Zilliz AI 初创计划是面向 AI 初创企业推出的一项扶持计划,预计提供总计 1000 万元的 Zilliz Cloud 抵扣金,致力于帮助 AI 开发者构建高效的非结构化数据管理系统,助力打造高质量 AI 服务与运用,加速产业落地。访问https://zilliz.com.cn/了解更多。
携程集团(Trip.com Group) 是全球领先的一站式旅行平台,旗下的平台可面向全球用户提供一套完整的旅行产品、 服务及差异化的旅行内容,能够提供超过 120 万种全球住宿服务。
而随着携程用户需求和搜索行为日趋复杂多样化,基于文本匹配的检索方法已经不能够很好地满足用户在个性化精准搜索方面的需要。其中比较常见的问题有多义词问题。基于文本的检索方法主要依赖于关键词匹配进行搜索和排序,所以会忽视搜索意图背后更深层次的语义信息,导致对搜索结果的准确性和召回率的性能上有较大的影响。例如,查询“苹果”可以指代水果,也可以指代科技公司。同时,传统的搜索引擎在处理长尾查询上也往往出现召回效果不佳的情况。
此外,酒店搜索还会涉及到丰富的信息维度,如酒店的位置、房间类型、标签、评价等。传统的文本匹配方法难以有效整合和利用这些多维信息,对于多条件的精确搜索和筛选也有一些乏力。搭建向量引擎可以有效地解决上述问题,本文将详细介绍向量引擎在携程酒店搜索中的应用场景和相关经验。
01.当前局限性剖析
局限性之一:用户和商户表述差异
搜索引擎的索引数据是基于携程酒店搜索引擎团队采集的酒店信息、设施信息、地理信息等基础数据建立的。然而,不同用户的搜索习惯因人而异,商户和用户的描述也存在差异,不同商户在维护信息时也会千差万别。因此,搜索引擎需要具备一定的语义理解能力,使其能够顺利的在用户搜索输入和商户维护词汇之间进行匹配,以便准确地召回用户最想要的结果。
