什么是hive?
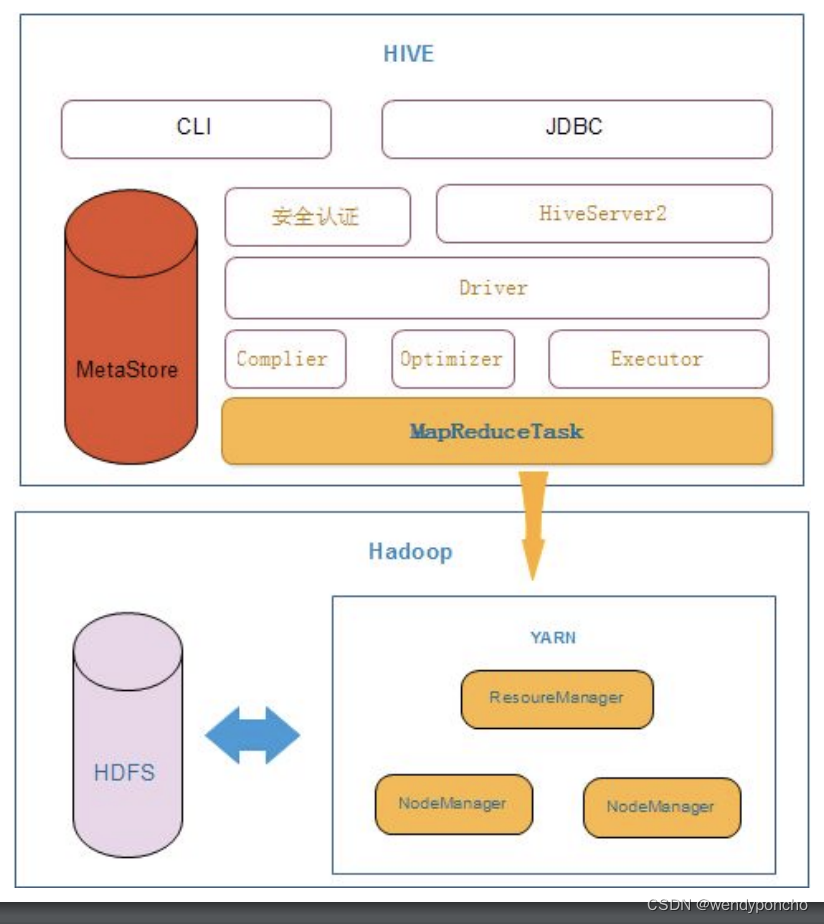
- Hive是Facebook开发并贡献给Hadoop开源社区的。它是建立在 Hadoop体系架构上的一层 SQL抽象,使得数据相关人 员使用他们最为熟悉的SQL语言就可以进行海量数据的处理、 分析和统计工作
- Hive将数据存储于HDFS的数据文件映射为一张数据库表,以MapReduce作为计算引擎 (Hive on MR),并提供完整的sql查询功能
- 由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建 的数据仓库也秉承了这些特性
Hive构架
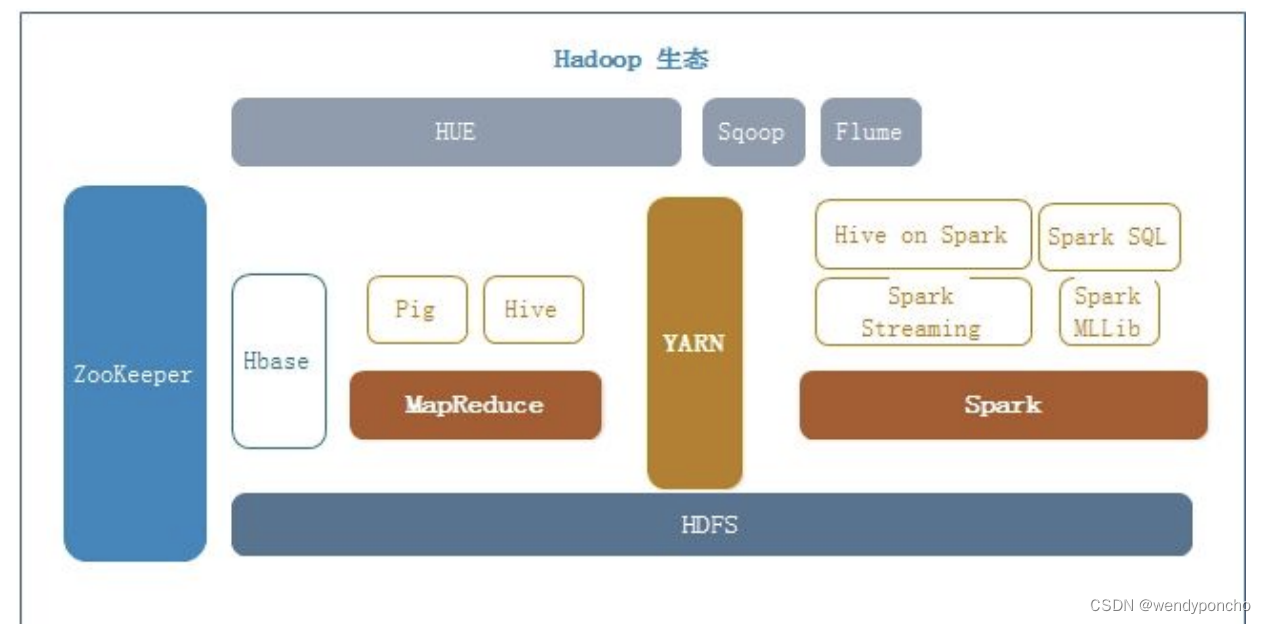
Hadoop生态
HQL
基础函数: SELECT FROM WHERE ORDER BY GROUP BY LIMIT ...
排序: SORT BY DISTRIBUTE BY CLUSTER BY
标准聚合函数: COUNT,SUM,MIN,MAX,AVG...
窗口函数: FIRST_VALUE,LAST_VALUE,ROW_NUMBER ,RANK…
CUBE函数:(维度限制) GROUPING SETS,CUBE,ROLLUP,GROUPING_ID(spark sql和hive不能兼容)
定义函数: UDF(User-Defined-Function) 用户自定义函数
UDTF(User-Defined Table-Generating Functions) 用来解决 输入一行输出多行(On-to-many maping)
UDAF(User- Defined Aggregation Funcation) 自定义聚类函数
Hive的数据单元
●Databases:数据库。概念等同于关系型数据 库的Schema;
●Tables:和关系型数据库中的表在概念上很 类似,每个表在HDFS中都有相应的目录用来存储表的数据
●外部表:Hive中的外部表和内部表很 类似,但是其数据不是放在自己表所属的目 录中,而是存放到别处,这样的好 处是如果你要删除这个外部表,该外部表所指向的数据是不会被 删除的,它只会删除外部表对应的元数据;而如果 你要删除表,该表对应的所有数据包括元数据都会被 删除 ●Partitions:分区,在Hive中,表的每一个分区 对应表下的相应目录,所有分区的数据都是存 储在对应的目录中
●Buckets :分桶,同一个分区内的数据 还可以细分,对指定的列计算其hash,根据hash值切分数据,目的是 为了并 行
●基本操作:
show databases;
show databases like 'xx*';
use database; show tables;
show partitions db.tbl_name;
desc db.table;
desc formatted db.tbl_name;
show create table db.tbl_name;
create table db.new_table like old_table
HQL优化
● 使用分区剪裁、列剪裁 在SELECT中,只拿需要的列,如果有,尽量使用分区 过滤,少用SELECT * 在分区剪裁中,当使用外关 联时,如果将副表的过滤条件写在Where后面,那么就会先全表关 联,之后再过滤 正确的写法是写在 ON后面,或者直接写成子 查询 通过执行计划可以看到具体在哪里 过滤,不确定就分析执行计划,看看执行是怎么样被优化的
● 少用多重COUNT DISTINCT
selecta,sum(b),count(distinct c),count(distinct d) from test group by a;
优化后:
select a,sum(b)as b,count(c) as c,count(d) as d from ( select a,0 as b,c,null as d from test group by a,c union all select a,0 as b,null as c,d from test group by a,d union all select a,b,null as c,null as d from test )tmp group by a;
● 是否存在多对多的关联 ● 尽量原子化操作,尽量避免一个 SQL包含复杂逻辑 ● 使用动态分区 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict