目录
- 一. XGBoost 算法
- 1. XGBoost 算法流程
- 2. XGBoost 算法评价
- 二. LightGBM 算法
- 2. LightGBM 算法优势
上一篇文章中,我们了解了Boosting思想的两种算法:Adboost和GBDT;其中对于GBDT算法,存在两种改进,即:
- XGBoost
- LightGBM
一. XGBoost 算法
XGBoost是GBDT(梯度提升树)的一个改进版本
能够更快的、更高效率的训练模型
X代表的就是eXtreme(极致)
学习器:决策树将这些决策树称为”弱学习器“,这些”弱学习器“共同组成了XGboost算法思想:XGBoost的决策树之间是有先后顺序后一棵决策树的生成会考虑前一棵决策树的预测结果,即:将前一棵决策树的偏差考虑在内,也就是更改y值数据使用:生成每棵决策树使用的是整个数据集

1. XGBoost 算法流程
-
构造初始化常数函数,以及模型跟新
F 0 ( x ) = f 0 ( x ) = 0 F_{0}(x)=f_{0}(x)=0 F0(x)=f0(x)=0F 1 ( x ) = F 0 ( x ) + f 1 ( x ) F_{1}(x)=F_{0}(x)+f_{1}(x) F1(x)=F0(x)+f1(x)
F 2 ( x ) = F 1 ( x ) + f 2 ( x ) F_{2}(x)=F_{1}(x)+f_{2}(x) F2(x)=F1(x)+f2(x)
. . . . . . ...... ......
F 0 ( x ) = F ( k − 1 ) ( x ) + f k ( x ) F_{0}(x)=F_{(k-1)}(x)+f_{k}(x) F0(x)=F(k−1)(x)+fk(x)
我们的目标为:求出函数 f 1 ( x ) f_{1}(x) f1(x), f 2 ( x ) f_{2}(x) f2(x),…, f k ( x ) f_{k}(x) fk(x)
-
定义损失函数
XGBoost算法的损失函数:在GBDT的基础上增加了正则化项,用于限制模型的复杂度
o b j = ∑ i = 1 n L ( y i , F i ( k ) ( x ) ) + ∑ i = 1 k Ω ( f i ) o b j=\sum_{i=1}^{n} L\left(y_{i}, F_{i}^{(k)}(x)\right)+\sum_{i=1}^{k} \Omega\left(f_{i}\right) obj=i=1∑nL(yi,Fi(k)(x))+i=1∑kΩ(fi)公式解释:
o b j 函数 obj函数 obj函数 为构建 k k k棵树的总损失预测误差 + 每棵树复杂度的惩罚项
对于正则化项,我们做出以下公式优化:
f k ( x ) = w q ( x ) f_{k}(x)=w_{q(x)} fk(x)=wq(x)
Ω ( f ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} Ω(f)=γT+21λj=1∑Twj2公式解释:
f k ( x ) f_{k}(x) fk(x)可以表示一棵树f 是一棵决策树, f k f_{k} fk是第 k k k棵决策树
x 是一个样本,丢进 f 函数 f函数 f函数中就需要对该样本进行预测
q ( x ) q(x) q(x) 表示进入的样本x落在哪个叶子节点中
w q ( x ) w_{q(x)} wq(x) 是叶子节点 q ( x ) q(x) q(x)的值先算在哪个叶子节点上,然后根据该叶子节点的值返回
Ω ( f ) \Omega(f) Ω(f)可以表示一棵树的复杂程度
T 表示这棵决策树叶子节点的数量:叶子节点越多,决策树越复杂
w j 2 w_{j}^{2} wj2 表示所有叶子节点值的平方和w w w为叶子节点的值
由于每个弱学习器拟合的都是残差,所以 w w w不能太大
如果模型企图去拟合离群点,那么 w w w就会变大此时,目标函数可以写为
L k = ∑ i = 1 n L [ y i , F k − 1 ( x ) + f k ( x i ) ] + ∑ j = 1 K Ω ( f j ) L^{k}=\sum_{i=1}^{n} L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]+\sum_{j=1}^{K} \Omega\left(f_{j}\right) Lk=i=1∑nL[yi,Fk−1(x)+fk(xi)]+j=1∑KΩ(fj)公式推导:
L k L^{k} Lk
= ∑ i = 1 n L [ y i , F k − 1 ( x ) + f k ( x i ) ] + ∑ j = 1 K Ω ( f j ) =\sum_{i=1}^{n} L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]+\sum_{j=1}^{K} \Omega\left(f_{j}\right) =∑i=1nL[yi,Fk−1(x)+fk(xi)]+∑j=1KΩ(fj)
= ∑ i = 1 n L [ y i , F k − 1 ( x ) + f k ( x i ) ] + ∑ j = 1 k − 1 Ω ( f j ) + Ω ( f k ) =\sum_{i=1}^{n} L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]+\sum_{j=1}^{k-1} \Omega\left(f_{j}\right)+\Omega\left(f_{k}\right) =∑i=1nL[yi,Fk−1(x)+fk(xi)]+∑j=1k−1Ω(fj)+Ω(fk)
= ∑ i = 1 n L [ y i , F k − 1 ( x ) + f k ( x i ) ] + Ω ( f k ) =\sum_{i=1}^{n} L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]+\Omega\left(f_{k}\right) =∑i=1nL[yi,Fk−1(x)+fk(xi)]+Ω(fk)
即: L k = ∑ i = 1 n L [ y i , F k − 1 ( x ) + f k ( x i ) ] + Ω ( f k ) L^{k}=\sum_{i=1}^{n} L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]+\Omega\left(f_{k}\right) Lk=i=1∑nL[yi,Fk−1(x)+fk(xi)]+Ω(fk)
3. 二阶展开
一元函数在x0点的泰勒展式:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + … + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + … f(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+\ldots f(x)=f(x0)+f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+…+n!f(n)(x0)(x−x0)n+…
注意:我们只求至二阶导即可
所以,对于 L [ y i , F k − 1 ( x ) + f k ( x i ) ] L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right] L[yi,Fk−1(x)+fk(xi)],可以写为:
L [ y i , F k − 1 ( x ) + f k ( x i ) ] L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right] L[yi,Fk−1(x)+fk(xi)]
= L [ y i , F k − 1 ( x ) ] + ∂ F k − 1 L [ y i , F k − 1 ( x ) ] f k ( x i ) + 1 2 ∂ F k − 1 2 L [ y i , F k − 1 ( x ) ] f k 2 ( x i ) =L[y_{i}, F_{k-1}(x)]+\partial_{F_{k-1}}L[y_{i}, F_{k-1}(x)] f_{k}\left(x_{i}\right)+\frac{1}{2} \partial_{F_{k-1}}^{2}L[y_{i}, F_{k-1}(x)] f_{k}^{2}\left(x_{i}\right) =L[yi,Fk−1(x)]+∂Fk−1L[yi,Fk−1(x)]fk(xi)+21∂Fk−12L[yi,Fk−1(x)]fk2(xi)
其中:
g i = ∂ F k − 1 L [ y i , F k − 1 ( x ) ] ,即 L 关于 x 0 的一阶导 g_{i}=\partial_{F_{k-1}}L[y_{i}, F_{k-1}(x)],即L关于x_{0}的一阶导 gi=∂Fk−1L[yi,Fk−1(x)],即L关于x0的一阶导
h i = ∂ F k − 1 2 L [ y i , F k − 1 ( x ) ] ,即 L 关于 x 0 的二阶导 h_{i}= \partial_{F_{k-1}}^{2}L[y_{i}, F_{k-1}(x)] ,即L关于x_{0}的二阶导 hi=∂Fk−12L[yi,Fk−1(x)],即L关于x0的二阶导
对于 L [ y i , F k − 1 ( x ) + f k ( x i ) ] L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right] L[yi,Fk−1(x)+fk(xi)]
x = F k − 1 ( x ) + f k ( x i ) x = F_{k-1}(x)+f_{k}\left(x_{i}\right) x=Fk−1(x)+fk(xi)
x 0 = F k − 1 ( x ) x_{0}= F_{k-1}(x) x0=Fk−1(x)
x − x 0 = f k ( x i ) x-x_{0} = f_{k}(x_{i}) x−x0=fk(xi)i为样本,所以 g i , h i g_{i},h_{i} gi,hi是可以计算得到的
也就是说, L [ y i , F k − 1 ( x ) ] L[y_{i}, F_{k-1}(x)] L[yi,Fk−1(x)]为常数即,为了求下一棵树,我需要求每个样本的一阶导,二阶导
因此,我们可以得到:
L [ y i , F k − 1 ( x ) + f k ( x i ) ] = L [ y i , F k − 1 ( x ) ] + g i ∗ f k ( x i ) + 1 2 h i ∗ f k 2 ( x i ) L\left[y_{i}, F_{k-1}(x)+f_{k}\left(x_{i}\right)\right]=L[y_{i}, F_{k-1}(x)]+g_{i} * f_{k}\left(x_{i}\right)+\frac{1}{2} h_{i} * f_{k}^{2}\left(x_{i}\right) L[yi,Fk−1(x)+fk(xi)]=L[yi,Fk−1(x)]+gi∗fk(xi)+21hi∗fk2(xi)
因为 L [ y i , F k − 1 ( x ) ] L[y_{i}, F_{k-1}(x)] L[yi,Fk−1(x)]为常数,所以对于每个样本,可以得到:
L k = ∑ i = 1 n g i ∗ f k ( x i ) + 1 2 h i ∗ f k 2 ( x i ) L^{k}=\sum_{i=1}^{n}g_{i} * f_{k}\left(x_{i}\right)+\frac{1}{2} h_{i} * f_{k}^{2}\left(x_{i}\right) Lk=i=1∑ngi∗fk(xi)+21hi∗fk2(xi)
L k = ∑ i = 1 n ( g i ∗ w q ( x i ) + 1 2 h i ∗ w q ( x i ) 2 ) + γ T + 1 2 λ ∑ j = 1 T w j 2 L^{k}=\sum_{i=1}^{n}\left(g_{i} * w_{q\left(x_{i}\right)}+\frac{1}{2} h_{i} * w_{q\left(x_{i}\right)}^{2}\right)+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} Lk=i=1∑n(gi∗wq(xi)+21hi∗wq(xi)2)+γT+21λj=1∑Twj2
我们认为,对于n个样本,最终会落到T个叶子节点上去
也就是说,对于某一个叶子节点:g a + g b + g c + . . . . = G j g_{a}+g_{b}+g_{c}+.... = G_{j} ga+gb+gc+....=Gj
同理,也可得到 H j H_{j} Hj
将公式转换为对于每个每个叶子节点求和,我们就可以得到:
L k = ∑ j = 1 T ( G j ∗ w j + 1 2 H j ∗ w j 2 ) + γ T + 1 2 λ ∑ j = 1 T w j 2 L^{k}=\sum_{j=1}^{T}\left(G_{j} * w_{j}+\frac{1}{2} H_{j} * w_{j}^{2}\right)+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} Lk=j=1∑T(Gj∗wj+21Hj∗wj2)+γT+21λj=1∑Twj2
合并后,最终得到的损失函数为:
L k = ∑ j = 1 T ( G j ∗ w j + 1 2 ( H j + λ ) ∗ w j 2 ) + γ T L^{k}=\sum_{j=1}^{T}\left(G_{j} * w_{j}+\frac{1}{2}\left(H_{j}+\lambda\right) * w_{j}^{2}\right)+\gamma T Lk=j=1∑T(Gj∗wj+21(Hj+λ)∗wj2)+γT
-
为了使损失函数最小,需要损失函数对于 w j w_{j} wj 求导,并令导数为0,求得最优的w:
注意:此时树的结构是确定的,即q函数确定
w j ∗ = − G j H j + λ w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda} wj∗=−Hj+λGj
即:每个叶子节点值为 w j ∗ w_{j}^{*} wj∗时,模型最佳
将 w w w带入,得到最小损失为:
L min k = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T L_{\min }^{k}=-\frac{1}{2} \sum_{j=1}^{T} \frac{G_{j}^{2}}{H_{j}+\lambda}+\gamma T Lmink=−21j=1∑THj+λGj2+γT
- 计算增益
上面,我们在树结构确定时,算出来最小损失
那么,我们现在的问题是:怎么确定树的结构?
对于一次节点分裂,显然损失下降越多,分裂节点越佳
这里我们解释 ∑ j = 1 T G j \sum_{j=1}^{T}G_{j} ∑j=1TGj:
假设数据集中共存在10个样本: g 1 , g 2 , . . . , g 10 g_{1},g_{2},...,g_{10} g1,g2,...,g10将样本1-5落在R叶子节点内
将样本6-10落在L叶子节点内因此我们可以得到 ∑ j = 1 T G j = G R + G L \sum_{j=1}^{T}G_{j}=G_{R}+G_{L} ∑j=1TGj=GR+GL
同理,可以得到 H R , H L H_{R},H_{L} HR,HL
对于分裂前,我们有:
loss before = − 1 2 ( G L + G R ) 2 ( H L + H R ) + λ + γ \text { loss }_{\text {before }}=-\frac{1}{2} \frac{\left(G_{L}+G_{R}\right)^{2}}{\left(H_{L}+H_{R}\right)+\lambda}+\gamma loss before =−21(HL+HR)+λ(GL+GR)2+γ
对于分裂后,我们有:
loss a f t e r = − [ 1 2 G L 2 H L + λ + γ ] − [ 1 2 G R 2 H R + λ + γ ] = − 1 2 ( G L 2 H L + λ + G R 2 H R + λ ) + 2 γ \text { loss }_{a f t e r}=-[\frac{1}{2} \frac{G_{L}^{2}}{H_{L}+\lambda } +\gamma] -[\frac{1}{2} \frac{G_{R}^{2}}{H_{R}+\lambda } +\gamma] =-\frac{1}{2}\left(\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}\right)+2 \gamma loss after=−[21HL+λGL2+γ]−[21HR+λGR2+γ]=−21(HL+λGL2+HR+λGR2)+2γ
因此,信息增益为:
计算所有候选分裂点对应的gain
选择gain最大的分裂点进行分裂
如果一个节点的所有候选分裂点都不能带来gain,则该节点不分裂
g a i n = 1 2 ( G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 ( H L + H R ) + λ ) − γ gain=\frac{1}{2}\left(\frac{G_{L}^{2}}{H_{L}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}-\frac{\left(G_{L}+G_{R}\right)^{2}}{\left(H_{L}+H_{R}\right)+\lambda}\right)-\gamma gain=21(HL+λGL2+HR+λGR2−(HL+HR)+λ(GL+GR)2)−γ
2. XGBoost 算法评价
- 与决策树不同,XGBoost并不直接使用基尼系数或信息增益这些指标来进行特征选择或分裂点选择,而是计算每个特征的分裂增益(Gain)来选择最佳的最佳的特征和分裂点,从而构建更准确的树模型
- 分裂增益表示在分裂前后损失函数的减少程度
在计算分裂增益时,有两种方式:
-
精确算法:遍历所有特征的所有可能的分裂点,计算gain值,选择最大的 gain值对应的分裂点进行分裂
如:上述公式推导部分 -
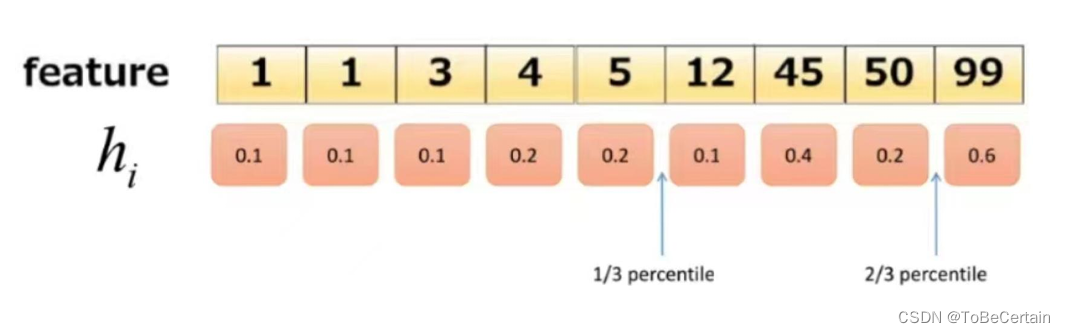
近似算法:对于每个特征,只考虑分位点,减少计算复杂度
分位点:按照上一轮的预测误差函数的二阶导数值作为权重进行划分
二. LightGBM 算法
LightGBM是由微软开发的boosting集成模型,类似于XGBoost,对GBDT进行了优化和高效实现,原理有一些相似之处;但它的主要优势在于能够处理大规模数据
在实验中:LightGBM 比 XGBoost 快将近10倍内存占用率大约为XGBoost的1/6
2. LightGBM 算法优势
GBDT 在每一次迭代的时候,都需要遍历整个训练数据多次如果把整个训练数据一次性装进内存,会明显限制训练数据的大小如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
面对大规模工业级数据,传统的GBDT算法无法满足需求。LightGBM的主要目的之一是解决上述大数据量级下的GBDT训练问题,以便在工业实践中支持大规模数据并保证效率
算法思想:LightGBM提出直方图算法:为了减少分裂点的数量
直方图就是把连续的浮点特征离散化为k个整数(也就是分桶bins的思想),比如:
[ 0 , 0.1 ] = > 0 [0,0.1] =>0 [0,0.1]=>0
[ 0.1 , 0.3 ] = > 1 [0.1,0.3] => 1 [0.1,0.3]=>1这里的思想类似XGBoost的分位点

感谢阅读🌼
如果喜欢这篇文章,记得点赞👍和转发🔄哦!
有任何想法或问题,欢迎留言交流💬,我们下次见!
本文相关代码存放位置
【Boosting思想 扩展算法 代码实现】
祝愉快🌟!




![LeetCode每日一题[c++]-322.零钱兑换](https://img-blog.csdnimg.cn/direct/ac538a8588c3496eae163cacb0d1863e.png)



![[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction](https://img-blog.csdnimg.cn/img_convert/b9f1b3a80a11baf04f6d2162abd203c8.png)