接着这一篇博客做进一步说明:
机器学习 - 选择模型
为了解决测试和预测之间的差距,可以通过更新 internal parameters, the weights set randomly use nn.Parameter() and bias set randomly use torch.randn().
Much of the time you won’t know what the ideal parameters are for a model.
Instead, it is much more fun to write code to see if the model can try and figure them out itself. That is a loss function as well as and optimizer.
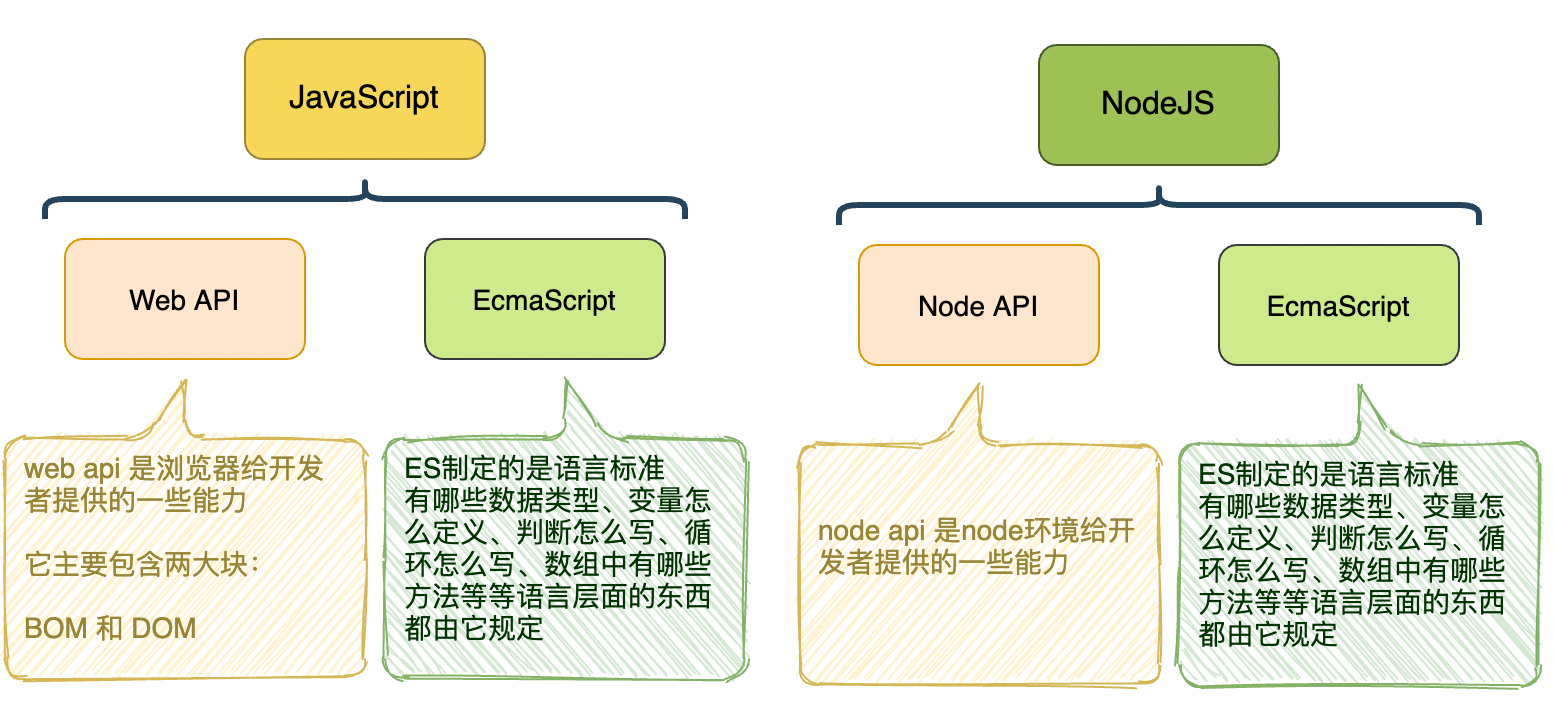
| Function | What does it do? | Where does it live in PyTorch? | Common values |
|---|---|---|---|
| Loss function | Measures how wrong your models predictions (e.g. y_preds) are compared to the truth labels (e.g. y_test). Lower the better.差距越小越好 | PyTorch has plenty of built-in loss functions in torch.nn | Mean absolute error (MAE) for regression problems (torch.nn.L1Loss()). Binary cross entropy for binary classification problems (torch.nn.BCELoss()) |
| Optimizer | Tells your model how to update its internal parameters to best lower the loss. | You can find various optimization function implementations in torch.optim | Stochastic gradient descent (torch.optim.SGD()). Adam.optimizer (torch.optim.Adam()) |
介绍 MAE: Mean absolute error 也称为平均绝对误差,是一种用于衡量预测值与真实值之间差异的损失函数。MAE计算的是预测值与真实值之间的绝对差值的平均值,即平均误差的绝对值。在 PyTorch 中可以使用 torch.nn.L1Loss 来计算MAE.
介绍Stochastic gradient descent:
这是一种常用的优化算法,用于训练神经网络模型。它是梯度下降算法的变种,在每次更新参数时都使用随机样本的梯度估计来更新参数。SGD的基本思想是通过最小化损失函数来调整模型参数,使得模型的预测结果与真实标签尽可能接近。在每次迭代中,SGD随机选择一小批样本 (mini-batch) 来计算损失函数关于参数的梯度,并使用该梯度来更新参数。由于每次更新只使用了一部分样本,因此SGD通常具有更快的收敛速度和更低的计算成本。在 PyTorch 中,可以使用 torch.optim.SGD(params, lr) 来实现,其中
paramsis the target model parameters you’d like to optimize (e.g. theweightsandbiasvalues we randomly set before).lris the learning rate you’d like the optimizer to update the parameters at, higher means the optimizer will try larger updates (these can sometimes be too large and the optimizer will fail to work), lower means the optimizer will try smaller updates (these can sometimes be too small and the optimizer will take too long to find the ideal values). Common starting values for the learning rate are0.01,0.001,0.0001.
介绍 Adam 优化器:
Adam优化器是一种常用的优化算法,它结合了动量法和自适应学习率调整的特性,能够高效地优化神经网络模型的参数。Adam优化器的基本思想是在梯度下降的基础上引入了动量项和自适应学习率调整项。动量项可以帮助优化器在更新参数时保持方向性,从而加速收敛;而自适应学习率调整项可以根据参数的历史梯度来调整学习率,从而在不同参数上使用不同的学习率,使得参数更新更加稳健。
介绍学习率:
学习率是在训练神经网络时控制参数更新步长的一个超参数。它决定了每次参数更新时,参数沿着梯度方向更新的程度。学习率越大,参数更新的步长越大;学习率越小,参数更新的步长越小。选择合适的学习率通常是训练神经网络时需要调节的一个重要超参数。如果学习率过大,可能导致参数更新过大,导致模型不稳定甚至发散;如果学习率过小,可能导致模型收敛速度过慢,训练时间变长。
代码如下:
import torch# Create the loss function
loss_fn = nn.L1Loss() # MAE loss is same as L1Loss# Create the optimizer
optimizer = torch.optim.SGD(params = model_0.parameters(),lr = 0.01)现在创造一个optimization loop
The training loop involves the model going through the training data and learning the relationships between the features and labels.
The testing loop involves going through the testing data and evaluating how good the patterns are that the model learned on the training data (the model never sees the testing data during training).
Each of these is called a “loop” because we want our model to look (loop through) at each sample in each dataset. 所以,得用 for 循环来实现。
PyTorch training loop
| Number | Step name | What does it do? | Code example |
|---|---|---|---|
| 1 | Forward pass | The model goes through all of the training data once, performing its forward() function calculations. | model(x_train) |
| 2 | Calculate the loss | The model’s outputs (predictions) are compared to the ground truth and evaluated to see how wrong they are. | loss = loss_fn(y_pred, y_train) |
| 3 | Zero gradients | The optimizers gradients are set to zero (they are accumulated by default) so they can be recalculated for the specific training step. | optimizer.zero_grad() |
| 4 | Perform backpropagation on the loss | Computes the gradient of the loss with respect for every model parameter to be updated (each parameter with requires_grad=True). This is known as backpropagation, hence “backwards”. | loss.backward() |
| 5 | Update the optimizer (gradient descent) | Update the parameters with requires_grad=True with respect to the loss gradients in order to improve them. | optimizer.step() |
PyTorch testing loop
As for the testing loop (evaluating the model), the typical steps include:
| Number | Step name | What does it do? | Code example |
|---|---|---|---|
| 1 | Forward pass | The model goes through all of the training data once, performing its forward() function calculations. | model(x_test) |
| 2 | Calculate the loss | The model’s outputs (predictions) are compared to the ground truth and evaluated to see how wrong they are. | loss = loss_fn(y_pred, y_test) |
| 3 | Calculate evaluation metrics (optional) | Alongside the loss value you may want to calculate other evaluation metrics such as accuracy on the test set. | Custom functions |
下面是代码实现
# Create the loss function
# 那你。L1Loss() 是用于计算平均绝对误差 (MAE) 的损失函数。
loss_fn = nn.L1Loss() # MAE loss is same as L1Loss# Create the optimizer
# torch.optim.SGD() 是用于创建随机梯度下降优化器的函数。
# parameters() 返回一个包含了模型中所有需要进行梯度更新的参数的迭代器
optimizer = torch.optim.SGD(params = model_0.parameters(),lr = 0.01)# Set the number of epochs (how many times the model will pass over the training data)
epochs = 200# Create empty loss lists to track values
train_loss_values = []
test_loss_values = []
epoch_count = []for epoch in range(epochs):### Training # Put model in training mode (this is the default state of a model)# train() 函数通常用于将模型设置为训练模式model_0.train()# 1. Forward pass on train data using the forward() method insidey_pred = model_0(X_train)# 2. Calculate the loss (how different are our models predictions to the ground truth)loss = loss_fn(y_pred, y_train)# 3. Zero grad of the optimizeroptimizer.zero_grad() # 4. Loss backwardsloss.backward()# 5. Progress the optimizer# step() 用于执行一步参数更新操作。optimizer.step() ### Testing# Put the model in evaluation modemodel_0.eval() with torch.inference_mode():# 1. Forward pass on test data test_pred = model_0(X_test)# 2. Calculate loss on test data test_loss = loss_fn(test_pred, y_test.type(torch.float)) # predictions come in torch.float datatype, so comparisons need to be done with tensors of the same type # Print out if epoch % 10 == 0:epoch_count.append(epoch)# detach() 方法用于将这个张量从计算图中分离出来,目的是为了避免在将张量转换为numpy数组时保留计算图的依赖关系,减少内存占用并加速代码的执行train_loss_values.append(loss.detach().numpy())test_loss_values.append(test_loss.detach().numpy())print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss}")plt.plot(epoch_count, train_loss_values, label="Train loss")
plt.plot(epoch_count, test_loss_values, label="Test loss")
plt.title("Training and test loss curves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend()print("The model learned the following values for weights and bias: ")
print(model_0.state_dict())
print("\nAnd the original values for weights and bias are: ")
print(f"weights: {weight}, bias: {bias}")# 结果如下:
Epoch: 0 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 10 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 20 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 30 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 40 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 50 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 60 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 70 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 80 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 90 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 100 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 110 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 120 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 130 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 140 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 150 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 160 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 170 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 180 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
Epoch: 190 | MAE Train Loss: 0.008932482451200485 | MAE Test Loss: 0.005023092031478882
The model learned the following values for weights and bias:
OrderedDict([('weights', tensor([0.6990])), ('bias', tensor([0.3093]))])And the original values for weights and bias are:
weights: 0.7, bias: 0.3Loss is the measure of how wrong your model is. Loss 的值越低,效果越好。

都看到这了,点个赞支持下呗~