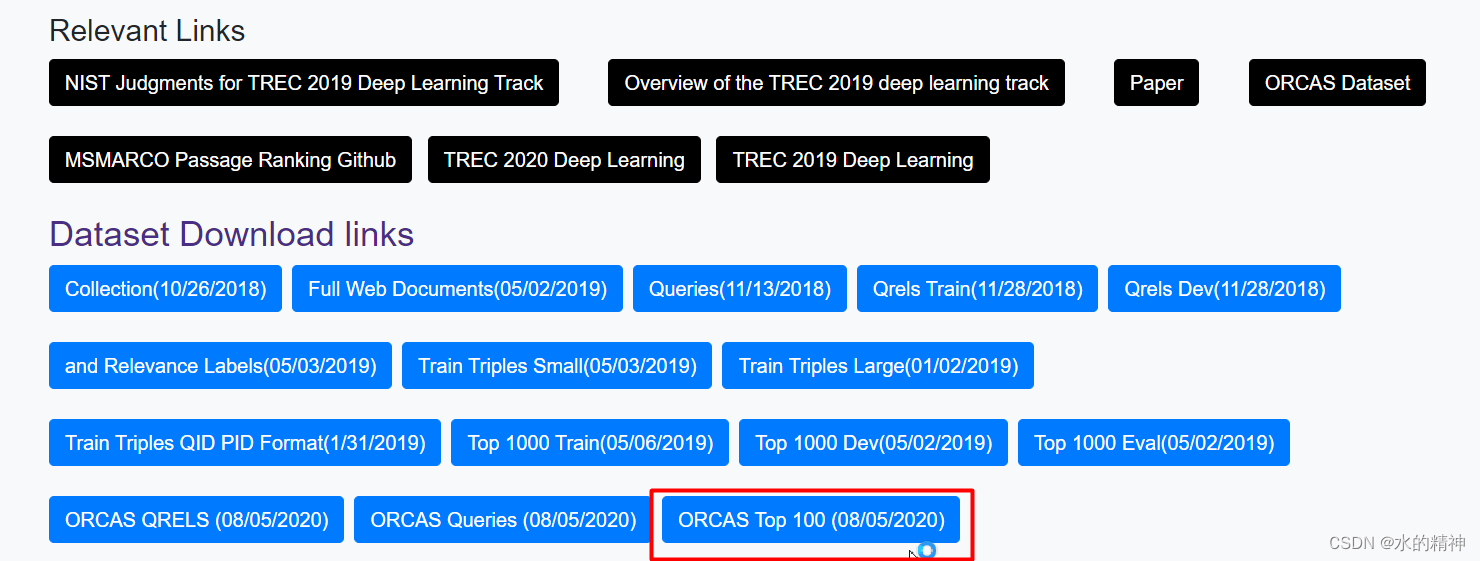
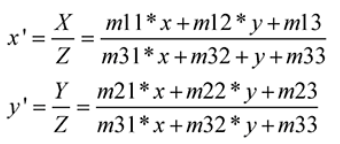以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏
让我们看看为你的程序添加数据的技巧。在构建神经网络的时候,我们总是想要更多的数据,但是获取更多的数据往往是十分昂贵又缓慢的。相反地,添加数据的另一种方法是专注于添加有帮助的数据。
在上一篇博客之中,我们提到了垃圾邮件识别器,其中解决提高系统性能的方法之一就是添加专门的某种类型数据,从而增强神经网络的性能。如今,研究人员如果发现神经网络在某种特定的数据上表现特别差,有一种方法能够做到只添加一点点数据,就可以大幅增强神经网络的表现,这叫做数据增强。
文章目录
- 数据增强 Data Augmentation
- 手写识别
- 语音识别
- 数据合成
- 迁移原理
- 原理
数据增强 Data Augmentation
手写识别
例如,如果你在做一个字母识别的神经网络,希望神经网络能够更好地识别字母A,那么你除了传入一张字母A作为数据,还可以将这张图片旋转一定角度,从而产生一个新的示例;或者将图片放大或者缩小一点;或者改变图片的对比度;如果不是对称图形,你也可以添加它的镜像等等。
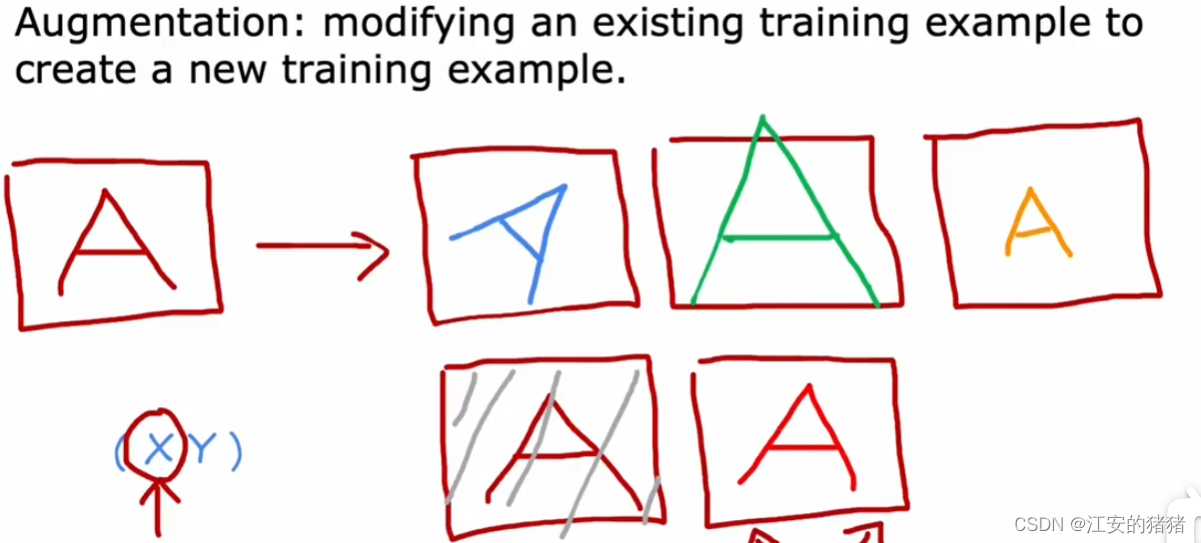
另外一种常用的方法是,将图像放在网格之上,之后随机扭曲图像:

