1、什么是消息队列?
是一个用于存放数据的组件,用于系统之间或者是模块之间的消息传递。
2、消息队列的应用场景?
主要是用于模块之间的解耦合、异步处理、日志处理、流量削峰
3、什么是kafka?
kafka是一种基于订阅发布模式的高性能,高吞吐的实时的消息队列,是一个分布式系统,高性能的TCP网络协议进行的。
4、消息队列的模式主要分成两种模式?
a、生产者、消费者模式
b、消息队列模式
5、kafka的组成:
kafaka主要是由生产者、消费者、broker、zookeeper组成
其中:
生产者:生产数据
消费者:消费数据
broker:是kafka集群中服务器节点
topic:一个topic是kafka集群中数据流中的列别,存储数据
partition:一个topic可以分成多个分区。
replica:副本,实现kafka集群的容错
consumer group:消费者组,对于同一个消费者中的消费者可以消费同一个topic
offset:偏移量,对于消费者和partition来说,可以通过offset进行拉取数据。
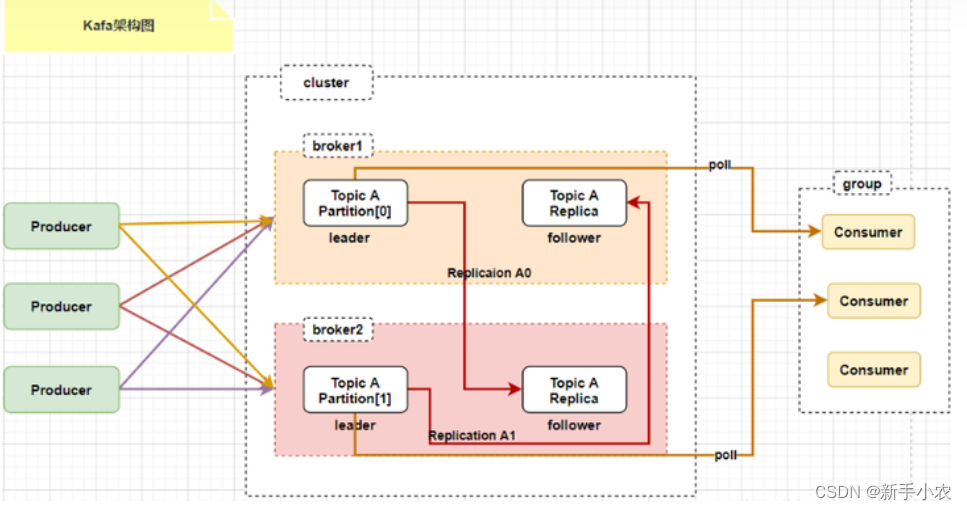
6、在kafka集群中,对于分区也分leader和follower(在分区的层面上讨论)
leader :只负责读写数据
follower:负责同步数据,选举作用。
7、幂等性:
所谓的幂等性就是无论生产者向broker中发送多少条数据,broker只会持久化一条数据
实现原理:
当生产者生产完数据就会发送到分区中进行保存,此时kafka就会向生产者发送ack信号,当生产者接受的ack响应表示数据保存,否则就会重新发送一条相同的数据。
8、副本的ack机制:
1、acks=0,生产者只负责写入数据,不管数据是否写入成功,数据可能会丢失,性能是最好的。
2、acks=1,生产者将数据写入到leader中,返回写入成功,就会继续发送下一条数据
3、acks=-1/all,生产者将数据写入到leader中,同时也会将数据写入到副本中,当所有的数据都写入成功后,就返回写入成功,才会发送下一条数据。
9、生产者写入分区的策略:
1、轮询负载策略:将数据循环写入分区中
2、基于hash的分区策略:根据hash的值进入不同的分区中
3、基于key写入分区:通过hash值与分区的个数继续取余,但是会导致数据倾斜。
4、消费者消费数分区分配策略:默认使用的是range分配。
10、leader选举:
在kafka集群中,controller是通过zk进行选举。在分区中的leader是通过ISR进行选举的。
11、kafka的读写流程:
kafka的读数据:
1、通过zk找出partition对应的leader,leader负责读取数据。
2、通过zk找出对应的消费者的offset
3、leader从对应的offset开始读取数据
4、提交offset
kafka的写数据
1、通过zk找到对应的partition对应的leader,leader负责写入数据
2、生产者向leader中写入数据
3、ISR中的fllower负责同步数据,并返回ack给leader。
4、返回ack给生产者。
12、kafka性能高的原因:
1、kafka采用的是一个sendfile的零拷贝技术
2、kafka是批量写入和读取的,一批批的写入数据,默认写入和读取的大小月约64kb左右。
3、kafka写磁盘是顺序读取和写入的。
13、kafka中的文件删除策略:
默认是7天作为一个周期,删除的是整个文件,系统默认是1G生成一个文件,可以在配置文件中修改:
server.properties14、kafka中分区的目的:
实现分布式,一个topic的数据量非常大,只存在同一个分区中压力会比较大。
15、在Kafka中是如何保证数据不丢失:
1、broker保证数据不丢失的原因是副本机制
2、生产者保证数据不丢失的原因是acks机制
3、消费者保证数据不丢失的原因是控制offset
16、zk在Kafka中作用:
1、负责选举controller
2、存储元数据信息
17、kafka的架构:
主节点:controller
从节点:borker
18、消费者和消费者组的关系:
1、消费者是负责订阅分区中的数据,然而对于消费者组来说是负责订阅topic的
2、一个消费者组中包含多个消费者,同一个消费者组中消费者可以订阅同一个topic
19、在Kafka中是如何保证数据的安全性
是通过kafka中的副本机制保证了数据的安全性。
20、怎么解决kafka数据量过大
1、可以增加topic的分区数,可以提高并行处理更多的数据
kafka-topics.sh --zookeeper localhost:2181 --alter --topic my-topic --partitions 102、增加副本因子,可以提高数据的冗余,提高数据的可靠性
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic my-topic --replication-factor 33、调整消费者的并行度
4、优化生产者配置:
batch.size:增加批处理提高吞吐量5、配置清理策列:根据数据保留策略配置日志保留时间和日志大小,定期清理旧数据
6、扩大kafka集群的规模:增加broker节点的数量
21、在Kafka中生产者是如何保证数据不丢失的
通过acks机制保证数据不丢失。
22、kafka中是如何保证数据不重复的
在kafka中使用幂等性来保证数据不重复的,在发送数据的时候,会给数据定义一个编号ID,当下次传输数据的时候ID+1,将数据写入的时候会记住这个编号,如果下一条数据的ID与上一个数据的ID一致,那么说明数据重复,不写入,返回ack。
23、消费者出问题,如何保证数据不丢失
kafka中使用commit offset 机制,会将消费的位置存储到comsumer-offset文件中。
24、什么是AR、ISR、OSR
AR:所有的副本
ISR:健康的副本
OSR:有问题的副本