Softmax 回归 + 损失函数 + 图片分类数据集
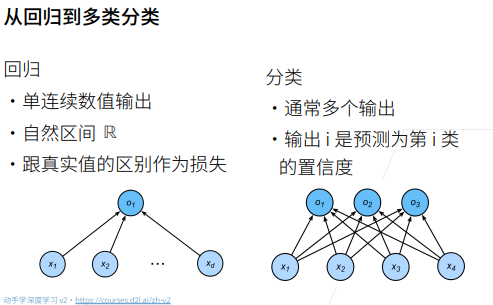
- 1 softmax
- 2 损失函数
- 1均方
- L1Loss
- Huber Loss
- 3 图像分类数据集
- 4 softmax回归的从零开始实现
1 softmax
Softmax是一个常用于机器学习和深度学习中的激活函数。它通常用于多分类问题,将一个实数向量转换为概率分布。Softmax函数常用于多类别分类问题,其中模型需要为每个类别分配一个概率,以便选择最有可能的类别。在深度学习的神经网络中,Softmax通常作为输出层的激活函数。oftmax函数在多分类问题中常用于神经网络的输出层,其主要作用是将神经元的输出转化为概率分布,使得每个类别的输出值都在0到1之间,并且所有类别的输出值之和为1。这种转换有助于我们理解和解释模型的预测结果,知道每个类别的预测概率。
然而,softmax函数通常并不与其他常见的激活函数(如sigmoid、ReLU等)一起用在同一个网络层。这是因为softmax函数本身就是一种特殊的激活函数,专门用于处理多分类问题的输出。它已经在输出层完成了将输出值转换为概率分布的任务,因此不需要再与其他激活函数一起使用。
在神经网络的其他层,我们可能会使用其他的激活函数,如ReLU、sigmoid等,来增加网络的非线性特性,提高网络的表达能力。但在输出层,当我们需要得到每个类别的预测概率时,就会使用softmax函数。
所以,softmax函数并不经常和其他激活函数一起用在同一个网络层,而是在特定的输出层中使用,用于将输出转换为概率分布。

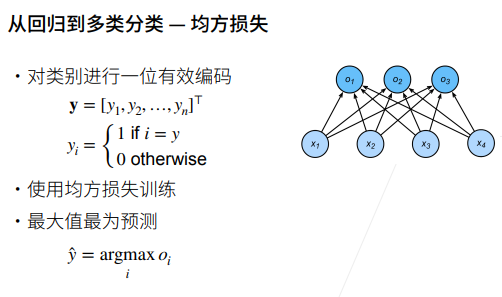
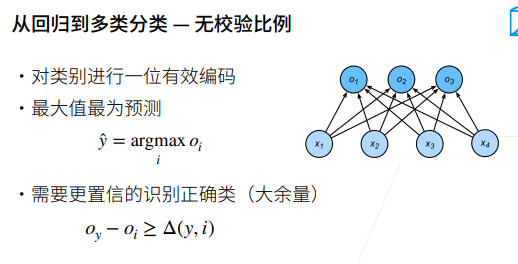
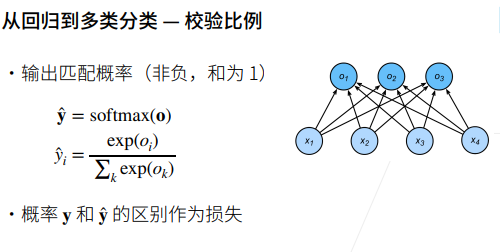


叉熵损失函数(Cross-Entropy Loss)是在分类问题中常用的损失函数,特别是在深度学习任务中。它用于衡量模型的输出概率分布与实际标签之间的差异。
在深度学习中,通常使用梯度下降等优化算法来最小化交叉熵损失,从而使模型的预测逼近实际标签。交叉熵损失对于分类问题而言,是一种常见且有效的选择,尤其与softmax激活函数结合使用,因为它可以自然地惩罚模型对正确类别的不确定性。

2 损失函数
函数(Loss Function)是在机器学习中用来衡量模型预测与实际目标之间差异的函数。它是优化算法的核心组成部分,帮助模型学习从输入到输出的映射,并调整模型参数以最小化预测错误。
选择合适的损失函数取决于任务的性质,例如回归、分类、多类别分类等。正确选择损失函数有助于模型更好地学习数据的特征,提高其性能。
在训练过程中,模型的目标是最小化损失函数的值。损失函数通常是一个标量,表示模型对于给定样本或一批样本的性能表现。常见的损失函数包括:
1均方
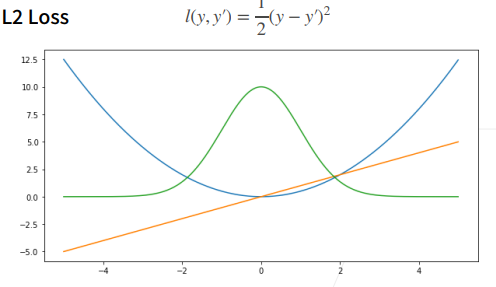
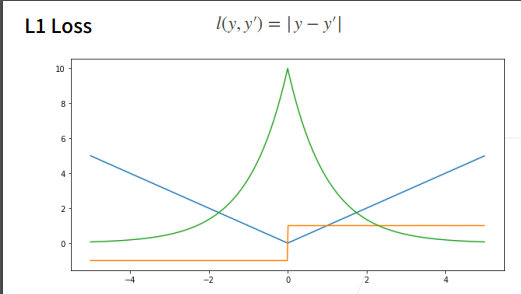
L1Loss
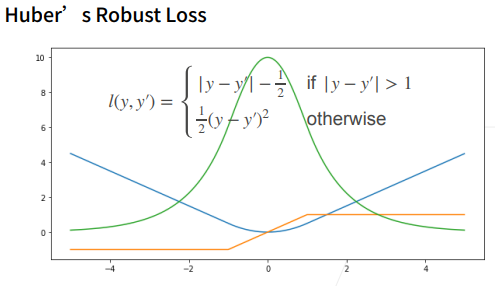
Huber Loss
其他:

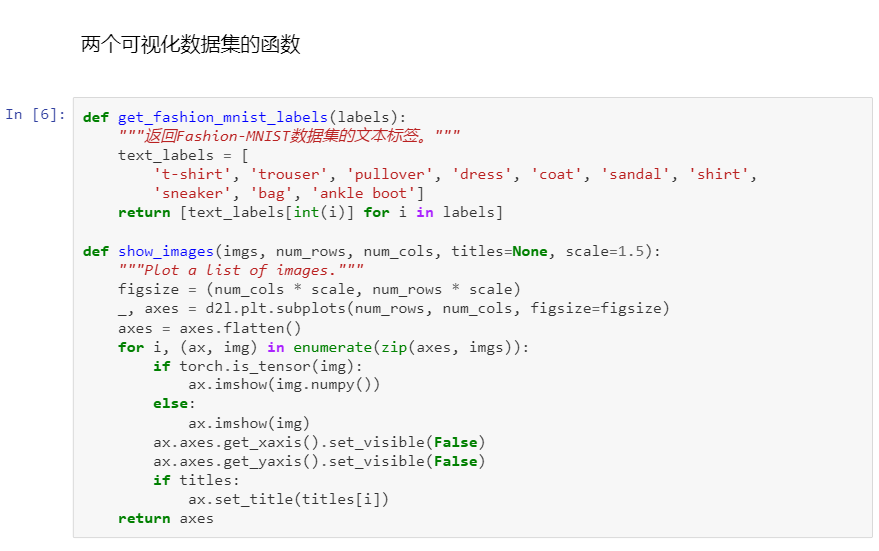
3 图像分类数据集
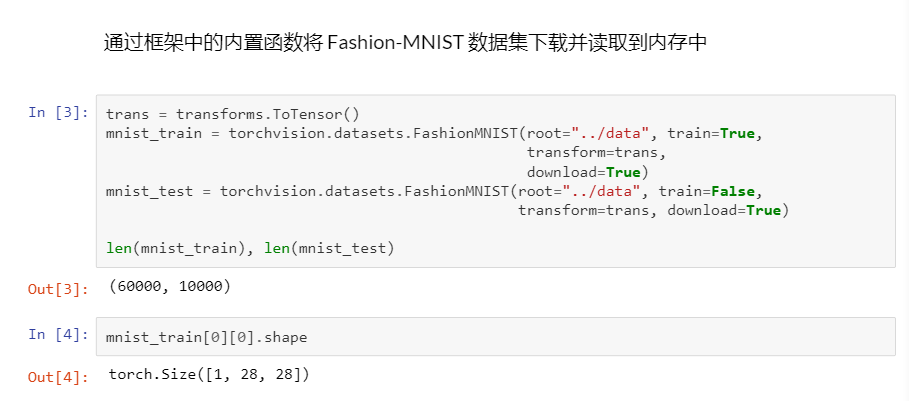
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。我们将使用类似但更复杂的Fashion-MNIST数据集
MNIST(Modified National Institute of Standards and Technology)是一个常用的手写数字识别数据集,被广泛用于测试和验证机器学习模型的性能。该数据集包含了大量的手写数字图像,涵盖了数字 0 到 9。
图像大小: 所有的图像都是28x28像素的灰度图像。
样本类别: 数据集包含 10 个类别,分别对应数字 0 到 9。
训练集和测试集: MNIST数据集通常被分为训练集和测试集,以便在模型训练和评估时使用。通常,60,000张图像用于训练,10,000张图像用于测试。
标签: 每个图像都有相应的标签,表示图像中的数字。
应用场景: MNIST数据集通常用于学术研究、演示和教学,尤其是对于深度学习初学者。它被认为是计算机视觉领域中的 “Hello World”,因为它是一个相对简单但足够复杂的问题,可以用于验证和比较不同模型的性能。
挑战性: 尽管MNIST数据集相对较小,但由于其广泛使用,它已经成为测试新模型和算法性能的标准基准之一。
在使用MNIST数据集时,研究人员和开发者通常尝试构建模型,以准确地识别手写数字。这种任务是一个经典的图像分类问题,可以使用各种深度学习模型,如卷积神经网络(CNN),来解决。

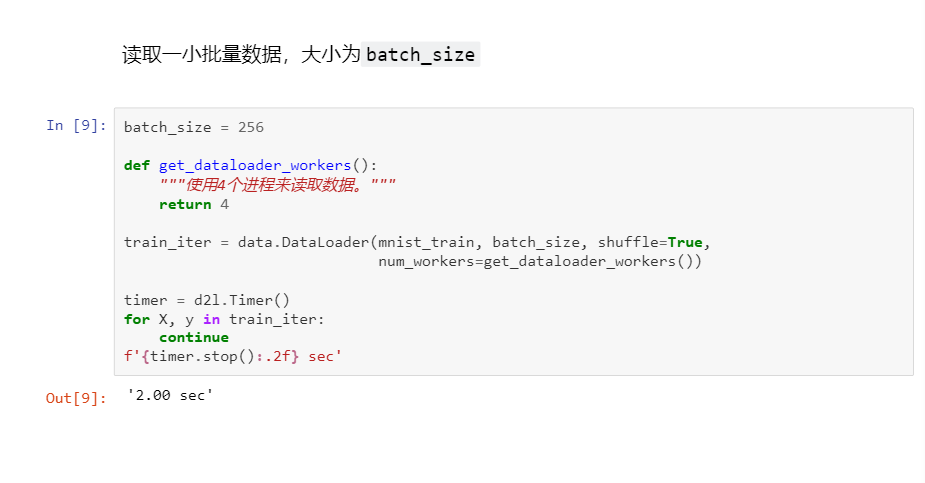
数据读取速度要比模型训练速度块。