大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用27-关于VoVNetV2模型的应用场景,VoVNetV2模型结构介绍。VoVNetV2(Visual Object-Driven Representation Learning Network Version 2)是一种深度学习模型,主要用于计算机视觉领域中的目标检测任务。该模型通过引入“单阶段逐点卷积”的核心设计理念,有效改进了特征图的生成和利用效率,从而在处理大规模图像数据时能够实现更高效的计算性能和更高的检测精度。
VoVNetV2模型结构设计独特,其核心在于构建了一种深度可分离卷积的变体——集中式卷积,这种卷积方式可以将所有输入通道的信息集中到一个单一输出通道上,然后进行逐点卷积操作,以此来减少计算量并增强特征表达能力。此外,VoVNetV2还采用了跨层连接策略,如残差连接和多尺度特征融合机制,以进一步提升模型对不同尺度目标的检测能力。
文章目录
- 一、VoVNetV2模型应用场景阐述
- 1.1:目标检测任务
- 1.2:图像语义分割任务
- 二、VoVNetV2模型结构详细介绍
- 2.1:SAC(Scatter-Attention Convolution)模块
- 2.2:渐进式深度可分离卷积设计
- 四、VoVNetV2模型的数学原理
- 五、VoVNetV2模型的代码实现
- 六、总结
一、VoVNetV2模型应用场景阐述
1.1:目标检测任务
标题1:目标检测任务
VoVNetV2模型在目标检测任务中扮演着重要角色,其核心在于对视觉特征的高效提取与融合。该模型通过引入多尺度特征融合机制和深度可分离卷积等技术,有效提升了目标检测的速度和精度。在处理复杂场景时,VoVNetV2能够自适应地捕获不同大小和比例的目标特征,尤其对于小目标检测具有显著优势。在YOLO、Faster R-CNN等主流目标检测框架中集成VoVNetV2作为主干网络,可以实现更快速准确的目标定位与识别。
想象一下,在一个繁忙的城市街道监控视频中,我们希望实时检测并追踪行人、车辆以及各种交通标志。VoVNetV2模型就像一位经验丰富的“智能侦探”,它能迅速从纷繁复杂的图像信息中抽丝剥茧,精准锁定每一个目标的位置和类别。比如,无论行人是远距离的小像素块,还是近距离占据较大视野的车辆,亦或是微小但关键的交通标志,VoVNetV2都能有效地提取它们的特征并进行准确识别,从而为智能交通管理、安全预警等应用提供有力支持。
1.2:图像语义分割任务
在深度学习领域中,VoVNetV2(Visual Object-ness Network Version 2)模型是一种先进的卷积神经网络结构,尤其适用于图像语义分割任务。图像语义分割是对图像中的每个像素进行分类,以确定其所属的物体类别,是计算机视觉中的一个重要问题。VoVNetV2通过引入多尺度特征融合和高效的通道注意力机制,能够精确地识别并区分图像中的不同对象。
具体来说,在图像语义分割任务中,VoVNetV2模型首先对输入图像进行深层特征提取,利用其特有的连续性金字塔特征模块,实现对图像全局上下文信息的有效捕获,同时保持了局部细节的精准表达。此外,VoVNetV2采用动态卷积的方式,使得模型能灵活适应不同大小和形状的目标,提高了分割精度。
生活实例:假设我们想要让机器自动识别并区分一张家庭照片中的各个元素,如人物、沙发、电视等。这时,应用VoVNetV2模型进行图像语义分割,就能将照片分割成多个区域,并为每个像素赋予正确的标签,如“人”、“家具”等。这样,机器不仅能知道照片中有几个人,还能明确指出每个人所在的具体位置以及他们周围的物品,从而实现对复杂场景的智能理解与解析。
二、VoVNetV2模型结构详细介绍
2.1:SAC(Scatter-Attention Convolution)模块
SAC(Scatter-Attention Convolution)模块是VoVNetV2模型中的核心组成部分,它通过创新的注意力机制改进了传统卷积操作,以实现更高效的特征提取和信息传播。在该模块中,首先对输入特征图进行深度可分离卷积处理,以降低计算复杂度并保持通道间的相互依赖性。接着,通过点播注意力(Point-wise Attention)机制,每个位置的特征都能够自适应地关注到全局上下文信息,从而强化重要特征并抑制无关噪声。这种“散射”式的注意力计算方式使得网络能够动态地调整各位置特征的重要性,实现了对特征图的全局优化。
想象一下,在一个大型图书馆中,图书管理员(SAC模块)需要快速整理各类书籍(特征图)。传统的做法是一本一本独立检查和分类(常规卷积),而SAC模块则采用了一种更为智能的方法。它首先将书籍按照主题大致划分(深度可分离卷积),然后通过全局观察和理解每本书在整个馆藏中的价值与关联(点播注意力机制),有针对性地突出重要书籍或系列书籍,同时减少对不相关或重复信息的关注。这样,不仅提高了工作效率,也使整个图书馆的资源布局更加合理且高效。同样,SAC模块在图像识别任务中,通过对特征图的全局理解和优化,提升了模型的识别精度和效率。
2.2:渐进式深度可分离卷积设计
在VoVNetV2模型中,其创新性地采用了渐进式深度可分离卷积(Progressive Depthwise Separable Convolution, PDSConv)设计。该结构通过逐步增加感受野并保持计算效率的方式,有效提升了模型的特征提取能力。
PDSConv的设计主要包括两部分:深度可分离卷积和渐进式扩张。深度可分离卷积首先将标准卷积分解为深度卷积和逐点卷积两个步骤,前者用于在同一通道内进行特征强化,后者则负责跨通道的信息交互,这种分解方式大大降低了模型的计算复杂度。而在VoVNetV2中,进一步引入了渐进式的扩张策略,即随着网络层级的加深,深度卷积的扩张率逐渐增大,从而使得每一层能够捕获更大范围的空间上下文信息,同时避免了由于扩张率过大导致的细节丢失问题。
假设我们正在制作一幅拼图,每一片拼图代表一种特征。传统的卷积操作就像是快速查看并处理每一片拼图,而深度可分离卷积则是先对单片拼图进行深入理解,再考虑与其他拼图的关系。在此基础上,渐进式深度可分离卷积就像我们在拼图过程中,从关注局部小区域开始,随着进度推进,逐渐扩大观察范围,既保证了对整体布局的把握,又不忽视每个局部细节,最终高效完成整个图像的理解与构建。
四、VoVNetV2模型的数学原理
我大致介绍一下VoVNetV2模型的核心思想,并尝试构建一个基础的数学表达式框架。
VoVNetV2是一种用于目标检测的深度神经网络模型,其主要创新点在于引入了“单阶段卷积”(Single-Stage One-Shot Channel-wise Aggregation, SSOCA)机制,该机制能够在一个单一的卷积层中实现跨层级特征的有效聚合。
在SSOCA机制中,假设输入特征图F,其维度为 C × H × W C \times H \times W C×H×W,其中C为通道数,H和W分别为特征图的高度和宽度。在进行跨层级特征聚合时,可以表示为:
F ^ = SSOCA ( F ) = ∑ i = 1 N W i ∗ F i \hat{F} = \text{SSOCA}(F) = \sum_{i=1}^{N} W_i * F_i F^=SSOCA(F)=i=1∑NWi∗Fi
其中, F i F_i Fi代表第i个层级的特征图, W i W_i Wi是对应的可学习权重, SSOCA \text{SSOCA} SSOCA是对这些层级特征进行聚合的操作, F ^ \hat{F} F^是聚合后的特征图。
然而,这只是对VoVNetV2模型核心机制的一个简化表述,实际的数学表达会更复杂,包括但不限于涉及多尺度特征融合、注意力机制等高级操作。要得到详细的数学表达式,需要查阅具体论文中的技术细节。
五、VoVNetV2模型的代码实现
由于VoVNetV2模型的完整实现涉及到大量的层定义和复杂的网络结构,这里仅提供一个简化版的VoVNetV2模型在PyTorch中的基本实现框架。实际应用中,请参考官方论文或开源库进行详细实现。
import torch
import torch.nn as nn
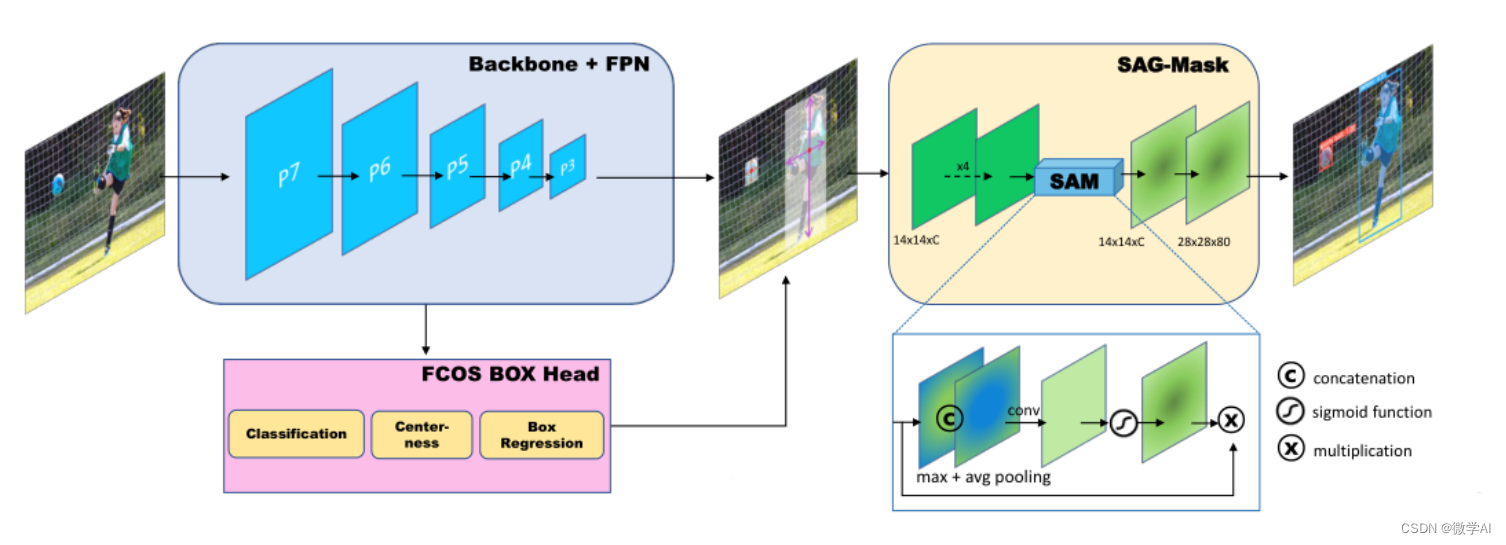
import torchvision__all__ = ['VoVNet', 'vovnet27_slim', 'vovnet39', 'vovnet57']def Conv3x3BNReLU(in_channels,out_channels,stride,groups=1):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))def Conv3x3BN(in_channels,out_channels,stride,groups):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups, bias=False),nn.BatchNorm2d(out_channels))def Conv1x1BNReLU(in_channels,out_channels):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))def Conv1x1BN(in_channels,out_channels):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),nn.BatchNorm2d(out_channels))class eSE_Module(nn.Module):def __init__(self, channel,ratio = 16):super(eSE_Module, self).__init__()self.squeeze = nn.AdaptiveAvgPool2d(1)self.excitation = nn.Sequential(nn.Conv2d(channel, channel, kernel_size=1, padding=0),nn.ReLU(inplace=True),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.squeeze(x)z = self.excitation(y)return x * z.expand_as(x)class OSAv2_module(nn.Module):def __init__(self, in_channels,mid_channels, out_channels, block_nums=5):super(OSAv2_module, self).__init__()self._layers = nn.ModuleList()self._layers.append(Conv3x3BNReLU(in_channels=in_channels, out_channels=mid_channels, stride=1))for idx in range(block_nums-1):self._layers.append(Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1))self.conv1x1 = Conv1x1BNReLU(in_channels+mid_channels*block_nums,out_channels)self.ese = eSE_Module(out_channels)self.pass_conv1x1 = Conv1x1BNReLU(in_channels, out_channels)def forward(self, x):residual = xoutputs = []outputs.append(x)for _layer in self._layers:x = _layer(x)outputs.append(x)out = self.ese(self.conv1x1(torch.cat(outputs, dim=1)))return out + self.pass_conv1x1(residual)class VoVNet(nn.Module):def __init__(self, planes, layers, num_classes=2):super(VoVNet, self).__init__()self.groups = 1self.stage1 = nn.Sequential(Conv3x3BNReLU(in_channels=3, out_channels=64, stride=2, groups=self.groups),Conv3x3BNReLU(in_channels=64, out_channels=64, stride=1, groups=self.groups),Conv3x3BNReLU(in_channels=64, out_channels=128, stride=1, groups=self.groups),)self.stage2 = self._make_layer(planes[0][0],planes[0][1],planes[0][2],layers[0])self.stage3 = self._make_layer(planes[1][0],planes[1][1],planes[1][2],layers[1])self.stage4 = self._make_layer(planes[2][0],planes[2][1],planes[2][2],layers[2])self.stage5 = self._make_layer(planes[3][0],planes[3][1],planes[3][2],layers[3])self.avgpool = nn.AdaptiveAvgPool2d(output_size=1)self.flatten = nn.Flatten()self.dropout = nn.Dropout(p=0.2)self.linear = nn.Linear(in_features=planes[3][2], out_features=num_classes)def _make_layer(self, in_channels, mid_channels,out_channels, block_num):layers = []layers.append(nn.MaxPool2d(kernel_size=3, stride=2, padding=1))for idx in range(block_num):layers.append(OSAv2_module(in_channels=in_channels, mid_channels=mid_channels, out_channels=out_channels))in_channels = out_channelsreturn nn.Sequential(*layers)def init_params(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.stage1(x)x = self.stage2(x)x = self.stage3(x)x = self.stage4(x)x = self.stage5(x)x = self.avgpool(x)x = self.flatten(x)x = self.dropout(x)out = self.linear(x)return outdef vovnet27_slim(**kwargs):planes = [[128, 64, 128],[128, 80, 256],[256, 96, 384],[384, 112, 512]]layers = [1, 1, 1, 1]model = VoVNet(planes, layers)return modeldef vovnet39(**kwargs):planes = [[128, 128, 256],[256, 160, 512],[512, 192, 768],[768, 224, 1024]]layers = [1, 1, 2, 2]model = VoVNet(planes, layers)return modeldef vovnet57(**kwargs):planes = [[128, 128, 256],[256, 160, 512],[512, 192, 768],[768, 224, 1024]]layers = [1, 1, 4, 3]model = VoVNet(planes, layers)return modelclass SAG_Mask(nn.Module):def __init__(self, in_channels, out_channels):super(SAG_Mask, self).__init__()mid_channels = in_channelsself.fisrt_convs = nn.Sequential(Conv3x3BNReLU(in_channels=in_channels, out_channels=mid_channels, stride=1),Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1),Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1),Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1))self.avg_pool = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)self.max_pool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.conv3x3 = Conv3x3BNReLU(in_channels=mid_channels*2, out_channels=mid_channels, stride=1)self.sigmoid = nn.Sigmoid()self.deconv = nn.ConvTranspose2d(mid_channels,mid_channels,kernel_size=2, stride=2)self.conv1x1 = Conv1x1BN(mid_channels,out_channels)def forward(self, x):residual = x = self.fisrt_convs(x)aggregate = torch.cat([self.avg_pool(x), self.max_pool(x)], dim=1)sag = self.sigmoid(self.conv3x3(aggregate))sag_x = residual + sag * xout = self.conv1x1(self.deconv(sag_x))return outif __name__=='__main__':model = vovnet27_slim()#print(model)input = torch.randn(1, 3, 64, 64)out = model(input)print(out.shape)sag_mask = SAG_Mask(16,80)print(sag_mask)input = torch.randn(1, 16, 14, 14)out = sag_mask(input)print(out.shape)
六、总结
VoVNetV2,即视觉对象驱动表征学习网络第二版,是一种专为计算机视觉领域目标检测任务设计的深度学习模型。该模型创新性地运用了“单阶段逐点卷积”理念,显著提升了特征图生成与利用效率,尤其在处理大规模图像数据时,表现出卓越的计算性能和高检测精度。VoVNetV2的关键结构特点是采用了一种深度可分离卷积的变体——集中式卷积,它能将所有输入通道信息汇聚至单一输出通道并执行逐点卷积,从而降低计算复杂度并强化特征表达力。此外,模型还融合了残差连接和多尺度特征融合技术,增强了对不同尺寸目标的检测能力。VoVNetV2模型凭借高效、轻量级以及精准的特性,在诸多实时目标检测应用场景中展现出广泛应用价值,例如视频监控、自动驾驶及无人机导航等。同时,由于其优越的性能,VoVNetV2也被广泛应用在图像识别、物体定位等多种视觉任务中。