这个模型在U-net的基础上融合了Transformer模块和残差网络的原理。
论文地址:https://arxiv.org/pdf/2303.07428.pdf
具体的网络结构如下:
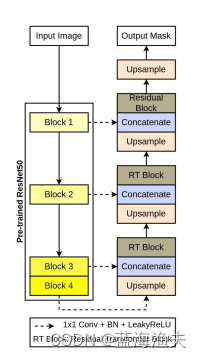
网络的原理还是比较简单的,
编码分支用的是预训练的resnet模块,解码分支则重新设计了。
解码器分支的模块结构示意图如下:
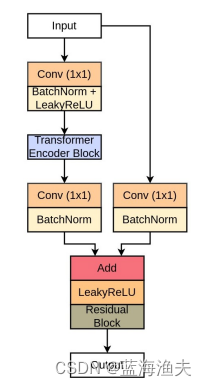
可以看出来,就是Transformer模块和残差连接相加,然后再经过一个residual模块处理。
1,用pytorch实现时,首先要把这个解码器模块实现出来:
class residual_transformer_block(nn.Module):def __init__(self, in_c, out_c, patch_size=4, num_heads=4, num_layers=2, dim=None):super().__init__()self.ps = patch_sizeself.c1 = Conv2D(in_c, out_c)encoder_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=num_heads)self.te = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)self.c2 = Conv2D(out_c, out_c, kernel_size=1, padding=0, act=False)self.c3 = Conv2D(in_c, out_c, kernel_size=1, padding=0, act=False)self.relu = nn.LeakyReLU(negative_slope=0.1, inplace=True)self.r1 = residual_block(out_c, out_c)def forward(self, inputs):x = self.c1(inputs)b, c, h, w = x.shapenum_patches = (h*w)//(self.ps**2)x = torch.reshape(x, (b, (self.ps**2)*c, num_patches))x = self.te(x)x = torch.reshape(x, (b, c, h, w))x = self.c2(x)s = self.c3(inputs)x = self.relu(x + s)x = self.r1(x)return x其中我们需要注意的是这里构建Transformer块的方法,也就是下面两句:
encoder_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=num_heads)
self.te = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)首先,第一句是用nn.TransformerEncoderLayer定义了一个Transformer层,并存储在encoder_layer变量中。
nn.TransformerEncoderLayer的参数包括:d_model(输入特征的维度大小),nhead(自注意力机制中注意力头数量),dim_feedforward(前馈网络的隐藏层维度大小),dropout(dropout比例),apply(用于在编码器层及其子层上应用函数,例如初始化或者权重共享等功能)。
第二句则是将多个Transformer层堆叠在一起,构建一个Transformer编码器块。
nn.TransformerEncoder的参数包括:encoder_layer(用于构建模块的每个Transformer层),num_layer(堆叠的层数),norm(执行的标准化方法),apply(同上)。
2,在上面的解码器模块中,还有一个residual block需要额外实现,如下:
class residual_block(nn.Module):def __init__(self, in_c, out_c):super().__init__()self.conv = nn.Sequential(nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),nn.BatchNorm2d(out_c),nn.LeakyReLU(negative_slope=0.1, inplace=True),nn.Conv2d(out_c, out_c, kernel_size=3, padding=1),nn.BatchNorm2d(out_c))self.shortcut = nn.Sequential(nn.Conv2d(in_c, out_c, kernel_size=1, padding=0),nn.BatchNorm2d(out_c))self.relu = nn.LeakyReLU(negative_slope=0.1, inplace=True)def forward(self, inputs):x = self.conv(inputs)s = self.shortcut(inputs)return self.relu(x + s)这个代码就是简单的残差卷积模块,不赘述。
3,重要的模块实现完了,接下来就是按照UNet的形状拼装网络,代码如下:
class Model(nn.Module):def __init__(self):super().__init__()""" Encoder """backbone = resnet50()self.layer0 = nn.Sequential(backbone.conv1, backbone.bn1, backbone.relu)self.layer1 = nn.Sequential(backbone.maxpool, backbone.layer1)self.layer2 = backbone.layer2self.layer3 = backbone.layer3self.layer4 = backbone.layer4self.e1 = Conv2D(64, 64, kernel_size=1, padding=0)self.e2 = Conv2D(256, 64, kernel_size=1, padding=0)self.e3 = Conv2D(512, 64, kernel_size=1, padding=0)self.e4 = Conv2D(1024, 64, kernel_size=1, padding=0)""" Decoder """self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)self.r1 = residual_transformer_block(64+64, 64, dim=64)self.r2 = residual_transformer_block(64+64, 64, dim=256)self.r3 = residual_block(64+64, 64)""" Classifier """self.outputs = nn.Conv2d(64, 1, kernel_size=1, padding=0)def forward(self, inputs):""" Encoder """x0 = inputsx1 = self.layer0(x0) ## [-1, 64, h/2, w/2]x2 = self.layer1(x1) ## [-1, 256, h/4, w/4]x3 = self.layer2(x2) ## [-1, 512, h/8, w/8]x4 = self.layer3(x3) ## [-1, 1024, h/16, w/16]e1 = self.e1(x1)e2 = self.e2(x2)e3 = self.e3(x3)e4 = self.e4(x4)""" Decoder """x = self.up(e4)x = torch.cat([x, e3], axis=1)x = self.r1(x)x = self.up(x)x = torch.cat([x, e2], axis=1)x = self.r2(x)x = self.up(x)x = torch.cat([x, e1], axis=1)x = self.r3(x)x = self.up(x)""" Classifier """outputs = self.outputs(x)return outputs其中,x1,x2,x3,x4就是编码器模块,用的都是resnet50的预训练模块。
其中r1,r2,r3,r4则是解码器的模块,就是上面实现的模块。
而e1,e2,e3,e4则是在skip connection前给编码器的输出做1x1卷积,作用大体上就是减少计算量。
完整代码:https://github.com/DebeshJha/TransNetR/blob/main/model.py#L45