本篇文章的第一部分是关于探索词嵌入(word embedding)向量空间。词嵌入是一种语言模型和文本表示技术,其中单词或短语从词汇表被映射到向量的高维空间中。通过这种方式,可以通过计算向量之间的距离来捕捉单词之间的语义关系。
1. 词嵌入向量空间探索
1.1 视觉探索
实验指导书建议使用CMU开发的词嵌入可视化 工具 进行探索。通过这个工具,你可以通过向量算术的例子来探索词向量空间的行为。向量算术指的是使用加法和减法等操作来组合或比较单词向量,以发现它们之间的语义关系。例如:
Spain is to Madrid as France is to...(西班牙之于马德里,如同法国之于……)这个问题的答案应该是“Paris”(巴黎),因为“Madrid”是西班牙的首都,“Paris”是法国的首都,这反映了首都这一概念在向量空间中的位置关系。
France is to wine as Germany is to...(法国之于葡萄酒,德国之于……)这里,答案可能是beer(啤酒),因为葡萄酒是法国的典型饮品,而啤酒是德国的典型饮品。
Man is to researcher as woman is to..."(男人之于研究员,女人之于……)这个例子用于探索性别偏见,答案应该是基于性别中立的职业描述,但也可能揭示词嵌入模型中的性别偏见。
这个实验鼓励你尝试尽可能多的例子来发现向量空间中的语义关系。通过不仅观察最接近的向量结果,还要观察前十个结果,你可以更深入地了解这些词嵌入模型可能存在的偏见。
链接:https://www.cs.cmu.edu/~dst/WordEmbeddingDemo/.
1.2 程序化探索
在这一部分,我们将通过编程的方式探索词嵌入向量空间。这里使用的是 gensim 库,它是一个专门用于从文档中自动提取语义主题的Python库,非常适合进行词嵌入模型的加载和操作。
首先,你需要安装gensim库。可以通过运行如下命令来安装。
pip install gensim安装完成后,你可以加载一个预先训练好的词嵌入模型。这里,我们使用的是Google News数据集上训练的word2vec模型,该模型包含300万个词向量,每个向量的维度为300。模型相当大,大小约为1.6GB,因此下载和加载可能需要一些时间。
import gensim.downloader as api
vectors = api.load('word2vec-google-news-300')
一旦加载了模型,你就可以通过简单地使用单词作为索引来获取对应的词向量,例如vectors["dog"]将会返回 dog 这个单词的向量表示。
gensim还允许你进行向量算术操作。例如,你可以通过加减向量来探索语义关系,如找到与某些词性质相近的词。对于给定的向量v,你可以使用以下方法来找到最相似的词向量:
vectors.most_similar([v])这个方法返回一个列表,列表中包含了与向量v最相似的单词及其相似度。
通过这种程序化的方法,你可以在大规模的词向量空间中进行高效的探索,发现复杂的语义关系,甚至挖掘潜在的偏见。例如,你可以通过向量运算来探索“国家-首都”、“物品-产地”等关系,或者探讨性别和职业的关系,以及它们如何在词嵌入空间中被表示。
2. 文本语料库创建词嵌入
2.1 背景
在这一部分,我们将学习如何使用一个文本语料库创建词嵌入。文本语料库名为“tp1-text8-fr-v1.txt”,大小为103MB,内容是从法文维基百科中提取的,主要是法语文本。
文章内容举例如下:
paul jules antoine meillet né le à moulins allier moulins allier
département allier et mort le à châteaumeillant cher département cher
est le principal liste de linguistes linguiste français des premières
décennies du il est aussi philologue d origine bourbonnaise fils d un
notaire de châteaumeillant cher département cher antoine meillet fait
ses études secondaires au lycée théodore de banville lycée de moulins
allier moulins étudiant à la faculté des lettres de paris à partir de
où il suit notamment les cours de louis havet il assiste également à
ceux de michel bréal au collège de france et de ferdinand de saussure à
l école pratique des hautes études en il est major de l agrégation de
grammaire il assure à la suite de saussure le cours de grammaire
comparée qu il complète à partir de par une conférence sur les langues
persanes en il soutient sa thèse pour le doctorat ès lettres recherches
sur l emploi du génitif accusatif en vieux slave en il occupe la chaire2.2 代码
# 从gensim.models.doc2vec导入Word2Vec模型
from gensim.models.doc2vec import Word2Vec# 设置向量的大小,训练周期数,和词汇表的最大大小
VECTOR_SIZE = 300
EPOCHS = 30
VOCAB_SIZE = 40000# 初始化Word2Vec模型,设置相关参数
model = Word2Vec(vector_size=VECTOR_SIZE, min_count=3, \
epochs=EPOCHS, max_final_vocab=VOCAB_SIZE)print("Building vocabulary...")