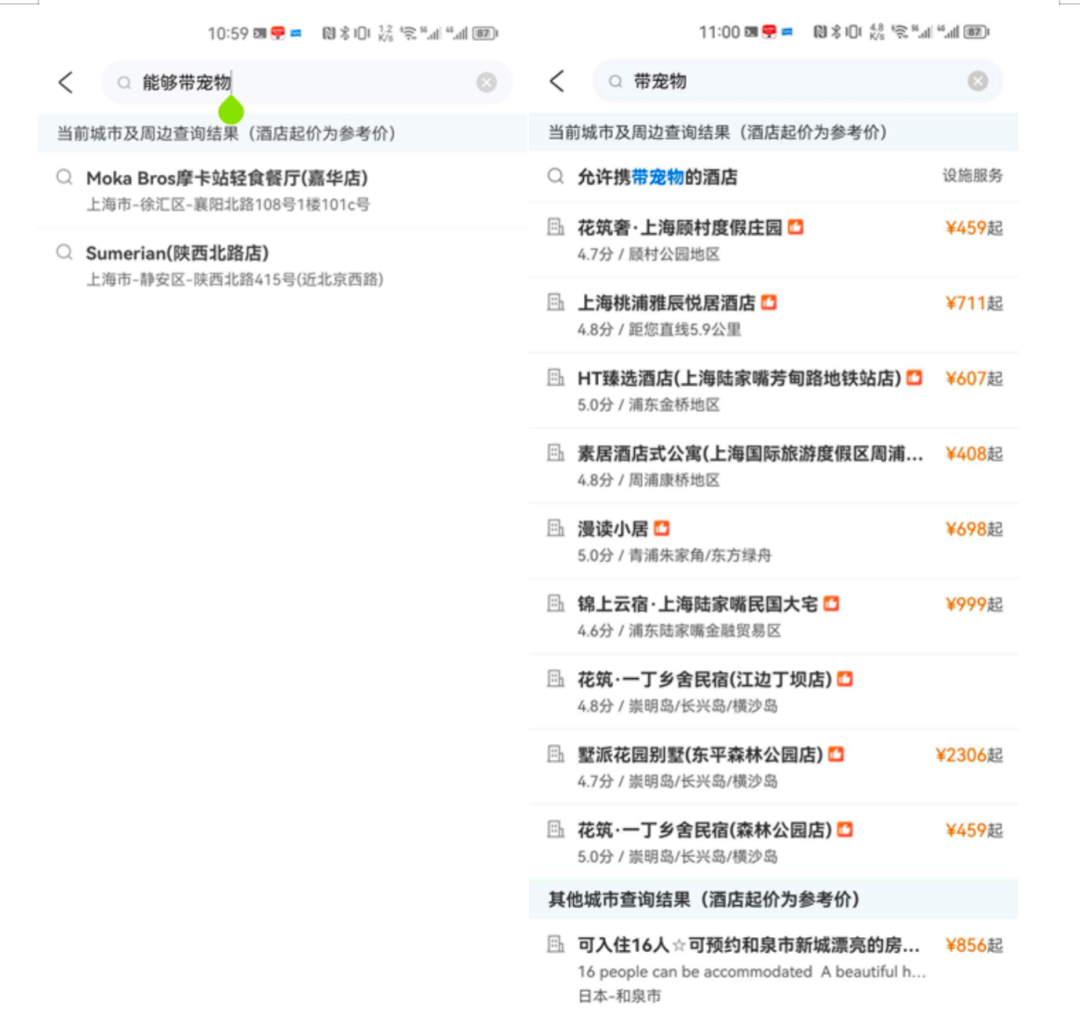
举个例子,如果商户维护了一个名为"带宠物"的设施服务标签,如果有一部分用户的输入是"能够带宠物",相关的设施服务和酒店就无法被搜索到。以往的常规解决方案是给"带宠物"标签添加别名"能够带宠物",这样可以通过关联别名来解决用户和商户之间的表述差异,使得不同的搜索输入能够召回同一类型的结果。然而,这种方法存在一定的局限性。别名的选择依赖于现有搜索词的点击情况,如果搜索引擎中没有某个词,那么该词就不会被展示出来,从而无法产生点击行为,那么该别名就无法被发掘到。
局限性之二:不同语种的表述差异
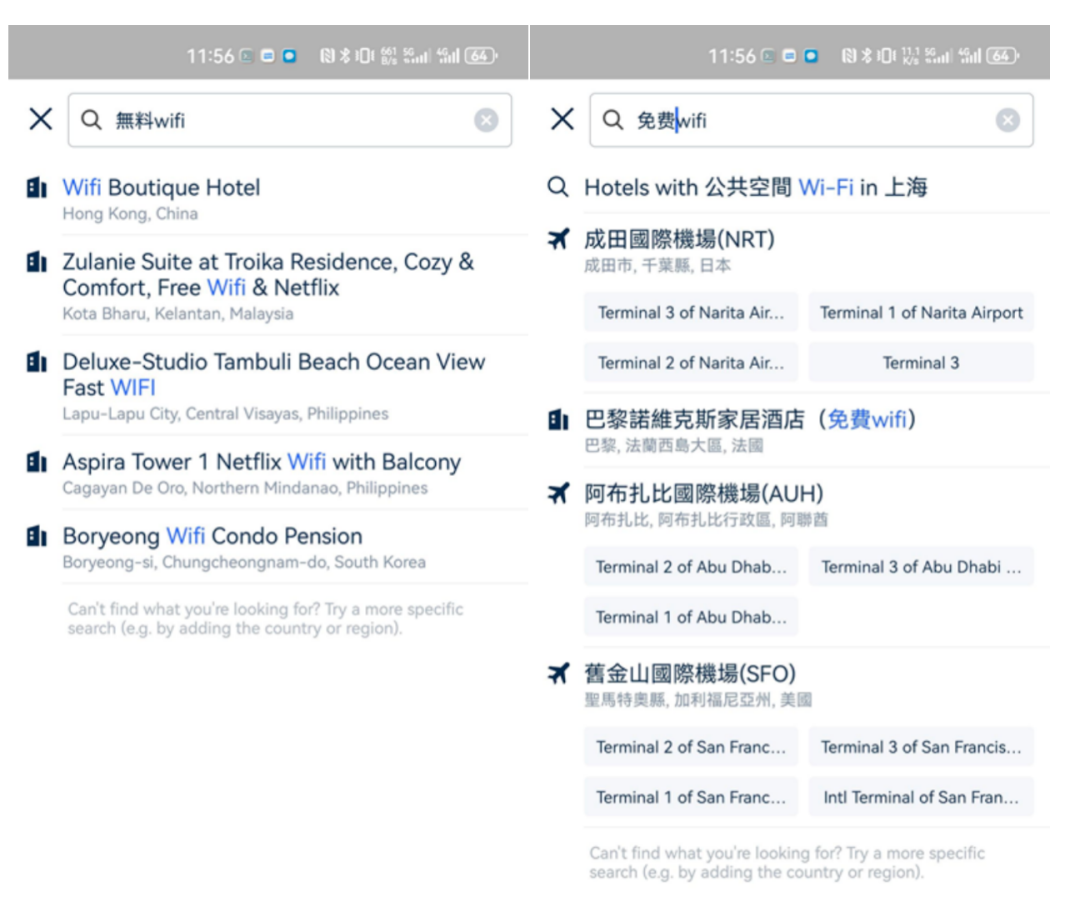
举个例子,在携程海外搜索场景中,如果在多语言标签库中没有维护"無料Wi-Fi",搜索"無料Wi-Fi"时,搜索结果中就没有相关的酒店设施标签。在这种情况下,"無料"一词在日语中意味着免费,"無料Wi-Fi"实际上想要表达的是可以免费使用的无线网络连接。然而,如果没有维护多语言的标签名称,搜索引擎将无法正确识别用户的意图,导致搜索结果不准确。
为了解决这个问题,团队的解决方案是补充维护更多不同语言的标签信息,例如将设施标签的日文表达"無料Wi-Fi"添加到搜索引擎中。但这种方法依赖于翻译库的准确度和丰富度。由于词库庞大,很多词无法进行人工翻译,可能只能依靠机翻,这就存在准确度的问题,翻译的准确性对于能否搜索到所需内容有很大影响。
局限性之三:不同背景下的音译表述差异
