where
1、我们为什么需要where?
我们经常需要一个数据来自好几个的取值,而这些取值通常是不规律的,这就会导致使用传统的拆分和合并会非常的麻烦。我们也可以使用for循环嵌套来取值,也是可以的,但是使用for循环就意味着是python,那并没有很好的利用pytorch提供的使用gpu加速计算,当数据量非常大的话,会很大的拉低效率,因此我们使用pytorch提供的where。
2、where的使用
语法:torch.where(condition, x, y) ------> tensor
返回值:最后的返回值是一个张量,最后每个元素来自数据x,还是数据y依赖于条件。
使用where的条件:x.shape = y.shape = c.shape = condition.shape(c为结果,condition为0 1矩阵)
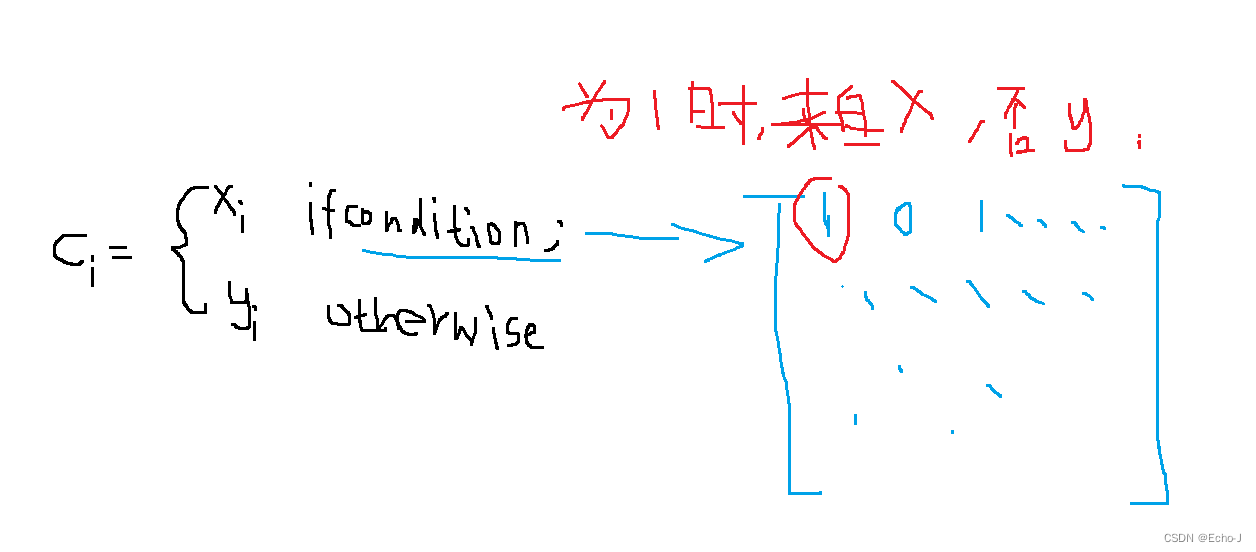
代码示例:
cond = torch.tensor([[0.6,0.7],[0.8,0.4]])
a = torch.zeros(2,2)
b = torch.ones(2,2)
print(torch.where(cond>0.5,a,b))
# tensor([[0., 0.],
# [0., 1.]])gather
1、我们为什么需要gather?
gather:根据index收集数据。
不使用gather的情况:

可以从上图中看出,索引是非常繁琐的,而且不小心就看错了,虽说也不是很难,但是深度学习处理的数据都是非常庞大的,比如一个1024*1024的图片,这时候内心是崩溃的🌹。还有一点,我们可以使用gpu帮助我们加快数据处理的效率。
2、gather的使用
语法:torch.gather(input, dim, index, out=None) -----> tensor
input:表
dim:在哪个维度查表
index:索引表
代码示例:
prob=torch.randn(4,10)
idx=prob.topk(dim=1,k=3)
idx=idx[1]
# 以上为了得到索引表
label=torch.arange(10)+100
print(torch.gather(label.expand(4,10),dim=1,index=idx))





![[C语言]一维数组二维数组的大小](https://img-blog.csdnimg.cn/direct/8456245efec84329909bc73c5ac9225c.png)