文章目录
- 一、基础知识
- 1、字面量
- 2、常用值类型
- 3、注释
- 4、输入输出
- 5、数据类型转换
- 6、其他
- 二、字符串拓展
- 1、字符串定义
- 2、字符串拼接
- 3、字符串格式化
- 4、格式化精度控制
- 三、条件/循环语句
- 1、if
- 2、while
- 3、for循环
- 四、函数
- 1、函数定义
- 2、函数说明文档
- 3、global关键字
- 五、数据容器
- 1、概念
- 2、列表(list)
- 3、元组(tuple)
- 4、字符串(str)
- 5、序列的切片操作
- 6、集合(set)
- 7、字典(dict)
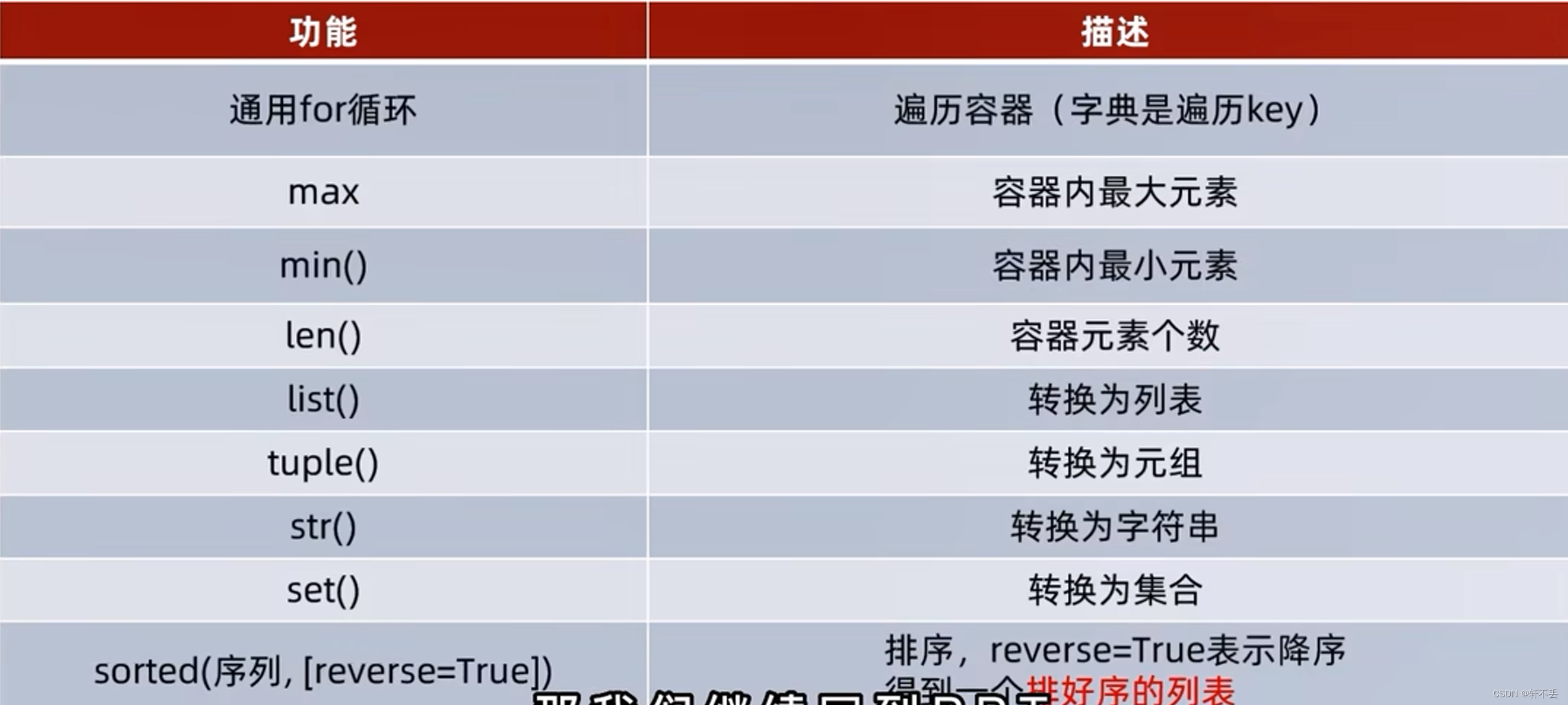
- 8、通用操作
- 六、文件操作
- 1、常见打开模式
- 2、读取操作
- 3、写文件
一、基础知识
1、字面量
在代码中,被写下来固定的值,称为字面量。
2、常用值类型
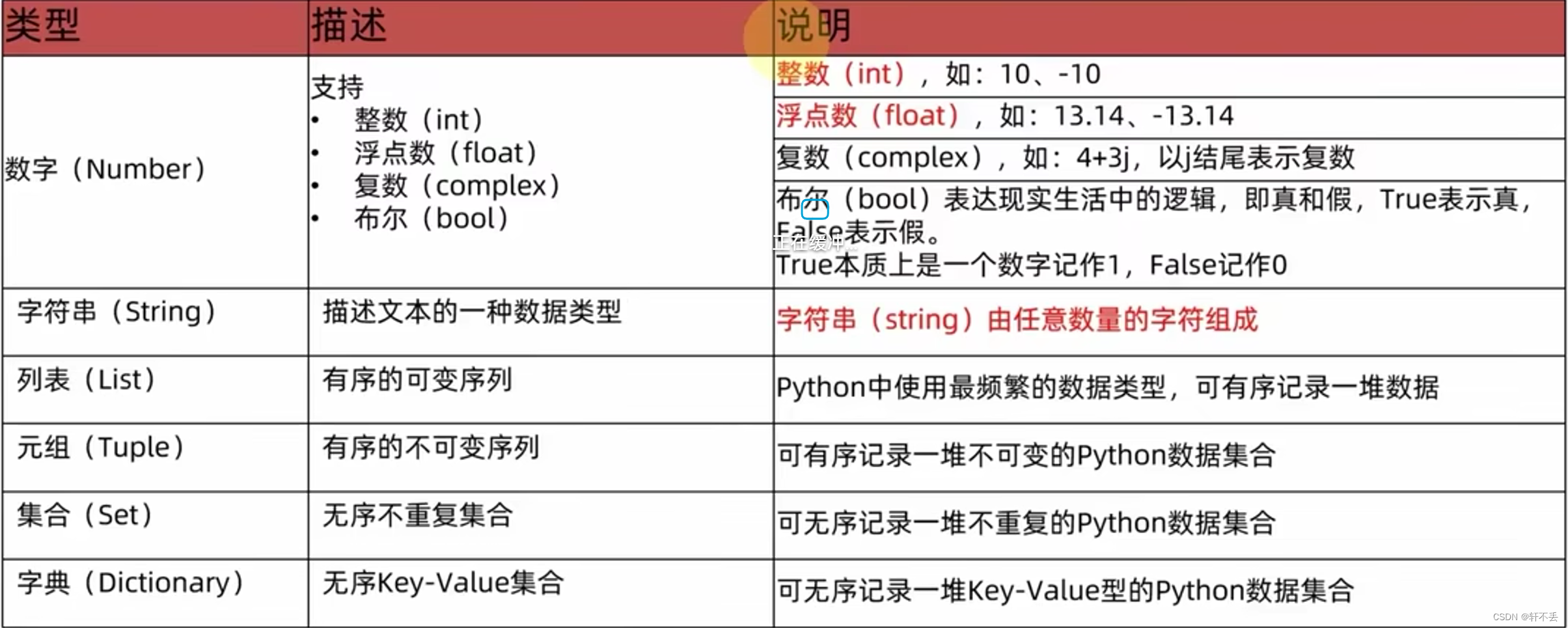
- type(变量/字面量) 可看变量类型
3、注释
- 单行注释:
# - 多行注释:一堆三个双引号
"""python
"""
4、输入输出
1.input
name = input("提示内容") //输入全是字符串,后续需要类型转换
2.print
money = 50
print("python")
print("钱包有:",money,"元")
5、数据类型转换
int(x)
float(x)
str(x)
6、其他
1.python变量命名大小写敏感
2.**是指数,a**b表示a的b次方,还可以a**=b
二、字符串拓展
1、字符串定义
单/双/三引号都可以
/可以使用转义字符解除引号的效用
name = 'python' //里面可以内含双引号
name = "python" //里面可以内含单引号
name = """ python
"""
2、字符串拼接
1.print('python' + 'is easy') 输出python is easy
2.age = '18'
print('I am' + age+'years old') 输出I am 18 years old
3.'python' +18是不行的,字符串不能通过+与非字符串类型拼接
3、字符串格式化
//%为占位符,将后面变量占到前面所需要的地方
1.age = '18'
message = 'I am %s years old' % age
2.不同类型,多种变量都可以
age1 = 18,age2=20
message = "I am %s,she is %s" % (age1,age2) //此时整型转换成字符串格式进去3.f"内容{变量}" 快速格式化,不过此时无法做精度控制
message = f"I am {age1},she is {age2}"4.表达式格式化
messgae = "I am %d years old" % (1*1)
messgae = f"I am {1*1} years old"
常见占位符

4、格式化精度控制
m.n来控制数据的宽度和精度
- m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效(小数和小数点都进入精度计算)。
宽度太多从左用控制替代,比如%3d,而整数是2,写成[空格][空格]2 - .n,控制小数点精度,要求是数字,会进行小数的四舍五入
三、条件/循环语句
1、if
1.注意缩进~
if 要判断的条件: //冒号不要忘记程序
elif 要判断条件:程序
else:程序
2.案例
import random
age = random.randint(1,100)
if age > 10 :print("11")
elif age > 8 :print("22")
else:print("33")
2、while
1.条件满足进入循环
while 条件:程序
3、for循环
与其他语言不太一样,对内容进行逐个处理
1.基础语法
for 临时变量 in 待处理数据集:程序
//待处理的数据集是序列类型,其内容是一个个依次取出来的一种类型,包括字符串,列表,元组等
案例:
name = "BUAA"
for x in name:print(x)
2.range语句
range(5)得到的是一个序列:[0,1,2,3,4]
range(5,10)得到的是[5,6,7,8,9]
range(5,10,2)得到的是[5,7,9]
与for结合
for x in range(5)程序
四、函数
1、函数定义
1.定义
def定义带有名称的函数
def 函数名(传入参数):函数体return 返回值//无return时,是有返回值的,返回一个特殊字面量,类型是<class 'NoneType'>
//手动返回return none也行
//if判断中,none等同于false,一般函数中主动返回none,与if配合处理
//无内容变量,暂时不需要值,可以name = none
2.多返回值
def 函数名(传入参数):return 返回值1,返回值2
接收:var1,var2 = 函数名(参数)
3.函数调用
一个函数fnc(name,age,gender)
位置传参:可以fnc("b",18,"男")这样按照位置接收
关键字传参:可以fnc(age=18,gender="男",name="a")接收(不按位置)
混用:还可以func("a",gender="男",age=18)接收,混用是位置参数必须在前
4.缺省参数
def fnc(name,age,gender="男") //设置默认值
调用时若不传参采用默认值
缺省参数必须统一在位置参数后面
5.不定长参数
位置传递:def func(*args) args是元组类型
关键字传递:def fnc(**kwargs) kwargs是字典类型,传参必须是key=value形式
6.匿名函数
lambda定义匿名函数
lambda 传入参数:函数体 //函数体只能写一行,函数体直接将结果return
2、函数说明文档
def 函数名(传入参数):"""函数整体说明:param x:形参x说明:param y:形参y说明:return:返回值说明"""函数体return 返回值
3、global关键字
num = 200
def func():global num//此时num指定指代的全局变量num=200num=300 //num改动全局变量num就会变
五、数据容器
1、概念
批量存储数据。根据特点不同,比如是否支持重复元素,是否可以修改,是否有序等,分为五类,列表(list),元组(tuple),字符串(str),集合(set),字典(dict)
2、列表(list)
1.定义:变量名称 = [元素1,元素2,元素3,...]
