文章目录
- 生成模型概述
- 一、生成模型类型
- 二、生成对抗网络(GANs)
- 三、自回归模型(Autoregressive Models)
- 四、扩散模型(Diffusion Models)
- 五、流模型(Flow-based Models)
- 参考
生成模型概述
一、生成模型类型
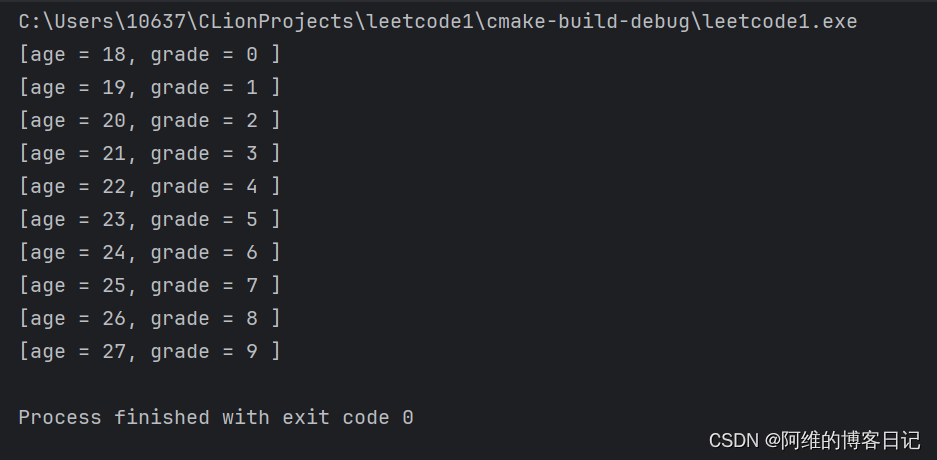
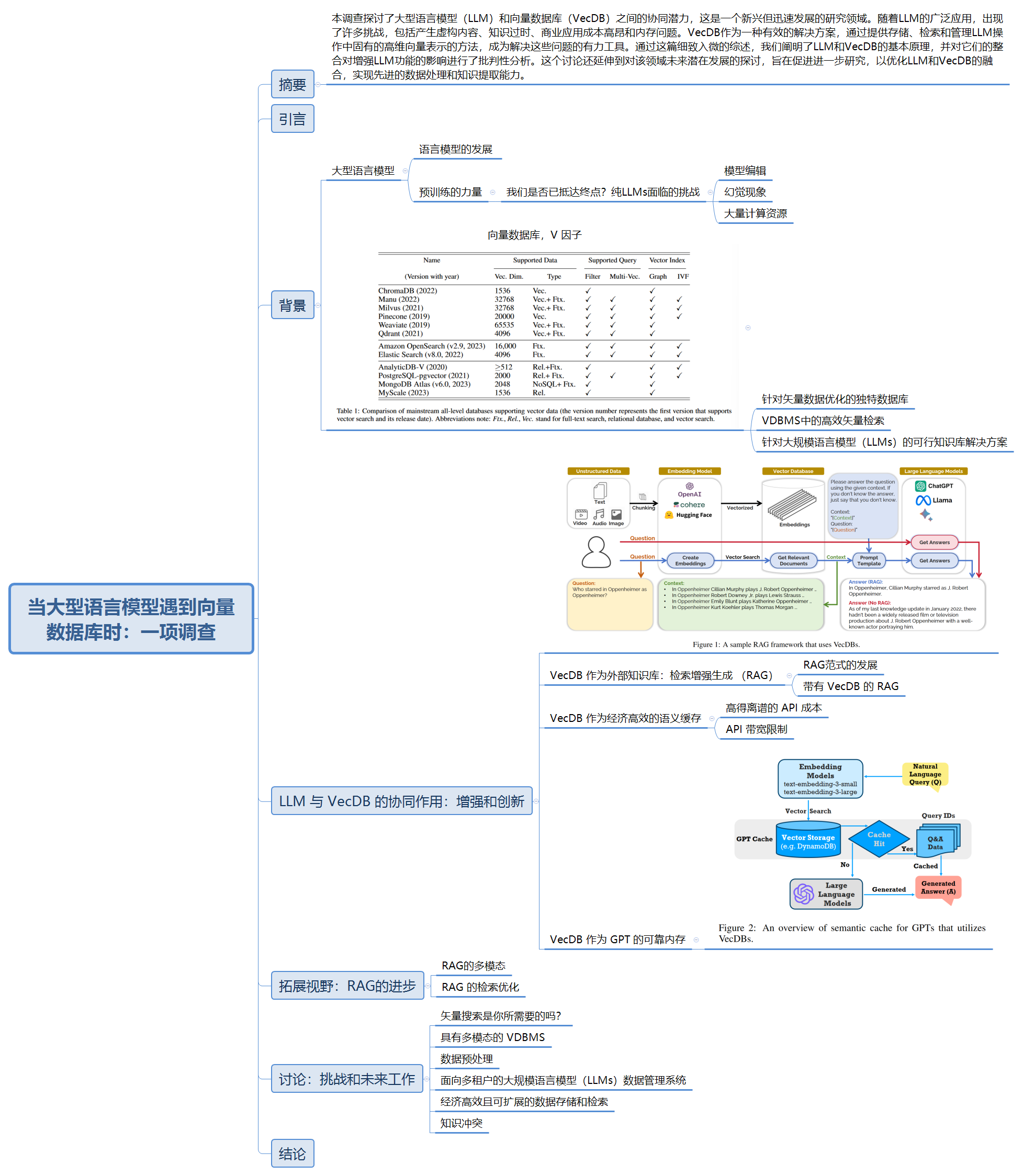
生成模型是深度学习领域的一类模型,它们的目标是学习如何生成数据的分布,从而能够生成新的、与真实数据类似的样本。
以下是一些主要的生成模型:
-
生成对抗网络(GANs):
GAN由两个部分组成:生成器(生成新数据)和判别器(区分真实数据和生成的数据)。这两部分在训练过程中相互竞争,提高彼此的性能。
应用:图像生成、艺术创作、数据增强、风格迁移等。 -
自回归模型(Autoregressive Models):
如Transformer在自然语言处理领域的应用。这些模型预测序列中的下一个元素,基于前面的元素。
应用:文本生成、机器翻译等。 -
扩散模型(Diffusion Models):
这类模型通过将数据转化为噪声,然后再逆过程中重建原始数据,来生成新的数据样本。
应用:高质量图像生成、文本到图像生成等。 -
流模型(Flow-based Models):
如RealNVP和Glow,这些模型通过可逆的神经网络变换实现从数据空间到潜在空间的映射。
应用:图像生成、数据去噪、概率建模等。 -
变分自编码器(VAEs):
VAE是一种基于贝叶斯推理的生成模型,它通过编码器将数据映射到潜在空间,然后通过解码器从潜在空间重构数据。
应用:图像生成、图像去噪、推荐系统等。 -
循环神经网络(RNNs)及其变体(如LSTM、GRU):
RNN及其变体特别擅长处理序列数据,可以用于生成文本、音乐等序列数据。
应用:文本生成、语音合成、音乐创作等。
其中,较为常见的方法主要为:生成对抗网络(GANs),自回归模型(Autoregressive Models),扩散模型(Diffusion Models)和Flow-base model。
二、生成对抗网络(GANs)
生成对抗网络的基本原理可以看左侧的示意图。

2014 年,Ian J.Goodfellow 提出了 GAN,它是由一个生成器 G 和一个判别器 D 组成。生成网络产生「假」数据,并试图欺骗判别网络;训练的时候,判别网络对生成数据进行真伪鉴别,试图正确识别所有「假」数据。在训练迭代的过程中,两个网络持续地进化和对抗,直到达到平衡状态,判别网络无法再识别「假」数据。
推理的时候,只要保留生成器 G 就行了,输入一个随机噪声 vector,生成一张图像。
右侧是一个经典的 AttnGAN 的框架,是一个引入了 attention 结构(使得图片生成局部能够和文本描述更加匹配)、并且从粗粒度到细粒度 coarse to fine 进行生成的框架,在当时还是取得了不错的生成效果。
GAN 的优势是在一些窄分布(比如人脸)数据集上效果很好,采样速度快,方便嵌入到一些实时应用里面去。
缺点是比较难训练、不稳定,而且有 Mode Collapse(模式崩塌)等问题。
三、自回归模型(Autoregressive Models)
第二种方法是自回归方式,自回归方式在自然语言中用的比较多,像大家听到最多的比如 GPT 系列。

这个方法比较出名的就是 VQGAN,还有就是 openai 的 dall-e。
VQGAN 是将类似的思路拓展到了视觉生成领域。他主要包括两个步骤:
第一步:将原始的 RGB 图像通过 vqvae 或者 vqgan 离散压缩成一系列的 视觉 code,这些视觉 code 可以利用一个训练得到的 decoder 恢复出原始的图像信息,当然会损失一些细节,但整体恢复质量还是 OK 的,特别是加了 GAN loss 的。
第二步:利用 transformer 或者 GPT,来按照一定的顺序,逐个的去预测每个视觉 code,当所有 code 都预测完了之后,就可以用第一步训练好的 Decoder 来生成对应的图像。因为每个 code 预测过程是有随机采样的,因此可以生成多样性比较高的不同图像。
四、扩散模型(Diffusion Models)
扩散模型也就是我们目前大多数文生图模型所采用的技术。
扩散模型也分为两个过程,一个是前向过程,通过向原始数据不断加入高斯噪声来破坏训练数据,最终加噪声到一定步数之后,原始数据信息就完全被破坏,无限接近与一个纯噪声。另外一个过程是反向过程,通过深度网络来去噪,来学习恢复数据。
训练完成之后,我们可以通过输入随机噪声,传递给去噪过程来生成数据。这就是 DDPM 的基本原理。
图中是 DALLE2 的一个基本框架,他的整个 pipeline 稍微有些复杂,输入文本,经过一个多模态的 CLIP 模型的文本编码器,学习一个 prior 网络,生成 clip 图像编码,然后 decoder 到 64*64 小图,再经过两个超分网络到 256*256,再到 1024*1024。

五、流模型(Flow-based Models)
OpenAI 曾经根据 GLOW 做过一些 Demo,Demo 网址:Glow: Better reversible generative models (openai.com)我们在这里给出 Demo的一些功能和简单的原理。
flow model 原理参考本人的另一篇博客:生成模型-流模型(Flow)
人脸混合:将一个人脸通过 G 逆输出成 z1,另一个人脸通过 G 逆输出成 z2,然后 z1 与 z2 取平均,平均值再通过 G,就可以得到混合后的人脸:

参考
常见的生成模型有哪些?_生成模型科普-CSDN博客
https://github.com/datawhalechina/sora-tutorial/tree/main/docs