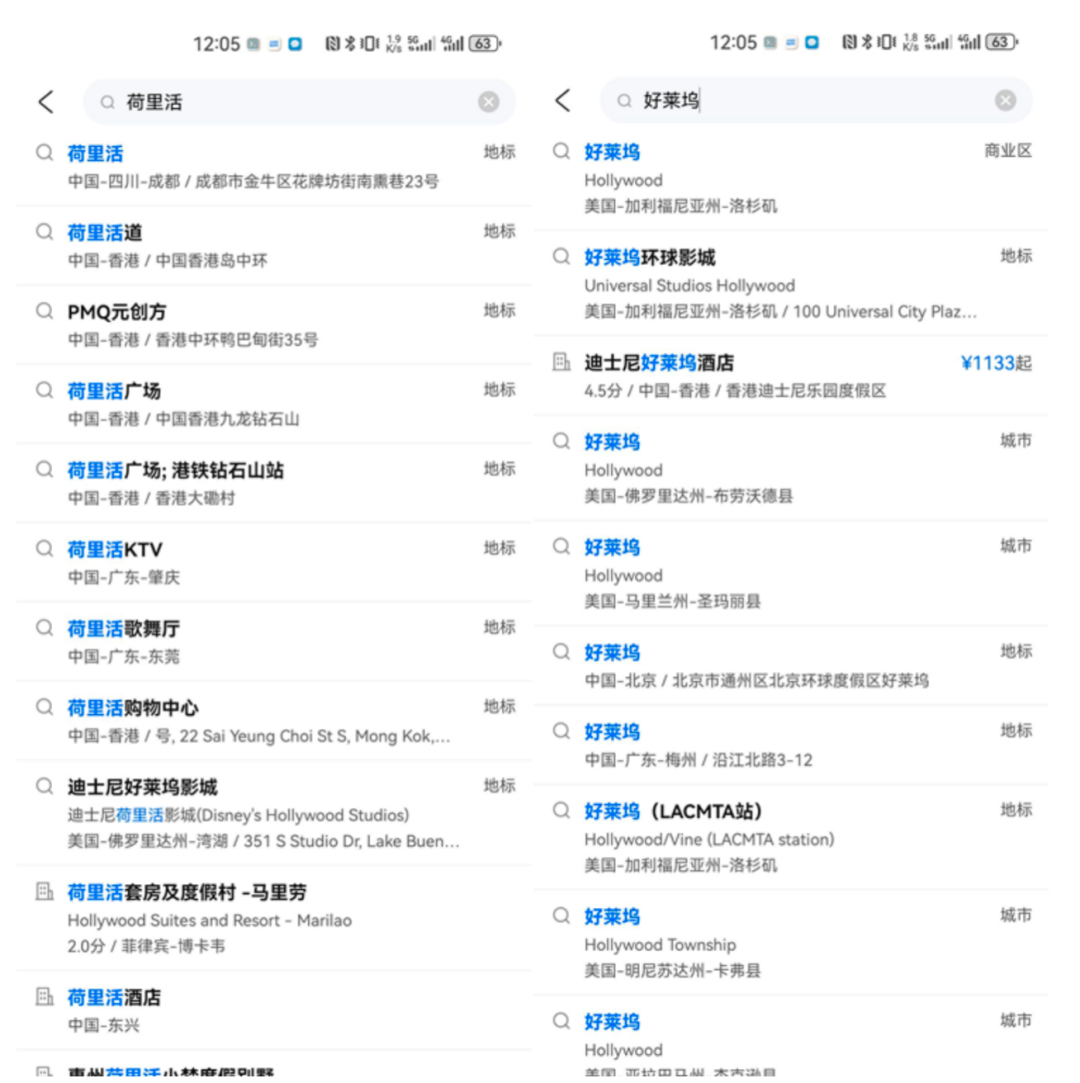
由于音译表述的差异,用户可能使用不同的拼写或注音来搜索同一个词或短语。如果搜索引擎无法正确理解用户的音译表述,用户换一种音译翻译词搜索就无法找到相应的结果,可能会导致搜索结果的相关性和准确性下降。举个例子,当用户搜索"荷里活"时,搜索结果可能全是中国的地标,而当搜索"好莱坞"时,则会正常召回美国好莱坞的相关结果。
常规的解决方案是添加同义词"好莱坞"和"荷里活"之间的关联,例如将"荷里活"作为"好莱坞"的别名,并在商区实体维护中进行相应的标注。这样可以确保搜索引擎既能召回相关结果,又能保证结果的排序准确性。但是由于音译词组合的多样性,有可能导致指数级别的爆炸问题,搜索引擎会承受的巨大索引压力,且收益不佳。
02.向量引擎的前期调研
通过上面的问题分析,可以看到,携程酒店搜索面临着泛化召回和模糊召回的场景需求。为了能够满足需求,团队考虑了使用向量查询来帮助实现更准确的搜索。向量查询是一种基于向量空间模型的信息检索方法,其基本思想是将查询和文档表示为向量,通过计算它们之间的相似度来确定匹配程度,以此来召回与查询最相关的文档。
为了初步验证向量化能否解决问题,团队做了一个简单的初步验证:通过调用 OpenAI 的 text-embedding-ada-002 模型来获取查询词(query)和酒店名(item)的向量表示,并利用这些计算向量之间的余弦相似度。一般在语义上越是相似的词,其向量之间的相似度越高。可以根据计算向量的相似度,评估文本之间所包含的语义相似度。
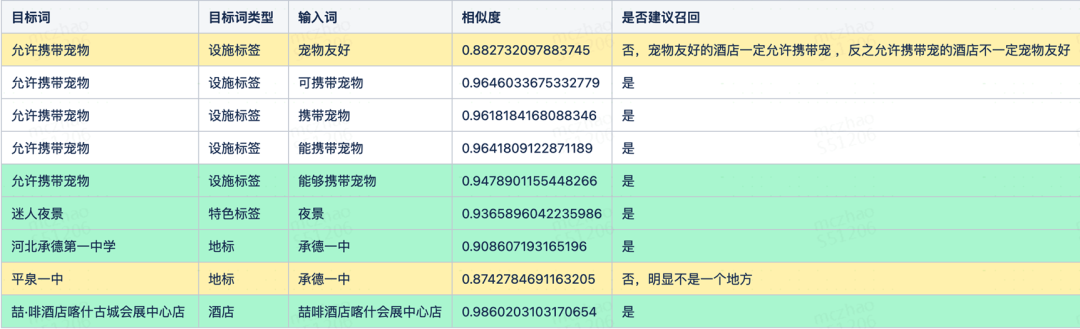
