头歌 实验一 关系数据库标准语言SQL
制作不易!点个关注呗!为大家创造更多的价值!
目录
- 头歌 实验一 关系数据库标准语言SQL
- **`制作不易!点个关注呗!为大家创造更多的价值!`**
- 第一关:创建数据库
- 第二关:创建表
- 第三关:插入数据
- 第四关:数据查询-基础查询
- 第五关:数据查询-条件查询
- 第六关:数据查询-连接查询
- 第七关:数据查询-子查询
- 第八关:修改数据
- 第九关:创建视图
- 第十关:定义索引
- **`制作不易!点个关注呗!为大家创造更多的价值!`**
第一关:创建数据库
任务描述
本关任务:建立数据库
为了完成本关任务,你需要掌握:
如何创建数据库,显示已经建立的数据库
相关知识
创建数据库
创建数据库是在系统磁盘上划分一块区域用于数据的存储和管理。
命令格式:
CREATE DATABASE database_name;
创建完数据库之后我们可以通过show databases;命令查看MySQL中已存在的所有数据库。
任务要求
建立demo数据库
并显示所有数据库
开始你的任务吧,祝你成功!
代码如下:
#代码开始
CREATE DATABASE demo;#代码结束
show databases;
第二关:创建表
任务描述
本关任务:建立数据表
相关知识
选择数据库
命令格式:
use 数据库名;
选择数据库为当前数据库
创建数据表
创建数据表的命令格式:
CREATE TABLE 表名
( 列名1 数据类型 字段属性,列名2 数据类型 字段属性,…列名n 数据类型 字段属性
);
常用的数据类型如下

枚举型和集合型

在字段类型选择的时候,
对于数值类型,ZEROFILL 表示前导零填充数值类型值以达到列的显示宽度。
auto_increment表示对于数值型字段自动增加
not null表示不允许该字段值为null
显示数据表结构
describe 数据表名;
查看数据表的基本结构
任务要求
设有一个demo数据库,包括S,P,J,SPJ四个关系模式:
S(SNO,SNAME,STATUS,CITY)
P(PNO,PNAME,COLOR,WEIGHT)
J(JNO,JNAME,CITY)
SPJ(SNO,PNO,JNO,QTY)
供应商表S由供应商代码(SNO)、供应商姓名(SNAME)、供应商状态(STATUS)、供应商所在城市(CITY)组成;
零件表P由零件代码(PNO)、零件名(PNAME)、颜色(COLOR)、重量(WEIGHT)组成;
工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、工程项目所在城市(CITY)组成;
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,表示某供应商 供应某种零件 给某工程项目的数量为QTY。
demo数据库已经创建好,请按下面步骤完成任务。
1.切换到demo数据库
2.分别创建s、p、j和spj数据表
3.查看s、p、j和spj数据表的详细结构
注意:表名统一用小写。
数据表结构如下:
s表

p表

j表

spj表

开始你的任务吧,祝你成功!
代码如下:
#代码开始#1. 切换到demo数据库use demo;#2. 分别创建s、p、j和spj数据表
/*清除表结构*/
-- DROP TABLE j, p,s,spj;
/**创建s表**/
CREATE TABLE s
(
sno CHAR(2) NULL ,
sname VARCHAR(10) ,
status INT(11) NULL ,
city VARCHAR(10)
);
-- /**创建p表**/
CREATE TABLE p
(
pno CHAR(2) null ,
pname VARCHAR(10),
color CHAR(1),
weight int
);
-- /**创建J表**/
CREATE TABLE j
(jno CHAR(2) null ,jname VARCHAR(10),city VARCHAR(10)
);
-- /*创建spj表*/
CREATE TABLE spj
(
sno CHAR(2) null ,
pno CHAR(2),
jno CHAR(2),
qty INT
);#3. 查看s、p、j和spj数据表的详细结构describe s;describe p;describe j;describe spj;#代码结束
第三关:插入数据
任务描述
本关任务:在s、p、j和spj数据表中插入数据。
相关知识
在数据表中插入一条记录,对指定字段赋值
INSERT INTO <表名> (<字段1>[,<字段2>…])
VALUES (<表达式1>[,<表达式2>…])
向指定的数据表插入一条记录,并用指定的表达式对各个字段赋值,VALUES短语中各个表达式应该与数据表结构的字段顺序一一对应。
例如:
INSERT INTO spj(sno,jno,pno,qty) VALUES('S1','J1','P1',200);
在数据表中插入一条记录,对所有字段赋值
INSERT INTO <表名> VALUES (<表达式1>[,<表达式2>…])
向指定的数据表插入一条记录,并用指定的表达式对所有字段赋值,VALUES短语中各个表达式应该与数据表结构的字段顺序一一对应。
例如:
INSERT INTO spj VALUES('S1','J1','P1',200);
在数据表中插入多条记录
INSERT INTO <表名> (<字段1>[,<字段2>…])
VALUES (<表达式11>[,<表达式12>…]),(<表达式21>[,<表达式22>…]),(<表达式31>[,<表达式32>…])……
例如:
INSERT INTO spj VALUES('S1','J1','P1',200),('S1','P1','J3',100),('S1','P1','J4',700);
显示数据表的数据
插入数据之后我们可以通过select * from 数据表;命令查看该数据表的所有数据。
例如:
查看s表所有数据
select * from s;
任务要求
分别在s、p、j和spj数据表中插入数据
分别显示s、p、j和spj数据表的所有数据
s、p、j和spj数据表的原始数据如下所示:
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始
#插入s表数据
INSERT INTO s VALUES('S1','精益',20,'天津');
INSERT INTO s VALUES('S2','盛锡',10,'北京');
INSERT INTO s VALUES('S3','东方红',30,'北京');
INSERT INTO s VALUES('S4','丰泰盛',20,'天津');
INSERT INTO s VALUES('S5','为民',30,'上海');#插入p表数据INSERT INTO p VALUES('P1','螺母','红',12);
INSERT INTO p VALUES('P2','螺栓','绿',17);
INSERT INTO p VALUES('P3','螺丝刀','蓝',14);
INSERT INTO p VALUES('P4','螺丝刀','红',14);
INSERT INTO p VALUES('P5','凸轮','蓝',40);
INSERT INTO p VALUES('P6','齿轮','红',30);#插入j表数据
INSERT INTO j VALUES('J1','三建','北京');
INSERT INTO j VALUES('J2','一汽','长春');
INSERT INTO j VALUES('J3','弹簧厂','天津');
INSERT INTO j VALUES('J4','造船厂','天津');
INSERT INTO j VALUES('J5','机车厂','唐山');
INSERT INTO j VALUES('J6','无线电厂','常州');
INSERT INTO j VALUES('J7','半导体厂','南京');
#插入spj表数据
INSERT INTO spj VALUES('S1','P1','J1',200);
INSERT INTO spj VALUES('S1','P1','J3',100);
INSERT INTO spj VALUES('S1','P1','J4',700);
INSERT INTO spj VALUES('S1','P2','J2',100);
INSERT INTO spj VALUES('S2','P3','J1',400);
INSERT INTO spj VALUES('S2','P3','J2',200);
INSERT INTO spj VALUES('S2','P3','J4',500);
INSERT INTO spj VALUES('S2','P3','J5',400);
INSERT INTO spj VALUES('S2','P5','J1',400);
INSERT INTO spj VALUES('S2','P5','J2',100);
INSERT INTO spj VALUES('S3','P1','J1',200);
INSERT INTO spj VALUES('S3','P3','J1',200);
INSERT INTO spj VALUES('S4','P5','J1',100);
INSERT INTO spj VALUES('S4','P6','J3',300);
INSERT INTO spj VALUES('S4','P6','J4',200);
INSERT INTO spj VALUES('S5','P2','J4',100);
INSERT INTO spj VALUES('S5','P3','J1',200);
INSERT INTO spj VALUES('S5','P6','J2',200);
INSERT INTO spj VALUES('S5','P6','J4',500);
#分别查询s、p、j和spj表的所有数据
select * from s;
select * from p;
select * from j;
select * from spj;#代码结束
第四关:数据查询-基础查询
相关知识
基础查询
*查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据
例如:
查询name、age两列
select name,age from stu;
查询所有列的数据,列名的列表可以使用*替代
select * from stu;
上面语句中的不建议大家使用,因为在这写不方便我们阅读sql语句。我们写字段列表的话,可以提高程序的可读性。
而在上课期间为了简约课程的时间,老师很多地方都会写*。
查询地址信息
select address from stu;
执行上面语句结果如下:

从上面的结果我们可以看到有重复的数据,我们也可以使用 distinct 关键字去重重复数据。
*去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
*去除重复记录
select distinct address from stu;
*起别名
SELECT 字段列表 AS 别名 FROM 表名;
AS关键字也可以省略
查询姓名、数学成绩、英语成绩,并通过as给math和english起别名(as关键字可以省略)
select name,math as 数学成绩,english as 英文成绩 from stu;
select name,math 数学成绩,english 英文成绩 from stu;
排序查询
语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
上述语句中的排序方式有两种,分别是:
ASC : 升序排列 (默认值)
DESC : 降序排列
任务要求
请用SQL语句完成下面题目的查询。
查询所有供应商的姓名和所在城市(按供应商姓名升序排列)。
查询所有零件的名称、颜色、重量(按零件名称升序排列)。
注意:数据大小写要保持一致。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始#1. 查询所有供应商的姓名和所在城市(按供应商姓名升序排列)。
select s.sname,s.city from s order by s.sname;#2. 查询所有零件的名称、颜色、重量(按零件名称升序排列)。
select p.pname,p.color,p.weight from p order by p.pname;#代码结束
第五关:数据查询-条件查询
任务描述
本关任务:按题目要求完成数据表的查询。
相关知识
条件查询
语法
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件列表可以使用以下运算符
image-20210722190508272
模糊查询
模糊查询使用like关键字,可以使用通配符进行占位:
_ : 代表单个任意字符
% : 代表任意个数字符
例如:
查询姓’马’的学员信息
select * from stu where name like '马%';
查询第二个字是’花’的学员信息
select * from stu where name like '_花%';
查询名字中包含 ‘德’ 的学员信息
select * from stu where name like '%德%';
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
任务要求
请用SQL语句完成下面题目的查询。
1、查询供应工程J1零件的供应商号码(去除重复,按供应商号码升序排列)。
2、查询供应工程J1零件P1的供应商号码(按供应商号码升序排列)。
3、查询使用供应商S1所供应零件的工程号码(按工程号码升序排列)。
注意:数据大小写要保持一致。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始
#1. 查询供应工程J1零件的供应商号码(去除重复,按供应商号码升序排列)。SELECT distinct spj.sno FROM spj WHERE jno='J1' ; #2. 查询供应工程J1零件P1的供应商号码(按供应商号码升序排列)。SELECT spj.sno FROM spj WHERE spj.jno='J1' AND spj.pno ='P1';#3. 查询使用供应商S1所供应零件的工程号码(按工程号码升序排列)。SELECT spj.jno FROM spj WHERE spj.sno="S1" order by spj.jno;#代码结束第六关:数据查询-连接查询
任务描述
本关任务:按题目要求完成数据表的查询。
相关知识
多表查询
多表查询顾名思义就是从多张表中一次性的查询出我们想要的数据。我们通过具体的示例来进行讲解。
DROP TABLE IF EXISTS emp;
DROP TABLE IF EXISTS dept;# 创建部门表CREATE TABLE dept(did INT PRIMARY KEY AUTO_INCREMENT,dname VARCHAR(20));# 创建员工表CREATE TABLE emp (id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(10),gender CHAR(1), -- 性别salary DOUBLE, -- 工资join_date DATE, -- 入职日期dep_id INT,FOREIGN KEY (dep_id) REFERENCES dept(did) -- 外键,关联部门表(部门表的主键));-- 添加部门数据INSERT INTO dept (dNAME) VALUES ('研发部'),('市场部'),('财务部'),('销售部');-- 添加员工数据INSERT INTO emp(NAME,gender,salary,join_date,dep_id) VALUES('孙悟空','男',7200,'2013-02-24',1),('猪八戒','男',3600,'2010-12-02',2),('唐僧','男',9000,'2008-08-08',2),('白骨精','女',5000,'2015-10-07',3),('蜘蛛精','女',4500,'2011-03-14',1),('小白龙','男',2500,'2011-02-14',null);
执行下面的多表查询语句
select * from emp , dept; -- 从emp和dept表中查询所有的字段数据
结果如下:

从上面的结果我们看到有一些无效的数据,如 孙悟空 这个员工属于1号部门,但也同时关联的2、3、4号部门。所以我们要通过限制员工表中的 dep_id 字段的值和部门表 did 字段的值相等来消除这些无效的数据,
select * from emp , dept where emp.dep_id = dept.did;
执行后结果如下:

上面语句就是连接查询,那么多表查询都有哪些呢?
连接查询

内连接查询 :相当于查询AB交集数据
外连接查询
左外连接查询 :相当于查询A表所有数据和交集部门数据
右外连接查询 : 相当于查询B表所有数据和交集部分数据
子查询
内连接查询
语法
-- 隐式内连接
SELECT 字段列表 FROM 表1,表2… WHERE 条件;
-- 显示内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;
例如
隐式内连接
SELECT * FROM emp, dept
WHERE emp.dep_id = dept.did;
执行上述语句结果如下:

查询 emp的 name, gender和dept表的dname
SELECTemp. NAME,emp.gender,dept.dname
FROMemp,dept
WHEREemp.dep_id = dept.did;
执行语句结果如下:

上面语句中使用表名指定字段所属有点麻烦,sql也支持给表指别名,上述语句可以改进为
SELECTt1. NAME,t1.gender,t2.dname
FROMemp t1,dept t2
WHEREt1.dep_id = t2.did;
显式内连接
select * from emp inner join dept on emp.dep_id = dept.did;
-- 上面语句中的inner可以省略,可以书写为如下语句
select * from emp join dept on emp.dep_id = dept.did;
执行结果如下:

外连接查询
语法
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
– 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
左外连接:相当于查询A表所有数据和交集部分数据
右外连接:相当于查询B表所有数据和交集部分数据

案例
查询emp表所有数据和对应的部门信息(左外连接)
select * from emp left join dept on emp.dep_id = dept.did;
执行语句结果如下:
结果显示查询到了左表(emp)中所有的数据及两张表能关联的数据。
查询dept表所有数据和对应的员工信息(右外连接)
select * from emp right join dept on emp.dep_id = dept.did;
执行语句结果如下:

结果显示查询到了右表(dept)中所有的数据及两张表能关联的数据。
要查询出部门表中所有的数据,也可以通过左外连接实现,只需要将两个表的位置进行互换:
select * from dept left join emp on emp.dep_id = dept.did;
任务要求
请用SQL语句完成下面题目的查询。
查询工程项目J2使用的各种零件的名称及其数量(按零件名称升序排列)。
查询上海厂商供应的所有零件号码(去除重复,按零件号码升序排列)。
查询使用上海产的零件的工程名称(按工程名称升序排列,去除重复数据)。
注意:数据大小写要保持一致。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始#1. 查询工程项目J2使用的各种零件的名称及其数量(按零件名称升序排列)。
select p.pname,spj.qty from p,spj where p.pno=spj.pno and spj.jno='J2' order by p.pname;#2. 查询上海厂商供应的所有零件号码(去除重复,按零件号码升序排列)。
SELECT spj.pno FROM spj WHERE spj.sno IN(SELECT s.`SNO` FROM s WHERE s.city='上海') GROUP BY spj.pno;#3. 查询使用上海产的零件的工程名称(按工程名称升序排列,去除重复数据)。SELECT j.jname FROM j WHERE j.jno IN(SELECT spj.jno FROM spj WHERE spj.sno IN(SELECT s.sno FROM s WHERE s.city='上海')) order by j.jname#代码结束
第七关:数据查询-子查询
相关知识
子查询
概念
查询中嵌套查询,称嵌套查询为子查询。
什么是查询中嵌套查询呢?我们通过一个例子来看:
需求:查询工资高于猪八戒的员工信息。
来实现这个需求,我们就可以通过二步实现,第一步:先查询出来 猪八戒的工资
select salary from emp where name = '猪八戒'
第二步:查询工资高于猪八戒的员工信息
select * from emp where salary > 3600;
第二步中的3600可以通过第一步的sql查询出来,所以将3600用第一步的sql语句进行替换
select * from emp where salary > (select salary from emp where name = '猪八戒');
这就是查询语句中嵌套查询语句。
子查询根据查询结果不同,作用不同
子查询语句结果是单行单列,子查询语句作为条件值,使用 = != > < 等进行条件判断
子查询语句结果是多行单列,子查询语句作为条件值,使用 in 等关键字进行条件判断
子查询语句结果是多行多列,子查询语句作为虚拟表
案例
*查询 '财务部' 和 '市场部' 所有的员工信息
-- 查询 '财务部' 或者 '市场部' 所有的员工的部门did
select did from dept where dname = '财务部' or dname = '市场部';
select * from emp where dep_id in (select did from dept where dname = '财务部' or dname = '市场部');
查询入职日期是 '2011-11-11' 之后的员工信息和部门信息
-- 查询入职日期是 '2011-11-11' 之后的员工信息
select * from emp where join_date > '2011-11-11' ;
-- 将上面语句的结果作为虚拟表和dept表进行内连接查询
select * from (select * from emp where join_date > '2011-11-11' ) t1, dept where t1.dep_id = dept.did;
任务要求
请用SQL语句完成下面题目的查询。
查询供应工程J1零件为红色的供应商号码(按供应商号码升序排列)。
查询没有使用天津供应商生产的红色零件的工程号码(去除重复数据,按工程号码升序排列)。
注意:数据大小写要保持一致。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始#1. 查询供应工程J1零件为红色的供应商号码(按供应商号码升序排列)。SELECT spj.sno FROM spj WHERE spj.jno='J1' and spj.pno in (SELECT p.pno from p where p.color='红');#2. 查询没有使用天津供应商生产的红色零件的工程号码(去除重复数据,按工程号码升序排列)。
#找到天津生产的零件
SELECT DISTINCT jno FROM spj WHERE jno NOT IN (SELECT DISTINCT jno FROM spj NATURAL JOIN p NATURAL JOIN s WHERE city='天津' AND color='红') order by jno asc;#代码结束第八关:修改数据
相关知识
更新表中指定的内容
通过前几关的学习,我们已经掌握了INSERT语句的操作。同样,UPDATE操作也很简单,只要记住UPDATE语句三要素就能轻松掌握,它们分别是:
**需要更新的表(table)名;
需要更新的字段(column)名和它的新内容(value);
决定更新哪一条内容(value)的过滤条件。
语法规则为:
UPDATE 表名 SET 字段名1 = 内容1, 字段名2 = 内容2, 字段名3 = 内容3 WHERE 过滤条件;**
删除表中的指定行
从数据表中删除数据内容需要使用DELETE语句,它需要WHERE语句来配合它来指定我们究竟应该删除哪些数据内容。
语法规则为: DELETE FROM 表名 WHERE 条件语句;
我们可以指定删除某一行的数据内容,当然,我们还可以指定删除很多行的数据内容,区别就在于条件语句。
删除表中的所有行
删除表中的所有行就更简单了。如果需要删除表中所有的行,只需要省略WHERE语句即可。
语法规则为:DELETE FROM 表名;
任务要求
请用SQL语句完成下面题目。
1、把全部红色零件的颜色改成蓝色。
2、由S5供给J4的零件P6改为由S3供应。
3、从供应商关系中删除供应商号是S2的记录,并从供应情况关系中删除相应的记录。
4、请将(S2,J6,P4,200)插入供应情况关系表。
数据修改完后请和原始数据进行比对以查看修改结果。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始
#1. 把全部红色零件的颜色改成蓝色。
UPDATE p SET p.color='蓝' WHERE p.color='红';#2. 由S5供给J4的零件P6改为由S3供应。
UPDATE spj SET spj.sno='S3' WHERE spj.sno='S5' AND spj.pno='P6' and spj.jno='J4';#3. 从供应商关系中删除供应商号是S2的记录,并从供应情况关系中删除相应的记录。DELETE FROM s WHERE s.sno='S2';
DELETE FROM spj WHERE spj.sno='S2';
#4. 请将(S2,J6,P4,200)插入供应情况关系表。
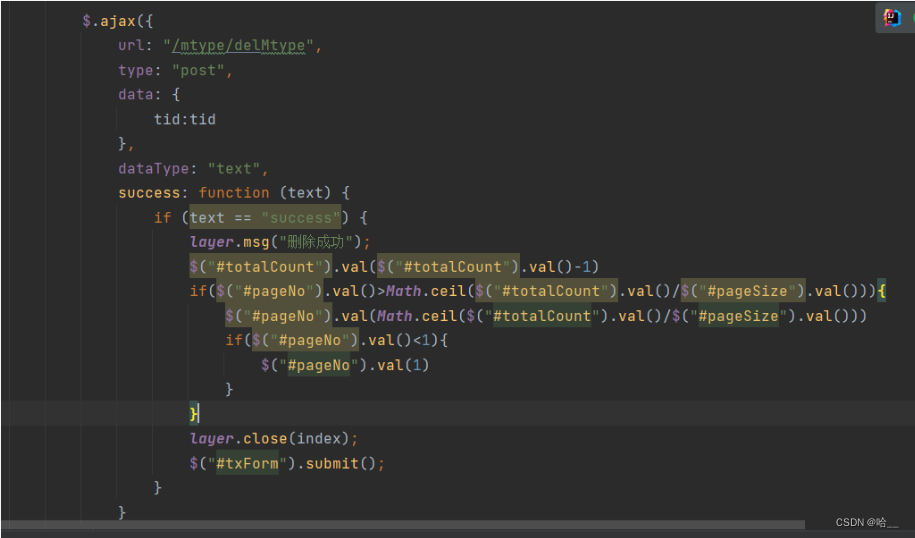
INSERT INTO spj VALUE('S2','P4','J6',200);#代码结束#评测使用,不要删除下面代码
select * from s;
select * from p;
select * from spj;第九关:创建视图
相关知识
聚合函数
概念
将一列数据作为一个整体,进行纵向计算。
如何理解呢?假设有如下表

现有一需求让我们求表中所有数据的数学成绩的总和。这就是对math字段进行纵向求和。
聚合函数分类

聚合函数语法
SELECT 聚合函数名(列名) FROM 表;
注意:null 值不参与所有聚合函数运算
例如:
统计班级一共有多少个学生
select count(id) from stu;
select count(english) from stu;
上面语句根据某个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。所以可以在count() 来实现。 表示所有字段数据,一行中也不可能所有的数据都为null,所以建议使用 count(*)
select count(*) from stu;
查询数学成绩的最高分
select max(math) from stu;
查询数学成绩的最低分
select min(math) from stu;
查询数学成绩的总分
select sum(math) from stu;
查询数学成绩的平均分
select avg(math) from stu;
查询英语成绩的最低分
select min(english) from stu;
分组查询
语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
例如:
查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select name, sex, avg(math) from stu group by sex; -- 这里查询name字段就没有任何意义
查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex;
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math),count(*) from stu where math > 70 group by sex;
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having 区别:
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
定义视图
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。通过视图,可以展现基表(用来创建视图的表)的部分数据;视图数据来自定义视图的查询表。
我们知道了视图的定义,那么,为什么要使用它呢?
因为视图有如下优点:①. 简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。②. 安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行或列,但是通过视图就可以简单的实现。③. 数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列队视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
总而言之,使用视图的大部分情况是为了保障数据安全性,提高查询效率。
创建视图
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]
参数说明:
1、OR REPLACE:表示替换已有视图。
ALGORITHM:表示视图选择算法,默认算法是UNDEFINED(未定义的): MySQL 自动选择要使用的算法 ;merge合并;temptable临时表。
2、column_list:可选参数,指定视图中各个属性的名词,默认情况下与select语句中查询的属性相同。
3、select_statement:表示select语句。
4、[WITH [CASCADED | LOCAL] CHECK OPTION]:表示视图在更新时保证在视图的权限范围之内;cascade是默认值,表示更新视图的时候,要满足视图和表的相关条件;local表示更新视图的时候,要满足该视图定义的一个条件即可。
示例一:

示例二:

以上两个示例可以看出,虽然两个视图的字段名不同,但是,数据是相同的,因为两个视图引用的是同一个表中的数据,并且,as后的创建视图的语句也相同。
在实际开发中,用户可以根据自己的需求,通过视图的方式,获取基本表中自己需要的数据,这样既能满足用户的需求,也不会破坏基本表原来的结构,从而保证了基本表中数据的安全性。
操作视图
视图是逻辑表,也就是说视图不是真实的表,但操作视图和操作普通表的语法是一样的。
用户可以在视图中无条件地使用select语句查询数据。但使用insert、update和delete操作需要在创建视图时满足以下条件(满足以下条件的视图称为可更新视图):
1、from子句中只能引用有1个表(真实表或可更新视图)。
2、不能包含 with、distinct、group by、having、limit等子句。
3、不能使用复合查询,即不能使用union、intersect、except等集合操作。
4、select子句的字段列表不能包含聚合、窗口函数、集合返回函数。
我们仍使用之前示例中的数据来操作视图:

删除视图
若视图不再被需要,我们可以将其删除,且视图的删除并不影响源表中的数据。
删除视图的 SQL 如下:
DROP VIEW view_name;
示例:

查看视图
查看视图是指查看数据库中,已经存在的视图的定义
查看视图,必须要有SHOW VIEW的权限
语法格式
DESCRIBE 视图名;
或者简写
DESC 视图名;
任务要求
1、请为三建工程项目建立一个供应情况的视图(v_spj),包括供应商代码(SNO)、零件代码(PNO)、供应数量(QTY)。
2、查看视图(v_spj)信息。
针对视图(v_spj)完成下列查询:
(1) 查询三建工程项目使用的各种零件代码及其总数量(total)
提示:利用聚合函数sum()和分组查询实现,总数量起别名total。
(2) 查询供应商S1的供应情况。
原始数据如下所示:
s表
(‘S1’,‘精益’,20,‘天津’)
(‘S2’,‘盛锡’,10,‘北京’)
(‘S3’,‘东方红’,30,‘北京’)
(‘S4’,‘丰泰盛’,20,‘天津’)
(‘S5’,‘为民’,30,‘上海’)
p表
(‘P1’,‘螺母’,‘红’,12)
(‘P2’,‘螺栓’,‘绿’,17)
(‘P3’,‘螺丝刀’,‘蓝’,14)
(‘P4’,‘螺丝刀’,‘红’,14)
(‘P5’,‘凸轮’,‘蓝’,40)
(‘P6’,‘齿轮’,‘红’,30)
j表
(‘J1’,‘三建’,‘北京’)
(‘J2’,‘一汽’,‘长春’)
(‘J3’,‘弹簧厂’,‘天津’)
(‘J4’,‘造船厂’,‘天津’)
(‘J5’,‘机车厂’,‘唐山’)
(‘J6’,‘无线电厂’,‘常州’)
(‘J7’,‘半导体厂’,‘南京’)
spj表
(‘S1’,‘P1’,‘J1’,200)
(‘S1’,‘P1’,‘J3’,100)
(‘S1’,‘P1’,‘J4’,700)
(‘S1’,‘P2’,‘J2’,100)
(‘S2’,‘P3’,‘J1’,400)
(‘S2’,‘P3’,‘J2’,200)
(‘S2’,‘P3’,‘J4’,500)
(‘S2’,‘P3’,‘J5’,400)
(‘S2’,‘P5’,‘J1’,400)
(‘S2’,‘P5’,‘J2’,100)
(‘S3’,‘P1’,‘J1’,200)
(‘S3’,‘P3’,‘J1’,200)
(‘S4’,‘P5’,‘J1’,100)
(‘S4’,‘P6’,‘J3’,300)
(‘S4’,‘P6’,‘J4’,200)
(‘S5’,‘P2’,‘J4’,100)
(‘S5’,‘P3’,‘J1’,200)
(‘S5’,‘P6’,‘J2’,200)
(‘S5’,‘P6’,‘J4’,500)
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始
#1. 请为“三建”工程项目建立一个供应情况的视图(v_spj),包括供应商代码(SNO)、零件代码(PNO)、供应数量(QTY)。
CREATE VIEW v_spj(sno,pno,qty) AS SELECT sno,pno,qty FROM spj WHERE jno=(SELECT jno FROM j WHERE jname='三建');#2. 查看视图(v_spj)信息。
desc v_spj;#针对视图(v_spj)完成下列查询:
#(1) 查询“三建”工程项目使用的各种零件代码及其总数量(total)
#提示:利用聚合函数sum()和分组查询实现,总数量起别名total。SELECT pno,SUM(qty) total FROM v_spj GROUP BY pno;#(2) 查询供应商S1的供应情况。sELECT sno,pno,qty FROM v_spj WHERE sno='S1';
#代码结束第十关:定义索引
任务描述
为了完成本关任务,你需要掌握如下知识点:
什么是索引
索引的分类
索引的定义
删除索引
查看索引
相关知识
什么是索引
官方介绍索引是帮助MySQL高效获取数据的数据结构。简单来讲,数据库索引就像是书前面的目录,能加快数据库的查询速度。
事实上,索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。
但对于海量数据来说,它的目录也是很大的,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
索引的分类
单列索引
一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了
1、普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一 点。
2、唯一索引:索引列中的值必须是唯一的,但是允许为空值。
3、主键索引:是一种特殊的唯一索引,不允许有空值。(主键约束,就是一个主键索引)。
组合索引
指在多个字段上创建的索引,在多个字段上创建的普通索引和唯一索引都是组合索引,所谓组合实际是字段的组合,对于多个字段上的唯一索引,要求组合字段必须唯一。
索引的定义
根据创建时机的不同,索引主要有两种创建方式:
在创建表时同时创建普通索引
语法:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
(col_name column_definition,INDEX|KEY [index_name] [index_type] (col_name [(length)] [ASC | DESC])
)index_type:USING {BTREE | HASH}
其中方括号[]中内容表示可选项,竖线|表示两者选一。
col_name:列名;
column_definition:列的具体定义,这里省略了;
INDEX|KEY:表示使用INDEX和KEY都能创建普通索引,因为在MySQL中,INDEX和KEY是一样的。
[index_name]:索引的名字,是可选项,如果没有写,默认使用字段名作为索引的名称,一般以idx_字段名作为前缀来命名;
[index_type]:索引类型,表示索引的数据结构,有两类:BTREE和HASH,如果没有指明,默认是BTREE;
col_name [(length)] [ASC | DESC]:col_name是要添加索引的列,length表示要在类型为字``符串的列的前length个字符构成的字符串上添加索引,[ASC|DESC]表示升序还是降序方式存储索引,默认是升序方式存储;
例如:
CREATE TABLE my_table
(
id INT(11) not NULL auto_increment,
name VARCHAR(20) NOT NULL,
address VARCHAR(20) NOT NULL,
PRIMARY KEY(id),
INDEX idx_name (name)
);
该语句在创建my_table表时,同时在字段name上创建了一个名为idx_name的普通索引。
创建表之后创建索引
(1) 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name (col_name [(length)] [ASC | DESC])
例如:
ALTER TABLE my_table ADD INDEX idx_address(address)
该语句在my_table表的address字段上添加了名为idx_address的普通索引。
(2) 直接创建索引
CREATE INDEX index_name ON table(column[(length)] [ASC|DESC])
例如:
CREATE INDEX idx_name ON my_table(name)
删除索引
删除索引的命令格式:
DROP INDEX index_name ON table_name
查看索引
查看索引的语法格式如下:
SHOW INDEX FROM <表名> [ FROM <数据库名>]
语法说明如下:
<表名>:指定需要查看索引的数据表名。
<数据库名>:指定需要查看索引的数据表所在的数据库,可省略。比如,SHOW INDEX FROM student FROM test; 语句表示查看 test 数据库中 student 数据表的索引。
任务要求
在spj表定义索引IDX_SPJ,包括(sno,pno,jno)。
查看spj表索引定义。
开始你的任务吧,祝你成功!
代码如下:
use demo;#代码开始# 1.在spj表定义索引IDX_SPJ,包括(sno,pno,jno)。
ALTER TABLE spj ADD INDEX IDX_SPJ(sno,pno,jno);# 2. 查看spj表索引定义。
SHOW INDEX FROM spj;#代码结束