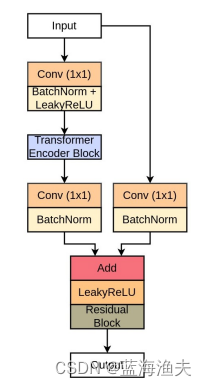
随着Open AI公司推出的Sora文生视频模型惊艳亮相互联网,AI语音克隆创企ElevenLabs又为Sora的演示视频生成了配音,所有的音效均由AI创造,与视频内容完美融合。

ElevenLabs的语音克隆技术能够从一分钟的音频样本中创建逼真的声音。为了实现这一功能,系统需要大量的语音数据来学习和模仿各种语音特征。高质量的数据集可以提供丰富的语音细节和变化,使得语音克隆技术能够更准确地复制和生成逼真的声音。
ElevenLabs的文本转语音模型依赖于大量的文本和语音数据来训练其深度学习模型。高质量的数据集可以提供准确的文本和相应的语音样本,帮助模型更好地理解文本和语音之间的对应关系,从而生成更自然、更准确的语音输出。
无论是使用语音克隆技术还是文本转语音模型,ElevenLabs都需要生成高质量的音频输出。高质量的音频样本用于大模型训练,可以使得生成的音频更加清晰、逼真,满足用户的需求。
景联文科技自有45万高质量真人普通话音频数据,涵盖了网文小说、出版物的有声书和各类影视广播剧。其中有声小说音频包含单播、双播和多播多种类型,覆盖了不同说话人、不同语速和不同语调等情况。
该数据集提供了丰富、清晰、准确的语音语料,主播不仅涵盖了男女老少真人的口音和不同语速,还包括了不同的情感、语调和表达方式。经过我司严格的筛选和编辑,确保音频的品质和格式符合大模型训练的需求。数据准确率 99%,所有数据均经过严格流程质检。
景联文科技是大语言模型数据供应商,拥有丰富的语音数据采集项目经验,也自建了专业的语音采集录音室,有高度还原真实场景能力,在全国30多个省市有近一万人的被采集人员储备,全球范围内也有采集渠道,支持多语种、多方言语音采集。支持语音识别ASR采集、语音合成TTS采集、唤醒词采集、多人对话采集、车载语音采集、普通话采集、方言采集、英语采集、小语种采集、近远场采集、语音VAD采集等。
支持AI算法预处理,支持本地化部署和SAAS服务。通过智能化的标注平台产品赋能AI训练数据行业,能够有效提高人机协作效率扩大产能,及时调整方案做好逾期风险管控,准确把控数据质量问题,为语音相关企业提供处理大规模语音数据的能力,节省企业的时间和开发成本,实现人力驱动向技术驱动的重要升级,为行业赋能。
景联文科技|数据采集|数据标注|大语言模型数据集
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。

![[杂谈]QtCreator调试输出窗与chromium的调试输出窗](https://img-blog.csdnimg.cn/direct/9ded9aafc4744336a28cca905be48f9f.png)