目录
介绍:
模板:
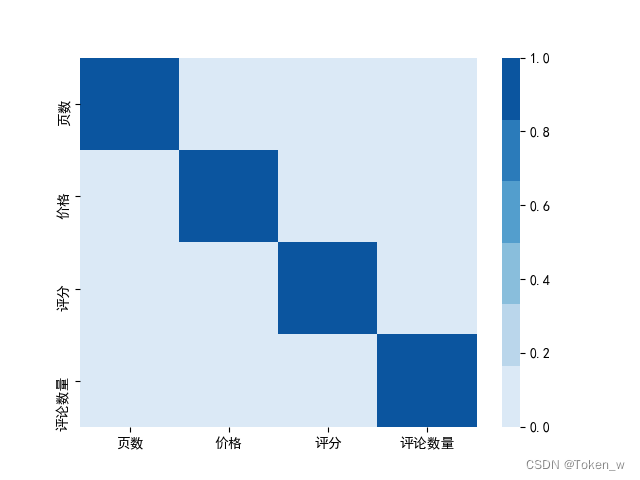
案例:哪些原因影响结婚率
数据标准化:
灰色关联度系数:
完整代码:
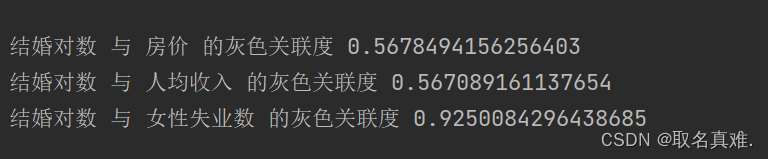
结果:
介绍:
灰色关联度是一种多指标综合评价方法,用于分析和评价不同指标之间的关联程度。它可以用于确定多个因素之间的相关性,以及它们对某个问题或现象的影响程度。
灰色关联度根据数据的相对大小和发展趋势,将指标划分为灰色数列,然后通过计算各指标之间的相对关联度来确定其关联程度。
灰色关联度的计算过程包括以下几个步骤:
1. 数据标准化:将各指标的原始数据进行标准化处理,将其转化为无量纲的数据。
2. 累积生成:将各指标数据按照一定顺序进行累积生成,得到灰色数列。
3. 关联系数计算:计算各指标与问题或现象之间的关联度,得到关联系数。
4. 排序和评价:根据关联系数对指标进行排序,评价其对问题或现象的影响程度。通过灰色关联度分析,可以帮助人们理解指标之间的关系,并进一步确定影响问题或现象的主要因素。这种方法常用于战略决策、经济发展、工程管理等领域,具有较高的应用价值。
模板:
import numpy as npdef gray_relation_coefficient(x, y):'''计算两个序列的灰色关联度参数:x: 序列x(一维数组)y: 序列y(一维数组)返回值:关联度值(float)'''n = len(x)# 数据标准化x_mean = np.mean(x)y_mean = np.mean(y)x_std = np.std(x)y_std = np.std(y)x_normalized = (x - x_mean) / x_stdy_normalized = (y - y_mean) / y_std# 构造灰色数列x_cumulative = np.cumsum(x_normalized)y_cumulative = np.cumsum(y_normalized)# 计算关联系数d = np.abs(x_cumulative - y_cumulative)delta = np.max(d)rho = 0.5relation_coefficient = (rho * delta + 1) / (d + rho * delta + 1)return relation_coefficient# 测试示例
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 5, 7, 9, 11])relation_coefficient = gray_relation_coefficient(x, y)
print("关联度值:", relation_coefficient)案例:哪些原因影响结婚率
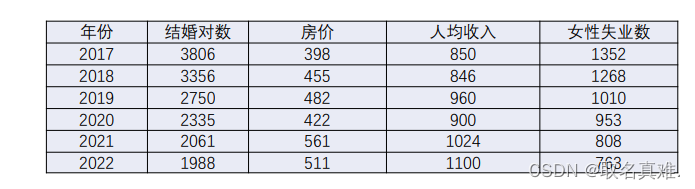
数据标准化:
def normalization(data1):[m, n] = data1.shape # 得到行数和列数data2 = data1.astype('float')data3 = data2ymin = 0.001ymax = 1for j in range(0, n):d_max = max(data2[:, j])d_min = min(data2[:, j])data3[:, j] = (ymax - ymin) * (data2[:, j] - d_min) / (d_max - d_min) + ymin#print(data3)return data3灰色关联度系数:
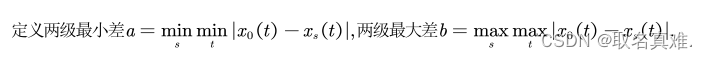
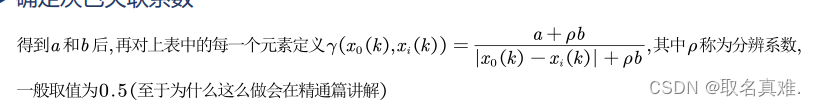

def Score(data):# 得到其他列和参考列相等的绝对值data3=data[n, m] = data3.shape#print(n)for i in range(1, m):data3[:, i] = np.abs(data3[:, i] - data3[:, 0])# 得到绝对值矩阵的全局最大值和最小值data4 = data3[:, 1:m]d_max = np.max(data4)d_min = np.min(data4)a = 0.5 # 定义分辨系数# 计算灰色关联矩阵data4 = (d_min + a * d_max) / (data4 + a * d_max)score = np.mean(data4, axis=0)return score完整代码:
# coding=gbk
import pandas as pd
import numpy as np
def normalization(data1):[m, n] = data1.shape # 得到行数和列数data2 = data1.astype('float')data3 = data2ymin = 0ymax = 1for j in range(0, n):d_max = max(data2[:, j])d_min = min(data2[:, j])data3[:, j] = (ymax - ymin) * (data2[:, j] - d_min) / (d_max - d_min) + ymin#print(data3)return data3def Score(data):# 得到其他列和参考列相等的绝对值data3=data[n, m] = data3.shape#print(n)for i in range(1, m):data3[:, i] = np.abs(data3[:, i] - data3[:, 0])# 得到绝对值矩阵的全局最大值和最小值data4 = data3[:, 1:m]d_max = np.max(data4)d_min = np.min(data4)a = 0.5 # 定义分辨系数# 计算灰色关联矩阵data4 = (d_min + a * d_max) / (data4 + a * d_max)print("灰色关联矩阵:")print(data4)score = np.mean(data4, axis=0)return scoreif __name__ == '__main__':# 导入数据data = pd.read_excel('D:\\桌面\\建模\\6\\代码\\marry.xlsx')# print(data)# 提取变量名label_need = data.keys()[1:]# print(label_need)# 提取上面变量名下的数据data1 = data[label_need].values#print(data1)data3=normalization(data1)#标准化scores=Score(data3)#算灰色关联度[m, n] = data1.shape # 得到行数和列数#print(data)print()for i in range(1, n):print(label_need[0], "与", label_need[i], "的灰色关联度", scores[i - 1])结果: