Decoupled Multimodal Distilling for Emotion Recognition 论文阅读
- Abstract
- 1. Introduction
- 2. Related Works
- 2.1. Multimodal emotion recognition
- 2.2. Knowledge distillation
- 3. The Proposed Method
- 3.1. Multimodal feature decoupling
- 3.2. GD with Decoupled Multimodal Features
- 3.3. Objective optimization
- 4. Experiments
- 5. Conclusion and discussion
文章信息:

原文链接:https://arxiv.org/abs/2303.13802
源码:https://github.com/mdswyz/DMD
发表于:CVPR 2023
Abstract
这项工作旨在通过语言、视觉和声音等多种形式感知人类情感,即人类多模态情感识别(MER)。尽管先前的MER方法表现出色,但固有的多模态异质性仍然存在,不同模态的贡献差异显著。为了解决这个问题,我们提出了一种分离式多模态蒸馏(DMD)方法,通过促进灵活和自适应的跨模态知识蒸馏,旨在增强每种模态的区分特征。特别地,每种模态的表示被分解为两部分,即与模态无关/独占的空间,以自回归方式进行。DMD利用图蒸馏单元(GD-Unit)对每个分离的部分进行处理,以便每个GD可以以更专业和有效的方式执行。GD-Unit由一个动态图组成,其中每个顶点代表一个模态,每条边表示动态知识蒸馏。这种GD范式提供了一种灵活的知识传递方式,其中蒸馏权重可以自动学习,从而实现多样化的跨模态知识传递模式。实验结果表明,DMD始终比最先进的MER方法具有更好的性能。可视化结果显示,DMD中的图边展示了与模态无关/独占特征空间相关的有意义的分布模式。代码已在https://github.com/mdswyz/DMD上发布。
1. Introduction
人类多模态情感识别(MER)旨在从视频剪辑中感知人类的情感态度。视频流涉及来自各种模态的时间序列数据,例如语言、声音和视觉。这种丰富的多模态性有助于我们从协同的角度理解人类行为和意图。最近,MER已成为情感计算中最活跃的研究课题之一,具有丰富的吸引力应用,例如智能辅导系统、产品反馈估计和机器人技术。
对于MER来说,同一视频片段中的不同模态通常是相辅相成的,为语义和情感消歧提供额外线索。MER的核心部分是多模态表示学习和融合,其中模型旨在编码和整合来自多个模态的表示,以理解原始数据背后的情感。尽管主流MER方法取得了一定成就,但不同模态之间的内在异质性仍然困扰着我们,增加了健壮的多模态表示学习的难度。不同的模态,例如图像、语言和声音,包含传达语义信息的不同方式。通常,语言模态由有限的转录文本组成,其语义比非语言行为更为抽象。如图1(a)所示,语言在MER中起着最重要的作用,而内在的异质性导致不同模态之间的性能差异显著。
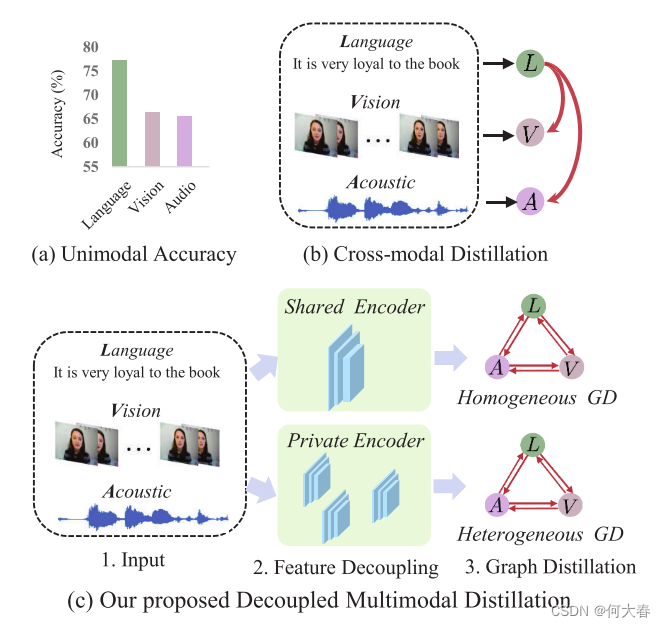
图1. (a) 描述了使用单模态的情感识别存在显著差异,改编自Mult [28]。 (b) 展示了传统的跨模态蒸馏方法。 ( c) 展示了我们提出的分离式多模态蒸馏(DMD)方法。DMD包括两个图蒸馏(GD)单元:同质GD和异质GD。分离式GD范式减少了吸收异质数据知识的负担,并允许每个GD以更专业和有效的方式执行。
缓解显著的模态异质性的一种方法是从强模态向弱模态提炼可靠和可泛化的知识[6],如图1(b)所示。然而,对于蒸馏方向或权重的手动分配应该是繁琐的,因为存在各种潜在的组合。相反,模型应该学会根据不同的示例自动调整蒸馏,例如,许多情感通过语言更容易识别,而一些情感通过视觉更容易识别。此外,跨模态之间显著的特征分布不匹配使得直接的跨模态蒸馏效果不佳[21, 37]。
为此,我们提出了一种分离式多模态蒸馏(DMD)方法,以学习跨模态的动态蒸馏,如图1(c)所示。通常,每种模态的特征通过共享编码器和私有编码器分解为模态无关/独占空间。为了实现特征分解,我们设计了一种自回归机制,预测分解后的模态特征,然后自监督地回归它们。为了加强特征分解,我们加入了一个边缘损失,规范了跨模态和情感表示之间的关系近似性。因此,分离式GD范式将减少从异质数据中吸收知识的负担,并允许每个GD以更专业和有效的方式执行。
基于分离的多模态特征空间,DMD利用每个空间中的图蒸馏单元(GD-Unit),以便以更专业和有效的方式执行跨模态知识蒸馏。一个GD-Unit由一个图组成,其中(1)顶点代表来自模态的表示或逻辑,(2)边表示知识蒸馏的方向和权重。当模态无关(同质)特征之间的分布差距足够减小时,GD可以直接应用于捕获跨模态的语义相关性。对于模态独占(异质)特征,我们利用多模态转换器[28]来建立语义对齐并弥合分布差距。多模态转换器中的跨模态注意机制强化了多模态表示,并减少了存在于不同模态中的高级语义概念之间的差异。为了简化,我们分别将在分离的多模态特征上的蒸馏称为同质图知识蒸馏(HomoGD)和异质图知识蒸馏(HeteroGD)。这种重新表述使我们能够明确探索每个分离空间中不同模态之间的交互作用。
这项工作的贡献可以概括为:
- 我们提出了一种分离式多模态蒸馏框架,称为Decoupled Multimodal Distillation(DMD),用于学习跨模态的动态蒸馏,以实现强大的MER。在DMD中,我们明确地将多模态表示分解为模态无关/-独占空间,以便在两个分离空间上进行知识蒸馏。DMD提供了一种灵活的知识传递方式,其中蒸馏方向和权重可以自动学习,从而实现灵活的知识传递模式。
- 我们在公开的MER数据集上进行了全面的实验,并获得了优越或可比较的结果,超过了当前技术水平。可视化结果验证了DMD的可行性,图边展示了与HomoGD和HeteroGD相关的有意义的分布模式。
2. Related Works
2.1. Multimodal emotion recognition
多模态情感识别(MER)旨在从视频剪辑中嵌入的语言、视觉和声音信息中推断出人类情感。不同模态之间的异质性可以为MER提供不同层次的信息。主流的MER方法可以分为两类:基于融合策略的[14, 33, 34]和基于跨模态注意力的[13, 17, 28]。
前者旨在设计复杂的多模态融合策略,以生成具有区分性的多模态表示,例如,Zadeh等人[33]设计了一种张量融合网络(TFN),可以逐步融合多模态信息。然而,不同模态之间的固有异质性和内在的信息冗余阻碍了多模态特征之间的融合。因此,一些工作旨在通过特征分解探索多模态表示的特征和共性,以促进更有效的多模态表示融合[7, 29, 32]。Hazarika等人[7]将多模态特征分解为模态不变/特定组件,以学习精细化的多模态表示。分离的多模态表示减少了信息冗余,并提供了多模态数据的整体视图。最近,基于跨模态注意力的方法推动了MER的发展,因为它们学习跨模态相关性,以获得增强的模态表示。代表性工作是MulT [28]。该工作提出了一个多模态转换器,由跨模态注意力机制组成,用于学习从一种模态到另一种模态的潜在适应性和相关性,从而实现模态之间的语义对齐。Lv等人[17]基于[28]设计了一种基于渐进模态增强的方法,旨在学习从多模态表示到单模态表示的潜在适应性和相关性。我们提出的DMD与之前的特征分解方法[7, 29, 32]有着本质上的不同,因为DMD能够在分离的特征空间中提炼跨模态知识。
2.2. Knowledge distillation
知识蒸馏(KD)的概念最早在[9]中提出,通过最小化教师和学生的预测逻辑之间的KL散度来传递知识。随后,基于[9]提出了各种KD方法[4, 5, 20, 39],并进一步扩展到中间特征之间的蒸馏[1, 8, 22, 27]。
大多数知识蒸馏(KD)方法侧重于将知识从教师传递给学生,而一些最近的研究则利用图结构探索了多个教师和学生之间有效的消息传递机制,以及多个实例的知识[16, 19, 38]。张等人[38]提出了一种用于视频分类的图蒸馏(GD)方法,其中每个顶点代表一个自监督教师,边表示从多个自监督教师到学生的蒸馏方向。罗等人[16]考虑了模态差异,以将源域的特权信息纳入,并建模了一个有向图来探索不同模态之间的关系。每个顶点代表一个模态,边表示一个模态与另一个模态之间的连接强度(即蒸馏强度)。与它们不同的是,我们旨在在分离的特征空间中使用独占的GD单元,以促进有效的跨模态蒸馏。
3. The Proposed Method
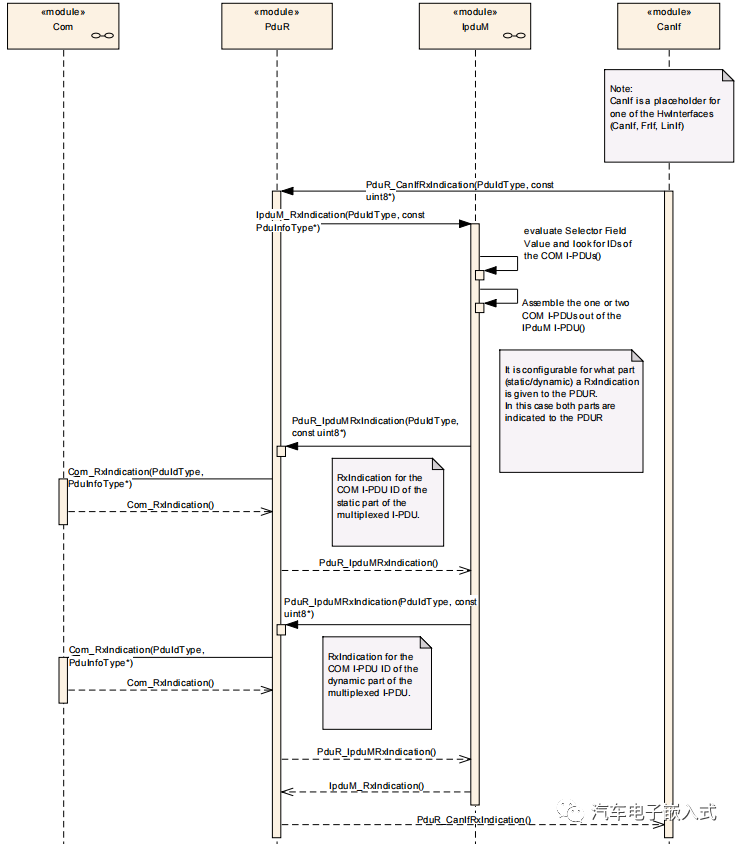
我们的DMD框架如图2所示。主要包括三个部分:多模态特征分离、同质图蒸馏(HomoGD)、异质图蒸馏(HeteroGD)。考虑到模态之间的显著分布不匹配,我们通过学习共享和独占的多模态编码器,将多模态表示分解为同质和异质多模态特征。分离的详细过程在第3.1节中介绍。为了促进灵活的知识传递,接下来我们从同质/异质特征中提取知识,这些特征被设计成两个图蒸馏单元(GD-Unit),即同质图蒸馏和异质图蒸馏。在同质图蒸馏中,同质多模态特征相互蒸馏,以补偿彼此的表征能力。在异质图蒸馏中,引入了多模态transform来明确建立模态间的相关性和语义对齐,以进一步提取特征。蒸馏的详细过程在第3.2节中介绍。最后,通过蒸馏得到的精炼的多模态特征被自适应地融合,用于强大的MER。接下来,我们将介绍DMD的三个部分的细节。
3.1. Multimodal feature decoupling
我们考虑三种模态,即语言( L \mathcal{L} L)、视觉( V V V)和声音( A A A)。首先,我们利用三个单独的一维时间卷积层来聚合时间信息,并获得低层次的多模态特征: X ~ m ∈ R T m × d m \tilde{\mathbf{X}}_m\in \mathbb{R} ^{T_m\times d_m} X~m∈RTm×dm,其中 m ∈ { L , V , A } m\in \{ \mathcal{L}, V, A\} m∈{L,V,A} 表示一个模态。在这种浅层编码之后,每个模态都保留了输入的时间维度,以便同时处理不对齐和对齐的情况。此外,为了方便后续的特征分离,所有模态都被缩放到相同的特征维度,即 d L = d V = d A = d d_\mathcal{L}=d_V=d_A=d dL=dV=dA=d。
为了将多模态特征分解为同质(与模态无关)部分 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom和异质(模态独占)部分 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt,我们利用一个共享的多模态编码器 ε c o m \varepsilon^\mathrm{com} εcom和三个私有编码器 ε m p r t \varepsilon_m^\mathrm{prt} εmprt来明确预测分解后的特征。形式上,
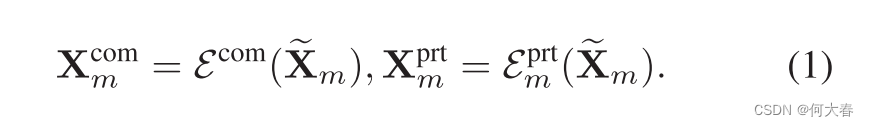
为了区分 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom和 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt之间的差异并减少特征的歧义性,我们以自回归的方式合成了原始的耦合特征 X m \mathbf{X}_m Xm。从数学上讲,我们对每个模态的 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom和 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt进行连接,并利用一个私有解码器 D m \mathcal{D}_m Dm来生成耦合特征,即 D m ( [ X m c o m , X m p r t ] ) \mathcal{D}_m([\mathbf{X}_m^\mathrm{com},\mathbf{X}_m^\mathrm{prt}]) Dm([Xmcom,Xmprt])。随后,耦合特征将通过私有编码器 E m p r t \mathcal{E}_m^\mathrm{prt} Emprt重新编码,以回归异质特征。符号 [ . ] [.] [.]表示特征的连接。形式上,原始/合成的耦合多模态特征之间的差异可以被表示为:
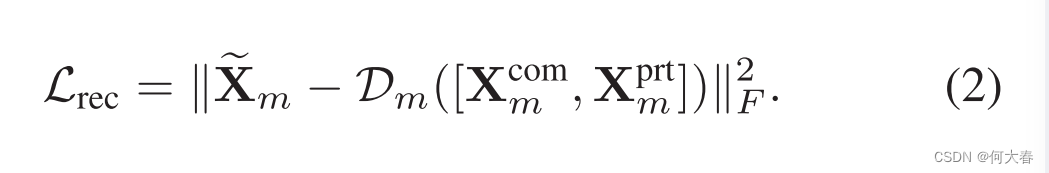
此外,原始/合成的异质特征之间的差异可以表示为:
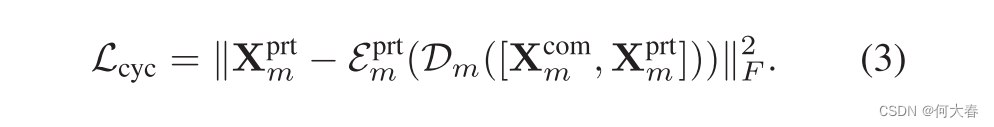
对于上述的重构损失,仍然不能保证完全的特征分离。事实上,信息可以在表示之间自由泄漏,例如,所有的模态信息可能仅仅被编码在 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt中,以便解码器可以轻松地合成输入,从而使得同质多模态特征变得无意义。为了巩固特征的分离,我们认为来自相同情感但不同模态的同质表示应该比来自相同模态但不同情感的表示更相似。为此,我们定义了一个边缘损失:
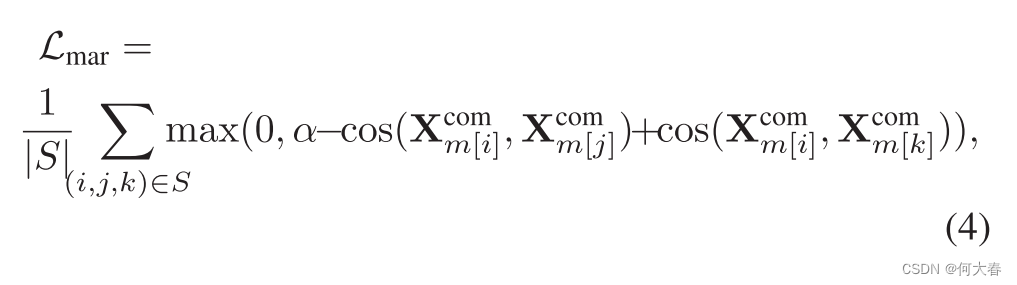
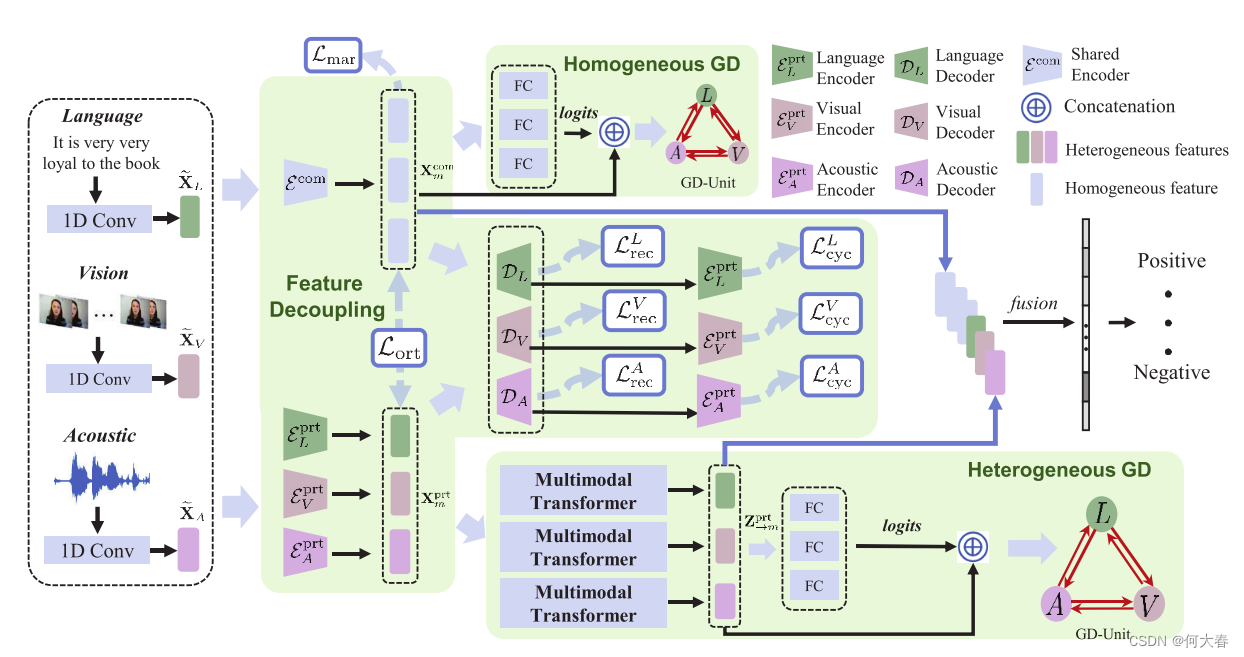
图2. DMD的框架。给定输入的多模态数据,DMD对它们分别进行编码,得到浅层特征 X ~ m \tilde{\mathbf{X}}_m X~m,其中 m ∈ { L , V , A } m\in\{\mathcal{L},V,A\} m∈{L,V,A}。在特征分离阶段,DMD利用共享和独占编码器分别提取分离的同质/异质多模态特征 X m c o m / X m p r t \mathbf{X}_m^\mathrm{com}/\mathbf{X}_m^\mathrm{prt} Xmcom/Xmprt。 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt将以自回归的方式进行重构(第3.1节)。随后, X m c o m \mathcal{X}_m^\mathrm{com} Xmcom将被输入到一个GD单元中,进行自适应的知识蒸馏,即 H o m o G D HomoGD HomoGD。在 H e t e r o G D HeteroGD HeteroGD中,通过多模态转换器将 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt增强到 Z → m p r t \mathbb{Z}_{\to m}^\mathrm{prt} Z→mprt,以弥合分布差距。 H e t e r o G D HeteroGD HeteroGD中的GD单元以 Z → m p r t \mathbf{Z}_{\to m}^\mathrm{prt} Z→mprt作为输入进行蒸馏(第3.2节)。最后, X m c o m \mathbf{X}_m^\mathrm{com} Xmcom和 Z → m p r t \mathbb{Z}_{\to m}^\mathrm{prt} Z→mprt将被自适应地融合用于MER。
我们收集了一个三元组集合 S = { ( i , j , k ) ∣ m [ i ] ≠ m [ j ] , m [ i ] = m [ k ] , c [ i ] = c [ j ] , c [ i ] ≠ c [ k ] } S = \{(i, j, k) | m[i] \neq m[j], m[i] = m[k], c[i] = c[j], c[i] \neq c[k]\} S={(i,j,k)∣m[i]=m[j],m[i]=m[k],c[i]=c[j],c[i]=c[k]}。这里, m [ i ] m[i] m[i]表示样本 i i i的模态, c [ i ] c[i] c[i]表示样本 i i i的类标签, c o s ( ⋅ , ⋅ ) cos(·, ·) cos(⋅,⋅)表示两个特征向量之间的余弦相似性。方程4中的损失限制了属于相同情绪但不同模态,或反之亦然的同质特征之间的差异,从而避免了得到琐碎的同质特征。α是一个距离裕度,用于确保正样本(相同情绪;不同模态)的距离小于负样本(相同模态;不同情绪)的距离,其差距为α。考虑到解耦的特征分别捕获模态无关/排他性特征,我们进一步制定了软正交性,以减少同质和异质多模态特征之间的信息冗余:
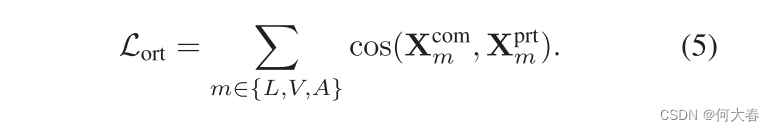
最后,我们将这些约束结合起来形成解耦损耗,
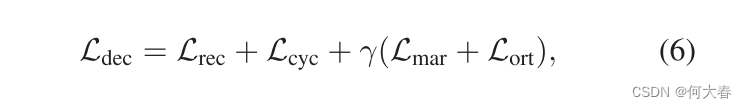
其中γ是平衡因子。
3.2. GD with Decoupled Multimodal Features
针对解耦的同质和异质多模态特征,我们设计了一个图蒸馏单元(GDUnit)来进行自适应的知识蒸馏。通常,一个GDUnit包括一个有向图 G \mathcal{G} G。设 v i v_i vi表示一个与某个模态相关的节点, w i → j w_{i\to j} wi→j表示从模态 v i v_i vi到 v j v_j vj的蒸馏强度。从 v i v_i vi到 v j v_j vj的蒸馏被定义为它们对应logits之间的差异,用 ϵ i → j \epsilon_{i\to j} ϵi→j表示。设 E E E表示具有 E i j = ϵ i → j E_{ij}=\epsilon_{i\to j} Eij=ϵi→j的蒸馏矩阵。对于目标模态 j j j,加权蒸馏损失可以通过考虑注入边来制定,
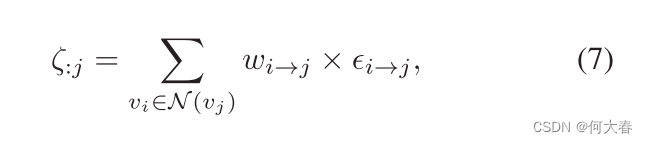
其中 N ( v j ) \mathcal{N}(v_j) N(vj)表示注入到 v j v_j vj的顶点的集合。
为了学习与蒸馏强度 w w w对应的动态自适应权重,我们提出将模态logits和表示编码到图的边上。形式上,
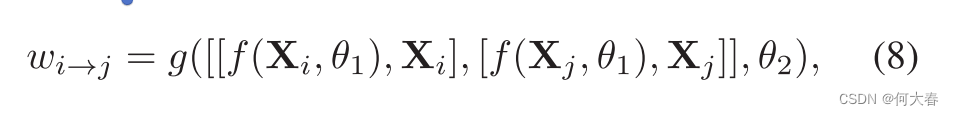
其中, [ ⋅ , ⋅ ] [\cdot,\cdot] [⋅,⋅]表示特征连接, g g g是一个具有可学习参数 θ 2 \theta_2 θ2的全连接(FC)层, f f f是一个用于回归logits的具有参数 θ 1 \theta_1 θ1的FC层。图的边权重 W W W,其中 W i j = w i → j W_{ij}=w_{i\to j} Wij=wi→j,可以通过重复应用方程8来构建和学习所有模态对之间的边。为了减少尺度效应,我们通过softmax操作对 W W W进行归一化。因此,对所有模态的图蒸馏损失可以写成:
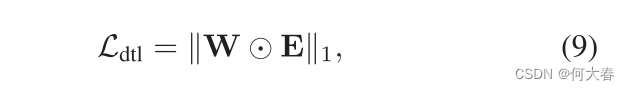
其中, ⊙ \odot ⊙表示逐元素乘积。显然,GD单元中的蒸馏图为学习动态的跨模态交互提供了基础。同时,它还促进了一种灵活的知识传递方式,其中蒸馏强度可以自动学习,从而实现多样化的知识传递模式。接下来,我们详细说明HomoGD和HeteroGD的细节。
HomoGD。如图2所示,对于解耦的同质特征 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom,由于模态之间的分布差距已经足够减少,我们将特征 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom及其对应的logits f ( X m c o m ) f(\mathbf{X}_m^\mathrm{com}) f(Xmcom) 输入到一个GDUnit中,并根据方程8计算图边权重矩阵 W W W和蒸馏损失矩阵 E E E。然后,通过方程 9. \color{red}{9.} 9.,可以自然地得到总的蒸馏损失 L d t l h o m o \mathcal{L}_\mathrm{dtl}^\mathrm{homo} Ldtlhomo。
HeteroGD。解耦的异质特征 X m p r t \mathbf{X}_m^\mathrm{prt} Xmprt聚焦于每个模态的多样性和独特特征,因此展现出显著的分布差距。为了缓解这个问题,我们利用多模态transform[28]来弥合特征分布差距并建立模态适应性。多模态transform的核心是跨模态注意力单元(CA),它接收来自一对模态的特征并融合跨模态信息。以语言模态 X L p r t \mathbf{X}_L^\mathrm{prt} XLprt为源和视觉模态 X V p r t \mathbf{X}_V^\mathrm{prt} XVprt为目标,跨模态注意力可以定义为: Q V = X V p r t P q \mathbf{Q}_V=\mathbf{X}_V^\mathrm{prt}\mathbf{P}_q QV=XVprtPq, K L = X L p r t P k \mathbf{K}_L= \mathbf{X}_L^\mathrm{prt}\mathbf{P}_k KL=XLprtPk, 和 V L = X L p r t P v \mathbf{V}_L= \mathbf{X}_L^\mathrm{prt}\mathbf{P}_v VL=XLprtPv,其中 P q , P k , P v \mathbf{P}_q, \mathbf{P}_k, \mathbf{P}_v Pq,Pk,Pv是可学习参数。每个头的表达式为:
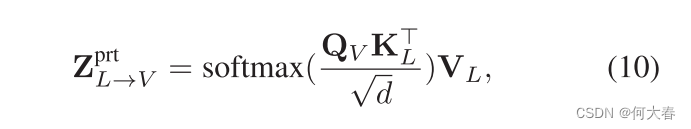
其中, Z L → V p r t \mathbf{Z}_{L\to V}^\mathrm{prt} ZL→Vprt是从语言到视觉的增强特征, d d d表示 Q V \mathbf{Q}_V QV和 K L \mathbf{K}_L KL的维度。对于MER中的三种模态,每种模态都会被另外两种模态增强,得到的特征将被连接起来。
对于每个目标模态,我们将来自其他模态的所有增强特征连接到目标模态上,作为被增强的特征,用 Z → m p r t \mathbf{Z}_{\to m}^\mathrm{prt} Z→mprt表示,这些特征在蒸馏损失函数 L d t l h e t e r o \mathcal{L}_\mathrm{dtl}^\mathrm{hetero} Ldtlhetero中使用,并且可以通过方程9自然地获得。
我们使用特征融合。我们使用增强的异质特征 Z → m p r t \mathbf{Z}_{\to m}^\mathrm{prt} Z→mprt和原始的解耦同质特征 X m c o m \mathbf{X}_m^\mathrm{com} Xmcom进行自适应特征融合,得到用于多模态情感识别的自适应融合特征。
3.3. Objective optimization
我们将上述损失综合起来,以达到全部目标:
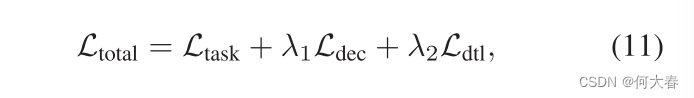
其中, L t a s k \mathcal{L}_\mathrm{task} Ltask是情感任务相关的损失(这里是均方误差), L d t l = L d t l h o m o + L d t l h e t e r o \mathcal{L}_\mathrm{dtl}=\mathcal{L}_\mathrm{dtl}^\mathrm{homo}+\mathcal{L}_\mathrm{dtl}^\mathrm{hetero} Ldtl=Ldtlhomo+Ldtlhetero表示由HomoGD和HeteroGD生成的蒸馏损失, λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2控制不同约束的重要性。
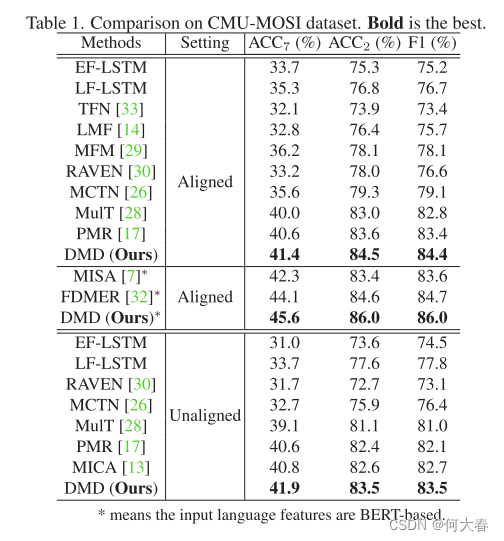
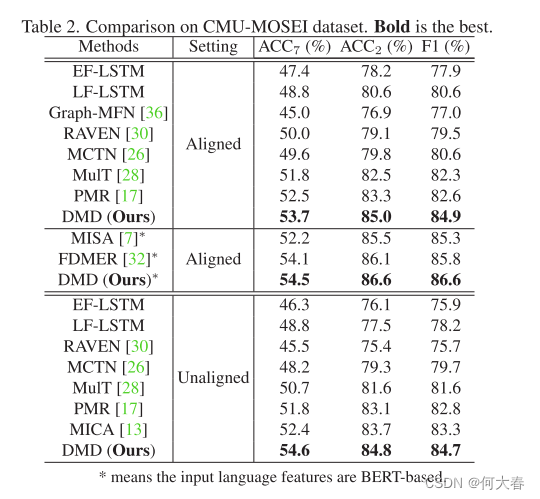
4. Experiments
5. Conclusion and discussion
在本文中,我们提出了一种用于MER的解耦多模态蒸馏方法(DMD)。我们的方法受到了不同模态贡献显著差异的观察的启发。因此,通过在模态之间蒸馏可靠且具有一般性的知识,可以实现稳健的MER。为了减轻模态异质性,DMD以自回归方式将模态特征解耦为模态无关/专属空间。每个解耦特征都包含两个GD单元,以促进自适应的跨模态蒸馏。定量和定性实验一致表明了DMD的有效性。一个限制是DMD没有明确考虑模态内部的交互作用。我们将在未来的工作中探索这一点。