引言
通用文档理解,是OCR任务的终极目标。现阶段的OCR各种垂类任务都是通用文档理解任务的子集。这感觉就像我们一下子做不到通用文档理解,退而求其次,先做各种垂类任务。
现阶段,Transformer技术的发展,让通用文档理解任务变得不再是那么遥不可及,伴随而来的是出现了很多OCR-free的工作。
该部分的工作可以分为三个阶段:
- 监督类的方法,像LayoutLM系列
- 只有Transformer结构
- 结合了LLM做通用文档理解
本篇文章着重梳理第2点和第3点涉及到的OCR-free的通用文档理解的工作。行文难免挂一漏万,还望大家多多指教。
⚠️注意:行文顺序是从新到旧
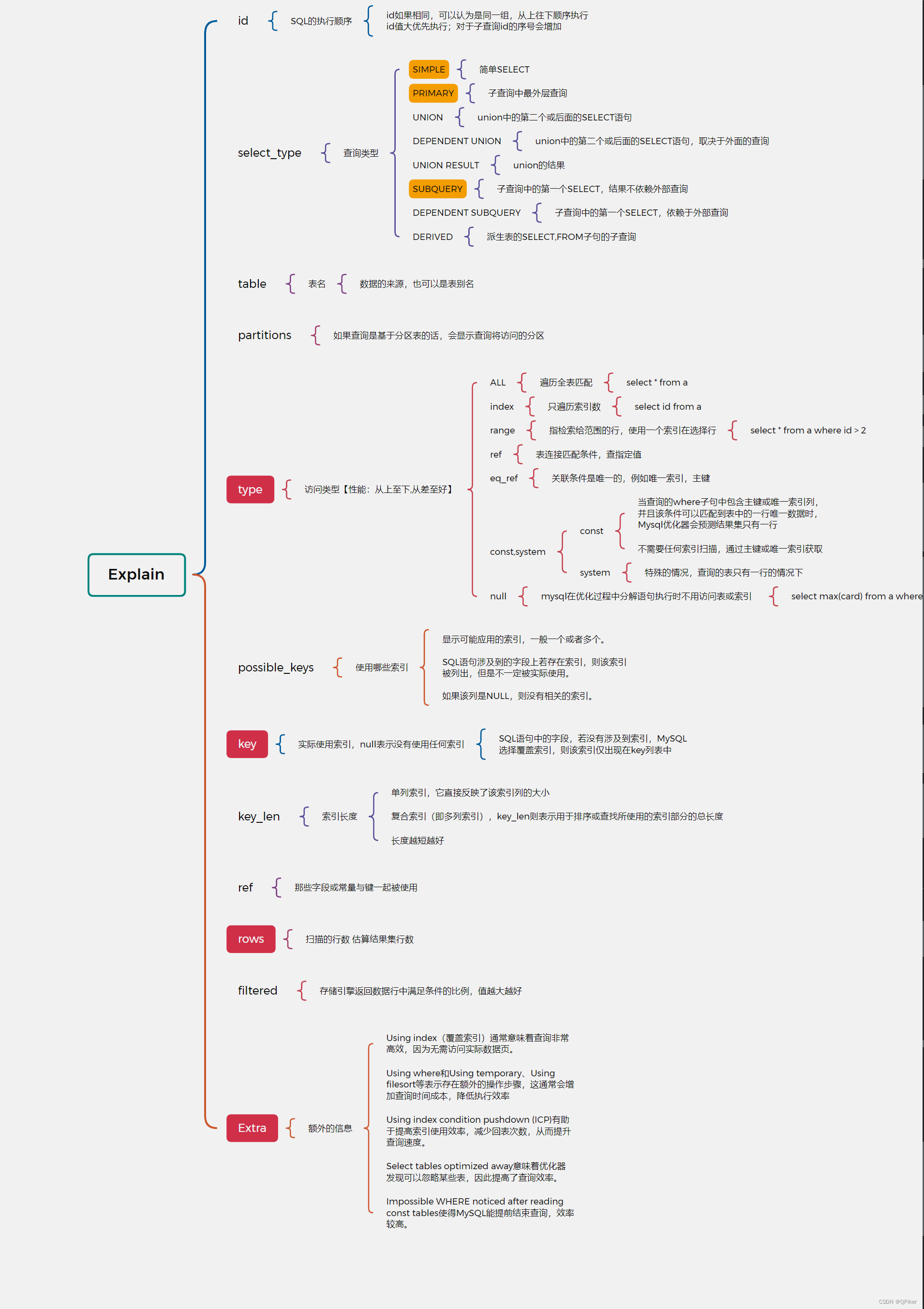
(2024 TextMonkey) TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
code: https://github.com/Yuliang-Liu/Monkey

TextMoneky工作源于之前Moneky的工作,主要贡献点有以下几点:
- 通过使用sliding window将原始图像划分为non-overlapping 448x448 patches的方式,间接地增加了输入图像的尺寸
- 为了增加多个window patches彼此之间的connections, 作者引入了Shifted Window Attention层,插入到多个Endcoder Layer中间
- 提出了Token Sampler,用于找到其中真正起到关键作用的tokens,减少计算量。这一点有一个假设前提:image包含冗余的tokens
- 为了减少模型的幻觉,作者添加了一些额外的training task,例如:text spotting和reading text任务。这些任务可以确保模型学到text和location data之间的关系。
- 论文还探索了作为App Agent的潜力
PS: 整个工作还是比较间接有效,唯一有些缺憾的是相关中文数据用的较少,在中文上效果较差。
(2023 DocPedia) Docpedia: Unleashing the power of large multimodal model in the frequency domain for versatile document understanding
code: 无

DocPedia中Pedia的意思是百科的意思。该篇工作并没有开源相关代码,认真看的动力一下子小了不少。主要亮点有二:
- 仍然着眼于输入图像尺寸问题。这次可以直接输入 2560 × 2560 2560 \times 2560 2560×2560的图像尺寸。借助了JPEG DCT模块来提取DCT系数。这部分参见下图:

- 两阶段的训练方法。

PS: DocPedia中处理大尺寸的图像方法的确打开了思路,值得借鉴。
(2023 TGDoc) Towards improving document understanding: An exploration on textgrounding via mllms
code: https://github.com/harrytea/TGDoc

该篇工作着眼于多模态LLM的text-grounding能力。通俗来说,就是MLLM对图像中文本位置感知能力:可以感觉输入的prompt,来得到图像中对应文本的坐标。可以参考下图例子,就很清楚了:

本文工作主要做了两点:
- 探索在没有引入额外的文本检测能力前提下,MLLM中text-grounding的能力
- 通过PaddleOCR构建了一个99K PPT数据集和GPT-4 构建了12K高质量数据集。
(EMNLP2023 UReder) UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model
code: https://github.com/LukeForeverYoung/UReader

UReader的工作和mPLUG-DocOwl有重合部分,也是通过一个统一的instruction format,在广泛的Visually-situated Language Understanding任务中fine-tuned得来。
亮点部分有两个:
-
为了增强visual text和semantic understanding的能力,作者添加了两个额外的任务,但是是一样的输入格式。这两个任务是text reading和key points generation任务。
-
由于现有的vision encoder是frozen,也就是说训练过程中不训练该部分,所以其输入图像的尺寸较小,一般是 224 × 224 224 \times 224 224×224。作者提出了shape-adaptive cropping module来动态将输入vision encoder的high-resolution图像切分为合适几块。

Shape-Adaptive Cropping Module,让我想到了目标检测任务中Anchor的做法,先预设一些分割类型块,然后根据IoU计算,挑选合适的分割块。
也让我想到了在做一些遥感类目标检测任务时,由于图像过于大,没有办法一下子输入到模型中去,只好使用一个滑动窗口,overlapping切分该图。
这部分工作和Moneky中的做法不谋而合。相比于Moneky,UReader反而做的更加精细一些。下图是Moneky做法,可注意看从右下角部分。

在论文最后部分,作者提到了当前工作的局限部分:当前做法是将切分得到的图像都同等看待,送入后续模型中,但是一张图像中并不是所有子图像都是有效的。可以考虑用度量的方法也动态决定将有效的图像块送进去。这一点在TextMoneky中的 Token Sampler模块有异曲同工之妙。
(2023 mPLUG-DocOwl) mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
code: https://github.com/X-PLUG/mPLUG-DocOwl

mPLUG-DocOwl是在mPLUG-Owl基础上,基于统一的instruction tuning,来平衡language-only, general vision-and-language和document understanding三个任务。

使用的统一的instruction tuning是:<image>Human:{question} AI:{answer},不同的文档理解数据集都会通过替换{questiong}和{answer}两个关键字段来统一为以上格式。
同时,论文中构建了一个指令理解(instruction understanding)的测评集,名为LLMDoc,来评估多样文档理解能力。
PS: 本篇工作主要贡献点就只有上述两个地方。值得称赞的是,开源的相关的代码和模型,为后续学者研究提供了极大便利。
(2023 UniDoc) Unidoc: A universal large multimodal model for simultaneous text detection, recognition, spotting and understanding
code: 无

UniDoc是一个可以同时做文本检测、文本识别和文档理解的多模态模型。具体所做的任务如下图:

UniDoc,在我看来,算是第一个用LLM做OCR任务的。因此,该论文主要工作在于构建了instruction following数据集,但是没有开源。同时代码和模型权重也没有开源。这让我有些难以评论哈!
由于UniDoc输入图像尺寸是224x224的,因此不能提取fine-grained visual features。这一点也是其后续工作的主要创新点。
(2023 Vary) Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
code: https://github.com/Ucas-HaoranWei/Vary

该篇工作着眼于dense and fine-grained vision perception任务,例如文档级别OCR和图表理解任务。这一点和Nougat工作有些类似。论文主要可分为两个阶段:
- 设计一个vocabulary network,通过自回归的方式产生所需要的vocabulary
- 将上一阶段的new vocabulary与LLM中现有的vanilla vision vocabulary融合,使得LLM获得新的能力。
因为在第一阶段训练Vary-tiny时,image encoder用的是在ViTDet上训练所得SAM-base模型,所以其输入图像尺寸是1024x1024x3。这一点可以有效缓解文档类图像在较小尺寸下输入,文字模糊变形问题。但是并未从实际上提高模型的输入尺寸。
PS: 整个Vary工作,我个人认为最大的一点价值是提供了合成中文文档数据的思路,但是并未开源任何合成的相关代码,同时也未开源其模型。 这也难怪后续的工作,很少有与Vary做对比的。这一点从TextMoneky工作中就可看出来。因为Vary用了私有数据集,模型也未开源,所以不能相比。
(2023 Pix2struct)Pix2struct: Screenshot parsing as pretraining for visual language understanding
code: https://github.com/google-research/pix2struct

该篇工作主要是将网页上masked screenshots转换简单的HTML代码,示例图如上面所示,第一列是模型的输入,第二列是模型对应的输出结果。首次证明了一个模型在多个不同visual-language understanding任务中都能取得较好效果。
Pix2struct是基于ViT的标准image-encoder-text-decoder结构,论文中并没有给出具体框图,只是说明了相对于标准的结构,做了哪些改变:
- 由于观察到在一些visual-language task中,对同样图像,输入不同aspect ratio图像,结果有很大影响。因此作者在保持宽高比的基础上,对图像做了scaling,具体做法可参考下图:

- 为了能够处理图像中variable resolutions unambiguously,作者引入了2维绝对位置embedding。直白一些,就是加入了位置编码。
以上两点,使得标准的ViT网络更加鲁棒。
值得注意的是,Pix2struct是针对不同任务,都需要重新训练对应的模型。也就是说,我有6个不同visual-language tasks,我就需要分别训练对应6个模型,虽然这6个模型的网络结构是一样的。
PS: 整篇文章看得我有些懵逼,始终没有找到用了多少数据训练的。🤦🏻♀️
(2023 Nougat) Nougat: Neural Optical Understanding for Academic Documents
code: https://github.com/facebookresearch/nougat

该篇工作基于Donut,整个网络结构都是来自Donut。因此该篇工作的主要贡献不在算法侧,而是在于数据侧,主要有以下三点:
- 训练了pre-trained model,可以转换PDF到轻量的mardown格式,包括PDF中表格和公式
- 通过构造了一个完整pipeline,来构造一个将PDF转换为对应MMD格式的数据集
- 该方法其输入仅仅是图像,且能够处理扫描的论文和书籍
对于以上三点,我个人最能受益的是第2点。可以说,构造PDF → mmd格式数据集是整个问题的关键。这一点在后续OCR-free与LLM结合的工作中,体现的更加明显。我自己的确也真正跑通了构造数据集的代码,并得到了大约34w 英文文档数据集。在这里不得不为Nougat的工作点赞。

(ECCV 2022 Donut) OCR-free Document Understanding Transformer
code: https://github.com/clovaai/donut

该工作将OCR中多个子任务都集成到了一个End-to-End的网络中,网络是基于transformer的编解码结构。这应该是第一篇将Transformer 编解码结构应用到整个OCR任务中的工作,包括文档分类、文档信息提取和文档问答三个任务。
虽然之前有基于Transformer的文本识别工作–TrOCR,但是也仅仅限于文本识别这一个单一任务。与之前工作相比,Donut与之前工作的差异,可以用下图中清晰体现出来:
Donut的结构有些像Text Spotting任务(检测和识别都在一个模型中完成),但是Donut做的要比Text Spotting任务更进一步。Text Spotting任务只是将图像中文本和对应框坐标提了出来,并没有做进一步操作,而Donut则是在理解图像中文本内容基础上做结构化内容任务。
下图就是Text Spotting任务常见结构图(选自PGNet):

值得一提的是,论文中提出了一种合成文档数据的Pipeline-- SynthDoG。这为后续开展进一步研究提供了极大的便利。

PS: 这篇工作可谓是经典之作,打开了新思路。