语音识别
数据增强也适用于语音识别之中。
你可以给原始语音添加噪音、汽车声、不同的背景音乐:

数据增强的一个技巧是,对数据做的更改或扭曲应该代表训练集中的噪声或扭曲。
如果你对示例的更改在测试集不常遇到,那么其实对数据的帮助是有限的。因此,考虑数据增强的一种方法是思考如何在扭曲、更改或在数据中增加更多的噪音,即让你的训练集能够和测试集更加相似。其中有一种技术叫做数据合成(data synthesis),让你可以从头开始构建新的示例。
数据合成
让我们以照片OCR为例,它的作用是自动读取图片并且能够读取出其中的文字。

以上是OCR中的一个真实数据,我们该怎么做呢?
任务的一个关键人物就是能从图中读出各个字母的小图像并识别出图中的字母:

因此你创建人工数据的方法就是利用计算机中自带的文本编辑器,然后交给神经网络去学习,从而你可以合成类似下图的字母,看起来和上图真的很类似:

通过合成数据生成,能够为神经网络提供大量数据,从而很快地提高应用性能。
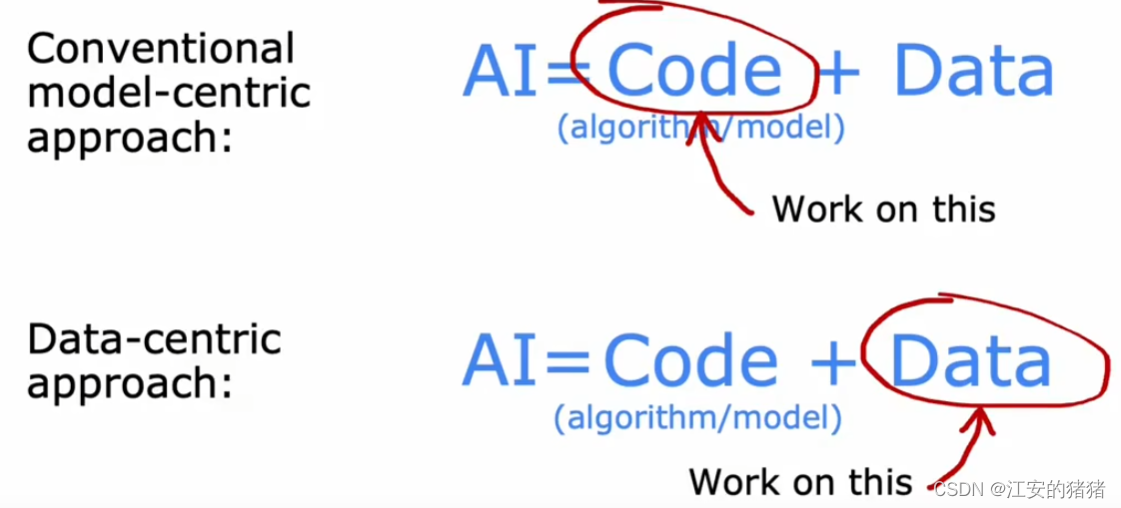
过去几十年之中,大部分研究人员的注意力都集中在传统的以模型为中心的基础上,因此对于数据都会下载固定的数据集,从而专注于改进算法或者模型,但其实专注于数据的处理也是一条很有前景的道路。
对于没有那么多数据的程序,使用迁移学习从而使用其它不同任务的数据是个很好的方法。以下是迁移学习的工作原理。
迁移原理
假设你想要做一个手写字识别的项目,但是你没有那么多的标记数据。而假设你找到了个非常大的数据集,其中包含一百万张猫,狗,人,汽车的照片等一千个类别。然后,你可以在这个数据集上,让你的神经网络训练这1000个物品的任意一个,你将获得一系列的w,b参数。之后你要做的,是将这些参数直接插入你手写识别的神经网络之中,只是输出层的参数不能使用,因为你的分类从1000变成了手写识别的十个,之后,再重新训练网络。
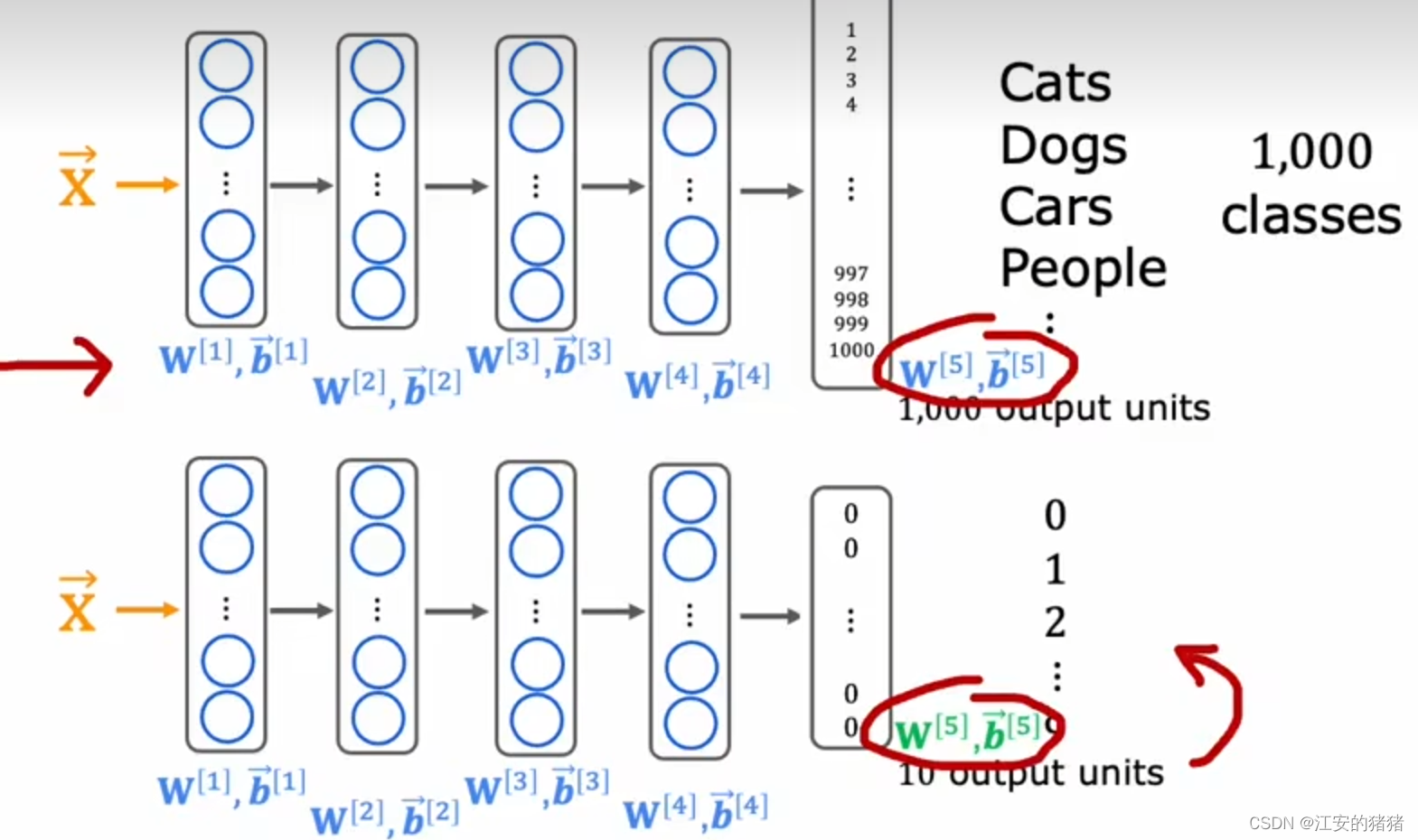
之后,你就有两种选择,第一种,只重新训练输出层的参数,这适用于你的神经网络参数真的很小的情况下,第二种,是在前四层不懂的基础上再往后面训练一个神经网络,这适用于神经网络还是有一定量的数据集的情况下。这种方法就叫做迁移学习,即将神经网络的的早期层学习一些合理的参数集,然后将这些参数转移到新的神经网络之中,这样我们就可以进一步学习一点点,最后被优化为一个非常好的模型。
其中,这在其它神经网络上获得参数的过程叫做监督预训练;第二步叫做微调,即优化获得的参数从而使得其能够变为专门应用于手写数字识别的应用。
另一个好处是,你也许不需要亲自进行预训练。因为网上有很多研究者已经训练好的神经网络,你可以直接使用,然后将输出层替换为自己需要的就行了。
原理
为什么识别猫猫狗狗的深度学习网络最后可以识别手写数字呢?这与算法背后的直觉有关。

以上是一些原因,由于神经网络的早期层基本上都是进行一些边,角落还有基本图形的处理。因此在不同的数据集上其实是有共通性的。
但是迁移学习的一个限制是图像类型x必须于你预训练的图片类型相同,即图片尺寸相同。例如如果你要构建一个语音识别系统,那么以上数据集的参数可能就没什么帮助了。
当你预训练的数据集很大,而自己的数据集较小时,效果往往会更好

为了给读者你造成不必要的麻烦,博主的所有视频都没开仅粉丝可见,如果想要阅读我的其他博客,可以点个小小的关注哦。