从验证结果来看,通过对比不同词语的向量相似度,可以区分出具有相同含义的词语和语义有差异的词语。那么向量相似度可以作为携程酒店搜索提供更准确的语义相似度衡量方式,引入向量引擎来改进携程酒店搜索结果的质量是一种可行方案。
03.向量引擎的架构设计
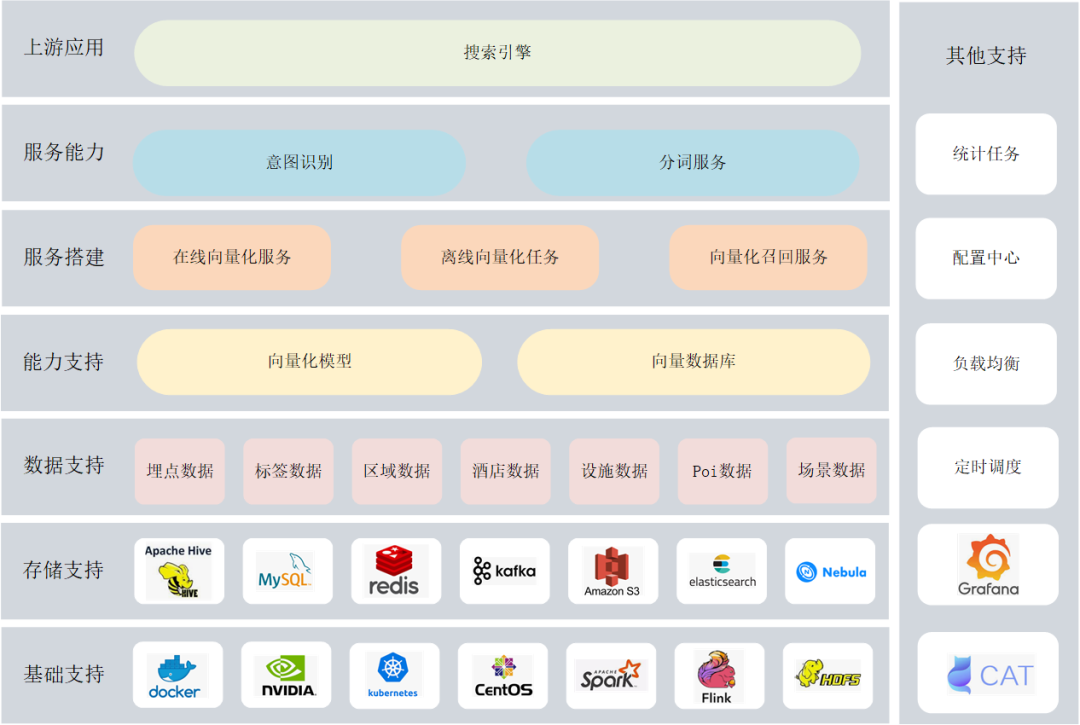
04.技术选型
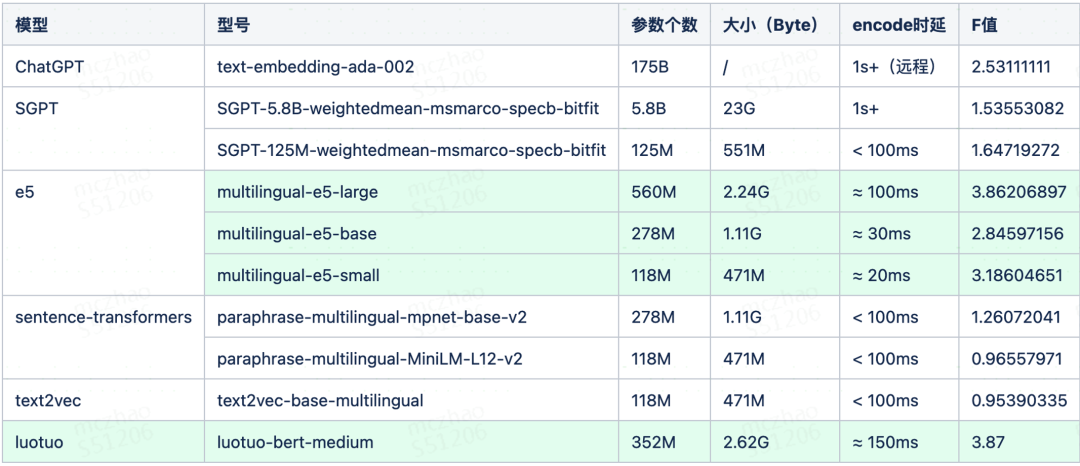
向量化模型选型
向量化模型是我们实现向量引擎的第一块基石。团队对比了一些常见的语言向量化模型,就准确率而言, multilingual-e5 和 Luotuo 都表现出相对较高的准确率。
dmultilingual-e5 在多语言处理方面具有更好的表现,相比之下,Luotuo 在小语种处理方面表现不佳。就性能而言,大模型(超过 1B 参数)的在线推理速度较慢,不适合实时调用。所以综合考虑准确率和性能两方面原因,团队最终选择了 multilingual-e5 模型作为语言模型。
向量数据库选型
向量数据库则是支撑向量引擎进行向量检索的的另一大基石。根据市场上的选择,向量引擎可分为三类:向量索引组件+自建服务、专用向量数据库和传统引擎+向量索引组件。

在进行技术选型时,携程酒店团队对向量引擎的几种实现方式进行了分类和对比,以便于根据具体需求和考虑因素来选择最适合的向量引擎,以此满足开发和业务的需求。
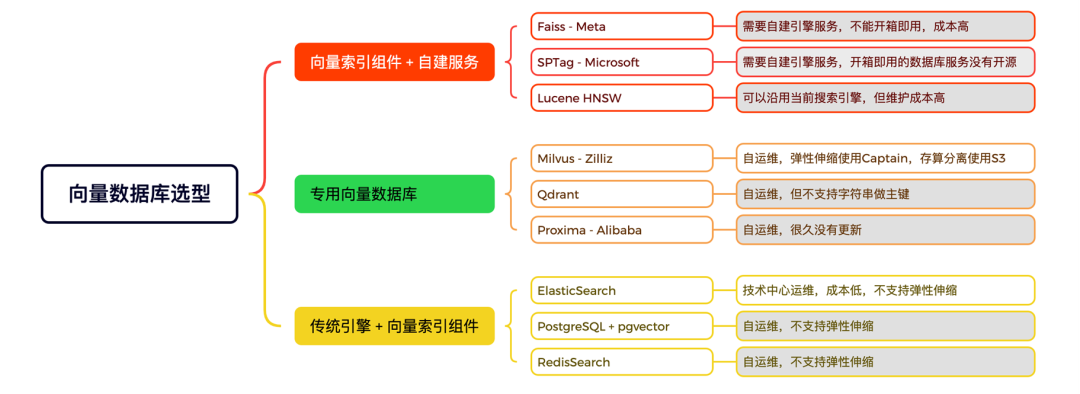
对于向量索引组件+自建服务的方式上来说:为适应具体的应用场景和数据特点,可能需要更多时间的学习组件及额外编写代码处理索引的构建更新等,这可能增加了使用和维护的难度。传统引擎+向量索引组件这个方向上,公司的基础服务部门如果有这方面的支持,对于使用方来说,也是一种比较省力的办法。还有一个方向是使用专用向量数据库,所谓专业的工具做专业的事,可以实现事半功倍的效果。
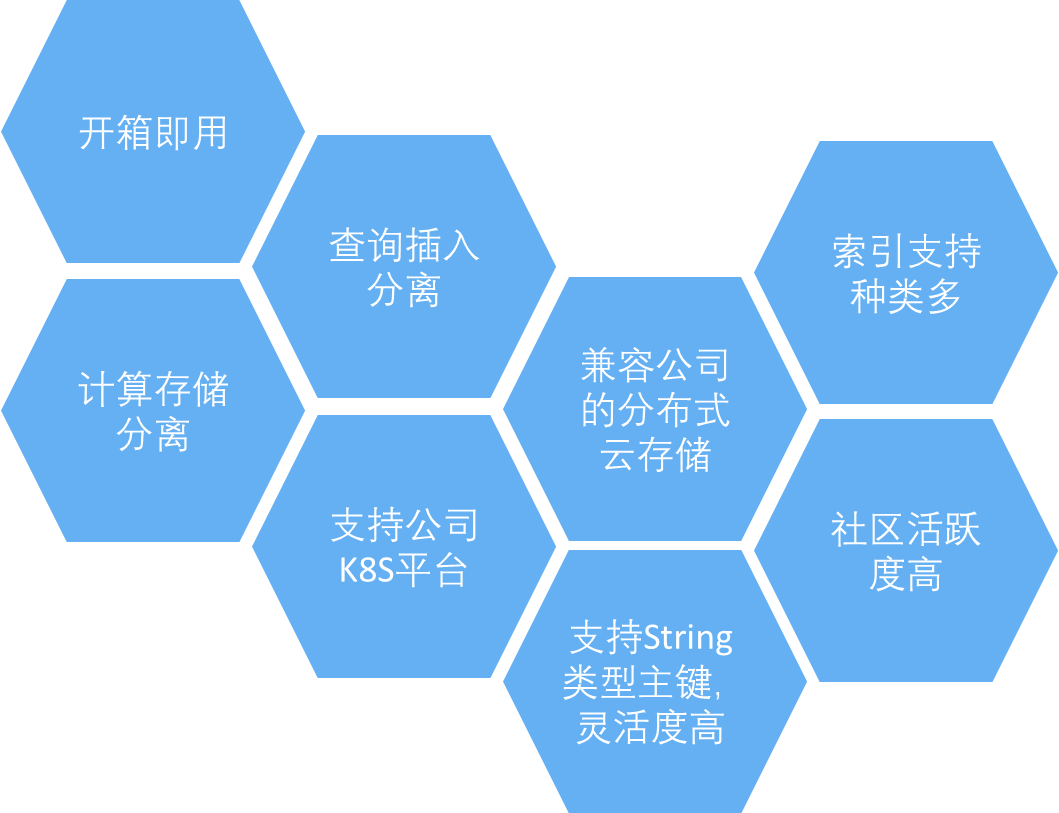
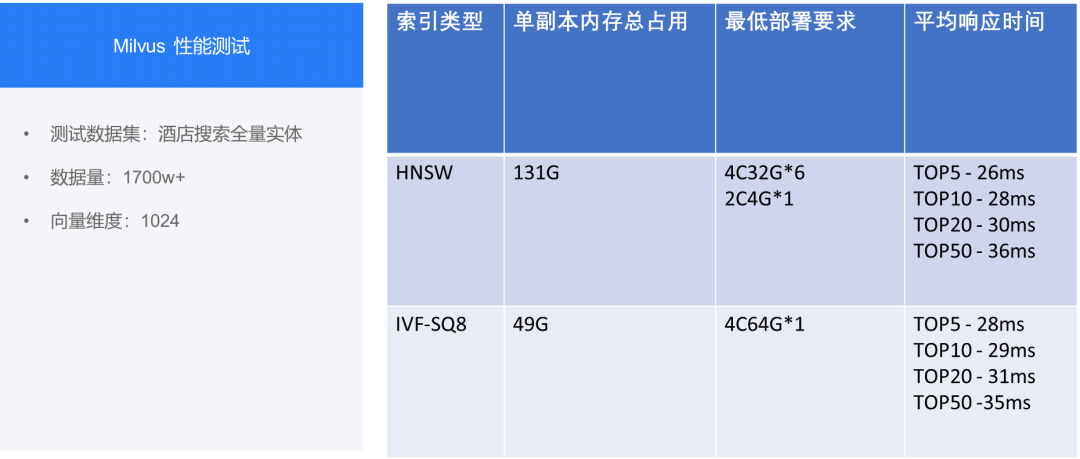
经过上面的对比,团队选择将 Milvus 作为向量引擎,原因如下图所示:
在服务能力上,为了确保能够满足接口服务的响应时间要求,团队对 Milvus 进行了相关性能测试。从测试环境下的测试结果可以看到,两种索引均能保证在 30ms 左右召回。IVF-SQ8 索引占用内存相对较少,优点是可实现单机部署,但该索引方式在召回性能上会略差于 HNSW,可根据实际需求平衡选择哪种索引结构做向量数据存储。
05.向量引擎搭建实现
向量化服务
向量化服务主要包含三个方面的工作,即在线向量服务、实体数据离线向量化和向量化召回服务。
在线向量服务:通过文本在线向量化服务,用户可以将文本数据转换为数值向量表示,从而方便进行文本相似度计算等任务。使用的是 multilingual-e5 预训练的文本向量模型,可以直接使用这些模型进行文本向量化,无需自行训练。
实体数据离线向量化:该服务将实体数据转化为向量形式并做持久化,以便后续的向量检索和召回使用。
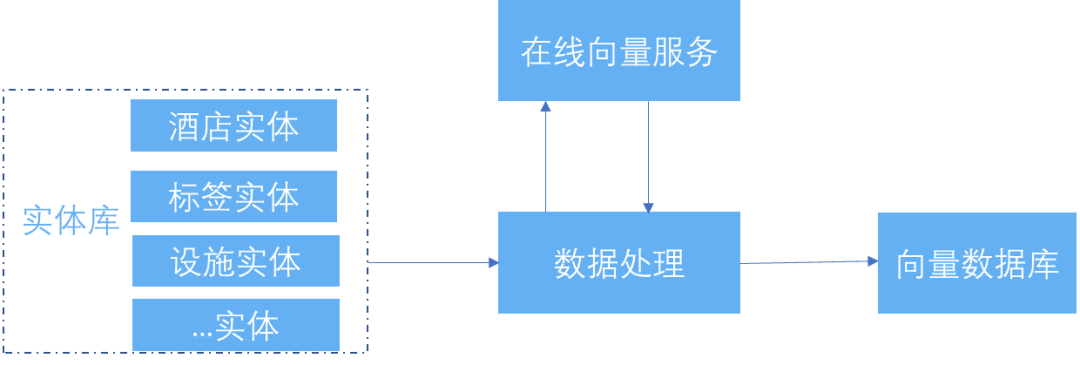
向量化召回服务:向量化召回服务会对召回的向量会进行相关的依赖检查,确保召回的实体满足业务需求。最终,该服务会返回 TOPK 个最相似的满足依赖检查的实体。
