目录
- 前言
- 一、思路
- 二、实战
- 1.安装etcdctl指令
- 2.重置旧节点的k8s
- 3.旧节点的的 etcd 从 etcd 集群删除
- 4.在 master03 上,创建存放证书目录
- 5.把其他控制节点的证书拷贝到 master01 上
- 6.把 master03 加入到集群
- 7.验证 master03 是否加入到 k8s 集群,检查业务
- 三、总结
前言
各位小伙伴们好鸭,小涛又来了,分享一个近期遇到的Kubernetes运维案例
有3个控制节点(master)和n个工作节点(node),有一个控制节点 master03 出问题并关机,修复不成功,执行 kubectl delete node master03 把 master03 移除
移除之后(过了一周),机器恢复了重新上架,打算还把个机器加到k8s 集群,还是做控制节点,如何做?
小涛陷入了沉思……
一、思路
总的来说,需要操作的步骤如下:
- 把 master03 这个节点的 etcd 从 etcd 集群删除
- 在 master03 上,创建存放证书目录
- 把其他控制节点的证书拷贝到 master03 上
- 把 master03 节点加入到集群
- 验证 master03 是否加入到 k8s 集群
二、实战
口说无凭,下面跟着小涛一块实操吧,亲测有效
1.安装etcdctl指令
如果已安装,这步跳过
etcdctl链接:https://pan.baidu.com/s/1TvXSoVeTDKAJfcN4shnmPw
提取码:etcd
注意:如果是用kubeadm安装的k8s,etcd是跑在pod里面的,所以我们没有etcd、etcdctl指令的,大家可以yum 安装一下,如果是内网环境,可以把这个安装包里的etcd、etcdctl,赋权后cp 到 /use/bin 目录下
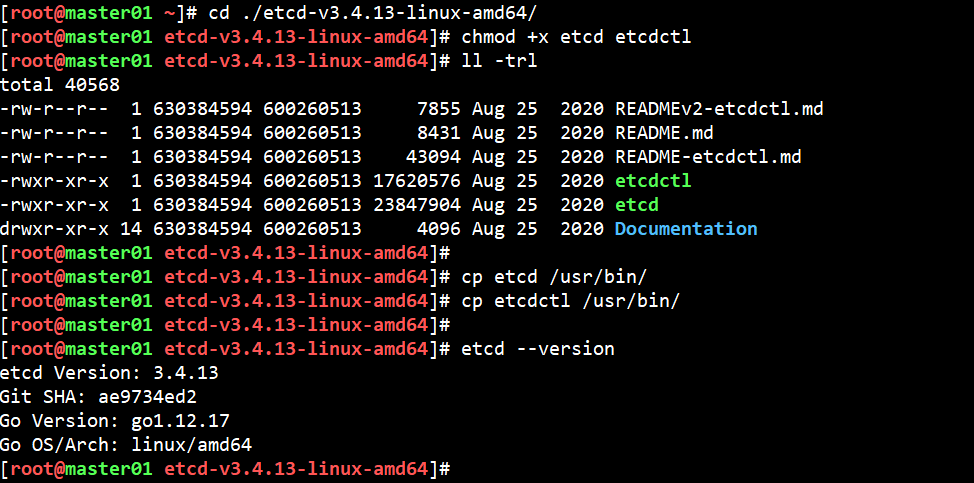
#把etcdctl目录解压后,放入k8s-master节点中【每个master节点都执行】
tar -zxvf etcd-v3.4.13-linux-amd64.tar.gz
cd ./etcd-v3.4.13-linux-amd64/
chmod +x etcd etcdctl
cp etcd /usr/bin/
cp etcdctl /usr/bin/
2.重置旧节点的k8s
目的:保证其是一个干净的节点【以免脏数据影响重新加入集群】
ssh master03
kubeadm reset #检查是不是需要重置的旧节点再执行,慎重!!!

3.旧节点的的 etcd 从 etcd 集群删除
切记,任何操作前提前备份,这是一个好的工作习惯
#备份ETCD数据
ETCDCTL_API=3 etcdctl \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--endpoints=127.0.0.1:2379 \
snapshot save ./etcd-snapshot-`date +%Y%m%d%H%M`.db#查看ETCD备份文件是否正常【查看备份文件不用指定证书目录】
ETCDCTL_API=3 etcdctl --endpoints=127.0.0.1:2379 \
snapshot status ./etcd-snapshot-`date +%Y%m%d%H%M`.db -w table

