作者:来自 Elastic Jessica Taylor, Aditya Tripathi
人工智能工具无处不在,其原因并不神秘。 他们可以执行各种各样的任务并找到许多日常问题的解决方案。 但这些应用程序的好坏取决于它们的人工智能搜索算法。
简单来说,人工智能搜索算法是人工智能工具用来找到特定问题的最佳解决方案的决策公式。 搜索算法可能会在速度、相关性或其他加权因素之间进行权衡。 它考虑了查询的约束和目标,并返回了它计算出的最佳解决方案。
在这篇文章中,我们将介绍:
- AI 搜索算法的重要性和应用
- 人工智能搜索算法的要素
- 不同类型的人工智能搜索算法
- AI 搜索算法用例
- 使用人工智能搜索算法时的挑战和限制
读完本文后,你将清楚地了解它们是什么以及如何在 AI 工具中使用它们。
人工智能中的搜索算法是什么?
人工智能搜索算法是一种通过评估索引数据和文档来理解自然语言查询并查找相关结果的方法。 它通过探索一组潜在的解决方案来实现这一点,以便找到针对所给出的查询的最佳答案或解决方案。
想象一下,你正在使用人工智能构建一个国际象棋应用程序,该应用程序可以预测下一步的最佳走法。 为了确定最佳动作,你的人工智能搜索算法必须评估不同的选项,以决定哪一个最好。 这意味着系统地评估每个棋子的位置,评估每种可能的走法组合,并计算你您带来最佳获胜机会的策略。
AI 搜索算法的重要性和应用
人工智能搜索算法在众多领域发挥着至关重要的作用。 其范围从计算机科学问题解决到复杂的物流决策。 它们的多功能性使它们对于应对各种挑战和解决重要问题不可或缺。
例如,NASA 能够使用 Elastic® 中的 AI 搜索算法分析来自火星任务的漫游器数据。 这使他们能够比手动分析这些数据更快地解锁关键见解并应对复杂的挑战。 在医疗保健领域,人工智能搜索算法被用来协助医疗诊断、治疗计划和药物发现。 这将带来更好的诊断准确性、更有效的治疗计划以及新疗法的开发。
这些例子强调了重要性和潜力,但这些算法的应用远远超出了这些用例。 金融、制造、法律服务等各个领域已经受益于这种处理大量数据并做出明智决策的新能力。 随着人工智能算法的不断发展,它将在各个行业发挥更加突出的作用,并对我们周围的世界产生巨大影响。
人工智能搜索算法的要素
每个人工智能搜索算法都可以分为四个要素:状态(states)、动作(actions)、目标(goals)和路径成本(path costs)。 这种元素框架是算法如何导航复杂问题空间以找到最佳解决方案的方式。
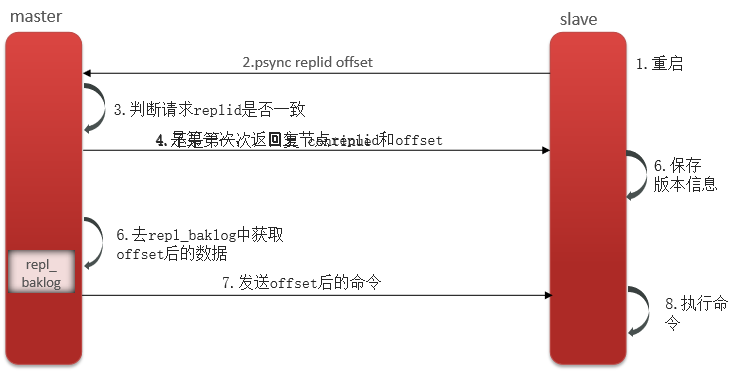
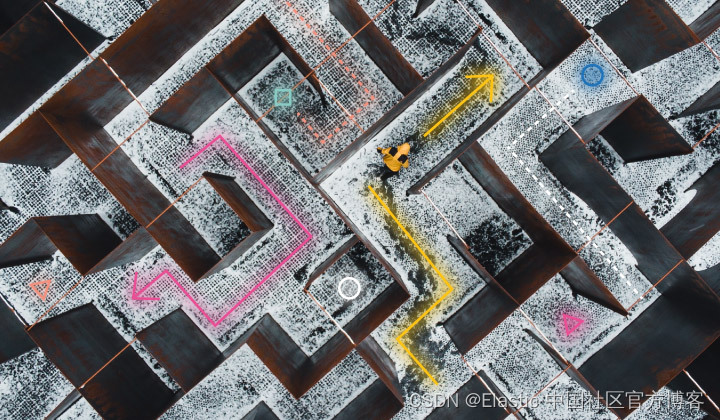
状态是特定时间点问题的快照。 它们封装了当时问题的所有相关信息,因此算法可以评估当前情况。 把它想象成一个迷宫 —— 每个转弯都代表迷宫中不同的 “状态”。 因此,通过查看状态,你就知道人工智能在算法中的位置。
动作是状态之间可能的转换。 继续使用迷宫的比喻,这些动作是你可以选择的可用方向。 通过组合这些操作,你可以确定穿过迷宫的不同潜在路径。
目标是搜索过程的最终目标。 在搜索中,这个目标将是初始查询的最佳且最相关的答案。 这为算法提供了明确的方向,因此其工作重点是寻找最佳结果。 在迷宫示例中,查询 “找到逃离迷宫的最佳路线” 将是目标。
