| java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 |
|---|
目前校招的面试,经常会遇到各种各样的有关字符串处理的算法。掌握正则表达式可以秒杀大部分普通方法处理起来偏难的题目。
而且正则表达式也是实际工作中使用频率非常高的工具。
记得几年前学习正则表达式,因为当时英语不好,所以是从b站视频入手学习的,今天回到b站搜了一下,发现依然是韩顺平老师讲解的比较全面。本文也是当年我学习这套视频所做的笔记(只不过当时记在了A4纸上),这么多年如果涉及使用正则表达式的场景,也是直接翻笔记就搞定了。链接如下:
| 韩顺平JAVA,正则表达式:https://www.bilibili.com/video/BV1Eq4y1E79W/ |
|---|
但是要
注意,正则表达式的效率不如直接进行字符操作。所以做题时,使用正则表达式尽量不要对同一个子串进行超过一次以上的匹配。否则反而影响效率。
如何正确使用正则表达式提升效率呢?只要是字符操作十分繁琐麻烦,而使用正则可以一步到位的情况都可以使用。例如下面Leetcode205题,我们想要跳过一些比较有规律,但是处理起来比较繁琐的字符串时,就可以使用正则表达式来处理
- 没有使用正则
- 使用了正则后
文章目录
- 一、正则底层实现概述
- 1. matcher.find()
- 2. matcher.group(0)
- 3. 分组情况下
- 二、正则表达式语法
- 1. 正则转义符
- 2. 字符匹配符
- 3. 选择匹配符
- 4. 正则限定符
- 5. 正则定位符
- 三、分组
- 1. 捕获分组
- 2. 非捕获分组
- 四、实战案例
一、正则底层实现概述
这里很重要,一定要掌握,否则大家后面学再多语法,都不知道为什么这样用。
| 拿一段简单的测试代码,来讲解两个重要的方法的底层实现。这里使用的是java语言,其它语言大同小异。 |
|---|
- 下面代码的功能是,实现从文本中提取出所有的IP地址
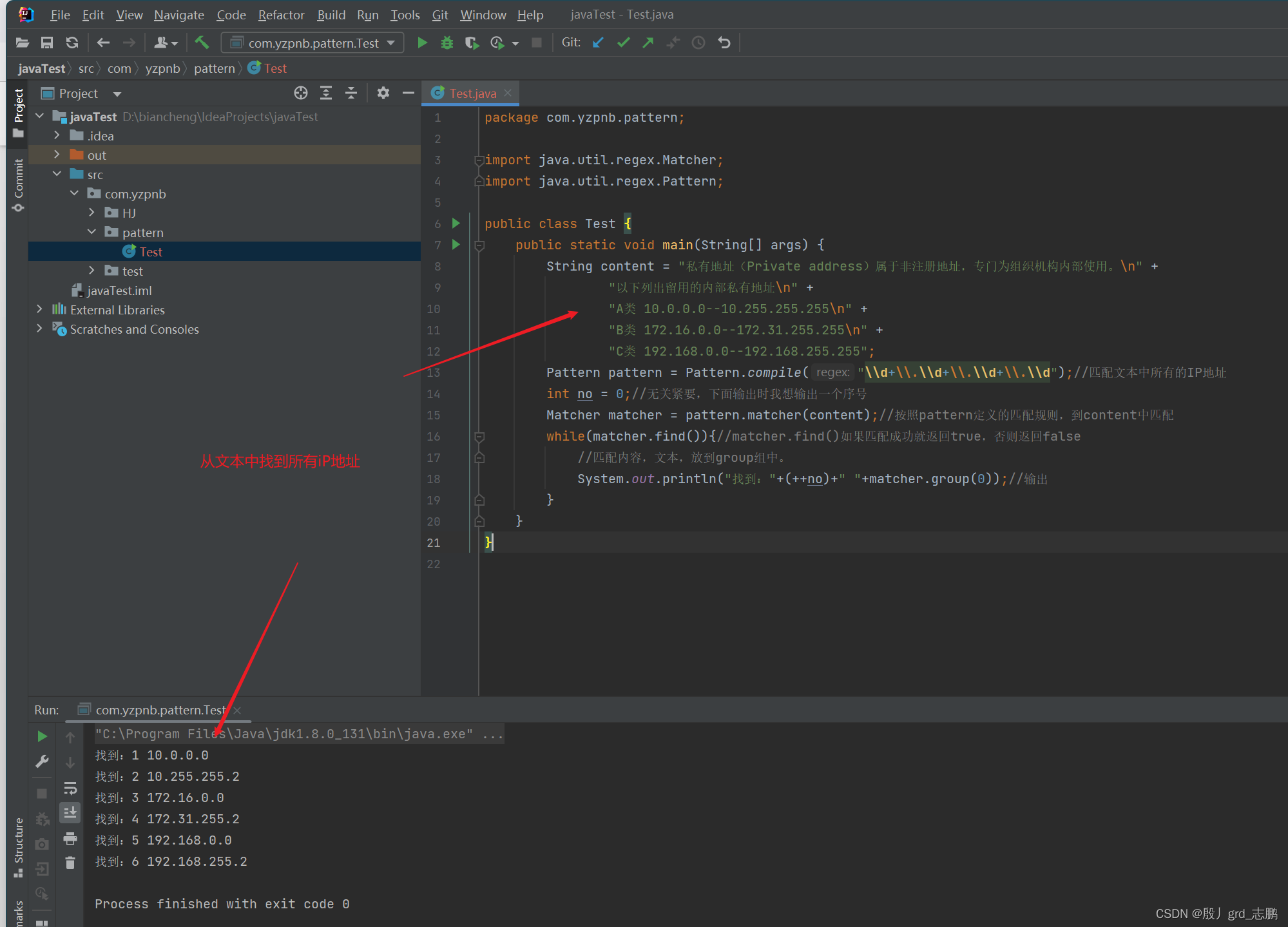
package com.yzpnb.pattern;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String content = "私有地址(Private address)属于非注册地址,专门为组织机构内部使用。\n" +"以下列出留用的内部私有地址\n" +"A类 10.0.0.0--10.255.255.255\n" +"B类 172.16.0.0--172.31.255.255\n" +"C类 192.168.0.0--192.168.255.255";Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");//匹配规则,这里实现匹配文本中所有的IP地址int no = 0;//无关紧要,下面输出时我想输出一个序号Matcher matcher = pattern.matcher(content);//按照pattern定义的匹配规则,到content中匹配while(matcher.find()){//matcher.find()如果匹配成功就返回true,否则返回false//匹配内容,文本,放到group组中。System.out.println("找到:"+(++no)+" "+matcher.group(0));//输出}}
}
1. matcher.find()
| 功能概述 |
|---|
- 根据指定规则,定位字符串中满足规则的子字符串
- 定位成功后,此方法返回true
- 同时会将子字符串的开始索引记录到matcher对象的一个,类型为int型一维数组的属性中(int[] groups)
- 假设找到的子字符串起始下标为start,结尾下标为end。那么会让groups[0] = start;groups[1] =
end+1;- end+1很重要,它可以方便我们下次匹配,减少工作量。所以只要涉及到结尾下标,几乎都保存结尾下标+1的值。比如String.substring(start,end)方法,都是包含start不包含end的区间。
| 原理解析 |
|---|
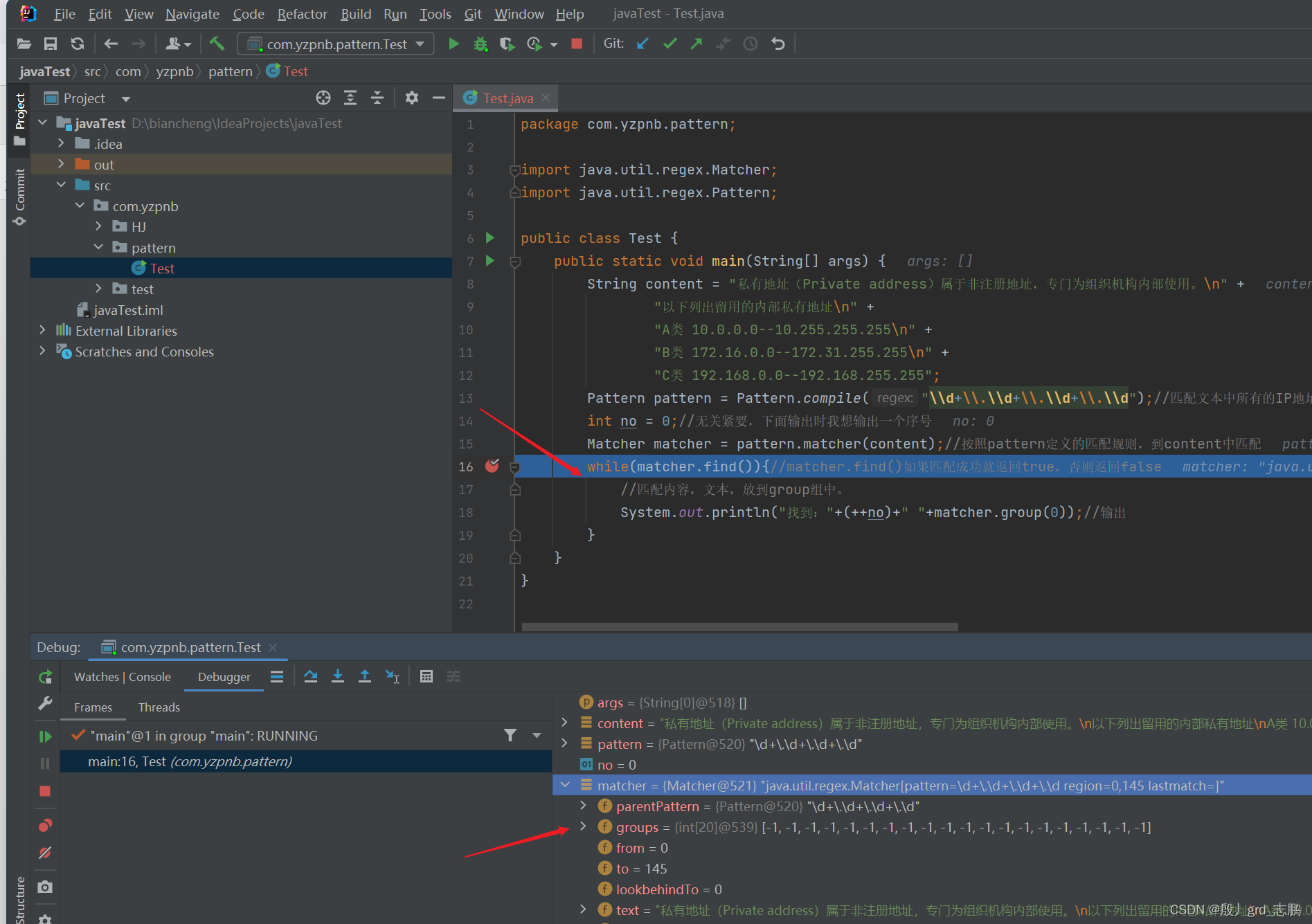
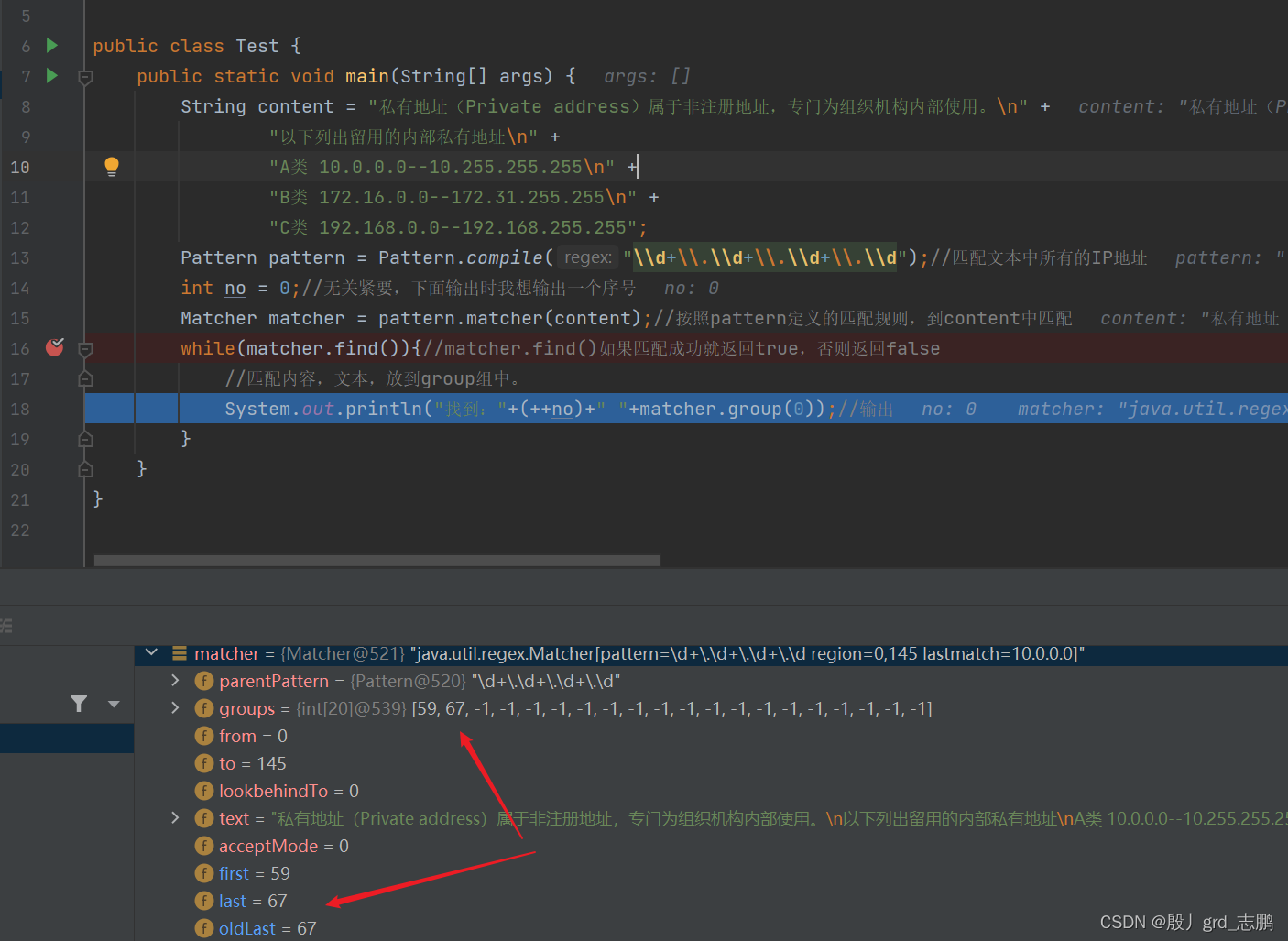
- matcher实例化后:
- 可以看到下图中,matcher对象中会有一个初始大小为20的groups数组,初始值为-1
- 同时,first变量初始值也是1,last为0,oldLast也是-1
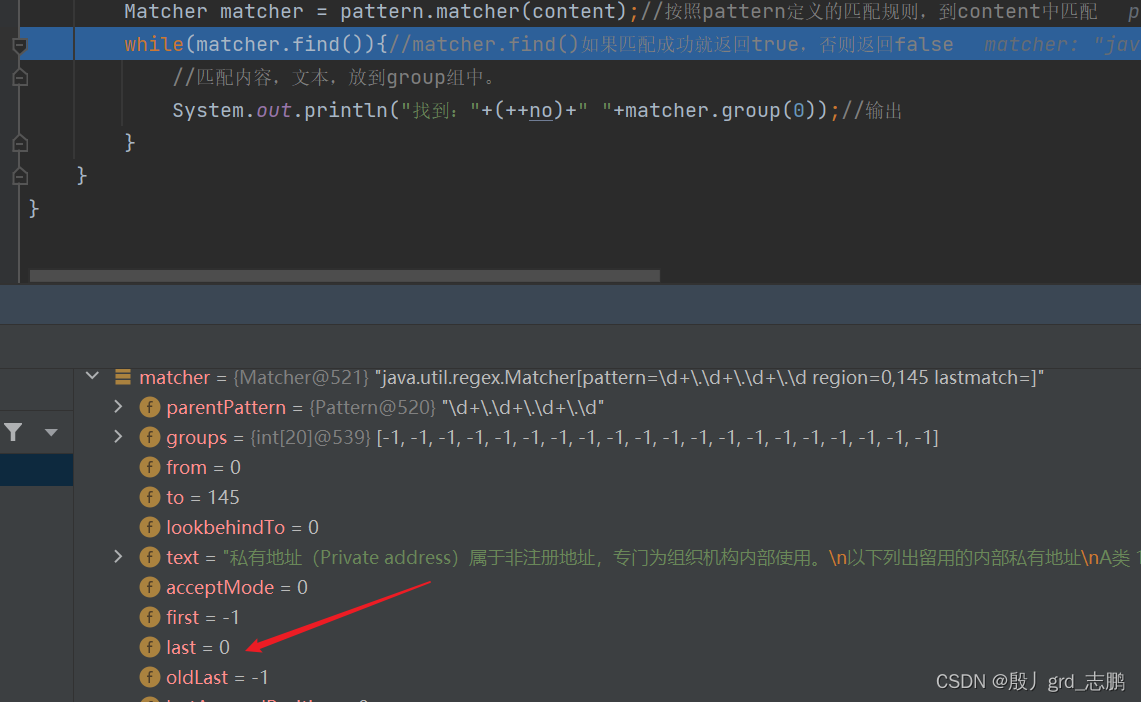
- 当执行find()方法后:
- 我们会发现,它会在groups[0]记录找到的子串的起始下标。groups[1]会记录结尾下标+1。为什么要记录结尾下标+1呢?是因为方便我们下次查找时,直接跳过已经查找过的。
- 同时,会将本次结尾下标+1这个值,作为下次查找的起始地址保存到oldLast属性中
另外first属性保存本次匹配成功的串的起始位置,last属性保存本次匹配成功的串的结束位置+1.
2. matcher.group(0)
| 功能概述 |
|---|
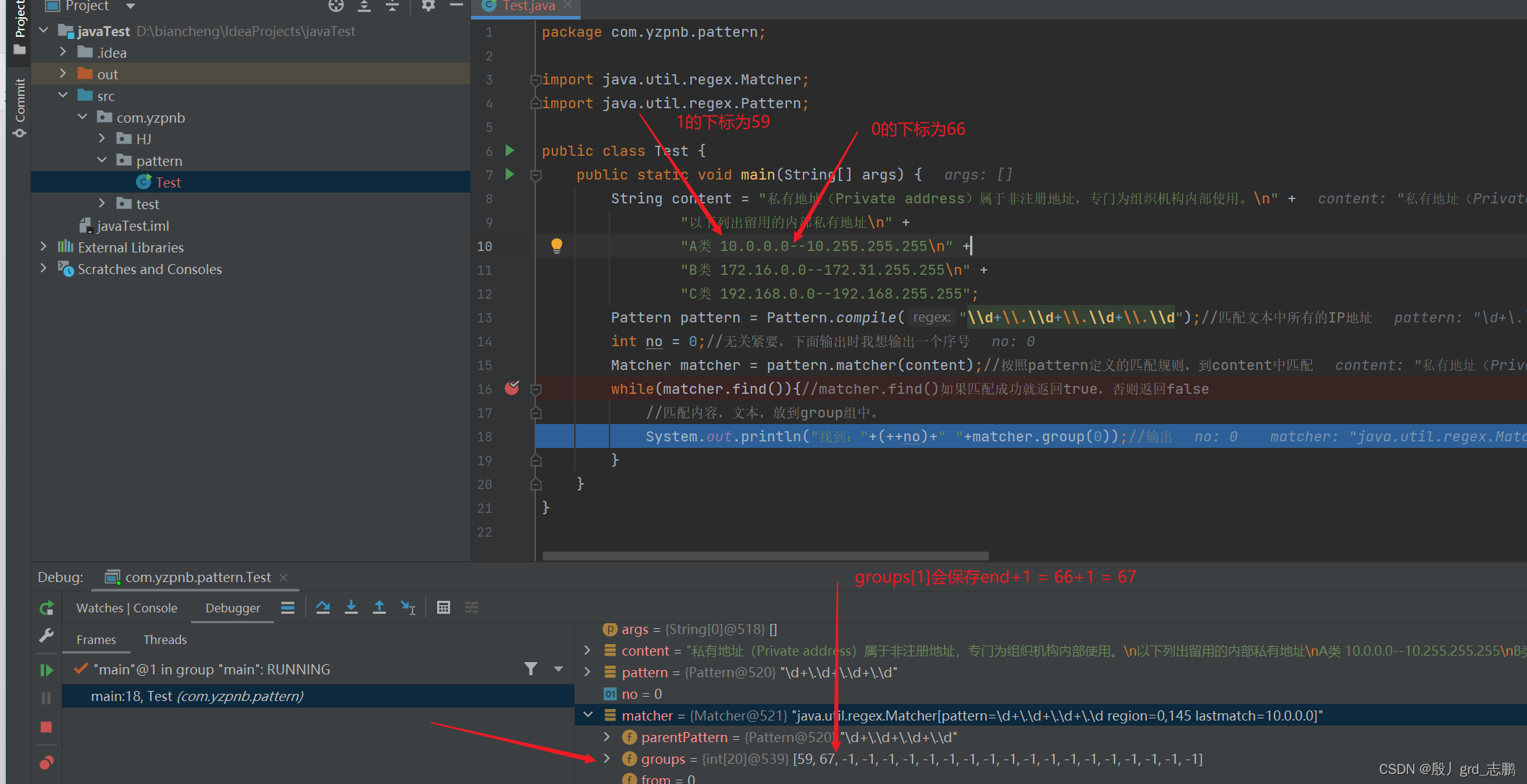
- 根据groups[0]=59和groups[1]=67记录的值,从字符串中,截取groups[0]到groups[1]之间的子字符串. 左闭右开区间:
[59 , 67)=== 闭区间:[59 , 66]
| 为什么我们例子中group()方法中传参为0呢?为什么不group(1)? |
|---|
- 下面是group方法的源码:
- 第一个if语句:如果成功使用find()方法匹配,first会>=0,否则抛出没匹配到的异常
- 第二个if语句:我们调用group()方法时,这个传参必须>=0. 并且 这个值也必须<=组的个数(groups[]数组的下标范围,不可越界)否则抛出下标越界异常
- 第三个if语句,如果获取指定groups[]数组中的值为-1,就返回null
- 最后的return,就是为什么传参需要为0
- 我们上面的例子中,我们匹配后的子串下标,保存在groups[0]和groups[1]中
- 这是因为find()这个方法是可以一次找到多个的。第0个放在groups[0]和groups[1]中。如果有第1个,就放在groups[2]和groups[3]中,依次类推。
- 现在group()方法,想要实现我们传0,获取第0个,我们传1获取第1个是如何实现的呢?
每一个都有两个下标,0 * 2 = 0 , 0 * 2+1 = 1. 这样就获取第0个子串的groups[]数组下标
同理,如果我们传参为1,就说明我们想要第1个子串。1 * 2 = 2 , 1 * 2 + 1 = 3. 这样就获取了第1个子串的groups[]数组下标了。
public String group(int group) {if (first < 0)throw new IllegalStateException("No match found");if (group < 0 || group > groupCount())throw new IndexOutOfBoundsException("No group " + group);if ((groups[group*2] == -1) || (groups[group*2+1] == -1))return null;return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
3. 分组情况下
前面的案例,是只考虑分一组的情况,只会使用到groups[0]和groups[1]两个数组元素。下面分析分多组的情况。
下面的案例中,我将ip地址10.0.0.0分组,每组保存IP地址的数字,也就是10,0,0,0去掉那些点,只保留每两个点之间的数字
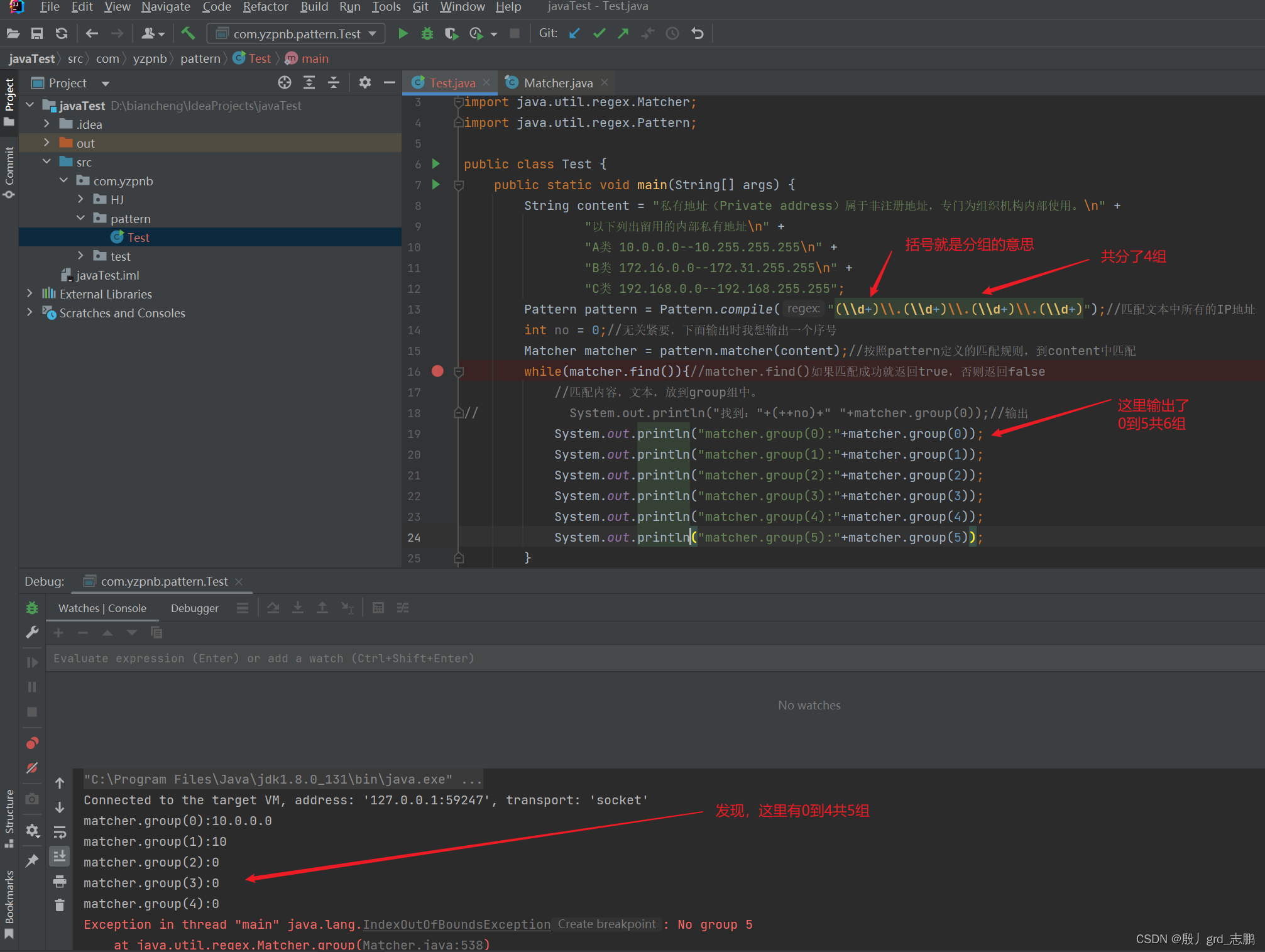
package com.yzpnb.pattern;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Test {public static void main(String[] args) {String content = "私有地址(Private address)属于非注册地址,专门为组织机构内部使用。\n" +"以下列出留用的内部私有地址\n" +"A类 10.0.0.0--10.255.255.255\n" +"B类 172.16.0.0--172.31.255.255\n" +"C类 192.168.0.0--192.168.255.255";Pattern pattern = Pattern.compile("(\\d+)\\.(\\d+)\\.(\\d+)\\.(\\d+)");//匹配文本中所有的IP地址int no = 0;//无关紧要,下面输出时我想输出一个序号Matcher matcher = pattern.matcher(content);//按照pattern定义的匹配规则,到content中匹配while(matcher.find()){//matcher.find()如果匹配成功就返回true,否则返回false//匹配内容,文本,放到group组中。
// System.out.println("找到:"+(++no)+" "+matcher.group(0));//输出System.out.println("matcher.group(0):"+matcher.group(0));System.out.println("matcher.group(1):"+matcher.group(1));System.out.println("matcher.group(2):"+matcher.group(2));System.out.println("matcher.group(3):"+matcher.group(3));System.out.println("matcher.group(4):"+matcher.group(4));System.out.println("matcher.group(5):"+matcher.group(5));}}
}
- 可以发现,上面我们分了4组,实际上保存了5组到groups[]数组中
- 其中group(0)获取到的第0组,为整个匹配规则匹配到的完整子串
- 而剩下的group(1)到group(4)为我们想要的分组,分别为4个点与点之间的数字
- 而group(5)是为大家演示,下标越界异常。没有第5组
| 第0组遵循end+1原则。而其它分组,也同样遵循end+1 |
|---|
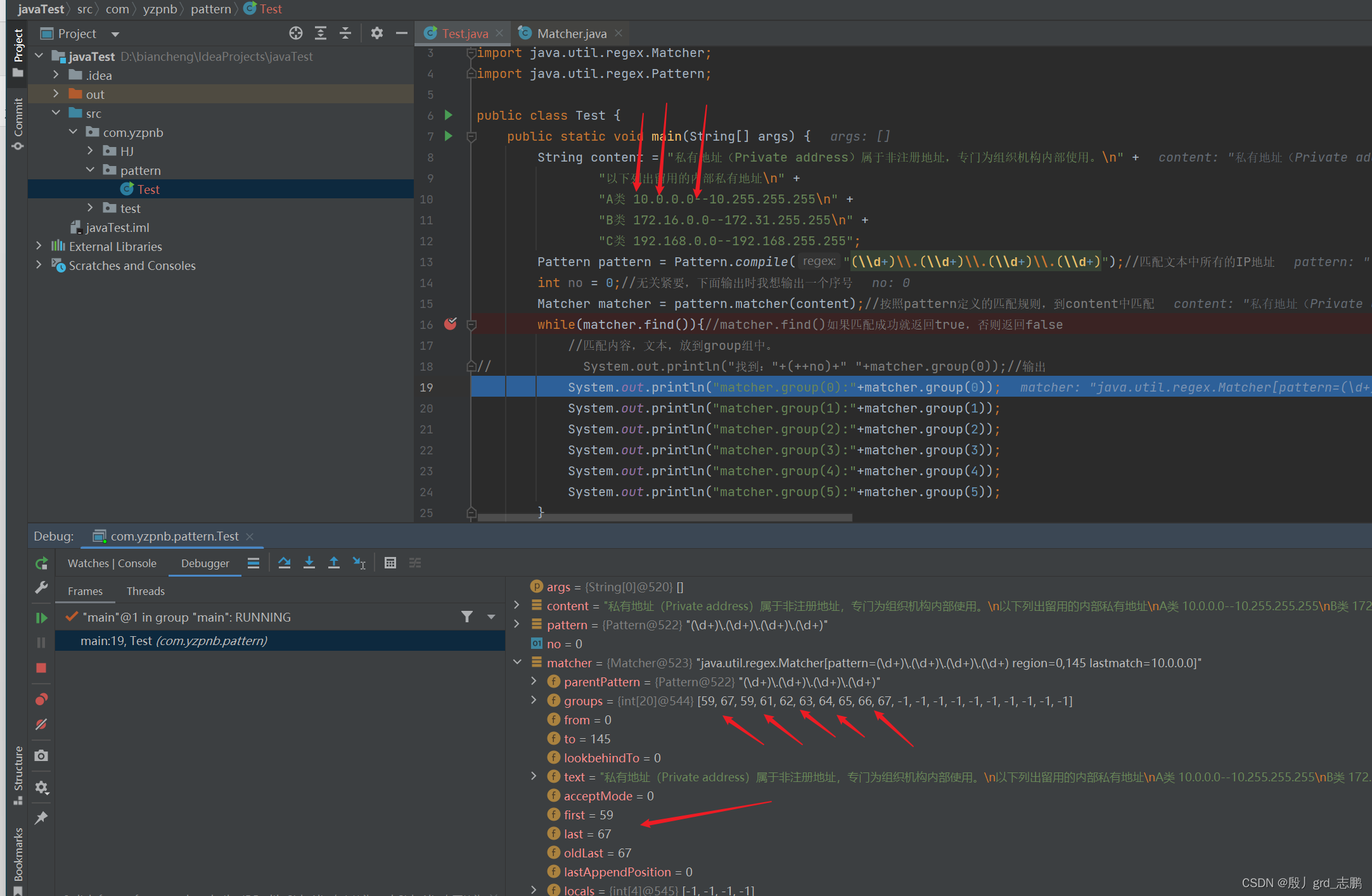
- 第0组因为是保留完整匹配成功的子串。依然会遵循前面案例分析的,groups[1]依然保存end+1的位置,方便下次匹配。
- 而其它组,它的末尾根本就不是下一次匹配应该开始的位置。
但是,完全没必要因为这个就特殊处理其它组,所以也都保存end+1的位置。
二、正则表达式语法
元字符(Metacharacter)分为:限定符、选择匹配符、分组组合和反向引用符、特殊字符、字符匹配符、定位符
1. 正则转义符
转义号:\\,用来指定后面的字符,当做字符,而不当做关键字。 |
|---|
简单来讲,我们以普通转义字符(字符串,不是正则)为例。java中字符串用两个双引号 “字符串” 来标识。那么如果字符串中,包含双引号怎么办呢?例如" 这是一个"字符串"哦! “,此时java就会报错,因为它不知道从哪开始到哪结束算作一个字符串。而需要转义” 这是一个\ "字符串\ "哦! "
- 正则表达式与普通字符串中的转义原理一样,但是普通字符串用一个反斜杠
\表示转义字符,而正则表达式用两个反斜杠\\表示转义字符


- 用正则表达式检索某些特殊字符,需要转义符号,否则会无法完成检索,甚至报错(因为这些符合直接出现在正则表达式中,富有特殊的含义。因此只是当做普通字符使用时,必须转义)
常见的需要用转移符号的字符如下:[
.,*,+,(,),$,/,\,?,[,],^,{,}]
- Java的正则表达式和其它大部分语言不同,其它语言的转义号是
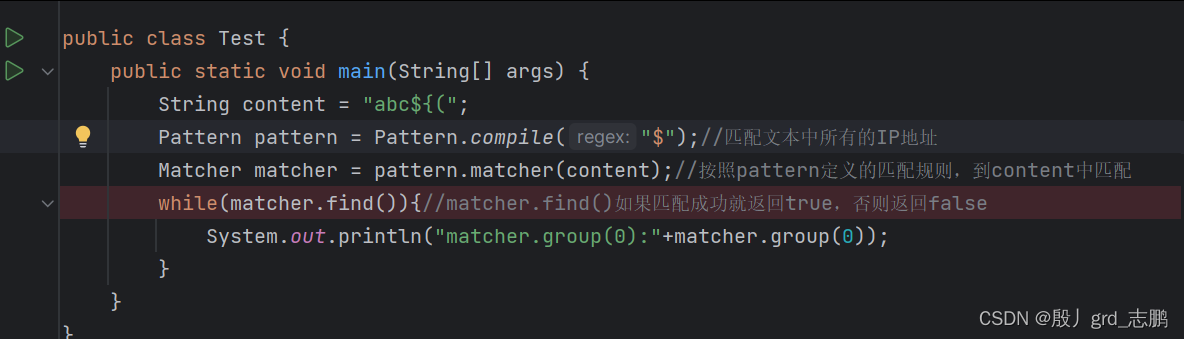
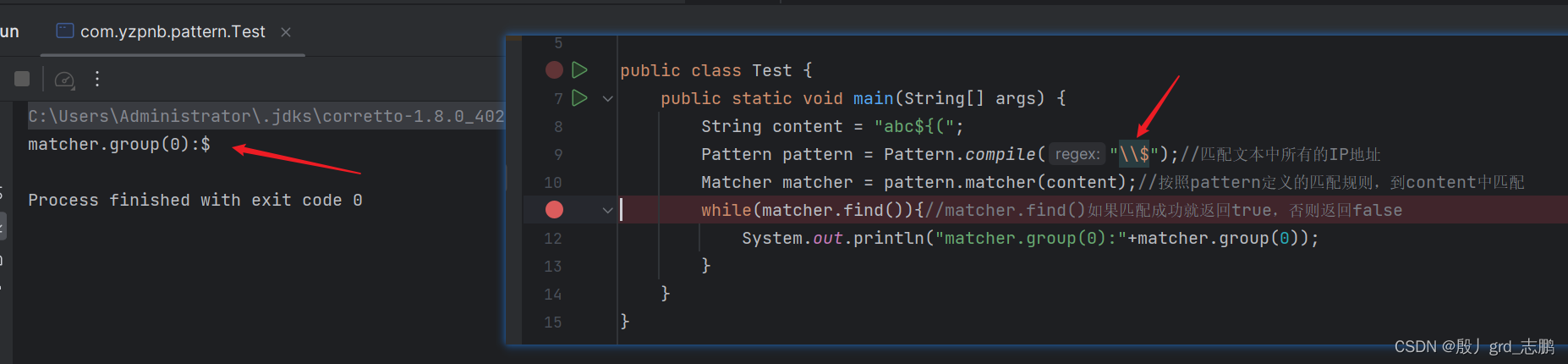
\(一个反斜杠),而Java是\\(两个反斜杠)- 下面是例子,尝试匹配$符号
- 直接用 $ 来匹配 $ 符号,可以发现结果为空
- 用 \ \ $来匹配,可以发现匹配成功
2. 字符匹配符
在正则表达式中有特殊意义的字符,这些字符往往就是前面讲的需要转义字符
\\标识,才能识别为普通字符的字符。直接使用这些字符,将富有特殊的含义。而反过来,普通的字母。例如w如果进行转义\\w,也会富有特殊的含义。这些都是设计者所规定的规则,我们使用时,记住并遵守这些约定即可。
| 符号 | 描述 | 示例(示例中有不认识的符号,可以参考正则限定符中内容) | 示例解析 |
|---|---|---|---|
[ ] | 规定当前位置匹配可选字符列表 | [abcd] | 当前位置可选a,b,c,d中任意一个字符 |
[^ ] | 规定当前位置匹配,不接收的字符列表 | [^abcd] | 当前位置可选,除了a,b,c,d之外的任意一个字符 |
- | 连字符 | A-Z | 任意从A到Z的单个大写字母 |
. | 匹配除 \n(换行符)以外的任何字符 | a..b | 以a开头,b结尾,中间两个点表示,这两个位置可以匹配任意字符长度为4的字符串(例如:aaab、a35b、a#*b…) |
\\d | 默认匹配单个数字字符,等价与[0-9],是\\d{1}的简写形式.如果后面加个{}表示匹配几个,例如\\d{3}表示匹配3个数字字符 | \\d{3}(\\d)? | 匹配3或4个数字 |
\\D | \\d的相反匹配规则。匹配单个非数字字符,等价于[^0-9],同样可以使用{} | \\D(\\d)* | 单个非数字字符开头,后接任意个数字字符(例如:a,A342) |
\\w | 匹配单个数字、大小写字母和下划线_,相当于匹配[0-9a-zA-Z] | \\d{3}\\w{4} | 以3个数字字符开头,后面4个是任意数字,大小写字母组成的,长度为7的数字字母字符串 |
\\W | \\w的相反匹配规则。匹配单个非数字、大小写字母和下划线,相当于[^0-9a-zA-Z] | \\W+\\d{2} | 以至少1个非数字字母字符开头,2个数字字符结尾的字符串 |
(?i) | 后面的匹配规则进行匹配时,不区分大小写,其中i是字母i,是单词Insensitive (adj.不敏感的;漠不关心的;)的缩写 | (?i)abc 或 a(?i)bc 或 a((?i)b)c | 1、abc都不区分大小写 2、bc不区分大小写 3、只有b不区分大小写 |
\\s | 匹配任何空白字符(空格,制表符) | a\\sb | 匹配a空格b或者a制表符b等结果 |
\\S | \\s的相反匹配规则,匹配任何非空白字符 | a\\Sb | 只要是a和b之间不是一个空白字符,就匹配 |
| 待续待续待续待续待续 | 待续待续待续待续待续 | 待续待续待续待续待续续待续待续续待续待续续待续待续续续待续待续 | 待续待续待续待续待续 |
额外的实现(?i)效果的方法(不区分大小写):其中i是字母i,是单词Insensitive (adj.不敏感的;漠不关心的;)的缩写 |
|---|
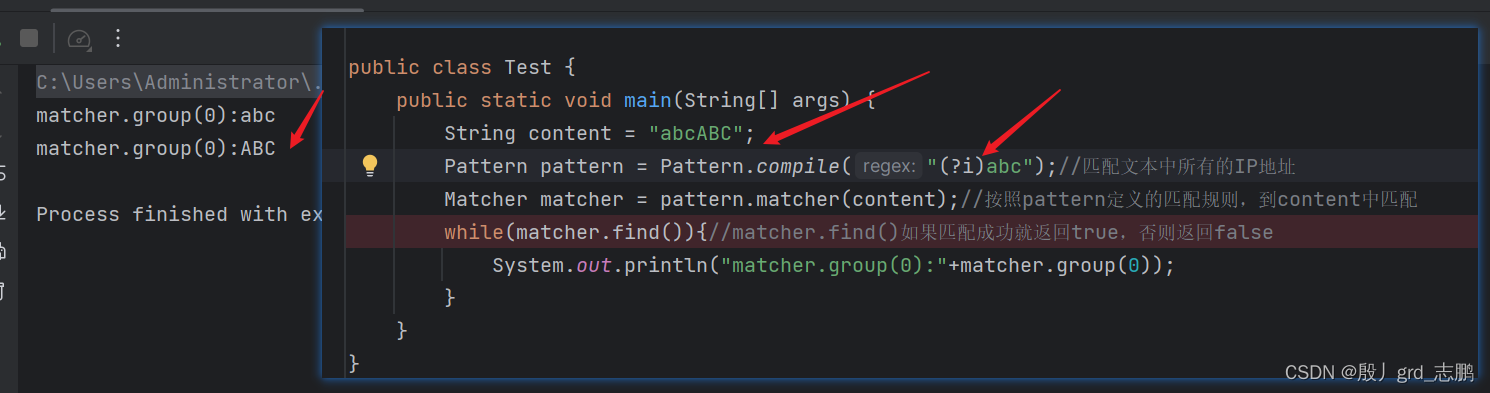
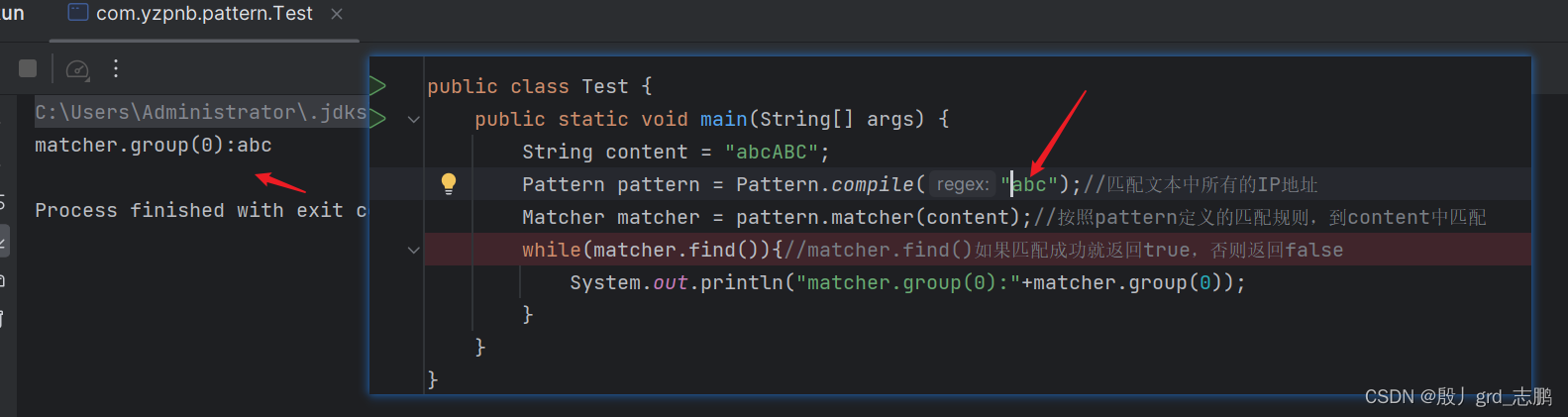
正常状况下,我们匹配abc,默认是区分大小写的,也就是无法匹配到ABC
- 第一个方法是在正则表达式中使用
(?i)
- 下图中实现通过
(?i),用abc匹配到了ABC的效果
- 而直接使用abc匹配,则无法匹配到ABC
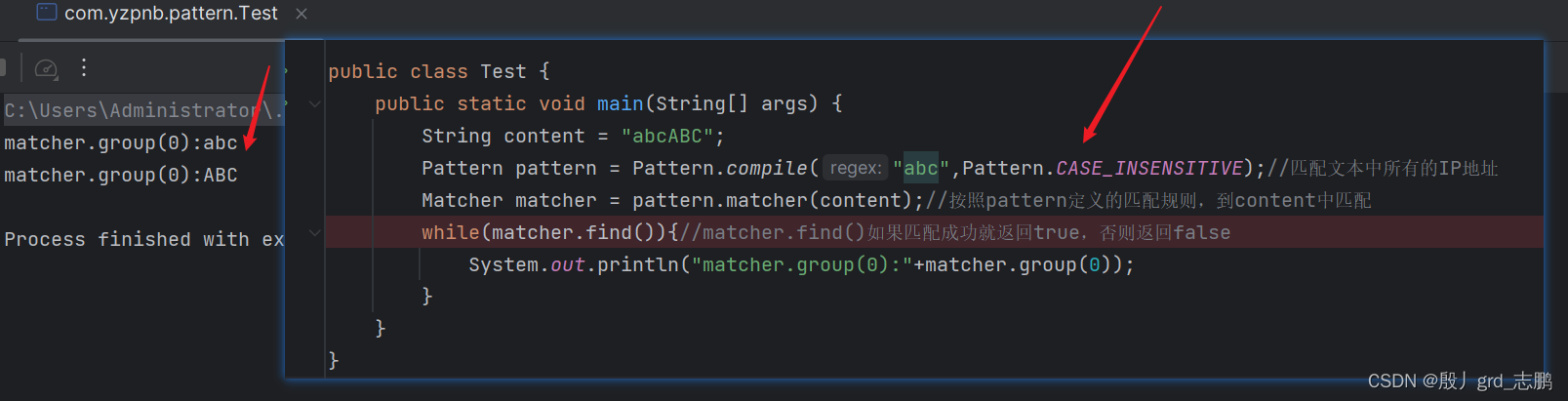
- 额外的方法是:生成Pattern对象时,指定参数Pattern.CASE_INSENSITIVE, 实现不区分大小写,但是这种方法只能实现整体不区分大小写,无法和
(?i)一样实现精细控制某一个字符不区分大小写的目的
3. 选择匹配符
一个竖杠|就是选择匹配符,和或运算符||有异曲同工之妙.表示只要满足一个条件就匹配 |
|---|
例如我们想要实现匹配Java或者抓哇。两个随便一个都行,就可以通过选择匹配符来实现。下面的例子中,想要在字符串java抓哇中,匹配出java或者抓哇。那么就可以使用正则表达式java
|抓哇
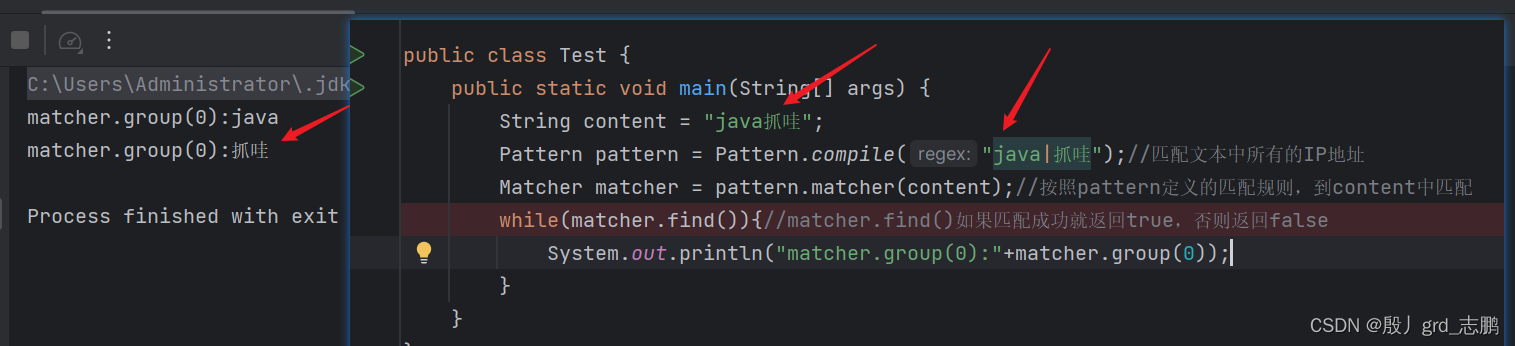
4. 正则限定符
java默认贪婪匹配,例如+代表匹配1个或多个,如果当前字符串符合条件的连续字符有多个,默认贪婪匹配多个,而不是1个1个匹配。
如何取消贪婪匹配,选择用非贪婪匹配呢?只需要限定符后面加个
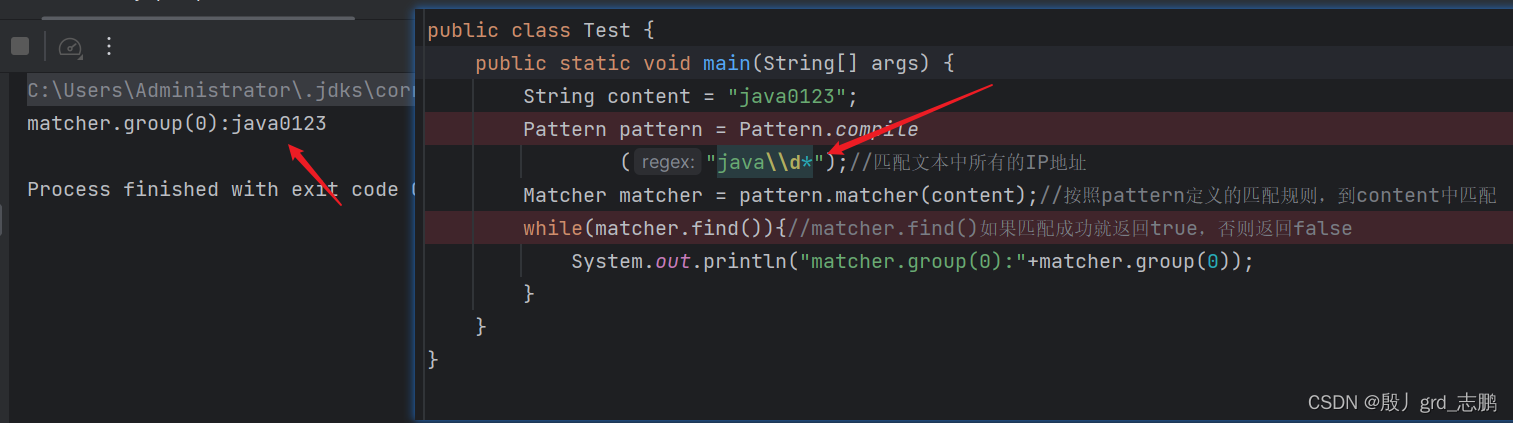
?即可。例如我们想要从java0123完成匹配
java\\d*表示java开头,后面跟随0或多个数字。会直接匹配出java0123,因为是贪心匹配,优先尽可能多的匹配
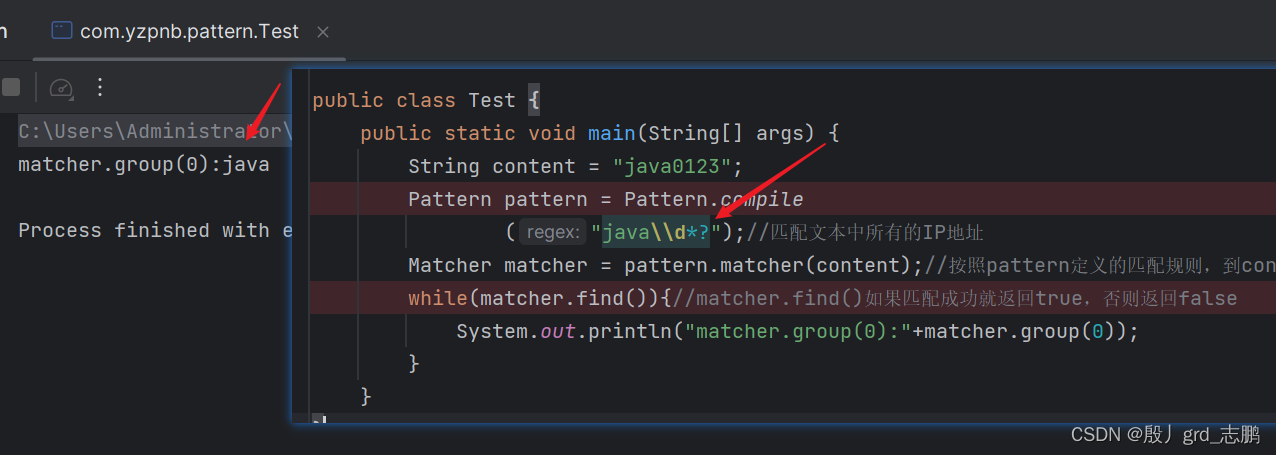
java\\d*?表示java开头,后面跟随0或多个数字,并且非贪婪匹配。则会匹配出java,因为是非贪婪匹配,优先尽可能少的匹配,而*表示匹配0或多个,最少就是0个,所以非贪婪优先最少,也就是0个
| 符号 | 描述 | 示例(示例中有不认识的符号,可以参考正则限定符中内容) | 示例解析 |
|---|---|---|---|
{num} | 按指定规则一次性匹配num个字符 | \\d{3} | 按照\\d规则,匹配连续的3个字符,这3个字符全部满足\\d规则 |
? | 按照指定规则,匹配0或1个字符 | \\d? | 按照\\d规则,匹配0或1个字符 |
* | 按照指定规则,匹配任意个字符(0个,1个或多个) | \\d* | 按照\\d规则匹配任意个 |
+ | 按照指定规则,匹配1个或多个字符 | \\W+ | 按照\\W规则,匹配非数字或字母字符,1个或多个 |
| {num}:按照指定规则,连续num个字符匹配。就是至少连续num个符合指定规则的字符才能完成匹配 |
|---|
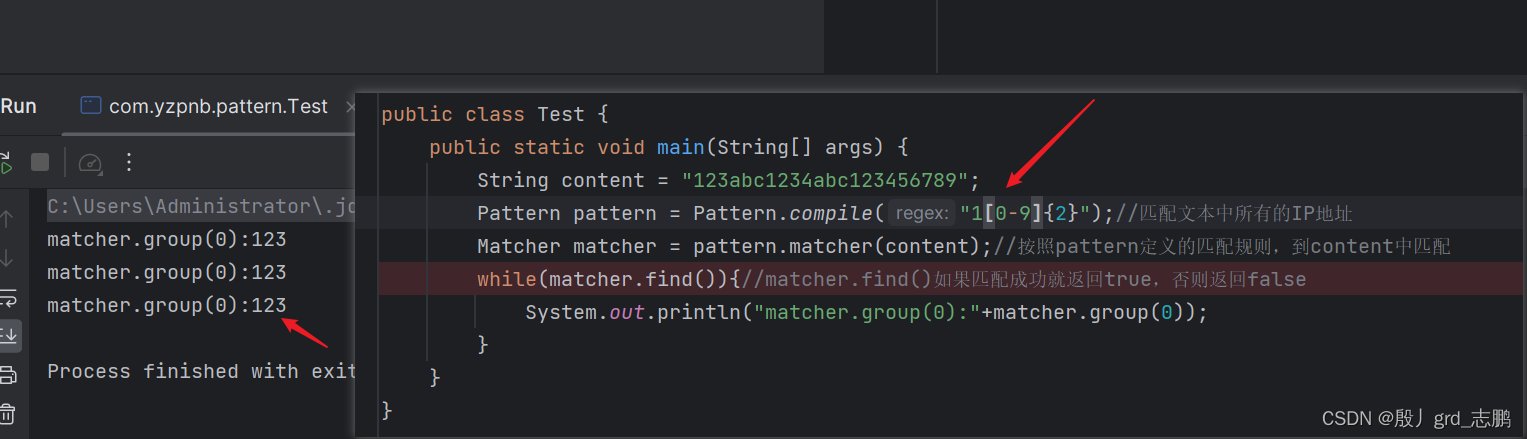
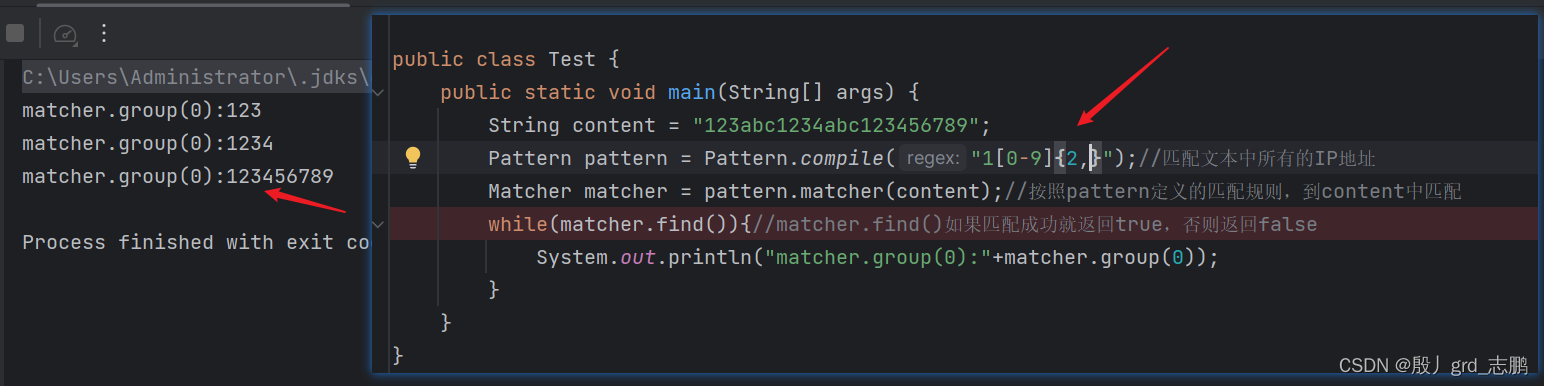
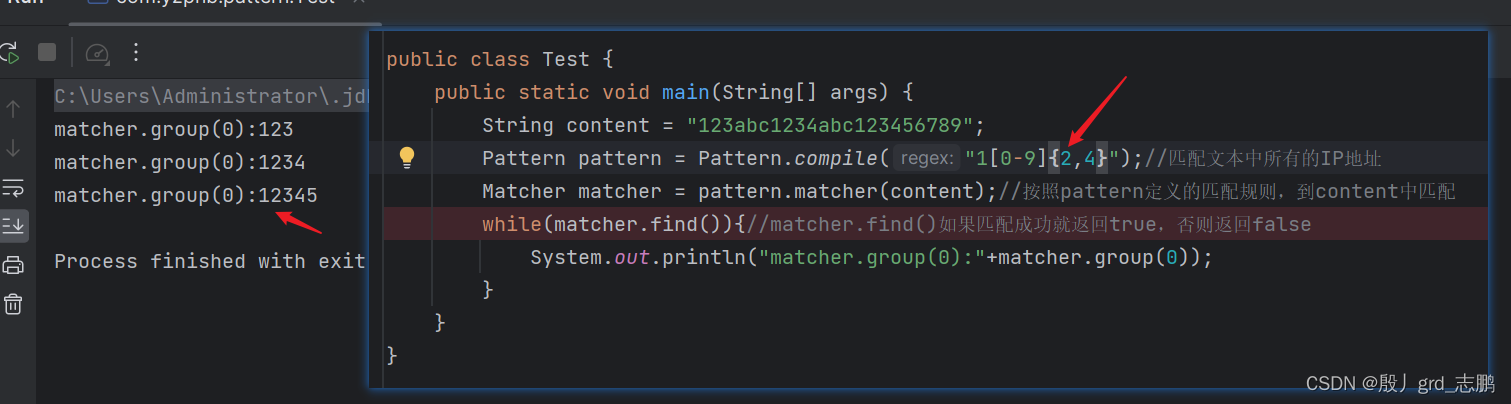
使用例子"123abc1234abc123456789",我们要对其中123,1234,123456789进行匹配
- 直接用{num}形式,表示必须num个,不能多也不能少。下面例子中,我们按照1[0-9]规则并限定[0-9]{2}.也就是1开头,后面跟[0-9]数字,必须长度为2,不能多也不能少。
下图结果中可以看出,1开头满足后,只会匹配2个[0-9]的数字,多一个少一个都没有匹配到
- 用{num,}形式,表示至少匹配num个,上不封顶,我们[0-9]{num,}进行匹配时,会匹配[0-9]至少两个,多了也没关系,但是不能少
下图结果中可以看出,1开头满足后,后面匹配[0-9]至少2个,但是上不封顶
- 用{left,right}形式,至少匹配left个,最多匹配right个。默认贪婪匹配,如果一次性匹配不完(原字符串符合规则字符个数超出right,优先先匹配right个,剩下的再依次匹配)
下图中,我们限定开头必须是1,且对[0-9]限定至少2个,最多4个。匹配结果也同样满足条件
5. 正则定位符
规定要匹配的字符串出现的位置,比如在字符串开始还是结束位置。换句话说:指定要匹配的位置
| 符号 | 描述 | 示例(示例中有不认识的符号,可以参考正则限定符中内容) | 示例解析 |
|---|---|---|---|
^ | 指定起始字符 | ^[0-9]+[a-z]* | 至少1个数字开头,后接任意个小写字母 |
$ | 指定结束字符 | ^[0-9]\\-[a-z]+$ | 以一个数字开头,接连字符"-",至少1个小写字母结尾 |
\\b | 匹配以指定规则结尾的边界 | yin\\b* | 边界:用空格分开的子串的两边,或目标字符串的起始和结束位置,例如这个字符串“yinabcdyin aaaayin”,标黄的位置就是以yin结尾的边界 |
\\B | 与\\b的含义正好相反,匹配以指定规则开头的边界 | yin\\B | “yinabcdyin aaaayin”,其中标黄的是以yin为开头的边界 |
| 待续待续待续待续待续 | 待续待续待续待续待续 | 待续待续待续待续待续续待续待续续待续待续续待续待续续续待续待续 | 待续待续待续待续待续 |
三、分组
适用于,我们匹配到内容后,想要单独获取其中某一部分的场景
例如匹配ip地址,10.0.76.1 我们匹配成功后,想要单独获取第3个字段中的内容76,就可以用分组来实现
1. 捕获分组
- (pattern):用一对小括号来实现分组称为非命名捕获。捕获匹配的子字符串。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其它捕获结果则根据左括号的顺序从1开始自动编号。
pattern是匹配规则,也就是要分组的正则表达式
- (? < name>pattern):命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中,用于name的字符串不能包含任何标点符合,并且不能以数字开头。可以使用单引号代替尖括号。例如(?'name’pattern)
| 命名捕获,实战中基本都是使用命名捕获,只有很简单的匹配会使用非命名捕获 |
|---|
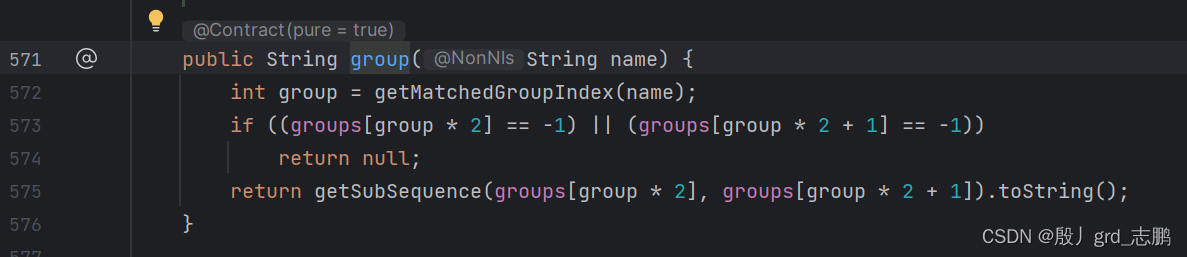
最上面的底层实现中,我们已经介绍过非命名捕获了。接下来是命名捕获,通过使用group方法的重载实现,这个group方法的源码如下,通过字符串获取对应组下标,然后剩下的逻辑和非命名一致。
- 我们想要实现,从一个字符串中,匹配出IP地址,并且通过"one"获取ip第一个字段,"two"获取第二个,"three"和"four"获取第3个和第4个
- 上图中发现,我们通过(?< name>)的方式为分组命名,并通过group方法,使用指定name获取分组内容。
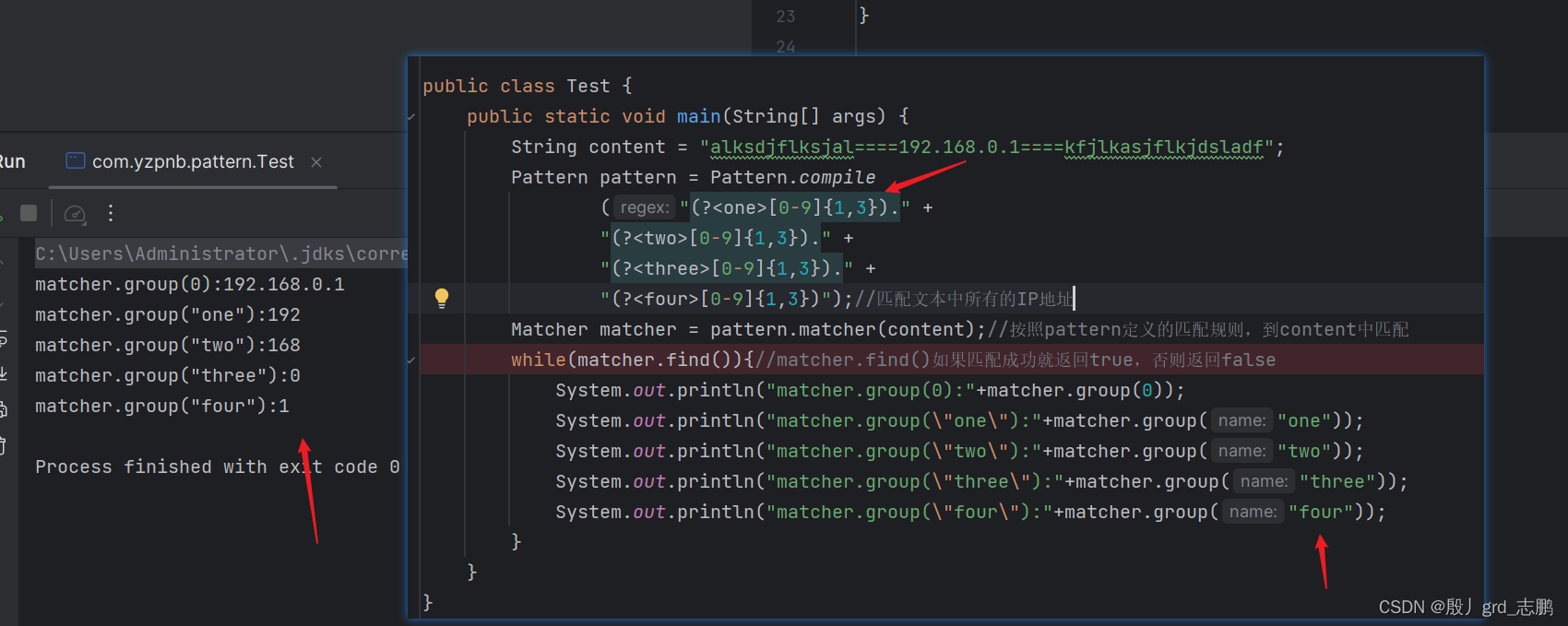
public static void main(String[] args) {String content = "alksdjflksjal====192.168.0.1====kfjlkasjflkjdsladf";Pattern pattern = Pattern.compile("(?<one>[0-9]{1,3})." +"(?<two>[0-9]{1,3})." +"(?<three>[0-9]{1,3})." +"(?<four>[0-9]{1,3})");//匹配文本中所有的IP地址Matcher matcher = pattern.matcher(content);//按照pattern定义的匹配规则,到content中匹配while(matcher.find()){//matcher.find()如果匹配成功就返回true,否则返回falseSystem.out.println("matcher.group(0):"+matcher.group(0));System.out.println("matcher.group(\"one\"):"+matcher.group("one"));System.out.println("matcher.group(\"two\"):"+matcher.group("two"));System.out.println("matcher.group(\"three\"):"+matcher.group("three"));System.out.println("matcher.group(\"four\"):"+matcher.group("four"));}}
2. 非捕获分组
想要使用一下分组的功能,但是不想浪费额外空间和时间,放到group(0)之类的。也就是说,捕获分组会将分组的内容捕获并存储。而非捕获分组,只是提供分组功能,但是不进行捕获和存储
常用于"or"字符(
|选择匹配符)组合模式部件的情况。
我们知道,分组是独立的,它富有()的功能,也就是括号里的单独处理(数学中,括号里的先算)
- (?:pattern):匹配pattern,分组中内容和pattern中匹配即可。简写了选择匹配符的实现,例如我们要匹配java0,java1,java2,java3,…
下面两个表达式等价,它极大的减少了重复操作,实现共有部分写一遍,单独用分组处理不同的部分。
- java(?:0|1|2|3)
- java0|java1|java2|java3
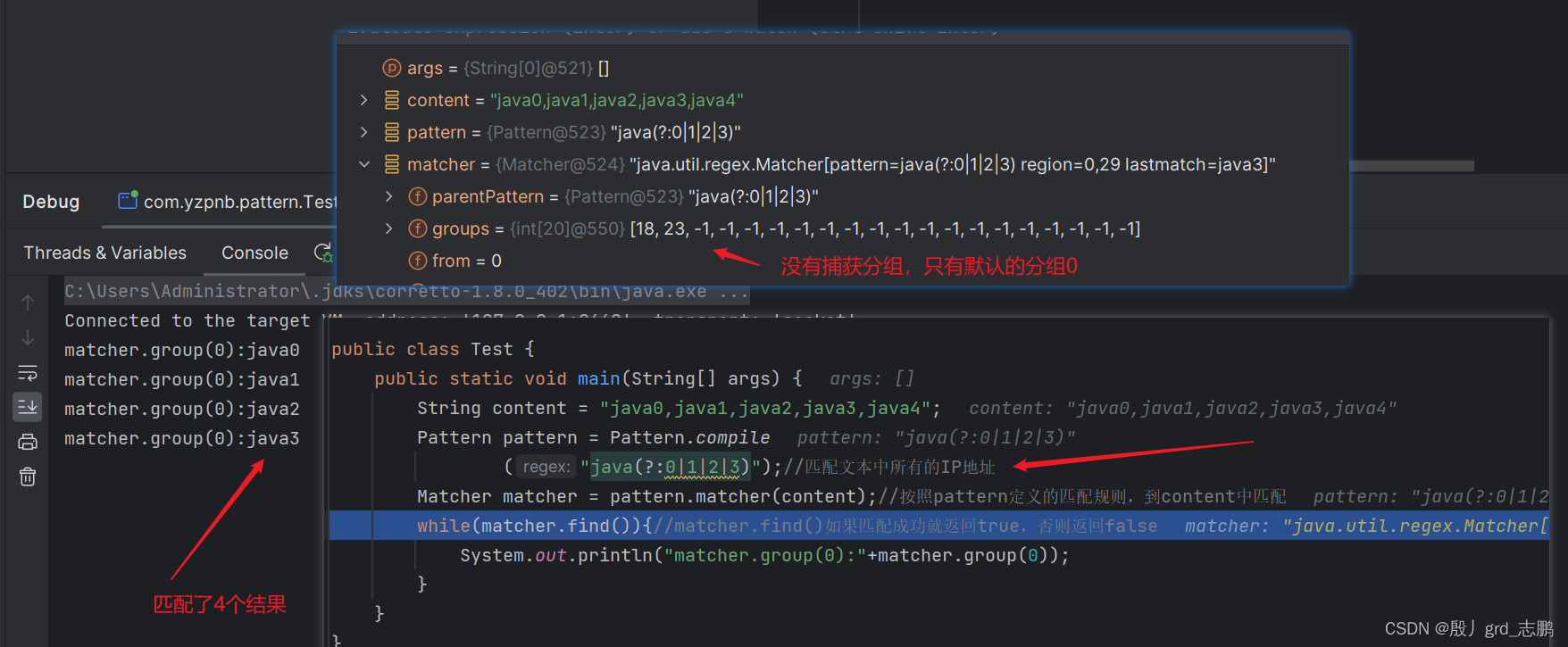
public static void main(String[] args) {String content = "java0,java1,java2,java3,java4";Pattern pattern = Pattern.compile("java(?:0|1|2|3)");//匹配文本中所有的IP地址Matcher matcher = pattern.matcher(content);//按照pattern定义的匹配规则,到content中匹配while(matcher.find()){//matcher.find()如果匹配成功就返回true,否则返回falseSystem.out.println("matcher.group(0):"+matcher.group(0));}}
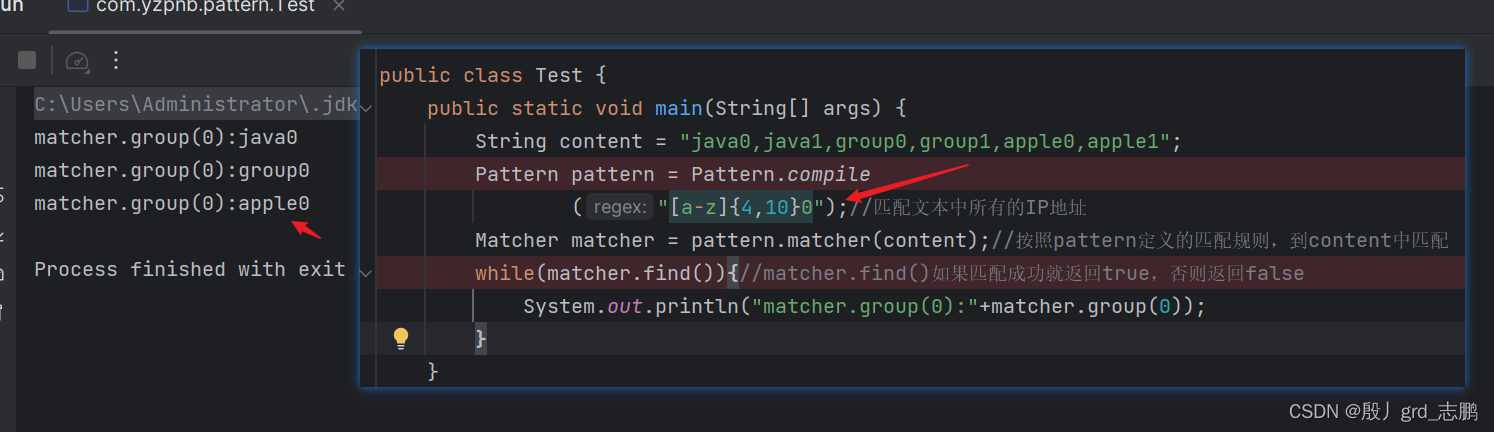
- (?=pattern):条件判断pattern,也就是这是将这个分组当做一个匹配条件,不参与到匹配结果中
例如我们想要匹配这个字符串java0,java1,group0,group1,apple0,apple1中,所有后面数字是0的英文字母,并且这个数字0不放入最终匹配结果中
- 直接用普通正则
[a-z]{4,10}0匹配,无法实现这个效果,可见下面的正则会将数字0也匹配出来
- 用非捕获分组,
[a-z]{4,10}(?=0),可以轻松匹配出这些单词,并且不带后面的0
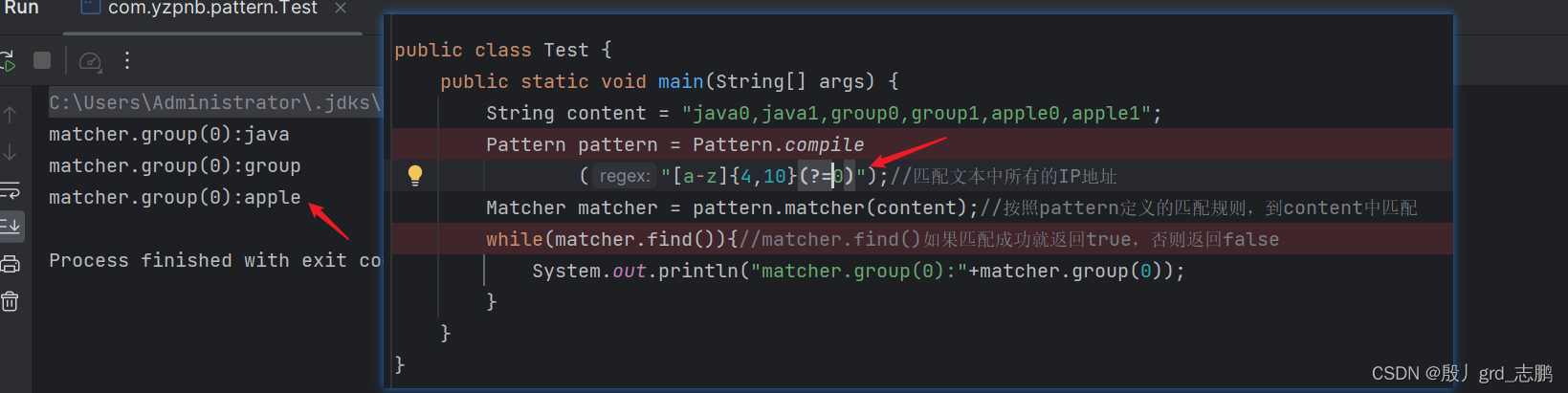
public static void main(String[] args) {String content = "java0,java1,group0,group1,apple0,apple1";Pattern pattern = Pattern.compile("[a-z]{4,10}(?=0)");//匹配文本中所有的IP地址Matcher matcher = pattern.matcher(content);//按照pattern定义的匹配规则,到content中匹配while(matcher.find()){//matcher.find()如果匹配成功就返回true,否则返回falseSystem.out.println("matcher.group(0):"+matcher.group(0));}}
- 有啥用?
- 当我们想要统计所有1999年生产的手机型号时。例如这个字符串"诺基亚1999,iPhone2018,摩托罗拉1999…",我们想匹配出1999年的所有手机,诺基亚和摩托罗拉。就可以用这个。而不是匹配出诺基亚1999,摩托罗拉1999,最后还得通过其它处理,将1999去掉。
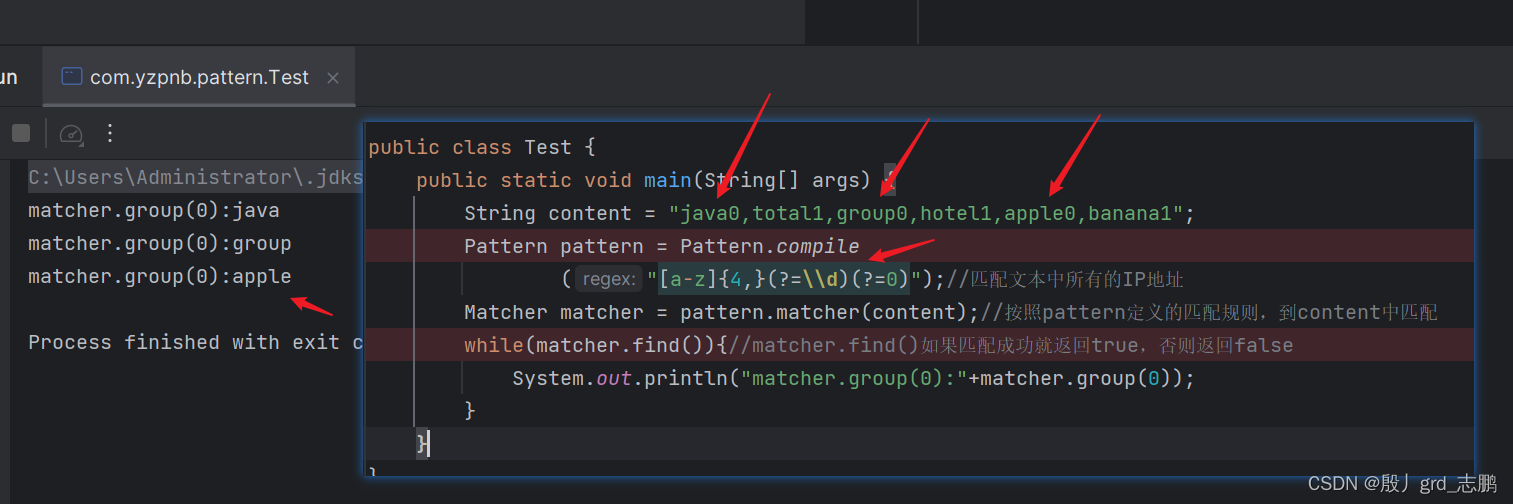
- (?!pattern),和(?=pattern)是相反的操作,表示拒绝匹配pattern
我们想要对java0,total1,group0,hotel1,apple0,banana1进行指定匹配
- 先用(?=pattern)举例:匹配所有单词,以数字结尾,并且这个数字必须是0. 这个就可以使用(?=pattern)操作,可以使用正则
[a-z]{4,}(?=\d)(?=0),表示最少4个字母,并且以数字结尾,并且末尾数字必须为0
- 匹配所有单词,以数字结尾,但是这个数字
不能为0.这时就用(?!pattern)操作,可以使用正则[a-z]{4,}(?=\d)(?!0)实现最少4个字母,以数字结尾,并且末尾数字必须不能为0

四、实战案例
| 因为篇幅原因,我将其放在另一篇文章中:https://blog.csdn.net/grd_java/article/details/136963602 |
|---|