第三部分:类和协议
第十一章:一个 Python 风格的对象
使库或框架成为 Pythonic 是为了让 Python 程序员尽可能轻松和自然地学会如何执行任务。
Python 和 JavaScript 框架的创造者 Martijn Faassen。¹
由于 Python 数据模型,您定义的类型可以像内置类型一样自然地行为。而且这可以在不继承的情况下实现,符合鸭子类型的精神:你只需实现对象所需的方法,使其行为符合预期。
在之前的章节中,我们研究了许多内置对象的行为。现在我们将构建行为像真正的 Python 对象一样的用户定义类。你的应用程序类可能不需要并且不应该实现本章示例中那么多特殊方法。但是如果你正在编写一个库或框架,那么将使用你的类的程序员可能希望它们的行为像 Python 提供的类一样。满足这种期望是成为“Pythonic”的一种方式。
本章从第一章结束的地方开始,展示了如何实现在许多不同类型的 Python 对象中经常看到的几个特殊方法。
在本章中,我们将看到如何:
-
支持将对象转换为其他类型的内置函数(例如
repr()、bytes()、complex()等) -
实现一个作为类方法的替代构造函数
-
扩展 f-strings、
format()内置函数和str.format()方法使用的格式迷你语言 -
提供对属性的只读访问
-
使对象可哈希以在集合中使用和作为
dict键 -
使用
__slots__节省内存
当我们开发Vector2d时,我们将做所有这些工作,这是一个简单的二维欧几里德向量类型。这段代码将是第十二章中 N 维向量类的基础。
示例的演变将暂停讨论两个概念性主题:
-
如何以及何时使用
@classmethod和@staticmethod装饰器 -
Python 中的私有和受保护属性:用法、约定和限制
本章的新内容
我在本章的第二段中添加了一个新的引语和一些文字,以解释“Pythonic”的概念——这在第一版中只在最后讨论过。
“格式化显示”已更新以提及在 Python 3.6 中引入的 f-strings。这是一个小改变,因为 f-strings 支持与format()内置和str.format()方法相同的格式迷你语言,因此以前实现的__format__方法可以与 f-strings 一起使用。
本章的其余部分几乎没有变化——自 Python 3.0 以来,特殊方法大部分相同,核心思想出现在 Python 2.2 中。
让我们开始使用对象表示方法。
对象表示
每种面向对象的语言至少有一种标准方法可以从任何对象获取字符串表示。Python 有两种:
repr()
返回一个表示开发者想要看到的对象的字符串。当 Python 控制台或调试器显示一个对象时,你会得到这个。
str()
返回一个表示用户想要看到的对象的字符串。当你print()一个对象时,你会得到这个。
特殊方法__repr__和__str__支持repr()和str(),正如我们在第一章中看到的。
有两个额外的特殊方法支持对象的替代表示:__bytes__和__format__。__bytes__方法类似于__str__:它被bytes()调用以获取对象表示为字节序列。关于__format__,它被 f-strings、内置函数format()和str.format()方法使用。它们调用obj.__format__(format_spec)以获取使用特殊格式代码的对象的字符串显示。我们将在下一个示例中介绍__bytes__,然后介绍__format__。
警告
如果您从 Python 2 转换而来,请记住,在 Python 3 中,__repr__,__str__ 和 __format__ 必须始终返回 Unicode 字符串(类型 str)。 只有 __bytes__ 应该返回字节序列(类型 bytes)。
向量类 Redux
为了演示生成对象表示所使用的许多方法,我们将使用类似于我们在第一章中看到的 Vector2d 类。 我们将在本节和未来的章节中继续完善它。 示例 11-1 说明了我们从 Vector2d 实例中期望的基本行为。
示例 11-1。 Vector2d 实例有几种表示形式
>>> v1 = Vector2d(3, 4)>>> print(v1.x, v1.y) # ①3.0 4.0>>> x, y = v1 # ②>>> x, y(3.0, 4.0)>>> v1 # ③Vector2d(3.0, 4.0)>>> v1_clone = eval(repr(v1)) # ④>>> v1 == v1_clone # ⑤True>>> print(v1) # ⑥(3.0, 4.0)>>> octets = bytes(v1) # ⑦>>> octetsb'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'>>> abs(v1) # ⑧5.0>>> bool(v1), bool(Vector2d(0, 0)) # ⑨(True, False)
①
Vector2d 的组件可以直接作为属性访问(无需 getter 方法调用)。
②
Vector2d 可以解包为一组变量的元组。
③
Vector2d 的 repr 模拟了构造实例的源代码。
④
在这里使用 eval 显示 Vector2d 的 repr 是其构造函数调用的忠实表示。²
⑤
Vector2d 支持与 == 的比较;这对于测试很有用。
⑥
print 调用 str,对于 Vector2d 会产生一个有序对显示。
⑦
bytes 使用 __bytes__ 方法生成二进制表示。
⑧
abs 使用 __abs__ 方法返回 Vector2d 的大小。
⑨
bool 使用 __bool__ 方法,对于零大小的 Vector2d 返回 False,否则返回 True。
Vector2d 来自示例 11-1,在 vector2d_v0.py 中实现(示例 11-2)。 该代码基于示例 1-2,除了 + 和 * 操作的方法,我们稍后会看到在第十六章中。 我们将添加 == 方法,因为它对于测试很有用。 到目前为止,Vector2d 使用了几个特殊方法来提供 Pythonista 在设计良好的对象中期望的操作。
示例 11-2。 vector2d_v0.py:到目前为止,所有方法都是特殊方法
from array import array
import mathclass Vector2d:typecode = 'd' # ①def __init__(self, x, y):self.x = float(x) # ②self.y = float(y)def __iter__(self):return (i for i in (self.x, self.y)) # ③def __repr__(self):class_name = type(self).__name__return '{}({!r}, {!r})'.format(class_name, *self) # ④def __str__(self):return str(tuple(self)) # ⑤def __bytes__(self):return (bytes([ord(self.typecode)]) + # ⑥bytes(array(self.typecode, self))) # ⑦def __eq__(self, other):return tuple(self) == tuple(other) # ⑧def __abs__(self):return math.hypot(self.x, self.y) # ⑨def __bool__(self):return bool(abs(self)) # ⑩
①
typecode 是我们在将 Vector2d 实例转换为/从 bytes 时将使用的类属性。
②
在 __init__ 中将 x 和 y 转换为 float 可以及早捕获错误,这在 Vector2d 被使用不合适的参数调用时很有帮助。
③
__iter__ 使 Vector2d 可迭代;这就是解包工作的原因(例如,x, y = my_vector)。 我们简单地通过使用生成器表达式逐个产生组件来实现它。³
④
__repr__ 通过使用 {!r} 插值组件来构建字符串;因为 Vector2d 是可迭代的,*self 将 x 和 y 组件提供给 format。
⑤
从可迭代的 Vector2d 中,很容易构建一个用于显示有序对的 tuple。
⑥
要生成 bytes,我们将类型码转换为 bytes 并连接…
⑦
…通过迭代实例构建的 array 转换为的 bytes。
⑧
要快速比较所有组件,将操作数构建为元组。 这适用于 Vector2d 的实例,但存在问题。 请参阅以下警告。
⑨
大小是由x和y分量形成的直角三角形的斜边的长度。
⑩
__bool__使用abs(self)来计算大小,然后将其转换为bool,因此0.0变为False,非零为True。
警告
示例 11-2 中的__eq__方法适用于Vector2d操作数,但当将Vector2d实例与持有相同数值的其他可迭代对象进行比较时也返回True(例如,Vector(3, 4) == [3, 4])。这可能被视为一个特性或一个错误。进一步讨论需要等到第十六章,当我们讨论运算符重载时。
我们有一个相当完整的基本方法集,但我们仍然需要一种方法来从bytes()生成的二进制表示中重建Vector2d。
另一种构造方法
由于我们可以将Vector2d导出为字节,自然我们需要一个从二进制序列导入Vector2d的方法。在标准库中寻找灵感时,我们发现array.array有一个名为.frombytes的类方法,非常适合我们的目的——我们在“数组”中看到了它。我们采用其名称,并在vector2d_v1.py中的Vector2d类方法中使用其功能(示例 11-3)。
示例 11-3. vector2d_v1.py 的一部分:此片段仅显示了frombytes类方法,添加到 vector2d_v0.py 中的Vector2d定义中(示例 11-2)
@classmethod # ①def frombytes(cls, octets): # ②typecode = chr(octets[0]) # ③memv = memoryview(octets[1:]).cast(typecode) # ④return cls(*memv) # ⑤
①
classmethod装饰器修改了一个方法,使其可以直接在类上调用。
②
没有self参数;相反,类本身作为第一个参数传递—按照惯例命名为cls。
③
从第一个字节读取typecode。
④
从octets二进制序列创建一个memoryview,并使用typecode进行转换。⁴
⑤
将从转换结果中得到的memoryview解包为构造函数所需的一对参数。
我刚刚使用了classmethod装饰器,它非常特定于 Python,所以让我们谈谈它。
类方法与静态方法
Python 教程中没有提到classmethod装饰器,也没有提到staticmethod。任何在 Java 中学习面向对象编程的人可能会想知道为什么 Python 有这两个装饰器而不是其中的一个。
让我们从classmethod开始。示例 11-3 展示了它的用法:定义一个在类上而不是在实例上操作的方法。classmethod改变了方法的调用方式,因此它接收类本身作为第一个参数,而不是一个实例。它最常见的用途是用于替代构造函数,就像示例 11-3 中的frombytes一样。请注意frombytes的最后一行实际上通过调用cls参数来使用cls参数以构建一个新实例:cls(*memv)。
相反,staticmethod装饰器改变了一个方法,使其不接收特殊的第一个参数。实质上,静态方法就像一个普通函数,只是它存在于类体中,而不是在模块级别定义。示例 11-4 对比了classmethod和staticmethod的操作。
示例 11-4. 比较classmethod和staticmethod的行为
>>> class Demo:
... @classmethod
... def klassmeth(*args):
... return args # ①
... @staticmethod
... def statmeth(*args):
... return args # ②
...
>>> Demo.klassmeth() # ③
(<class '__main__.Demo'>,) >>> Demo.klassmeth('spam')
(<class '__main__.Demo'>, 'spam') >>> Demo.statmeth() # ④
() >>> Demo.statmeth('spam')
('spam',)
①
klassmeth只返回所有位置参数。
②
statmeth也是如此。
③
无论如何调用,Demo.klassmeth都将Demo类作为第一个参数接收。
④
Demo.statmeth的行为就像一个普通的旧函数。
注意
classmethod装饰器显然很有用,但在我的经验中,staticmethod的好用例子非常少见。也许这个函数即使从不涉及类也与之密切相关,所以你可能希望将其放在代码附近。即使如此,在同一模块中在类的前面或后面定义函数大多数情况下已经足够接近了。⁵
现在我们已经看到了classmethod的用途(以及staticmethod并不是很有用),让我们回到对象表示的问题,并看看如何支持格式化输出。
格式化显示
f-strings、format()内置函数和str.format()方法通过调用它们的.__format__(format_spec)方法将实际格式化委托给每种类型。format_spec是一个格式说明符,它可以是:
-
format(my_obj, format_spec)中的第二个参数,或 -
无论在 f-string 中的用
{}括起来的替换字段中的冒号后面的内容,还是在fmt.str.format()中的fmt中
例如:
>>> brl = 1 / 4.82 # BRL to USD currency conversion rate
>>> brl
0.20746887966804978 >>> format(brl, '0.4f') # ①
'0.2075' >>> '1 BRL = {rate:0.2f} USD'.format(rate=brl) # ②
'1 BRL = 0.21 USD' >>> f'1 USD = {1 / brl:0.2f} BRL' # ③
'1 USD = 4.82 BRL'
①
格式说明符是'0.4f'。
②
格式说明符是'0.2f'。替换字段中的rate部分不是格式说明符的一部分。它确定哪个关键字参数进入该替换字段。
③
再次,说明符是'0.2f'。1 / brl表达式不是其中的一部分。
第二个和第三个标注指出了一个重要的观点:例如'{0.mass:5.3e}'这样的格式字符串实际上使用了两种不同的表示法。冒号左边的'0.mass'是替换字段语法的field_name部分,它可以是 f-string 中的任意表达式。冒号后面的'5.3e'是格式说明符。格式说明符中使用的表示法称为格式规范迷你语言。
提示
如果 f-strings、format()和str.format()对你来说是新的,课堂经验告诉我最好先学习format()内置函数,它只使用格式规范迷你语言。在你掌握了这个要领之后,阅读“格式化字符串字面值”和“格式化字符串语法”来了解在 f-strings 和str.format()方法中使用的{:}替换字段符号,包括!s、!r和!a转换标志。f-strings 并不使str.format()过时:大多数情况下 f-strings 解决了问题,但有时最好在其他地方指定格式化字符串,而不是在将要呈现的地方。
一些内置类型在格式规范迷你语言中有自己的表示代码。例如——在几个其他代码中——int类型支持分别用于输出基数 2 和基数 16 的b和x,而float实现了用于固定点显示的f和用于百分比显示的%:
>>> format(42, 'b')
'101010'
>>> format(2 / 3, '.1%')
'66.7%'
格式规范迷你语言是可扩展的,因为每个类都可以根据自己的喜好解释format_spec参数。例如,datetime模块中的类使用strftime()函数和它们的__format__方法中的相同格式代码。以下是使用format()内置函数和str.format()方法的几个示例:
>>> from datetime import datetime
>>> now = datetime.now()
>>> format(now, '%H:%M:%S')
'18:49:05'
>>> "It's now {:%I:%M %p}".format(now)
"It's now 06:49 PM"
如果一个类没有__format__,则从object继承的方法返回str(my_object)。因为Vector2d有一个__str__,所以这样可以:
>>> v1 = Vector2d(3, 4)
>>> format(v1)
'(3.0, 4.0)'
然而,如果传递了格式说明符,object.__format__会引发TypeError:
>>> format(v1, '.3f')
Traceback (most recent call last):...
TypeError: non-empty format string passed to object.__format__
我们将通过实现自己的格式迷你语言来解决这个问题。第一步是假设用户提供的格式说明符是用于格式化向量的每个float组件。这是我们想要的结果:
>>> v1 = Vector2d(3, 4)
>>> format(v1)
'(3.0, 4.0)'
>>> format(v1, '.2f')
'(3.00, 4.00)'
>>> format(v1, '.3e')
'(3.000e+00, 4.000e+00)'
示例 11-5 实现了__format__以产生刚才显示的内容。
示例 11-5. Vector2d.__format__ 方法,第一部分
# inside the Vector2d classdef __format__(self, fmt_spec=''):components = (format(c, fmt_spec) for c in self) # ①return '({}, {})'.format(*components) # ②
①
使用内置的format应用fmt_spec到每个向量组件,构建格式化字符串的可迭代对象。
②
将格式化字符串插入公式'(x, y)'中。
现在让我们向我们的迷你语言添加自定义格式代码:如果格式说明符以'p'结尾,我们将以极坐标形式显示向量:<r, θ>,其中r是幅度,θ(theta)是弧度角。格式说明符的其余部分(在'p'之前的任何内容)将像以前一样使用。
提示
在选择自定义格式代码的字母时,我避免与其他类型使用的代码重叠。在格式规范迷你语言中,我们看到整数使用代码'bcdoxXn',浮点数使用'eEfFgGn%',字符串使用's'。因此,我选择了'p'来表示极坐标。因为每个类都独立解释这些代码,所以在新类型的自定义格式中重用代码字母不是错误,但可能会让用户感到困惑。
要生成极坐标,我们已经有了用于幅度的__abs__方法,我们将使用math.atan2()函数编写一个简单的angle方法来获取角度。这是代码:
# inside the Vector2d classdef angle(self):return math.atan2(self.y, self.x)
有了这个,我们可以增强我们的__format__以生成极坐标。参见示例 11-6。
示例 11-6. Vector2d.__format__ 方法,第二部分,现在包括极坐标
def __format__(self, fmt_spec=''):if fmt_spec.endswith('p'): # ①fmt_spec = fmt_spec[:-1] # ②coords = (abs(self), self.angle()) # ③outer_fmt = '<{}, {}>' # ④else:coords = self # ⑤outer_fmt = '({}, {})' # ⑥components = (format(c, fmt_spec) for c in coords) # ⑦return outer_fmt.format(*components) # ⑧
①
格式以'p'结尾:使用极坐标。
②
从fmt_spec中删除'p'后缀。
③
构建极坐标的tuple:(magnitude, angle)。
④
用尖括号配置外部格式。
⑤
否则,使用self的x, y组件作为直角坐标。
⑥
用括号配置外部格式。
⑦
生成组件格式化字符串的可迭代对象。
⑧
将格式化字符串插入外部格式。
通过示例 11-6,我们得到类似于以下结果:
>>> format(Vector2d(1, 1), 'p')
'<1.4142135623730951, 0.7853981633974483>'
>>> format(Vector2d(1, 1), '.3ep')
'<1.414e+00, 7.854e-01>'
>>> format(Vector2d(1, 1), '0.5fp')
'<1.41421, 0.78540>'
正如本节所示,扩展格式规范迷你语言以支持用户定义的类型并不困难。
现在让我们转向一个不仅仅关于外观的主题:我们将使我们的Vector2d可散列,这样我们就可以构建向量集,或者将它们用作dict键。
一个可散列的 Vector2d
截至目前,我们的Vector2d实例是不可散列的,因此我们无法将它们放入set中:
>>> v1 = Vector2d(3, 4)
>>> hash(v1)
Traceback (most recent call last):...
TypeError: unhashable type: 'Vector2d'
>>> set([v1])
Traceback (most recent call last):...
TypeError: unhashable type: 'Vector2d'
要使Vector2d可散列,我们必须实现__hash__(__eq__也是必需的,我们已经有了)。我们还需要使向量实例不可变,正如我们在“什么是可散列”中看到的。
现在,任何人都可以执行v1.x = 7,而代码中没有任何提示表明更改Vector2d是被禁止的。这是我们想要的行为:
>>> v1.x, v1.y
(3.0, 4.0)
>>> v1.x = 7
Traceback (most recent call last):...
AttributeError: can't set attribute
我们将通过在示例 11-7 中使x和y组件成为只读属性来实现这一点。
示例 11-7. vector2d_v3.py:仅显示使Vector2d成为不可变的更改;在示例 11-11 中查看完整清单
class Vector2d:typecode = 'd'def __init__(self, x, y):self.__x = float(x) # ①self.__y = float(y)@property # ②def x(self): # ③return self.__x # ④@property # ⑤def y(self):return self.__ydef __iter__(self):return (i for i in (self.x, self.y)) # ⑥# remaining methods: same as previous Vector2d
①
使用正好两个前导下划线(零个或一个尾随下划线)使属性私有化。⁶
②
@property装饰器标记属性的 getter 方法。
③
getter 方法的名称与其公共属性相对应:x。
④
只需返回self.__x。
⑤
重复相同的公式用于y属性。
⑥
每个仅读取x、y分量的方法都可以保持原样,通过self.x和self.y读取公共属性而不是私有属性,因此此列表省略了类的其余代码。
注意
Vector.x和Vector.y是只读属性的示例。读/写属性将在第二十二章中介绍,我们将深入探讨@property。
现在,我们的向量相对安全免受意外变异,我们可以实现__hash__方法。它应返回一个int,理想情况下应考虑在__eq__方法中也使用的对象属性的哈希值,因为比较相等的对象应具有相同的哈希值。__hash__特殊方法的文档建议计算一个包含组件的元组的哈希值,这就是我们在示例 11-8 中所做的。
示例 11-8。vector2d_v3.py:hash的实现
# inside class Vector2d:def __hash__(self):return hash((self.x, self.y))
通过添加__hash__方法,我们现在有了可散列的向量:
>>> v1 = Vector2d(3, 4)
>>> v2 = Vector2d(3.1, 4.2)
>>> hash(v1), hash(v2)
(1079245023883434373, 1994163070182233067)
>>> {v1, v2}
{Vector2d(3.1, 4.2), Vector2d(3.0, 4.0)}
提示
实现属性或以其他方式保护实例属性以创建可散列类型并不是绝对必要的。正确实现__hash__和__eq__就足够了。但是,可散列对象的值永远不应更改,因此这提供了一个很好的借口来谈论只读属性。
如果您正在创建具有合理标量数值的类型,还可以实现__int__和__float__方法,这些方法由int()和float()构造函数调用,在某些情况下用于类型强制转换。还有一个__complex__方法来支持complex()内置构造函数。也许Vector2d应该提供__complex__,但我会把这留给你作为一个练习。
支持位置模式匹配
到目前为止,Vector2d实例与关键字类模式兼容——在“关键字类模式”中介绍。
在示例 11-9 中,所有这些关键字模式都按预期工作。
示例 11-9。Vector2d主题的关键字模式——需要 Python 3.10
def keyword_pattern_demo(v: Vector2d) -> None:match v:case Vector2d(x=0, y=0):print(f'{v!r} is null')case Vector2d(x=0):print(f'{v!r} is vertical')case Vector2d(y=0):print(f'{v!r} is horizontal')case Vector2d(x=x, y=y) if x==y:print(f'{v!r} is diagonal')case _:print(f'{v!r} is awesome')
但是,如果您尝试使用这样的位置模式:
case Vector2d(_, 0):print(f'{v!r} is horizontal')
你会得到:
TypeError: Vector2d() accepts 0 positional sub-patterns (1 given)
要使Vector2d与位置模式配合使用,我们需要添加一个名为__match_args__的类属性,按照它们将用于位置模式匹配的顺序列出实例属性:
class Vector2d:__match_args__ = ('x', 'y')# etc...
现在,当编写用于匹配Vector2d主题的模式时,我们可以节省一些按键,如您在示例 11-10 中所见。
示例 11-10。Vector2d主题的位置模式——需要 Python 3.10
def positional_pattern_demo(v: Vector2d) -> None:match v:case Vector2d(0, 0):print(f'{v!r} is null')case Vector2d(0):print(f'{v!r} is vertical')case Vector2d(_, 0):print(f'{v!r} is horizontal')case Vector2d(x, y) if x==y:print(f'{v!r} is diagonal')case _:print(f'{v!r} is awesome')
__match_args__类属性不需要包括所有公共实例属性。特别是,如果类__init__具有分配给实例属性的必需和可选参数,可能合理地在__match_args__中命名必需参数,但不包括可选参数。
让我们退后一步,回顾一下我们到目前为止在Vector2d中编码的内容。
Vector2d 的完整列表,版本 3
我们已经在Vector2d上工作了一段时间,只展示了一些片段,因此示例 11-11 是vector2d_v3.py的综合完整列表,包括我在开发时使用的 doctests。
示例 11-11。vector2d_v3.py:完整的版本
"""
A two-dimensional vector class>>> v1 = Vector2d(3, 4)>>> print(v1.x, v1.y)3.0 4.0>>> x, y = v1>>> x, y(3.0, 4.0)>>> v1Vector2d(3.0, 4.0)>>> v1_clone = eval(repr(v1))>>> v1 == v1_cloneTrue>>> print(v1)(3.0, 4.0)>>> octets = bytes(v1)>>> octetsb'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'>>> abs(v1)5.0>>> bool(v1), bool(Vector2d(0, 0))(True, False)Test of ``.frombytes()`` class method:>>> v1_clone = Vector2d.frombytes(bytes(v1))>>> v1_cloneVector2d(3.0, 4.0)>>> v1 == v1_cloneTrueTests of ``format()`` with Cartesian coordinates:>>> format(v1)'(3.0, 4.0)'>>> format(v1, '.2f')'(3.00, 4.00)'>>> format(v1, '.3e')'(3.000e+00, 4.000e+00)'Tests of the ``angle`` method::>>> Vector2d(0, 0).angle()0.0>>> Vector2d(1, 0).angle()0.0>>> epsilon = 10**-8>>> abs(Vector2d(0, 1).angle() - math.pi/2) < epsilonTrue>>> abs(Vector2d(1, 1).angle() - math.pi/4) < epsilonTrueTests of ``format()`` with polar coordinates:>>> format(Vector2d(1, 1), 'p') # doctest:+ELLIPSIS'<1.414213..., 0.785398...>'>>> format(Vector2d(1, 1), '.3ep')'<1.414e+00, 7.854e-01>'>>> format(Vector2d(1, 1), '0.5fp')'<1.41421, 0.78540>'Tests of `x` and `y` read-only properties:>>> v1.x, v1.y(3.0, 4.0)>>> v1.x = 123Traceback (most recent call last):...AttributeError: can't set attribute 'x'Tests of hashing:>>> v1 = Vector2d(3, 4)>>> v2 = Vector2d(3.1, 4.2)>>> len({v1, v2})2"""from array import array
import mathclass Vector2d:__match_args__ = ('x', 'y')typecode = 'd'def __init__(self, x, y):self.__x = float(x)self.__y = float(y)@propertydef x(self):return self.__x@propertydef y(self):return self.__ydef __iter__(self):return (i for i in (self.x, self.y))def __repr__(self):class_name = type(self).__name__return '{}({!r}, {!r})'.format(class_name, *self)def __str__(self):return str(tuple(self))def __bytes__(self):return (bytes([ord(self.typecode)]) +bytes(array(self.typecode, self)))def __eq__(self, other):return tuple(self) == tuple(other)def __hash__(self):return hash((self.x, self.y))def __abs__(self):return math.hypot(self.x, self.y)def __bool__(self):return bool(abs(self))def angle(self):return math.atan2(self.y, self.x)def __format__(self, fmt_spec=''):if fmt_spec.endswith('p'):fmt_spec = fmt_spec[:-1]coords = (abs(self), self.angle())outer_fmt = '<{}, {}>'else:coords = selfouter_fmt = '({}, {})'components = (format(c, fmt_spec) for c in coords)return outer_fmt.format(*components)@classmethoddef frombytes(cls, octets):typecode = chr(octets[0])memv = memoryview(octets[1:]).cast(typecode)return cls(*memv)
总结一下,在本节和前几节中,我们看到了一些您可能希望实现以拥有完整对象的基本特殊方法。
注意
只有在您的应用程序需要时才实现这些特殊方法。最终用户不在乎构成应用程序的对象是否“Pythonic”。
另一方面,如果您的类是其他 Python 程序员使用的库的一部分,您实际上无法猜测他们将如何处理您的对象,他们可能期望我们正在描述的更多“Pythonic”行为。
如示例 11-11 中所编码的,Vector2d是一个关于对象表示相关特殊方法的教学示例,而不是每个用户定义类的模板。
在下一节中,我们将暂时离开Vector2d,讨论 Python 中私有属性机制的设计和缺点——self.__x中的双下划线前缀。
Python 中的私有和“受保护”的属性
在 Python 中,没有像 Java 中的private修饰符那样创建私有变量的方法。在 Python 中,我们有一个简单的机制来防止在子类中意外覆盖“私有”属性。
考虑这种情况:有人编写了一个名为Dog的类,其中内部使用了一个mood实例属性,但没有暴露它。你需要将Dog作为Beagle的子类。如果你在不知道名称冲突的情况下创建自己的mood实例属性,那么你将覆盖从Dog继承的方法中使用的mood属性。这将是一个令人头疼的调试问题。
为了防止这种情况发生,如果你将一个实例属性命名为__mood(两个前导下划线和零个或最多一个尾随下划线),Python 会将该名称存储在实例__dict__中,前缀是一个前导下划线和类名,因此在Dog类中,__mood变成了_Dog__mood,而在Beagle中变成了_Beagle__mood。这种语言特性被称为名称修饰。
示例 11-12 展示了来自示例 11-7 中Vector2d类的结果。
示例 11-12. 私有属性名称通过前缀_和类名“修饰”
>>> v1 = Vector2d(3, 4)
>>> v1.__dict__
{'_Vector2d__y': 4.0, '_Vector2d__x': 3.0}
>>> v1._Vector2d__x
3.0
名称修饰是关于安全性,而不是安全性:它旨在防止意外访问,而不是恶意窥探。图 11-1 展示了另一个安全设备。
知道私有名称是如何被修饰的人可以直接读取私有属性,就像示例 11-12 的最后一行所示的那样——这对调试和序列化实际上是有用的。他们还可以通过编写v1._Vector2d__x = 7来直接为Vector2d的私有组件赋值。但如果你在生产代码中这样做,如果出现问题,就不能抱怨了。
名称修饰功能并不受所有 Python 爱好者的喜爱,以及写作为self.__x的名称的倾斜外观也不受欢迎。一些人更喜欢避免这种语法,只使用一个下划线前缀通过约定“保护”属性(例如,self._x)。对于自动双下划线修饰的批评者,他们建议通过命名约定来解决意外属性覆盖的问题。Ian Bicking——pip、virtualenv 等项目的创建者写道:
永远不要使用两个前导下划线。这是非常私有的。如果担心名称冲突,可以使用显式的名称修饰(例如,
_MyThing_blahblah)。这与双下划线基本相同,只是双下划线会隐藏,而显式名称修饰则是透明的。⁷

图 11-1. 开关上的盖子是一个安全设备,而不是安全设备:它防止事故,而不是破坏。
单个下划线前缀在属性名称中对 Python 解释器没有特殊含义,但在 Python 程序员中是一个非常强烈的约定,你不应该从类外部访问这样的属性。⁸。尊重一个将其属性标记为单个下划线的对象的隐私是很容易的,就像尊重将ALL_CAPS中的变量视为常量的约定一样容易。
在 Python 文档的某些角落中,带有单个下划线前缀的属性被称为“受保护的”⁹。通过约定以self._x的形式“保护”属性的做法很普遍,但将其称为“受保护的”属性并不那么常见。有些人甚至将其称为“私有”属性。
总之:Vector2d的组件是“私有的”,我们的Vector2d实例是“不可变的”——带有引号——因为没有办法使它们真正私有和不可变。¹⁰
现在我们回到我们的Vector2d类。在下一节中,我们将介绍一个特殊的属性(不是方法),它会影响对象的内部存储,对内存使用可能有巨大影响,但对其公共接口影响很小:__slots__。
使用__slots__节省内存
默认情况下,Python 将每个实例的属性存储在名为__dict__的dict中。正如我们在“dict 工作原理的实际后果”中看到的,dict具有显着的内存开销——即使使用了该部分提到的优化。但是,如果你定义一个名为__slots__的类属性,其中包含一系列属性名称,Python 将使用替代的存储模型来存储实例属性:__slots__中命名的属性存储在一个隐藏的引用数组中,使用的内存比dict少。让我们通过简单的示例来看看它是如何工作的,从示例 11-13 开始。
示例 11-13。Pixel类使用__slots__
>>> class Pixel:
... __slots__ = ('x', 'y') # ①
...
>>> p = Pixel() # ②
>>> p.__dict__ # ③
Traceback (most recent call last):...
AttributeError: 'Pixel' object has no attribute '__dict__'
>>> p.x = 10 # ④
>>> p.y = 20
>>> p.color = 'red' # ⑤
Traceback (most recent call last):...
AttributeError: 'Pixel' object has no attribute 'color'
①
在创建类时必须存在__slots__;稍后添加或更改它没有效果。属性名称可以是tuple或list,但我更喜欢tuple,以明确表明没有改变的必要。
②
创建一个Pixel的实例,因为我们看到__slots__对实例的影响。
③
第一个效果:Pixel的实例没有__dict__。
④
正常设置p.x和p.y属性。
⑤
第二个效果:尝试设置一个未在__slots__中列出的属性会引发AttributeError。
到目前为止,一切顺利。现在让我们在示例 11-14 中创建Pixel的一个子类,看看__slots__的反直觉之处。
示例 11-14。OpenPixel是Pixel的子类
>>> class OpenPixel(Pixel): # ①
... pass
...
>>> op = OpenPixel()
>>> op.__dict__ # ②
{} >>> op.x = 8 # ③
>>> op.__dict__ # ④
{} >>> op.x # ⑤
8 >>> op.color = 'green' # ⑥
>>> op.__dict__ # ⑦
{'color': 'green'}
①
OpenPixel没有声明自己的属性。
②
惊喜:OpenPixel的实例有一个__dict__。
③
如果你设置属性x(在基类Pixel的__slots__中命名)…
④
…它不存储在实例__dict__中…
⑤
…但它存储在实例的隐藏引用数组中。
⑥
如果你设置一个未在__slots__中命名的属性…
⑦
…它存储在实例__dict__中。
示例 11-14 显示了__slots__的效果只被子类部分继承。为了确保子类的实例没有__dict__,你必须在子类中再次声明__slots__。
如果你声明__slots__ = ()(一个空元组),那么子类的实例将没有__dict__,并且只接受基类__slots__中命名的属性。
如果你希望子类具有额外的属性,请在__slots__中命名它们,就像示例 11-15 中所示的那样。
示例 11-15。ColorPixel,Pixel的另一个子类
>>> class ColorPixel(Pixel):
... __slots__ = ('color',) # ①
>>> cp = ColorPixel()
>>> cp.__dict__ # ②
Traceback (most recent call last):...
AttributeError: 'ColorPixel' object has no attribute '__dict__'
>>> cp.x = 2
>>> cp.color = 'blue' # ③
>>> cp.flavor = 'banana'
Traceback (most recent call last):...
AttributeError: 'ColorPixel' object has no attribute 'flavor'
①
本质上,超类的__slots__被添加到当前类的__slots__中。不要忘记单项元组必须有一个尾随逗号。
②
ColorPixel实例没有__dict__。
③
你可以设置此类和超类的__slots__中声明的属性,但不能设置其他属性。
“既能节省内存又能使用它”是可能的:如果将'__dict__'名称添加到__slots__列表中,那么你的实例将保留__slots__中命名的属性在每个实例的引用数组中,但也将支持动态创建的属性,这些属性将存储在通常的__dict__中。如果你想要使用@cached_property装饰器(在“第 5 步:使用 functools 缓存属性”中介绍),这是必要的。
当然,在__slots__中有'__dict__'可能完全打败它的目的,这取决于每个实例中静态和动态属性的数量以及它们的使用方式。粗心的优化比过早的优化更糟糕:你增加了复杂性,但可能得不到任何好处。
另一个你可能想要保留的特殊每实例属性是__weakref__,这对于对象支持弱引用是必要的(在“del 和垃圾回收”中简要提到)。该属性默认存在于用户定义类的实例中。但是,如果类定义了__slots__,并且你需要实例成为弱引用的目标,则需要在__slots__中包含'__weakref__'。
现在让我们看看将__slots__添加到Vector2d的效果。
简单的槽节省度量
示例 11-16 展示了在Vector2d中实现__slots__。
示例 11-16. vector2d_v3_slots.py:__slots__属性是Vector2d的唯一添加
class Vector2d:__match_args__ = ('x', 'y') # ①__slots__ = ('__x', '__y') # ②typecode = 'd'# methods are the same as previous version
①
__match_args__列出了用于位置模式匹配的公共属性名称。
②
相比之下,__slots__列出了实例属性的名称,这些属性在这种情况下是私有属性。
为了测量内存节省,我编写了mem_test.py脚本。它接受一个带有Vector2d类变体的模块名称作为命令行参数,并使用列表推导式构建一个包含 10,000,000 个Vector2d实例的list。在示例 11-17 中显示的第一次运行中,我使用vector2d_v3.Vector2d(来自示例 11-7);在第二次运行中,我使用具有__slots__的版本,来自示例 11-16。
示例 11-17. mem_test.py 创建了 10 百万个Vector2d实例,使用了命名模块中定义的类
$ time python3 mem_test.py vector2d_v3
Selected Vector2d type: vector2d_v3.Vector2d
Creating 10,000,000 Vector2d instances
Initial RAM usage: 6,983,680Final RAM usage: 1,666,535,424real 0m11.990s
user 0m10.861s
sys 0m0.978s
$ time python3 mem_test.py vector2d_v3_slots
Selected Vector2d type: vector2d_v3_slots.Vector2d
Creating 10,000,000 Vector2d instances
Initial RAM usage: 6,995,968Final RAM usage: 577,839,104real 0m8.381s
user 0m8.006s
sys 0m0.352s
如示例 11-17 所示,当每个 10 百万个Vector2d实例中使用__dict__时,脚本的 RAM 占用量增长到了 1.55 GiB,但当Vector2d具有__slots__属性时,降低到了 551 MiB。__slots__版本也更快。这个测试中的mem_test.py脚本基本上处理加载模块、检查内存使用情况和格式化结果。你可以在fluentpython/example-code-2e存储库中找到它的源代码。
提示
如果你处理数百万个具有数值数据的对象,你应该真的使用 NumPy 数组(参见“NumPy”),它们不仅内存高效,而且具有高度优化的数值处理函数,其中许多函数一次操作整个数组。我设计Vector2d类只是为了在讨论特殊方法时提供背景,因为我尽量避免在可以的情况下使用模糊的foo和bar示例。
总结__slots__的问题
如果正确使用,__slots__类属性可能会提供显著的内存节省,但有一些注意事项:
-
你必须记得在每个子类中重新声明
__slots__,以防止它们的实例具有__dict__。 -
实例只能拥有
__slots__中列出的属性,除非在__slots__中包含'__dict__'(但这样做可能会抵消内存节省)。 -
使用
__slots__的类不能使用@cached_property装饰器,除非在__slots__中明确命名'__dict__'。 -
实例不能成为弱引用的目标,除非在
__slots__中添加'__weakref__'。
本章的最后一个主题涉及在实例和子类中覆盖类属性。
覆盖类属性
Python 的一个显著特点是类属性可以用作实例属性的默认值。在Vector2d中有typecode类属性。它在__bytes__方法中使用了两次,但我们设计上将其读取为self.typecode。因为Vector2d实例是在没有自己的typecode属性的情况下创建的,所以self.typecode将默认获取Vector2d.typecode类属性。
但是,如果写入一个不存在的实例属性,就会创建一个新的实例属性,例如,一个typecode实例属性,而同名的类属性则保持不变。但是,从那时起,每当处理该实例的代码读取self.typecode时,实例typecode将被检索,有效地遮蔽了同名的类属性。这打开了使用不同typecode自定义单个实例的可能性。
默认的Vector2d.typecode是'd',意味着每个向量分量在导出为bytes时将被表示为 8 字节的双精度浮点数。如果在导出之前将Vector2d实例的typecode设置为'f',则每个分量将以 4 字节的单精度浮点数导出。示例 11-18 演示了这一点。
注意
我们正在讨论添加自定义实例属性,因此示例 11-18 使用了没有__slots__的Vector2d实现,如示例 11-11 中所列。
示例 11-18。通过设置以前从类继承的typecode属性来自定义实例
>>> from vector2d_v3 import Vector2d
>>> v1 = Vector2d(1.1, 2.2)
>>> dumpd = bytes(v1)
>>> dumpd
b'd\x9a\x99\x99\x99\x99\x99\xf1?\x9a\x99\x99\x99\x99\x99\x01@' >>> len(dumpd) # ①
17 >>> v1.typecode = 'f' # ②
>>> dumpf = bytes(v1)
>>> dumpf
b'f\xcd\xcc\x8c?\xcd\xcc\x0c@' >>> len(dumpf) # ③
9 >>> Vector2d.typecode # ④
'd'
①](#co_a_pythonic_object_CO13-1)
默认的bytes表示长度为 17 字节。
②
在v1实例中将typecode设置为'f'。
③
现在bytes转储的长度为 9 字节。
④
Vector2d.typecode保持不变;只有v1实例使用typecode为'f'。
现在应该清楚为什么Vector2d的bytes导出以typecode为前缀:我们想要支持不同的导出格式。
如果要更改类属性,必须直接在类上设置,而不是通过实例。你可以通过以下方式更改所有实例(没有自己的typecode)的默认typecode:
>>> Vector2d.typecode = 'f'
然而,在 Python 中有一种惯用的方法可以实现更持久的效果,并且更明确地说明更改。因为类属性是公共的,它们会被子类继承,所以习惯上是通过子类来定制类数据属性。Django 类基视图广泛使用这种技术。示例 11-19 展示了如何实现。
示例 11-19。ShortVector2d是Vector2d的子类,只覆盖了默认的typecode
>>> from vector2d_v3 import Vector2d
>>> class ShortVector2d(Vector2d): # ①
... typecode = 'f'
...
>>> sv = ShortVector2d(1/11, 1/27) # ②
>>> sv
ShortVector2d(0.09090909090909091, 0.037037037037037035) # ③
>>> len(bytes(sv)) # ④
9
①
创建ShortVector2d作为Vector2d的子类,只是为了覆盖typecode类属性。
②
为演示构建ShortVector2d实例sv。
③
检查sv的repr。
④
检查导出字节的长度为 9,而不是之前的 17。
这个例子还解释了为什么我没有在Vector2d.__repr__中硬编码class_name,而是从type(self).__name__获取它,就像这样:
# inside class Vector2d:def __repr__(self):class_name = type(self).__name__return '{}({!r}, {!r})'.format(class_name, *self)
如果我在class_name中硬编码,Vector2d的子类如ShortVector2d将不得不覆盖__repr__以更改class_name。通过从实例的type中读取名称,我使__repr__更安全地继承。
我们结束了构建一个简单类的覆盖,利用数据模型与 Python 的其他部分协作:提供不同的对象表示,提供自定义格式代码,公开只读属性,并支持 hash() 以与集合和映射集成。
章节总结
本章的目的是演示在构建一个良好的 Python 类时使用特殊方法和约定。
vector2d_v3.py(在 示例 11-11 中显示)比 vector2d_v0.py(在 示例 11-2 中显示)更符合 Python 风格吗?vector2d_v3.py 中的 Vector2d 类显然展示了更多的 Python 特性。但是第一个或最后一个 Vector2d 实现是否合适取决于它将被使用的上下文。Tim Peter 的“Python 之禅”说:
简单胜于复杂。
对象应该尽可能简单,符合需求,而不是语言特性的大杂烩。如果代码是为了一个应用程序,那么它应该专注于支持最终用户所需的内容,而不是更多。如果代码是为其他程序员使用的库,那么实现支持 Python 程序员期望的特殊方法是合理的。例如,__eq__ 可能不是支持业务需求所必需的,但它使类更容易测试。
我在扩展 Vector2d 代码的目标是为了讨论 Python 特殊方法和编码约定提供背景。本章的示例演示了我们在 Table 1-1(第一章)中首次看到的几个特殊方法:
-
字符串/字节表示方法:
__repr__、__str__、__format__和__bytes__ -
将对象转换为数字的方法:
__abs__、__bool__和__hash__ -
__eq__运算符,用于支持测试和哈希(以及__hash__)
在支持转换为 bytes 的同时,我们还实现了一个替代构造函数 Vector2d.frombytes(),这为讨论装饰器 @classmethod(非常方便)和 @staticmethod(不太有用,模块级函数更简单)提供了背景。frombytes 方法受到了 array.array 类中同名方法的启发。
我们看到 格式规范迷你语言 可通过实现 __format__ 方法来扩展,该方法解析提供给 format(obj, format_spec) 内置函数或在 f-strings 中使用的替换字段 '{:«format_spec»}' 中的 format_spec。
为了使 Vector2d 实例可哈希,我们努力使它们是不可变的,至少通过将 x 和 y 属性编码为私有属性,然后将它们公开为只读属性来防止意外更改。然后,我们使用推荐的异或实例属性哈希的技术实现了 __hash__。
我们随后讨论了在 Vector2d 中声明 __slots__ 属性的内存节省和注意事项。因为使用 __slots__ 会产生副作用,所以只有在处理非常大量的实例时才是有意义的——考虑的是百万级的实例,而不仅仅是千个。在许多这种情况下,使用 pandas 可能是最佳选择。
我们讨论的最后一个主题是覆盖通过实例访问的类属性(例如,self.typecode)。我们首先通过创建实例属性,然后通过子类化和在类级别上重写来实现。
在整个章节中,我提到示例中的设计选择是通过研究标准 Python 对象的 API 而得出的。如果这一章可以用一句话总结,那就是:
要构建 Pythonic 对象,观察真实的 Python 对象的行为。
古老的中国谚语
进一步阅读
本章涵盖了数据模型的几个特殊方法,因此主要参考资料与第一章中提供的相同,该章节提供了相同主题的高层次视图。为方便起见,我将在此重复之前的四个推荐,并添加一些其他的:
Python 语言参考的“数据模型”章节
我们在本章中使用的大多数方法在“3.3.1.基本自定义”中有文档记录。
Python 速查手册, 第 3 版,作者 Alex Martelli, Anna Ravenscroft 和 Steve Holden
深入讨论了特殊方法。
Python 食谱, 第 3 版,作者 David Beazley 和 Brian K. Jones
通过示例演示了现代 Python 实践。特别是第八章“类和对象”中有几个与本章讨论相关的解决方案。
Python 基础参考, 第 4 版,作者 David Beazley
详细介绍了数据模型,即使只涵盖了 Python 2.6 和 3.0(在第四版中)。基本概念都是相同的,大多数数据模型 API 自 Python 2.2 以来都没有改变,当时内置类型和用户定义类被统一起来。
在 2015 年,我完成第一版流畅的 Python时,Hynek Schlawack 开始了attrs包。从attrs文档中:
attrs是 Python 包,通过解除你实现对象协议(也称为 dunder 方法)的繁琐,为编写类带来乐趣。
我在“进一步阅读”中提到attrs作为@dataclass的更强大替代品。来自第五章的数据类构建器以及attrs会自动为你的类配备几个特殊方法。但了解如何自己编写这些特殊方法仍然是必要的,以理解这些包的功能,决定是否真正需要它们,并在必要时覆盖它们生成的方法。
在本章中,我们看到了与对象表示相关的所有特殊方法,除了__index__和__fspath__。我们将在第十二章中讨论__index__,“一个切片感知的 getitem”。我不会涉及__fspath__。要了解更多信息,请参阅PEP 519—添加文件系统路径协议。
早期意识到对象需要不同的字符串表示的需求出现在 Smalltalk 中。1996 年 Bobby Woolf 的文章“如何将对象显示为字符串:printString 和 displayString”讨论了该语言中printString和displayString方法的实现。从那篇文章中,我借用了“开发者想要看到的方式”和“用户想要看到的方式”这两个简洁的描述,用于定义repr()和str()在“对象表示”中。
¹ 来自 Faassen 的博客文章“什么是 Pythonic?”
² 我在这里使用eval来克隆对象只是为了说明repr;要克隆一个实例,copy.copy函数更安全更快。
³ 这一行也可以写成yield self.x; yield.self.y。关于__iter__特殊方法、生成器表达式和yield关键字,我在第十七章中还有很多要说。
⁴ 我们在“内存视图”中简要介绍了memoryview,解释了它的.cast方法。
⁵ 本书的技术审阅员之一 Leonardo Rochael 不同意我对 staticmethod 的低评价,并推荐 Julien Danjou 的博文“如何在 Python 中使用静态、类或抽象方法的权威指南”作为反驳意见。Danjou 的文章非常好;我推荐它。但这并不足以改变我的对 staticmethod 的看法。你需要自己决定。
⁶ 私有属性的利弊是即将到来的“Python 中的私有和‘受保护’属性”的主题。
⁷ 来自“粘贴风格指南”。
⁸ 在模块中,顶层名称前的单个 _ 确实有影响:如果你写 from mymod import *,带有 _ 前缀的名称不会从 mymod 中导入。然而,你仍然可以写 from mymod import _privatefunc。这在Python 教程,第 6.1 节,“关于模块的更多内容”中有解释。
⁹ 一个例子在gettext 模块文档中。
¹⁰ 如果这种情况让你沮丧,并且让你希望 Python 在这方面更像 Java,那就不要阅读我对 Java private 修饰符相对强度的讨论,见“Soapbox”。
¹¹ 参见“可能的最简单的工作方式:与沃德·坎宁安的对话,第五部分”。
第十二章:序列的特殊方法
不要检查它是否是一只鸭子:检查它是否像一只鸭子一样嘎嘎叫,走路,等等,具体取决于你需要与之进行语言游戏的鸭子行为子集。(
comp.lang.python,2000 年 7 月 26 日)Alex Martelli
在本章中,我们将创建一个表示多维Vector类的类——这是从第十一章的二维Vector2d中迈出的重要一步。Vector将表现得像一个标准的 Python 不可变的扁平序列。它的元素将是浮点数,并且在本章结束时将支持以下功能:
-
基本序列协议:
__len__和__getitem__ -
安全表示具有许多项目的实例
-
适当的切片支持,生成新的
Vector实例 -
聚合哈希,考虑每个包含元素的值
-
自定义格式化语言扩展
我们还将使用__getattr__实现动态属性访问,以替换我们在Vector2d中使用的只读属性——尽管这不是序列类型的典型做法。
代码密集的展示将被一个关于协议作为非正式接口的概念讨论所打断。我们将讨论协议和鸭子类型的关系,以及当你创建自己的类型时的实际影响。
本章的新内容
本章没有重大变化。在“协议和鸭子类型”末尾附近的提示框中有一个新的typing.Protocol的简短讨论。
在“一个切片感知的 getitem”中,示例 12-6 中__getitem__的实现比第一版更简洁和健壮,这要归功于鸭子类型和operator.index。这种变化延续到了本章和第十六章中对Vector的后续实现。
让我们开始吧。
Vector:用户定义的序列类型
我们实现Vector的策略将是使用组合,而不是继承。我们将把分量存储在一个浮点数的数组中,并将实现Vector所需的方法,使其表现得像一个不可变的扁平序列。
但在我们实现序列方法之前,让我们确保我们有一个基线实现的Vector,它与我们先前的Vector2d类兼容——除非这种兼容性没有意义。
Vector 第一版:与 Vector2d 兼容
Vector的第一个版本应尽可能与我们先前的Vector2d类兼容。
但是,按设计,Vector构造函数与Vector2d构造函数不兼容。我们可以通过在__init__中使用*args来接受任意数量的参数使Vector(3, 4)和Vector(3, 4, 5)起作用,但是序列构造函数的最佳实践是在构造函数中将数据作为可迭代参数接受,就像所有内置序列类型一样。示例 12-1 展示了实例化我们新的Vector对象的一些方法。
示例 12-1。Vector.__init__和Vector.__repr__的测试
>>> Vector([3.1, 4.2])
Vector([3.1, 4.2])
>>> Vector((3, 4, 5))
Vector([3.0, 4.0, 5.0])
>>> Vector(range(10))
Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...])
除了一个新的构造函数签名外,我确保了我对Vector2d(例如,Vector2d(3, 4))进行的每个测试都通过并产生了与两个分量Vector([3, 4])相同的结果。
警告
当一个Vector有超过六个分量时,repr()产生的字符串会被缩写为...,就像在示例 12-1 的最后一行中看到的那样。这在可能包含大量项目的任何集合类型中至关重要,因为repr用于调试,你不希望一个大对象在控制台或日志中跨越数千行。使用reprlib模块生成有限长度的表示,就像示例 12-2 中那样。reprlib模块在 Python 2.7 中被命名为repr。
示例 12-2 列出了我们第一个版本的Vector的实现(此示例基于示例 11-2 和 11-3 中显示的代码)。
示例 12-2. vector_v1.py:派生自 vector2d_v1.py
from array import array
import reprlib
import mathclass Vector:typecode = 'd'def __init__(self, components):self._components = array(self.typecode, components) # ①def __iter__(self):return iter(self._components) # ②def __repr__(self):components = reprlib.repr(self._components) # ③components = components[components.find('['):-1] # ④return f'Vector({components})'def __str__(self):return str(tuple(self))def __bytes__(self):return (bytes([ord(self.typecode)]) +bytes(self._components)) # ⑤def __eq__(self, other):return tuple(self) == tuple(other)def __abs__(self):return math.hypot(*self) # ⑥def __bool__(self):return bool(abs(self))@classmethoddef frombytes(cls, octets):typecode = chr(octets[0])memv = memoryview(octets[1:]).cast(typecode)return cls(memv) # ⑦
①
self._components实例“受保护”的属性将保存带有Vector组件的array。
②
为了允许迭代,我们返回一个self._components上的迭代器。¹
③
使用reprlib.repr()获取self._components的有限长度表示(例如,array('d', [0.0, 1.0, 2.0, 3.0, 4.0, ...]))。
④
在将字符串插入Vector构造函数调用之前,删除array('d',前缀和尾随的)。
⑤
直接从self._components构建一个bytes对象。
⑥
自 Python 3.8 起,math.hypot接受 N 维点。我之前使用过这个表达式:math.sqrt(sum(x * x for x in self))。
⑦
与之前的frombytes唯一需要更改的地方在于最后一行:我们直接将memoryview传递给构造函数,而不像之前那样使用*进行解包。
我使用reprlib.repr的方式值得一提。该函数通过限制输出字符串的长度并用'...'标记截断来生成大型或递归结构的安全表示。我希望Vector的repr看起来像Vector([3.0, 4.0, 5.0])而不是Vector(array('d', [3.0, 4.0, 5.0])),因为Vector内部有一个array是一个实现细节。因为这些构造函数调用构建了相同的Vector对象,我更喜欢使用带有list参数的更简单的语法。
在编写__repr__时,我本可以使用这个表达式生成简化的components显示:reprlib.repr(list(self._components))。然而,这样做是浪费的,因为我需要将每个项从self._components复制到一个list中,只是为了使用list的repr。相反,我决定直接将reprlib.repr应用于self._components数组,并在[]之外截断字符。这就是示例 12-2 中__repr__的第二行所做的事情。
提示
由于在调试中的作用,对对象调用repr()不应引发异常。如果在__repr__的实现中出现问题,您必须处理该问题,并尽力产生一些可用的输出,以便用户有机会识别接收者(self)。
请注意,__str__、__eq__和__bool__方法与Vector2d中保持不变,frombytes中只有一个字符发生了变化(最后一行删除了一个*)。这是使原始Vector2d可迭代的好处之一。
顺便说一句,我们本可以从Vector2d中派生Vector,但出于两个原因我选择不这样做。首先,不兼容的构造函数确实使得子类化不可取。我可以通过在__init__中进行一些巧妙的参数处理来解决这个问题,但第二个原因更重要:我希望Vector是一个独立的实现序列协议的类的示例。这就是我们接下来要做的事情,在讨论术语协议之后。
协议和鸭子类型
早在第一章中,我们就看到在 Python 中创建一个完全功能的序列类型并不需要继承任何特殊类;你只需要实现满足序列协议的方法。但我们在谈论什么样的协议呢?
在面向对象编程的上下文中,协议是一种非正式接口,仅在文档中定义,而不在代码中定义。例如,在 Python 中,序列协议仅包括__len__和__getitem__方法。任何实现这些方法的类Spam,具有标准签名和语义,都可以在期望序列的任何地方使用。Spam是这个或那个的子类无关紧要;重要的是它提供了必要的方法。我们在示例 1-1 中看到了这一点,在示例 12-3 中重现。
示例 12-3。示例 1-1 中的代码,这里为方便起见重现
import collectionsCard = collections.namedtuple('Card', ['rank', 'suit'])class FrenchDeck:ranks = [str(n) for n in range(2, 11)] + list('JQKA')suits = 'spades diamonds clubs hearts'.split()def __init__(self):self._cards = [Card(rank, suit) for suit in self.suitsfor rank in self.ranks]def __len__(self):return len(self._cards)def __getitem__(self, position):return self._cards[position]
示例 12-3 中的FrenchDeck类利用了许多 Python 的功能,因为它实现了序列协议,即使在代码中没有声明。有经验的 Python 编程人员会查看它并理解它是一个序列,即使它是object的子类。我们说它是一个序列,因为它行为像一个序列,这才是重要的。
这被称为鸭子类型,源自亚历克斯·马特利在本章开头引用的帖子。
因为协议是非正式且不受强制执行的,所以如果您知道类将被使用的特定上下文,通常可以只实现协议的一部分。例如,为了支持迭代,只需要__getitem__;不需要提供__len__。
提示
使用PEP 544—Protocols: Structural subtyping (static duck typing),Python 3.8 支持协议类:typing构造,我们在“静态协议”中学习过。Python 中这个新用法的“协议”一词具有相关但不同的含义。当我需要区分它们时,我会写静态协议来指代协议类中规范化的协议,而动态协议则指传统意义上的协议。一个关键区别是静态协议实现必须提供协议类中定义的所有方法。第十三章的“两种协议”有更多细节。
我们现在将在Vector中实现序列协议,最初没有适当的切片支持,但稍后会添加。
Vector 第二版:可切片序列
正如我们在FrenchDeck示例中看到的,如果您可以将对象中的序列属性委托给一个序列属性,比如我们的self._components数组,那么支持序列协议就非常容易。这些__len__和__getitem__一行代码是一个很好的开始:
class Vector:# many lines omitted# ...def __len__(self):return len(self._components)def __getitem__(self, index):return self._components[index]
有了这些补充,现在所有这些操作都可以正常工作:
>>> v1 = Vector([3, 4, 5])
>>> len(v1)
3
>>> v1[0], v1[-1]
(3.0, 5.0)
>>> v7 = Vector(range(7))
>>> v7[1:4]
array('d', [1.0, 2.0, 3.0])
如您所见,即使支持切片,但并不是很好。如果Vector的切片也是Vector实例而不是array,那将更好。旧的FrenchDeck类也有类似的问题:当您对其进行切片时,会得到一个list。在Vector的情况下,当切片产生普通数组时,会丢失很多功能。
考虑内置序列类型:每一个,在切片时,都会产生自己类型的新实例,而不是其他类型的实例。
要使Vector生成Vector实例作为切片,我们不能简单地将切片委托给array。我们需要分析在__getitem__中获得的参数并做正确的事情。
现在,让我们看看 Python 如何将语法my_seq[1:3]转换为my_seq.__getitem__(...)的参数。
切片的工作原理
一个示例胜过千言万语,所以看看示例 12-4。
示例 12-4。检查__getitem__和切片的行为
>>> class MySeq:
... def __getitem__(self, index):
... return index # ①
...
>>> s = MySeq()
>>> s[1] # ②
1 >>> s[1:4] # ③
slice(1, 4, None) >>> s[1:4:2] # ④
slice(1, 4, 2) >>> s[1:4:2, 9] # ⑤
(slice(1, 4, 2), 9) >>> s[1:4:2, 7:9] # ⑥
(slice(1, 4, 2), slice(7, 9, None))
①
对于这个演示,__getitem__只是返回传递给它的任何内容。
②
单个索引,没什么新鲜事。
③
表示1:4变为slice(1, 4, None)。
④
slice(1, 4, 2)意味着从 1 开始,到 4 结束,步长为 2。
⑤
惊喜:[]内部有逗号意味着__getitem__接收到一个元组。
⑥
元组甚至可以包含多个slice对象。
现在让我们更仔细地看看slice本身在示例 12-5 中。
示例 12-5。检查slice类的属性
>>> slice # ①
<class 'slice'> >>> dir(slice) # ②
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__','__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'indices', 'start', 'step', 'stop']
①
slice是一个内置类型(我们在“切片对象”中首次看到它)。
②
检查一个slice,我们发现数据属性start、stop和step,以及一个indices方法。
在示例 12-5 中调用dir(slice)会显示一个indices属性,这个属性实际上是一个非常有趣但鲜为人知的方法。以下是help(slice.indices)的内容:
S.indices(len) -> (start, stop, stride)
假设长度为len的序列,计算由S描述的扩展切片的start和stop索引以及stride长度。超出边界的索引会像在正常切片中一样被截断。
换句话说,indices暴露了内置序列中实现的复杂逻辑,以优雅地处理缺失或负索引以及比原始序列长的切片。这个方法生成针对给定长度序列的非负start、stop和stride整数的“标准化”元组。
这里有几个例子,考虑一个长度为len == 5的序列,例如,'ABCDE':
>>> slice(None, 10, 2).indices(5) # ①
(0, 5, 2) >>> slice(-3, None, None).indices(5) # ②
(2, 5, 1)
①
'ABCDE'[:10:2]等同于'ABCDE'[0:5:2]。
②
'ABCDE'[-3:]等同于'ABCDE'[2:5:1]。
在我们的Vector代码中,我们不需要使用slice.indices()方法,因为当我们得到一个切片参数时,我们将把它的处理委托给_components数组。但是如果你不能依赖底层序列的服务,这个方法可以节省大量时间。
现在我们知道如何处理切片了,让我们看看改进的Vector.__getitem__实现。
一个了解切片的__getitem__
示例 12-6 列出了使Vector表现为序列所需的两个方法:__len__和__getitem__(后者现在已实现以正确处理切片)。
示例 12-6。vector_v2.py 的一部分:向Vector类添加了__len__和__getitem__方法,这些方法来自 vector_v1.py(参见示例 12-2)
def __len__(self):return len(self._components)def __getitem__(self, key):if isinstance(key, slice): # ①cls = type(self) # ②return cls(self._components[key]) # ③index = operator.index(key) # ④return self._components[index] # ⑤
①
如果key参数是一个slice…
②
…获取实例的类(即Vector)并…
③
…调用该类以从_components数组的切片构建另一个Vector实例。
④
如果我们可以从key中得到一个index…
⑤
…返回_components中的特定项。
operator.index()函数调用__index__特殊方法。该函数和特殊方法在PEP 357—允许任何对象用于切片中定义,由 Travis Oliphant 提出,允许 NumPy 中的众多整数类型用作索引和切片参数。operator.index()和int()之间的关键区别在于前者是为此特定目的而设计的。例如,int(3.14)返回3,但operator.index(3.14)会引发TypeError,因为float不应该用作索引。
注意
过度使用isinstance可能是糟糕的面向对象设计的迹象,但在__getitem__中处理切片是一个合理的用例。在第一版中,我还对key进行了isinstance测试,以测试它是否为整数。使用operator.index避免了这个测试,并且如果无法从key获取index,则会引发带有非常详细信息的TypeError。请参见示例 12-7 中的最后一个错误消息。
一旦将示例 12-6 中的代码添加到Vector类中,我们就具有了适当的切片行为,正如示例 12-7 所示。
示例 12-7。增强的Vector.__getitem__的测试,来自示例 12-6
>>> v7 = Vector(range(7)) >>> v7[-1] # ①6.0 >>> v7[1:4] # ②Vector([1.0, 2.0, 3.0]) >>> v7[-1:] # ③Vector([6.0]) >>> v7[1,2] # ④Traceback (most recent call last): ... TypeError: 'tuple' object cannot be interpreted as an integer
①
整数索引仅检索一个分量值作为float。
②
切片索引会创建一个新的Vector。
③
长度为 1 的切片也会创建一个Vector。
④
Vector不支持多维索引,因此索引或切片的元组会引发错误。
向量第三版:动态属性访问
从Vector2d到Vector的演变中,我们失去了通过名称访问向量分量的能力(例如,v.x,v.y)。我们现在正在处理可能具有大量分量的向量。尽管如此,使用快捷字母(如x,y,z)而不是v[0],v[1]和v[2]访问前几个分量可能更方便。
这是我们想要提供的用于读取向量前四个分量的替代语法:
>>> v = Vector(range(10))
>>> v.x
0.0
>>> v.y, v.z, v.t
(1.0, 2.0, 3.0)
在Vector2d中,我们使用@property装饰器提供了对x和y的只读访问(示例 11-7)。我们可以在Vector中编写四个属性,但这样做会很繁琐。__getattr__特殊方法提供了更好的方法。
当属性查找失败时,解释器会调用__getattr__方法。简单来说,给定表达式my_obj.x,Python 会检查my_obj实例是否有名为x的属性;如果没有,搜索会到类(my_obj.__class__)然后沿着继承图向上走。² 如果未找到x属性,则会调用my_obj类中定义的__getattr__方法,传入self和属性名称作为字符串(例如,'x')。
示例 12-8 列出了我们的__getattr__方法。基本上,它检查正在寻找的属性是否是字母xyzt中的一个,如果是,则返回相应的向量分量。
示例 12-8。vector_v3.py的一部分:Vector类中添加的__getattr__方法
__match_args__ = ('x', 'y', 'z', 't') # ①def __getattr__(self, name):cls = type(self) # ②try:pos = cls.__match_args__.index(name) # ③except ValueError: # ④pos = -1if 0 <= pos < len(self._components): # ⑤return self._components[pos]msg = f'{cls.__name__!r} object has no attribute {name!r}' # ⑥raise AttributeError(msg)
①
设置__match_args__以允许在__getattr__支持的动态属性上进行位置模式匹配。³
②
获取Vector类以备后用。
③
尝试获取__match_args__中name的位置。
④
.index(name)在未找到name时引发ValueError;将pos设置为-1。(我更愿意在这里使用类似str.find的方法,但tuple没有实现它。)
⑤
如果pos在可用分量的范围内,则返回该分量。
⑥
如果执行到这一步,请引发带有标准消息文本的AttributeError。
实现__getattr__并不难,但在这种情况下还不够。考虑示例 12-9 中的奇怪交互。
示例 12-9。不当行为:对v.x赋值不会引发错误,但会引入不一致性。
>>> v = Vector(range(5))
>>> v
Vector([0.0, 1.0, 2.0, 3.0, 4.0]) >>> v.x # ①
0.0 >>> v.x = 10 # ②
>>> v.x # ③
10 >>> v
Vector([0.0, 1.0, 2.0, 3.0, 4.0]) # ④
①
将元素 v[0] 作为 v.x 访问。
②
将新值分配给 v.x。这应该引发异常。
③
读取 v.x 显示新值 10。
④
然而,矢量组件没有发生变化。
你能解释发生了什么吗?特别是,如果向矢量组件数组中没有的值尝试 v.x 返回 10,那么为什么第二次会这样?如果你一时不知道,那就仔细研究一下在示例 12-8 之前给出的 __getattr__ 解释。这有点微妙,但是是理解本书后面内容的重要基础。
经过一番思考后,继续进行,我们将详细解释发生了什么。
示例 12-9 中的不一致性是由于 __getattr__ 的工作方式引入的:Python 仅在对象没有命名属性时才调用该方法作为后备。然而,在我们分配 v.x = 10 后,v 对象现在有一个 x 属性,因此 __getattr__ 将不再被调用来检索 v.x:解释器将直接返回绑定到 v.x 的值 10。另一方面,我们的 __getattr__ 实现不关心除 self._components 外的实例属性,从中检索列在 __match_args__ 中的“虚拟属性”的值。
我们需要自定义在我们的 Vector 类中设置属性的逻辑,以避免这种不一致性。
回想一下,在第十一章中关于最新 Vector2d 示例的情况,尝试分配给 .x 或 .y 实例属性会引发 AttributeError。在 Vector 中,我们希望任何尝试分配给所有单个小写字母属性名称时都引发相同的异常,以避免混淆。为此,我们将实现 __setattr__,如示例 12-10 中所列。
示例 12-10. Vector 类中的 __setattr__ 方法的一部分,位于 vector_v3.py 中。
def __setattr__(self, name, value):cls = type(self)if len(name) == 1: # ①if name in cls.__match_args__: # ②error = 'readonly attribute {attr_name!r}'elif name.islower(): # ③error = "can't set attributes 'a' to 'z' in {cls_name!r}"else:error = '' # ④if error: # ⑤msg = error.format(cls_name=cls.__name__, attr_name=name)raise AttributeError(msg)super().__setattr__(name, value) # ⑥
①
对单个字符属性名称进行特殊处理。
②
如果 name 是 __match_args__ 中的一个,设置特定的错误消息。
③
如果 name 是小写的,设置关于所有单个字母名称的错误消息。
④
否则,设置空白错误消息。
⑤
如果存在非空错误消息,则引发 AttributeError。
⑥
默认情况:调用超类上的 __setattr__ 以获得标准行为。
提示
super() 函数提供了一种动态访问超类方法的方式,在像 Python 这样支持多重继承的动态语言中是必不可少的。它用于将某些任务从子类中的一个方法委托给超类中的一个合适的方法,就像在示例 12-10 中所看到的那样。关于 super 还有更多内容,请参阅“多重继承和方法解析顺序”。
在选择与 AttributeError 一起显示的错误消息时,我的第一个检查对象是内置的 complex 类型的行为,因为它们是不可变的,并且有一对数据属性,real 和 imag。尝试更改 complex 实例中的任一属性都会引发带有消息 "can't set attribute" 的 AttributeError。另一方面,尝试设置只读属性(如我们在“可散列的 Vector2d”中所做的)会产生消息 "read-only attribute"。我从这两个措辞中汲取灵感,以设置 __setitem__ 中的 error 字符串,但对于被禁止的属性更加明确。
注意,我们并不禁止设置所有属性,只是单个字母、小写属性,以避免与支持的只读属性x、y、z和t混淆。
警告
知道在类级别声明__slots__可以防止设置新的实例属性,很容易就会想要使用这个特性,而不是像我们之前那样实现__setattr__。然而,正如在“总结与__slots__相关的问题”中讨论的所有注意事项,仅仅为了防止实例属性创建而使用__slots__是不推荐的。__slots__应该仅用于节省内存,而且只有在这是一个真正的问题时才使用。
即使不支持写入Vector分量,这个示例中有一个重要的要点:当你实现__getattr__时,很多时候你需要编写__setattr__,以避免对象中的不一致行为。
如果我们想允许更改分量,我们可以实现__setitem__以启用v[0] = 1.1和/或__setattr__以使v.x = 1.1起作用。但Vector将保持不可变,因为我们希望在接下来的部分使其可哈希。
Vector 第四版:哈希和更快的==
再次我们要实现一个__hash__方法。连同现有的__eq__,这将使Vector实例可哈希。
Vector2d中的__hash__(示例 11-8)计算了由两个分量self.x和self.y构建的tuple的哈希值。现在我们可能正在处理成千上万个分量,因此构建tuple可能成本太高。相反,我将对每个分量的哈希值依次应用^(异或)运算符,就像这样:v[0] ^ v[1] ^ v[2]。这就是functools.reduce函数的用途。之前我说过reduce不像以前那样流行,⁴但计算所有向量分量的哈希值是一个很好的使用案例。图 12-1 描述了reduce函数的一般思想。
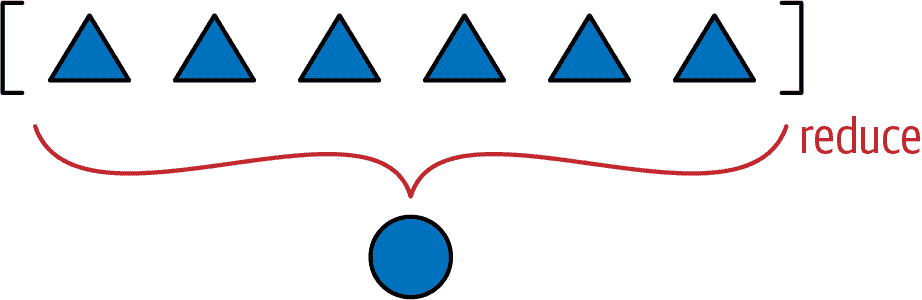
图 12-1。减少函数——reduce、sum、any、all——从序列或任何有限可迭代对象中产生单个聚合结果。
到目前为止,我们已经看到functools.reduce()可以被sum()替代,但现在让我们正确解释它的工作原理。关键思想是将一系列值减少为单个值。reduce()的第一个参数是一个二元函数,第二个参数是一个可迭代对象。假设我们有一个二元函数fn和一个列表lst。当你调用reduce(fn, lst)时,fn将被应用于第一对元素——fn(lst[0], lst[1])——产生第一个结果r1。然后fn被应用于r1和下一个元素——fn(r1, lst[2])——产生第二个结果r2。现在fn(r2, lst[3])被调用以产生r3 … 依此类推,直到最后一个元素,当返回一个单一结果rN。
这是如何使用reduce计算5!(5 的阶乘)的方法:
>>> 2 * 3 * 4 * 5 # the result we want: 5! == 120
120
>>> import functools
>>> functools.reduce(lambda a,b: a*b, range(1, 6))
120
回到我们的哈希问题,示例 12-11 展示了通过三种方式计算累积异或的想法:使用一个for循环和两个reduce调用。
示例 12-11。计算从 0 到 5 的整数的累积异或的三种方法
>>> n = 0
>>> for i in range(1, 6): # ①
... n ^= i
...
>>> n
1 >>> import functools
>>> functools.reduce(lambda a, b: a^b, range(6)) # ②
1 >>> import operator
>>> functools.reduce(operator.xor, range(6)) # ③
1
①
使用for循环和一个累加变量进行聚合异或。
②
使用匿名函数的functools.reduce。
③
使用functools.reduce用operator.xor替换自定义lambda。
在示例 12-11 中的备选方案中,最后一个是我最喜欢的,for循环排在第二位。你更喜欢哪种?
正如在“operator 模块”中所看到的,operator以函数形式提供了所有 Python 中缀运算符的功能,减少了对lambda的需求。
要按照我喜欢的风格编写Vector.__hash__,我们需要导入functools和operator模块。示例 12-12 展示了相关的更改。
示例 12-12。vector_v4.py 的一部分:从 vector_v3.py 添加两个导入和Vector类的__hash__方法
from array import array
import reprlib
import math
import functools # ①
import operator # ②class Vector:typecode = 'd'# many lines omitted in book listing...def __eq__(self, other): # ③return tuple(self) == tuple(other)def __hash__(self):hashes = (hash(x) for x in self._components) # ④return functools.reduce(operator.xor, hashes, 0) # ⑤# more lines omitted...
①
导入functools以使用reduce。
②
导入operator以使用xor。
③
对__eq__没有更改;我在这里列出它是因为在源代码中保持__eq__和__hash__靠近是一个好习惯,因为它们需要一起工作。
④
创建一个生成器表达式,以惰性计算每个组件的哈希值。
⑤
将hashes传递给reduce,使用xor函数计算聚合哈希码;第三个参数0是初始化器(参见下一个警告)。
警告
使用reduce时,最好提供第三个参数,reduce(function, iterable, initializer),以防止出现此异常:TypeError: reduce() of empty sequence with no initial value(出色的消息:解释了问题以及如何解决)。initializer是如果序列为空时返回的值,并且作为减少循环中的第一个参数使用,因此它应该是操作的身份值。例如,对于+,|,^,initializer应该是0,但对于*,&,它应该是1。
如示例 12-12 中实现的__hash__方法是一个完美的 map-reduce 计算示例(图 12-2)。
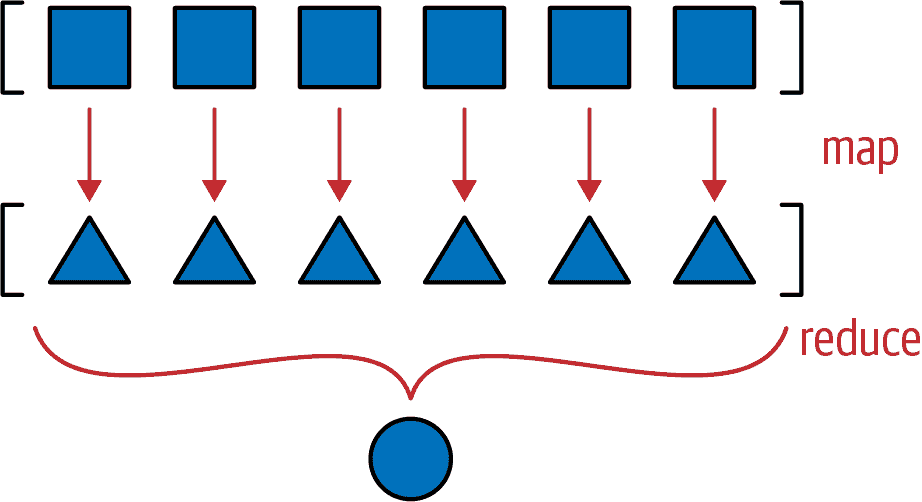
图 12-2。Map-reduce:将函数应用于每个项目以生成新系列(map),然后计算聚合(reduce)。
映射步骤为每个组件生成一个哈希值,减少步骤使用xor运算符聚合所有哈希值。使用map而不是genexp使映射步骤更加可见:
def __hash__(self):hashes = map(hash, self._components)return functools.reduce(operator.xor, hashes)
提示
在 Python 2 中,使用map的解决方案效率较低,因为map函数会构建一个包含结果的新list。但在 Python 3 中,map是惰性的:它创建一个生成器,按需产生结果,从而节省内存——就像我们在示例 12-8 的__hash__方法中使用的生成器表达式一样。
当我们谈论减少函数时,我们可以用另一种更便宜的方式来替换我们快速实现的__eq__,至少对于大向量来说,在处理和内存方面更便宜。正如示例 11-2 中介绍的,我们有这个非常简洁的__eq__实现:
def __eq__(self, other):return tuple(self) == tuple(other)
这适用于Vector2d和Vector——甚至将Vector([1, 2])视为(1, 2)相等,这可能是一个问题,但我们暂时忽略这一点。⁵ 但对于可能有数千个组件的Vector实例来说,这是非常低效的。它构建了两个元组,复制了操作数的整个内容,只是为了使用tuple类型的__eq__。对于Vector2d(只有两个组件),这是一个很好的快捷方式,但对于大型多维向量来说不是。比较一个Vector和另一个Vector或可迭代对象的更好方法将是示例 12-13。
示例 12-13。使用for循环中的zip实现的Vector.__eq__方法,用于更高效的比较
def __eq__(self, other):if len(self) != len(other): # ①return Falsefor a, b in zip(self, other): # ②if a != b: # ③return Falsereturn True # ④
①
如果对象的长度不同,则它们不相等。
②
zip生成一个由每个可迭代参数中的项目组成的元组生成器。如果您对zip不熟悉,请参阅“了不起的 zip”。在①中,需要进行len比较,因为zip在其中一个输入耗尽时会停止生成值而没有警告。
③
一旦两个分量不同,立即返回False。
④
否则,对象相等。
提示
zip函数的命名是根据拉链拉链器而来,因为物理设备通过相互锁定来自拉链两侧的牙齿对来工作,这与zip(left, right)所做的事情是一个很好的视觉类比。与压缩文件无关。
示例 12-13 是高效的,但all函数可以在一行中产生与for循环相同的聚合计算:如果操作数中对应分量之间的所有比较都为True,则结果为True。一旦有一个比较为False,all就返回False。示例 12-14 展示了使用all的__eq__的外观。
示例 12-14. 使用zip和all实现的Vector.__eq__:与示例 12-13 相同的逻辑
def __eq__(self, other):return len(self) == len(other) and all(a == b for a, b in zip(self, other))
请注意,我们首先检查操作数的长度是否相等,因为zip将停止在最短的操作数处。
示例 12-14 是我们在vector_v4.py中选择的__eq__的实现。
我们通过将Vector2d的__format__方法重新引入到Vector中来结束本章。
Vector Take #5: Formatting
Vector的__format__方法将类似于Vector2d的方法,但不是提供极坐标的自定义显示,而是使用球坐标——也称为“超球面”坐标,因为现在我们支持n维,而在 4D 及以上的维度中,球体是“超球体”。⁶ 因此,我们将自定义格式后缀从'p'改为'h'。
提示
正如我们在“Formatted Displays”中看到的,当扩展格式规范迷你语言时,最好避免重用内置类型支持的格式代码。特别是,我们扩展的迷你语言还使用浮点数格式代码'eEfFgGn%'的原始含义,因此我们绝对必须避免这些。整数使用'bcdoxXn',字符串使用's'。我选择了'p'来表示Vector2d的极坐标。代码'h'表示超球面坐标是一个不错的选择。
例如,给定 4D 空间中的Vector对象(len(v) == 4),'h'代码将产生类似于<r, Φ₁, Φ₂, Φ₃>的显示,其中r是大小(abs(v)),其余数字是角分量Φ₁,Φ₂,Φ₃。
这里是来自vector_v5.py的 doctests 中 4D 空间中球坐标格式的一些示例(参见示例 12-16):
>>> format(Vector([-1, -1, -1, -1]), 'h')
'<2.0, 2.0943951023931957, 2.186276035465284, 3.9269908169872414>'
>>> format(Vector([2, 2, 2, 2]), '.3eh')
'<4.000e+00, 1.047e+00, 9.553e-01, 7.854e-01>'
>>> format(Vector([0, 1, 0, 0]), '0.5fh')
'<1.00000, 1.57080, 0.00000, 0.00000>'
在我们可以实现__format__中所需的微小更改之前,我们需要编写一对支持方法:angle(n)用于计算一个角坐标(例如,Φ₁),以及angles()用于返回所有角坐标的可迭代对象。我不会在这里描述数学内容;如果你感兴趣,维基百科的“n-sphere”条目有我用来从Vector的分量数组中计算球坐标的公式。
示例 12-16 是vector_v5.py的完整清单,汇总了自从“Vector Take #1: Vector2d Compatible”以来我们实现的所有内容,并引入了自定义格式。
示例 12-16. vector_v5.py:包含最终Vector类的 doctests 和所有代码;标注突出显示了支持__format__所需的添加内容
"""
A multidimensional ``Vector`` class, take 5A ``Vector`` is built from an iterable of numbers::>>> Vector([3.1, 4.2])Vector([3.1, 4.2])>>> Vector((3, 4, 5))Vector([3.0, 4.0, 5.0])>>> Vector(range(10))Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...])Tests with two dimensions (same results as ``vector2d_v1.py``)::>>> v1 = Vector([3, 4])>>> x, y = v1>>> x, y(3.0, 4.0)>>> v1Vector([3.0, 4.0])>>> v1_clone = eval(repr(v1))>>> v1 == v1_cloneTrue>>> print(v1)(3.0, 4.0)>>> octets = bytes(v1)>>> octetsb'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'>>> abs(v1)5.0>>> bool(v1), bool(Vector([0, 0]))(True, False)Test of ``.frombytes()`` class method:>>> v1_clone = Vector.frombytes(bytes(v1))>>> v1_cloneVector([3.0, 4.0])>>> v1 == v1_cloneTrueTests with three dimensions::>>> v1 = Vector([3, 4, 5])>>> x, y, z = v1>>> x, y, z(3.0, 4.0, 5.0)>>> v1Vector([3.0, 4.0, 5.0])>>> v1_clone = eval(repr(v1))>>> v1 == v1_cloneTrue>>> print(v1)(3.0, 4.0, 5.0)>>> abs(v1) # doctest:+ELLIPSIS7.071067811...>>> bool(v1), bool(Vector([0, 0, 0]))(True, False)Tests with many dimensions::>>> v7 = Vector(range(7))>>> v7Vector([0.0, 1.0, 2.0, 3.0, 4.0, ...])>>> abs(v7) # doctest:+ELLIPSIS9.53939201...Test of ``.__bytes__`` and ``.frombytes()`` methods::>>> v1 = Vector([3, 4, 5])>>> v1_clone = Vector.frombytes(bytes(v1))>>> v1_cloneVector([3.0, 4.0, 5.0])>>> v1 == v1_cloneTrueTests of sequence behavior::>>> v1 = Vector([3, 4, 5])>>> len(v1)3>>> v1[0], v1[len(v1)-1], v1[-1](3.0, 5.0, 5.0)Test of slicing::>>> v7 = Vector(range(7))>>> v7[-1]6.0>>> v7[1:4]Vector([1.0, 2.0, 3.0])>>> v7[-1:]Vector([6.0])>>> v7[1,2]Traceback (most recent call last):...TypeError: 'tuple' object cannot be interpreted as an integerTests of dynamic attribute access::>>> v7 = Vector(range(10))>>> v7.x0.0>>> v7.y, v7.z, v7.t(1.0, 2.0, 3.0)Dynamic attribute lookup failures::>>> v7.kTraceback (most recent call last):...AttributeError: 'Vector' object has no attribute 'k'>>> v3 = Vector(range(3))>>> v3.tTraceback (most recent call last):...AttributeError: 'Vector' object has no attribute 't'>>> v3.spamTraceback (most recent call last):...AttributeError: 'Vector' object has no attribute 'spam'Tests of hashing::>>> v1 = Vector([3, 4])>>> v2 = Vector([3.1, 4.2])>>> v3 = Vector([3, 4, 5])>>> v6 = Vector(range(6))>>> hash(v1), hash(v3), hash(v6)(7, 2, 1)Most hash codes of non-integers vary from a 32-bit to 64-bit CPython build::>>> import sys>>> hash(v2) == (384307168202284039 if sys.maxsize > 2**32 else 357915986)TrueTests of ``format()`` with Cartesian coordinates in 2D::>>> v1 = Vector([3, 4])>>> format(v1)'(3.0, 4.0)'>>> format(v1, '.2f')'(3.00, 4.00)'>>> format(v1, '.3e')'(3.000e+00, 4.000e+00)'Tests of ``format()`` with Cartesian coordinates in 3D and 7D::>>> v3 = Vector([3, 4, 5])>>> format(v3)'(3.0, 4.0, 5.0)'>>> format(Vector(range(7)))'(0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0)'Tests of ``format()`` with spherical coordinates in 2D, 3D and 4D::>>> format(Vector([1, 1]), 'h') # doctest:+ELLIPSIS'<1.414213..., 0.785398...>'>>> format(Vector([1, 1]), '.3eh')'<1.414e+00, 7.854e-01>'>>> format(Vector([1, 1]), '0.5fh')'<1.41421, 0.78540>'>>> format(Vector([1, 1, 1]), 'h') # doctest:+ELLIPSIS'<1.73205..., 0.95531..., 0.78539...>'>>> format(Vector([2, 2, 2]), '.3eh')'<3.464e+00, 9.553e-01, 7.854e-01>'>>> format(Vector([0, 0, 0]), '0.5fh')'<0.00000, 0.00000, 0.00000>'>>> format(Vector([-1, -1, -1, -1]), 'h') # doctest:+ELLIPSIS'<2.0, 2.09439..., 2.18627..., 3.92699...>'>>> format(Vector([2, 2, 2, 2]), '.3eh')'<4.000e+00, 1.047e+00, 9.553e-01, 7.854e-01>'>>> format(Vector([0, 1, 0, 0]), '0.5fh')'<1.00000, 1.57080, 0.00000, 0.00000>'
"""from array import array
import reprlib
import math
import functools
import operator
import itertools # ①class Vector:typecode = 'd'def __init__(self, components):self._components = array(self.typecode, components)def __iter__(self):return iter(self._components)def __repr__(self):components = reprlib.repr(self._components)components = components[components.find('['):-1]return f'Vector({components})'def __str__(self):return str(tuple(self))def __bytes__(self):return (bytes([ord(self.typecode)]) +bytes(self._components))def __eq__(self, other):return (len(self) == len(other) andall(a == b for a, b in zip(self, other)))def __hash__(self):hashes = (hash(x) for x in self)return functools.reduce(operator.xor, hashes, 0)def __abs__(self):return math.hypot(*self)def __bool__(self):return bool(abs(self))def __len__(self):return len(self._components)def __getitem__(self, key):if isinstance(key, slice):cls = type(self)return cls(self._components[key])index = operator.index(key)return self._components[index]__match_args__ = ('x', 'y', 'z', 't')def __getattr__(self, name):cls = type(self)try:pos = cls.__match_args__.index(name)except ValueError:pos = -1if 0 <= pos < len(self._components):return self._components[pos]msg = f'{cls.__name__!r} object has no attribute {name!r}'raise AttributeError(msg)def angle(self, n): # ②r = math.hypot(*self[n:])a = math.atan2(r, self[n-1])if (n == len(self) - 1) and (self[-1] < 0):return math.pi * 2 - aelse:return adef angles(self): # ③return (self.angle(n) for n in range(1, len(self)))def __format__(self, fmt_spec=''):if fmt_spec.endswith('h'): # hyperspherical coordinatesfmt_spec = fmt_spec[:-1]coords = itertools.chain([abs(self)],self.angles()) # ④outer_fmt = '<{}>' # ⑤else:coords = selfouter_fmt = '({})' # ⑥components = (format(c, fmt_spec) for c in coords) # ⑦return outer_fmt.format(', '.join(components)) # ⑧@classmethoddef frombytes(cls, octets):typecode = chr(octets[0])memv = memoryview(octets[1:]).cast(typecode)return cls(memv)
①
导入itertools以在__format__中使用chain函数。
②
使用从n-sphere article调整的公式计算一个角坐标。
③
创建一个生成器表达式,按需计算所有角坐标。
④
使用itertools.chain生成genexp,以便无缝迭代幅度和角坐标。
⑤
配置带尖括号的球坐标显示。
⑥
配置带括号的笛卡尔坐标显示。
⑦
创建一个生成器表达式,以便按需格式化每个坐标项。
⑧
将格式化的组件用逗号分隔放在方括号或括号内。
注意
在__format__、angle和angles中大量使用生成器表达式,但我们的重点在于提供__format__以使Vector达到与Vector2d相同的实现水平。当我们在第十七章中讨论生成器时,我们将使用Vector中的一些代码作为示例,然后详细解释生成器技巧。
这就结束了本章的任务。Vector类将在第十六章中通过中缀运算符进行增强,但我们在这里的目标是探索编写特殊方法的技术,这些方法在各种集合类中都很有用。
章节总结
本章中的Vector示例旨在与Vector2d兼容,除了使用接受单个可迭代参数的不同构造函数签名外,就像内置序列类型所做的那样。Vector通过仅实现__getitem__和__len__就表现得像一个序列,这促使我们讨论协议,即鸭子类型语言中使用的非正式接口。
然后我们看了一下my_seq[a:b:c]语法在幕后是如何工作的,通过创建一个slice(a, b, c)对象并将其传递给__getitem__。有了这个知识,我们使Vector正确响应切片操作,通过返回新的Vector实例,就像预期的 Python 序列一样。
下一步是通过诸如my_vec.x这样的表示法为前几个Vector组件提供只读访问。我们通过实现__getattr__来实现这一点。这样做打开了通过编写my_vec.x = 7来为这些特殊组件赋值的可能性,揭示了一个潜在的错误。我们通过实现__setattr__来修复这个问题,以禁止向单个字母属性赋值。通常,当你编写__getattr__时,你需要添加__setattr__,以避免不一致的行为。
实现__hash__函数为使用functools.reduce提供了完美的背景,因为我们需要对所有Vector组件的哈希值连续应用异或运算符^,以产生整个Vector的聚合哈希码。在__hash__中应用reduce后,我们使用all内置的 reduce 函数来创建一个更高效的__eq__方法。
对Vector的最后一个增强是通过支持球坐标作为默认笛卡尔坐标的替代来重新实现Vector2d中的__format__方法。我们使用了相当多的数学和几个生成器来编写__format__及其辅助函数,但这些都是实现细节——我们将在第十七章中回到生成器。最后一节的目标是支持自定义格式,从而实现Vector能够做到与Vector2d一样的一切,甚至更多。
正如我们在第十一章中所做的那样,这里我们经常研究标准 Python 对象的行为,以模拟它们并为Vector提供“Pythonic”的外观和感觉。
在第十六章中,我们将在Vector上实现几个中缀运算符。数学将比这里的angle()方法简单得多,但探索 Python 中中缀运算符的工作方式是面向对象设计的一课。但在我们开始运算符重载之前,我们将暂时离开单个类的工作,转而关注组织多个类的接口和继承,这是第十三章和第十四章的主题。
进一步阅读
在Vector示例中涵盖的大多数特殊方法也出现在第十一章的Vector2d示例中,因此“进一步阅读”中的参考资料在这里都是相关的。
强大的reduce高阶函数也被称为 fold、accumulate、aggregate、compress 和 inject。更多信息,请参阅维基百科的“Fold (higher-order function)”文章,该文章重点介绍了该高阶函数在递归数据结构的函数式编程中的应用。该文章还包括一张列出了几十种编程语言中类似 fold 函数的表格。
“Python 2.5 中的新功能”简要解释了__index__,旨在支持__getitem__方法,正如我们在“一个支持切片的 getitem”中看到的。PEP 357—允许任何对象用于切片详细介绍了从 C 扩展的实现者的角度看它的必要性——Travis Oliphant,NumPy 的主要创造者。Oliphant 对 Python 的许多贡献使其成为一种领先的科学计算语言,从而使其在机器学习应用方面处于领先地位。
¹ iter()函数在第十七章中有介绍,还有__iter__方法。
² 属性查找比这更复杂;我们将在第五部分中看到详细内容。现在,这个简化的解释就足够了。
³ 尽管__match_args__存在于支持 Python 3.10 中的模式匹配,但在之前的 Python 版本中设置这个属性是无害的。在本书的第一版中,我将其命名为shortcut_names。新名称具有双重作用:支持case子句中的位置模式,并保存__getattr__和__setattr__中特殊逻辑支持的动态属性的名称。
⁴ sum、any和all涵盖了reduce的最常见用法。请参阅“map、filter 和 reduce 的现代替代品”中的讨论。
⁵ 我们将认真考虑Vector([1, 2]) == (1, 2)这个问题,在“运算符重载 101”中。
⁶ Wolfram Mathworld 网站有一篇关于超球体的文章;在维基百科上,“超球体”重定向到“n-球体”条目。
⁷ 我为这个演示调整了代码:在 2003 年,reduce是内置的,但在 Python 3 中我们需要导入它;此外,我用my_list和sub替换了x和y的名称,用于子列表。

![[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction](https://img-blog.csdnimg.cn/img_convert/b9f1b3a80a11baf04f6d2162abd203c8.png)