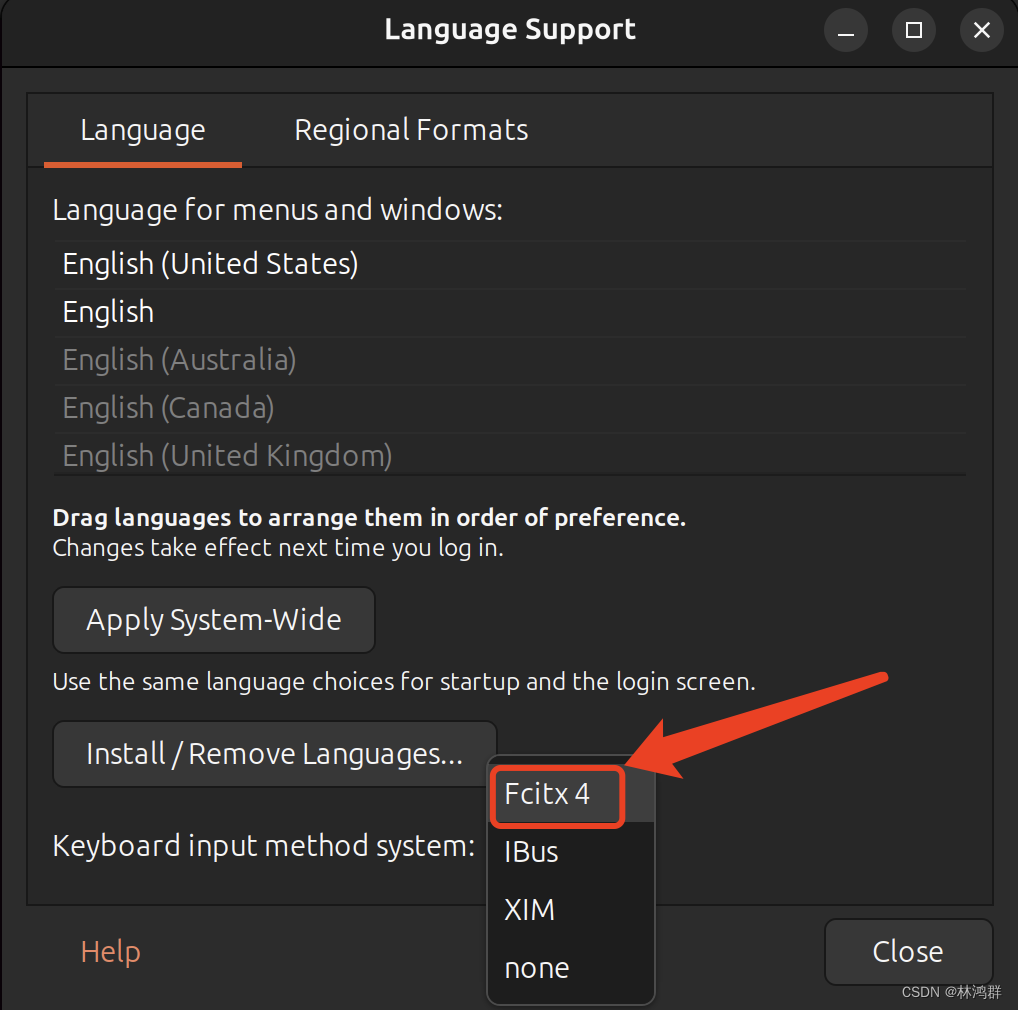
1.Normalizer(归一化)(更加推荐使用)
优点:将每个样本向量的欧几里德长度缩放为1,适用于计算样本之间的相似性。
缺点:只对每个样本的特征进行缩放,不保留原始数据的分布形状。
公式:对于每个样本,公式为:x / ||x||,其中x是样本向量,||x||是x的欧几里德范数。
2.MinMaxScaler(最小-最大标准化)
优点:将数据缩放到指定的范围(通常是0到1之间),保留了原始数据的形式。适用于需要保留原始数据分布形状的算法。
缺点:受异常值的影响较大,对分布不均匀的数据集可能导致信息损失。
公式:对于每个特征,公式为:(x - min) / (max - min),其中x是特征值,min是特征的最小值,max是特征的最大值。

3.Normalizer和MinMaxScaler区别
Normalizer和MinMaxScaler是不同的数据标准化方法。
Normalizer是一种将每个样本向量的长度缩放为1的归一化方法,它逐个样本对特征向量进行归一化,使得每个样本的特征向量都具有相同的尺度。
MinMaxScaler是一种将特征缩放到指定范围(通常是0到1之间)的标准化方法。它通过对每个特征进行线性变换,将特征值缩放到指定的最小值和最大值之间。
这两种方法有相似之处,都可以将数据缩放到一定范围内,但是归一化和最小-最大标准化的方式和目的不同。
归一化(Normalizer)在每个样本上进行操作,主要是为了保持样本之间的向量方向或角度关系,使得样本之间的相似性或距离计算更具可比性。
最小-最大标准化(MinMaxScaler)在每个特征上进行操作,主要是为了将特征值缩放到指定的范围,保留特征之间的相对关系。
因此,虽然它们都属于数据标准化的方法,但实际应用中,选择使用归一化还是最小-最大标准化取决于数据的特点和具体任务的需求。
4.案例解释
当使用Normalizer进行归一化时,每个样本的特征向量都会被调整为单位范数(默认为L2范数)。假设我们有一个包含两个样本的数据集,每个样本有两个特征。数据集如下:
样本1: [2, 4]
样本2: [1, 3]
使用Normalizer进行归一化后,结果如下:
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Normalizer,RobustScaler
>>> scaler_x = Normalizer()
>>> scaler_x.fit_transform(x)
array([[0.4472136 , 0.89442719],[0.31622777, 0.9486833 ]])
样本1归一化后: [0.447, 0.894]
样本2归一化后: [0.316, 0.949]
每个样本的特征向量都被缩放到单位长度。
而当使用MinMaxScaler进行最小-最大标准化时,特征值会被缩放到一个指定的范围(通常是0到1之间)。假设我们有相同的数据集:
样本1: [2, 4]
样本2: [1, 3]
使用MinMaxScaler进行最小-最大标准化,将特征值缩放到0到1之间,结果如下:
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Normalizer,RobustScaler
>>> scaler_x = MinMaxScaler()
>>> import numpy as np
>>> x = np.array([[2,4],[1,3]])
>>> scaler_x.fit_transform(x)
array([[1., 1.],[0., 0.]])
样本1标准化后: [1, 1]
样本2标准化后: [0, 0]
特征值被缩放到指定的范围之间。
可以看到,Normalizer(归一化)通过调整每个样本的特征向量的长度来进行归一化,而MinMaxScaler(最小-最大标准化)通过线性变换将特征值缩放到指定的范围内。在这个例子中,归一化操作将样本1归一化后的特征向量缩放到单位长度,而最小-最大标准化将样本1标准化后的特征值缩放到0到1之间。