基于频率增强的数据增广的视觉语言导航方法(VLN论文阅读)

摘要
视觉和语言导航(VLN)是一项具有挑战性的任务,它需要代理基于自然语言指令在复杂的环境中导航。
在视觉语言导航任务中,之前的研究主要是在空间上进行数据增广,本文的重点是在傅里叶频率方面,它旨在增强视觉文本匹配。
作者首先探索了高频信息的意义,并提供了证据表明这些高频信息对增强视觉文本匹配是有用的(instrumental)。
基于此,作者首先提出了一种Frequency-enhanced Data Augmentation (FDA)技术,提高模型捕捉关键高频信息的能力。
具体来说,这种方法要求代理在只有一个高频视觉信息对应所提供的文本指令的子集的环境中导航,最终促进了代理根据给定的指令选择性地识别和捕获相关的高频特征的能力。
方法好处:1.简单有效,2,模型架构无关,3不增加参数
1. 引言
最近的研究从空间域的角度调研了注意力机制,检测模型,细粒度的轨迹-指令对等方式以提高跨模态的匹配能力。
本文重点关注 Fourier domain来enhance visual textual matching,a research area that has received limited prior investigation。
具体来说,当在傅里叶域内进行分析时,高频和低频信息属于图像的不同组成部分。高频部分包括快速的变化,细粒度的细节,边,纹理。低频包括平滑的颜色梯度。如图一所示。

图1:高频和低频信息的示例。蓝色背景部分是经过傅里叶反变换后的空间域高频谱和高频信息。橙色的背景部分是关于这两种内容的低频信息。
我们只是简单地通过扰动图像中的低频或高频分量来研究基准方法对低频或高频信息的敏感性。
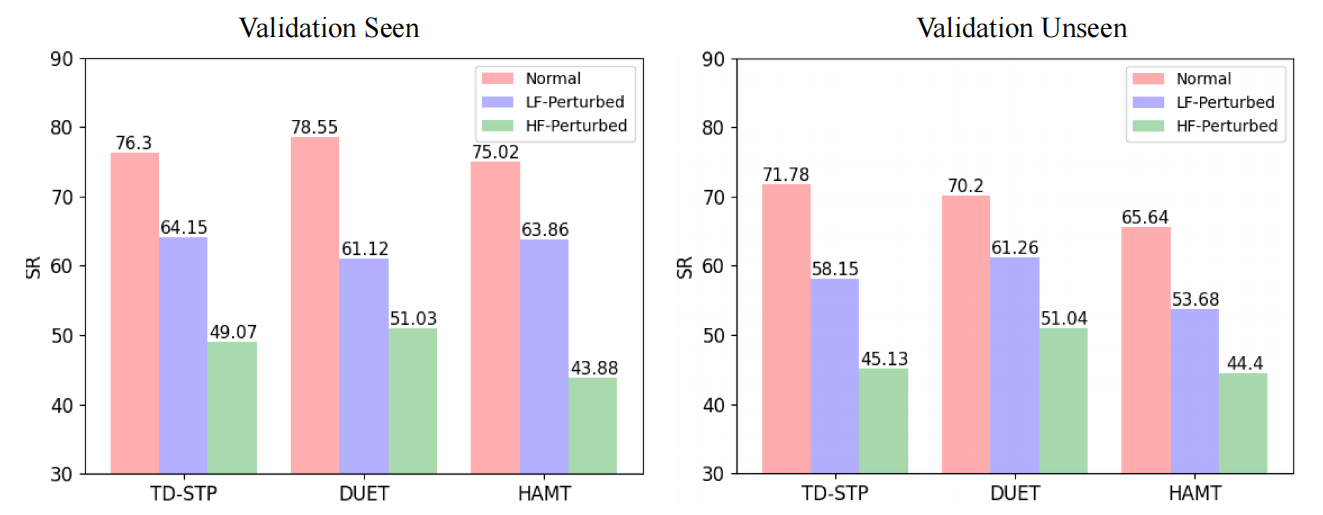
图2:基准方法对高、低频信息的敏感性分析,即HAMT [9]、DUET [10]和TD-STP [64]。正常的导航场景表示正常的导航场景。hf扰动和lf扰动分别表示高频和低频被扰动的导航场景。
如图2所示,在R2R数据集上,当基线模型(HAMT,DUET,TD-STP)低频被扰动时,仍然保持一个高的准确率,当高频被扰动时,模型成功率减低明显。这些结果表明VLN模型对高频信息更加敏感。
为了有效地利用高频信息的好处,我们进一步提出了一种频率增强数据增强(FDA)tailored for VLN,这是一种简单而有效的方法,以增强模型捕获基本高频信息的能力。
具体来说,FDA方法在导航view上利用离散傅里叶变换,从RGB通道中提取高频和低频成分。它用来自干扰图像的部分高频分量替换原图像的部分高频分量,以此引入高频扰动。通过应用傅里叶反变换对扰动高频和原始低频分量的组合,得到了增广数据。通过训练代理同时将原始指令与原始导航视图和增强导航视图相匹配,FDA的方法鼓励代理磨练(hone)其捕获与给定指令最一致的相关高频信息的能力。
本文贡献总结如下: 1)对VLN任务中的频域信息进行了首次深入的分析,强调了高频信息在提高导航性能方面的重要性。这种新颖的视角为社区探索和增强VLN模型提供了新的研究机会。2)我们进一步介绍了一种简单、有效的数据增强方法,即频率增强数据增强(FDA),它增强了模型在不增加复杂性的情况下识别和捕获基本高频信息的能力,为研究界提供了实用的解决方案。3)该方法在R2R、RxR、CVDN和幻想等各种跨模态导航任务上取得了良好的效果,并在不同模型间表现出较强的适应性。
2. 方法(Frequency Perspective for Vision-and-Language Navigation)
方法包括三个部分:1)VLN问题定义,2)高频信息和低频信息的作用,3)FDA方法(Frequency-enhanced Data Augmentation)
2.1 VLN问题定义
根据VLN设置, an agent 在含有许多预设点 p i p^i pi 的室内环境 E = { p 1 , p 2 , . . . , p ∣ E ∣ } E=\{p^1,p^2,...,p^{|E|}\} E={p1,p2,...,p∣E∣} 中导航, 遵循一共人类指令 T = { w 1 , w 2 , . . . , w ∣ T ∣ } . T=\{w_1,w_2,...,w_{|T|}\}. T={w1,w2,...,w∣T∣}. 假设在步骤t, the agent站在点 p t i p_t^i pti 可以接收到周围的全景图 O t = ( o t k ) k = 1 36 O_t=(o_t^k)_{k=1}^{36} Ot=(otk)k=136 包含36个离散的observation o t k o_t^k otk. 每个 observation o t k = ( I t k , θ t k , ϕ t k ) o_t^k=(I_t^k,\theta_t^k,\phi_t^k) otk=(Itk,θtk,ϕtk) 由第 k t h k_{th} kth 个视图 I t k I_t^k Itk 以及它对应的 θ t k \theta_t^k θtk 和仰角 ϕ t k \phi_t^k ϕtk结合. 临近的可导航点 N ( p t i ) N(p_t^i) N(pti)分布在这些视图中. The agent 根据指令 T T T 和 N ( p t i ) N(p_t^i) N(pti)所在的环境 o f k o_f^k ofk之间的关系从相邻的点 N ( p t i ) N(p_t^i) N(pti)中选择下一个可导航点 . 然后,代理将被传送到那个选定的点。导航继续,直到代理预测停止操作或超过预设的步骤阈值。当代理站在目标目的地3米内停止时,导航被认为是成功的。
2.2 高频信息和低频信息的作用(High Frequency or Low Frequency: Which Benefits VLN Performance?)
考虑到图2的观察结果,我们假设图像中的高频信息可能对跨模态导航任务至关重要。为了验证这一假设,我们进行了一个简单的实验,即将原始图像特征与其相应的高频或低频分量进行融合。这些合并后的特性随后在训练和测试过程中作为导航网络的输入,如图3所示。TD-STP [64]的结果见表1。

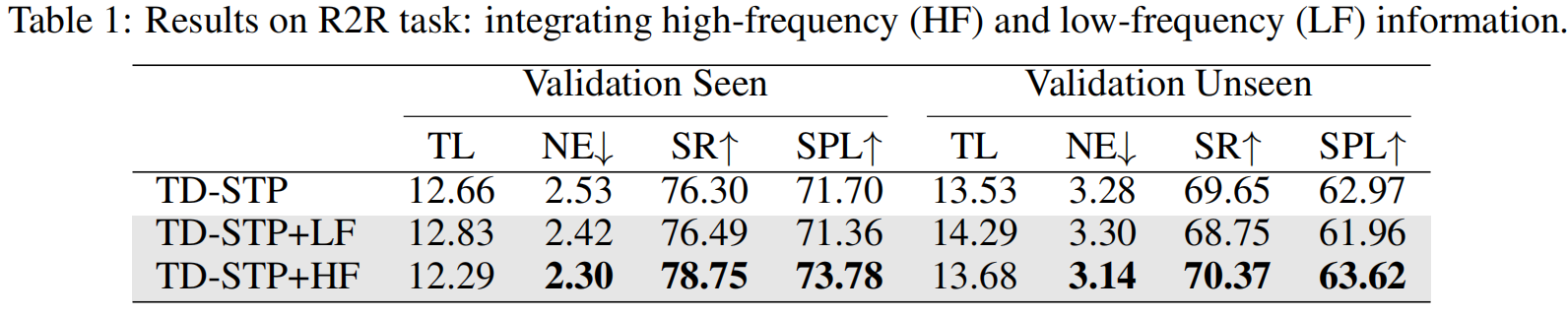
以上观察结果突出了高频信息在跨模态导航中的关键作用。这是因为
1)高频信息包含了一些细节,如边、角和纹理模式。这些细节对于准确地识别和区分物体、场景和位置至关重要,这可以导致更有效的视觉-文本匹配和更好的导航表现。
2)使用高频信息训练的模型往往对环境变化更健壮,并对看不见的环境表现出更强的泛化能力,因为该模型学习了专注于一组更多样化的特征,而不是仅仅记忆训练数据中出现的特定的低频、全局模式。
2.3 FDA方法(Frequency-enhanced Data Augmentation)
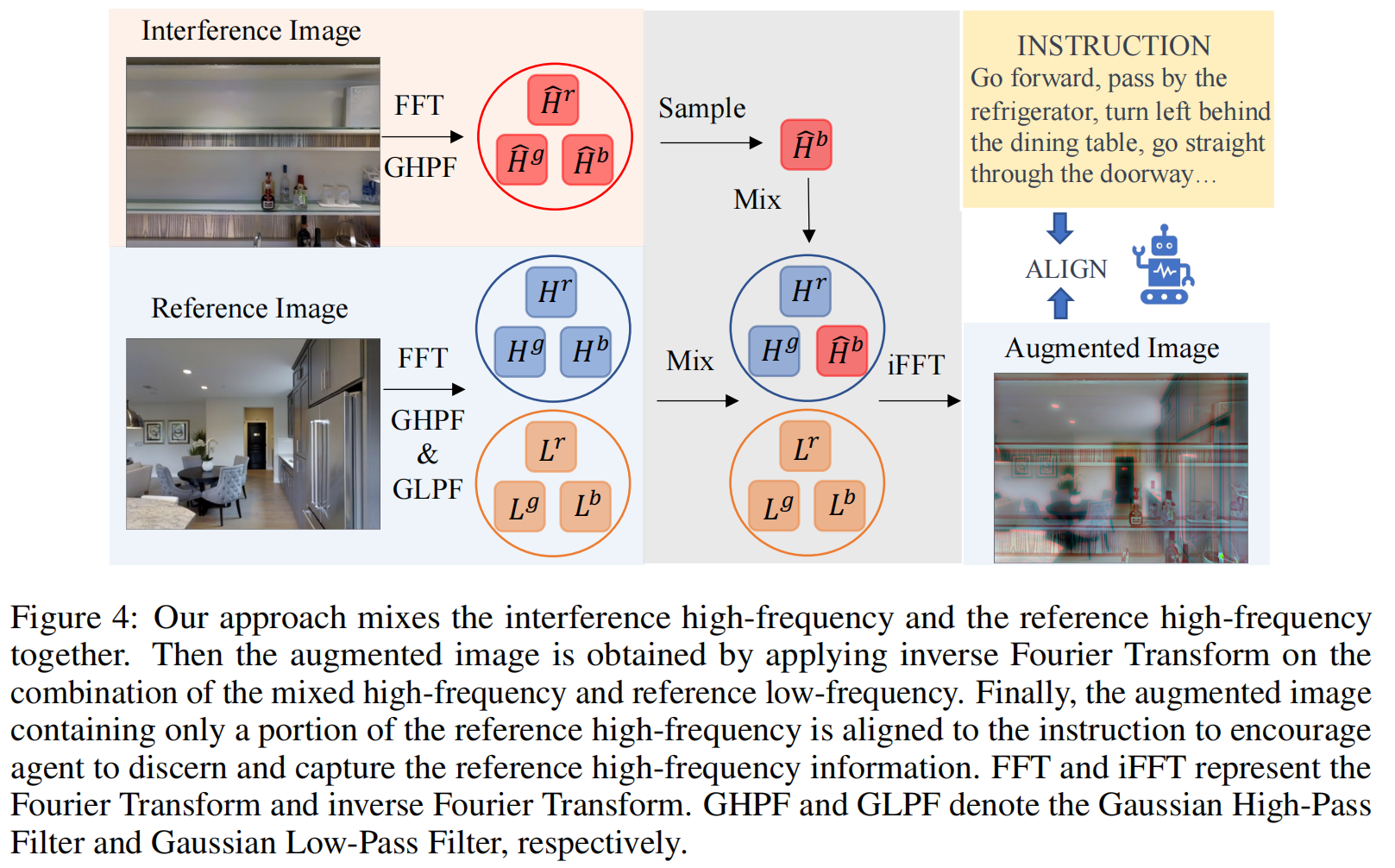
图4:我们的方法将干扰高频和参考高频混合在一起。然后,通过对混合高频和参考低频的组合应用傅里叶反变换,得到了增广图像。最后,将只包含部分参考高频的增强图像与指令对齐,以鼓励代理识别和捕获参考高频信息。FFT和iFFT表示傅里叶变换和傅里叶反变换。GHPF和GLPF分别表示高斯高通滤波器和高斯低通滤波器。
如图4所示,参考图像I是与导航指令T对应的导航视图(“向前走,经过冰箱,在餐桌后面左转,直接穿过门口……”)。干涉图像Iˆ是从Matterport3d(Mp3d)数据集[6]中随机采样的另一个导航视图。为了防止信息泄漏,所有的干扰图像都从训练/验证可见分割中采样,并且不使用验证未可见分割和测试分割中的图像。
我们首先通过傅里叶变换(FFT)将这两张图片转换到频率空间,得到两个频率谱 F I { r g b } F_I^{\{rgb\}} FI{rgb} and F I ^ { r g b } F_{\hat{I}}^{\{rgb\}} FI^{rgb}:
F I { r g b } = F { r g b } ( I ) , F I ^ { r g b } = F { r g b } ( I ^ ) F_I^{\{rgb\}}=\mathcal{F}^{\{rgb\}}(I),~F_{\hat{I}}^{\{rgb\}}=\mathcal{F}^{\{rgb\}}(\hat{I}) FI{rgb}=F{rgb}(I), FI^{rgb}=F{rgb}(I^) 其中 F { r g b } \mathcal{F}^{\{rgb\}} F{rgb} 表示RGB颜色通道上的傅里叶变换。然后,我们在两个频谱上应用高通和低通高斯滤波器来获得参考高频 H { r g b } H^{\{rgb\}} H{rgb},参考低频 L { r g b } L^{\{rgb\}} L{rgb} 和干扰高频y H ^ { r g b } . \hat{H}^{\{rgb\}}. H^{rgb}.
H { r g b } = G h ⊙ F I { r g b } , L { r g b } = G l ⊙ F I { r g b } , H ^ { r g b } = G h ⊙ F I ^ { r g b } \begin{aligned}H^{\{rgb\}}=\mathcal{G}_h\odot F_I^{\{rgb\}},&L^{\{rgb\}}=\mathcal{G}_l\odot F_I^{\{rgb\}},&\hat{H}^{\{rgb\}}=\mathcal{G}_h\odot F_{\hat{I}}^{\{rgb\}}\end{aligned} H{rgb}=Gh⊙FI{rgb},L{rgb}=Gl⊙FI{rgb},H^{rgb}=Gh⊙FI^{rgb} 其中 G h G_h Gh and G l G_l Gl 表示 Gaussian High-Pass Filter (GHPF)和 Gaussian Low-Pass Filter (GLPF), and ∙ ◯ \textcircled{\bullet} ∙◯ is element-wise multiplication. 然后我们将这两个图像的高频部分混合,具体来说,对于参考图像的每个RGB信道,有一定的概率是其高频分量被来自同一信道的干扰高频所取代:
H m i x c = M i x ( H c , H ^ c ) = { H c , p r o b a b i l i t y o f 1 / 3 H ^ c , o t h e r s , c ∈ { r , g , b } H m i x { r g b } = M i x ( H { r g b } , H ^ { r g b } ) \begin{gathered} \left.H_{mix}^{c}=\mathcal{M}ix(H^{c},\hat{H}^{c})=\left\{\begin{array}{ll}{{H^{c},}}&{{probabilityof1/3}}\\{{\hat{H}^{c},}}&{{others}}\end{array}\right.\right.,c\in\{r,g,b\} \\ H_{mix}^{\{rgb\}}=\mathcal{M}ix(H^{\{rgb\}},\hat{H}^{\{rgb\}}) \end{gathered} Hmixc=Mix(Hc,H^c)={Hc,H^c,probabilityof1/3others,c∈{r,g,b}Hmix{rgb}=Mix(H{rgb},H^{rgb}) 其中 H m i x { r g b } H_{mix}^{\{rgb\}} Hmix{rgb} 是混合的高频. 我们将它与参考低频 L { r g b } L^{\{rgb\}} L{rgb} 结合然后用 iFFT获得频率增强的图像 I m i x I_{mix} Imix:
I m i x = F − 1 ( F m i x { r g b } ) = F − 1 ( H m i x { r g b } , L { r g b } ) . I_{mix}=\mathcal{F}^{-1}(F_{mix}^{\{rgb\}})=\mathcal{F}^{-1}(H_{mix}^{\{rgb\}},L^{\{rgb\}}). Imix=F−1(Fmix{rgb})=F−1(Hmix{rgb},L{rgb}). 最后原始图像 I I I 和增广图像 I m i x I_{mix} Imix 共享同一个文本指令标签 T T T 在训练阶段交替用于训练agent:
L ( θ ) = { N a v i g a t o r L o s s ( I , T , θ ) , o d d - n u m b e r e d s t e p N a v i g a t o r L o s s ( I m i x , T , θ ) , e v e n - n u m b e r e d s t e p \left.L(\theta)=\left\{\begin{array}{ll}NavigatorLoss(I,T,\theta),&odd\text{-}numberedstep\\NavigatorLoss(I_{mix},T,\theta),&even\text{-}numberedstep\end{array}\right.\right. L(θ)={NavigatorLoss(I,T,θ),NavigatorLoss(Imix,T,θ),odd-numberedstepeven-numberedstep 其中 L ( θ ) L(\theta) L(θ) 表示考虑了原始图像 I I I和频率增强图像 I m i x 的导航损失 , θ I_{mix}的导航损失,\theta Imix的导航损失,θ 表示导航器的参数。
3,实验
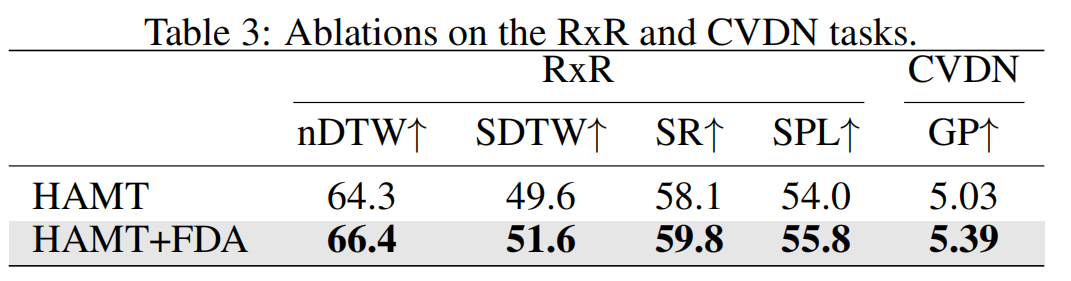
消融实验(在不同的模型和不同的数据集上)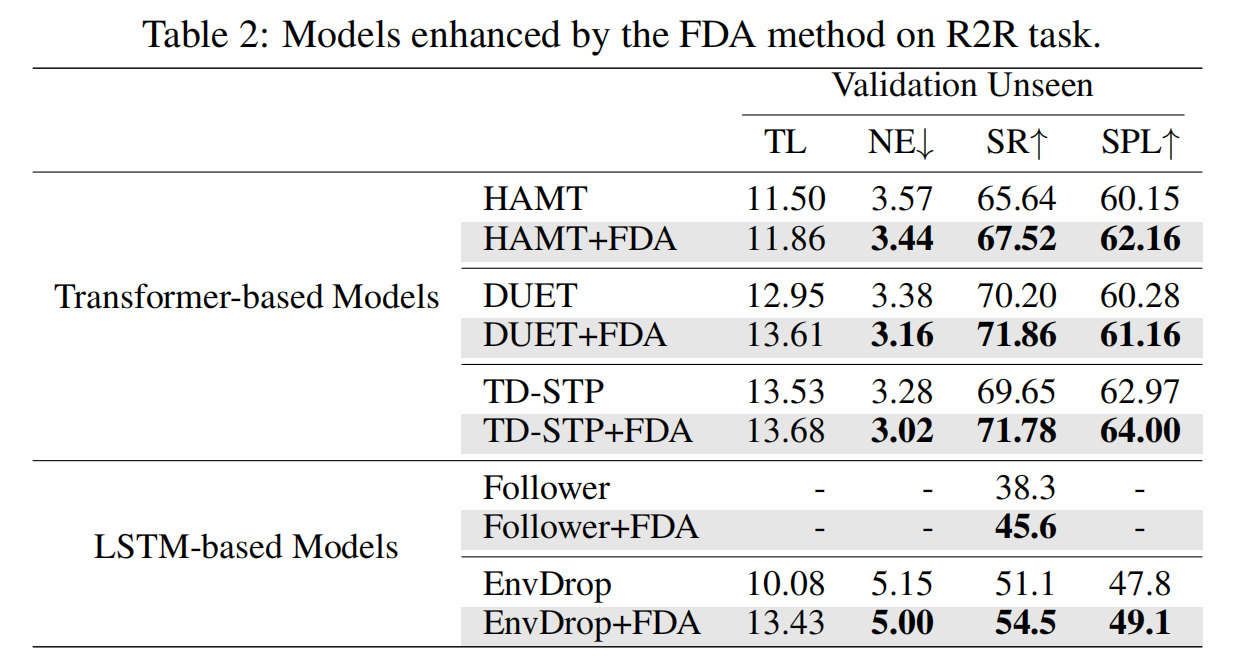

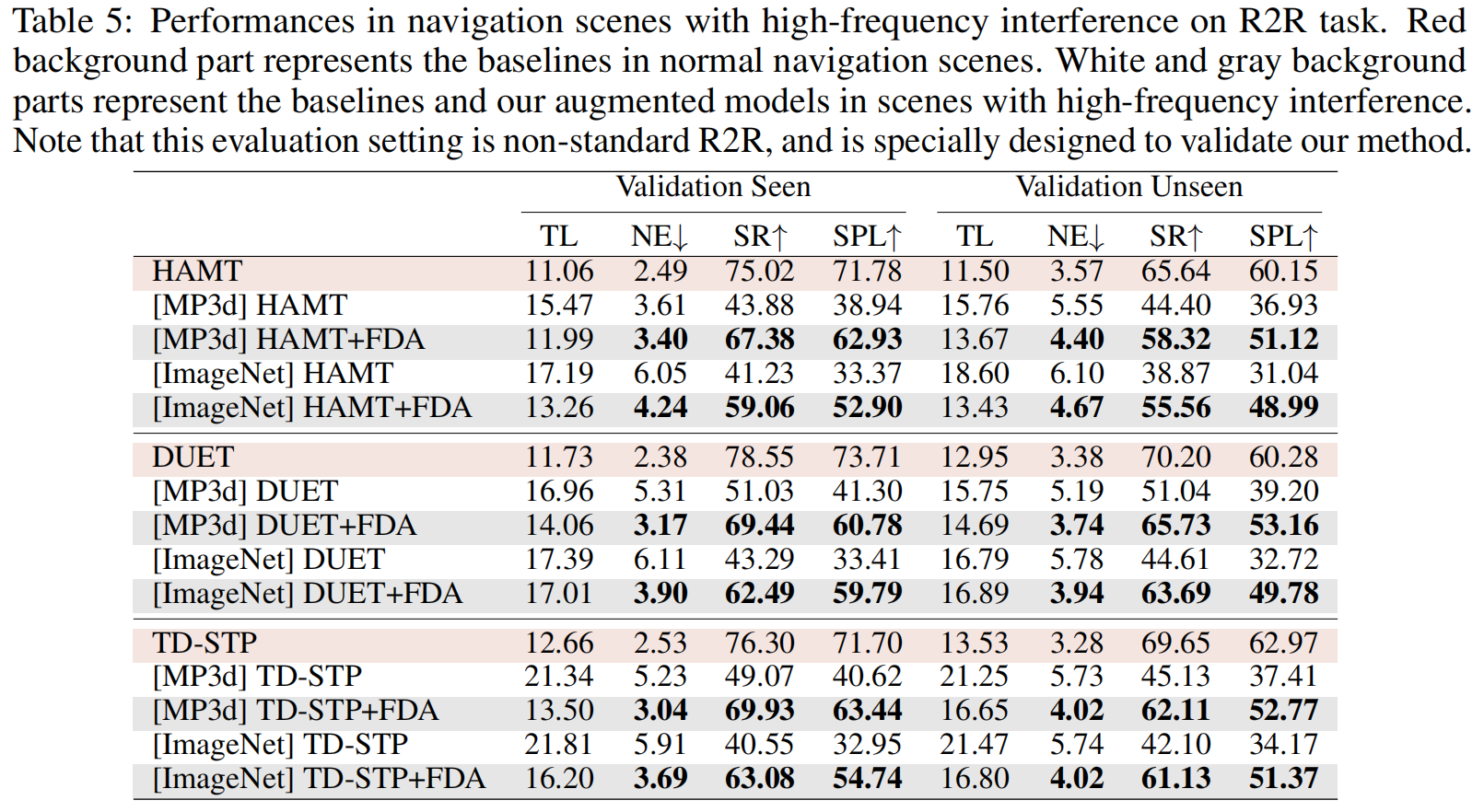
如表5,现有的VLN方法在高频扰动导航场景中受到了严重的限制。ImageNet表示从ImageNet中选取干扰图像。这有力地证明了我们的方法能够识别和捕获必要的高频信息,以提高导航性能。
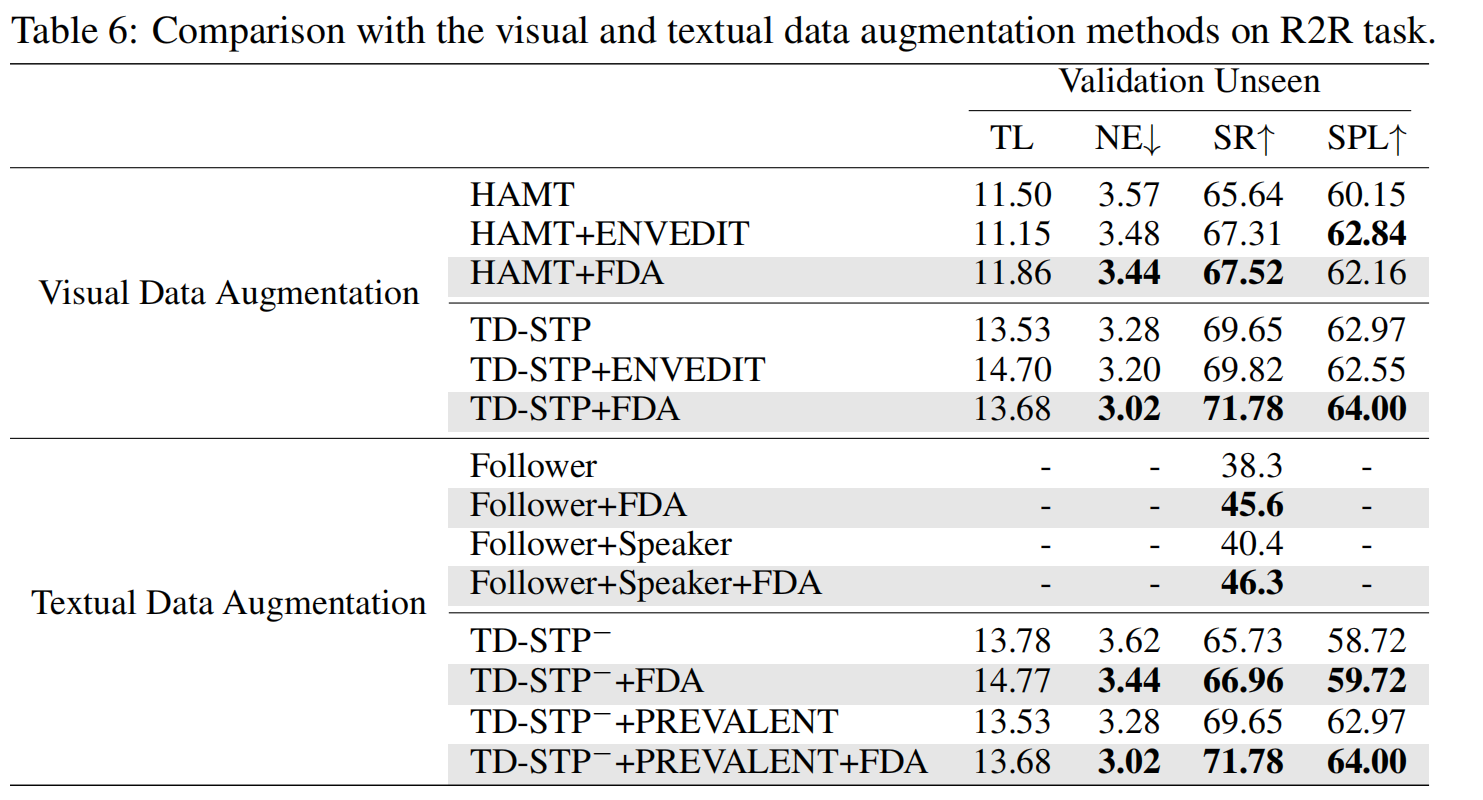
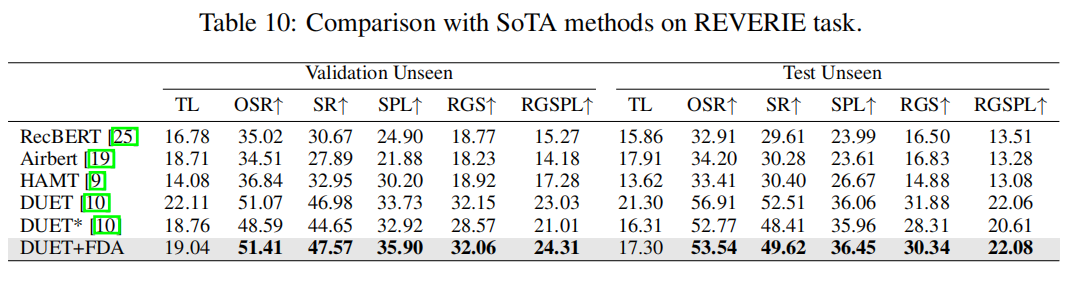
与sota结果相比
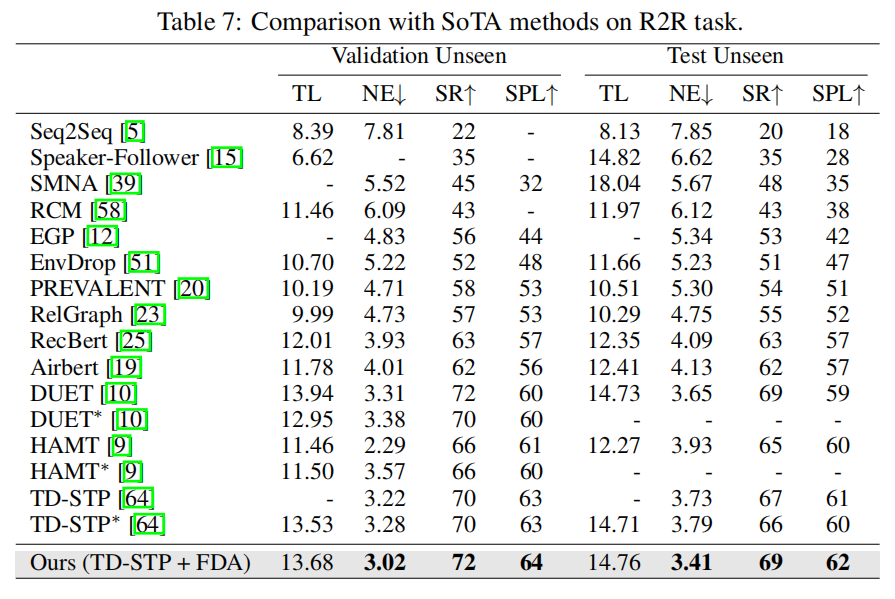
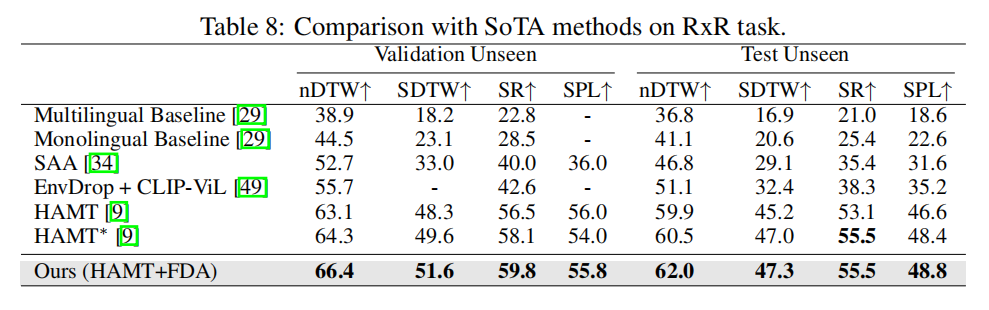
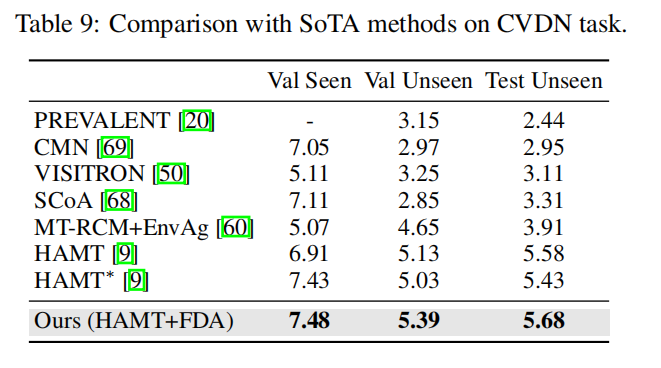
局限性和未来的工作。
本文重点是增强模型识别和捕获基本高频信息的一般能力。然而,还没有探索频率和特定场景或类别之间的细粒度相关性。这一调查领域仍然是未来探索的一条途径。







![[c++] char * 和 std::string](https://img-blog.csdnimg.cn/direct/41d882545669454391caf4a37bc6e6dd.png)