文章目录
- 前言
- 环境准备
- 调用
- 混合
- 总结
前言
郑重声明:本博文做法仅限毕设糊弄老师使用,不建议生产环境使用!!!
老项目缝缝补补又是三年,本来是打算直接重写写个社区然后给毕设使用的。但是怎么说呢,毕竟毕设的主角不是xx社区,这个社区是为我的编译器服务的,为了推广这个编译器,然后我才做了这个社区。然而不幸的是,开题答辩的时候,各位“专家”叫我以xx社区为主,听起来高级。于是没有办法,我只能强行做个社区,怎么做呢,照着以前写的社区抄,换个主题呗。但是重新写的成本太高了(一开始我是嫌弃白洞这个项目的部署成本比较高,因为里面确实集成了很多模块,有AI模块有传统微服务模块,当然开源的版本是没有这些东西的,毕竟还是要留点底裤的),但是重写实在难受,找了一圈想要找个开源的,结果都没有找到满意的,没办法,只能把白洞项目拿出来,然后做减法,加一个推荐系统。
推荐系统本来也是打算直接基于Java重写手写一个的,直接写个基于协同滤波的传统推荐算法。但是感谢开源,发现了个牛逼的框架mahout。这不就齐活了,我们直接糊弄糊弄毕设过去了就行了。借用某位大哥的话:你要搞清楚你的目的是什么,没有效益的事情少干。于是鄙人放弃了手写推荐系统,放弃了对netty重新封装。咱们有技术积累,但是没有能够产生实际效益的项目,所以不干,糊弄老师得了。
环境准备
这里的话,因为是糊弄毕设,所以我们是直接冷启动。用的是ItemCF,直接推荐博客。然后呢从100个用户里面数据里面推荐就行了,然后结果缓存起来,一天一推。多了没有,反正我用了这个玩意儿,现场查代码也没事,况且数据量根本就不够。
<!-- mahout推荐系统--><dependency><groupId>org.apache.mahout</groupId><artifactId>mahout-mr</artifactId><version>0.12.2</version></dependency>
导入依赖先。
创建记录表:
CREATE TABLE `user_article_operation` (`id` BIGINT(20) NOT NULL AUTO_INCREMENT,`create_time` DATETIME NOT NULL COMMENT '操作时间,我们默认抓取比较新的数据来进行统计',`userid` BIGINT(20) NULL DEFAULT NULL,`article_id` BIGINT(20) NULL DEFAULT NULL,`operation` INT(11) NULL DEFAULT NULL COMMENT '0-点赞,1-收藏,2-fork(不同的类型,不同的评分)',PRIMARY KEY (`id`) USING BTREE,INDEX `key` (`userid`, `article_id`, `operation`) USING BTREE
)
COMMENT='用户对文章的操作表'
COLLATE='utf8_unicode_ci'
ENGINE=InnoDB
;
这里的话,我使用的是mybatis-plus创建对应的dao和mapper(这里会使用到比较复杂的sql,得手写)
@Data
@TableName("user_article_operation")
public class BlogRe {@TableId(value = "id",type = IdType.AUTO)private Long id;private Long userid;private Long articleId;private Integer operation;private Date createTime;@TableField(exist = false)private Integer value;}对应的xml文件是:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.huterox.whitehole.whiteholeblog.dao.BlogReDao"><!--sql--><select id="getAllUserPreference" resultType="com.huterox.whitehole.whiteholeblog.entity.surface.blogRe.BlogRe">SELECTuserid,article_id,SUM(CASE operation_typeWHEN 0 THEN 2WHEN 1 THEN 3WHEN 2 THEN 5else 0 END) AS "value"FROMuser_article_operationGROUP BY user_id,article_idlimit 100</select></mapper>
调用
基本的环境准备好了,我们就得调用了。
这里的我的逻辑是,当用户登录了有数据,那么我就直接推荐,如果没有那就继续走默认,也就是按照热度进行推荐。
在我的项目里面最终是定位到了这里:
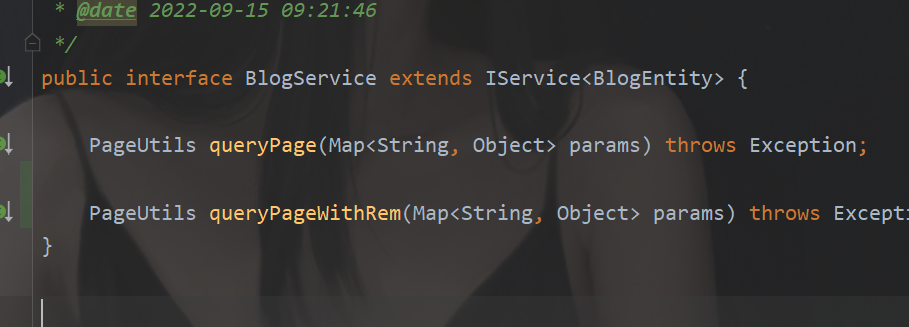
具体的推荐逻辑是这里:
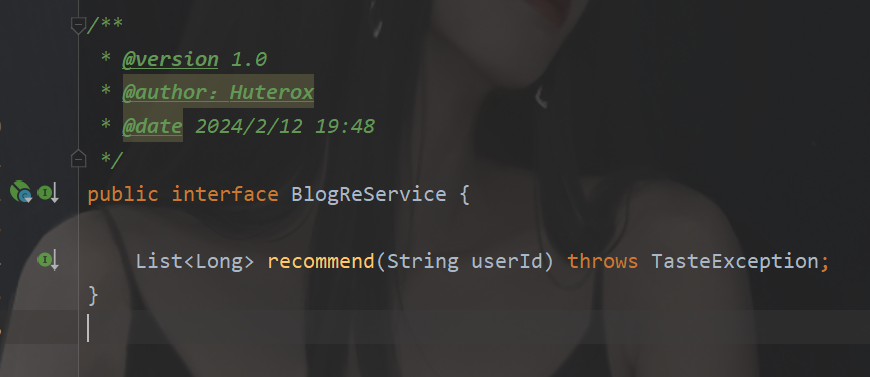
所以我们在这里重点关注这里的实现就可以:
@Service
public class BlogReServiceImpl implements BlogReService {@AutowiredBlogReDao blogReDao;@AutowiredBlogReUserIdDao blogReUserIdDao;@Overridepublic List<Long> recommend(String userId) throws TasteException {//注意这里我们限制了100个,我们从100个数据里面去拿到,然后做推荐List<BlogRe> userList = blogReDao.getAllUserPreference();//创建数据模型DataModel dataModel = this.createDataModel(userList);//获取用户相似程度UserSimilarity similarity = new UncenteredCosineSimilarity(dataModel);//获取用户邻居UserNeighborhood userNeighborhood = new NearestNUserNeighborhood(2, similarity, dataModel);//构建推荐器Recommender recommender = new GenericUserBasedRecommender(dataModel, userNeighborhood, similarity);//推荐2个BlogReUserId userMap = blogReUserIdDao.selectOne(new QueryWrapper<BlogReUserId>().eq("userid", userId));List<RecommendedItem> recommendedItems = recommender.recommend(userMap.getId(), 2);List<Long> itemIds = recommendedItems.stream().map(RecommendedItem::getItemID).collect(Collectors.toList());return itemIds;}private DataModel createDataModel(List<BlogRe> userArticleOperations) {FastByIDMap<PreferenceArray> fastByIdMap = new FastByIDMap<>();Map<Long, List<BlogRe>> map = userArticleOperations.stream().collect(Collectors.groupingBy(BlogRe::getUserid));Collection<List<BlogRe>> list = map.values();for (List<BlogRe> userPreferences : list) {GenericPreference[] array = new GenericPreference[userPreferences.size()];for (int i = 0; i < userPreferences.size(); i++) {BlogRe userPreference = userPreferences.get(i);GenericPreference item = new GenericPreference(userPreference.getUserid(), userPreference.getArticleId(), userPreference.getValue());array[i] = item;}fastByIdMap.put(array[0].getUserID(), new GenericUserPreferenceArray(Arrays.asList(array)));}return new GenericDataModel(fastByIdMap);}}
这里写得很清楚了,当然具体的算法原理也不难,可以去翻翻我往期的博文。有Python手撸的版本。加上几个数据源设配器也能直接用了。核心算法原理很简单,不会就问GPT,只要数学没啥问题就懂,不懂,那就直接调用API也挺好。
这里注意的是:
这里要求用户ID是Long类型。
所以如果你和我的项目一样用户ID用的不是雪花这种算法,而是UUID,那么你得搞个中间的转换表。我这里没辙,所以只能强行加一个转换表:
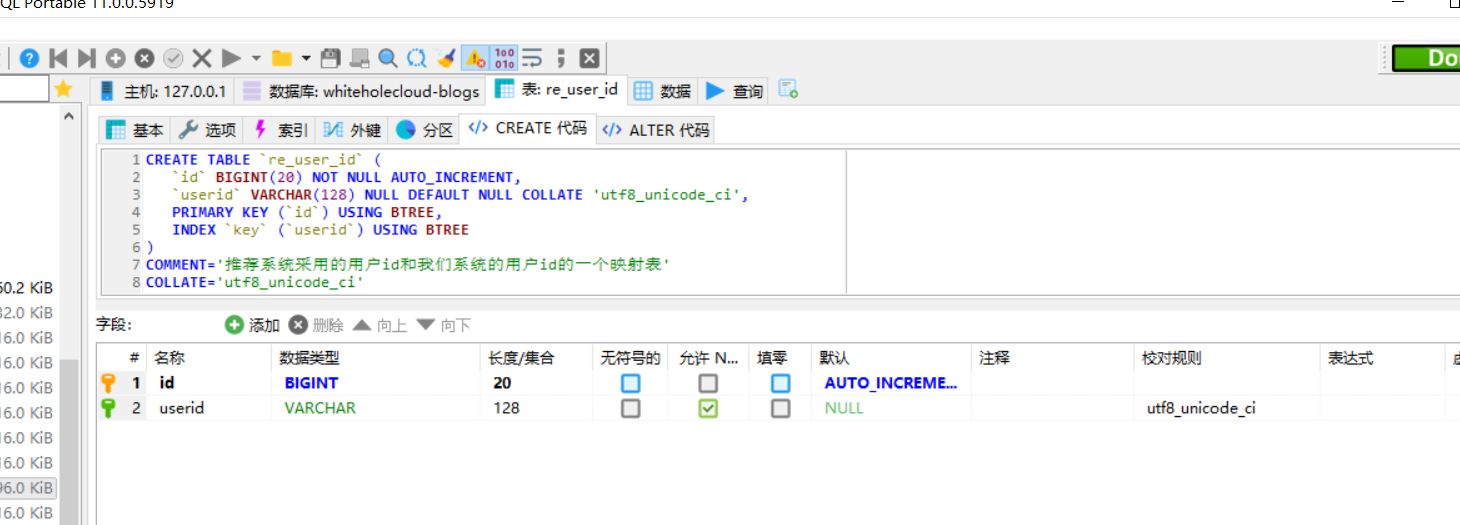
当然我们这里还得记录操作。
//记录一下操作BlogReUserId userMap = blogReUserIdDao.selectOne(new QueryWrapper<BlogReUserId>().eq("userid", userid));if(userMap==null){BlogReUserId blogReUserId = new BlogReUserId();blogReUserId.setUserid(userid);blogReUserIdDao.insert(blogReUserId);}BlogRe blogRe = new BlogRe();assert userMap != null;blogRe.setUserid(userMap.getId());blogRe.setArticleId(blogid);blogRe.setCreateTime(new Date());blogRe.setOperation(0);blogReDao.insert(blogRe);
这里看实际情况,反正我这就先这样操作了。
混合
之后的话就是做混合了
在我这里是直接这样了:
@Overridepublic PageUtils queryPageWithRem(Map<String, Object> params) throws Exception {//这里是携带推荐系统的PageUtils pageUtils = this.queryPage(params);if(params.get("rem").equals("1")){//触发满足使用推荐系统条件使用推荐系统if (params.get("userid")!=null){List<Long> blogIds = blogReService.recommend((String) params.get("userid"));List<BlogEntity> blogEntityList = this.list(new QueryWrapper<BlogEntity>().in("blogid", blogIds));//这个是按照热度推荐的List<BlogEntity> list = (List<BlogEntity>) pageUtils.getList();//将两者混合list.addAll(blogEntityList);pageUtils.setPageSize(list.size());pageUtils.setTotalCount(list.size());}}return pageUtils;}
数据不够的话可能推荐的数据是空的,所以得混合。之后缓存的话,是我直接在这个项目当中使用了SpringCache。当然最近搞项目的时候,我自己直接基于SpringAop写了个缓存注解实现,项目要求比较灵活,直接手写一个快。
总结
新年快乐~