1.什么是Flink
是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
官网:Flink
2.Flink的发展历史
-
Flink起源于一个叫作Stratosphere的项目,它是由3所地处柏林的大学和欧洲其他一些大学在2010~2014年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2014年4月,Stratosphere的代码被复制并捐赠给了Apache软件基金会,Flink就是在此基础上被重新设计出来的。
-
在德语中,“flink”’一词表示“快速、灵巧”。
-
项目的logo是一只彩色的松鼠。(如下图)

-
2014年8月,Flimnk第一个版本0.6正式发布,与此同时Fink的几位核心开发者创办Data Artisans公司;
-
2014年12月,Flink项目完成孵化;
-
2015年4月,Flink发布了里程碑式的重要版本0.9.0;
-
2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;
-
2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink1.9.0版本。
3.有界流和无界流
3.1 无界数据流
- 有定义流的开始,但没有定义流的结束;
- 它们会无休止的产生数据;
- 无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能得到所有数据都到达再处理,因为输入是无限的。
3.2 有界数据流
- 有定义流的开始,也有定义流的结束;
- 有界流可以在摄取所有数据后再进行计算;
- 有界流的数据可以被排序,所以并不需要有序摄取。
4.有状态流处理
- 把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态;
- 状态在内存中:优点,速度快;缺点,可靠性差;
- 状态在分布式系统中:优点,速度慢;缺点,可靠性高。
5.Flink特点
处理数据的目标:低延迟、高吞吐、结果的准确性和良好的容错性。
5.1 批流统一
- 同一套代码,可以跑流也可以跑批;
- 同一个SQL,可以跑流也可以跑批。
5.2 性能卓越(每秒处理数百万个事件,毫秒级延迟)
- 高吞吐;
- 低延时。
5.3 规模计算
- 支持水平扩展架构;
- 支持超大状态与增量检查点机制。
5.4 生态兼容
- 支持与Yarn集成;
- 支持与Kubernetes集成;
- 支持单机模式运行。
5.5 高容错
- 故障自动重试;
- 一致性检查点;
- 保证故障场景下精确一次的状态一致性。(Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。)
5.6 高可用
- 本身高可用的设置,加上与K8S,YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7x24全天候运行。
6.Flink的应用场景
- 电商和市场营销:实时数据报表、广告投放、实时推荐;
- 物联网(IOT):传感器实时数据采集和显示、实时报警,交通运输业;
- 物流配送和服务业:订单状态实时更新、通知信息推送;
- 银行和金融业:实时结算和通知推送,实时监测异常行为。
7.Fllink分层API
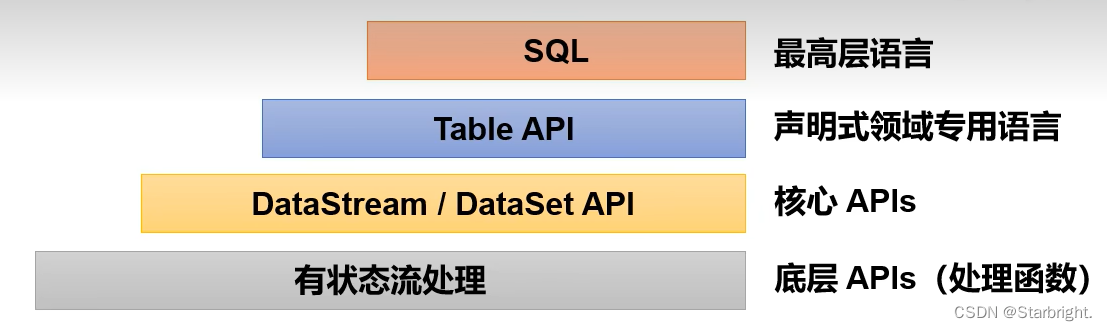
- 有状态流处理:通过底层API(处理函数),对最原始数据加工处理。底层API与DataStream API相集成,可以处理复杂的计算。
- DataStream API(流处理)和DataSet API(批处理)封装了底层处理函数,提供了通用的模块,比如转换(transformations,包括map、flatmap等),连接(joins),聚合(aggregations),窗口(windows)操作等。注意:Flink1.12以后,DataStream
API已经实现真正的流批一体,所以DataSet API已经过时。 - Table API是以表为中心的声明式编程,其中表可能会动态变化。Table API遵循关系模型:表有二维数据结构,类似于关系数据库中的表;同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。我们可以在表与DataStream/Dataset 之间无缝切换,以允许程序将Table API与DataStream以及DataSet混合使用。
- SQL这一层在语法与表达能力上与 Table API类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table
API交互密切,同时SOL查询可以直接在Table API定义的表上执行。



![[java入门到精通] 11 泛型,数据结构,List,Set](https://img-blog.csdnimg.cn/direct/77dc7a6315d443ac9caa6726ec3fe205.png#pic_center)