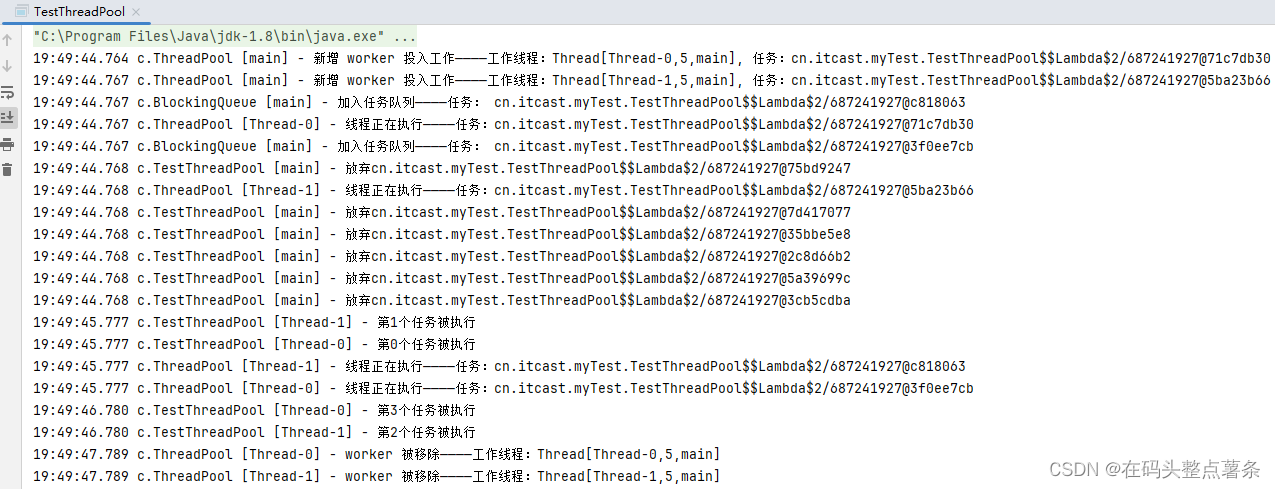
1 关联式容器
STL中我们常用的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器呢?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是**<key, value>结构的键值对**,在数据检索时比序列式容器效率更高。
2 键值对(pair)
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
stl中关于键值对的定义
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};
![![[Pasted image 20240324204650.png]]](https://img-blog.csdnimg.cn/direct/1735631fc53e446c9566b048758ffd5a.png)
可见,pair内有两个成员变量,一个是first,即key;一个是second,即value。
pair的构造函数:
![![[Pasted image 20240324204901.png]]](https://img-blog.csdnimg.cn/direct/e9914929868643039f6fc7ef179e6d31.png)
在C++98中,pair共有三个构造函数。
- 无参构造函数,根据模板参数推导出类型,调用该类型的默认构造函数生成key和value的值。
- 拷贝构造函数
- 通过两个值来构造,以key、value的顺序。
此外,C++中还提供了一种构造键值对的方法,利用make_pair函数
![![[Pasted image 20240324205256.png]]](https://img-blog.csdnimg.cn/direct/9d7ae163f4f94487bd86f9af72893e93.png)
可以看到,make_pair函数本质上是创建一个键值对对象并返回其拷贝。使用make_pair的好处是不用我们显示写模板参数。
在map的插入操作中,就需要插入一个一个的键值对。此时我们可以利用匿名对象构造插入,也可以使用make_pair函数。此外,C++11中还支持了多参数构造函数的隐式类型转换,为插入键值对提供了一种更新的方式,将在下文中演示。
3 树形结构的关联式容器
根据应用场景的不桶,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。
树型结构的关联式容器主要有四种:map、set、multimap、multiset。
这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
4 set
4.1 set
set的文档介绍如下:
![![[Pasted image 20240324210048.png]]](https://img-blog.csdnimg.cn/direct/aeb0767af9a24948a0a68d8d82204701.png)
翻译:
- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
- 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
- set在底层是用二叉搜索树(红黑树)实现的。
注意:
- 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
- set中插入元素时,只需要插入value即可,不需要构造键值对。
- set中的元素不可以重复(因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列
- set中的元素默认按照小于来比较
- set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2n
- set中的元素不允许修改(文档最后一句,set底层是搜索二叉树,如果允许修改整个树的大小关系就乱套了)
- set中的底层使用二叉搜索树(红黑树)来实现
注意set的模板参数中有一个Compare,这个是用于比较的仿函数,在priority_queue中也用到过仿函数这一工具。
4.2 set的使用
知晓了set的作用,set的使用其实非常简单,有了前面stl容器的使用经验,非常方便上手。
首先是set的构造函数,根据之前的经验,无非就是全缺省的默认构造函数、迭代器区间构造和拷贝构造。
![![[Pasted image 20240324210831.png]]](https://img-blog.csdnimg.cn/direct/764ed1ad58494b9fa25fb1213e4f118f.png)
不过要注意的是,由于set底层是一颗树,在执行拷贝构造和赋值时代价是比较大的,因为要进行深拷贝
4.2.1 insert
下面是比较重要的insert
![![[Pasted image 20240324211508.png]]](https://img-blog.csdnimg.cn/direct/d6d1519a306e46d4bf51e283d2b1df0c.png)
对于set,常用的插入操作时第一个函数。我们可以看见返回值是一个键值对,这是什么意思呢?
其实,这里牵扯到map实现方面的问题。在map中的insert需要设计成这样以支持[]运算符重载,这里是为了统一风格而设计。
由于set内不允许有重复元素,当插入元素并不存在于set中时才能执行插入,此时返回一个键值对,键值对中的key是插入元素的迭代器,value是一个bool值,如果插入成功则为true;当插入元素已经存在于set,此时键值对中的key是那个重复元素的迭代器,而value就为false。
其他的一些操作,命名也都沿袭了stl一贯的风格,看一眼大概就知道其功能。
![![[Pasted image 20240324212146.png]]](https://img-blog.csdnimg.cn/direct/398340d041eb4feaadf17f6ffab7ea89.png)
4.2.2 erase和find
想要删除一个元素可以用erase。可以直接以待删除元素的值作为参数。
// 在就删除,不在就不做任何处理
s.erase(3);
s.erase(30);
for (auto e : s)
{cout << e << " ";
}
cout << endl;
但是要注意的是,如果在set中没有找到要删除的值,是什么都不会发生的。
我们也可以用迭代器进行删除,用find搜索待删除元素。
// 这个值在,找到有效位置,再进行删除
pos = s.find(5);
s.erase(pos);
两种方式的区别是,find如果没有找到,而直接对其erase,是会报错的。
这是由于如果find找不到,将会返回end位置的迭代器,导致越界相关的问题。
此外,我们知道算法库里面也有一个find,通过一段迭代器区间来进行查找,但是这个find的效率不如set内置的效率高,因为set中时根据红黑树来查找的,而算法库中的find是根据迭代器一个一个的找。时间复杂度是对数级别和线性级别的差别。
4.2.3 count
count也可以用于查找一个元素在不在set中,如果在返回1,不在返回0。
4.2.4 lower_bound和upper_bound
![![[Pasted image 20240324213219.png]]](https://img-blog.csdnimg.cn/direct/b356ec150ad94b079ed7a23868891c80.png)
返回迭代器到下界
返回一个迭代器,该迭代器指向容器中的第一个元素,该元素不被认为位于val之前(即,它要么等价,要么在val之后)。
该函数使用其内部比较对象(key_comp)来确定这一点,并返回一个迭代器,指向key_comp(element,val)将返回false的第一个元素。
如果用默认比较类型(less)实例化set类,则该函数返回一个指向不小于val的第一个元素的迭代器。(即>=val的第一个值)
类似的成员函数upper_bound具有与lower_bound相同的行为,只是set包含一个与val等效的元素:在这种情况下,lower_bound返回一个指向该元素的迭代器,而upper_bound返回一个指向下一个元素的迭代器。(即>val的第一个值)
![![[Pasted image 20240324213237.png]]](https://img-blog.csdnimg.cn/direct/1746e2290e3f4d96a10633fb11c00c7c.png)
5 multiset
multyset和set非常类似,其区别是multiset允许键值冗余,即允许存在重复的元素,其余操作都是一样的。
此时如果我们再对multiset执行count操作,那么返回值就可能大于1了。
- multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
- 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除。
- 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
- multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列。
- multiset底层结构为二叉搜索树(红黑树)。
注意:
- multiset中再底层中存储的是<value, value>的键值对
- mtltiset的插入接口中只需要插入即可
- 与set的区别是,multiset中的元素可以重复,set是中value是唯一的
- 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
- multiset中的元素不能修改
- 在multiset中找某个元素,时间复杂度为 O ( l o g 2 N ) O(log_2 N) O(log2N)
- multiset的作用:可以对元素进行排序
6 map
6.1 map
先来看看map的介绍
![![[Pasted image 20240324213920.png]]](https://img-blog.csdnimg.cn/direct/f56cc7d1af934039a2eb8452b10346c5.png)
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
- 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:typedef pair<const key, T> value_type;
- 在内部,map中的元素总是按照键值key进行比较排序的。
- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
map内部的成员变量中,有如下三个是最为关键的
![![[Pasted image 20240324214143.png]]](https://img-blog.csdnimg.cn/direct/0de212acaec34634880f831bc4bd1d46.png)
由上到下分别是:
键(key)类型
值(value)类型(map有映射的意思,即key映射(mapped)之后的值为value)
键值对(key,value)类型
在map中,键值通常用于排序和唯一标识元素,而映射值存储与该键相关联的内容。键和映射值的类型可能不同,组合在成员类型value_type中,这是一种组合了两者的pair类型:
typdef pair<const Key, T> value_type;
其实,map和set本质上是非常接近的,区别在于存储的数据不同而已。map存放的是<key,value>,而set存放的是<value,value>
6.2 常用接口
![![[Pasted image 20240324214445.png]]](https://img-blog.csdnimg.cn/direct/84e23d4fcbe74737bc83c659c21cf100.png)
map大多数接口和set也很类似。先来看insert。
![![[Pasted image 20240324214646.png]]](https://img-blog.csdnimg.cn/direct/bd0c7100aca34d0682d14e57031c650e.png)
这里对于最常用的第一个,其返回值的意义同set是一样的。
对于map的insert,支持以下几种方式。
pair<string, string> p("banana", "香蕉");
m.insert(p);
m.insert(pair<string, string>("apple", "苹果"));
m.insert(make_pair("orange", "橙子"));
m.insert({ "blue","蓝色" }); // C++11新增,多参数构造函数的隐式类型转换
还需要注意的是,如果插入的时候,key相同,但是val不相同,是不会插入进去的,也不会覆盖进去的。即插入过程中,只比较key。key相同就不插入了。
删除操作也与set类似,需要注意的是,同样是以key作为标识。
6.3 map的[]运算符重载
map的[]运算符重载跟之前的序列容器(如vector,string)等实现方式有比较明显的区别。先来看文档说明。
![![[Pasted image 20240324220558.png]]](https://img-blog.csdnimg.cn/direct/eb9f28dd5f8e4350a6a33a6509ce0a4f.png)
可以看到,是以key为参数,返回值为该key对应的value的引用。这是为什么呢?
其实官方还给了一个非常重要的解释。
![![[Pasted image 20240324220739.png]]](https://img-blog.csdnimg.cn/direct/e9bf5580329946a3aae0144865b7b938.png)
我们把中间部分拆开来看
![![[Pasted image 20240324220812.png]]](https://img-blog.csdnimg.cn/direct/13e0a456221b4f3893f7a52fe7790e10.png)
会发现调用的是insert函数,而insert函数的返回值是一个pair
![![[Pasted image 20240324220850.png]]](https://img-blog.csdnimg.cn/direct/415873f7b1c04992b02d61c8d287286d.png)
再来看函数功能的介绍
![![[Pasted image 20240324221050.png]]](https://img-blog.csdnimg.cn/direct/a3be99abab2b47c09683ddd812e970ae.png)
访问元素
如果k与容器中某个元素的键匹配,则该函数返回对其映射值的引用。
如果k与容器中任何元素的键不匹配,则该函数用该键插入一个新元素,并返回对其映射值的引用。注意,这总是将容器的大小增加1,即使没有将映射值赋给元素(元素是使用其默认构造函数构造的)。
类似的成员函数map::at在具有键的元素存在时具有相同的行为,但在不存在时抛出异常。
简而言之, 原理就是用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中
- 如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器
- 如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器
- operator[]函数最后将insert返回值键值对中的value返回
有了这种机制,就可以利用下面的代码统计关键词的个数.
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto e : arr){countMap[e]++;}map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){cout << it->first << ":" << it->second << endl;it++;}
countMap对象中,它的两个参数是string和int,第一次的时候不存在,所以会创建一个pair<string,int>对象。int则会调用它的默认构造函数,即结果为0。然后有一个++,所以最终会将这个值给插入进去。
由于[]运算符重载返回的是value的引用,那么就可以实现以下几种功能:
- 插入
- 查找
- 修改
- 插入+修改
![![[Pasted image 20240324222612.png]]](https://img-blog.csdnimg.cn/direct/3a775152c2904bcf83dbe7d5866f1ce9.png)
7 multimap
类比multiset,multimap即允许一个键对应多个值。
这个在实际生活中也是有意义的,比如一个英文单词可能有多个中文意思。
但是与map在使用上还是有一些区别,比如这个容器没有提供[]运算符重载,因为无法根据一个key确定需要取的是哪个value。
同时,insert函数和erase函数也有一些变化。
insert不会再返回键值对,因为插入永远是成功的,只需要返回迭代器就可以了
![![[Pasted image 20240324222707.png]]](https://img-blog.csdnimg.cn/direct/e38cca67ac30453db274d379c4800a6d.png)
而对于erase,由于一个key对应多个value,此时对一个key进行删除,会将所有value一并删除。
总结
- Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key,value>,其中多个键值对之间的key是可以重复的。
- 在multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对:typedef pair<const Key, T> value_type;
- 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。
- multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍历multimap中的元素可以得到关于key有序的序列。
- multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的。