第五部分:元编程
第二十二章:动态属性和属性
属性的关键重要性在于,它们的存在使得将公共数据属性作为类的公共接口的一部分完全安全且确实可取。
Martelli、Ravenscroft 和 Holden,“为什么属性很重要”¹
在 Python 中,数据属性和方法统称为属性。方法是可调用的属性。动态属性呈现与数据属性相同的接口——即,obj.attr——但是根据需要计算。这遵循 Bertrand Meyer 的统一访问原则:
模块提供的所有服务都应通过统一的表示法可用,这种表示法不会泄露它们是通过存储还是计算实现的。²
在 Python 中有几种实现动态属性的方法。本章涵盖了最简单的方法:@property装饰器和__getattr__特殊方法。
实现__getattr__的用户定义类可以实现我称之为虚拟属性的动态属性变体:这些属性在类的源代码中没有明确声明,也不在实例__dict__中存在,但可能在用户尝试读取不存在的属性时在其他地方检索或在需要时动态计算,例如obj.no_such_attr。
编写动态和虚拟属性是框架作者所做的元编程。然而,在 Python 中,基本技术很简单,因此我们可以在日常数据整理任务中使用它们。这就是我们将在本章开始的方式。
本章的新内容
本章大部分更新的动机来自对@functools.cached_property(Python 3.8 中引入)的讨论,以及@property与@functools.cache(3.9 中新引入)的联合使用。这影响了出现在“计算属性”中的Record和Event类的代码。我还添加了一项重构以利用PEP 412—共享键字典优化。
为了突出更相关的特性,同时保持示例的可读性,我删除了一些非必要的代码——将旧的DbRecord类合并到Record中,用dict替换shelve.Shelve,并删除了下载 OSCON 数据集的逻辑——示例现在从Fluent Python代码库中的本地文件中读取。
使用动态属性进行数据整理
在接下来的几个示例中,我们将利用动态属性处理 O’Reilly 为 OSCON 2014 会议发布的 JSON 数据集。示例 22-1 展示了该数据集中的四条记录。³
示例 22-1。来自 osconfeed.json 的示例记录;一些字段内容已缩写
{ "Schedule": { "conferences": [{"serial": 115 }], "events": [ { "serial": 34505, "name": "Why Schools Don´t Use Open Source to Teach Programming", "event_type": "40-minute conference session", "time_start": "2014-07-23 11:30:00", "time_stop": "2014-07-23 12:10:00", "venue_serial": 1462, "description": "Aside from the fact that high school programming...", "website_url": "http://oscon.com/oscon2014/public/schedule/detail/34505", "speakers": [157509], "categories": ["Education"] } ], "speakers": [ { "serial": 157509, "name": "Robert Lefkowitz", "photo": null, "url": "http://sharewave.com/", "position": "CTO", "affiliation": "Sharewave", "twitter": "sharewaveteam", "bio": "Robert ´r0ml´ Lefkowitz is the CTO at Sharewave, a startup..." } ], "venues": [ { "serial": 1462, "name": "F151", "category": "Conference Venues" } ] }
}
示例 22-1 展示了 JSON 文件中的 895 条记录中的 4 条。整个数据集是一个带有键"Schedule"的单个 JSON 对象,其值是另一个具有四个键"conferences"、"events"、"speakers"和"venues"的映射。这四个键中的每一个都映射到一个记录列表。在完整数据集中,"events"、"speakers"和"venues"列表有几十个或几百个记录,而"conferences"只有在示例 22-1 中显示的那一条记录。每条记录都有一个"serial"字段,这是记录在列表中的唯一标识符。
我使用 Python 控制台来探索数据集,如示例 22-2 所示。
示例 22-2. 交互式探索 osconfeed.json
>>> import json
>>> with open('data/osconfeed.json') as fp:
... feed = json.load(fp) # ①
>>> sorted(feed['Schedule'].keys()) # ②
['conferences', 'events', 'speakers', 'venues'] >>> for key, value in sorted(feed['Schedule'].items()):
... print(f'{len(value):3} {key}') # ③
...1 conferences 484 events 357 speakers53 venues >>> feed['Schedule']['speakers'][-1]['name'] # ④
'Carina C. Zona' >>> feed['Schedule']['speakers'][-1]['serial'] # ⑤
141590 >>> feed['Schedule']['events'][40]['name']
'There *Will* Be Bugs' >>> feed['Schedule']['events'][40]['speakers'] # ⑥
[3471, 5199]
①
feed是一个包含嵌套字典和列表、字符串和整数值的dict。
②
列出"Schedule"内的四个记录集合。
③
显示每个集合的记录计数。
④
浏览嵌套的字典和列表以获取最后一个演讲者的姓名。
⑤
获取相同演讲者的序列号。
⑥
每个事件都有一个带有零个或多个演讲者序列号的'speakers'列表。
使用动态属性探索类似 JSON 的数据
示例 22-2 足够简单,但是feed['Schedule']['events'][40]['name']这样的语法很繁琐。在 JavaScript 中,您可以通过编写feed.Schedule.events[40].name来获取相同的值。在 Python 中,可以很容易地实现一个类似dict的类来做同样的事情——网络上有很多实现。⁴ 我写了FrozenJSON,比大多数方案更简单,因为它只支持读取:它只是用于探索数据。FrozenJSON也是递归的,自动处理嵌套的映射和列表。
示例 22-3 是FrozenJSON的演示,源代码显示在示例 22-4 中。
示例 22-3. FrozenJSON来自示例 22-4,允许读取属性如name,并调用方法如.keys()和.items()
>>> import json>>> raw_feed = json.load(open('data/osconfeed.json'))>>> feed = FrozenJSON(raw_feed) # ①>>> len(feed.Schedule.speakers) # ②357>>> feed.keys()dict_keys(['Schedule'])>>> sorted(feed.Schedule.keys()) # ③['conferences', 'events', 'speakers', 'venues']>>> for key, value in sorted(feed.Schedule.items()): # ④... print(f'{len(value):3} {key}')...1 conferences484 events357 speakers53 venues>>> feed.Schedule.speakers[-1].name # ⑤'Carina C. Zona'>>> talk = feed.Schedule.events[40]>>> type(talk) # ⑥<class 'explore0.FrozenJSON'>>>> talk.name'There *Will* Be Bugs'>>> talk.speakers # ⑦[3471, 5199]>>> talk.flavor # ⑧Traceback (most recent call last):...KeyError: 'flavor'
①
从由嵌套字典和列表组成的raw_feed构建一个FrozenJSON实例。
②
FrozenJSON允许通过属性表示法遍历嵌套字典;这里显示了演讲者列表的长度。
③
也可以访问底层字典的方法,比如.keys(),以检索记录集合名称。
④
使用items(),我们可以检索记录集合的名称和内容,以显示每个集合的len()。
⑤
一个list,比如feed.Schedule.speakers,仍然是一个列表,但其中的项目如果是映射,则转换为FrozenJSON。
⑥
events列表中的第 40 项是一个 JSON 对象;现在它是一个FrozenJSON实例。
⑦
事件记录有一个带有演讲者序列号的speakers列表。
⑧
尝试读取一个不存在的属性会引发KeyError,而不是通常的AttributeError。
FrozenJSON类的关键是__getattr__方法,我们已经在“Vector Take #3: Dynamic Attribute Access”中的Vector示例中使用过它,通过字母检索Vector组件:v.x、v.y、v.z等。需要记住的是,只有在通常的过程无法检索属性时(即,当实例、类或其超类中找不到命名属性时),解释器才会调用__getattr__特殊方法。
示例 22-3 的最后一行揭示了我的代码存在一个小问题:尝试读取一个不存在的属性应该引发AttributeError,而不是显示的KeyError。当我实现错误处理时,__getattr__方法变得两倍长,分散了我想展示的最重要的逻辑。考虑到用户会知道FrozenJSON是由映射和列表构建的,我认为KeyError并不会太令人困惑。
示例 22-4. explore0.py:将 JSON 数据集转换为包含嵌套FrozenJSON对象、列表和简单类型的FrozenJSON
from collections import abcclass FrozenJSON:"""A read-only façade for navigating a JSON-like objectusing attribute notation"""def __init__(self, mapping):self.__data = dict(mapping) # ①def __getattr__(self, name): # ②try:return getattr(self.__data, name) # ③except AttributeError:return FrozenJSON.build(self.__data[name]) # ④def __dir__(self): # ⑤return self.__data.keys()@classmethoddef build(cls, obj): # ⑥if isinstance(obj, abc.Mapping): # ⑦return cls(obj)elif isinstance(obj, abc.MutableSequence): # ⑧return [cls.build(item) for item in obj]else: # ⑨return obj
①
从mapping参数构建一个dict。这确保我们得到一个映射或可以转换为映射的东西。__data上的双下划线前缀使其成为私有属性。
②
只有当没有具有该name的属性时才会调用__getattr__。
③
如果name匹配实例__data dict中的属性,则返回该属性。这就是处理像feed.keys()这样的调用的方式:keys方法是__data dict的一个属性。
④
否则,从self.__data中的键name获取项目,并返回调用FrozenJSON.build()的结果。⁵
⑤
实现__dir__支持dir()内置函数,这将支持标准 Python 控制台以及 IPython、Jupyter Notebook 等的自动补全。这段简单的代码将基于self.__data中的键启用递归自动补全,因为__getattr__会动态构建FrozenJSON实例——对于交互式数据探索非常有用。
⑥
这是一个替代构造函数,@classmethod装饰器的常见用法。
⑦
如果obj是一个映射,用它构建一个FrozenJSON。这是鹅类型的一个例子——如果需要复习,请参阅“鹅类型”。
⑧
如果它是一个MutableSequence,它必须是一个列表,⁶因此我们通过递归地将obj中的每个项目传递给.build()来构建一个list。
⑨
如果不是dict或list,则返回原样。
FrozenJSON实例有一个名为_FrozenJSON__data的私有实例属性,如“Python 中的私有和‘受保护’属性”中所解释的那样。尝试使用其他名称检索属性将触发__getattr__。该方法首先查看self.__data dict是否具有该名称的属性(而不是键!);这允许FrozenJSON实例处理dict方法,比如通过委托给self.__data.items()来处理items。如果self.__data没有具有给定name的属性,__getattr__将使用name作为键从self.__data中检索项目,并将该项目传递给FrozenJSON.build。这允许通过build类方法将 JSON 数据中的嵌套结构转换为另一个FrozenJSON实例。
请注意,FrozenJSON不会转换或缓存原始数据集。当我们遍历数据时,__getattr__会一遍又一遍地创建FrozenJSON实例。对于这个大小的数据集和仅用于探索或转换数据的脚本来说,这是可以接受的。
任何生成或模拟来自任意来源的动态属性名称的脚本都必须处理一个问题:原始数据中的键可能不适合作为属性名称。下一节将解决这个问题。
无效属性名称问题
FrozenJSON代码不处理作为 Python 关键字的属性名称。例如,如果构建一个这样的对象:
>>> student = FrozenJSON({'name': 'Jim Bo', 'class': 1982})
你无法读取student.class,因为class是 Python 中的保留关键字:
>>> student.classFile "<stdin>", line 1student.class^
SyntaxError: invalid syntax
当然你总是可以这样做:
>>> getattr(student, 'class')
1982
但FrozenJSON的理念是提供对数据的便捷访问,因此更好的解决方案是检查传递给FrozenJSON.__init__的映射中的键是否是关键字,如果是,则在其末尾添加_,这样就可以像这样读取属性:
>>> student.class_
1982
通过用示例 22-5 中的版本替换示例 22-4 中的一行__init__,可以实现这一点。
示例 22-5. explore1.py:为 Python 关键字添加_作为属性名称的后缀
def __init__(self, mapping):self.__data = {}for key, value in mapping.items():if keyword.iskeyword(key): # ①key += '_'self.__data[key] = value
①
keyword.iskeyword(…)函数正是我们需要的;要使用它,必须导入keyword模块,这在这个片段中没有显示。
如果 JSON 记录中的键不是有效的 Python 标识符,可能会出现类似的问题:
>>> x = FrozenJSON({'2be':'or not'})
>>> x.2beFile "<stdin>", line 1x.2be^
SyntaxError: invalid syntax
在 Python 3 中,这些有问题的键很容易检测,因为str类提供了s.isidentifier()方法,告诉您s是否是根据语言语法的有效 Python 标识符。但将一个不是有效标识符的键转换为有效的属性名称并不是简单的。一个解决方案是实现__getitem__,允许使用x['2be']这样的表示法进行属性访问。为简单起见,我不会担心这个问题。
在考虑动态属性名称之后,让我们转向FrozenJSON的另一个重要特性:build类方法的逻辑。Frozen.JSON.build被__getattr__使用,根据正在访问的属性的值返回不同类型的对象:嵌套结构转换为FrozenJSON实例或FrozenJSON实例列表。
相同的逻辑可以实现为__new__特殊方法,而不是类方法,我们将在下面看到。
使用__new__进行灵活的对象创建
我们经常将__init__称为构造方法,但这是因为我们从其他语言中采用了术语。在 Python 中,__init__将self作为第一个参数,因此当解释器调用__init__时,对象已经存在。此外,__init__不能返回任何内容。因此,它实际上是一个初始化器,而不是构造函数。
当调用类以创建实例时,Python 在该类上调用的特殊方法来构造实例是__new__。它是一个类方法,但得到特殊处理,因此不适用@classmethod装饰器。Python 获取__new__返回的实例,然后将其作为__init__的第一个参数self传递。我们很少需要编写__new__,因为从object继承的实现对绝大多数用例都足够了。
如果必要,__new__方法也可以返回不同类的实例。当发生这种情况时,解释器不会调用__init__。换句话说,Python 构建对象的逻辑类似于这个伪代码:
# pseudocode for object construction
def make(the_class, some_arg):new_object = the_class.__new__(some_arg)if isinstance(new_object, the_class):the_class.__init__(new_object, some_arg)return new_object# the following statements are roughly equivalent
x = Foo('bar')
x = make(Foo, 'bar')
示例 22-6 展示了FrozenJSON的一个变体,其中前一个build类方法的逻辑移至__new__。
示例 22-6. explore2.py:使用__new__而不是build来构建可能是FrozenJSON实例的新对象。
from collections import abc
import keywordclass FrozenJSON:"""A read-only façade for navigating a JSON-like objectusing attribute notation"""def __new__(cls, arg): # ①if isinstance(arg, abc.Mapping):return super().__new__(cls) # ②elif isinstance(arg, abc.MutableSequence): # ③return [cls(item) for item in arg]else:return argdef __init__(self, mapping):self.__data = {}for key, value in mapping.items():if keyword.iskeyword(key):key += '_'self.__data[key] = valuedef __getattr__(self, name):try:return getattr(self.__data, name)except AttributeError:return FrozenJSON(self.__data[name]) # ④def __dir__(self):return self.__data.keys()
①
作为类方法,__new__的第一个参数是类本身,其余参数与__init__得到的参数相同,除了self。
②
默认行为是委托给超类的__new__。在这种情况下,我们从object基类调用__new__,将FrozenJSON作为唯一参数传递。
③
__new__的其余行与旧的build方法完全相同。
④
以前调用FrozenJSON.build的地方;现在我们只需调用FrozenJSON类,Python 会通过调用FrozenJSON.__new__来处理。
__new__方法将类作为第一个参数,因为通常创建的对象将是该类的实例。因此,在FrozenJSON.__new__中,当表达式super().__new__(cls)有效地调用object.__new__(FrozenJSON)时,由object类构建的实例实际上是FrozenJSON的实例。新实例的__class__属性将保存对FrozenJSON的引用,即使实际的构造是由解释器的内部实现的object.__new__在 C 中执行。
OSCON JSON 数据集的结构对于交互式探索并不有用。例如,索引为40的事件,标题为'There *Will* Be Bugs',有两位演讲者,3471和5199。查找演讲者的姓名很麻烦,因为那些是序列号,而Schedule.speakers列表不是按照它们进行索引的。要获取每位演讲者,我们必须遍历该列表,直到找到一个具有匹配序列号的记录。我们的下一个任务是重组数据,以准备自动检索链接记录。
我们在第十一章“可散列的 Vector2d”中首次看到@property装饰器。在示例 11-7 中,我在Vector2d中使用了两个属性,只是为了使x和y属性只读。在这里,我们将看到计算值的属性,从而讨论如何缓存这些值。
OSCON JSON 数据中的'events'列表中的记录包含指向'speakers'和'venues'列表中记录的整数序列号。例如,这是会议演讲的记录(省略了描述):
{ "serial": 33950, "name": "There *Will* Be Bugs", "event_type": "40-minute conference session","time_start": "2014-07-23 14:30:00", "time_stop": "2014-07-23 15:10:00", "venue_serial": 1449, "description": "If you're pushing the envelope of programming...", "website_url": "http://oscon.com/oscon2014/public/schedule/detail/33950", "speakers": [3471, 5199], "categories": ["Python"]
}
我们将实现一个具有venue和speakers属性的Event类,以便自动返回链接数据,换句话说,“解引用”序列号。给定一个Event实例,示例 22-7 展示了期望的行为。
示例 22-7。读取venue和speakers返回Record对象
>>> event # ①<Event 'There *Will* Be Bugs'> >>> event.venue # ②<Record serial=1449> >>> event.venue.name # ③'Portland 251' >>> for spkr in event.speakers: # ④... print(f'{spkr.serial}: {spkr.name}') ... 3471: Anna Martelli Ravenscroft 5199: Alex Martelli
①
给定一个Event实例…
②
…读取event.venue返回一个Record对象,而不是一个序列号。
③
现在很容易获取venue的名称。
④
event.speakers属性返回一个Record实例列表。
和往常一样,我们将逐步构建代码,从Record类和一个函数开始,该函数读取 JSON 数据并返回一个带有Record实例的dict。
步骤 1:基于数据创建属性
示例 22-8 展示了指导这一步骤的 doctest。
示例 22-8. 测试 schedule_v1.py(来自示例 22-9)
>>> records = load(JSON_PATH) # ①>>> speaker = records['speaker.3471'] # ②>>> speaker # ③<Record serial=3471>>>> speaker.name, speaker.twitter # ④('Anna Martelli Ravenscroft', 'annaraven')
①
load一个带有 JSON 数据的dict。
②
records中的键是由记录类型和序列号构建的字符串。
③
speaker是在示例 22-9 中定义的Record类的实例。
④
可以将原始 JSON 中的字段作为Record实例属性检索。
schedule_v1.py的代码在示例 22-9 中。
示例 22-9. schedule_v1.py:重新组织 OSCON 日程数据
import jsonJSON_PATH = 'data/osconfeed.json'class Record:def __init__(self, **kwargs):self.__dict__.update(kwargs) # ①def __repr__(self):return f'<{self.__class__.__name__} serial={self.serial!r}>' # ②def load(path=JSON_PATH):records = {} # ③with open(path) as fp:raw_data = json.load(fp) # ④for collection, raw_records in raw_data['Schedule'].items(): # ⑤record_type = collection[:-1] # ⑥for raw_record in raw_records:key = f'{record_type}.{raw_record["serial"]}' # ⑦records[key] = Record(**raw_record) # ⑧return records
①
这是一个常见的快捷方式,用关键字参数构建属性的实例(详细解释如下)。
②
使用serial字段构建自定义的Record表示,如示例 22-8 所示。
③
load最终将返回Record实例的dict。
④
解析 JSON,返回本机 Python 对象:列表、字典、字符串、数字等。
⑤
迭代四个名为'conferences'、'events'、'speakers'和'venues'的顶级列表。
⑥
record_type是列表名称去掉最后一个字符,所以speakers变成speaker。在 Python ≥ 3.9 中,我们可以更明确地使用collection.removesuffix('s')来做到这一点——参见PEP 616—删除前缀和后缀的字符串方法。
⑦
构建格式为'speaker.3471'的key。
⑧
创建一个Record实例,并将其保存在带有key的records中。
Record.__init__方法展示了一个古老的 Python 技巧。回想一下,对象的__dict__是其属性所在的地方——除非在类中声明了__slots__,就像我们在“使用 slots 节省内存”中看到的那样。因此,使用映射更新实例__dict__是一种快速创建该实例中一堆属性的方法。⁷
注意
根据应用程序的不同,Record类可能需要处理不是有效属性名称的键,就像我们在“无效属性名称问题”中看到的那样。处理这个问题会分散这个示例的关键思想,并且在我们正在读取的数据集中并不是一个问题。
在示例 22-9 中Record的定义是如此简单,以至于你可能会想为什么我没有在之前使用它,而是使用更复杂的FrozenJSON。有两个原因。首先,FrozenJSON通过递归转换嵌套映射和列表来工作;Record不需要这样做,因为我们转换的数据集中没有映射嵌套在映射或列表中。记录只包含字符串、整数、字符串列表和整数列表。第二个原因:FrozenJSON提供对嵌入的__data dict属性的访问——我们用它来调用像.keys()这样的方法——现在我们也不需要那个功能了。
注意
Python 标准库提供了类似于Record的类,其中每个实例都有一个从给定给__init__的关键字参数构建的任意属性集:types.SimpleNamespace、argparse.Namespace和multiprocessing.managers.Namespace。我编写了更简单的Record类来突出显示基本思想:__init__更新实例__dict__。
重新组织日程数据集后,我们可以增强Record类,自动检索event记录中引用的venue和speaker记录。我们将在接下来的示例中使用属性来实现这一点。
第 2 步:检索链接记录的属性
下一个版本的目标是:给定一个event记录,读取其venue属性将返回一个Record。这类似于 Django ORM 在访问ForeignKey字段时的操作:您将获得链接的模型对象,而不是键。
我们将从venue属性开始。查看示例 22-10 中的部分交互作为示例。
示例 22-10. 从 schedule_v2.py 的 doctests 中提取
>>> event = Record.fetch('event.33950') # ①>>> event # ②<Event 'There *Will* Be Bugs'>>>> event.venue # ③<Record serial=1449>>>> event.venue.name # ④'Portland 251'>>> event.venue_serial # ⑤1449
①
Record.fetch静态方法从数据集中获取一个Record或一个Event。
②
请注意,event是Event类的一个实例。
③
访问event.venue将返回一个Record实例。
④
现在很容易找出event.venue的名称。
⑤
Event实例还具有来自 JSON 数据的venue_serial属性。
Event是Record的一个子类,添加了一个venue来检索链接的记录,以及一个专门的__repr__方法。
本节的代码位于schedule_v2.py模块中,位于Fluent Python代码库中。示例有近 60 行,所以我将分部分呈现,从增强的Record类开始。
示例 22-11. schedule_v2.py:具有新fetch方法的Record类
import inspect # ①
import jsonJSON_PATH = 'data/osconfeed.json'class Record:__index = None # ②def __init__(self, **kwargs):self.__dict__.update(kwargs)def __repr__(self):return f'<{self.__class__.__name__} serial={self.serial!r}>'@staticmethod # ③def fetch(key):if Record.__index is None: # ④Record.__index = load()return Record.__index[key] # ⑤
①
inspect将在示例 22-13 中使用。
②
__index私有类属性最终将保存对load返回的dict的引用。
③
fetch是一个staticmethod,明确表示其效果不受调用它的实例或类的影响。
④
如有需要,填充Record.__index。
⑤
使用它来检索具有给定key的记录。
提示
这是一个使用staticmethod的例子。fetch方法始终作用于Record.__index类属性,即使从子类调用,如Event.fetch()—我们很快会探讨。将其编码为类方法会产生误导,因为不会使用cls第一个参数。
现在我们来看Event类中属性的使用,列在示例 22-12 中。
示例 22-12. schedule_v2.py:Event类
class Event(Record): # ①def __repr__(self):try:return f'<{self.__class__.__name__} {self.name!r}>' # ②except AttributeError:return super().__repr__()@propertydef venue(self):key = f'venue.{self.venue_serial}'return self.__class__.fetch(key) # ③
①
Event扩展了Record。
②
如果实例具有name属性,则用于生成自定义表示。否则,委托给Record的__repr__。
③
venue属性从venue_serial属性构建一个key,并将其传递给从Record继承的fetch类方法(使用self.__class__的原因将很快解释)。
Example 22-12 的venue方法的第二行返回self.__class__.fetch(key)。为什么不简单地调用self.fetch(key)?简单形式适用于特定的 OSCON 数据集,因为没有带有'fetch'键的事件记录。但是,如果事件记录有一个名为'fetch'的键,那么在特定的Event实例内,引用self.fetch将检索该字段的值,而不是Event从Record继承的fetch类方法。这是一个微妙的错误,它很容易在测试中被忽略,因为它取决于数据集。
警告
在从数据创建实例属性名称时,总是存在由于类属性(如方法)的遮蔽或由于意外覆盖现有实例属性而导致的错误风险。这些问题可能解释了为什么 Python 字典一开始就不像 JavaScript 对象。
如果Record类的行为更像映射,实现动态的__getitem__而不是动态的__getattr__,那么就不会有由于覆盖或遮蔽而导致的错误风险。自定义映射可能是实现Record的 Pythonic 方式。但是如果我选择这条路,我们就不会研究动态属性编程的技巧和陷阱。
该示例的最后一部分是 Example 22-13 中修改后的load函数。
示例 22-13. schedule_v2.py:load函数
def load(path=JSON_PATH):records = {}with open(path) as fp:raw_data = json.load(fp)for collection, raw_records in raw_data['Schedule'].items():record_type = collection[:-1] # ①cls_name = record_type.capitalize() # ②cls = globals().get(cls_name, Record) # ③if inspect.isclass(cls) and issubclass(cls, Record): # ④factory = cls # ⑤else:factory = Record # ⑥for raw_record in raw_records: # ⑦key = f'{record_type}.{raw_record["serial"]}'records[key] = factory(**raw_record) # ⑧return records
①
到目前为止,与schedule_v1.py中的load没有任何变化(Example 22-9)。
②
将record_type大写以获得可能的类名;例如,'event'变为'Event'。
③
从模块全局范围获取该名称的对象;如果没有这样的对象,则获取Record类。
④
如果刚刚检索到的对象是一个类,并且是Record的子类…
⑤
…将factory名称绑定到它。这意味着factory可以是Record的任何子类,取决于record_type。
⑥
否则,将factory名称绑定到Record。
⑦
创建key并保存记录的for循环与以前相同,只是…
⑧
…存储在records中的对象由factory构造,该factory可以是Record或根据record_type选择的Event等子类。
请注意,唯一具有自定义类的record_type是Event,但如果编写了名为Speaker或Venue的类,load将在构建和保存记录时自动使用这些类,而不是默认的Record类。
现在我们将相同的想法应用于Events类中的新speakers属性。
第三步:覆盖现有属性
Example 22-12 中venue属性的名称与"events"集合中的记录字段名称不匹配。它的数据来自venue_serial字段名称。相比之下,events集合中的每个记录都有一个speakers字段,其中包含一系列序列号。我们希望将该信息作为Event实例中的speakers属性公开,该属性返回Record实例的列表。这种名称冲突需要特别注意,正如 Example 22-14 所示。
示例 22-14. schedule_v3.py:speakers属性
@propertydef speakers(self):spkr_serials = self.__dict__['speakers'] # ①fetch = self.__class__.fetchreturn [fetch(f'speaker.{key}')for key in spkr_serials] # ②
①
我们想要的数据在speakers属性中,但我们必须直接从实例__dict__中检索它,以避免对speakers属性的递归调用。
②
返回一个具有与 spkr_serials 中数字对应的键的所有记录列表。
在 speakers 方法内部,尝试读取 self.speakers 将会快速引发 RecursionError。然而,如果通过 self.__dict__['speakers'] 读取相同的数据,Python 通常用于检索属性的算法将被绕过,属性不会被调用,递归被避免。因此,直接读取或写入对象的 __dict__ 中的数据是一种常见的 Python 元编程技巧。
警告
解释器通过首先查看 obj 的类来评估 obj.my_attr。如果类具有与 my_attr 名称相同的属性,则该属性会遮蔽同名的实例属性。“属性覆盖实例属性” 中的示例将演示这一点,而 第二十三章 将揭示属性是作为描述符实现的——这是一种更强大和通用的抽象。
当我编写 示例 22-14 中的列表推导式时,我的程序员蜥蜴大脑想到:“这可能会很昂贵。” 实际上并不是,因为 OSCON 数据集中的事件只有少数演讲者,所以编写任何更复杂的东西都会过早优化。然而,缓存属性是一个常见的需求,但也有一些注意事项。让我们在接下来的示例中看看如何做到这一点。
步骤 4:定制属性缓存
缓存属性是一个常见的需求,因为人们期望像 event.venue 这样的表达式应该是廉价的。⁸ 如果 Record.fetch 方法背后的 Event 属性需要查询数据库或 Web API,某种形式的缓存可能会变得必要。
在第一版 Fluent Python 中,我为 speakers 方法编写了自定义缓存逻辑,如 示例 22-15 所示。
示例 22-15. 使用 hasattr 的自定义缓存逻辑会禁用键共享优化
@propertydef speakers(self):if not hasattr(self, '__speaker_objs'): # ①spkr_serials = self.__dict__['speakers']fetch = self.__class__.fetchself.__speaker_objs = [fetch(f'speaker.{key}')for key in spkr_serials]return self.__speaker_objs # ②
①
如果实例没有名为 __speaker_objs 的属性,则获取演讲者对象并将它们存储在那里。
②
返回 self.__speaker_objs。
在 示例 22-15 中手动缓存是直接的,但在实例初始化后创建属性会破坏 PEP 412—Key-Sharing Dictionary 优化,如 “dict 工作原理的实际后果” 中所解释的。根据数据集的大小,内存使用量的差异可能很重要。
一个类似的手动解决方案,与键共享优化很好地配合使用,需要为 Event 类编写一个 __init__,以创建必要的 __speaker_objs 并将其初始化为 None,然后在 speakers 方法中检查这一点。参见 示例 22-16。
示例 22-16. 在 __init__ 中定义存储以利用键共享优化
class Event(Record):def __init__(self, **kwargs):self.__speaker_objs = Nonesuper().__init__(**kwargs)# 15 lines omitted...@propertydef speakers(self):if self.__speaker_objs is None:spkr_serials = self.__dict__['speakers']fetch = self.__class__.fetchself.__speaker_objs = [fetch(f'speaker.{key}')for key in spkr_serials]return self.__speaker_objs
示例 22-15 和 22-16 展示了在传统 Python 代码库中相当常见的简单缓存技术。然而,在多线程程序中,像这样的手动缓存会引入可能导致数据损坏的竞争条件。如果两个线程正在读取以前未缓存的属性,则第一个线程将需要计算缓存属性的数据(示例中的 __speaker_objs),而第二个线程可能会读取尚不完整的缓存值。
幸运的是,Python 3.8 引入了 @functools.cached_property 装饰器,它是线程安全的。不幸的是,它带来了一些注意事项,接下来会解释。
步骤 5:使用 functools 缓存属性
functools 模块提供了三个用于缓存的装饰器。我们在 “使用 functools.cache 进行记忆化”(第九章)中看到了 @cache 和 @lru_cache。Python 3.8 引入了 @cached_property。
functools.cached_property 装饰器将方法的结果缓存到具有相同名称的实例属性中。例如,在 示例 22-17 中,venue 方法计算的值存储在 self 中的 venue 属性中。之后,当客户端代码尝试读取 venue 时,新创建的 venue 实例属性将被使用,而不是方法。
示例 22-17. 使用 @cached_property 的简单示例
@cached_propertydef venue(self):key = f'venue.{self.venue_serial}'return self.__class__.fetch(key)
在 “第 3 步:覆盖现有属性的属性” 中,我们看到属性通过相同名称的实例属性进行遮蔽。如果这是真的,那么 @cached_property 如何工作呢?如果属性覆盖了实例属性,那么 venue 属性将被忽略,venue 方法将始终被调用,每次计算 key 并运行 fetch!
答案有点令人沮丧:cached_property 是一个误称。@cached_property 装饰器并不创建一个完整的属性,而是创建了一个 非覆盖描述符。描述符是一个管理另一个类中属性访问的对象。我们将在 第二十三章 中深入探讨描述符。property 装饰器是一个用于创建 覆盖描述符 的高级 API。第二十三章 将详细解释 覆盖 与 非覆盖 描述符的区别。
现在,让我们暂时搁置底层实现,关注从用户角度看 cached_property 和 property 之间的区别。Raymond Hettinger 在 Python 文档 中很好地解释了它们:
cached_property()的机制与property()有所不同。普通属性会阻止属性写入,除非定义了 setter。相比之下,cached_property允许写入。
cached_property装饰器仅在查找时运行,并且仅当同名属性不存在时才运行。当它运行时,cached_property会写入具有相同名称的属性。随后的属性读取和写入优先于cached_property方法,并且它的工作方式类似于普通属性。缓存的值可以通过删除属性来清除。这允许
cached_property方法再次运行。⁹
回到我们的 Event 类:@cached_property 的具体行为使其不适合装饰 speakers,因为该方法依赖于一个名为 speakers 的现有属性,其中包含活动演讲者的序列号。
警告
@cached_property 有一些重要的限制:
-
如果装饰的方法已经依赖于同名实例属性,则它不能作为
@property的即插即用替代品。 -
它不能在定义了
__slots__的类中使用。 -
它打败了实例
__dict__的键共享优化,因为它在__init__之后创建了一个实例属性。
尽管存在这些限制,@cached_property 以简单的方式满足了常见需求,并且是线程安全的。它的 Python 代码 是使用 可重入锁 的一个示例。
@cached_property 的 文档 建议了一个替代解决方案,我们可以在 speakers 上使用 @property 和 @cache 装饰器叠加,就像 示例 22-18 中展示的那样。
示例 22-18. 在 @property 上叠加 @cache
@property # ①@cache # ②def speakers(self):spkr_serials = self.__dict__['speakers']fetch = self.__class__.fetchreturn [fetch(f'speaker.{key}')for key in spkr_serials]
①
顺序很重要:@property 放在最上面…
②
…@cache。
从“堆叠装饰器”中回想一下该语法的含义。示例 22-18 的前三行类似于:
speakers = property(cache(speakers))
@cache应用于speakers,返回一个新函数。然后,该函数被@property装饰,将其替换为一个新构造的属性。
这结束了我们对只读属性和缓存装饰器的讨论,探索 OSCON 数据集。在下一节中,我们将开始一个新系列的示例,创建读/写属性。``````# 使用属性进行属性验证
除了计算属性值外,属性还用于通过将公共属性更改为由 getter 和 setter 保护的属性来强制执行业务规则,而不影响客户端代码。让我们通过一个扩展示例来详细讨论。
LineItem 第一次尝试:订单中的商品类
想象一个销售散装有机食品的商店的应用程序,客户可以按重量订购坚果、干果或谷物。在该系统中,每个订单将包含一系列行项目,每个行项目可以由一个类的实例表示,如示例 22-19 中所示。
示例 22-19。bulkfood_v1.py:最简单的LineItem类
class LineItem:def __init__(self, description, weight, price):self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.price
这很简单明了。也许太简单了。示例 22-20 展示了一个问题。
示例 22-20。负重导致负小计
>>> raisins = LineItem('Golden raisins', 10, 6.95)>>> raisins.subtotal()69.5>>> raisins.weight = -20 # garbage in...>>> raisins.subtotal() # garbage out...-139.0
这只是一个玩具示例,但并不像你想象的那样幻想。这是亚马逊.com 早期的一个故事:
我们发现客户可以订购负数数量的书!然后我们会用价格给他们的信用卡记账,我猜,等待他们发货。
亚马逊.com 创始人兼首席执行官杰夫·贝索斯¹⁰
我们如何解决这个问题?我们可以改变LineItem的接口,使用 getter 和 setter 来处理weight属性。那将是 Java 的方式,这并不是错误的。
另一方面,能够通过简单赋值来设置物品的weight是很自然的;也许系统已经在生产中,其他部分已经直接访问item.weight。在这种情况下,Python 的做法是用属性替换数据属性。
LineItem 第二次尝试:一个验证属性
实现一个属性将允许我们使用一个 getter 和一个 setter,但LineItem的接口不会改变(即,设置LineItem的weight仍然写作raisins.weight = 12)。
示例 22-21 列出了一个读/写weight属性的代码。
示例 22-21。bulkfood_v2.py:带有weight属性的LineItem
class LineItem:def __init__(self, description, weight, price):self.description = descriptionself.weight = weight # ①self.price = pricedef subtotal(self):return self.weight * self.price@property # ②def weight(self): # ③return self.__weight # ④@weight.setter # ⑤def weight(self, value):if value > 0:self.__weight = value # ⑥else:raise ValueError('value must be > 0') # ⑦
①
这里属性 setter 已经在使用中,确保不会创建带有负weight的实例。
②
@property装饰 getter 方法。
③
所有实现属性的方法都共享公共属性的名称:weight。
④
实际值存储在私有属性__weight中。
⑤
装饰的 getter 具有.setter属性,这也是一个装饰器;这将 getter 和 setter 绑定在一起。
⑥
如果值大于零,我们设置私有__weight。
⑦
否则,将引发ValueError。
请注意,现在无法创建具有无效重量的LineItem:
>>> walnuts = LineItem('walnuts', 0, 10.00)
Traceback (most recent call last):...
ValueError: value must be > 0
现在我们已经保护了weight免受用户提供负值的影响。尽管买家通常不能设置物品的价格,但是文书错误或错误可能会创建一个具有负price的LineItem。为了防止这种情况,我们也可以将price转换为属性,但这将在我们的代码中产生一些重复。
记住保罗·格雷厄姆在第十七章中的引用:“当我在我的程序中看到模式时,我认为这是一个麻烦的迹象。”重复的治疗方法是抽象。有两种抽象属性定义的方法:使用属性工厂或描述符类。描述符类方法更灵活,我们将在第二十三章中全面讨论它。实际上,属性本身是作为描述符类实现的。但在这里,我们将通过实现一个函数作为属性工厂来继续探讨属性。
但在我们实现属性工厂之前,我们需要更深入地了解属性。
对属性进行适当的查看
尽管经常被用作装饰器,但property内置实际上是一个类。在 Python 中,函数和类通常是可互换的,因为两者都是可调用的,而且没有用于对象实例化的new运算符,因此调用构造函数与调用工厂函数没有区别。并且两者都可以用作装饰器,只要它们返回一个适当替代被装饰的可调用对象。
这是property构造函数的完整签名:
property(fget=None, fset=None, fdel=None, doc=None)
所有参数都是可选的,如果没有为其中一个参数提供函数,则生成的属性对象不允许相应的操作。
property类型是在 Python 2.2 中添加的,但@装饰器语法只在 Python 2.4 中出现,因此在几年内,属性是通过将访问器函数作为前两个参数来定义的。
用装饰器的方式定义属性的“经典”语法在示例 22-22 中有所说明。
示例 22-22。bulkfood_v2b.py:与示例 22-21 相同,但不使用装饰器
class LineItem:def __init__(self, description, weight, price):self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.pricedef get_weight(self): # ①return self.__weightdef set_weight(self, value): # ②if value > 0:self.__weight = valueelse:raise ValueError('value must be > 0')weight = property(get_weight, set_weight) # ③
①
一个普通的 getter。
②
一个普通的 setter。
③
构建property并将其分配给一个公共类属性。
在某些情况下,经典形式比装饰器语法更好;我们将很快讨论的属性工厂的代码就是一个例子。另一方面,在一个有许多方法的类体中,装饰器使得明确哪些是 getter 和 setter,而不依赖于在它们的名称中使用get和set前缀的约定。
类中存在属性会影响实例中属性的查找方式,这可能一开始会让人感到惊讶。下一节将解释。
属性覆盖实例属性
属性始终是类属性,但实际上管理类的实例中的属性访问。
在“覆盖类属性”中,我们看到当一个实例及其类都有相同名称的数据属性时,实例属性会覆盖或遮蔽类属性——至少在通过该实例读取时是这样的。示例 22-23 说明了这一点。
示例 22-23。实例属性遮蔽类data属性
>>> class Class: # ①
... data = 'the class data attr'
... @property
... def prop(self):
... return 'the prop value'
...
>>> obj = Class()
>>> vars(obj) # ②
{} >>> obj.data # ③
'the class data attr' >>> obj.data = 'bar' # ④
>>> vars(obj) # ⑤
{'data': 'bar'} >>> obj.data # ⑥
'bar' >>> Class.data # ⑦
'the class data attr'
①
使用两个类属性data属性和prop属性定义Class。
②
vars返回obj的__dict__,显示它没有实例属性。
③
从obj.data中读取Class.data的值。
④
写入 obj.data 创建一个实例属性。
⑤
检查实例以查看实例属性。
⑥
现在从 obj.data 读取将检索实例属性的值。当从 obj 实例读取时,实例 data 遮蔽了类 data。
⑦
Class.data 属性保持不变。
现在,让我们尝试覆盖 obj 实例上的 prop 属性。继续之前的控制台会话,我们有示例 22-24。
示例 22-24. 实例属性不会遮蔽类属性(续自示例 22-23)
>>> Class.prop # ①
<property object at 0x1072b7408> >>> obj.prop # ②
'the prop value' >>> obj.prop = 'foo' # ③
Traceback (most recent call last):...
AttributeError: can't set attribute
>>> obj.__dict__['prop'] = 'foo' # ④
>>> vars(obj) # ⑤
{'data': 'bar', 'prop': 'foo'} >>> obj.prop # ⑥
'the prop value' >>> Class.prop = 'baz' # ⑦
>>> obj.prop # ⑧
'foo'
①
直接从 Class 中读取 prop 会检索属性对象本身,而不会运行其 getter 方法。
②
读取 obj.prop 执行属性的 getter。
③
尝试设置实例 prop 属性失败。
④
直接将 'prop' 放入 obj.__dict__ 中有效。
⑤
我们可以看到 obj 现在有两个实例属性:data 和 prop。
⑥
然而,读取 obj.prop 仍然会运行属性的 getter。属性不会被实例属性遮蔽。
⑦
覆盖 Class.prop 会销毁属性对象。
⑧
现在 obj.prop 检索实例属性。Class.prop 不再是属性,因此不再覆盖 obj.prop。
作为最后的演示,我们将向 Class 添加一个新属性,并看到它如何覆盖实例属性。示例 22-25 接续了示例 22-24。
示例 22-25. 新类属性遮蔽现有实例属性(续自示例 22-24)
>>> obj.data # ①
'bar' >>> Class.data # ②
'the class data attr' >>> Class.data = property(lambda self: 'the "data" prop value') # ③
>>> obj.data # ④
'the "data" prop value' >>> del Class.data # ⑤
>>> obj.data # ⑥
'bar'
①
obj.data 检索实例 data 属性。
②
Class.data 检索类 data 属性。
③
用新属性覆盖 Class.data。
④
obj.data 现在被 Class.data 属性遮蔽。
⑤
删除属性。
⑥
obj.data 现在再次读取实例 data 属性。
本节的主要观点是,像 obj.data 这样的表达式并不会从 obj 开始搜索 data。搜索实际上从 obj.__class__ 开始,只有在类中没有名为 data 的属性时,Python 才会在 obj 实例本身中查找。这适用于一般的覆盖描述符,其中属性只是一个例子。对描述符的进一步处理必须等到第二十三章。
现在回到属性。每个 Python 代码单元——模块、函数、类、方法——都可以有一个文档字符串。下一个主题是如何将文档附加到属性上。
属性文档
当工具如控制台的 help() 函数或 IDE 需要显示属性的文档时,它们会从属性的 __doc__ 属性中提取信息。
如果与经典调用语法一起使用,property 可以将文档字符串作为 doc 参数:
weight = property(get_weight, set_weight, doc='weight in kilograms')
getter 方法的文档字符串——带有 @property 装饰器本身——被用作整个属性的文档。图 22-1 展示了从示例 22-26 中的代码生成的帮助屏幕。
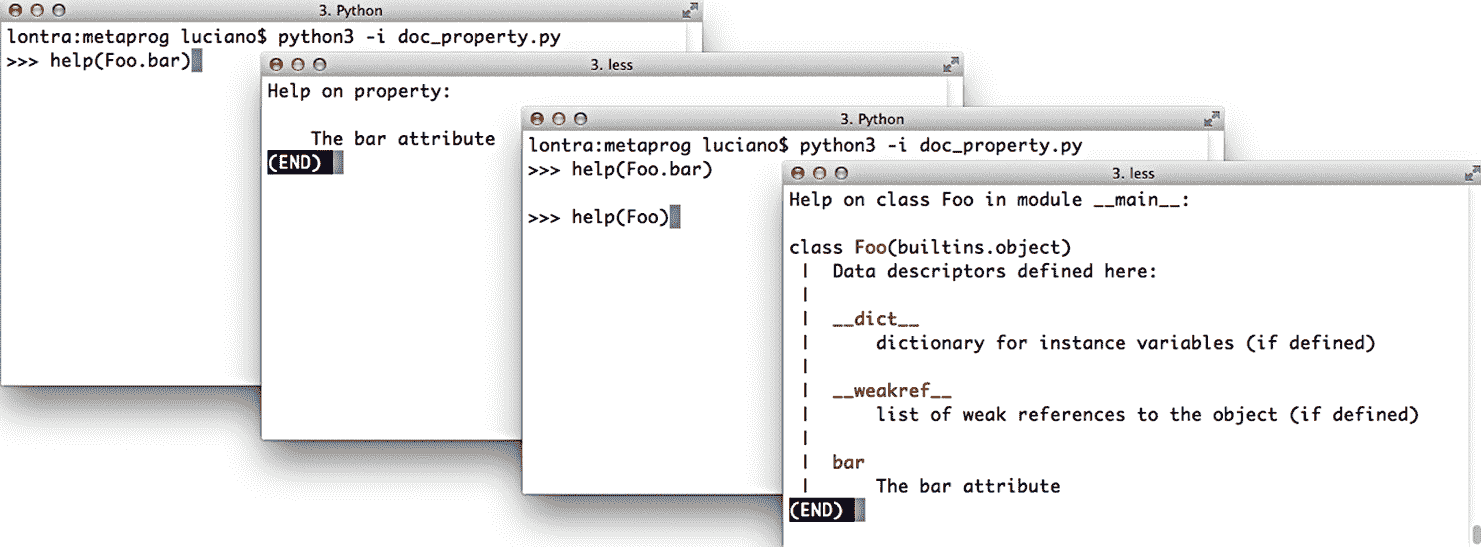
图 22-1. Python 控制台的屏幕截图,当发出命令 help(Foo.bar) 和 help(Foo) 时。源代码在示例 22-26 中。
示例 22-26. 属性的文档
class Foo:@propertydef bar(self):"""The bar attribute"""return self.__dict__['bar']@bar.setterdef bar(self, value):self.__dict__['bar'] = value
现在我们已经掌握了这些属性的基本要点,让我们回到保护 LineItem 的 weight 和 price 属性只接受大于零的值的问题上来,但不需要手动实现两个几乎相同的 getter/setter 对。
编写属性工厂
我们将创建一个工厂来创建 quantity 属性,因为受管属性代表应用程序中不能为负或零的数量。示例 22-27 展示了 LineItem 类使用两个 quantity 属性实例的清晰外观:一个用于管理 weight 属性,另一个用于 price。
示例 22-27. bulkfood_v2prop.py:使用 quantity 属性工厂
class LineItem:weight = quantity('weight') # ①price = quantity('price') # ②def __init__(self, description, weight, price):self.description = descriptionself.weight = weight # ③self.price = pricedef subtotal(self):return self.weight * self.price # ④
①
使用工厂定义第一个自定义属性 weight 作为类属性。
②
这第二次调用构建了另一个自定义属性 price。
③
这里属性已经激活,确保拒绝负数或 0 的 weight。
④
这些属性也在此处使用,检索存储在实例中的值。
请记住属性是类属性。在构建每个 quantity 属性时,我们需要传递将由该特定属性管理的 LineItem 属性的名称。在这一行中不得不两次输入单词 weight 是不幸的:
weight = quantity('weight')
但避免重复是复杂的,因为属性无法知道将绑定到它的类属性名称。记住:赋值语句的右侧首先被评估,因此当调用 quantity() 时,weight 类属性甚至不存在。
注意
改进 quantity 属性,使用户无需重新输入属性名称是一个非常棘手的元编程问题。我们将在第二十三章中解决这个问题。
示例 22-28 列出了 quantity 属性工厂的实现。¹¹
示例 22-28. bulkfood_v2prop.py:quantity 属性工厂
def quantity(storage_name): # ①def qty_getter(instance): # ②return instance.__dict__[storage_name] # ③def qty_setter(instance, value): # ④if value > 0:instance.__dict__[storage_name] = value # ⑤else:raise ValueError('value must be > 0')return property(qty_getter, qty_setter) # ⑥
①
storage_name 参数确定每个属性的数据存储位置;对于 weight,存储名称将是 'weight'。
②
qty_getter 的第一个参数可以命名为 self,但这将很奇怪,因为这不是一个类体;instance 指的是将存储属性的 LineItem 实例。
③
qty_getter 引用 storage_name,因此它将在此函数的闭包中保留;值直接从 instance.__dict__ 中检索,以绕过属性并避免无限递归。
④
qty_setter 被定义,同时将 instance 作为第一个参数。
⑤
value 直接存储在 instance.__dict__ 中,再次绕过属性。
⑥
构建自定义属性对象并返回它。
值得仔细研究的 示例 22-28 部分围绕着 storage_name 变量展开。当你以传统方式编写每个属性时,在 getter 和 setter 方法中硬编码了存储值的属性名称。但在这里,qty_getter 和 qty_setter 函数是通用的,它们依赖于 storage_name 变量来知道在实例 __dict__ 中获取/设置托管属性的位置。每次调用 quantity 工厂来构建属性时,storage_name 必须设置为一个唯一的值。
函数 qty_getter 和 qty_setter 将被工厂函数最后一行创建的 property 对象包装。稍后,当调用执行它们的职责时,这些函数将从它们的闭包中读取 storage_name,以确定从哪里检索/存储托管属性值。
在 示例 22-29 中,我创建并检查一个 LineItem 实例,暴露存储属性。
示例 22-29. bulkfood_v2prop.py:探索属性和存储属性
>>> nutmeg = LineItem('Moluccan nutmeg', 8, 13.95) >>> nutmeg.weight, nutmeg.price # ①(8, 13.95) >>> nutmeg.__dict__ # ②{'description': 'Moluccan nutmeg', 'weight': 8, 'price': 13.95}
①
通过遮蔽同名实例属性的属性来读取 weight 和 price。
②
使用 vars 检查 nutmeg 实例:这里我们看到用于存储值的实际实例属性。
注意我们的工厂构建的属性如何利用 “属性覆盖实例属性” 中描述的行为:weight 属性覆盖了 weight 实例属性,以便每个对 self.weight 或 nutmeg.weight 的引用都由属性函数处理,而绕过属性逻辑的唯一方法是直接访问实例 __dict__。
示例 22-28 中的代码可能有点棘手,但很简洁:它的长度与仅定义 weight 属性的装饰的 getter/setter 对相同,如 示例 22-21 中所示。在 示例 22-27 中,LineItem 定义看起来更好,没有 getter/setter 的干扰。
在一个真实的系统中,同样类型的验证可能出现在许多字段中,跨越几个类,并且 quantity 工厂将被放置在一个实用模块中,以便反复使用。最终,这个简单的工厂可以重构为一个更可扩展的描述符类,具有执行不同验证的专门子类。我们将在 第二十三章 中进行这样的操作。
现在让我们结束对属性的讨论,转向属性删除的问题。
处理属性删除
我们可以使用 del 语句来删除变量,也可以删除属性:
>>> class Demo:
... pass
...
>>> d = Demo()
>>> d.color = 'green'
>>> d.color
'green'
>>> del d.color
>>> d.color
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AttributeError: 'Demo' object has no attribute 'color'
在实践中,删除属性并不是我们在 Python 中每天都做的事情,而且要求使用属性处理它更加不寻常。但是它是被支持的,我可以想到一个愚蠢的例子来演示它。
在属性定义中,@my_property.deleter 装饰器包装了负责删除属性的方法。正如承诺的那样,愚蠢的 示例 22-30 受到了《Monty Python and the Holy Grail》中黑骑士场景的启发。¹²
示例 22-30. blackknight.py
class BlackKnight:def __init__(self):self.phrases = [('an arm', "'Tis but a scratch."),('another arm', "It's just a flesh wound."),('a leg', "I'm invincible!"),('another leg', "All right, we'll call it a draw.")]@propertydef member(self):print('next member is:')return self.phrases[0][0]@member.deleterdef member(self):member, text = self.phrases.pop(0)print(f'BLACK KNIGHT (loses {member}) -- {text}')
blackknight.py 中的文档测试在 示例 22-31 中。
示例 22-31. blackknight.py:示例 22-30 的文档测试(黑骑士永不认输)
>>> knight = BlackKnight()>>> knight.membernext member is:'an arm'>>> del knight.memberBLACK KNIGHT (loses an arm) -- 'Tis but a scratch.>>> del knight.memberBLACK KNIGHT (loses another arm) -- It's just a flesh wound.>>> del knight.memberBLACK KNIGHT (loses a leg) -- I'm invincible!>>> del knight.memberBLACK KNIGHT (loses another leg) -- All right, we'll call it a draw.
使用经典的调用语法而不是装饰器,fdel 参数配置了删除函数。例如,在 BlackKnight 类的主体中,member 属性将被编码为:
member = property(member_getter, fdel=member_deleter)
如果您没有使用属性,属性删除也可以通过实现更低级的__delattr__特殊方法来处理,如“属性处理的特殊方法”中所述。编写一个带有__delattr__的愚蠢类留给拖延的读者作为练习。
属性是一个强大的功能,但有时更简单或更低级的替代方案更可取。在本章的最后一节中,我们将回顾 Python 为动态属性编程提供的一些核心 API。
处理属性的基本属性和函数
在本章中,甚至在本书之前,我们已经使用了 Python 提供的一些用于处理动态属性的内置函数和特殊方法。本节将它们的概述放在一个地方,因为它们的文档分散在官方文档中。
影响属性处理的特殊属性
下面列出的许多函数和特殊方法的行为取决于三个特殊属性:
__class__
对象的类的引用(即obj.__class__与type(obj)相同)。Python 仅在对象的类中查找__getattr__等特殊方法,而不在实例本身中查找。
__dict__
存储对象或类的可写属性的映射。具有__dict__的对象可以随时设置任意新属性。如果一个类具有__slots__属性,则其实例可能没有__dict__。请参阅__slots__(下一节)。
__slots__
可以在类中定义的属性,用于节省内存。__slots__是一个命名允许的属性的字符串tuple。¹³ 如果__slots__中没有'__dict__'名称,那么该类的实例将不会有自己的__dict__,并且只允许在这些实例中列出的属性。更多信息请参阅“使用 slots 节省内存”。
用于属性处理的内置函数
这五个内置函数执行对象属性的读取、写入和内省:
dir([object])
列出对象的大多数属性。官方文档说dir用于交互使用,因此它不提供属性的全面列表,而是提供一个“有趣”的名称集。dir可以检查实现了__dict__或未实现__dict__的对象。dir本身不列出__dict__属性,但列出__dict__键。类的几个特殊属性,如__mro__、__bases__和__name__,也不被dir列出。您可以通过实现__dir__特殊方法来自定义dir的输出,就像我们在示例 22-4 中看到的那样。如果未提供可选的object参数,则dir列出当前范围中的名称。
getattr(object, name[, default])
从object中获取由name字符串标识的属性。主要用例是检索我们事先不知道的属性(或方法)。这可能会从对象的类或超类中获取属性。如果没有这样的属性存在,则getattr会引发AttributeError或返回default值(如果给定)。一个很好的使用getattr的例子是在标准库的cmd包中的Cmd.onecmd方法中,它用于获取和执行用户定义的命令。
hasattr(object, name)
如果命名属性存在于object中,或者可以通过object(例如通过继承)获取,则返回True。文档解释说:“这是通过调用 getattr(object, name)并查看它是否引发 AttributeError 来实现的。”
setattr(object, name, value)
如果object允许,将value分配给object的命名属性。这可能会创建一个新属性或覆盖现有属性。
vars([object])
返回object的__dict__;vars无法处理定义了__slots__且没有__dict__的类的实例(与dir相反,后者处理这些实例)。如果没有参数,vars()与locals()执行相同的操作:返回表示局部作用域的dict。
用于属性处理的特殊方法
当在用户定义的类中实现时,这里列出的特殊方法处理属性的检索、设置、删除和列出。
使用点符号表示法或内置函数getattr、hasattr和setattr访问属性会触发这里列出的适当的特殊方法。直接在实例__dict__中读取和写入属性不会触发这些特殊方法——这是需要绕过它们的常用方式。
章节“3.3.11. 特殊方法查找”中的“数据模型”一章警告:
对于自定义类,只有在对象的类型上定义了特殊方法时,隐式调用特殊方法才能保证正确工作,而不是在对象的实例字典中定义。
换句话说,假设特殊方法将在类本身上检索,即使操作的目标是实例。因此,特殊方法不会被具有相同名称的实例属性遮蔽。
在以下示例中,假设有一个名为Class的类,obj是Class的一个实例,attr是obj的一个属性。
对于这些特殊方法中的每一个,无论是使用点符号表示法还是“用于属性处理的内置函数”中列出的内置函数之一,都没有关系。例如,obj.attr和getattr(obj, 'attr', 42)都会触发Class.__getattribute__(obj, 'attr')。
__delattr__(self, name)
当尝试使用del语句删除属性时始终调用;例如,del obj.attr触发Class.__delattr__(obj, 'attr')。如果attr是一个属性,则如果类实现了__delattr__,则其删除方法永远不会被调用。
__dir__(self)
在对象上调用dir时调用,以提供属性列表;例如,dir(obj)触发Class.__dir__(obj)。在所有现代 Python 控制台中,也被用于制表完成。
__getattr__(self, name)
仅在尝试检索命名属性失败时调用,之后搜索obj、Class及其超类。表达式obj.no_such_attr、getattr(obj, 'no_such_attr')和hasattr(obj, 'no_such_attr')可能会触发Class.__getattr__(obj, 'no_such_attr'),但仅当在obj或Class及其超类中找不到该名称的属性时。
__getattribute__(self, name)
当尝试直接从 Python 代码中检索命名属性时始终调用(解释器在某些情况下可能会绕过此方法,例如获取__repr__方法)。点符号表示法和getattr以及hasattr内置函数会触发此方法。__getattr__仅在__getattribute__之后调用,并且仅在__getattribute__引发AttributeError时才会调用。为了检索实例obj的属性而不触发无限递归,__getattribute__的实现应该使用super().__getattribute__(obj, name)。
__setattr__(self, name, value)
当尝试设置命名属性时始终调用。点符号和setattr内置触发此方法;例如,obj.attr = 42和setattr(obj, 'attr', 42)都会触发Class.__setattr__(obj, 'attr', 42)。
警告
实际上,因为它们被无条件调用并影响几乎每个属性访问,__getattribute__和__setattr__特殊方法比__getattr__更难正确使用,后者仅处理不存在的属性名称。使用属性或描述符比定义这些特殊方法更不容易出错。
这结束了我们对属性、特殊方法和其他编写动态属性技术的探讨。
章节总结
我们通过展示简单类的实际示例来开始动态属性的覆盖。第一个示例是FrozenJSON类,它将嵌套的字典和列表转换为嵌套的FrozenJSON实例和它们的列表。FrozenJSON代码演示了使用__getattr__特殊方法在读取属性时动态转换数据结构。FrozenJSON的最新版本展示了使用__new__构造方法将一个类转换为灵活的对象工厂,不限于自身的实例。
然后,我们将 JSON 数据集转换为存储Record类实例的dict。Record的第一个版本只有几行代码,并引入了“bunch”习惯用法:使用self.__dict__.update(**kwargs)从传递给__init__的关键字参数构建任意属性。第二次迭代添加了Event类,通过属性实现自动检索链接记录。计算属性值有时需要缓存,我们介绍了几种方法。
在意识到@functools.cached_property并非总是适用后,我们了解了一种替代方法:按顺序将@property与@functools.cache结合使用。
属性的覆盖继续在LineItem类中进行,其中部署了一个属性来保护weight属性免受没有业务意义的负值或零值的影响。在更深入地了解属性语法和语义之后,我们创建了一个属性工厂,以强制在weight和price上执行相同的验证,而无需编写多个 getter 和 setter。属性工厂利用了微妙的概念——如闭包和属性覆盖实例属性——以使用与手动编码的单个属性定义相同数量的行提供优雅的通用解决方案。
最后,我们简要介绍了使用属性处理属性删除的方法,然后概述了核心 Python 语言中支持属性元编程的关键特殊属性、内置函数和特殊方法。
进一步阅读
属性处理和内省内置函数的官方文档位于Python 标准库的第二章,“内置函数”中。相关的特殊方法和__slots__特殊属性在Python 语言参考的“3.3.2. 自定义属性访问”中有文档。解释了绕过实例调用特殊方法的语义在“3.3.9. 特殊方法查找”中。在Python 标准库的第四章,“内置类型”中,“4.13. 特殊属性”涵盖了__class__和__dict__属性。
Python Cookbook,第 3 版,作者 David Beazley 和 Brian K. Jones(O’Reilly)包含了本章主题的几个示例,但我将重点介绍三个杰出的示例:“Recipe 8.8. 在子类中扩展属性”解决了从超类继承的属性内部方法覆盖的棘手问题;“Recipe 8.15. 委托属性访问”实现了一个代理类,展示了本书中“属性处理的特殊方法”中的大多数特殊方法;以及令人印象深刻的“Recipe 9.21. 避免重复的属性方法”,这是在示例 22-28 中呈现的属性工厂函数的基础。
Python in a Nutshell, 第三版,由 Alex Martelli, Anna Ravenscroft, 和 Steve Holden (O’Reilly) 是严谨和客观的。他们只用了三页来讨论属性,但这是因为该书遵循了公理化的展示风格:前面的 15 页左右提供了对 Python 类语义的彻底描述,包括描述符,这是属性在幕后实际上是如何实现的。所以当 Martelli 等人讨论属性时,他们在这三页中包含了许多见解—包括我选择用来开启本章的内容。
Bertrand Meyer—在本章开头引用的统一访问原则定义中—开创了契约式设计方法,设计了 Eiffel 语言,并撰写了优秀的 面向对象软件构造,第二版 (Pearson)。前六章提供了我见过的最好的面向对象分析和设计的概念介绍之一。第十一章介绍了契约式设计,第三十五章提供了 Meyer 对一些有影响力的面向对象语言的评估:Simula、Smalltalk、CLOS (Common Lisp Object System)、Objective-C、C++ 和 Java,并简要评论了其他一些语言。直到书的最后一页,他才透露他所使用的易读的伪代码“符号”是 Eiffel。
¹ Alex Martelli, Anna Ravenscroft, 和 Steve Holden, Python in a Nutshell, 第三版 (O’Reilly), 第 123 页。
² Bertrand Meyer, 面向对象软件构造,第二版 (Pearson),第 57 页。
³ OSCON—O’Reilly 开源大会—成为了 COVID-19 大流行的牺牲品。我用于这些示例的原始 744 KB JSON 文件在 2021 年 1 月 10 日之后不再在线。你可以在osconfeed.json 的示例代码库中找到一份副本。
⁴ 两个例子分别是AttrDict 和 addict。
⁵ 表达式 self.__data[name] 是可能发生 KeyError 异常的地方。理想情况下,应该处理它并引发 AttributeError,因为这是从 __getattr__ 中期望的。勤奋的读者被邀请将错误处理编码为练习。
⁶ 数据的来源是 JSON,而 JSON 数据中唯一的集合类型是 dict 和 list。
⁷ 顺便说一句,Bunch 是 Alex Martelli 用来分享这个提示的类的名称,这个提示来自于 2001 年的一篇名为“简单但方便的‘一堆命名东西’类”的食谱。
⁸ 这实际上是 Meyer 的统一访问原则的一个缺点,我在本章开头提到过。如果你对这个讨论感兴趣,可以阅读可选的“讲台”。
⁹ 来源:@functools.cached_property 文档。我知道 Raymond Hettinger 撰写了这份解释,因为他是作为我提出问题的回应而撰写的:bpo42781—functools.cached_property 文档应该解释它是非覆盖的。Hettinger 是官方 Python 文档和标准库的主要贡献者。他还撰写了优秀的“描述符指南”,这是第二十三章的重要资源。
¹⁰ 杰夫·贝佐斯在 华尔街日报 的报道“一个推销员的诞生”中的直接引用(2011 年 10 月 15 日)。请注意,截至 2021 年,您需要订阅才能阅读这篇文章。
¹¹ 这段代码改编自《Python Cookbook》第 3 版的“食谱 9.21。避免重复的属性方法”,作者是 David Beazley 和 Brian K. Jones(O’Reilly)。
¹² 这血腥场面在 2021 年 10 月我审阅时在 Youtube 上可供观看。
¹³ Alex Martelli 指出,虽然__slots__可以编码为一个list,但最好明确地始终使用一个tuple,因为在类体被处理后更改__slots__中的列表没有效果,因此在那里使用可变序列会产生误导。
¹⁴ Alex Martelli,《Python 速查手册》,第 2 版(O’Reilly),第 101 页。
¹⁵ 我即将提到的原因在《Dr. Dobbs Journal》的文章中提到,标题为“Java 的新特性有害”,作者是 Jonathan Amsterdam,以及在屡获殊荣的书籍Effective Java第 3 版的“考虑使用静态工厂方法代替构造函数”中,作者是 Joshua Bloch(Addison-Wesley)。
第二十三章:属性描述符
了解描述符不仅提供了更大的工具集,还深入了解了 Python 的工作原理,并欣赏了其设计的优雅之处。
Raymond Hettinger,Python 核心开发者和专家¹
描述符是在多个属性中重用相同访问逻辑的一种方式。例如,在 ORM 中,如 Django ORM 和 SQLAlchemy 中的字段类型是描述符,管理数据从数据库记录中的字段流向 Python 对象属性,反之亦然。
描述符是实现由__get__、__set__和__delete__方法组成的动态协议的类。property类实现了完整的描述符协议。与动态协议一样,部分实现是可以的。事实上,我们在实际代码中看到的大多数描述符只实现了__get__和__set__,许多只实现了这些方法中的一个。
描述符是 Python 的一个显著特征,不仅在应用程序级别部署,还在语言基础设施中部署。用户定义的函数是描述符。我们将看到描述符协议如何允许方法作为绑定或非绑定方法运行,具体取决于它们的调用方式。
理解描述符是掌握 Python 的关键。这就是本章的主题。
在本章中,我们将重构我们在“使用属性进行属性验证”中首次看到的大量食品示例,将属性替换为描述符。这将使在不同类之间重用属性验证逻辑变得更容易。我们将解决覆盖和非覆盖描述符的概念,并意识到 Python 函数也是描述符。最后,我们将看到一些关于实现描述符的提示。
本章的新内容
由于 Python 3.6 中添加了描述符协议的__set_name__特殊方法,“LineItem Take #4: 自动命名存储属性”中的Quantity描述符示例得到了极大简化。
我删除了以前在“LineItem Take #4: 自动命名存储属性”中的属性工厂示例,因为它变得无关紧要:重点是展示解决Quantity问题的另一种方法,但随着__set_name__的添加,描述符解决方案变得简单得多。
以前出现在“LineItem Take #5: 新的描述符类型”中的AutoStorage类也消失了,因为__set_name__使其变得过时。
描述符示例:属性验证
正如我们在“编写属性工厂”中看到的,属性工厂是一种避免重复编写获取器和设置器的方法,通过应用函数式编程模式来实现。属性工厂是一个高阶函数,它创建一个参数化的访问器函数集,并从中构建一个自定义属性实例,使用闭包来保存像storage_name这样的设置。解决相同问题的面向对象方式是使用描述符类。
我们将继续之前留下的LineItem示例系列,在“编写属性工厂”中,通过将quantity属性工厂重构为Quantity描述符类来使其更易于使用。
LineItem Take #3: 一个简单的描述符
正如我们在介绍中所说,实现__get__、__set__或__delete__方法的类是描述符。您通过将其实例声明为另一个类的类属性来使用描述符。
我们将创建一个Quantity描述符,LineItem类将使用两个Quantity实例:一个用于管理weight属性,另一个用于price。图表有助于理解,所以看一下图 23-1。
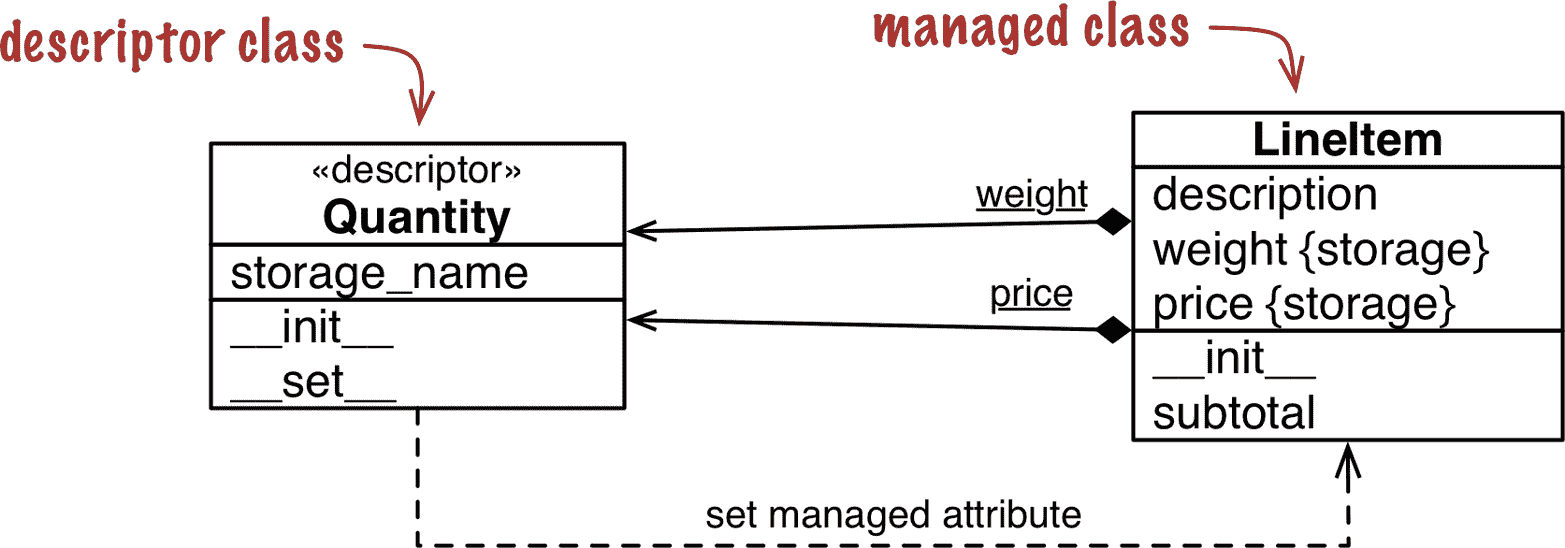
图 23-1。LineItem使用名为Quantity的描述符类的 UML 类图。在 UML 中带有下划线的属性是类属性。请注意,weight 和 price 是附加到LineItem类的Quantity实例,但LineItem实例也有自己的 weight 和 price 属性,其中存储这些值。
请注意,单词weight在图 23-1 中出现两次,因为实际上有两个名为weight的不同属性:一个是LineItem的类属性,另一个是将存在于每个LineItem对象中的实例属性。price也适用于此。
理解描述符的术语
实现和使用描述符涉及几个组件,精确命名这些组件是很有用的。在本章的示例中,我将使用以下术语和定义来描述。一旦看到代码,它们将更容易理解,但我想提前列出这些定义,以便您在需要时可以参考它们。
描述符类
实现描述符协议的类。在图 23-1 中就是Quantity。
托管类
声明描述符实例为类属性的类。在图 23-1 中,LineItem是托管类。
描述符实例
每个描述符类的实例,声明为托管类的类属性。在图 23-1 中,每个描述符实例由一个带有下划线名称的组合箭头表示(下划线表示 UML 中的类属性)。黑色菱形接触LineItem类,其中包含描述符实例。
托管实例
托管类的一个实例。在这个例子中,LineItem实例是托管实例(它们没有显示在类图中)。
存储属性
托管实例的属性,保存该特定实例的托管属性的值。在图 23-1 中,LineItem实例的属性weight和price是存储属性。它们与描述符实例不同,后者始终是类属性。
托管属性
托管类中的公共属性,由描述符实例处理,值存储在存储属性中。换句话说,描述符实例和存储属性为托管属性提供基础设施。
重要的是要意识到Quantity实例是LineItem的类属性。这一关键点在图 23-2 中由磨坊和小玩意突出显示。
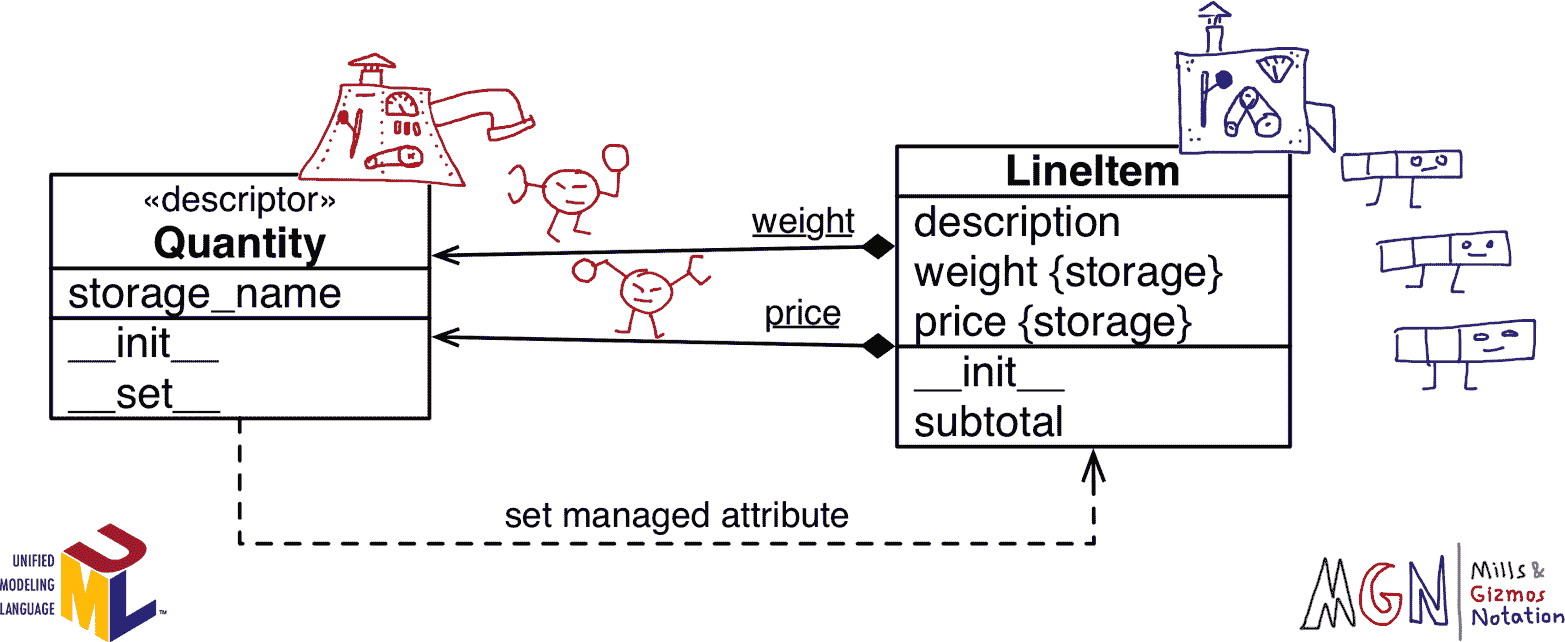
图 23-2。使用 MGN(磨坊和小玩意符号)注释的 UML 类图:类是生产小玩意的磨坊。Quantity磨坊生成两个带有圆形头部的小玩意,它们附加到LineItem磨坊:weight 和 price。LineItem磨坊生成具有自己的 weight 和 price 属性的矩形小玩意,其中存储这些值。
现在足够涂鸦了。这里是代码:示例 23-1 展示了Quantity描述符类,示例 23-2 列出了使用两个Quantity实例的新LineItem类。
示例 23-1。bulkfood_v3.py:Quantity描述符不接受负值
class Quantity: # ①def __init__(self, storage_name):self.storage_name = storage_name # ②def __set__(self, instance, value): # ③if value > 0:instance.__dict__[self.storage_name] = value # ④else:msg = f'{self.storage_name} must be > 0'raise ValueError(msg)def __get__(self, instance, owner): # ⑤return instance.__dict__[self.storage_name]
①
描述符是基于协议的特性;不需要子类化来实现。
②
每个Quantity实例都将有一个storage_name属性:这是用于在托管实例中保存值的存储属性的名称。
③
当尝试对托管属性进行赋值时,将调用__set__。在这里,self是描述符实例(即LineItem.weight或LineItem.price),instance是托管实例(一个LineItem实例),value是正在分配的值。
④
我们必须直接将属性值存储到__dict__中;调用setattr(instance, self.storage_name)将再次触发__set__方法,导致无限递归。
⑤
我们需要实现__get__,因为被管理属性的名称可能与storage_name不同。owner参数将很快解释。
实现__get__是必要的,因为用户可能会编写类似于这样的内容:
class House:rooms = Quantity('number_of_rooms')
在House类中,被管理的属性是rooms,但存储属性是number_of_rooms。给定一个名为chaos_manor的House实例,读取和写入chaos_manor.rooms会通过附加到rooms的Quantity描述符实例,但读取和写入chaos_manor.number_of_rooms会绕过描述符。
请注意,__get__接收三个参数:self、instance和owner。owner参数是被管理类的引用(例如LineItem),如果您希望描述符支持检索类属性以模拟 Python 在实例中找不到名称时检索类属性的默认行为,则很有用。
如果通过类(如LineItem.weight)检索被管理属性(例如weight),则描述符__get__方法的instance参数的值为None。
为了支持用户的内省和其他元编程技巧,最好让__get__在通过类访问被管理属性时返回描述符实例。为此,我们将像这样编写__get__:
def __get__(self, instance, owner):if instance is None:return selfelse:return instance.__dict__[self.storage_name]
示例 23-2 演示了在LineItem中使用Quantity。
示例 23-2. bulkfood_v3.py:Quantity描述符管理LineItem中的属性
class LineItem:weight = Quantity('weight') # ①price = Quantity('price') # ②def __init__(self, description, weight, price): # ③self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.price
①
第一个描述符实例将管理weight属性。
②
第二个描述符实例将管理price属性。
③
类主体的其余部分与bulkfood_v1.py中的原始代码一样简单干净(示例 22-19)。
示例 23-2 中的代码按预期运行,防止以$0 的价格出售松露:³
>>> truffle = LineItem('White truffle', 100, 0)
Traceback (most recent call last):...
ValueError: value must be > 0
警告
在编写描述符__get__和__set__方法时,请记住self和instance参数的含义:self是描述符实例,instance是被管理实例。管理实例属性的描述符应将值存储在被管理实例中。这就是为什么 Python 提供instance参数给描述符方法的原因。
存储每个被管理属性的值在描述符实例本身中可能很诱人,但是错误的。换句话说,在__set__方法中,而不是编写:
instance.__dict__[self.storage_name] = value
诱人但错误的替代方案是:
self.__dict__[self.storage_name] = value
要理解为什么这样做是错误的,请考虑__set__的前两个参数的含义:self和instance。这里,self是描述符实例,实际上是被管理类的类属性。您可能在内存中同时拥有成千上万个LineItem实例,但只有两个描述符实例:类属性LineItem.weight和LineItem.price。因此,您存储在描述符实例本身中的任何内容实际上是LineItem类属性的一部分,因此在所有LineItem实例之间共享。
示例 23-2 的一个缺点是在被管理类主体中实例化描述符时需要重复属性名称。如果LineItem类可以这样声明就好了:
class LineItem:weight = Quantity()price = Quantity()# remaining methods as before
目前,示例 23-2 需要显式命名每个Quantity,这不仅不方便,而且很危险。如果一个程序员复制粘贴代码时忘记编辑两个名称,并写出类似price = Quantity('weight')的内容,程序将表现糟糕,每当设置price时都会破坏weight的值。
问题在于——正如我们在第六章中看到的——赋值的右侧在变量存在之前执行。表达式Quantity()被评估为创建一个描述符实例,而Quantity类中的代码无法猜测描述符将绑定到的变量的名称(例如weight或price)。
幸运的是,描述符协议现在支持名为__set_name__的特殊方法。我们将看到如何使用它。
注意
描述符存储属性的自动命名曾经是一个棘手的问题。在流畅的 Python第一版中,我在本章和下一章中花了几页和几行代码来介绍不同的解决方案,包括使用类装饰器,然后在第二十四章中使用元类。这在 Python 3.6 中得到了极大简化。
LineItem 第 4 版:自动命名存储属性
为了避免在描述符实例中重新输入属性名称,我们将实现__set_name__来设置每个Quantity实例的storage_name。__set_name__特殊方法在 Python 3.6 中添加到描述符协议中。解释器在class体中找到的每个描述符上调用__set_name__——如果描述符实现了它。⁴
在示例 23-3 中,LineItem描述符类不需要__init__。相反,__set_item__保存了存储属性的名称。
示例 23-3. bulkfood_v4.py:__set_name__为每个Quantity描述符实例设置名称
class Quantity:def __set_name__(self, owner, name): # ①self.storage_name = name # ②def __set__(self, instance, value): # ③if value > 0:instance.__dict__[self.storage_name] = valueelse:msg = f'{self.storage_name} must be > 0'raise ValueError(msg)# no __get__ needed # ④class LineItem:weight = Quantity() # ⑤price = Quantity()def __init__(self, description, weight, price):self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.price
①
self是描述符实例(而不是托管实例),owner是托管类,name是owner的属性的名称,在owner的类体中将此描述符实例分配给的名称。
②
这就是示例 23-1 中的__init__所做的事情。
③
这里的__set__方法与示例 23-1 中完全相同。
④
实现__get__是不必要的,因为存储属性的名称与托管属性的名称匹配。表达式product.price直接从LineItem实例获取price属性。
⑤
现在我们不需要将托管属性名称传递给Quantity构造函数。这是这个版本的目标。
查看示例 23-3,您可能会认为这是为了管理几个属性而编写的大量代码,但重要的是要意识到描述符逻辑现在抽象为一个单独的代码单元:Quantity类。通常我们不会在使用它的同一模块中定义描述符,而是在一个专门设计用于跨应用程序使用的实用程序模块中定义描述符——即使在许多应用程序中,如果您正在开发一个库或框架。
有了这个想法,示例 23-4 更好地代表了描述符的典型用法。
示例 23-4. bulkfood_v4c.py:LineItem定义简洁;Quantity描述符类现在位于导入的model_v4c模块中
import model_v4c as model # ①class LineItem:weight = model.Quantity() # ②price = model.Quantity()def __init__(self, description, weight, price):self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.price
①
导入实现Quantity的model_v4c模块。
②
使用model.Quantity。
Django 用户会注意到 示例 23-4 看起来很像一个模型定义。这不是巧合:Django 模型字段就是描述符。
因为描述符是以类的形式实现的,我们可以利用继承来重用一些用于新描述符的代码。这就是我们将在下一节中做的事情。
LineItem 第五版:一种新的描述符类型
想象中的有机食品店遇到了麻烦:某种方式创建了一个带有空白描述的行项目实例,订单无法完成。为了防止这种情况发生,我们将创建一个新的描述符 NonBlank。在设计 NonBlank 时,我们意识到它将非常类似于 Quantity 描述符,除了验证逻辑。
这促使进行重构,生成 Validated,一个覆盖 __set__ 方法的抽象类,调用必须由子类实现的 validate 方法。
然后我们将重写 Quantity,并通过继承 Validated 并编写 validate 方法来实现 NonBlank。
Validated、Quantity 和 NonBlank 之间的关系是《设计模式》经典中描述的 模板方法 的应用:
模板方法以抽象操作的形式定义算法,子类重写这些操作以提供具体行为。⁵
在 示例 23-5 中,Validated.__set__ 是模板方法,self.validate 是抽象操作。
示例 23-5. model_v5.py:Validated 抽象基类
import abcclass Validated(abc.ABC):def __set_name__(self, owner, name):self.storage_name = namedef __set__(self, instance, value):value = self.validate(self.storage_name, value) # ①instance.__dict__[self.storage_name] = value # ②@abc.abstractmethoddef validate(self, name, value): # ③"""return validated value or raise ValueError"""
①
__set__ 将验证委托给 validate 方法…
②
…然后使用返回的 value 更新存储的值。
③
validate 是一个抽象方法;这就是模板方法。
Alex Martelli 更喜欢将这种设计模式称为 自委托,我同意这是一个更具描述性的名称:__set__ 的第一行自委托给 validate。⁶
本示例中的具体 Validated 子类是 Quantity 和 NonBlank,如 示例 23-6 所示。
示例 23-6. model_v5.py:Quantity 和 NonBlank,具体的 Validated 子类
class Quantity(Validated):"""a number greater than zero"""def validate(self, name, value): # ①if value <= 0:raise ValueError(f'{name} must be > 0')return valueclass NonBlank(Validated):"""a string with at least one non-space character"""def validate(self, name, value):value = value.strip()if not value: # ②raise ValueError(f'{name} cannot be blank')return value # ③
①
实现 Validated.validate 抽象方法所需的模板方法。
②
如果前导和尾随空格被剥离后没有剩余内容,则拒绝该值。
③
要求具体的 validate 方法返回经过验证的值,这为它们提供了清理、转换或规范化接收到的数据的机会。在这种情况下,value 被返回时没有前导或尾随空格。
model_v5.py 的用户不需要知道所有这些细节。重要的是他们可以使用 Quantity 和 NonBlank 来自动验证实例属性。请查看 示例 23-7 中的最新 LineItem 类。
示例 23-7. bulkfood_v5.py:LineItem 使用 Quantity 和 NonBlank 描述符
import model_v5 as model # ①class LineItem:description = model.NonBlank() # ②weight = model.Quantity()price = model.Quantity()def __init__(self, description, weight, price):self.description = descriptionself.weight = weightself.price = pricedef subtotal(self):return self.weight * self.price
①
导入 model_v5 模块,并给它一个更友好的名称。
②
将 model.NonBlank 投入使用。其余代码保持不变。
我们在本章中看到的 LineItem 示例展示了描述符管理数据属性的典型用法。像 Quantity 这样的描述符被称为覆盖描述符,因为其 __set__ 方法覆盖(即拦截和覆盖)了受管实例中同名实例属性的设置。然而,也有非覆盖描述符。我们将在下一节详细探讨这种区别。
覆盖与非覆盖描述符
请记住,Python 处理属性的方式存在重要的不对称性。通过实例读取属性通常会返回实例中定义的属性,但如果实例中没有这样的属性,则会检索类属性。另一方面,向实例分配属性通常会在实例中创建属性,而不会对类产生任何影响。
这种不对称性也影响到 descriptors,实际上创建了两种广泛的 descriptors 类别,取决于是否实现了__set__方法。如果存在__set__,则该类是 overriding descriptor;否则,它是 nonoverriding descriptor。在我们研究下面示例中的 descriptor 行为时,这些术语将会有意义。
观察不同 descriptor 类别需要一些类,因此我们将使用 Example 23-8 中的代码作为接下来章节的测试基础。
提示
Example 23-8 中的每个__get__和__set__方法都调用print_args,以便以可读的方式显示它们的调用。理解print_args和辅助函数cls_name和display并不重要,所以不要被它们分散注意力。
示例 23-8. descriptorkinds.py:用于研究 descriptor overriding 行为的简单类。
### auxiliary functions for display only ###def cls_name(obj_or_cls):cls = type(obj_or_cls)if cls is type:cls = obj_or_clsreturn cls.__name__.split('.')[-1]def display(obj):cls = type(obj)if cls is type:return f'<class {obj.__name__}>'elif cls in [type(None), int]:return repr(obj)else:return f'<{cls_name(obj)} object>'def print_args(name, *args):pseudo_args = ', '.join(display(x) for x in args)print(f'-> {cls_name(args[0])}.__{name}__({pseudo_args})')### essential classes for this example ###class Overriding: # ①"""a.k.a. data descriptor or enforced descriptor"""def __get__(self, instance, owner):print_args('get', self, instance, owner) # ②def __set__(self, instance, value):print_args('set', self, instance, value)class OverridingNoGet: # ③"""an overriding descriptor without ``__get__``"""def __set__(self, instance, value):print_args('set', self, instance, value)class NonOverriding: # ④"""a.k.a. non-data or shadowable descriptor"""def __get__(self, instance, owner):print_args('get', self, instance, owner)class Managed: # ⑤over = Overriding()over_no_get = OverridingNoGet()non_over = NonOverriding()def spam(self): # ⑥print(f'-> Managed.spam({display(self)})')
①
一个带有__get__和__set__的 overriding descriptor 类。
②
print_args函数被这个示例中的每个 descriptor 方法调用。
③
没有__get__方法的 overriding descriptor。
④
这里没有__set__方法,因此这是一个 nonoverriding descriptor。
⑤
托管类,使用每个 descriptor 类的一个实例。
⑥
spam方法在这里用于比较,因为方法也是 descriptors。
在接下来的章节中,我们将研究对Managed类及其一个实例上的属性读取和写入的行为,逐个检查定义的不同 descriptors。
Overriding Descriptors
实现__set__方法的 descriptor 是overriding descriptor,因为虽然它是一个类属性,但实现__set__的 descriptor 将覆盖对实例属性的赋值尝试。这就是 Example 23-3 的实现方式。属性也是 overriding descriptors:如果您不提供 setter 函数,property类的默认__set__将引发AttributeError,以表示该属性是只读的。通过 Example 23-8 中的代码,可以在 Example 23-9 中看到对 overriding descriptor 的实验。
警告
Python 的贡献者和作者在讨论这些概念时使用不同的术语。我从书籍Python in a Nutshell中采用了“overriding descriptor”。官方 Python 文档使用“data descriptor”,但“overriding descriptor”突出了特殊行为。Overriding descriptors 也被称为“enforced descriptors”。非 overriding descriptors 的同义词包括“nondata descriptors”或“shadowable descriptors”。
示例 23-9. overriding descriptor 的行为
>>> obj = Managed() # ①
>>> obj.over # ②
-> Overriding.__get__(<Overriding object>, <Managed object>, <class Managed>)
>>> Managed.over # ③
-> Overriding.__get__(<Overriding object>, None, <class Managed>)
>>> obj.over = 7 # ④
-> Overriding.__set__(<Overriding object>, <Managed object>, 7)
>>> obj.over # ⑤
-> Overriding.__get__(<Overriding object>, <Managed object>, <class Managed>)
>>> obj.__dict__['over'] = 8 # ⑥
>>> vars(obj) # ⑦
{'over': 8}
>>> obj.over # ⑧
-> Overriding.__get__(<Overriding object>, <Managed object>, <class Managed>)
①
为测试创建Managed对象。
②
obj.over触发 descriptor __get__ 方法,将托管实例obj作为第二个参数传递。
③
Managed.over触发 descriptor __get__ 方法,将None作为第二个参数(instance)传递。
④
对obj.over进行赋值会触发 descriptor __set__ 方法,将值7作为最后一个参数传递。
⑤
读取obj.over仍然会调用描述符__get__方法。
⑥
绕过描述符,直接将值设置到obj.__dict__。
⑦
验证该值是否在obj.__dict__中,位于over键下。
⑧
然而,即使有一个名为over的实例属性,Managed.over描述符仍然会覆盖尝试读取obj.over。
覆盖没有 get 的描述符
属性和其他覆盖描述符,如 Django 模型字段,实现了__set__和__get__,但也可以只实现__set__,就像我们在示例 23-2 中看到的那样。在这种情况下,只有描述符处理写入。通过实例读取描述符将返回描述符对象本身,因为没有__get__来处理该访问。如果通过直接访问实例__dict__创建了一个同名实例属性,并通过该实例访问设置了一个新值,则__set__方法仍将覆盖进一步尝试设置该属性,但读取该属性将简单地从实例中返回新值,而不是返回描述符对象。换句话说,实例属性将遮蔽描述符,但仅在读取时。参见示例 23-10。
示例 23-10. 没有__get__的覆盖描述符
>>> obj.over_no_get # ①
<__main__.OverridingNoGet object at 0x665bcc>
>>> Managed.over_no_get # ②
<__main__.OverridingNoGet object at 0x665bcc>
>>> obj.over_no_get = 7 # ③
-> OverridingNoGet.__set__(<OverridingNoGet object>, <Managed object>, 7)
>>> obj.over_no_get # ④
<__main__.OverridingNoGet object at 0x665bcc>
>>> obj.__dict__['over_no_get'] = 9 # ⑤
>>> obj.over_no_get # ⑥
9
>>> obj.over_no_get = 7 # ⑦
-> OverridingNoGet.__set__(<OverridingNoGet object>, <Managed object>, 7)
>>> obj.over_no_get # ⑧
9
①
这个覆盖描述符没有__get__方法,因此读取obj.over_no_get会从类中检索描述符实例。
②
如果我们直接从托管类中检索描述符实例,也会发生同样的事情。
③
尝试将值设置为obj.over_no_get会调用__set__描述符方法。
④
因为我们的__set__不进行更改,再次读取obj.over_no_get将从托管类中检索描述符实例。
⑤
通过实例__dict__设置一个名为over_no_get的实例属性。
⑥
现在over_no_get实例属性遮蔽了描述符,但仅用于读取。
⑦
尝试为obj.over_no_get分配一个值仍然会通过描述符集。
⑧
但是对于读取,只要有同名实例属性,该描述符就会被遮蔽。
非覆盖描述符
一个不实现__set__的描述符是一个非覆盖描述符。设置一个同名的实例属性将遮蔽描述符,在该特定实例中无法处理该属性。方法和@functools.cached_property被实现为非覆盖描述符。示例 23-11 展示了非覆盖描述符的操作。
示例 23-11. 非覆盖描述符的行为
>>> obj = Managed()
>>> obj.non_over # ①
-> NonOverriding.__get__(<NonOverriding object>, <Managed object>, <class Managed>)
>>> obj.non_over = 7 # ②
>>> obj.non_over # ③
7
>>> Managed.non_over # ④
-> NonOverriding.__get__(<NonOverriding object>, None, <class Managed>)
>>> del obj.non_over # ⑤
>>> obj.non_over # ⑥
-> NonOverriding.__get__(<NonOverriding object>, <Managed object>, <class Managed>)
①
obj.non_over触发描述符__get__方法,将obj作为第二个参数传递。
②
Managed.non_over是一个非覆盖描述符,因此没有__set__干扰此赋值。
③
现在obj有一个名为non_over的实例属性,它遮蔽了Managed类中同名的描述符属性。
④
Managed.non_over描述符仍然存在,并通过类捕获此访问。
⑤
如果删除non_over实例属性…
⑥
…然后读取obj.non_over会触发类中描述符的__get__方法,但请注意第二个参数是受控实例。
在之前的示例中,我们看到了对实例属性进行多次赋值,属性名与描述符相同,并根据描述符中是否存在__set__方法而产生不同的结果。
类中属性的设置不能由附加到同一类的描述符控制。特别是,这意味着描述符属性本身可以被赋值给类,就像下一节所解释的那样。
在类中覆盖描述符
无论描述符是覆盖还是非覆盖的,都可以通过对类的赋值来覆盖。这是一种猴子补丁技术,但在示例 23-12 中,描述符被整数替换,这将有效地破坏任何依赖描述符进行正确操作的类。
示例 23-12. 任何描述符都可以在类本身上被覆盖
>>> obj = Managed() # ①
>>> Managed.over = 1 # ②
>>> Managed.over_no_get = 2
>>> Managed.non_over = 3
>>> obj.over, obj.over_no_get, obj.non_over # ③
(1, 2, 3)
①
创建一个新实例以供后续测试。
②
覆盖类中的描述符属性。
③
描述符真的消失了。
示例 23-12 揭示了关于读取和写入属性的另一个不对称性:尽管可以通过附加到受控类的__get__的描述符来控制类属性的读取,但是通过附加到同一类的__set__的描述符无法处理类属性的写入。
提示
为了控制类中属性的设置,您必须将描述符附加到类的类中,换句话说,元类。默认情况下,用户定义类的元类是type,您无法向type添加属性。但是在第二十四章中,我们将创建自己的元类。
现在让我们专注于描述符在 Python 中如何用于实现方法。
方法是描述符
当在实例上调用时,类中的函数会变成绑定方法,因为所有用户定义的函数都有一个__get__方法,因此当附加到类时,它们作为描述符运行。示例 23-13 演示了从示例 23-8 中引入的Managed类中读取spam方法。
示例 23-13. 方法是一个非覆盖描述符
>>> obj = Managed()
>>> obj.spam # ①
<bound method Managed.spam of <descriptorkinds.Managed object at 0x74c80c>>
>>> Managed.spam # ②
<function Managed.spam at 0x734734>
>>> obj.spam = 7 # ③
>>> obj.spam
7
①
从obj.spam读取会得到一个绑定的方法对象。
②
但是从Managed.spam读取会得到一个函数。
③
给obj.spam赋值会隐藏类属性,使得obj实例无法从spam方法中访问。
函数不实现__set__,因为它们是非覆盖描述符,正如示例 23-13 的最后一行所示。
从示例 23-13 中另一个关键点是obj.spam和Managed.spam检索到不同的对象。与描述符一样,当通过受控类进行访问时,函数的__get__返回对自身的引用。但是当访问通过实例进行时,函数的__get__返回一个绑定的方法对象:一个可调用对象,包装函数并将受控实例(例如obj)绑定到函数的第一个参数(即self),就像functools.partial函数所做的那样(如“使用 functools.partial 冻结参数”中所示)。要更深入地了解这种机制,请查看示例 23-14。
示例 23-14. method_is_descriptor.py:一个从UserString派生的Text类
import collectionsclass Text(collections.UserString):def __repr__(self):return 'Text({!r})'.format(self.data)def reverse(self):return self[::-1]
现在让我们来研究Text.reverse方法。参见示例 23-15。
示例 23-15. 使用方法进行实验
>>> word = Text('forward')>>> word # ①Text('forward')>>> word.reverse() # ②Text('drawrof')>>> Text.reverse(Text('backward')) # ③Text('drawkcab')>>> type(Text.reverse), type(word.reverse) # ④(<class 'function'>, <class 'method'>)>>> list(map(Text.reverse, ['repaid', (10, 20, 30), Text('stressed')])) # ⑤['diaper', (30, 20, 10), Text('desserts')]>>> Text.reverse.__get__(word) # ⑥<bound method Text.reverse of Text('forward')>>>> Text.reverse.__get__(None, Text) # ⑦<function Text.reverse at 0x101244e18>>>> word.reverse # ⑧<bound method Text.reverse of Text('forward')>>>> word.reverse.__self__ # ⑨Text('forward')>>> word.reverse.__func__ is Text.reverse # ⑩True
①
Text实例的repr看起来像一个Text构造函数调用,可以创建一个相同的实例。
②
reverse方法返回拼写颠倒的文本。
③
在类上调用的方法作为一个函数。
④
注意不同类型:一个function和一个method。
⑤
Text.reverse作为一个函数运行,甚至可以处理不是Text实例的对象。
⑥
任何函数都是非覆盖描述符。使用实例调用其__get__将检索绑定到该实例的方法。
⑦
使用None作为instance参数调用函数的__get__将检索函数本身。
⑧
表达式word.reverse实际上调用了Text.reverse.__get__(word),返回绑定方法。
⑨
绑定方法对象有一个__self__属性,保存着调用该方法的实例的引用。
⑩
绑定方法的__func__属性是指向所管理类中原始函数的引用。
绑定方法对象还有一个__call__方法,用于处理实际的调用。这个方法调用__func__中引用的原始函数,将方法的__self__属性作为第一个参数传递。这就是传统self参数的隐式绑定方式的工作原理。
将函数转换为绑定方法的方式是描述符在语言中作为基础设施使用的一个典型例子。
在深入了解描述符和方法的工作原理之后,让我们来看看关于它们使用的一些建议。
描述符使用提示
以下列表解决了刚才描述的描述符特性的一些实际后果:
使用property保持简单
内置的property创建覆盖描述符,实现__set__和__get__,即使你没有定义一个 setter 方法。⁷ 属性的默认__set__会引发AttributeError: can't set attribute,因此属性是创建只读属性的最简单方式,避免了下面描述的问题。
只读描述符需要__set__
如果你使用描述符类来实现一个只读属性,你必须记得编写__get__和__set__,否则在实例上设置一个同名属性将会遮蔽描述符。只读属性的__set__方法应该只是引发AttributeError并附带适当的消息。⁸
验证描述符只能与__set__一起使用
在仅用于验证的描述符中,__set__方法应该检查其接收到的value参数,如果有效,直接在实例的__dict__中使用描述符实例名称作为键设置它。这样,从实例中读取具有相同名称的属性将尽可能快,因为它不需要__get__。查看示例 23-3 的代码。
使用__get__可以高效地进行缓存
如果只编写 __get__ 方法,则具有非覆盖描述符。 这些对于进行一些昂贵的计算然后通过在实例上设置同名属性来缓存结果很有用。⁹ 同名实例属性将遮蔽描述符,因此对该属性的后续访问将直接从实例 __dict__ 中获取,而不再触发描述符 __get__。 @functools.cached_property 装饰器实际上生成一个非覆盖描述符。
非特殊方法可以被实例属性遮蔽
因为函数和方法只实现 __get__,它们是非覆盖描述符。 诸如 my_obj.the_method = 7 这样的简单赋值意味着通过该实例进一步访问 the_method 将检索数字 7 —— 而不会影响类或其他实例。 但是,这个问题不会干扰特殊方法。 解释器只在类本身中查找特殊方法,换句话说,repr(x) 被执行为 x.__class__.__repr__(x),因此在 x 中定义的 __repr__ 属性对 repr(x) 没有影响。 出于同样的原因,实例中存在名为 __getattr__ 的属性不会颠覆通常的属性访问算法。
实例中非特殊方法如此容易被覆盖可能听起来脆弱且容易出错,但在我个人超过 20 年的 Python 编码中从未受到过这方面的影响。 另一方面,如果您正在进行大量的动态属性创建,其中属性名称来自您无法控制的数据(就像我们在本章的前面部分所做的那样),那么您应该意识到这一点,并可能实现一些过滤或转义动态属性名称以保持理智。
注意
FrozenJSON 类在 示例 22-5 中受到实例属性遮蔽方法的保护,因为它的唯一方法是特殊方法和 build 类方法。 只要始终通过类访问类方法,类方法就是安全的,就像我在 示例 22-5 中使用 FrozenJSON.build 一样——后来在 示例 22-6 中被 __new__ 取代。 “计算属性” 中介绍的 Record 和 Event 类也是安全的:它们只实现特殊方法、静态方法和属性。 属性是覆盖描述符,因此不会被实例属性遮蔽。
结束本章时,我们将介绍两个我们在属性中看到但在描述符的上下文中尚未解决的功能:文档和处理尝试删除托管属性。
描述符文档字符串和覆盖删除
描述符类的文档字符串用于记录托管类中每个描述符的实例。 图 23-4 显示了带有示例 23-6 和 23-7 中的 Quantity 和 NonBlank 描述符的 LineItem 类的帮助显示。
这有点令人不满意。 对于 LineItem,例如,添加 weight 必须是千克的信息会很好。 这对于属性来说是微不足道的,因为每个属性处理一个特定的托管属性。 但是使用描述符,Quantity 描述符类用于 weight 和 price。¹⁰
我们讨论了与属性一起讨论的第二个细节,但尚未使用描述符处理尝试删除托管属性的尝试。这可以通过在描述符类中实现__delete__方法来完成,而不是通常的__get__和/或__set__。我故意省略了对__delete__的覆盖,因为我认为实际使用是罕见的。如果您需要此功能,请参阅“实现描述符”部分的Python 数据模型文档。编写一个带有__delete__的愚蠢描述符类留给悠闲的读者作为练习。
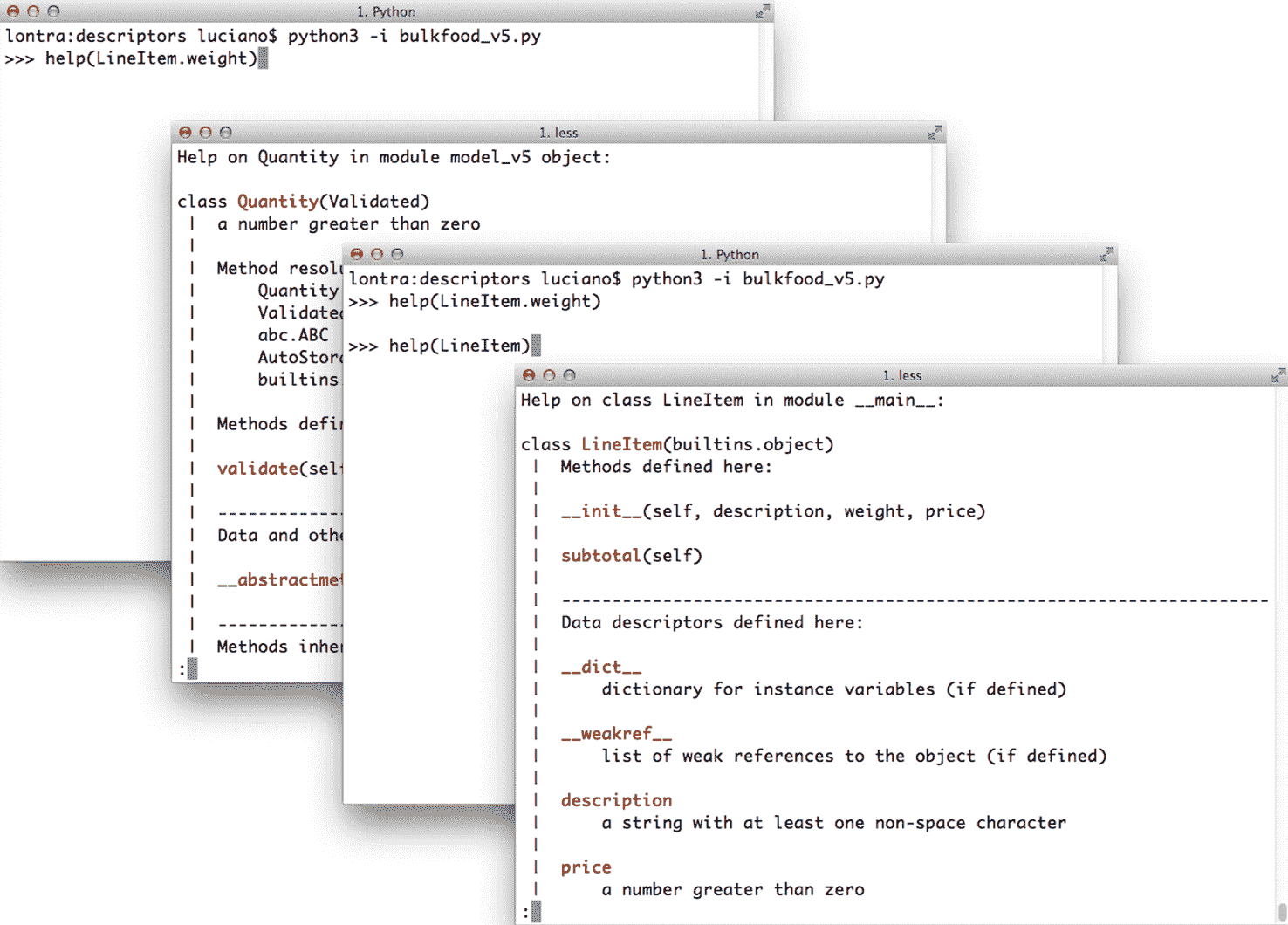
图 23-4。在发出命令help(LineItem.weight)和help(LineItem)时 Python 控制台的屏幕截图。
章节总结
本章的第一个示例是从第二十二章的LineItem示例中延续的。在示例 23-2 中,我们用描述符替换了属性。我们看到描述符是一个提供实例的类,这些实例被部署为托管类中的属性。讨论这种机制需要特殊术语,引入了诸如托管实例和存储属性之类的术语。
在“LineItem Take #4: Automatic Naming of Storage Attributes”中,我们取消了要求使用显式storage_name声明Quantity描述符的要求,这是多余且容易出错的。解决方案是在Quantity中实现__set_name__特殊方法,将托管属性的名称保存为self.storage_name。
“LineItem Take #5: A New Descriptor Type”展示了如何对抽象描述符类进行子类化,以在构建具有一些共同功能的专门描述符时共享代码。
然后,我们研究了提供或省略__set__方法的描述符的不同行为,区分了重写和非重写描述符,即数据和非数据描述符。通过详细测试,我们揭示了描述符何时控制何时被遮蔽、绕过或覆盖。
随后,我们研究了一类特定的非重写描述符:方法。控制台实验揭示了当通过实例访问时,附加到类的函数如何通过利用描述符协议成为方法。
结束本章,“描述符使用技巧”提供了实用技巧,而“描述符文档字符串和重写删除”则简要介绍了如何记录描述符。
注意
正如在“本章新内容”中所指出的,本章中的几个示例由于描述符协议中 Python 3.6 中添加的__set_name__特殊方法而变得简单得多。这就是语言的进化!
进一步阅读
除了对“数据模型”章节的必要参考外,Raymond Hettinger 的“描述符指南”是一个宝贵的资源——它是官方 Python 文档中HowTo 系列的一部分。
与 Python 对象模型主题一样,Martelli、Ravenscroft 和 Holden 的Python in a Nutshell,第 3 版(O’Reilly)是权威且客观的。Martelli 还有一个名为“Python 的对象模型”的演示,深入介绍了属性和描述符(请参阅幻灯片和视频)。
警告
请注意,在 2016 年采用 PEP 487 之前编写或记录的描述符覆盖内容可能在今天显得过于复杂,因为在 Python 3.6 之前的版本中不支持__set_name__。
对于更多实际示例,《Python Cookbook》,第 3 版,作者 David Beazley 和 Brian K. Jones(O’Reilly)有许多示例说明描述符,其中我想强调“6.12. 读取嵌套和可变大小的二进制结构”,“8.10. 使用惰性计算属性”,“8.13. 实现数据模型或类型系统”和“9.9. 定义装饰器作为类”。最后一种方法解决了函数装饰器、描述符和方法交互的深层问题,解释了如果将函数装饰器实现为具有__call__的类,还需要实现__get__以便与装饰方法和函数一起使用。
PEP 487—更简单的类创建自定义引入了__set_name__特殊方法,并包括一个验证描述符的示例。
¹ Raymond Hettinger,《描述符指南》(https://fpy.li/descrhow)。
² 在 UML 类图中,类和实例被绘制为矩形。虽然在类图中有视觉差异,但实例很少在类图中显示,因此开发人员可能不会将其识别为实例。
³ 白松露每磅成本数千美元。不允许以 0.01 美元出售松露留给有企图的读者作为练习。我知道一个人实际上因为在线商店的错误(这次不是Amazon.com)而以 18 美元购买了一本价值 1800 美元的统计百科全书。
⁴ 更准确地说,__set_name__是由type.__new__调用的——表示类的对象的构造函数。内置的type实际上是一个元类,用户定义类的默认类。这一点一开始很难理解,但请放心:第二十四章专门讨论了类的动态配置,包括元类的概念。
⁵ Gamma 等人,《设计模式:可复用面向对象软件的元素》,第 326 页。
⁶ Alex Martelli 的“Python 设计模式”演讲第 50 页幻灯片(https://fpy.li/23-1)。强烈推荐。
⁷ property装饰器还提供了一个__delete__方法,即使您没有定义删除方法。
⁸ Python 在这类消息中并不一致。尝试更改complex数的c.real属性会得到AttributeError: readonly attribute,但尝试更改complex的方法c.conjugate会得到AttributeError: 'complex' object attribute 'conjugate' is read-only。甚至“read-only”的拼写也不同。
⁹ 但是,请记住,在__init__方法运行后创建实例属性会破坏关键共享内存优化,正如从“dict 工作原理的实际后果”中讨论的那样。
¹⁰ 自定义每个描述符实例的帮助文本实际上是非常困难的。一种解决方案需要为每个描述符实例动态构建一个包装类。






![[数据集][目标检测]焊接件表面缺陷检测数据集VOC+YOLO格式2292张10类别](https://img-blog.csdnimg.cn/direct/784231002051407cabd33a05f6c8ed38.jpeg)