06.向量数据库部署搭建
Milvus 部署的前置依赖
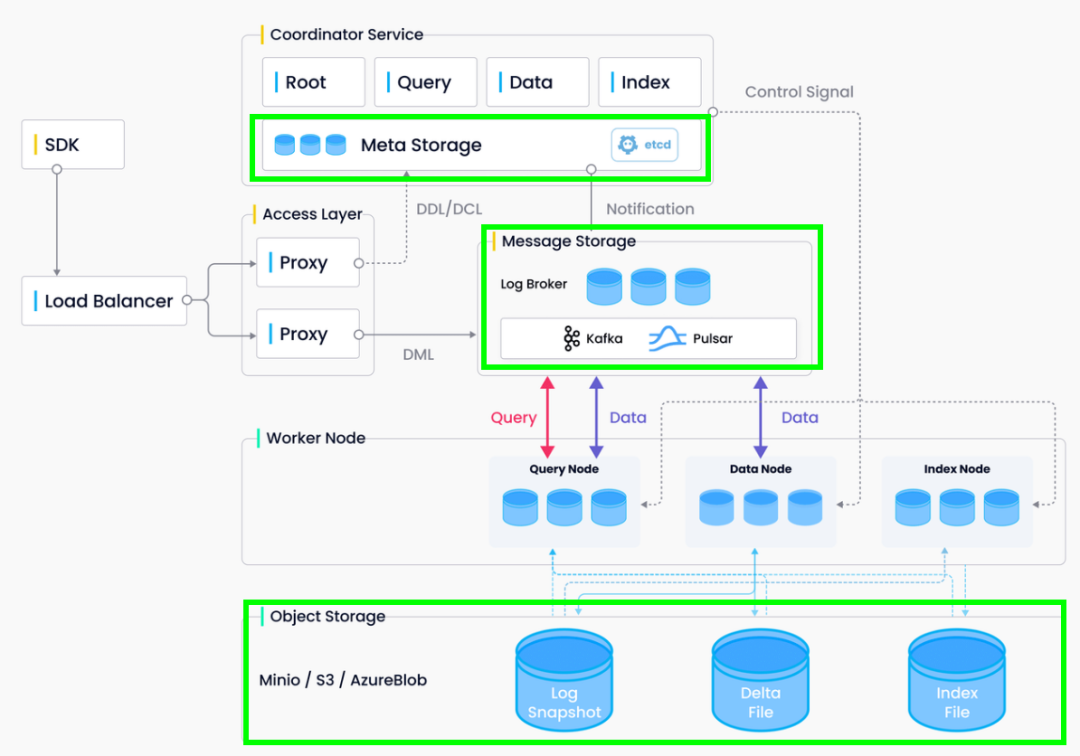
Milvus 向量数据库的部署的前置依赖是对象存储、消息队列和分布式键值存储。
-
分布式键值存储:团队使用的是 ETCD 负责存储和管理各个节点的配置信息,用于配置和服务发现。
-
消息队列:团队使用的是公司提供的 Kafka 基础服务,用于实时数据处理和消息传递。
-
对象存储:团队使用的是公司提供的对象云存储平台,用于存储向量数据和相关的元数据。
Milvus 部署情况
-
部署方式
团队使用的是 GitHub 上的源码构建自定义镜像的方式进行 Milvus 向量数据库的部署。版本为:v2.3.1。基于携程 k8s 基础服务平台,采用了集群部署方式。
-
部署节点
针对于 Milvus 数据库的部署模块,集群部署方式需要部署以下 8 个组件,分别是访问代理层(proxy)、协调节点(Root coordinator,Query coordinator ,Data coordinator,Index coordinator)和执行节点(Query node,Data node,Index node)。

-
索引选择
索引选择的 HNSW 索引。HNSW 是基于图的索引,该索引具有高效的近似最近邻搜索,在处理高维度向量数据时表现出色,适用于追求高查询效率的场景。
-
资源大小
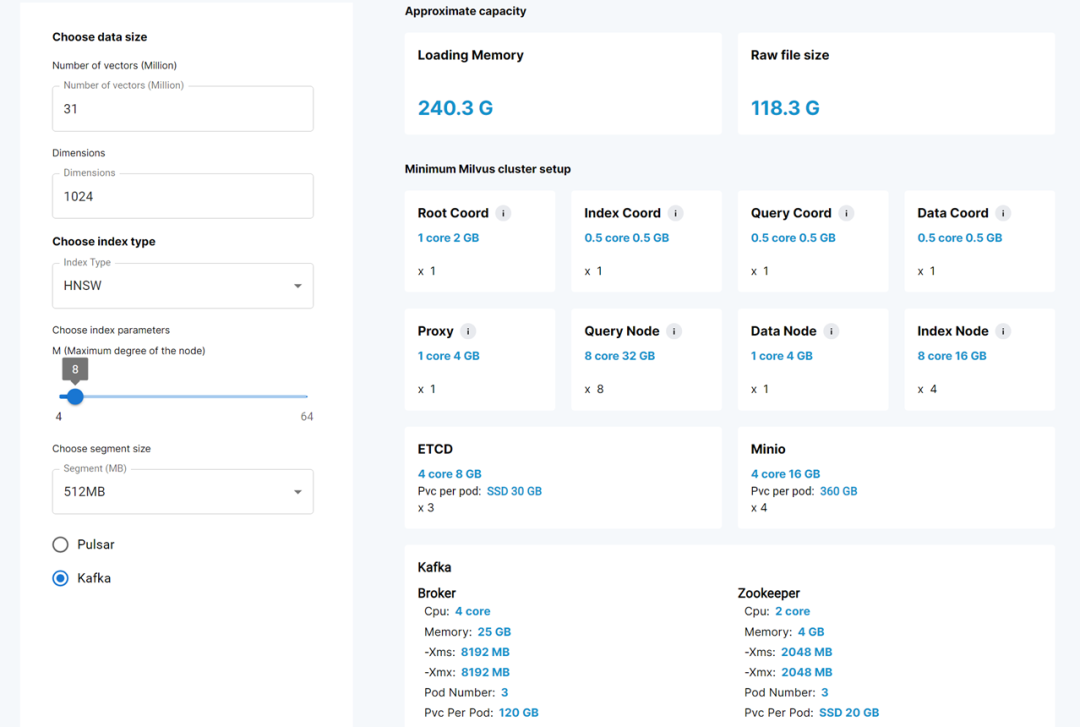
在 Milvus 的部署中,参考 Milvus 官方提供的工具和根据实际的数据量和维度来配置资源。实际生产环境中,数据量达到了 3100 万+,每个向量数据的维度为 1024 维。下图展示了各个节点的资源配置情况:
07.向量引擎的使用场景
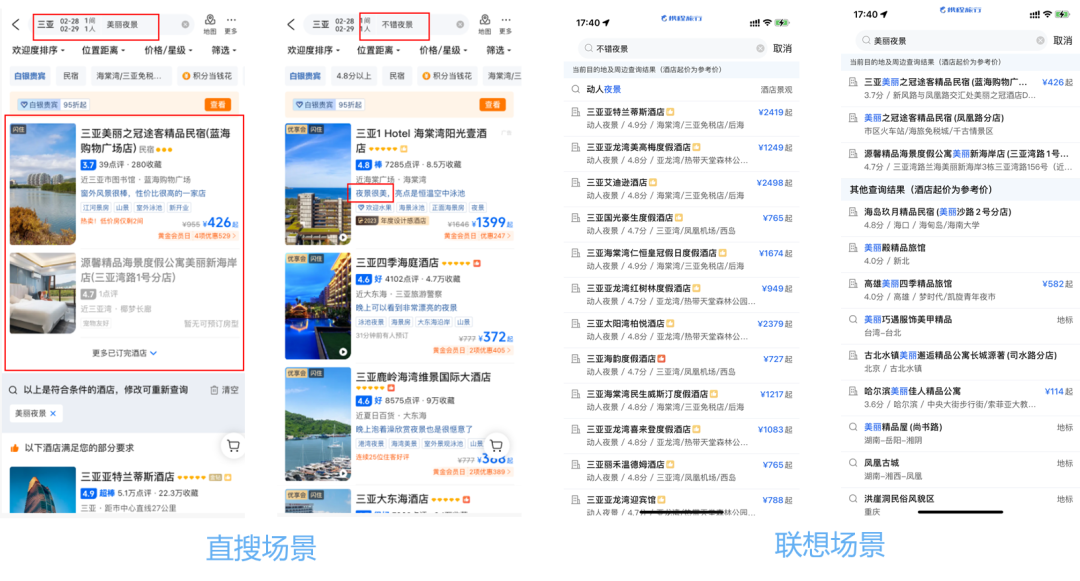
场景一:携程酒店搜索场景
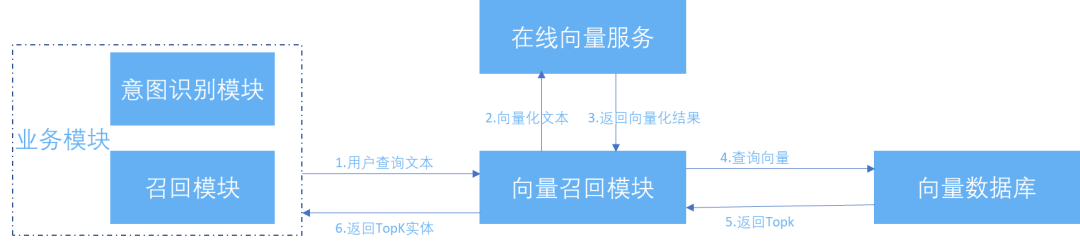
未引入向量引擎前,在直搜和联想场景下,例如搜索"美丽夜景",可能只能召回两家酒店。但如果搜索"不错夜景",则可以召回更多酒店。"美丽夜景"和"不错夜景"实际上都是酒店的一种标签类型,可以视为同义词。从查询语义的一致性上来说,使用"美丽夜景"应该具有召回"不错夜景"酒店的能力。因此,该场景下,可以引入向量引擎来实现同义词的召回,得到更准确的结果召回,以满足用户的需求。
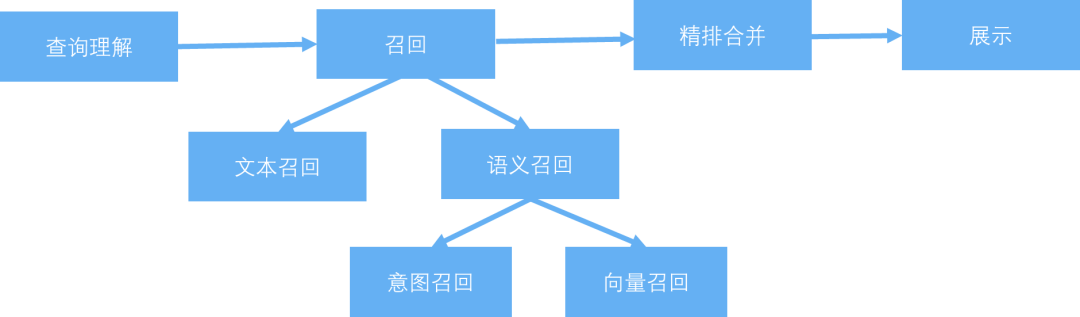
携程酒店搜索引入向量引擎召回的过程总览如下:
-
查询理解:根据用户的输入词进行查询理解,生成查询理解语句。
-
召回阶段:召回阶段包含文本召回和语义召回。
a. 文本召回:对查询理解语句进行切词,使用文本匹配的方式进行召回。b. 语义召回:语义召回包含意图召回和向量召回。意图召回是根据用户的查询输入,进行意图识别,并根据成功识别的用户意图进行酒店召回;向量召回是在无法准确识别用户意图的情况下,通过向量引擎进行向量召回。 -
合并和精排:根据召回的结果进行合并和精排的操作,最终输出展示给用户。
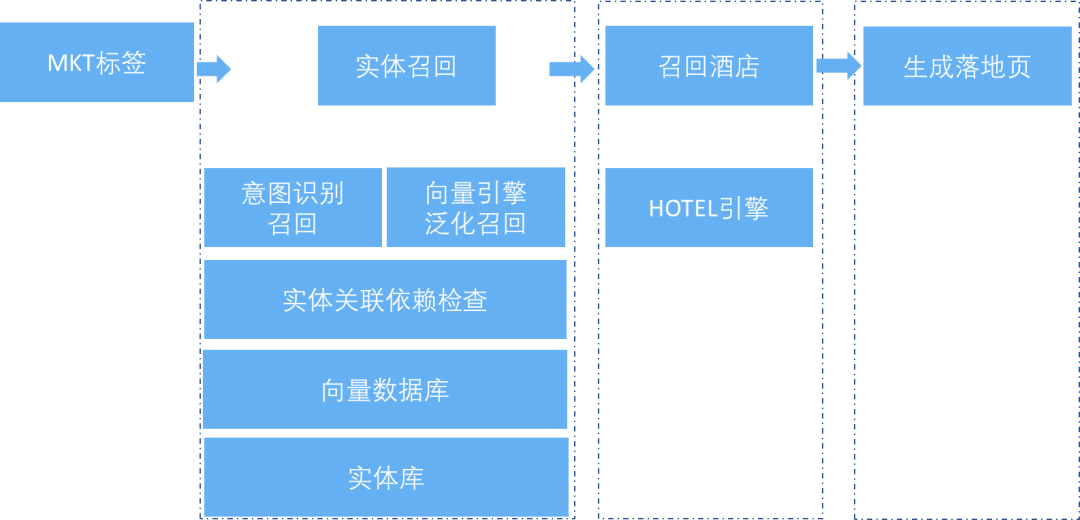
场景二:SEO 落地页生成

SEO 落地页生成整个过程如下:
-
关键词挖掘:通过国际化团队的挖掘结果获取相关的关键词。
-
实体召回:根据挖掘的关键词召回相关的实体。
-
意图识别:对用户搜索词做意图分析识别。
-
向量引擎泛化召回:当意图识别失败时,使用向量引擎进行泛化召回,以扩大召回范围。
-
相关依赖检查:对召回的实体进行相关依赖检查,确保召回的实体与用户需求相关。
-
酒店相关召回:根据识别和泛化召回的实体,进行与酒店相关的召回。
-
筛选排序:对召回的酒店进行筛选和排序,按照产品规则进行处理。
-
精排:根据精细排名规则对召回的酒店进行精细排名,以优化搜索结果的质量。
-
生成 SEO 落地页:根据最终召回和排名结果生成相应的 SEO 落地页。
08.总结
本文主要介绍了向量引擎在携程酒店搜索中的应用场景和相关经验,分别从以下几个方面进行了介绍:
-
携程酒店为什么需要向量引擎。携程酒店搜索亟需提升泛化搜索能力,以此更好的解决传统文本检索的同义词问题和长尾问题等。
-
探讨了实现向量引擎如何做技术选型。在选择向量数据库时,根据携程酒店的需求和实际情况,选择了 Milvus 向量数据库作为解决方案。
-
介绍了如何设计搭建向量引擎,包括向量化服务搭建和向量数据库部署等方面。
-
介绍了向量引擎在携程酒店搜索中的使用场景,利用向量引擎的泛化召回能力,在酒店搜索场景和 SEO 优化上提高搜索结果的质量和准确性。
通过以上介绍,可以看出向量引擎在携程酒店搜索中的重要性和应用价值,对向量引擎进行合适的选型和设计,能够实现更精准高效的酒店搜索服务,提升用户的搜索体验。
本文作者
-
赵明辰 携程酒店搜索引擎高级研发经理; -
刘阳 携程酒店搜索引擎资深研发
本文由 mdnice 多平台发布