IEEE Transactions on Affective Computing上的一篇文章,做微表情识别,阅读完做个笔记。本文讨论了Data Leakage对模型准确度评估的影响,及如何融合多个微表情数据集,从而提升模型的准确度。工作量非常饱满,很认真,并且开源了,赞一个。

摘要:
data leakage
数据泄漏指的是在模型训练过程中,模型学到了在测试集中不应该知道的信息,从而导致在测试时性能过于乐观或不准确。这可能是因为在训练集中包含了来自测试集的信息,导致模型在真正面对未见过的数据时无法准确泛化。
fragmented
碎片化指的是评估协议或方法的分散、零散,导致评估过程不一致或无法比较不同模型的性能。这可能包括使用不同的标准、数据集划分方式或评估指标,使得研究结果难以复现或比较,降低了研究的可靠性。
To this end,we go through common pitfalls,propose a new standardized evaluation protocol using facial action units withover 2000 micro-expression samples,and provide an open source library that implements the evaluation protocols in a standardized manner.
为了解决这个问题,作者梳理了常见的陷阱,提出了一个新的标准化评估协议,使用了超过2000个微表情样本的面部动作单元,并提供了一个实现标准化评估协议的开源库。
1.简介
However,recently,we have spotted aworrying trend with extremely high yet unreliable perfor-mances reaching close to perfect performance and potentialissues during evaluation when analyzing available sourcecode.
然而,最近我们注意到了一个令人担忧的趋势,即出现了极高但不可靠的性能,接近完美表现,并在分析可用源代码时出现了潜在的评估问题。
Data leakage refers to using information from the testing data during the training procedure,giving an overly optimisticevaluation result.
数据泄露是指在训练过程中利用测试数据中的信息,给出过于乐观的评估结果。
The concern with data leakage is that it creates a misleading understanding of the capabilities ofmodels.
对数据泄露的担忧在于,它造成了对模型能力的误导性理解。
The use of different datasets with varying evaluation strategies and different numberof emotions,subjects and samples creates more confusion and difficulties.
使用不同的数据集、不同的评估策略以及不同数量的情感、受试者和样本,会导致更多的混淆和困难。
To act towards more united protocols,we propose a new protocol,CD6ME,that consists of six ME datasets with over 2000 samples.
为了实现更加统一的协议,我们提出了一个新的协议CD6ME,该协议由6个超过2000个样本的ME数据集组成。
By combining the datasets and using AUs,problems with the inconsistency of the labels can be largely alleviated,as the datasets are annotated by standardized FACS(facial actioncoding system)[38]certified coders.
通过组合数据集和使用AUs,可以在很大程度上缓解标签不一致的问题,因为数据集由标准化的FACS(面部动作编码系统) [ 38 ]认证的编码员进行注释。
MEB imple-ments tedious data loading routines,standardized trainingpipelines and multiple dif
ferent models from the ME lit-erature.
MEB 实现了繁琐的数据加载例程、标准化的训练流程以及来自微表情文献的多种不同模型。
本文的贡献:
Common pitfalls found in the ME literature areshowcased and discussed.
展示和讨论了ME文献中发现的常见缺陷。
A new composite cross-dataset action unit classifica-tion protocol for ME analysis is proposed.
提出了一种新的用于ME分析的复合跨数据集动作单元分类协议。
Comprehensive analysis is performed that comparesaction units and emotions in MEs.
综合分析比较了MEs中的动作单元和情感。
2.基础内容
The typical framework of a micro-expressionanalysis system consists of two phases:spotting and recog-nition.
典型的微表情分析系统框架包括两个阶段:定位 和 识别。
In the spotting phase,unsegmented videos are givenas inputs and the task is to spot a temporal sequence duringwhich an ME is occurring.
在定位阶段,给定未分割的视频作为输入,任务是识别发生ME的时间序列。
In the recognition phase,the pre-segmented video clip is classified to an emotioncategory such as happiness,sadness,surprise,etc.
在识别阶段,将预分割后的视频剪辑分类为快乐、悲伤、惊讶等情感类别。
The FACS(facial action coding system)[38]is a taxonomy offine-grained facial configurations.
FACS(面部动作编码系统) [ 38 ]是一个细粒度面部结构的分类法。
AUs(action units)
AUs(动作单元) 作为对面部肌肉运动进行编码的基本单元。

AUs can b econsidered as sign judgement of the face[49],as opposed to emotional labels that attempt to convey the meaning.Due to this difference,automatic AU systems can be applied to a wider set of applications such as pain detection and analysis of nonaffective facial expressions[49].
AUs可被视为对面部的标志性判断[49],与试图传达情感含义的情感标签形成对比。由于这种差异,自动AU系统可应用于更广泛的应用,如疼痛检测和非情感面部表情分析[49]。
Each AU can be given five different intensity levels(and one forneutral)denoted by an uppercase letter from A to E,whereA is a trace and E is maximum[38].
每个AU可以具有五个不同的强度级别(以及一个中性级别),用大写字母A到E表示,其中A是微弱的迹象,E是最大强度[38]。
Most datasets usea different set of emotion inducing videos.
大多数数据集使用了不同的情绪诱发视频集。数据集之间差异也较大

Compared to the onset and apex frames,the offset frameis more ambiguous as faces do not necessarily fully return to a relaxed state.
相对于起始框架和顶点框架,偏移框架更加模糊,因为面孔并不一定完全回到放松状态,这是一个难点。
Different annotation strategies create a discrepancy between the datasets and makes comparison between the datasets inconsistent.
不同的标注策略会造成数据集之间的差异,使得数据集之间的比较不一致。
这个是衡量两个数据集类别之间差异的函数

The measure is between zero and one,where one means complete agreement.
该测度介于0和1之间,其中1表示完全一致。
Objective classes[39]based on action units have been suggested to avoid this problem.More recently,directly using action units[43]have also been suggested.
基于动作单元的目标类[ 39 ]被提出以避免这一问题。最近,直接使用动作单元[ 43 ]也被提出。
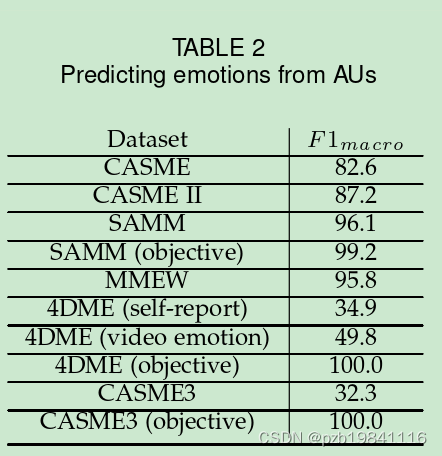
However,a large meta study of facial expressions[10]suggests that there is no one-to-one mapping between facial movements and emotions.
然而,一项关于面部表情的大型元研究[ 10 ]表明,面部动作与情绪之间并不存在一一对应的映射关系。
This supports the findings of the meta-study[10]and that there are no one-to-one mappings between AUs and self-reported emotions for MEs.
这支持了元研究[ 10 ]的发现,即对于情绪智力而言,AU与自我报告的情绪之间不存在一对一的映射关系。
These inconsistencies makes training on emotions difficult,especially with small datasets.
这些不一致性使得对情绪的训练变得困难,特别是在小数据集的情况下。
This means that we cannot expect models to perform with an accuracy of 100% as the ground-truth labels contain noise.
意味着,由于真实标签包含噪声,我们不能期望模型以100 %的准确率运行。
3.微表情识别的评估问题
These include data leakage,imprecise use ofthe F1-Score and evaluation strategies.
这些问题包括数据泄露、F1 - Score的使用不精确以及评价策略等。
In data leakage,information from the testing data leaks to the training data that is used to train the model,leading to overly optimistic evaluation.
在数据泄露中,测试数据中的信息泄露到用于训练模型的训练数据中,导致评估结果过于乐观。

early stopping
在机器学习中,早停(Early Stopping)是一种用于防止过拟合的技术。它通过在模型在验证数据集上性能不再提高时停止训练,以防止模型在训练数据上学习到噪声而失去泛化能力。通常,训练过程中监测验证集上的性能指标,一旦性能不再提高或开始下降,就停止训练。
Using information from the test data during training can lead to a large positive bias,but the positive bias is misleading and not representative of the generalizable performance,especially when a fold isjust a single subject.
在训练过程中使用测试数据的信息可能导致较大的正向偏差,但这种正向偏差是误导性的,不代表可泛化的性能,特别是当一个折叠只是一个单独的主体时。
The experiments show that using early stopping with test data can create a large positive bias,while using the validation data shows barely no impact.
实验表明,使用测试数据提前停止会产生较大的正偏差,而使用验证数据则几乎没有影响。
To avoid the above issue,the pre-training should be done using additional data not part of the evaluation data or the pre-training should be done inside the individual folds.
为避免上述问题,预训练应该使用不包含在评估数据中的额外数据,或者预训练应该在各个交叉验证折叠内完成。
If the evaluation is done with the same dataset that the generative model was trained on,a data leak may occur.
如果使用与生成模型训练相同的数据集进行评估,可能会出现数据泄露的情况。
A dummy model that always predicts the class with the most common occurrence could achieve good performance with accuracy.Use of F1-Score is a standard practice in the ME recognition task[40].
一个始终预测具有最常见出现的类别的虚拟模型可能会在准确率上取得良好的性能。在微表情识别任务中,使用F1-Score是一种标准做法[40]。
F1-Score 的计算方式。

The F1-Score can be generalized to a multi-class setting by a few different strategies.
F1-Score可以通过几种不同的策略推广到多类别设置。
样本不均衡是的计算方法

One should be aware that when computing the F1-Score as noted by Opitz and Burst[35],the averaging can be done in two ways,as shown in Equation 4 or by first aggregating over the classes to compute precision and recalland using Equation 2 to compute the F1-Score.
值得注意的是,在计算Opitz和Burst [ 35 ]所指出的F1 - Score时,可以通过两种方式进行平均,如公式4所示,或者通过先聚合类来计算精确率和召回率,以及使用公式2来计算F1 - Score。
A common pitfall is to compute the F1-Score in each foldseparately and aggregate the results together.
一个常见的陷阱是在每个折叠中单独计算F1-Score,然后将结果聚合在一起。
As can be seen,both micro-and weighted F1give a positive bias as they do not take the class imbalanceinto account.While averaging over the folds leads to asignificant negative bias.
如图所示,微观和加权F1都产生了正偏差,因为它们没有考虑类别不平衡。而在折叠上进行平均导致了显著的负偏差。

They split the validation strategies to three categories 1)person dependent evaluation(PDE),2)person independent evaluation(PIE)and 3)cross domain evaluation(CDE).
他们将验证策略分为三类:1 )个体依赖性评价( PDE ),2 )个体独立性评价( PIE )和3 )跨领域评价( CDE )。三种策略依次从简单到难。
In addition to different evaluation strategies,the number of samples and the number of used emotions may be differ-ent across articles.
除了不同的评价策略之外,不同文章的样本数量和使用的情感数量也可能不同。
4.CD6ME
However,dif-ferent works use changing subsets with different numberof emotions and samples.Add this to the common pitfalls discussed in the previous section and the comparison of different works is extremely difficult.
不同的研究使用不同数量情感和样本的不同子集。结合前面讨论的常见问题,不同研究的比较变得极其困难。
The use of AUs allows us to combine the datasets as the annotation of AUs is standardized by hav-ing the annotators be qualified FACS coders.
使用AUs允许我们结合这些数据集,因为AUs的注释是由合格的FACS编码器标准化的。
The trainingand testing is repeated for n D times,where n D refers to the number of datasets.
训练和测试重复n D次,其中n D为数据集的个数。
In AU detection an unsegmented video clip is given with frame level labels.The task is to predict a binary multi-label whether an AU exists for each frame separately.
在AU检测中,一个未分割的视频片段被赋予帧级标签。其任务是预测一个二元多标签是否对每一帧单独存在一个AU。
In AU classification a pre-segmented video clip is given with a single binary multi-label[78].The task is to predict whether an AU exists for the whole clip.
在AU分类中,一个预分割的视频片段被赋予一个单一的二进制多标签[ 78 ]。任务是预测整个剪辑中是否存在一个AU。
5.实验
Optical strain
光学应变(Optical Strain)是指在图像中检测物体表面的形变和变化的一种方法。在计算机视觉中,特别是在分析运动或变形时,光学应变常用于表示物体或场景中的局部形状变化。
As mentioned previously,data leakage and evaluation issues are largely affected,which made reproduc-ing results difficult.
如前所述,数据泄露和评估问题在很大程度上受到影响,导致结果难以再现。
By combining the above together in this paper,we are able to evaluate methods in a more realistic setting,while providing increased perfor-mance by using additional data.
通过在本文中将上述内容结合在一起,我们能够在更现实的情境中评估方法,同时通过使用额外的数据提高性能。
Multiple AUs may occurat different times,using only the apex may therefore miss one or more AUs.
不同的AUs可能在不同的时间发生,仅使用顶点可能会错过一个或多个AUs。
The resultsin Table 6 show promising results for the use of RGB asinput when using large composite data.
在使用大型组合数据时,使用RGB作为输入的效果令人鼓舞。
As shown by our work,significant gains can be obtained without touching the models.
可以在不改变模型的情况下获得显著的增益。
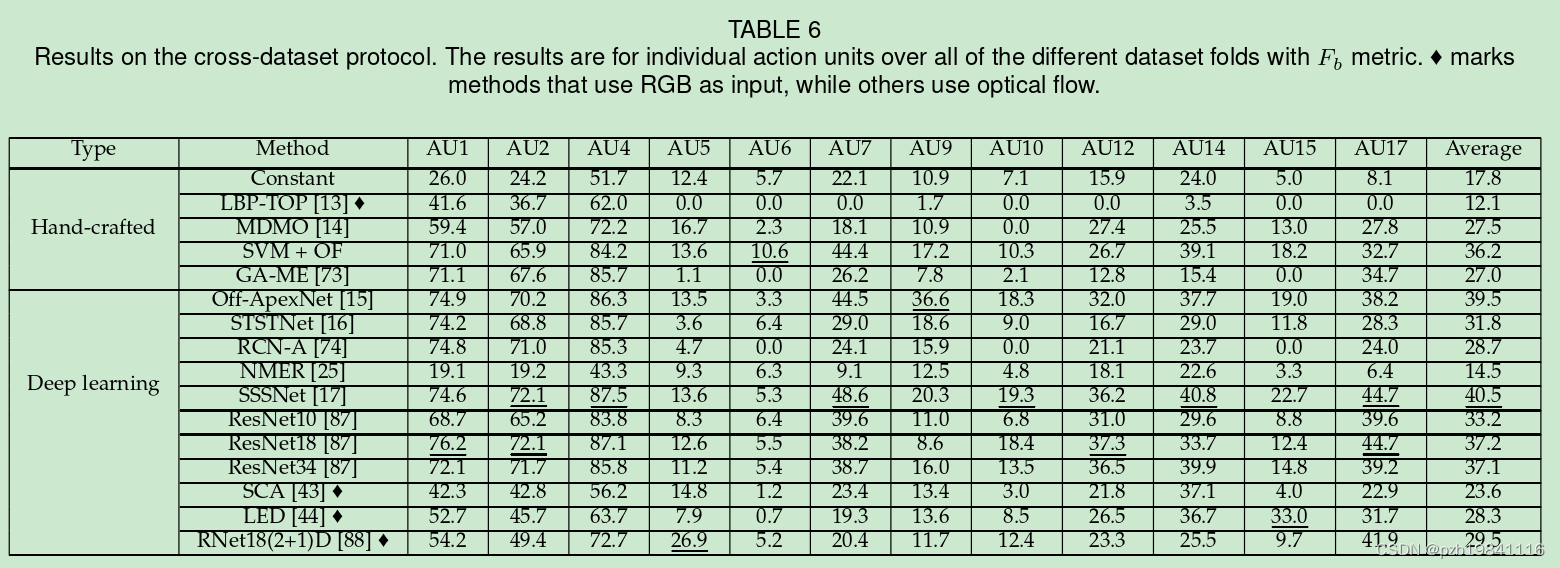
Although the cross-dataset is a more realis-tic setting,the data is still from a laboratory setting,which limits the applicability for in-the-wild scenarios.
尽管跨数据集是一个更真实的设置,但数据仍来自实验室环境,这限制了在野外场景中的适用性。
Another limitation is the need for data which requires capturing spontaneous subtle facial-expressions from human subjectsand accurate labor intensive annotations.
另一个限制是需要捕捉人类主体的自发微妙面部表情并进行准确且繁重的注释。
6.结论
we point out common pitfalls such as data leakage and fragmented use of evaluation protocols in micro-expression recognition.
我们指出了微表情识别中常见的数据泄露和评估协议碎片化使用等缺陷。
We propose a new benchmark,CD6ME,that uses a cross-dataset protocol for generalized evaluation.
我们提出了一个新的基准CD6ME,它使用一个跨数据集协议来进行广义评估。
Action units are used instead ofemotional classes for a more objective and consistent label.
使用动作单元代替情感类,以获得更加客观和一致的标签。
A micro-expression analysis library,MEB,with the implementation of data loading routines,training loops and several commonly used micro-expression models,is introduced and openly shared.
引入了一个微表情分析库MEB,其中包括数据加载例程、训练循环以及一些常用的微表情模型的实现,并进行了开放共享。

![[VNCTF2024]-PWN:preinit解析(逆向花指令,绕过strcmp,函数修改,机器码)](https://img-blog.csdnimg.cn/direct/a25d17ccb3bd424f8e88d47e6ea67e8d.png)