论文笔记GPT1--Improving Language Understanding by Generative Pre-Training
- 1. 文章简介
- 2. 文章导读
- 2.1 概括
- 2.2 文章重点技术
- 2.2.1 无监督预训练
- 2.2.2 有监督微调
- 2.2.3 不同微调任务的输入
- 3. Bert&GPT
- 4. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:Improving Language Understanding by Generative Pre-Training
- 作者:Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
- 日期:2018
2. 文章导读
2.1 概括
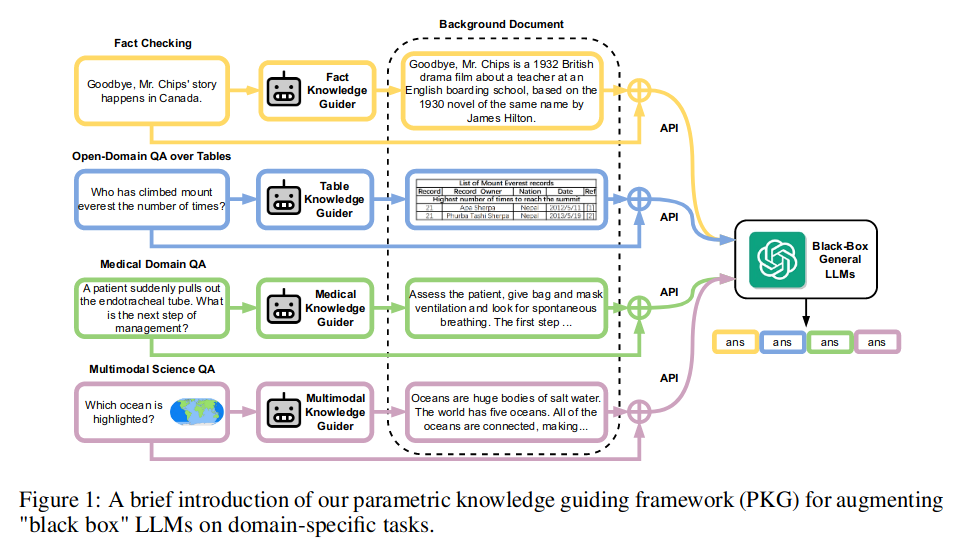
文章利用了Transformer架构,通过无监督的生成式(generative)预训练和有监督的微调相结合方式得到了适应多种NLP下游任务的模型。文章在包括文本分类、文本相似度分析、问答和知识推理四个任务的数据集上进行了数值实验。结果表明,生成式预训练在9/12个数据集上取得了State-of-the-art水平。文章提出的GPT训练方式是当前LLM的一种主流训练方式。
文章整体架构如下
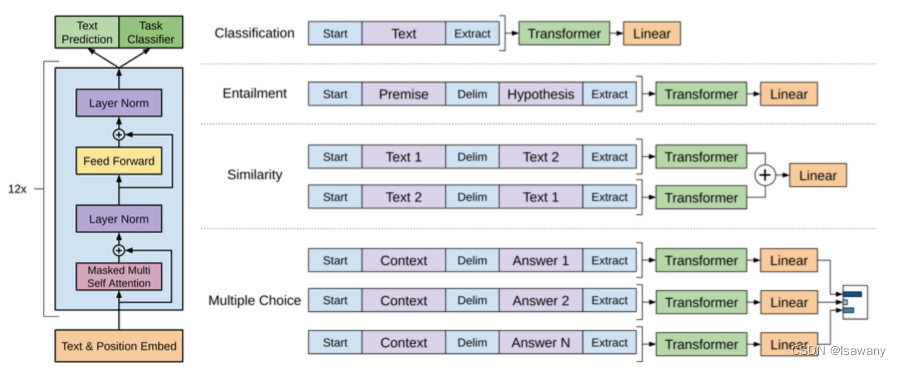
2.2 文章重点技术
2.2.1 无监督预训练
在预训练阶段,文章提出了通过生成式的预训练来学习语言结构,即通过前面的token预测当前的token,结构化表示为 L 1 ( U ) = ∑ i log P ( u i ∣ u i − 1 , … , u i − k ; Θ ) L_1(\mathcal{U}) = \sum_i \log P(u_i| u_{i-1}, \dots, u_{i-k}; \Theta) L1(U)=i∑logP(ui∣ui−1,…,ui−k;Θ),其中 k k k表示窗口大小, Θ \Theta Θ为神经网络的参数。
神经网络采用多层Transformer解码架构,相比于传统Transformer采用sin函数进行位置编码,这里通过模型学习到位置嵌入(position embedding)。其它部分则与Transformer解码部分基本一致。
2.2.2 有监督微调
得到了预训练模型之后,我们将模型在标记数据集 C \mathcal{C} C上面进行微调。给定 ( x = ( x 1 , … , x m ) , y ) ∈ C (x=(x^1, \dots, x^m), y) \in \mathcal{C} (x=(x1,…,xm),y)∈C,其中 x , y x, y x,y分别表示输入句子和对应的标注,我们首先将 x x x输入到预训练模型,得到输出 h l m h_l^m hlm,再增加一个线性层和Softmax得到输出概率 P ( y ∣ x ) = SoftMax ( h l m W y ) P(y|x) = \text{SoftMax}(h_l^m W_y) P(y∣x)=SoftMax(hlmWy),从而模型的最大似然函数为 L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x ) . L_2(\mathcal{C})= \sum_{(x, y)} \log P(y|x). L2(C)=(x,y)∑logP(y∣x).