# 使用指定的文本文件构建模型的词汇表
model.build_vocab(corpus_file="tp1-text8-fr-v1.txt")
print("Vocabulary built with size " + str(len(model.wv)))print("Starting training...")
# 根据文本语料库训练Word2Vec模型
model.train(corpus_file="tp1-text8-fr-v1.txt", \
total_examples=model.corpus_count, \
epochs=model.epochs, total_words=len(model.wv))
print("Training done. Saving model.")
# 训练完成后,保存模型供将来使用
model.save("word2vec_fr")# 加载训练好的模型(这行被注释掉了,因为模型已经在前面的步骤中被保存和加载)
# model = Word2Vec.load("word2vec_fr")# 打印与单词“maison”(房子)最相似的单词
print(model.wv.most_similar("maison"))
# 打印与单词“roi”(国王)最相似的单词
print(model.wv.most_similar("roi"))
首先,我们使用 gensim 库中的 Word2Vec 模型来创建词嵌入。Word2Vec 是一个流行的算法,用于将文本中的单词表示为向量。这些向量捕获了单词之间的语义关系,如相似性、上下文关联等。
在代码中,我们首先设置了一些参数,如向量大小(`VECTOR_SIZE = 300`),训练周期(`EPOCHS = 30`),和词汇表大小(`VOCAB_SIZE = 40000`)。然后,我们使用文本语料库来构建模型的词汇表,并训练模型。训练完成后,我们保存了这个模型,并使用`model.wv.most_similar("word")`方法来查找与给定单词最相似的单词。
2.3 运行结果
[('profession', 0.9986109137535095), ('sat', 0.9981982707977295),
('provence', 0.9981659054756165), ('campagne', 0.9980286359786987), ('reconnaissance', 0.9976771473884583), ('auprès', 0.9975213408470154), ('référence', 0.9973973035812378), ('barrière', 0.9973931908607483),
('château', 0.9973866939544678), ('traités', 0.9973354935646057)][('gouverneur', 0.9945092797279358), ('mort', 0.9923467636108398),
('duc', 0.9919790029525757), ('archipel', 0.9909862279891968),
('point', 0.990552544593811), ('lymphe', 0.9904707074165344),
('dauphiné', 0.9902621507644653), ('entrée', 0.9895468950271606),
('mise', 0.9894086122512817), ('haut', 0.9891223907470703)]在给定的例子中,我们查询了“maison”(房子)和“roi”(国王)这两个单词最相似的单词。结果显示了与“maison”和“roi”最相似的一系列单词及它们的相似度得分。例如,maison最相似的单词包括“profession”(职业)、“sat”(卫星)、“provence”(普罗旺斯)等,而 roi 最相似的单词包括“gouverneur”(州长)、“mort”(死亡)、“duc”(公爵)等。
这个过程展示了如何从一个特定的文本语料库中创建词嵌入,以及如何使用这些词嵌入来探索语言中单词之间的语义关系。通过训练,模型学习到的词向量能够揭示单词之间复杂的语义和语法关系,这对于理解自然语言处理和机器学习在文本分析中的应用非常重要。
3. 训练 Doc2Vec 模型并检索类似文件
这一部分的目的是训练一个Doc2Vec模型,并用它来检索与给定查询最相似的文档。我们将使用一个包含480,373条法语句子的语料库(文件名为`tp2-sentences-fr400k.txt`,大约20MB)。以下是文件的开头:
Lorsqu'il a demandé qui avait cassé la fenêtre, tous les garçons ont pris un air innocent.
Je ne supporte pas ce type.
Pour une fois dans ma vie je fais un bon geste... Et ça ne sert à rien.
Ne tenez aucun compte de ce qu'il dit.
Essayons quelque chose !
Qu'est-ce que tu fais ?
Qu'est-ce que c'est ?
Aujourd'hui nous sommes le 18 juin et c'est l'anniversaire de Muiriel !
Joyeux anniversaire Muiriel !
Muiriel a 20 ans maintenant.下面是代码以及运行过程的:
3.1 安装Gensim库
首先,确保安装了Gensim库,因为我们将使用它的Doc2Vec功能。
pip install gensim3.2 代码
# 导入Doc2Vec模型、用于文本预处理的simple_preprocess工具,以及TaggedDocument类
from gensim.models.doc2vec import Doc2Vec
from gensim.utils import simple_preprocess
from gensim.models.doc2vec import TaggedDocument# 定义一个函数,用于读取文本文件并预处理每一行文本
def read_corpus(file_path):with open(file_path, encoding="utf-8") as f: # 打开文件for i, line in enumerate(f): # 遍历文件的每一行# 使用simple_preprocess对行进行预处理(如分词),并将结果封装成TaggedDocument对象yield TaggedDocument(simple_preprocess(line), [i])# 读取文本文件,并将其转换为训练集
train_set = list(read_corpus('tp2-sentences-fr400k.txt'))
# 初始化Doc2Vec模型,设置向量大小、最小出现次数和训练迭代次数
model = Doc2Vec(vector_size=256, min_count=3, epochs=30)
# 根据训练集构建词汇表
model.build_vocab(train_set)# 训练模型
print("Starting training...")
model.train(train_set, total_examples=model.corpus_count, epochs=model.epochs)
# 保存训练好的模型到文件
model.save("doc2vec_fr")# 加载训练好的模型(这行代码被注释掉了,因为模型已经在前面的步骤中被保存)
# model = Doc2Vec.load("doc2vec_fr")
print("Training done. Saving model.")# 使用模型将一组单词(查询句子)转换为向量
query_vec = model.infer_vector(['Le', 'temps', 'passe', 'si', 'vite'])
# 查找最相似的文档,返回前10个最相似的文档及其相似度得分
sims = model.docvecs.most_similar([query_vec], topn=10)
# 打印出相似度得分和相应的文档内容
for doc_id, sim in sims:print('{:3.2f} {}'.format(sim, train_set[doc_id].words))
3.3 定义读取语料库的函数
通过定义一个 read_corpus 函数,我们可以逐行读取文件,并使用 Gensim 的simple_preprocess 对每一行进行简单的预处理(比如分词),然后将每个句子标记为`、TaggedDocument。每个`TaggedDocument`包含处理过的单词和一个唯一的标签(在这里,我们使用句子的行号作为标签)。
3.4 训练Doc2Vec模型
使用 Doc2Vec 类创建一个模型实例,设置向量大小(vector_size=256),最小出现次数(min_count=3),和训练迭代次数(`epochs=30`)。然后,使用`build_vocab`方法构建词汇表,并用 train 方法训练模型。
3.5 保存和加载模型
训练完成后,使用`save`方法保存模型,这样就可以在以后重新加载而不需要重新训练。
3.6 使用模型进行查询
为了找到与给定查询句子最相似的文档,首先使用`infer_vector`方法将查询句子转换成一个向量。然后,使用`docvecs.most_similar`方法找到这个向量最相似的文档向量。
3.7 展示查询结果
0.74 ['tu', 'étais', 'pas', 'sérieuse', 'si']
0.70 ['vos', 'parents', 'doivent', 'être', 'si', 'fiers', 'de', 'vous']
0.68 ['si', 'elles', 'veulent']
0.68 ['ils', 'ont', 'pas', 'air', 'si', 'mauvais']
0.67 ['je', 'veux', 'aider', 'si', 'je', 'peux']
0.67 ['est', 'si', 'gentil', 'de', 'votre', 'part']
0.67 ['mon', 'cœur', 'bat', 'si', 'fort']
0.67 ['ai', 'été', 'si', 'humiliée']
0.66 ['vous', 'ne', 'semblez', 'pas', 'si', 'malignes']
0.66 ['vous', 'étiez', 'pas', 'sérieuse', 'si']对于每个找到的相似文档,打印出相似度得分和文档的内容。在这个例子中,查询句子包含词汇"Le", "temps", "passe", "si", "vite"(时间过得真快),并展示了与这个查询最相似的10个句子及其相似度得分。
这个过程演示了如何使用Doc2Vec模型来理解和检索文本数据,特别是如何从大量的文本中找到语义上相似的句子或文档。这对于很多自然语言处理和信息检索任务都是非常有用的。
4. 使用 LSTM 进行句子语言检测
我们尝试使用深度学习技术实现语言检测,具体来说是使用长短期记忆(LSTM)模型。除了学习如何训练这样的模型,这还允许我们与上一实验室中使用的基于朴素贝叶斯方法的训练持续时间和准确性结果进行比较。
我们将使用相同的每种语言10,000句子(使用拉丁字母的柏柏尔语、德语、英语、世界语、法语、匈牙利语、意大利语、葡萄牙语、西班牙语和土耳其语),另外还有10,000句用于验证(tp3-dev.tsv)。
为了加速训练过程,你可以使用Google Colab或者使用你的GPU进行训练。只需不要忘记在开始时激活GPU(执行/修改执行类型)。
4.2 安装要求
pip install allennlp
pip install allennlp-models
pip install --upgrade torch torchvision在Google Colab下,每行命令前需要加上‘!’
接下来的代码定义了类和函数并加载了数据。源代码也可以在绑定资源中找到。
通过使用LSTM模型进行语言检测,我们可以探索深度学习在文本处理领域的应用。LSTM模型因其在处理时间序列数据和文本数据中捕捉长期依赖性方面的优势而被广泛使用。在语言检测任务中,模型需要从文本数据中学习并识别不同语言的特定特征和模式。
使用Google Colab和GPU加速可以显著减少模型训练所需的时间,使我们能够更快地迭代和改进模型。通过与朴素贝叶斯方法的比较,我们可以更深入地理解深度学习方法与传统机器学习方法在处理实际NLP任务时的差异和潜在优势。
4.1 代码
from typing import Dict
import numpy as np
import torch
import torch.optim as optim
from allennlp.common.file_utils import cached_path
from allennlp.data.data_loaders import MultiProcessDataLoader
from allennlp.data.dataset_readers import DatasetReader
from allennlp.data.fields import LabelField, TextField
from allennlp.data.instance import Instance
from allennlp.data.samplers import BucketBatchSampler
from allennlp.data.token_indexers import TokenIndexer, SingleIdTokenIndexer
from allennlp.data.tokenizers.character_tokenizer import CharacterTokenizer
from allennlp.data.vocabulary import Vocabulary
from allennlp.modules.seq2vec_encoders import PytorchSeq2VecWrapper
from allennlp.modules.text_field_embedders import BasicTextFieldEmbedder
from allennlp.modules.token_embedders import Embedding
from allennlp.training import GradientDescentTrainer
import picklefrom allennlp.data import TextFieldTensors
from allennlp.models import Model
from allennlp.modules.text_field_embedders import TextFieldEmbedder, BasicTextFieldEmbedder
from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper
from allennlp.training.metrics import CategoricalAccuracy, F1Measure
from allennlp.nn.util import get_text_field_mask# AllenNLP中的Model类代表了一个已经训练好的模型。
# @Model.register("lstm_classifier")
class LstmClassifier(Model):def __init__(self,embedder: TextFieldEmbedder,encoder: Seq2VecEncoder,vocab: Vocabulary,positive_label: str = '4') -> None:super().__init__(vocab)# 我们需要嵌入层将词ID转换为它们的向量表示self.embedder = embedderself.encoder = encoder# 在将一系列向量转换为单个向量后,我们将其输入到一个全连接的线性层中,# 以减少其维度到标签总数。self.linear = torch.nn.Linear(in_features=encoder.get_output_dim(),out_features=vocab.get_vocab_size('labels'))# 监控指标 - 我们使用准确率以及对于标签4(非常积极)的精确度、召回率和F1分数positive_index = vocab.get_token_index(positive_label, namespace='labels')self.accuracy = CategoricalAccuracy()self.f1_measure = F1Measure(positive_index)# 我们使用交叉熵损失函数,因为这是一个分类任务。# 注意PyTorch的CrossEntropyLoss结合了softmax和对数似然损失,# 这使得添加一个单独的softmax层变得不必要。self.loss_function = torch.nn.CrossEntropyLoss()# 实例在批处理后被送入前向传播。# 字段通过与它们同名的参数传递。def forward(self,tokens: TextFieldTensors,label: torch.Tensor = None) -> torch.Tensor:# 在深度NLP中,当不同长度的张量序列被批量处理时,# 较短的序列会被零填充以使它们长度相等。# 掩码是忽略由填充添加的额外零的过程mask = get_text_field_mask(tokens)# 前向传播embeddings = self.embedder(tokens)encoder_out = self.encoder(embeddings, mask)logits = self.linear(encoder_out)probs = torch.softmax(logits, dim=-1)# 在AllenNLP中,forward()的输出是一个字典。# 你的输出字典必须包含一个"loss"键,以便你的模型能被训练。output = {"logits": logits, "cls_emb": encoder_out, "probs": probs}if label is not None:self.accuracy(logits, label)self.f1_measure(logits, label)output["loss"] = self.loss_function(logits, label)return outputdef get_metrics(self, reset: bool = False) -> Dict[str, float]:return {'accuracy': self.accuracy.get_metric(reset),**self.f1_measure.get_metric(reset)}class TatoebaSentenceReader(DatasetReader):def __init__(self,token_indexers: Dict[str, TokenIndexer]=None):super().__init__()# 使用字符级分词器self.tokenizer = CharacterTokenizer()# 如果没有提供token_indexers,则默认使用SingleIdTokenIndexerself.token_indexers = token_indexers or {'tokens': SingleIdTokenIndexer()}# 将文本转换为模型可以处理的实例def text_to_instance(self, tokens, label=None):fields = {}# 将tokens添加到实例中fields['tokens'] = TextField(tokens, self.token_indexers)# 如果提供了标签,则添加标签到实例中if label:fields['label'] = LabelField(label)return Instance(fields)# 读取数据文件,每一行代表一个样本def _read(self, file_path: str):# 确保文件路径是可访问的file_path = cached_path(file_path)with open(file_path, "r") as text_file:for line in text_file:# 每行数据格式为"语言ID\t句子"lang_id, sent = line.rstrip().split('\t')# 使用tokenizer分词tokens = self.tokenizer.tokenize(sent)# 生成并返回一个实例yield self.text_to_instance(tokens, lang_id)# 设置嵌入层和隐藏层的维度大小
EMBEDDING_DIM = 16
HIDDEN_DIM = 16# 实例化数据读取器
reader = TatoebaSentenceReader()# 训练集和验证集的路径
train_path = 'tp3-train.tsv' # tp3-train.tsv
dev_path = 'tp3-dev.tsv' # tp3-dev.tsv# 使用BucketBatchSampler来对数据进行批处理,这里指定批大小为32,并根据"tokens"字段进行排序
# 这有助于优化训练过程,因为它减少了每个批次中填充的数量
sampler = BucketBatchSampler(batch_size=32, sorting_keys=["tokens"])# 创建用于训练和验证的数据加载器,这里使用了多进程加载器以加速数据的准备过程
train_data_loader = MultiProcessDataLoader(reader, train_path, batch_sampler=sampler)
dev_data_loader = MultiProcessDataLoader(reader, dev_path, batch_sampler=sampler)# 从训练数据加载器生成的实例中创建词汇表,设置最小出现次数为3
# 这有助于过滤掉稀有词,减小模型大小和提高处理速度
vocab = Vocabulary.from_instances(train_data_loader.iter_instances(), min_count={'tokens': 3})# 将词汇表索引应用到数据加载器,确保文本转换为正确的整数索引
train_data_loader.index_with(vocab)
dev_data_loader.index_with(vocab)# 创建一个词嵌入层,指定词汇表的大小和嵌入向量的维度
token_embedding = Embedding(num_embeddings=vocab.get_vocab_size('tokens'), embedding_dim=EMBEDDING_DIM)# 使用基础文本字段嵌入器将词嵌入层包装起来,以便处理不同的文本字段
word_embeddings = BasicTextFieldEmbedder({"tokens": token_embedding})# 创建一个编码器,这里使用Pytorch的LSTM作为序列到向量的编码器,设置嵌入层维度为输入,隐藏层维度为输出,并确保输入输出数据的第一个维度为批次大小
encoder = PytorchSeq2VecWrapper(torch.nn.LSTM(EMBEDDING_DIM, HIDDEN_DIM, batch_first=True))# 实例化LSTM分类器模型,传入之前创建的词嵌入、编码器和词汇表,指定'eng'为正类标签
model = LstmClassifier(word_embeddings, encoder, vocab, positive_label='eng')# 如果你想使用GPU加速,请取消下面这行代码的注释
# model.to('cuda')# 将词汇表索引应用到训练和验证数据加载器,确保数据集中的文本可以转换成正确的整数索引
train_data_loader.index_with(vocab)
dev_data_loader.index_with(vocab)# 初始化优化器,这里使用Adam优化器,并将其应用于模型的所有参数
optimizer = optim.Adam(model.parameters())# 创建一个梯度下降训练器,配置模型、优化器、数据加载器等训练相关的参数
# 包括训练耐心(patience)、训练轮数(num_epochs)以及是否使用GPU(cuda_device)
trainer = GradientDescentTrainer(model=model,optimizer=optimizer,data_loader=train_data_loader,validation_data_loader=dev_data_loader,patience=10,num_epochs=20,cuda_device=-1) # 将"cuda_device=0"设置为使用GPU# 开始训练模型,并打印出训练过程中的关键信息
print("开始训练模型...")
trainer.train()
print("模型训练完成。")# 将训练好的模型保存到文件中
pickle.dump(model, open("tp3-model.p", "wb"))
print("模型已保存到'tp3-model.p'。")# 定义一个函数,用于分类输入的文本
def classify(text: str, model: LstmClassifier):# 实例化一个字符级的分词器tokenizer = CharacterTokenizer()token_indexers = {'tokens': SingleIdTokenIndexer()}# 使用分词器对输入文本进行分词tokens = tokenizer.tokenize(text)instance = Instance({'tokens': TextField(tokens, token_indexers)})# 使用模型对实例进行预测,并获取logitslogits = model.forward_on_instance(instance)['logits']# 从logits中找到最大值对应的标签idlabel_id = np.argmax(logits)# 将标签id转换成具体的标签名label = model.vocab.get_token_from_index(label_id, 'labels')# 打印出输入文本及其对应的分类标签print('text: "{}", label: "{}"'.format(text, label))# 使用定义好的分类函数对几个文本样例进行分类
classify("Ceci est un test, ça marchera peut-être.", model)
classify("Jetzt werden wir sehen ob es klappt.", model)
classify("Let us see whether it works.", model)
4.2 运行结果
text: "Ceci est un test, ça marchera peut-être.", label: "fra"
text: "Jetzt werden wir sehen ob es klappt.", label: "deu"
text: "Let us see whether it works.", label: "eng"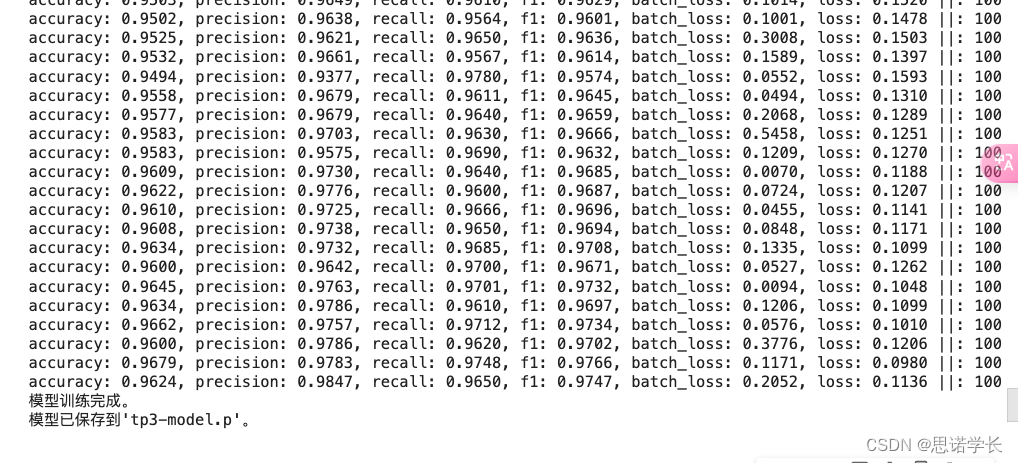
5. 参考代码
https://colab.research.google.com/drive/1IeB5zO47G535ZpcXc7SlTT2Di8U1Byuo?usp=sharing