分享主流电商平台网页数据批量采集,数据采集API接口的相关知识。
电商数据采集是很多运营工作中必不可少的一个环节。有了足够的数据,才能够更好地了解自身的受众群体,并且根据受众的喜好进行有针对性的设计和优化。
数据采集的流程是怎样的呢?
一般来说,数据采集的流程包括三个步骤:数据采集、数据清洗、数据分析和数据应用。

搭建采集流程
如何搭建网页数据采集的流程呢?
首先,我们需要确定数据采集的目标。然后,分析自己在目标站上的操作流程和执行操作的定位点。有时候我们的操作流程会涉及多次点击、打开新页面、输入内容并点击等,这种情况往往会形成循环嵌套,对此我们最好先把任务进行拆分,完成一部分,调试一部分,调试没有问题后再进入下一个循环进行设计。

网页特性决定采集方法
在网页采集中,通常采用xpath的方式定位元素位置及文本内容,属性值,这个可能需要有一定的基础,关键的定位点搞定了后,基本就决定了数据采集的方式。最后,我们需要建立数据采集的流程。
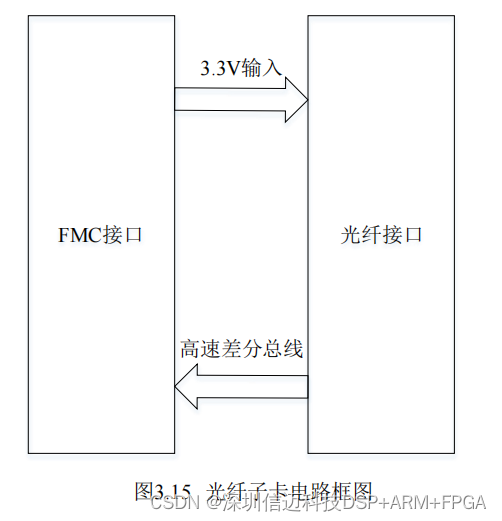
举个案例:网页的数据采集,采集的目标可以是任何东西,比如页面中的基本信息、访问量、页面代码中的信息等。
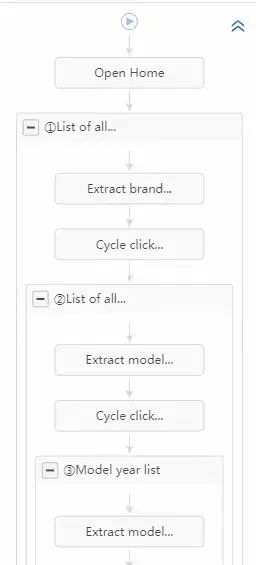
这个采集流程是用八爪鱼采集器完成的,有5层网页嵌套,是为一个国外客户做的当地二手车信息汇总的采集项目,最终表格有32列数据,由每一层页面提取一部分信息组合起来的。

说在最后的话
数据采集的方式可以是自动采集和手动采集,也有自动+手动配合实施的。具体实施哪种技术方案,主要是根据目标情况来的。Python是比较常用的技术方案,但实现的时间成本比较高,现在也有很多现成的采集工具可以使用,设计流程稍微简单一些,但是有很多特殊可能无法实现,比如图片文件按自己需要的规律保存在特定文件夹和名称,如果前两者都搞不定,还有RPA技术等其他技术方案。
总之,网页上公开展示的信息,基本都是可以批量提取下载来。批量采集节省大量的人工劳力,采集流程的规则设计,还是非常值得考虑。