2.空列表:变量名称 = [ ] 变量名称 = list()
//列表存储的数据可以为不同数据类型,且支持嵌套
3.读:arr[0]
或反向索引:从后向前开始,依次递减(-1,-2,-3...)
列表方法
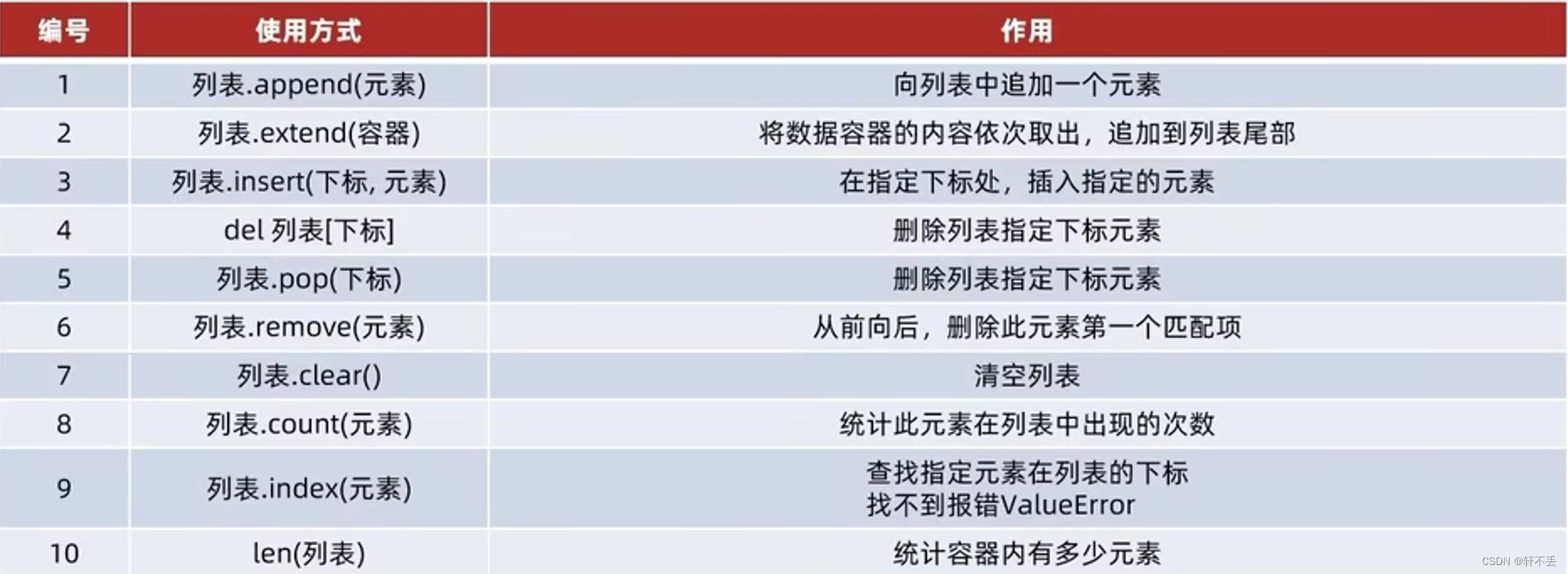
3、元组(tuple)
可以封装多个,不同类型的元素,唯一区别就是一旦定义完成就不可以修改了。
1.定义:变量名称 = (元素1,元素2,元素3,...)
2.空列表:变量名称 = () 变量名称 = tuple()
3.定义单个元素:变量名称 = (元素1,) //单元素一定要加括号,不然类型是字符串
//元组内部也支持嵌套
4.读:arr[0]
元组方法

注意点:
//元组内部嵌套list,list是可以修改的
arr = (1,2,["1","2","3"])
arr[2][1]="4"是可以的
4、字符串(str)
1.str = "abcd"
可以通过str[0]读取
2.对于字符串的修改都无法在原来的基础上,只能得到新的字符串
字符串方法
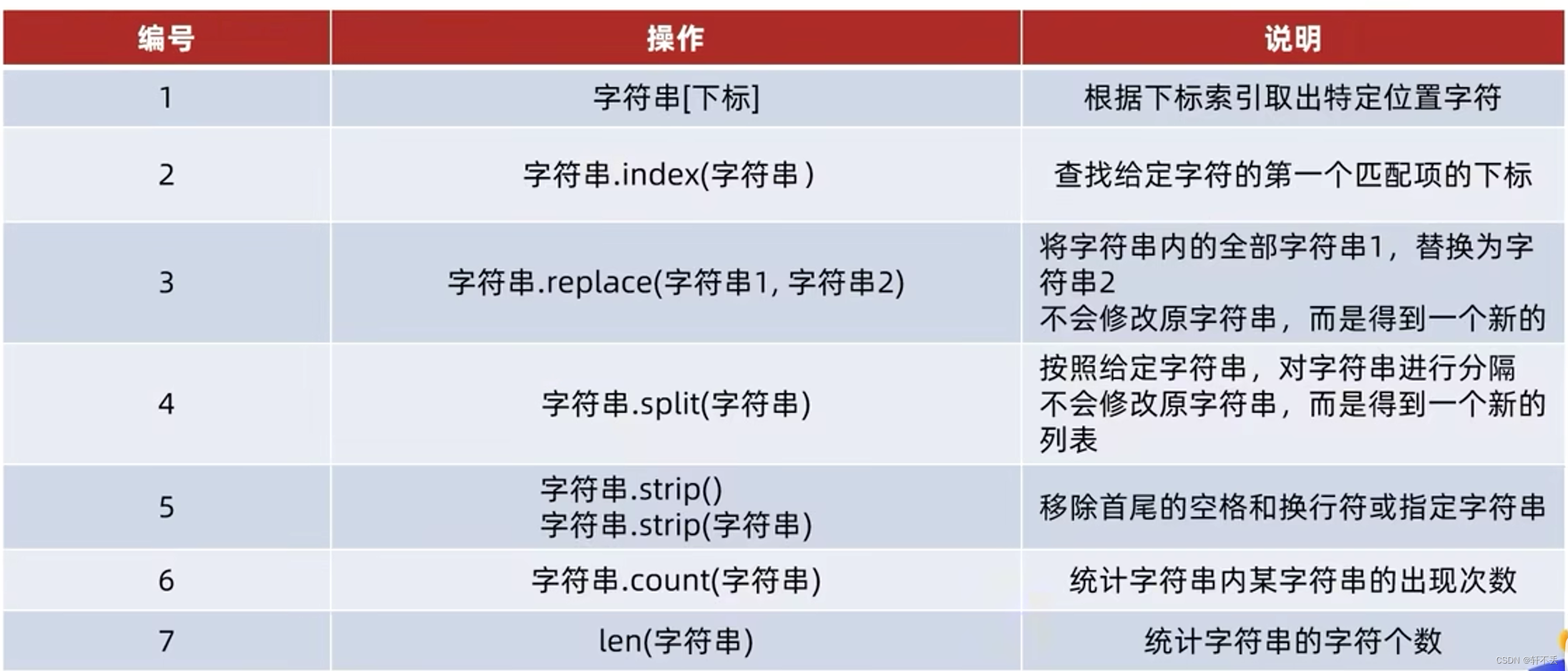
5、序列的切片操作
- 序列是指内容连续,有序,可使用下标索引的一类数据容器。
- 列表、元组、字符串都可视为序列
- 切片操作:从一个序列中,取出一个子序列
语法:[起始下标:结束下标:步长]- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
6、集合(set)
- 特点:不支持元素重复,内容无序
1.定义:变量名称 = {元素1,元素2,元素3,...}
2.空集合:变量名称 = {} 变量名称 = set{}
//列表存储的数据可以为不同数据类型,且支持嵌套
3.读:集合无序,因此不支持下标索引访问
或反向索引:从后向前开始,依次递减(-1,-2,-3...)
集合方法
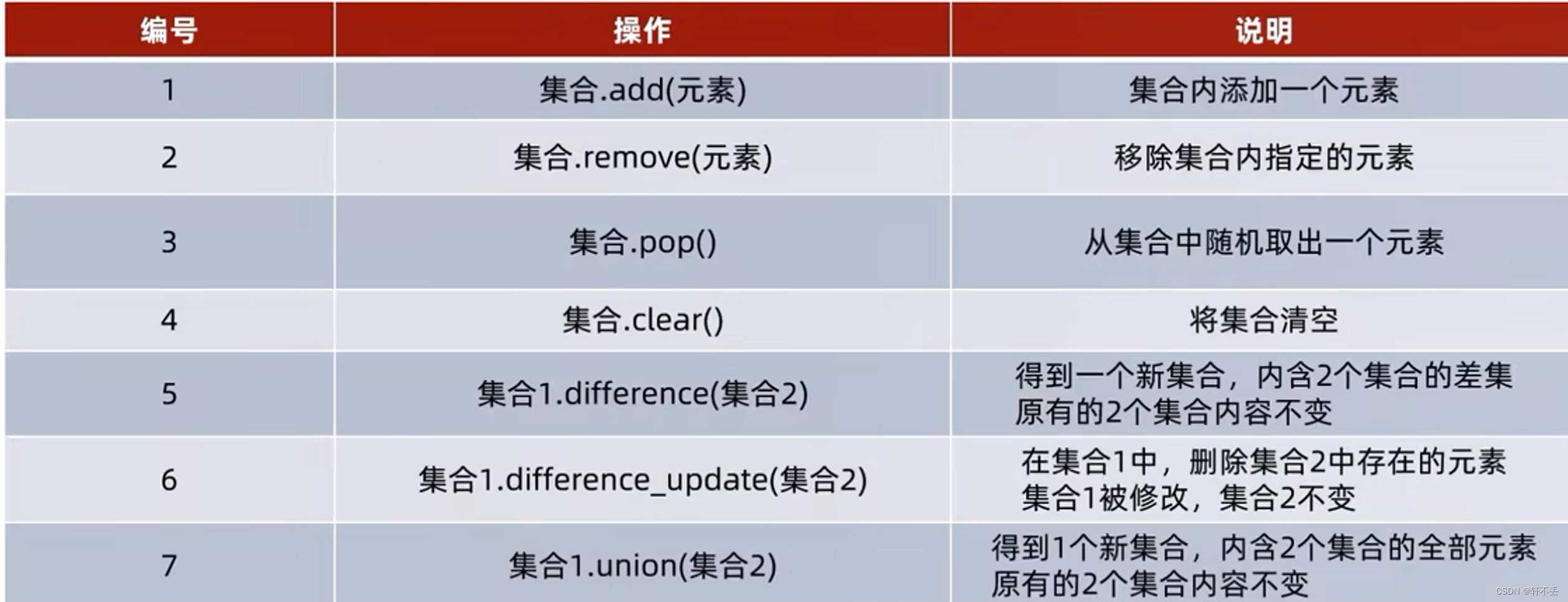
7、字典(dict)
1.定义:变量名称 = {key:value,key:value,....}
2.空字典:变量名称 = {} 变量名称 = dict{}
//字典的key不允许重复,重复添加等于覆盖原有数据。
//允许嵌套
3.读取:arr[key]
4.for x in dict: //每次取出来的是key
常见方法
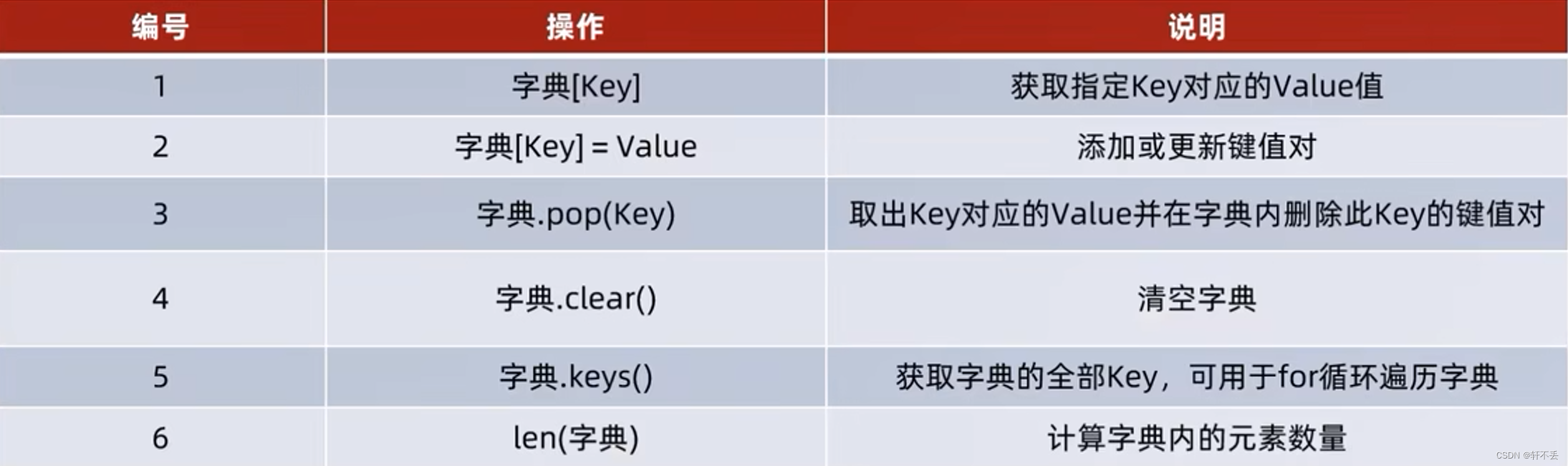
8、通用操作
- 类型转换
list(容器) //字典转列表得到keys
str(容器)
tuple(容器)
set(容器)
其他容器类型很难转换成字典
六、文件操作
1、常见打开模式

2、读取操作
1.打开
open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
# encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
eg.f = open('python.txt','r',encoding='utf-8')
2.读取
f.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
一次读取后则下次是从上次读取的地方继续读取
f.readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f.readline()一次读取一行内容 一次读取后则下次是从上次读取的地方继续读取
3.关闭
f.close() //不关闭则文件会一直被python文件占用
4.
with open(name,mode,encoding) as f:程序
通过在with open的语句块中对文件进行操作。可以在操作完成后自动关闭close文件,避免遗忘掉close方法
3、写文件
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
1.打开文件 f = open(name,'w'/a)
2.写入f.write(内容)
3.f.flush()
//注意f.close内置了flush方法,因此关闭前也会刷新
//w和a在文件不存在都会创建文件,不过文件存在w会清空文件再写,a是追加在后面


![[项目设计] 从零实现的高并发内存池(四)](https://img-blog.csdnimg.cn/c446ebae288e480d84f5d14d494c88bb.gif)