欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/137269049
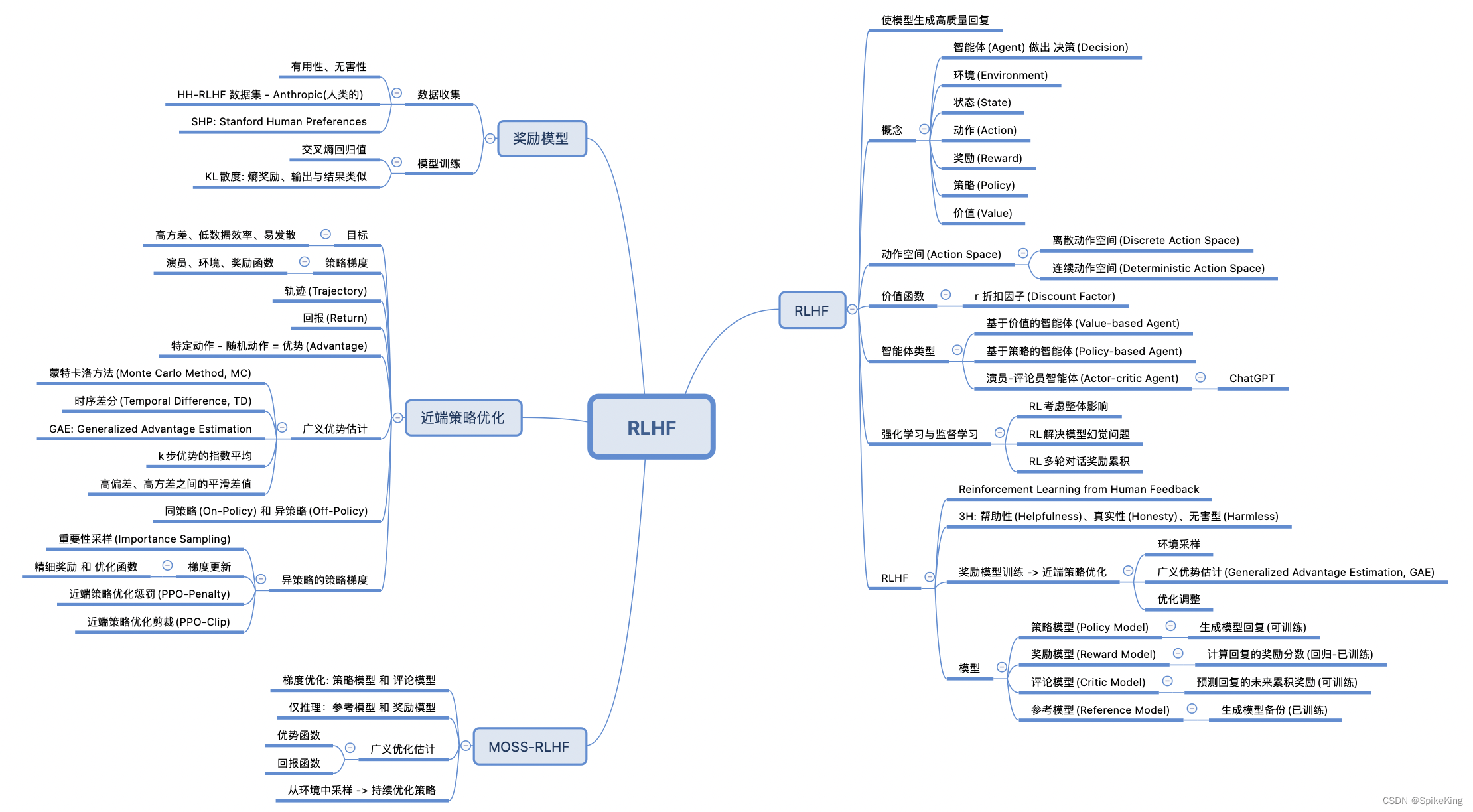
基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback),结合 强化学习(RL) 和 人类反馈 来优化模型的性能。这种方法主要包括:
- 多种策略产生样本并收集人类反馈:使用不同的策略来生成文本样本,然后,由人类评估这些样本的质量,以收集反馈数据。
- 训练奖励模型:基于收集到的人类反馈,训练奖励模型(Reward Model, RM),该模型的目标是评估模型输出的文本质量。
- 训练强化学习策略,微调语言模型:在这一步中,将初始语言模型的微调任务建模为强化学习问题,定义策略(Policy)、动作空间(Action Space)和奖励函数(Reward Function)。然后,使用近端策略优化(Proximal Policy Optimization,PPO)等算法来更新模型的参数,优化奖励函数。
通过这种方法,模型能够学习人类的偏好,并且,生成更符合

![【PyTorch][chapter 25][李宏毅深度学习][ CycleGAN]【实战】](https://img-blog.csdnimg.cn/direct/b746796bf6454d4e892a33bec050fff9.png)