路径成本是回答查询的路径中每个步骤或动作的精确度和召回率之间的权衡。 该成本代表进行每个特定动作所需的努力或资源。 然后,算法可以使用该成本来优先考虑高效且资源经济的路线。
AI 搜索算法的类型
自然语言处理 (NLP) 算法
NLP 算法是搜索的重要组成部分,因为它们弥合了人类交流和机器理解之间的差距。 这使得搜索人工智能能够理解所要求的内容,并提供与查询相关且上下文相关的结果。
使用 NLP,搜索结果将更加符合用户的意图,并且算法将能够通过理解更细微的请求来处理复杂的查询。 这是因为它可以识别情绪并理解上下文,并根据之前与用户的对话来个性化搜索体验。
词嵌入 - word embeddings
算法处理单词以查找相似性的方法之一是使用词嵌入,其中单词和资产表示为向量。 这是它分析文本和图像等非结构化数据并将其转换为数值的地方。
一个流行的例子是 Word2vec,这是一种从大量书面文本中学习词嵌入的算法。 然后,它分析周围的文本以确定含义并理解上下文。 另一个例子是 GloVe(Global Vectors for Word Representation - 单词表示的全局向量),它也被训练为通过根据语义相似性映射不同单词来建立不同单词之间的连接。
语言模型
还有一些语言模型可以分析大量数据,以便准确预测单词出现顺序的可能性。 或者更简单地说,它们是算法,使搜索人工智能不仅能够理解我们所说的内容,而且能够以与人类沟通方式相匹配的方式做出响应。
例如,BERT(来自 Transformers 的双向编码器表示)是一种流行的语言模型,能够理解复杂而细致的语言,然后可用于强大的语义搜索和问答。
近似最近邻(Aproximate nearest neighbors - ANN)
使用 kNN 查找最接近的匹配的另一种方法是查找足以满足你的特定需求的匹配。 这就是近似最近邻算法的优势所在。 这是因为 ANN 算法会查找与查询非常接近的数据,但不一定是最接近的数据。 因此,人工神经网络不会费力地分析每一个数据,这可能会耗费时间和资源,而是会满足于不太接近但相对而言仍然 “足够接近” 的东西。
这样做的好处是你可以创建更快、更高效的相似性搜索。 人工神经网络通过推断内容和数据之间的语义关系来实现这些 “足够接近” 的结果。
然而,要使这种方法有价值,你需要接受准确的权衡,因为它不能保证最接近的结果。 大多数时候,人工神经网络都是一个很好的解决方案,但如果你需要保证绝对准确性,这可能不是你的最佳选择。
无信息 (uninformed)或盲目的搜索算法
无信息搜索算法(也称为盲搜索算法)不知道有关搜索空间的信息。 他们系统地解决查询,没有指导或特定领域的知识。 他们完全依赖搜索空间的现有结构来寻找解决方案。
无信息搜索算法有多种不同类型,但最常见的三种是广度优先搜索 (breath-first search - BFS)、深度优先搜索 (depth-first search - DFS) 和统一成本搜索 (uniform cost search - UCS)。
知情(informed)或启发式搜索算法
知情搜索算法(也称为启发式搜索算法)是一种使用附加信息和特定领域知识来指导搜索的搜索类型。 与无信息的搜索不同,他们使用启发式方法,这是经验法则和估计,可以帮助他们确定路径的优先级并避免不必要的探索。
有几种不同类型的知情搜索算法,但最常见的是贪婪最佳优先搜索(best-first search)、A* 搜索和束搜索(beam search)。
AI 搜索算法的用例
正如我们已经提到的,人工智能搜索算法正在广泛的行业中用于完成各种任务。 这里只是一些现实世界的例子,它们产生了巨大的影响。
- 信息检索:NLP 搜索算法可以通过理解查询的上下文和语气来增强搜索结果,以检索更多有用的信息。
- 推荐:kNN 算法通常用于根据偏好和过去的行为推荐产品、电影或音乐。
- 语音识别:人工神经网络算法通常用于识别语音模式。 这在语音转文本和语言识别等方面非常有用。
- 医疗诊断:人工智能搜索算法可以帮助加快医疗诊断速度。 例如,它们可以接受海量医学图像数据集的训练,并使用图像识别来检测照片、X 射线、CT 扫描等中的异常情况。
- 寻路:无信息搜索算法可以帮助找到地图或网络上两点之间的最短路径。 例如,确定司机的最短送货路线。
AI 搜索算法的挑战和局限性
人工智能搜索算法可能通过高效的问题解决和决策而彻底改变了各个行业,但它们也带来了挑战和限制。 首先,所涉及的计算复杂性可能使它们的运行成本极其昂贵。 这是因为它们需要大量的处理、计算和内存资源来执行搜索。 在有限制的情况下,这限制了它们的有效性。
另一个问题是,知情搜索算法的好坏取决于它所使用的启发式算法。 如果启发式函数不准确,它可能会导致算法走上错误的道路并导致次优甚至不正确的解决方案。
此外,人工智能搜索算法通常被设计用来解决特定类型的问题,例如寻路和约束满足。 这对于某些任务很有用,但解决问题的范围仍然存在限制,特别是在解决更多样化的问题时。
解码人工智能搜索未来
人工智能搜索算法是解决各个领域复杂的现代问题的重要工具。 它们的多样性和多功能性使它们对于寻路、规划和机器学习等任务不可或缺。
尽管它们正在彻底改变机器人、医疗保健和金融等行业,但仍然存在巨大的潜力。 当前的局限性和挑战也是未来进步的机遇。 随着研究不断提高性能,人工智能搜索算法将继续在解决现实问题和改变技术面貌方面发挥日益突出的作用。
接下来你应该做什么
只要你准备好...我们可以通过以下四种方式帮助你从业务数据中获取见解:
- 开始免费试用,看看 Elastic 如何帮助你的业务。
- 浏览我们的解决方案,了解 Elasticsearch 平台的工作原理以及我们的解决方案如何满足你的需求。
- 了解如何在企业中提供生成式人工智能。
- 通过电子邮件、LinkedIn、Twitter 或 Facebook 与你认识的愿意阅读本文的人分享本文。
更多关于人工智能的文章,请参阅 “NLP - 自然语言处理,向量搜索及人工智能” 专栏。
原文:Understanding AI search algorithms | Elastic Blog
![位运算03 不用加号的加法[C++]](https://img-blog.csdnimg.cn/direct/b492aacc5cd5476fa6db2ca19f334f07.png)