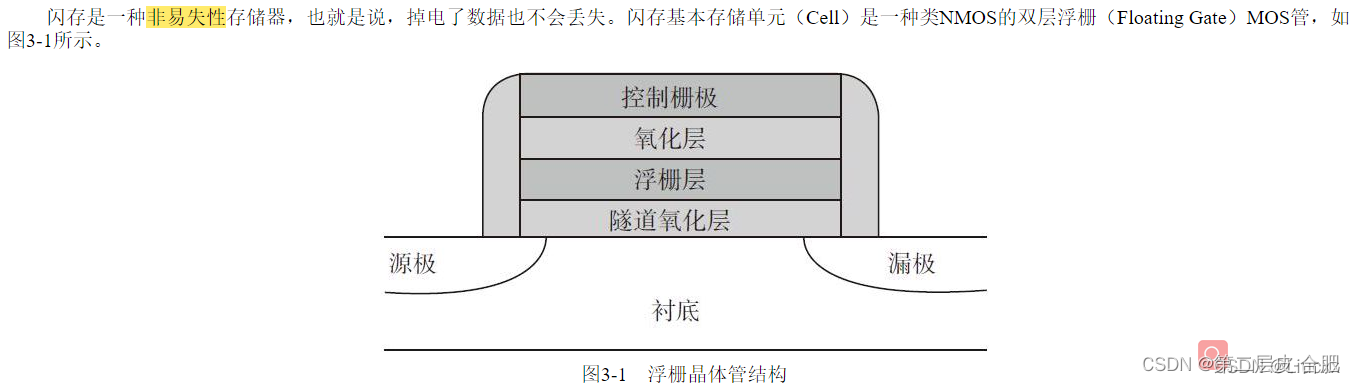
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
新闻文章分类模型比较项目报告
项目介绍
背景
新闻文章自动分类是自然语言处理和文本挖掘领域的一个重要任务。正确分类新闻文章不仅能帮助用户快速找到感兴趣的内容,还能提高信息检索系统的效率。
目的
本项目的目标是比较三种不同的机器学习算法 — 朴素贝叶斯、决策树和支持向量机(SVM) — 在新闻文章分类任务上的性能。使用的是scikit-learn中的20个新闻组数据集。
展示结果
准确率比较
- 朴素贝叶斯 准确率: 0.77
- 决策树 准确率: 0.55
- SVM 准确率: 0.82
混淆矩阵
每个模型的混淆矩阵展示了在各个类别上的分类性能。
![图片[1]-新闻文章分类项目-VenusAI](https://img-blog.csdnimg.cn/img_convert/655bdd07d48338c7863b972aa1426c12.png)
解决过程
数据预处理
- 数据集:使用
scikit-learn中的20个新闻组数据集。 - 文本向量化:利用TF-IDF(Term Frequency-Inverse Document Frequency)方法将文本转换为数值向量。
模型构建和训练
- 朴素贝叶斯:一个适用于文本分类的经典算法,特别是在数据集较小的情况下。
- 决策树:易于理解和解释,但在文本分类中可能不如其他算法表现好。
- 支持向量机(SVM):在各种文本分类任务中常表现出色,尤其是在高维数据上。
模型评估
- 使用准确率作为主要评估指标。
- 利用混淆矩阵详细分析每个模型在不同类别上的性能。
代码
详情代码请见
新闻文章分类项目-VenusAI (aideeplearning.cn)
结论
在本项目中,SVM在新闻文章分类任务上展现了最高的准确率,而朴素贝叶斯也表现出了相对较好的性能。决策树的准确率相对较低,可能因为其在处理高维稀疏数据时的局限性。这些发现表明,在选择合适的文本分类算法时,应考虑数据的特性和应用场景。

![[java入门到精通] 11 泛型,数据结构,List,Set](https://img-blog.csdnimg.cn/direct/77dc7a6315d443ac9caa6726ec3fe205.png#pic_center)