最终模型学习的目标函数为 L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda L_1(\mathcal{C}) L3(C)=L2(C)+λL1(C),其中 λ \lambda λ表示预训练的权重。
注意,以上损失函数是针对微调任务生效的,而不是说每次都要重新训练大模型。
2.2.3 不同微调任务的输入
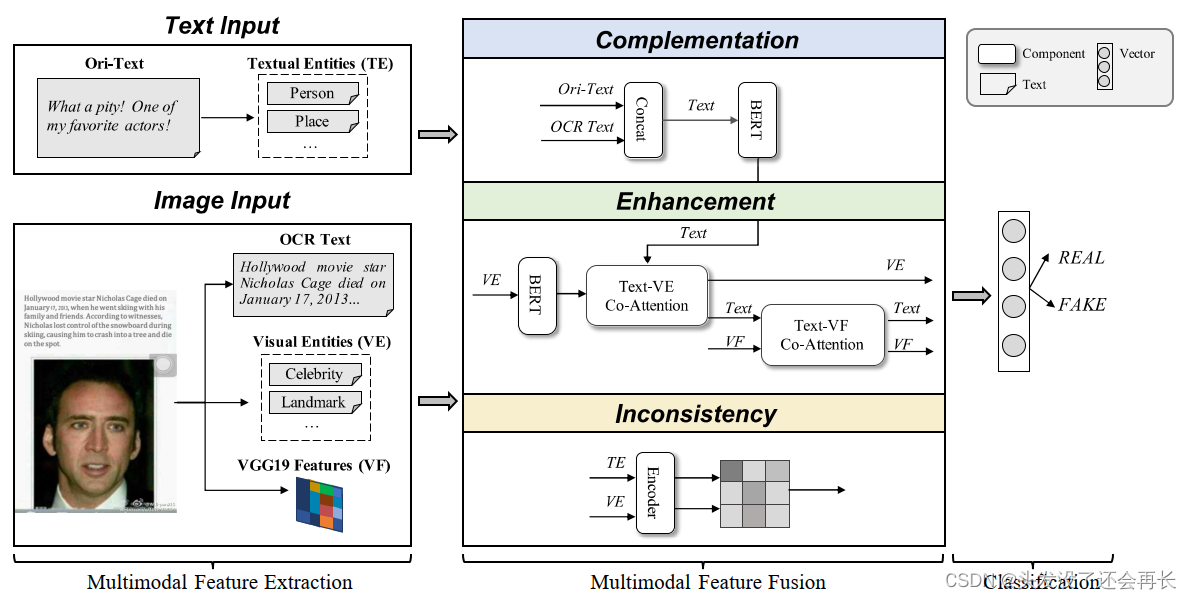
针对不同的微调任务,文章采用了traversal-style方法,即将所有输入转化为一个有序的句子(Start标志句子开始,Extract标志句子结束),从而模型可以直接处理。具体的不同任务的处理方式如下图所示。
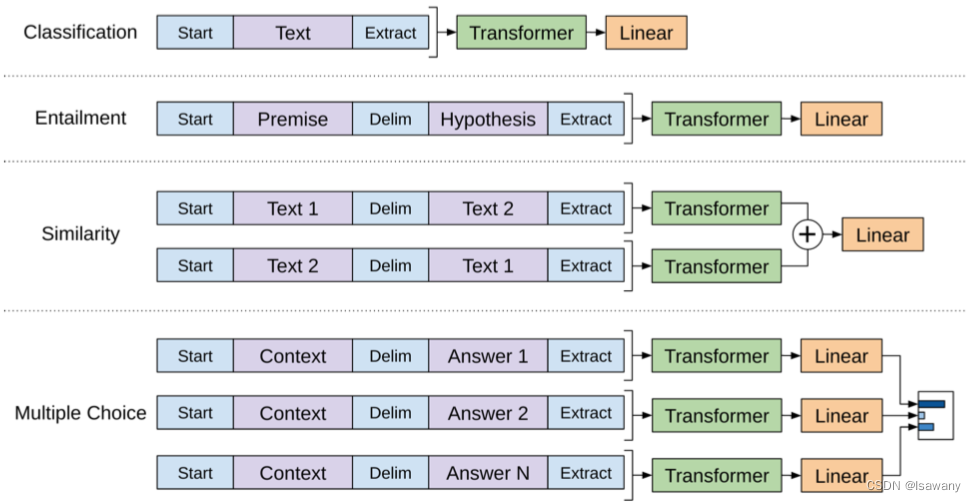
- 文本分类:直接输入当前句子
- 知识推理:输入Premise+Hypothesis,用Delim分隔
- 文本相似度:输入两个句子–Text1+Text2和Text2+Text1,均用Delim分隔,再用线性层将其结合
- 问答:输入每个可能答案的句子上下文+答案,分别送入不同的线性层,最后均喂给模型
3. Bert&GPT
Bert和GPT是当下最受欢迎的两种预训练模型。二者均采用Transformer架构,但Bert采用的是双向Transformer架构(解码部分),而GPT为单向Transformer架构(编码部分)。从预训练方式看,Bert采用的是掩码预测预测方式,而GPT采用的是生成式预训练,即通过前面的token预测当前token,这也间接要求GPT采用单向Transformer架构。
4. 文章亮点
文章提出了一种生成式预训练+微调的语言模型训练方法,更有效地捕获到语言模型结构。文章的GPT1也是后来GPT2、GPT3乃至ChatGPT的原型,是大语言模型(LLM)的一个重要里程碑。
5. 原文传送门
Improving Language Understanding by Generative Pre-Training
6. References
[1] Bert和GPT的区别
[2] GPT系列来龙去脉