交叉熵损失函数torch.nn.CrossEntropyLoss
交叉熵主要是用来判定实际的输出与期望的输出的接近程度,为什么这么说呢,举个例子:
- 在做分类的训练的时候,如果一个样本属于第K类,那么这个类别所对应的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果。也就是说用它来衡量网络的输出与标签的差异,利用这种差异经过反向传播去更新网络参数。
损失函数计算原理
交叉熵损失,是分类任务中最常用的一个损失函数。在Pytorch中是基于下面的公式实现的。
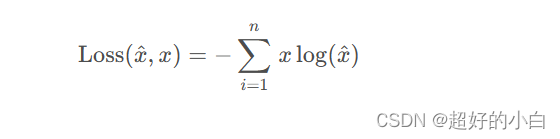
其中x 是真实标签, x ^是预测值。
取单个样本举例, 假设x = [ 0 , 1 , 0 ] , 模型预测样本x ^的概率为[ 0.1 , 0.5 , 0.4 ] 。(因为是分布, 所以属于各个类的和为1)。则样本的损失计算如下所示:
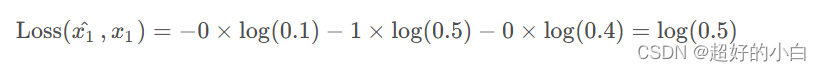
需要注意的点:
-
torch.nn.CrossEntropyLoss(input,target)中的标签target使用的是类别的序号,而不是one-hot形式。
假设现在共有5个候选类别,当前标签是第三个。故类别序号如:2,(下标从0开始),而one-hot编码表示为:[0,0,1,0,0]。在torch中,输入的target只需要是类别序号即可,
torch.nn.CrossEntropyLoss(input,target)会自动进行one-hot编码。这是因为在target中只会有一个类别为真,最终得到loss也只是会和真的这个类别相乘,故自动编码很容易。 -
torch.nn.CrossEntropyLoss(input, target)的input是没有归一化的每个类的得分,而不是softmax之后的分布。即input是直接模型的输出即可,不需要进行softmax操作。
对于推理阶段,需要使用torch.argmax() 或者softmax等函数来找出概率最大的类别。