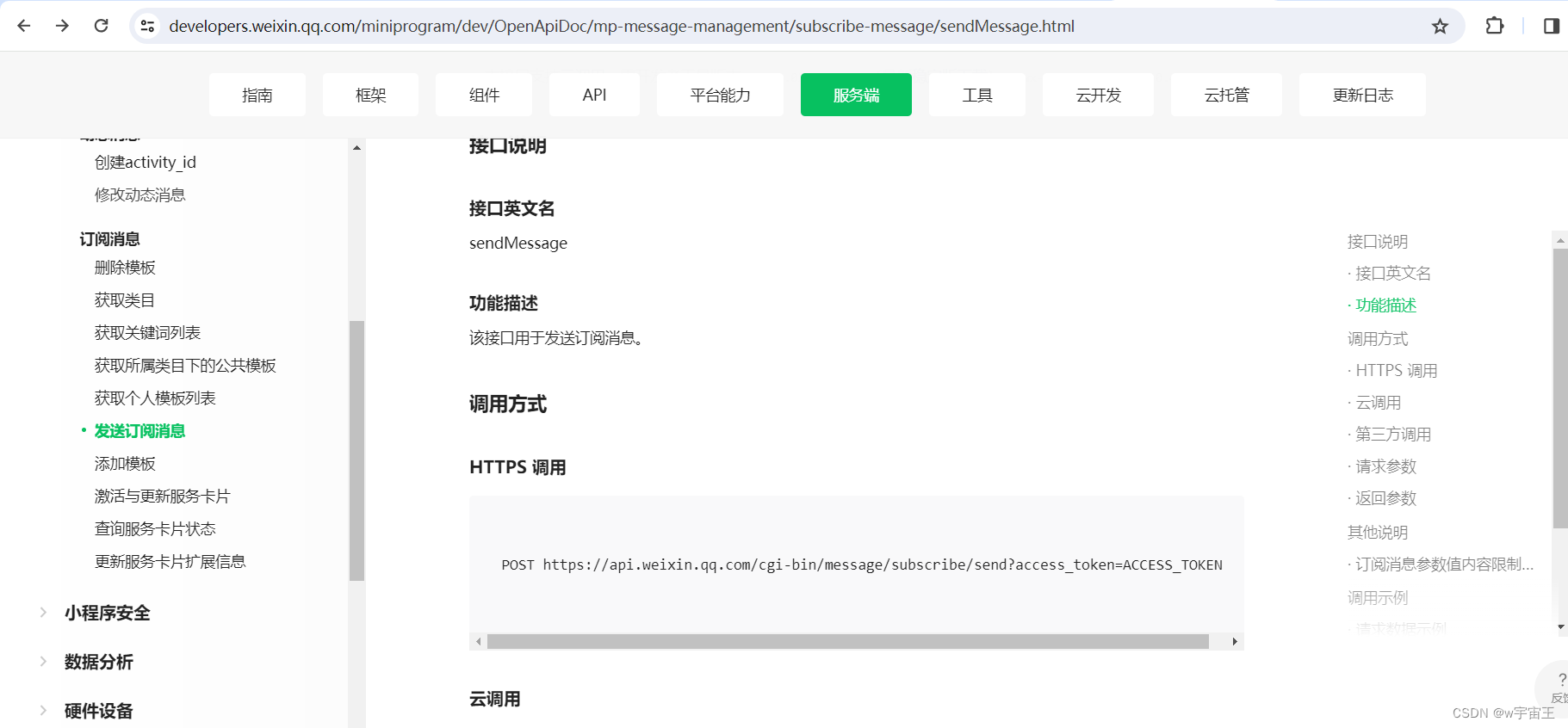
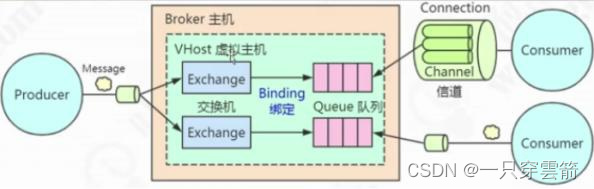
在Python语言中局部变量可以是任意标识符,因为局部变量在函数结束时相当于被销毁,即使与全局变量同名也可以正常运行
在函数内部引用数字类型全局变量时,必须使用global保留字声明
函数内部引用组合类型全局变量时,可以不通过global保留字声明
 此时函数并没有任何输出的语句将结果显示,所以没有任何输出
此时函数并没有任何输出的语句将结果显示,所以没有任何输出
 组合数据类型根据数据的关系分为序列类型、集合类型和映射类型,其中集合类型和映射类型都是没有顺序的数据类型,不能够通过序号访问
组合数据类型根据数据的关系分为序列类型、集合类型和映射类型,其中集合类型和映射类型都是没有顺序的数据类型,不能够通过序号访问

存储多信息的数据最适合的是列表数据类型
 在Python语言中,turtle库没有turtlesize()函数,shape()函数用于设置绘图箭头的形状。setup()函数打开一个自定义大小和位置的画布。
在Python语言中,turtle库没有turtlesize()函数,shape()函数用于设置绘图箭头的形状。setup()函数打开一个自定义大小和位置的画布。
requests是网络爬虫方向的第三方库,NLTK是Python自然语言处理的第三方库,pillow是Python图像处理的第三方库

ls = eval(input())
s = ""
for item in ls:if ___(1)_____ == type("香山"):s += ___(2)_____
print(s)首先要判断其是否属于字符串类型,属于字符串来性的元素才进行连接。
ls = eval(input())
s = ""
for item in ls:if type(item) == type("香山"):s += item
print(s)整体来看的话还是不难的,首先将输入的数据进行类型转换,设立一个空的s,然后开始对ls中的元素进行遍历,如果数据类型相同的话,都是字符串类型,便进行拼接

import randomrandom.seed(25)
n = ___________(1)____________
for m in range(1,7):x = eval(input("请输入猜测数字:"))if x == n:print("恭喜你,猜对了!")breakelif ___________(2)___________:print("大了,再试试")else:print("小了,再试试")if ___________(3)___________:print("谢谢!请休息后再猜")import randomrandom.seed(25)
n = random.randint(1,100)
for m in range(1,7):x = eval(input("请输入猜测数字:"))if x == n:print("恭喜你,猜对了!")breakelif x > n:print("大了,再试试")else:print("小了,再试试")if m == 6:print("谢谢!请休息后再猜")此时的运算次数是到达6次时便会输出,但是m此时最大的取值就是6,只需取值恒等于6就可以,不用超过6

def f(n):___________(1)___________if ___________(2)___________:for i in range(1, n+1, 2):s += 1/ielse:for i in range(2, n+1, 2):s += 1/ireturn s
n = int(input())
print(___________(3)___________)def f(n):n = eval(input("请输入一个自然数:"))if n % 2 !=0:for i in range(1, n+1, 2):s += 1/ielse:for i in range(2, n+1, 2):s += 1/ireturn s
n = int(input())
print(s.format(:2f))def f(n):s = 0if n%2 == 1:for i in range(1, n+1, 2):s += 1/ielse:for i in range(2, n+1, 2):s += 1/ireturn s
n = int(input())
print('{:.2f}'.format(f(n)))一般的第一行都需要首先定义一个空值或者 0 值,可以看到此时最下边有选择的输入整数的选项,所以上边就没有必要再进行输入了。此时在判断输入的整数n是奇数还是偶数时,我觉得这两种做法都是可以的,或许是因为0的缘故。format的格式化输出一定要记得怎么用。

import turtle as t
color = ['red','green','blue']
rs = [10,30,60]for i in range(___(1)___):t.penup()t.goto(0, ___(2)___)t. ___(3)___t.pencolor(___(4)___)t.circle(___(5)___)
t.done()turtle函数的用法在平常的用法之中不太常见,在考试中会经常出现
import turtle as t
color = ['red','green','blue']
rs = [10,30,60]for i in range(3):t.penup()t.goto(0,-rs[i])t.pd()t.pencolor(color[i])t.circle(rs[i])
t.done()
import jieba
s = input("请输入一段中文文本,句子之间以逗号或句号分隔:")
......for i in slist:if i in ",。":continue......print("\n中文词语数是:{}\n".format(m))
import jieba
s = input("请输入一段中文文本,句子之间以逗号或句号分隔:")
slist = jieba.lcut(s)
m = 0for i in slist:if i in ",。":continuem += 1print(i,end='/') print("\n中文词语数是:{}\n".format(m))ss = ''
for i in s:if i in ',。':print('{: ^20}'.format(ss))ss = ''continuess += i
fi = open('data.txt','r')
fo = open('studs.txt','w')
students = fi.readlines()
for i in students:i = i.strip().split(':')name = i[0]score = i[1].split(',')[-1]fo.write(name+':'+score+'\n')
fi.close()
fo.close()根据这个第一问来看的话还是不难的,这里文件的打开方式没有使用read.txt等打开方式,计算机二级的选择题也是一直在考察使用open来打开文件的用法,此时考生文件夹中不存在studs.txt,使用写的方式打开会进行创建。第一题就是分别通过切片来获取不同的字段进行组合,切割完字符进行组合时根据题目要求加入换行符
fi = open('data.txt','r')
students = fi.readlines()
l=[]
for i in students:i = i.strip().split(':')name = i[0]score = i[1].split(',')[-1]l.append([name,score])
l.sort(key=lambda x:eval(x[1]),reverse=True)
print(l[0][0]+':'+l[0][1])
fi.close()此时第二问是主要考察的关于文件内容排序的问题,此时使用lambda 函数进行正向排序并获取出最高分,分别取最高分的姓名和分数,中间且用冒号隔开
fi = open('data.txt','r')
d = {}
students = fi.readlines()
for i in students:i = i.strip().split(':')clas,score = i[1].split(',')d[clas] = d.get(clas,[])+[eval(score)]for i in d:avg_score = sum(d[i])/len(d[i])print('{}:{:.2f}'.format(i,avg_score))第三问是考察计算每个班级的平均分,则首先需要将属于每个班级的分数进行整合,然后再进行平均获取平均分。