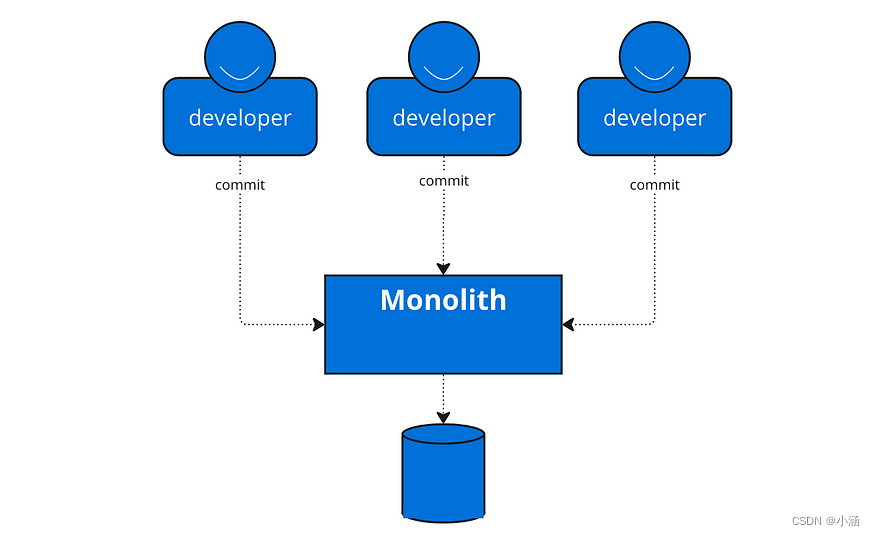
由于具有代表性的OpenAI公司GPT模型并没有开源,所以本章节是参考一些开源和现有课程(李宏毅)讲解ChatGPT原理。本章没有涉及到很多数学运算,比较适合小白了解GPT到底是怎么练成。GPT的三个英文字母分别代表Generative(生成式),Pre-trained(预训练),Transformer(Transforer模型,参考《Transformer家族》和《Transformer原理》)。
目前GPT模型已经发展出很多类似版本,不仅仅是OpenAI的GPT,还有Google Brad、Anthropic Claude以及xAI的Grok等等。
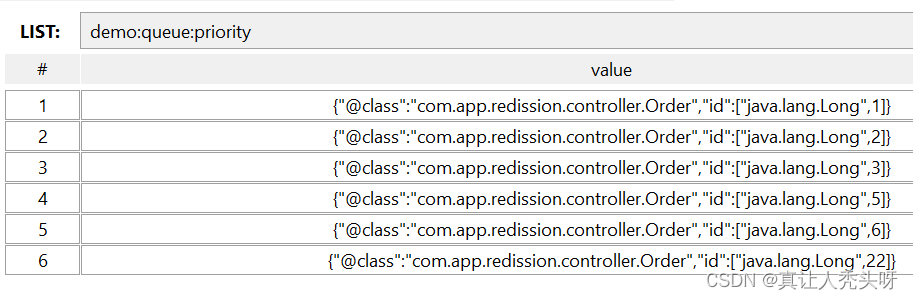
01 GPT的原理—文字接龙游戏
GPT真正在做的事就是”文字接龙“。简单来说就是预测输入的下一个字概率。
但并不是直接选择概率最大的文字作为输出,而是在输出时候还要掷骰子,也就是说答案具有随机性 也就是为什么每次你问大模型的时候,一样的问题会得到不一样的输出。
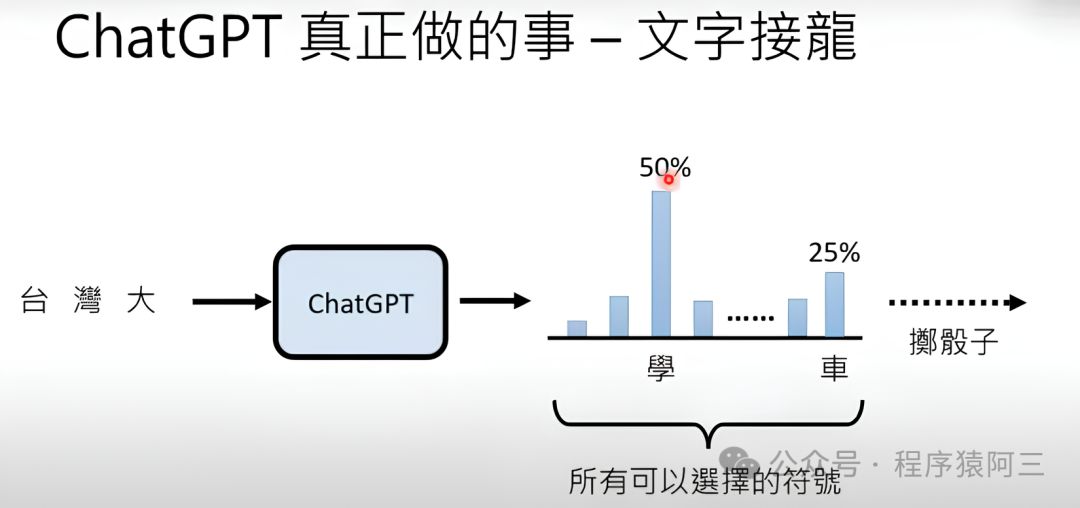
这跟我们以往做预测的时候,感觉很不一样, 以往我们都是输出概率最大作为结果, 所以为什么要掷骰子呢?
因为有很多相关研究证明,每次输出最大概率不一定是最好的,类似地文章《The Curious Case of Neural Text Degeneration》中有论证过, 同时这也符合我们人类特征, 同一个问题,可能问同一个人多次, 答案的输出并不是一模一样。
ChatGPT的答案为什么不一定是对的?
如果我们理解了ChatGPT的原理之后,其实ChatGPT就是在关心文字接龙顺不顺畅, 而不会关心内容的真实性(如果有朋友用过,就知道它的答案不一定是正确)。
GPT为什么可以实现上下文关联?
其实还是文字接龙的游戏, 在每次回答问题的时候,GPT不仅考虑当前的输入, 也会将历史的对话作为输入。
02 GPT是怎么学习文字接龙的呢?
基本经历过自学、人类教导、找到好老师、老师引导四个的过程。
2.1 自学
其实任何文本都是可以作为训练资料的, 比如下图的例子,就是依次学习文句,增加下个字的概率。
但是光靠学习文字接龙还远远不够, 比如GPT 仍不知道该如何给出有用的回答。比如问 GPT “世界上最高的山是哪座山?”,“你能告诉我么”、“珠穆朗玛峰”、“这是一个好问题” 都是上下文通顺的回答,但显然 “珠穆朗玛峰” 是更符合人类期望的回答。这时需要人类的指导。
2.2 人类教导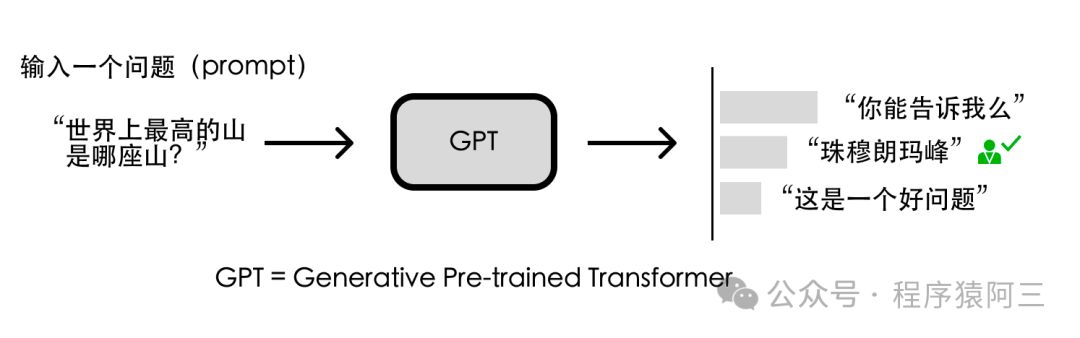
这时候在语言模型自学之后,需要引入人类监督训练。这个阶段不需要很多标注好资料去训练,毕竟成本太大。

通过这种人类监督训练,我们就可以得到一个简易版的GPT模型。
2.3 找到好老师
为了让简易版的GPT模型变强,其实OpenAI参考了以前的AlphaGo模型的方式,通过海量的自我对弈优化模型,最终超过人类。为了完成目标,人类引导的方式成本过高,于是乎,请了一个”好老师“(reward模型),这个老师不会像人类监督那样,直接给出答案,而是对模型输出给一个反馈,只有好与不好,让模型根据反馈自动调整输出,直到老师给出好的评价。
怎么找到有个能辨别 GPT 回答好坏的老师模型(即 Reward 模型)?
于是研究人员让 GPT 对特定问题给出多个答案,由人类来对这些答案的好坏做排序(相比直接给出答案,让人类做排序要简单得多)。基于这些评价数据,研究人员训练了一个符合人类评价标准的老师(Reward 模型)。
2.4 老师引导
有了好老师后,就可以开始像周伯通那样,左手(GPT)右手(好老师)互搏。要实现 AI 引导AI,得借助强化学习技术;简单来说就是让 AI 通过不断尝试,有则改之、无则加勉,从而逐步变强。
有了人类训练出来的好老师,通过好老师夜以继日引导,从而最终对齐了人类的偏好,最终实现了符合人类特征的回答。
3 总结
以上语言模型学习接龙的过程其实也是对应我们微调模型PPO策略:
自学->对应 PreTraing (预训练)
人类指导-> Supervised Finetuing(监督微调)
好老师-> Reward Modeing(奖励模型)
老师引导-> Reinforcement Learning(强化学习)

GPT经过这样过程学会成为文字接龙高手,它能够对答如流,但实际上这些回答往往欠缺逻辑性和正确性的考虑,从某种意义上说模型有时候是 “一本正经地胡说八道”,因而闹出很多笑话。但是GPT在很多领域依然能够超越人类(毕竟人类很多时候也会一本正经胡说八道,从某种意义来说更像人类了),并且还在不断发展,GPT功能是很强,但是如何学会用它,也是一门需要学习课程(提示工程师),有些人也用了提示工程结合其他工具制作出来很多GPT外挂(GPTs)。