视频地址:https://www.bilibili.com/video/BV1wf4y1G7EQ/
定义
Flume是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。
Flume高最要的作用就是实时读取服务器本地磁盘的数据,将数据写入HDFS。
官网:https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
源码包:https://gitee.com/apache/flume.git
架构图
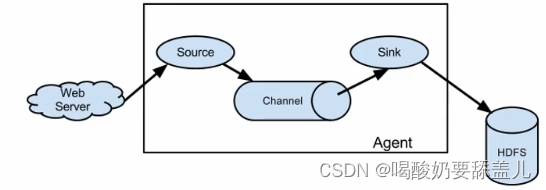
1.Agent
Agent主要有3个部分组成,Source、Channel、Sink
2.Source
Source是负责接收数据到Flume Agent的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。
3.Sink
Sink 不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink 组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
4.Channel
Channel是位于Source 和Sink之间的缓冲区。因此,Channel允许Source 和Sink 运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个
Sink 的读取操作。←Flume自带两种Channel:MemoryChannel和File Channel。Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么MemoryChanne1就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。←
FileChannel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event
传输单元,Flume数据传输的基本单元,以vent的形式将数据从源头送至目的地。Event 由Header 和 Body 两部分组成,Header 用来存放该event 的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
示例
官方文档
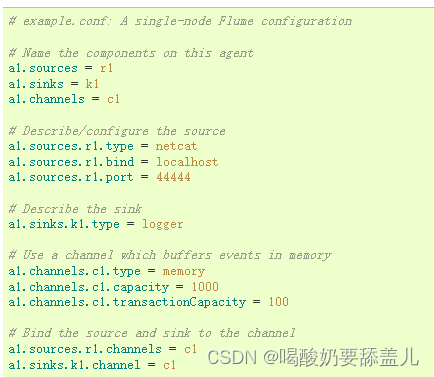
1.配置文件
# example.conf: A single-node Flume configuration# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 可以配置多个source、sink、channel
- 事务容量要比总容量小,事务容量指单次最大的事件数量
- 一个source可以绑定多个channel
- 一个sink只能绑定一个channel
- 一个channel可以绑定多个sink
2.启动命令
bin/flume-ng agent -n a1 -c conf -f conf/flume-conf
- -n --name : agent名称
- -c --conf: conf目录
- -f --conf-file: 配置文件
- -Dflume.root.logger=INFO,console 打印日志
3.Agent
3.1.内部原理
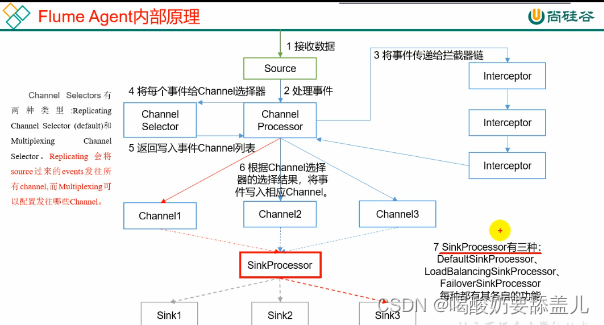
3.1.1.Channel Selectors
3.1.1.1.ReplicatingChannel Selector
(默认)将source过来的events发往所有channel

示例

3.1.1.2.MultiplexingChannel Selector
可以配置发往哪些Chanmel

示例

3.1.2.SinkProcessor
3.1.2.1.DefaultSinkProcessor
只接收一个请求,只能绑定一个Sink
3.1.2.2.LoadBalanceingSinkProcessor
负载均衡,分散到其他sink中
 示例
示例

3.1.2.3.FailoverSinkProcessor
故障转移,按优先级排序

示例

4.Source
4.1.exec
4.1.1.示例
监控文件内容

4.1.2.缺点
不能断点续传
4.2.spooldir

4.2.1.示例
监控目录中新文件

4.2.2.缺点
不能动态监听变化文件
4.3.Taildir
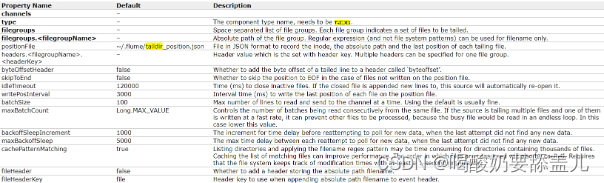
4.3.1.示例
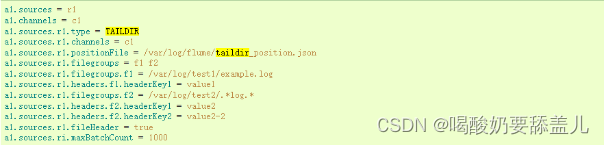
4.3.2.优点
1.监控不同目录
2.
4.4.Avro
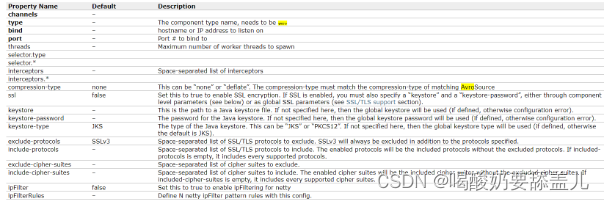
4.4.1.示例

4.4.2.缺点
5.Sink
5.1.HDFS


5.1.1.示例
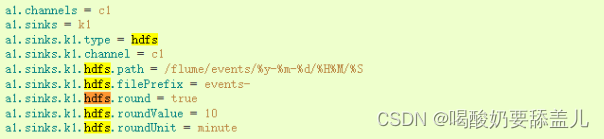
5.2.Avro

5.2.1.示例

5.3.FileRoll

5.3.1.示例

6.修改源码
下载源码:https://gitee.com/apache/flume.git
Flume拓扑结构
1.简单串联
1.1.结构图
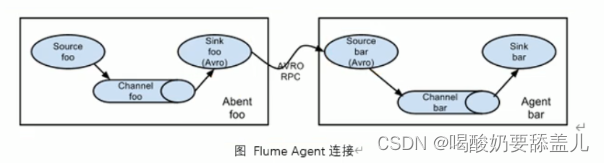
1.2.示例
2.复制和多路利用
2.1.结构图

2.2.示例
2.2.1.单数据源多出口案例
2.2.1.1.需求
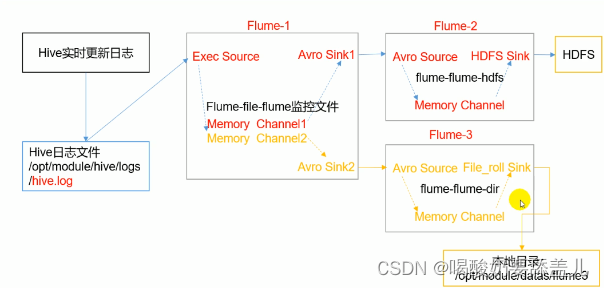
2.2.1.2.flume-file-flume.conf
# Name the comnentson this agent
a1.sources=r1
a1.channels=c1
a1.sinks = k1 k2#Describe/configure the source
a1.sources.r1.type =exec
a1.sources.r1.command=tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell= /bin/bash -c#Describe the sink
a1.sinks.kl.type =avro
a1.sinks.k1.hostname =hadoop102
a1.sinks.k1.port =4141a1.sinks.k2.type =avro
a1.sinks.k2.hostname =hadoop102
a1.sinks.k2.port =4142#Describe the channe
a1.channels.c1.type=memory
al.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100#将数据流复制给所有channele
a1.sources.r1.selector.type=relicating# Bind the source and sink to the channel
a1.sources.r1.channels=c1 c2
al.sinks.k1.channel=c1
a1.sinks.k2.

![洛谷P1000超级玛丽游戏题解[Python, Rust, Go]](https://img-blog.csdnimg.cn/direct/cd835ec5e9f541f2a262b47c1625392f.png)
![[计算机效率] 文本编辑工具:Notepad++](https://img-blog.csdnimg.cn/direct/d8b258cac2604bd3921d715b689a78de.png)



![【PyTorch][chapter 25][李宏毅深度学习][ CycleGAN]【实战】](https://img-blog.csdnimg.cn/direct/b746796bf6454d4e892a33bec050fff9.png)