#以下是小涛整理一个每天自动备份脚本【大家可自行取用】
# 0 1 * * * /bin/bash /backup/etcd_backup.sh > /dev/null 2>&1cat etcd_backup.sh
#!/bin/bashsource /etc/profile
date;ENDPOINTS="127.0.0.1:2379" #IP换成etcd所在节点IP
SNAPSHOT_DIR="/backup/snapshot" #备份文件存放路径
SNAPSHOT_LOG="/backup/log" #备份产生的日志存放路径ETCDCTL_API=3 /usr/bin/etcdctl \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--endpoints=${ENDPOINTS} \
snapshot save ${SNAPSHOT_DIR}/etcd-snapshot-`date +%Y%m%d%H%M`.db >> ${SNAPSHOT_LOG}/etcd-snapshot-`date +%Y%m%d%H%M`.logETCDCTL_API=3 /usr/bin/etcdctl --endpoints=${ENDPOINTS} \
snapshot status ${SNAPSHOT_DIR}/etcd-snapshot-`date +%Y%m%d%H%M`.db -w table >> ${SNAPSHOT_LOG}/etcd-snapshot-`date +%Y%m%d%H%M`.log# 备份文件保留30天后删除
find ${SNAPSHOT_DIR} -name *.db -mtime +30 -exec rm -f {} \;
find ${SNAPSHOT_LOG} -name *.log -mtime +30 -exec rm -f {} \;
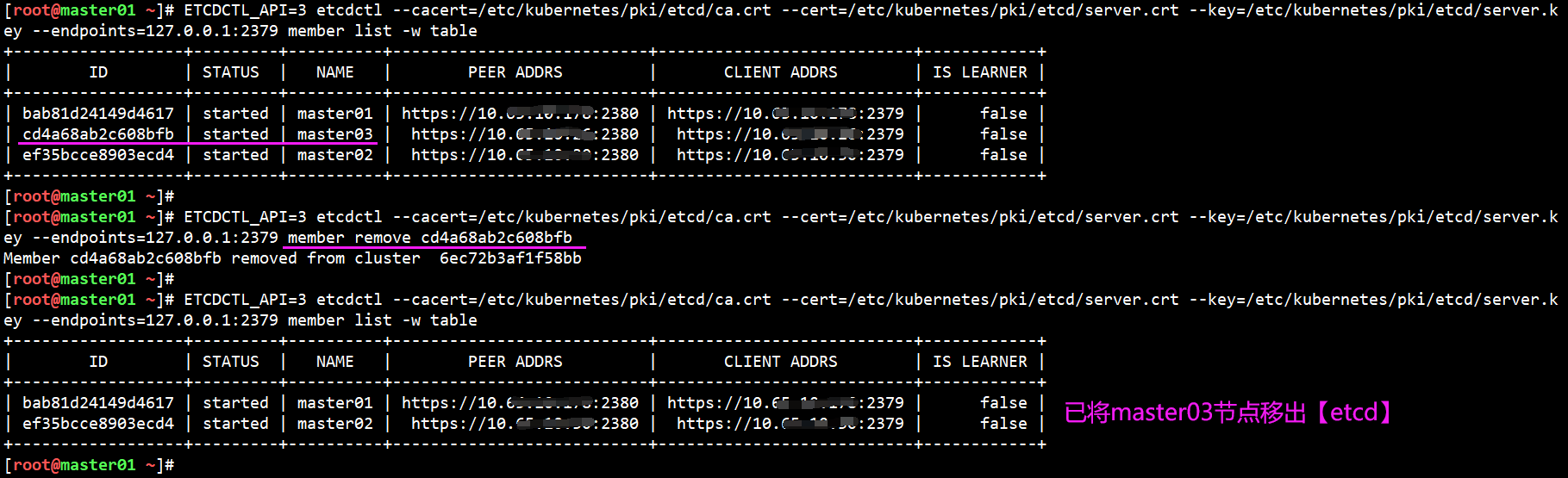
#找到 master03 这个机器的etcd 的id 是cd4a68ab2c608bfb 【具体id以实际为准】
ETCDCTL_API=3 etcdctl member list
ETCDCTL_API=3 etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --endpoints=127.0.0.1:2379 member list -w table

#删除 master03 节点的etcd【在ETCD正常的节点执行】
ETCDCTL_API=3 etcdctl member delete id
ETCDCTL_API=3 etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --endpoints=127.0.0.1:2379 member remove cd4a68ab2c608bfb
4.在 master03 上,创建存放证书目录
ssh master03
cd /root && mkdir -p /etc/kubernetes/pki/etcd && mkdir -p ~/.kube/

5.把其他控制节点的证书拷贝到 master01 上
export HostName=master03
echo ${HostName}
scp /etc/kubernetes/pki/ca.crt ${HostName}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key ${HostName}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key ${HostName}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub ${HostName}:/etc/kubernetes/
scp /etc/kubernetes/pki/front-proxy-ca.crt ${HostName}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key ${HostName}:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt ${HostName}:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key ${HostName}:/etc/kubernetes/pki/etcd/
6.把 master03 加入到集群
kubeadm token create --print-join-command
显示如下:

#master03节点执行:
#【把刚才获取的token指令粘贴过来,加上"--control-plane --ignore-preflight-errors=SystemVerification"参数】
ssh master03
kubeadm join apiserver.cluster.local:6443 --token hrm6ki.xxxx --discovery-token-ca-cert-hash sha256:449fddxxxxxxxxxxxx \
--control-plane --ignore-preflight-errors=SystemVerification
7.验证 master03 是否加入到 k8s 集群,检查业务
接下来,静观其变,等待加入k8s集群
#查看master03节点是否已正常加入集群,
kubectl get node -o wide
集群节点都是Ready状态后,检查pod状态是否正常,同时检查生产业务是否正常
三、总结
奈斯,Get一个新技能,小伙伴们小本本记得记好了,有帮助大家还请点赞收藏一波😉
下一篇博客再见了,欢迎评论区讨论,我是卑微涛,不断输出,冲冲冲!