目录
- 前言
- 1. 基本知识
- 2. 模板
- 3. Demo
前言
分布式ID的生成推荐阅读:分布式ID生成方法的超详细分析(全)
1. 基本知识
Snowflake 算法是一种用于生成全局唯一 ID 的分布式算法,最初由 Twitter 设计并开源
它被设计用于解决分布式系统中生成唯一 ID 的需求,特别是在微服务架构和大规模分布式系统中
Snowflake 算法的核心思想是利用时间戳、工作机器 ID 和序列号来生成全局唯一的 64 位长整型 ID
其核心的组成部分如下:
-
时间戳(Timestamp):通常以毫秒为单位,用于标识生成 ID 的时间点。时间戳的精度对 ID 的唯一性至关重要
-
工作机器 ID(Worker ID):用于标识不同的工作机器或节点。在分布式系统中,每个节点需要有唯一的标识
-
数据中心 ID(Datacenter ID):用于标识不同的数据中心。在大规模分布式系统中,可能存在多个数据中心,每个数据中心需要有唯一的标识
-
序列号(Sequence Number):用于解决同一时间戳下生成多个 ID 的冲突问题。序列号通常是一个自增的数字,通过与一定的位数掩码进行位运算来确保不会溢出
Snowflake 算法的作用:
-
生成全局唯一 ID:Snowflake 算法可以在分布式系统中生成全局唯一的 ID,确保不同节点生成的 ID 不会冲突
-
适用于分布式环境:由于Snowflake算法只依赖于机器的时钟和网络通信,因此非常适合在分布式环境中使用
-
简单且高效:Snowflake 算法的实现相对简单,且性能高效,可以快速生成唯一 ID
2. 模板
以下模板带有注释
实现了一个 Snowflake 类,通过调用 generate 方法可以生成唯一的 Snowflake ID
Snowflake ID 是一个 64 位长整型,包含了时间戳、数据中心 ID、工作机器 ID 和序列号等信息
import timeclass SnowFlake(object):def __init__(self, worker_id, datacenter_id, sequence=0):self.worker_id = worker_id # 用于标识不同的工作机器self.datacenter_id = datacenter_id # 用于标识不同的数据中心self.sequence = sequence # 序列号,用于解决并发生成的 ID 冲突self.tw_epoch = 1288834974657 # Twitter Snowflake epoch (in milliseconds),Snowflake 算法的起始时间点# Bit lengths,用于计算位数self.worker_id_bits = 5 # 5位,最大值为31self.datacenter_id_bits = 5 # 5位,最大值为31self.max_worker_id = -1 ^ (-1 << self.worker_id_bits) # 最大工作机器 IDself.max_datacenter_id = -1 ^ (-1 << self.datacenter_id_bits) # 最大数据中心 IDself.sequence_bits = 12 # 12位,支持的最大序列号数self.sequence_mask = -1 ^ (-1 << self.sequence_bits) # 序列号掩码,用于生成序列号# Create initial timestamp,初始化上一次生成 ID 的时间戳self.last_timestamp = self.current_timestamp()# Check worker_id and datacenter_id values,检查工作机器 ID 和数据中心 ID 的取值范围if self.worker_id > self.max_worker_id or self.worker_id < 0:raise ValueError(f"Worker ID must be between 0 and {self.max_worker_id}")if self.datacenter_id > self.max_datacenter_id or self.datacenter_id < 0:raise ValueError(f"Datacenter ID must be between 0 and {self.max_datacenter_id}")@staticmethoddef current_timestamp():return int(time.time() * 1000) # 获取当前时间戳,单位为毫秒def generate(self):timestamp = self.current_timestamp() # 获取当前时间戳if timestamp < self.last_timestamp: # 如果当前时间戳小于上一次生成 ID 的时间戳raise ValueError("Clock moved backwards. Refusing to generate ID for {} milliseconds".format(self.last_timestamp - timestamp)) # 抛出异常,时钟回拨if timestamp == self.last_timestamp: # 如果当前时间戳等于上一次生成 ID 的时间戳self.sequence = (self.sequence + 1) & self.sequence_mask # 增加序列号,并与序列号掩码进行与运算,防止溢出if self.sequence == 0: # 如果序列号归零timestamp = self.wait_next_millis(self.last_timestamp) # 等待下一毫秒else:self.sequence = 0 # 时间戳变化,序列号重置为零self.last_timestamp = timestamp # 更新上一次生成 ID 的时间戳# Generate Snowflake ID,生成 Snowflake ID_id = ((timestamp - self.tw_epoch) << (self.worker_id_bits + self.datacenter_id_bits)) | (self.datacenter_id << self.worker_id_bits) | self.worker_id << self.sequence_bits | self.sequence # 使用时间戳、数据中心 ID、工作机器 ID 和序列号生成 IDreturn f"{_id:016d}" # 返回 64 位长整型 ID 的字符串表示,补齐到16位长度def wait_next_millis(self, last_timestamp):timestamp = self.current_timestamp() # 获取当前时间戳while timestamp <= last_timestamp: # 循环直到获取到下一毫秒的时间戳timestamp = self.current_timestamp()return timestamp # 返回下一毫秒的时间戳
3. Demo
结合以上模板,放一个调用的过程:
# 示例用法
if __name__ == "__main__":# 假设有两个数据中心,每个数据中心有两个工作机器worker_id = 1datacenter_id = 1snowflake = SnowFlake(worker_id, datacenter_id)# 生成10个IDfor i in range(10):print(snowflake.generate())
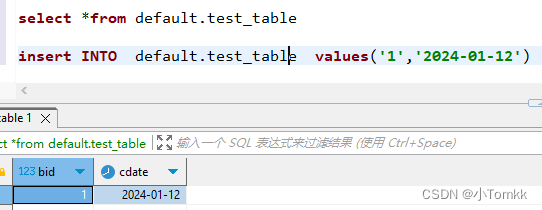
截图如下: