什么是搜索引擎(SEO)爬虫&它们是如何工作的?

你的网站上有蜘蛛🕷️。别抓狂!我说的不是真正的八条腿的蜘蛛🕷️。
我指的是搜索引擎优化爬虫。他们是实现SEO的机器人。每个主要的搜索引擎都使用爬虫来对可感知的互联网进行分类。正是通过这些爬虫(有时被称为爬行爬虫或爬行器)的工作,你的网站才在谷歌、必应、雅虎等流行搜索引擎上排名。当然,谷歌是搜索引擎界的大狗,所以在优化网站时,最好记住谷歌的爬虫。但什么是搜索引擎爬行爬虫?关键很简单:为了在搜索引擎结果页面上排名靠前,你必须编写、设计和编码你的网站以吸引他们。这意味着你必须知道他们是什么,他们在寻找什么,以及他们是如何工作的。有了这些信息,你将能够更好地优化你的网站,知道世界上最重要的搜索引擎在寻找什么。
一、什么是搜索引擎爬虫?
在你了解网络爬虫是如何工作的以及如何吸引它之前,你首先必须知道它们是什么。
搜索引擎爬虫是搜索引擎世界的步兵。像谷歌这样的搜索引擎有一些东西想从排名靠前的网站上看到。爬行器在网络上移动,并执行搜索引擎的意愿。

爬行器只是一个由特定目的引导的软件。对于爬虫来说,其目的是对网站信息进行编目。
谷歌的爬虫在网站上爬行,收集和存储数据。他们不仅要确定页面是什么,还要确定内容的质量和其中包含的主题。他们为网络上的每个网站都这样做。从长远来看,截至2019年,活跃的网站有19.4亿个,而且这个数字每天都在上升。每一个弹出的新网站都必须由爬虫机器人进行抓取、分析和编目。然后,搜索引擎爬网程序将收集的数据传递给搜索引擎进行索引。这些信息一直保存到需要时为止。当启动谷歌搜索查询时,结果和排名都是根据该索引生成的。
二、爬行器是如何工作的?
爬行器是一个复杂的软件。如果你要对整个网络进行编目,你必须这样做。但是这个机器人是如何工作的呢?首先,爬虫访问网页,寻找要包含在搜索引擎索引中的新数据。这是它的终极目标,也是它存在的原因。但这个搜索引擎机器人的任务需要做很多工作。
第一步: 爬虫检查你的Robots.txt文件
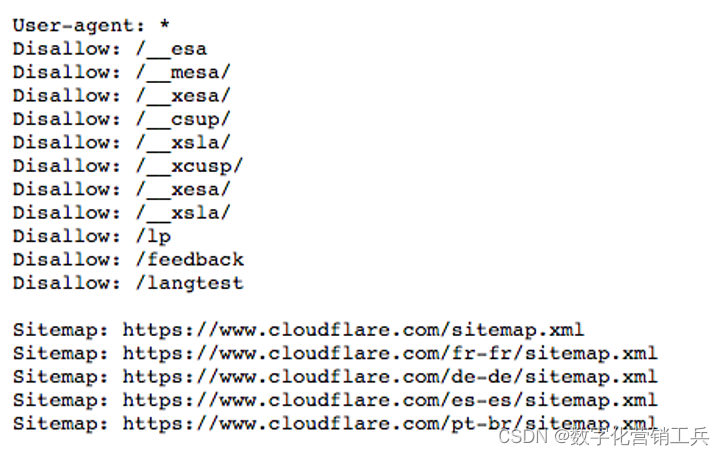
当谷歌的爬虫到达一个新网站时,它们会立即下载该网站的robots.txt文件。robots.txt文件为spider提供了关于网站上可以和应该对哪些页面进行爬网的规则。它还允许他们查看网站地图,以确定页面的总体布局以及如何对其进行编目。Robots.txt是SEO难题中有价值的一块,但它是许多网站建设者无法直接控制的。你的网站上有一些单独的页面,你可能想避开谷歌的爬虫。
你能阻止你的网站被爬网吗?
你绝对可以,使用robots.txt。
但你为什么要这么做?
假设你有两个非常相似的页面,有很多重复的内容。谷歌讨厌重复的内容,这会对你的排名产生负面影响。这就是为什么能够编辑你的robots.txt文件,使谷歌看不到可能对你的SEO分数产生不利影响的特定页面是件好事。

谷歌对重复内容等内容非常挑剔,因为它的商业模式致力于提供准确、高质量的搜索结果。这就是为什么他们的搜索算法如此先进的原因。如果他们提供了尽可能好的信息,客户将继续涌向他们的平台,寻找他们想要的东西。通过提供高质量的搜索结果,谷歌将消费者吸引到他们的平台上,在那里他们可以向他们展示广告(占谷歌收入的70.9%)。因此,如果你认为爬虫对重复内容等内容过于挑剔,请记住质量是谷歌最关心的问题:
- 质量建议带来更多用户
- 用户越多,广告销量就越高
- 广告销售额的增加带来了盈利能力
第二步:爬虫检查你的链接
爬虫所关注的一个主要因素是链接。爬虫不仅能识别超链接,而且还能跟随超链接。他们使用您网站的内部链接来移动并继续编目。内部链接是必不可少的,原因有很多,但它们也为搜索机器人创造了一条简单的路径。爬虫还会仔细注意哪些出站链接,以及哪些第三方网站链接到你的网站。当我们说链接构建是SEO计划中最关键的元素之一时,我们说的是实话。你必须在你的网页和博客文章之间创建一个内部链接网络。您还必须确保链接到外部来源。

但除此之外,你必须确保那些受到谷歌高度青睐并与你的网站相关的外部网站与你链接。正如我们在上一节中提到的,谷歌需要知道,它正在向搜索者提供高质量和合法的建议,以保持其主导地位,进而保持盈利能力。当一个网站链接到你时,把它想象成一封推荐信。如果你正在申请护士的工作,你会收到以前的医院管理人员和与你共事过的医疗专业人员的推荐信。如果你带着一封来自快递员和狗美容师的短信出现,他们可能会对你说一些美好的话,但他们的话在医学领域不会有多大分量。
SEO是谷歌的求职面试
你在网上的每一秒都在面试你所在行业的顶尖人物。谷歌的爬虫是进行面试的人力资源代表,在向上级报告并决定你的资格之前,先检查你的消息来源。
第三步:爬虫检查你的副本
关于搜索引擎爬虫的一个常见误解是 - 它们只会出现在页面上并统计你的所有关键词。虽然关键词在你的排名中起着一定的作用,但爬虫的作用远不止于此。

SEO就是对你的副本进行调整
这些调整是为了给谷歌的爬虫留下深刻印象,并给他们想要的东西。但是,当搜索引擎爬虫审查你的网站副本时,他们在寻找什么?
他们试图确定三个关键因素
内容的相关性 the relevance of your content
如果你是一个牙科网站,你是否专注于牙科信息?你是在随意偏离主题,还是把网站的某些区域专门用于其他无关的主题?如果是这样的话,谷歌的机器人会对他们应该如何对你进行排名感到困惑。
内容的整体质量 the overall quality of your content
谷歌爬虫坚持高质量的写作。他们希望确保你的文本符合谷歌的高标准。记住,谷歌的推荐是有分量的,所以它不仅仅是关于你可以在一段话中插入多少关键词。爬虫们希望看到质量胜于数量。
您的内容的权威性 the authority of your content
如果你是一个牙科网站,谷歌需要确保你是你所在行业的权威。如果你想成为特定关键词或短语的头号搜索词,那么你必须向谷歌的爬虫证明你是该特定主题的权威。如果你在网站的代码中包含结构化数据,也被称为模式标记,你将通过谷歌的爬虫获得额外的积分。这种编码语言为爬虫提供了更多关于你的网站的信息,并帮助它们更准确地列出你。试图欺骗谷歌的爬虫也从来都不是一个好主意。他们并不像许多SEO营销人员想象的那样愚蠢。
黑帽SEO包括不道德的策略,用来试图欺骗谷歌在不创建高质量内容和链接的情况下给网站更高的排名。黑帽子SEO策略的一个例子是关键词填充,即你将毫无意义的关键词堆积到页面中。黑帽SEO公司使用的另一种策略是通过包含链接的虚假页面创建反向链接。十年前,这些策略奏效了。但从那以后,谷歌进行了许多更新,其爬虫机器人现在能够识别黑帽子战术并惩罚肇事者。Spiders索引黑帽SEO信息,如果您的内容被证明有问题,则可能会受到处罚。这些处罚可以是小而有效的,比如降低网站的排名,也可以是严重到完全除名的处罚,即你的网站从谷歌上完全消失。
第四步:爬虫看你的图片
爬虫在网络上爬行时会对你网站的图像进行统计。然而,这是谷歌机器人需要一些额外帮助的领域。爬虫不能只看一张照片就确定它是什么。它知道那里有一个图像,但它还不够先进,无法获得实际的背景。这就是为什么将alt标签和标题与每张图片关联起来是如此重要。如果你是一家清洁公司,你可能会有照片展示你各种办公室清洁技术的效果。除非你在alt标签(在HTML中,用于为图像提供替代文本描述的标签。)或标题中指定图片是办公室清洁技术,否则爬虫不会知道。
第五步:爬虫再做一遍
谷歌爬虫的工作永远不会完成。一旦它完成了对网站的编目,它就会继续前进,并最终重新对你的网站进行编目,以更新谷歌的内容和优化工作。这些机器人不断地爬行以寻找新页面和新内容。您可以间接确定页面重新爬网的频率。如果你定期更新你的网站,你就给了谷歌一个再次为你编目的理由。这就是为什么一致的更新(和博客文章)应该成为每个SEO计划的一部分。
你如何为SEO爬虫优化你的网站?
回顾一下,你可以采取几个步骤来确保你的网站已经准备好让谷歌的爬虫爬行。
步骤1:有一个清晰的站点层次结构 (site hierarchy)
网站结构对于在搜索引擎中排名至关重要。确保页面在点击几下即可轻松访问,使爬网程序能够尽快访问所需的信息。
步骤2:进行关键词研究 (key word)
了解你的受众正在使用什么样的搜索词,并找到将它们融入你的内容的方法。
步骤3:创建高质量的内容 (quality content)
写出清晰的内容,展示你在某一主题上的权威。记住不要在你的文本中添加关键词。坚持主题,证明你的相关性和专业知识。
步骤4:建立链接 (links)
创建一系列内部链接,供谷歌的机器人在访问您的网站时使用。从与您所在行业相关的外部来源建立反向链接,以提高您的权威。
步骤5:优化元描述和标题标签 (Title Tags)
在网络爬虫进入你的页面内容之前,它将首先读取你的页面标题和元数据。请确保这些都使用关键字进行了优化。对高质量内容的需求也延伸到这里。
步骤6:为所有图像添加Alt Tags标签
记住,爬虫看不到你的照片。你必须通过优化的副本向谷歌描述它们。用完允许的字符,画出清晰的图片。
步骤7:确保NAP(网络接入点)一致性 (consistency)
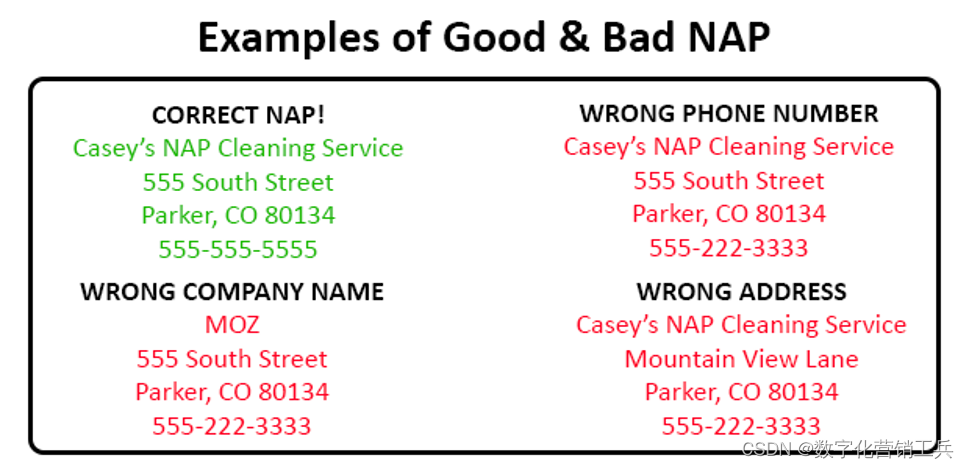
如果你是当地企业,你必须确保你的姓名、地址和电话号码不仅出现在你的网站和各种第三方平台上,而且在任何地方都是一致的。这意味着,无论你在哪里列出NAP引文,信息都应该是相同的。
这也适用于拼写和缩写。如果你在主街,但你想缩写为Main St.,请确保你在任何地方都这样做。爬虫会注意到不一致,这会损害你的品牌合法性和SEO得分。
步骤8:定期更新您的网站 regularly update your site
源源不断的新内容将确保谷歌总是有理由再次抓取你的网站并更新你的分数。博客文章是一种完美的方式,可以让搜索引擎机器人在你的网站上保持源源不断的新鲜内容。
总结
对SEO爬虫和搜索引擎爬行的深入了解可以对您的SEO工作产生积极影响。你需要知道它们是什么,它们是如何工作的,以及如何优化你的网站以适应他们的需求。
忽略SEO爬虫爬行器可以是确保您的网站在默默无闻中打滚的最快方法。每一个查询都是一个机会。吸引爬虫,你就可以利用你的数字营销计划提升搜索引擎的排名,在你的行业中占据榜首,并在未来几年保持领先地位。
数字化营销工兵观察
SEO&SEM虽然是一个老生常谈的话题,但是随着大语言模型和文本自动生成技术的日趋成熟,未来的SEO&SEM工作,肯定充满了新的变化、挑战和方法。后面我们一起找时间来学习未来的SEO&SEM工作。一起期待吧。