1 简述
并发是指在同一时间段内,能够处理多个任务的能力。为了提升应用的响应速度与帧率,以及防止耗时任务对主线程的干扰,OpenHarmony系统提供了异步并发和多线程并发两种处理策略,ArkTS支持异步并发和多线程并发。并发能力在多种场景中都有应用,其中包括单次I/O任务、CPU密集型任务、I/O密集型任务和同步任务等。
-
异步并发:是指异步代码在执行到一定程度后会被暂停,以便在未来某个时间点继续执行,这种情况下,同一时间只有一段代码在执行。
Promise和async/await提供异步并发能力,适用于单次I/O任务的开发场景。详细请参见异步并发概述。 -
多线程并发:允许在同一时间段内同时执行多段代码。在主线程继续响应用户操作和更新UI的同时,后台也能执行耗时操作,从而避免应用出现卡顿。
TaskPool和Worker提供多线程并发能力,适用于CPU密集型任务、I/O密集型任务和同步任务等并发场景。详细请参见【鸿蒙开发】第十三章 Stage模型应用组件-线程和进程。
2 异步并发
Promise和async/await提供异步并发能力,是标准的JS异步语法。异步代码会被挂起并在之后继续执行,同一时间只有一段代码执行,适用于单次I/O任务的场景开发,例如一次网络请求、一次文件读写等操作。(异步语法是一种编程语言的特性,允许程序在执行某些操作时不必等待其完成,而是可以继续执行其他操作。)
2.1 Promise
Promise是一种用于处理异步操作的对象,可以将异步操作转换为类似于同步操作的风格,以方便代码编写和维护。Promise提供了一个状态机制来管理异步操作的不同阶段,并提供了一些方法来注册回调函数以处理异步操作的成功或失败的结果。
Promise有三种状态:
- pending(进行中)
- fulfilled(已完成)
- rejected(已拒绝)。
Promise对象创建后处于pending状态,并在异步操作完成后转换为fulfilled或rejected状态。
通过传入一个executor(resolve: Function, reject: Function)函数,参数resolve和reject分别表示异步操作成功和失败时的回调函数,构造一个Promise对象
const promise: Promise<number> = new Promise((resolve: Function, reject: Function) => {// 拟了一个异步操作,1000ms后执行setTimeout(() => {const randomNumber: number = Math.random();if (randomNumber > 0.5) {// 回调并将随机数作为参数传递resolve(randomNumber);} else {// 回调并传递一个错误对象作为参数reject(new Error('Random number is too small'));}}, 1000);})// `Promise`对象创建后,可以使用`then`方法和`catch`方法指定`fulfilled`状态和`rejected`状态的回调函数。promise// `then`方法可接受两个参数,一个处理`fulfilled`状态的函数,另一个处理`rejected`状态的函数。// 只传一个参数则表示状态改变就执行,不区分状态结果。.then((result: number) => {console.info(`Random number is ${result}`);})// 使用`catch`方法注册一个回调函数,用于处理“失败”的结果,即捕获`Promise`的状态改变为`rejected`状态或操作失败抛出的异常.catch((error: BusinessError) => {console.error(error.message);});2.2 async/await
async/await是一种用于处理异步操作的Promise语法糖,使得编写异步代码变得更加简单和易读。通过使用async关键字声明一个函数为异步函数,并使用await关键字等待Promise的解析(完成或拒绝),以同步的方式编写异步操作的代码。
async函数是一个返回Promise对象的函数,用于表示一个异步操作。在async函数内部,可以使用await关键字等待一个Promise对象的解析,并返回其解析值。如果一个async函数抛出异常,那么该函数返回的Promise对象将被拒绝,并且异常信息会被传递给Promise对象的onRejected()方法。
async function myAsyncFunction(): Promise<void> {// 使用`try/catch`块来捕获异步操作中的异常try {const result: string = await new Promise((resolve: Function) => {setTimeout(() => {resolve('Hello, world!');}, 3000);});// 等待3秒钟后,返回result。输出: Hello, world!console.info(result);} catch (e) {console.error(`Get exception: ${e}`);}
}myAsyncFunction();在上述示例代码中,使用了await关键字来等待Promise对象resolve的结果,返回到result中,然后输出。其中代码块使用try/catch块来捕获异步操作中的异常。
2.3 单次I/O任务 (Promise和async/await)
Promise和async/await提供异步并发能力,适用于单次I/O任务的场景开发
下面我们看看实现单次I/O任务逻辑。
// 采用异步能力调用单次I/O任务。
async function testFunc(): Promise<void> {let context = getContext() as common.UIAbilityContext;// 应用文件路径let filePath: string = context.filesDir + "/test.txt";let file: fs.File = await fs.open(filePath, fs.OpenMode.READ_WRITE | fs.OpenMode.CREATE);// 调用上面实现的异步write方法,写入write('Hello World!', file).then(() => {console.info('Succeeded in writing data.');}).catch((err: BusinessError) => {console.error(`Failed to write data. Code is ${err.code}, message is ${err.message}`);})fs.close(file);
}testFunc();
3 多线程并发
并发模型是用来实现不同应用场景中并发任务的编程模型,常见的并发模型分为基于内存共享的并发模型和基于消息通信的并发模型。
Actor并发模型作为基于消息通信并发模型的典型代表,不需要开发者去面对锁带来的一系列复杂偶发的问题,同时并发度也相对较高,因此得到了广泛的支持和使用。
当前ArkTS提供了TaskPool和Worker两种并发能力,TaskPool和Worker都基于Actor并发模型实现。
下面我们先来了解下Actor并发相关知识:
3.1 Actor
内存共享并发模型:指多线程同时执行复数任务,这些线程依赖同一内存并且都有权限访问,线程访问内存前需要抢占并锁定内存的使用权,没有抢占到内存的线程需要等待其他线程释放使用权再执行。
Actor并发模型:每一个线程都是一个独立Actor,每个Actor有自己独立的内存,Actor之间通过消息传递机制触发对方Actor的行为,不同Actor之间不能直接访问对方的内存空间。
Actor并发模型对比内存共享并发模型的优势在于不同线程间内存隔离,不会产生不同线程竞争同一内存资源的问题。开发者不需要考虑对内存上锁导致的一系列功能、性能问题,提升了开发效率。
由于Actor并发模型线程之间不共享内存,需要通过线程间通信机制传输并发任务和任务结果。
本文以经典的生产者消费者问题为例,对比呈现这两种模型在解决具体问题时的差异。
3.1.1 内存共享模型
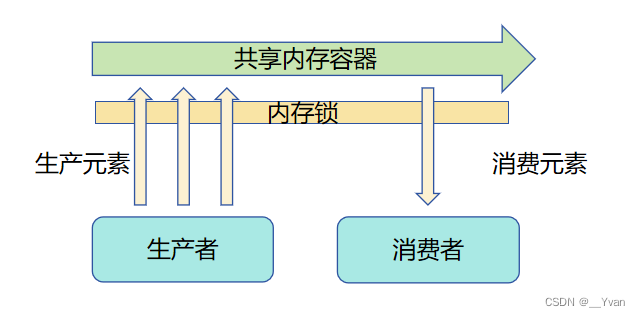
为了避免不同生产者或消费者同时访问一块共享内存的容器时产生的脏读,脏写现象,同一时间只能有一个生产者或消费者访问该容器,也就是不同生产者和消费者争夺使用容器的锁。当一个角色获取锁之后其他角色需要等待该角色释放锁之后才能重新尝试获取锁以访问该容器。
BufferQueue {Queue queueMutex mutexadd(value) {// 尝试获取锁if (mutex.lock()) {queue.push(value)mutex.unlock()}}take() {// 尝试获取锁if (mutex.lock()) {if (queue.empty()) {return null}let res = queue.pop(value)mutex.unlock()return res}}
}// 构造一段全局共享的内存
let g_bufferQueue = new BufferQueue()Producer {run() {let value = random()// 跨线程访问bufferQueue对象g_bufferQueue.add(value)}
}Consumer {run() {// 跨线程访问bufferQueue对象let res = g_bufferQueue.take()if (res != null) {// 添加消费逻辑}}
}Main() {let consumer = new Consumer()let producer = new Producer()// 多线程执行生产任务for 0 in 10 :let thread = new Thread()thread.run(producer.run())consumer.run()
}3.1.2 Actor模型
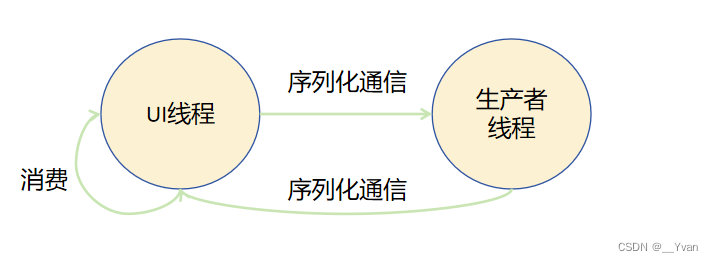
Actor模型不同角色之间并不共享内存,生产者线程和UI线程都有自己独占的内存。生产者生产出结果后通过序列化通信将结果发送给UI线程,UI线程消费结果后再发送新的生产任务给生产者线程。
import taskpool from '@ohos.taskpool';
// 跨线程并发任务
@Concurrent
async function produce(): Promise<number>{// 添加生产相关逻辑console.log("producing...");return Math.random();
}class Consumer {public consume(value : number) {// 添加消费相关逻辑console.log("consuming value: " + value);}
}@Entry
@Component
struct Index {@State message: string = 'Hello World'build() {Row() {Column() {Text(this.message).fontSize(50).fontWeight(FontWeight.Bold)Button() {Text("start")}.onClick(() => {let produceTask: taskpool.Task = new taskpool.Task(produce);let consumer: Consumer = new Consumer();for (let index: number = 0; index < 10; index++) {// 执行生产异步并发任务taskpool.execute(produceTask).then((res : number) => {consumer.consume(res);}).catch((e : Error) => {console.error(e.message);})}}).width('20%').height('20%')}.width('100%')}.height('100%')}
}3.2 TaskPool
任务池(TaskPool)作用是为应用程序提供一个多线程的运行环境,降低整体资源的消耗、提高系统的整体性能,且您无需关心线程实例的生命周期。
3.2.1 TaskPool运作机制
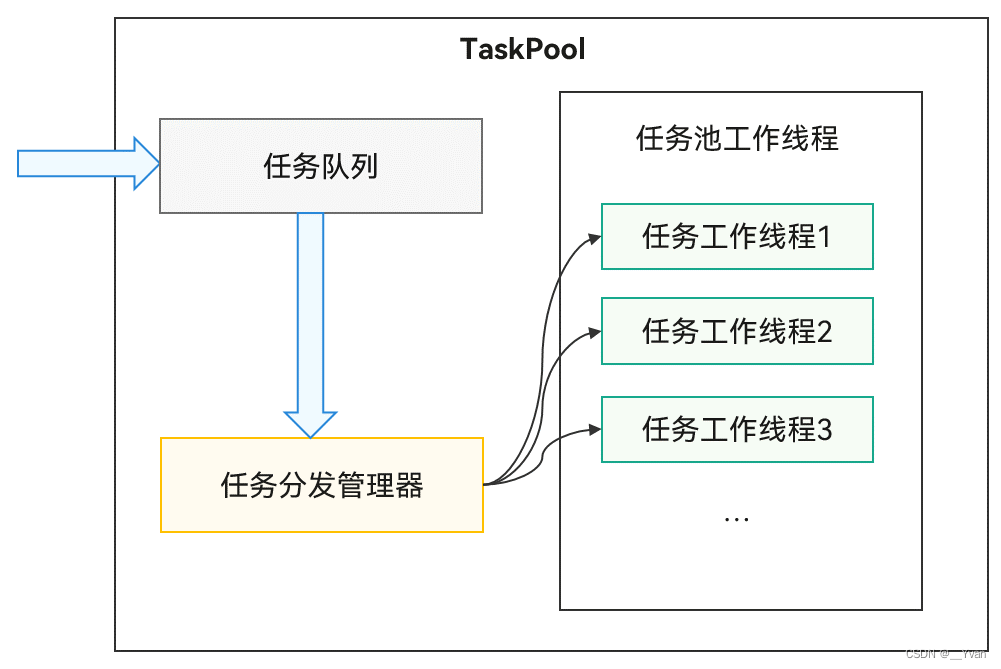
TaskPool支持开发者在主线程封装任务抛给任务队列,系统选择合适的工作线程,进行任务的分发及执行,再将结果返回给主线程。接口直观易用,支持任务的执行、取消,以及指定优先级的能力,同时通过系统统一线程管理,结合动态调度及负载均衡算法,可以节约系统资源。系统默认会启动一个任务工作线程,当任务较多时会扩容,工作线程数量上限跟当前设备的物理核数相关,具体数量内部管理,保证最优的调度及执行效率,长时间没有任务分发时会缩容,减少工作线程数量。
3.2.2 TaskPool注意事项
- 实现任务的函数需要使用装饰器
@Concurrent标注,且仅支持在.ets文件中使用。在使用TaskPool时,执行的并发函数需要使用该装饰器修饰,否则无法通过相关校验。
| @Concurrent并发装饰器 | 说明 |
|---|---|
| 装饰器参数 | 无。 |
| 使用场景 | 仅支持在Stage模型的工程中使用。 |
| 装饰的函数类型 | 允许标注async函数或普通函数。禁止标注generator、箭头函数、method。 |
| 装饰的函数内的变量类型 | 允许使用local变量、入参和通过import引入的变量。禁止使用闭包变量。 |
-
任务函数在
TaskPool工作线程的执行耗时不能超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),否则会被强制退出。 -
实现任务的函数入参需满足序列化支持的类型。
TaskPool和Worker的底层模型为Actor模型,基于Actor模型的内存隔离特性,执行多线程任务和取得结果需要通过跨线程序列化传输。目前支持传输的数据对象类型可以分为:
普通对象:
普通对象传输采用标准的结构化克隆算法(Structured Clone)进行序列化,此算法可以通过递归的方式拷贝传输对象,相较于其他序列化的算法,支持的对象类型更加丰富。
序列化支持的类型包括:除Symbol之外的基础类型、Date、String、RegExp、Array、Map、Set、Object(仅限简单对象,比如通过“{}”或者“new Object”创建,普通对象仅支持传递属性,不支持传递其原型及方法)、ArrayBuffer、TypedArray。可转移对象
可转移对象(Transferable object)传输采用地址转移进行序列化,不需要内容拷贝,会将ArrayBuffer的所有权转移给接收该ArrayBuffer的线程,转移后该ArrayBuffer在发送它的线程中变为不可用,不允许再访问。
// 定义可转移对象
let buffer: ArrayBuffer = new ArrayBuffer(100);可共享对象
共享对象SharedArrayBuffer,拥有固定长度,可以存储任何类型的数据,包括数字、字符串等。
共享对象传输指SharedArrayBuffer支持在多线程之间传递,传递之后的SharedArrayBuffer对象和原始的SharedArrayBuffer对象可以指向同一块内存,进而达到内存共享的目的。
SharedArrayBuffer对象存储的数据在同时被修改时,需要通过原子操作保证其同步性,即下个操作开始之前务必需要等到上个操作已经结束。
// 定义可共享对象,可以使用Atomics进行操作
let sharedBuffer: SharedArrayBuffer = new SharedArrayBuffer(1024);Native绑定
Native绑定对象(Native Binding Object)是系统所提供的对象,该对象与底层系统功能进行绑定,提供直接访问底层系统功能的能力。
当前支持序列化传输的Native绑定对象主要包含:Context和RemoteObject。
Context对象包含应用程序组件的上下文信息,它提供了一种访问系统服务和资源的方式,使得应用程序组件可以与系统进行交互。获取Context信息的方法可以参考获取上下文信息。
RemoteObject对象的主要作用是实现远程通信的功能,它允许在不同的进程间传递对象的引用,使得不同进程之间可以共享对象的状态和方法,服务提供者必须继承此类,RemoteObject对象的创建可以参考RemoteObject的实现。
-
ArrayBuffer参数在TaskPool中默认转移,需要设置转移列表的话可通过接口setTransferList()设置。 -
由于不同线程中上下文对象是不同的,因此
TaskPool工作线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。 -
序列化传输的
数据量大小限制为16MB。
3.3 Worker
Worker主要作用是为应用程序提供一个多线程的运行环境,可满足应用程序在执行过程中与主线程分离,在后台线程中运行一个脚本操作耗时操作,极大避免类似于计算密集型或高延迟的任务阻塞主线程的运行。
3.3.1 Worker运作机制
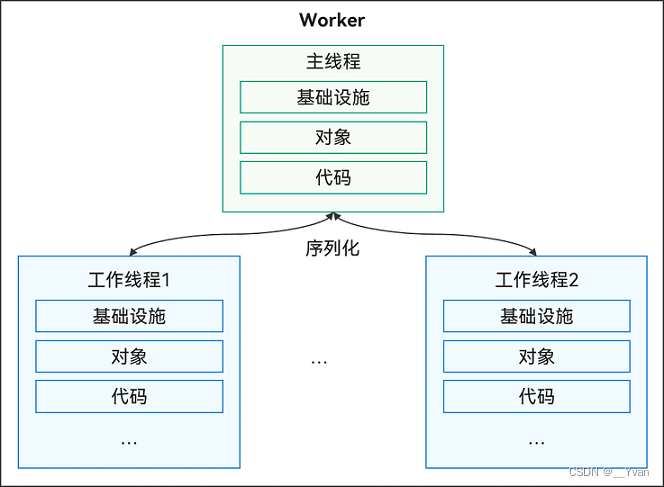
创建Worker的线程称为宿主线程(不一定是主线程,工作线程也支持创建Worker子线程),Worker自身的线程称为Worker子线程(或Actor线程、工作线程)。每个Worker子线程与宿主线程拥有独立的实例,包含基础设施、对象、代码段等。Worker子线程和宿主线程之间的通信是基于消息传递的,Worker通过序列化机制与宿主线程之间相互通信,完成命令及数据交互。
3.3.2 Worker注意事项
-
创建Worker时,传入的Worker.ts路径在不同版本有不同的规则,详情请参见文件路径注意事项。
-
Worker创建后需要手动管理生命周期,且最多同时运行的Worker子线程数量为8个,详情请参见生命周期注意事项。
-
Ability类型的Module支持使用Worker,Library类型的Module不支持使用Worker。
-
创建Worker不支持使用其他Module的Worker.ts文件,即不支持跨模块调用Worker。
-
由于不同线程中上下文对象是不同的,因此Worker线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。
-
序列化传输的数据量大小限制为16MB。
-
使用Worker模块时,需要在主线程中注册onerror接口,否则当worker线程出现异常时会发生jscrash问题。
- 文件路径注意事项
当使用Worker模块具体功能时,均需先构造Worker实例对象,其构造函数与API版本相关。
// 导入模块
import worker from '@ohos.worker';// API 9及之后版本使用:
const worker1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');
// API 8及之前版本使用:
const worker2: worker.Worker = new worker.Worker('entry/ets/workers/MyWorker.ts');构造函数需要传入Worker的路径(scriptURL),Worker文件存放位置默认路径为Worker文件所在目录与pages目录属于同级。
// 导入模块
import worker from '@ohos.worker';// 写法一
// Stage模型-目录同级(entry模块下,workers目录与pages目录同级)
const worker1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts', {name:"first worker in Stage model"});
// Stage模型-目录不同级(entry模块下,workers目录是pages目录的子目录)
const worker2: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/pages/workers/MyWorker.ts');// 写法二
// Stage模型-目录同级(entry模块下,workers目录与pages目录同级),假设bundlename是com.example.workerdemo
const worker3: worker.ThreadWorker = new worker.ThreadWorker('@bundle:com.example.workerdemo/entry/ets/workers/worker');
// Stage模型-目录不同级(entry模块下,workers目录是pages目录的子目录),假设bundlename是com.example.workerdemo
const worker4: worker.ThreadWorker = new worker.ThreadWorker('@bundle:com.example.workerdemo/entry/ets/pages/workers/worker');- 生命周期注意事项
- Worker的创建和销毁耗费性能,建议开发者合理管理已创建的Worker并重复使用。Worker空闲时也会一直运行,因此当不需要Worker时,可以调用terminate()接口或parentPort.close()方法主动销毁Worker。若Worker处于已销毁或正在销毁等非运行状态时,调用其功能接口,会抛出相应的错误。
- Worker存在数量限制,支持最多同时存在8个Worker。
- 在API version 8及之前的版本,当Worker数量超出限制时,会抛出“Too many workers, the number of workers exceeds the maximum.”错误。
- 从API version 9开始,当Worker数量超出限制时,会抛出“Worker initialization failure, the number of workers exceeds the maximum.”错误。
3.4 TaskPool和Worker对比
TaskPool(任务池)和Worker的作用是为应用程序提供一个多线程的运行环境,用于处理耗时的计算任务或其他密集型任务。可以有效地避免这些任务阻塞主线程,从而最大化系统的利用率,降低整体资源消耗,并提高系统的整体性能。
3.4.1 实现特点对比
| 实现 | TaskPool | Worker |
|---|---|---|
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移和SharedArrayBuffer共享。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移和SharedArrayBuffer共享。 |
| 参数传递 | 直接传递,无需封装,默认进行transfer。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接将方法传入调用。 | 在Worker线程中进行消息解析并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage解析赋值。 |
| 生命周期 | TaskPool自行管理生命周期,无需关心任务负载高低。 | 开发者自行管理Worker的数量及生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启8个Worker线程。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 不支持。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
3.4.2 适用场景对比
TaskPool和Worker均支持多线程并发能力。由于TaskPool的工作线程会绑定系统的调度优先级,并且支持负载均衡(自动扩缩容),而Worker需要开发者自行创建,存在创建耗时以及不支持设置调度优先级,故在性能方面使用TaskPool会优于Worker,因此大多数场景推荐使用TaskPool。
TaskPool偏向独立任务维度,该任务在线程中执行,无需关注线程的生命周期,超长任务(大于3分钟)会被系统自动回收;而Worker偏向线程的维度,支持长时间占据线程执行,需要主动管理线程生命周期。
常见的一些开发场景及适用具体说明如下:
-
运行时间超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)的任务。例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。
-
有关联的一系列同步任务。例如在一些需要创建、使用句柄的场景中,句柄创建每次都是不同的,该句柄需永久保存,保证使用该句柄进行操作,需要使用Worker。
-
需要设置优先级的任务。例如图库直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,需要使用TaskPool。
-
需要频繁取消的任务。例如图库大图浏览场景,为提升体验,会同时缓存当前图片左右侧各2张图片,往一侧滑动跳到下一张图片时,要取消另一侧的一个缓存任务,需要使用TaskPool。
-
大量或者调度点较分散的任务。例如大型应用的多个模块包含多个耗时任务,不方便使用8个Worker去做负载管理,推荐采用TaskPool。
3.5 CPU密集型任务
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。
基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。
当任务不需要长时间(3分钟)占据后台线程,而是一个个独立的任务时,推荐使用TaskPool,反之推荐使用Worker。接下来将以图像直方图处理以及后台长时间的模型预测任务分别进行举例。
3.5.1 使用TaskPool进行图像直方图处理
- 实现图像处理的业务逻辑。
- 数据分段,通过任务组发起关联任务调度。 创建
TaskGroup并通过addTask()添加对应的任务,通过execute()执行任务组,并指定为高优先级,在当前任务组所有任务结束后,会将直方图处理结果同时返回。 - 结果数组汇总处理。
import taskpool from '@ohos.taskpool';@Concurrent
function imageProcessing(dataSlice: ArrayBuffer): ArrayBuffer {// 步骤1: 具体的图像处理操作及其他耗时操作return dataSlice;
}function histogramStatistic(pixelBuffer: ArrayBuffer): void {// 步骤2: 分成三段并发调度let number: number = pixelBuffer.byteLength / 3;let buffer1: ArrayBuffer = pixelBuffer.slice(0, number);let buffer2: ArrayBuffer = pixelBuffer.slice(number, number * 2);let buffer3: ArrayBuffer = pixelBuffer.slice(number * 2);let group: taskpool.TaskGroup = new taskpool.TaskGroup();group.addTask(imageProcessing, buffer1);group.addTask(imageProcessing, buffer2);group.addTask(imageProcessing, buffer3);taskpool.execute(group, taskpool.Priority.HIGH).then((ret: ArrayBuffer[]) => {// 步骤3: 结果数组汇总处理})
}@Entry
@Component
struct Index {@State message: string = 'Hello World'build() {Row() {Column() {Text(this.message).fontSize(50).fontWeight(FontWeight.Bold).onClick(() => {let buffer: ArrayBuffer = new ArrayBuffer(24);histogramStatistic(buffer);})}.width('100%')}.height('100%')}
}3.5.2 使用Worker进行长时间数据分析
本文通过某地区提供的房价数据训练一个简易的房价预测模型,该模型支持通过输入房屋面积和房间数量去预测该区域的房价,模型需要长时间运行,房价预测需要使用前面的模型运行结果,因此需要使用Worker。
DevEco Studio提供了Worker创建的模板,新建一个Worker线程,例如命名为“MyWorker”。- 在主线程中通过调用
ThreadWorker的constructor()方法创建Worker对象,当前线程为宿主线程。
import worker from '@ohos.worker';const workerInstance: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');- 在宿主线程中通过调用
onmessage()方法接收Worker线程发送过来的消息,并通过调用postMessage()方法向Worker线程发送消息。 例如向Worker线程发送训练和预测的消息,同时接收Worker线程发送回来的消息。
import worker from '@ohos.worker';const workerInstance: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');// 接收Worker子线程的结果
workerInstance.onmessage = (() => {console.info('MyWorker.ts onmessage');
})workerInstance.onerror = (() => {// 接收Worker子线程的错误信息
})// 向Worker子线程发送训练消息
workerInstance.postMessage({ 'type': 0 });
// 向Worker子线程发送预测消息
workerInstance.postMessage({ 'type': 1, 'value': [90, 5] });- 在
MyWorker.ts文件中绑定Worker对象,当前线程为Worker线程。
import worker, { ThreadWorkerGlobalScope, MessageEvents, ErrorEvent } from '@ohos.worker';let workerPort: ThreadWorkerGlobalScope = worker.workerPort;- 在
Worker线程中通过调用onmessage()方法接收宿主线程发送的消息内容,并通过调用postMessage()方法向宿主线程发送消息。 例如在Worker线程中定义预测模型及其训练过程,同时与主线程进行信息交互。
import worker, { ThreadWorkerGlobalScope, MessageEvents, ErrorEvent } from '@ohos.worker';
let workerPort: ThreadWorkerGlobalScope = worker.workerPort;
// 定义训练模型及结果
let result: Array<number>;
// 定义预测函数
function predict(x: number): number {return result[x];
}
// 定义优化器训练过程
function optimize(): void {result = [];
}
// Worker线程的onmessage逻辑
workerPort.onmessage = (e: MessageEvents): void => {// 根据传输的数据的type选择进行操作switch (e.data.type as number) {case 0:// 进行训练optimize();// 训练之后发送主线程训练成功的消息workerPort.postMessage({ type: 'message', value: 'train success.' });break;case 1:// 执行预测const output: number = predict(e.data.value as number);// 发送主线程预测的结果workerPort.postMessage({ type: 'predict', value: output });break;default:workerPort.postMessage({ type: 'message', value: 'send message is invalid' });break;}
}- 在
Worker线程中完成任务之后,执行Worker线程销毁操作。销毁线程的方式主要有两种:根据需要可以在宿主线程中对Worker线程进行销毁;也可以在Worker线程中主动销毁Worker线程。
在宿主线程中通过调用onexit()方法定义Worker线程销毁后的处理逻辑。
// Worker线程销毁后,执行onexit回调方法
workerInstance.onexit = (): void => {console.info("main thread terminate");
}方式一:在宿主线程中通过调用terminate()方法销毁Worker线程,并终止Worker接收息。
// 销毁Worker线程
workerInstance.terminate();
方式二:在Worker线程中通过调用close()方法主动销毁Worker线程,并终止Worker接收消息。
// 销毁线程
workerPort.close();
3.6 I/O密集型任务
使用异步并发可以解决单次I/O任务阻塞的问题,但是如果遇到I/O密集型任务,同样会阻塞线程中其它任务的执行,这时需要使用多线程并发能力来进行解决。
I/O密集型任务的性能重点通常不在于CPU的处理能力,而在于I/O操作的速度和效率。这种任务通常需要频繁地进行磁盘读写、网络通信等操作。此处以频繁读写系统文件来模拟I/O密集型并发任务的处理。
- 定义并发函数,内部密集调用I/O能力。
// a.ts
import fs from '@ohos.file.fs';// 定义并发函数,内部密集调用I/O能力
// 写入文件的实现
export async function write(data: string, filePath: string): Promise<void> {let file: fs.File = await fs.open(filePath, fs.OpenMode.READ_WRITE);await fs.write(file.fd, data);fs.close(file);
}
import { write } from './a'
import { BusinessError } from '@ohos.base';@Concurrent
async function concurrentTest(fileList: string[]): Promise<boolean> {// 循环写文件操作for (let i: number = 0; i < fileList.length; i++) {write('Hello World!', fileList[i]).then(() => {console.info(`Succeeded in writing the file. FileList: ${fileList[i]}`);}).catch((err: BusinessError) => {console.error(`Failed to write the file. Code is ${err.code}, message is ${err.message}`)return false;})}return true;
}- 使用
TaskPool执行包含密集I/O的并发函数:通过调用execute()方法执行任务,并在回调中进行调度结果处理。
import taskpool from '@ohos.taskpool';let filePath1: string = "path1"; // 应用文件路径
let filePath2: string = "path2";// 使用TaskPool执行包含密集I/O的并发函数
// 数组较大时,I/O密集型任务任务分发也会抢占主线程,需要使用多线程能力
taskpool.execute(concurrentTest, [filePath1, filePath2]).then(() => {// 调度结果处理
})3.7 同步任务
同步任务是指在多个线程之间协调执行的任务,其目的是确保多个任务按照一定的顺序和规则执行,例如使用锁来防止数据竞争。
同步任务的实现需要考虑多个线程之间的协作和同步,以确保数据的正确性和程序的正确执行。
由于TaskPool偏向于单个独立的任务,因此当各个同步任务之间相对独立时推荐使用TaskPool,例如一系列导入的静态方法,或者单例实现的方法。如果同步任务之间有关联性,则需要使用Worker,例如无法单例创建的类对象实现的方法。
3.7.1 使用TaskPool处理同步任务
当调度独立的任务,或者一系列任务为静态方法实现,或者可以通过单例构造唯一的句柄或类对象,可在不同任务线程之间使用时,推荐使用TaskPool。
- 定义并发函数,内部调用同步方法。
- 创建任务
Task,通过execute()接口执行该任务,并对任务返回的结果进行操作。 - 执行并发操作。
模拟一个包含同步调用的单实例类。
3.7.2 使用Worker处理关联的同步任务
当一系列同步任务需要使用同一个句柄调度,或者需要依赖某个类对象调度,无法在不同任务池之间共享时,需要使用Worker。
- 在主线程中创建
Worker对象,同时接收Worker线程发送回来的消息。
import worker from '@ohos.worker';@Entry
@Component
struct Index {@State message: string = 'Hello World';build() {Row() {Column() {Text(this.message).fontSize(50).fontWeight(FontWeight.Bold).onClick(() => {let w: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');w.onmessage = (): void => {// 接收Worker子线程的结果}w.onerror = (): void => {// 接收Worker子线程的错误信息}// 向Worker子线程发送Set消息w.postMessage({'type': 0, 'data': 'data'})// 向Worker子线程发送Get消息w.postMessage({'type': 1})// ...// 根据实际业务,选择时机以销毁线程w.terminate()})}.width('100%')}.height('100%')}
}- 在
Worker线程中绑定Worker对象,同时处理同步任务逻辑。
// handle.ts代码
export default class Handle {syncGet() {return;}syncSet(num: number) {return;}
}// MyWorker.ts代码
import worker, { ThreadWorkerGlobalScope, MessageEvents } from '@ohos.worker';
import Handle from './handle' // 返回句柄let workerPort : ThreadWorkerGlobalScope = worker.workerPort;// 无法传输的句柄,所有操作依赖此句柄
let handler: Handle = new Handle()// Worker线程的onmessage逻辑
workerPort.onmessage = (e : MessageEvents): void => {switch (e.data.type as number) {case 0:handler.syncSet(e.data.data);workerPort.postMessage('success set');case 1:handler.syncGet();workerPort.postMessage('success get');}
}参考文献:
[1]OpenHarmoney应用开发文档









![[业务系统]人物坐骑系统介绍I](https://img-blog.csdnimg.cn/img_convert/7436abf21e1a796fb747dc41ab7db860.png)