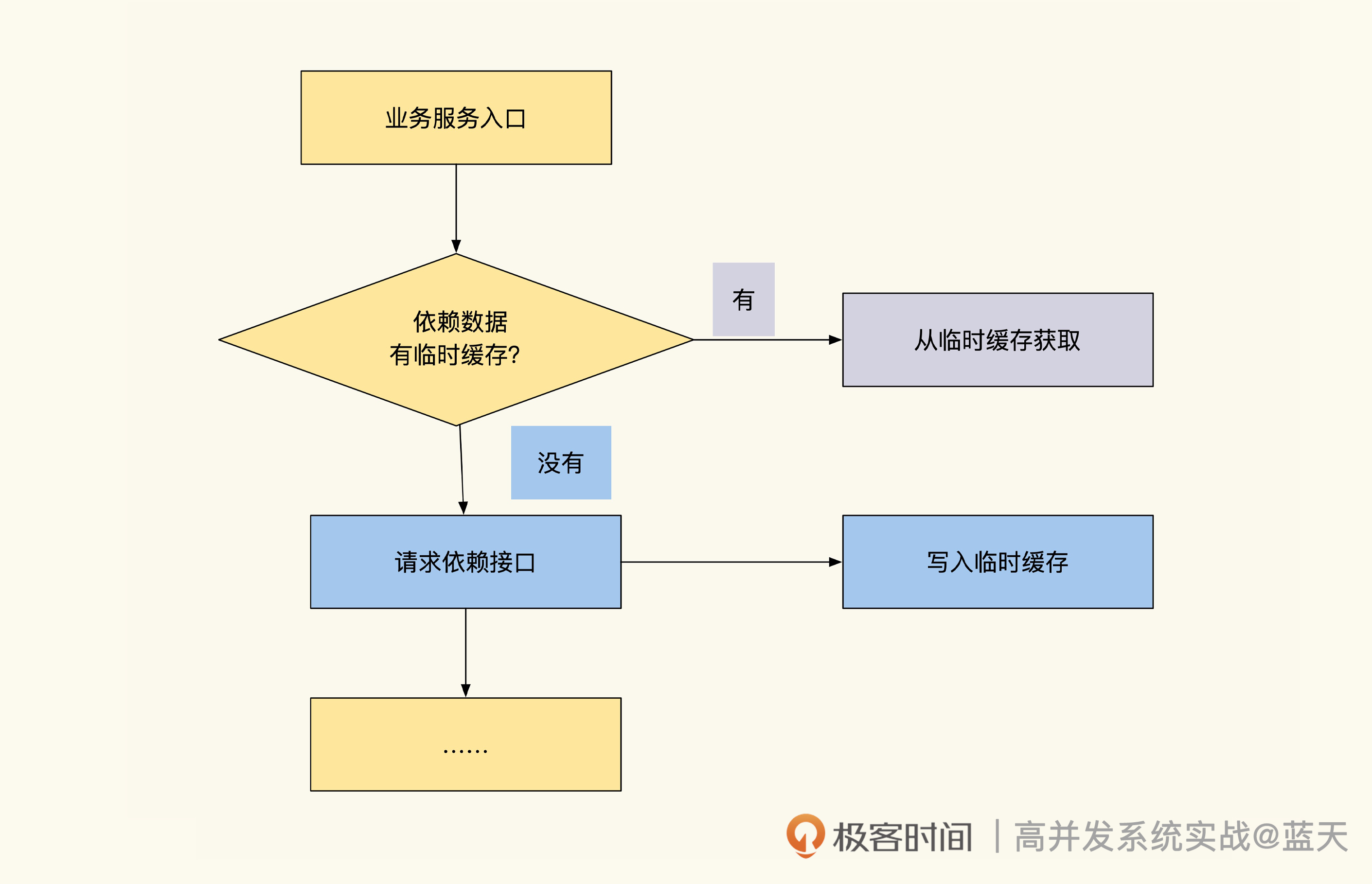
请求依赖接口如果有缓存,则直接走缓存
结合上图,我们可以看到,接口请求依赖数据时会优先请求缓存,如果拿到缓存,那么就直接从缓存中获取数据,如果没有缓存直接从数据源获取,这样可以加快我们服务的响应速度。在通过临时缓存优化的服务做压测的时候,你会看到同参数的请求响应很快,甚至 QPS 也很高,但这不等同于服务的真实性能情况,系统不稳定的隐患仍然存在。为什么这么说呢?这是因为临时缓存的优化,针对的是会被频繁重复访问的接口,优化之后,接口的第一次请求还是很缓慢。如果某类服务原有接口依赖响应很慢,而且同参数的请求并不频繁,那这类服务的缓存就是形同虚设的。所以这种结构不适合用在低频率访问的业务场景,压测时我们也要注意这种接口平时在线上的表现。
分片架构
接下来,我们再看看数据分片架构。下图是通过分片缓解压力的架构(我们在第 18 节课的时候提到过):
数据分片架构的服务,会根据一些标识 id 作为分片依据,期望将请求均衡地转发到对应分片,但是实际应用时,情况不一定和预期一致。我结合一个曾经踩过的坑和你分享经验。在线培训的业务里,当时选择了班级 ID 作为分片标识,10W 人在线互动时,实际却只有一个分片对外服务,所有用户都请求到了一个分片上,其他分片没有太多流量。出现这种情况主要是两个原因:第一,我们的班级 id 很少,这是一个很小的数据范围,所以 hash 的时候如果算法不够分散,就会把数据放到同一个分片上;第二,因为 hash 算法有很多种,不同算法计算出的结果,分散程度也不同,因此有些特征的数据计算结果不会太分散,需要我们验证选择。为了预防类似的问题,建议你压测时,多拿实际的线上数据做验证,如果总有单个热点分片就需要考虑更换 hash 算法。做好这个测试后,别忘了配合随机数据再压测一次,直到找到最适合业务情况的算法(hash 算法变更牵连甚广,所以选择和更换时一定要慎重)。
数据量
除了架构情况以外,数据量也是影响压测效果的重要因素。如果接口通过多条数据来进行计算服务,就需要考虑到数据量是否会影响到接口的 QPS 和稳定性。如果数据量对接口性能有直接影响,压测时就要针对不同数据量分别做验证。因为不完善的测试样例,会给大流量服务留下雪崩的隐患,为了尽可能保证测试真实,这类接口在压测时,要尽量采用一些脱敏后的线上真实数据来操作。这里特别提醒一下,对于需要实时汇总大量数据的统计服务,要慎重对外提供服务。如果服务涉及的数据量过多,建议转换实现的思路,用预计算方式去实现。如果我们的核心业务接口不得不提供数据统计的服务,建议更改方式或增加缓存,预防核心服务崩溃。
压测环境注意事项
了解到性能和架构的关系知识后,相信你已经有了很多清晰的想法,是不是觉得已经可以顺利上机做压测了?但现实并非这么简单,我们还得考虑压测环境和真实环境的差异。在压测之前,要想让自己的压测结果更准确,最好减少影响的因素。在压测前的数据准备环节,我们通常要考虑的因素包括这些方面:压测环境前后要一致:尽量用同一套服务器及配置环境验证优化效果。避免缓存干扰:建议在每次压测时,缓一段时间让服务和缓存过期后再进行压测,这样才能验证测试的准确性。数据状态一致:要尽量保证服务用的数据量、压测用户量以及缓存的状态是一致的。接下来,我们再看看搭建压测环境时还有哪些注意事项。我发现很多朋友会在本地开发电脑上做压测验证,但这样很多情况是测试不出来的,建议多准备几个发起压测请求的服务器,再弄几个业务服务器接收压测请求,这样压测才更接近真实业务的运转效果。另外,Linux 环境配置我们也不能忽视。Linux 内核优化配置选项里,比较常用的包括:本地可用端口个数限制、文件句柄限制、长链接超时时间、网卡软中断负载均衡、各种 IO 缓存大小等。这些选项都会影响我们的服务器性能,建议在正式压测之前优化一遍,在这里提及这个是因为我之前碰到过类似问题。某次压测的时候,我们发现,业务不管怎么压测都无法超过 1W QPS,为此我们写了一个不执行任何逻辑的代码,直接返回文本的接口,然后对这个接口进行基准测试压测,发现性能还是达不到 1W QPS,最后把 Linux 配置全部升级改进后,才解决了这个问题。
线上压测及影子库
虽然线上压测更真实,但这样会在短时间内会产生大量垃圾数据,比如大量的日志、无用测试数据、伪造的业务数据,可能有大量堆积的队列,占用服务器的资源,甚至直接引起各种线上故障。压测 QPS 在 10W 以上时,压测一次制造的“数据垃圾”,相当于日常业务一个月产生的数据量,人工清理起来也非常困难。因此,为了确保测试不会影响线上正常服务,我更推荐用影子库的方式做压测。该方式会在压测的请求里带上一个特殊的 header,这样所有的数据读写请求都会转为请求压测数据库,而不是线上库。有了影子数据库,可以帮我们有效地降低业务数据被污染的风险。
全链路压测以及流量回放测试
之前讨论的压测都是单接口、单个服务的压测。但实践过程中,最常遇到的问题就是单接口压测时表现很好,但是实际生产还没到预估流量,系统就崩掉了。出现这种问题,原因在于我们的服务并不是完全独立的,往往上百个接口共享一套数据库、缓存、队列。所以,我们检测系统服务能力要综合检测。比如你优化了单接口 A,但这条流程需要调用 A、B、C 三个接口,而 B、C 接口性能较慢或对系统资源消耗很大。那么,即便单接口 A 压测状况很好,但整体的服务流程性能仍然上不去。再比如,如果一个业务占用过多的公共资源,就会影响到其他共用资源的服务性能,所以压测做完单接口性能测试后,建议做全链路压测。上面这两种情况,都可以通过全链路压测来解决,这种方式可以帮助我们将各种交叉复杂的使用情况模拟出来,帮助我们更综合地评估系统运转情况,从而找到性能瓶颈。如何模拟“交叉复杂的使用情况”呢?建议你最好可以把多个业务主要场景,设计成并行运行的流程一起跑,比如一组 vUser 在浏览搜索商品,一组 vUser 在下单支付,一组 vUser 在后台点常见功能。这种方式压测出来的性能数据,可以作为我们最忙时线上服务压力的上限,如果某个流程核心的接口压力大、响应慢的话,则会拖慢整个流程的效率,这样我们可以通过整体流程的 QPS 发现瓶颈点和隐患。如果压测一段时间服务指标都很稳定,我们可以加大单个流程压测线程数,尝试压垮系统,以此观察系统可能出现的缺陷以及预警系统是否及时预警。不过这样做,需要做好修复数据库的准备。如果业务比较复杂,人工写压测脚本比较困难,还有一个方式,就是回放线上真实用户请求进行压测。这种方式还可以用于一些特殊故障的请求场景还原。具体可以使用tcpcopy这个工具录制线上的流量请求,生成请求记录文件后,模拟搭建录制时线上数据时的全量数据镜像,然后回放即可。不过这个工具使用起来有一定难度,最好配合成型的压测平台工具使用。此外,我们还需要一个独立旁路服务器来压测或录制,要注意支付一类的服务不要请求到线上,否则可能会造成用户财产损失。
总结
性能压测是我们的验证我们服务改造效果、容量评估、架构合理性以及灾难演练的必备工具。通过压测,我们会更清楚服务的运转情况和承压能力,综合分析出性能瓶颈点。每次业务出现变更,或者做了优化时,都可以通过性能压测来评估优化效果。我想强调的是,压测的 QPS 并不一定能够反映我们的优化是否合理,这一点需要结合业务架构来综合评估。我们来回顾一下课程里讲过的几个典型例子:并行请求依赖服务优化成串行请求的服务,虽然能够提高接口的响应速度,但是会让内网压力更大;临时缓存服务虽然能降低内网重复查询的压力,但如果是低频率数据访问,那么优化效果就很一般;分片架构的服务压测时需要注意单片热点的问题,不然压测虽然表现良好,线上运转却可能会出问题。受参与计算的数据量影响大的接口,要尤其注意真实系统环境和极端数据量的测试。除了对并行请求、临时缓存、分片架构、数据量这几个点做验证以外,还建议做一些极端测试,对服务的稳定性进行评估。数据量较多的接口,压测时要时刻关注相关数据库压力及索引、缓存的命中率情况,预防数据库出现压力过大、响应缓慢的问题。另外,我们要在人少的时候停机做线上环境压测,但是要预防压测期间产生的垃圾数据,这里可以用影子库方式解决,不过这需要所有业务配合,需要提前做好协调确认。最后,相比单接口的压测,为了尽量模拟线上真实情况,我带你了解了两种更综合的压测方式,分别是全链路压测和流量回放测试。