目录
一、SpringData ElasticSearch
1.1、环境配置
1.2、创建实体类
1.3、ElasticsearchRestTemplate 的使用
1.3.1、创建索引 设置映射
1.3.2、创建索引映射注意事项(必看)
1.3.3、简单的增删改查
1.3.4、搜索
1.4、ElasticsearchRepository
1.4.1、使用方式
1.4.2、简单的增删改查
1.4.3、分页排序查询
一、SpringData ElasticSearch
1.1、环境配置
a)依赖如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
b)配置文件如下:
spring:elasticsearch:uris: env-base:9200
1.2、创建实体类
a)简单结构如下(后续实例,围绕此结构展开):
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType/*** @shards: 主分片数量* @replicas: 副本分片数量*/
@Document(indexName = "album_info", shards = 1, replicas = 0)
data class AlbumInfoDo(/*** @Id: 表示文档中的主键,并且会在保存在 ElasticSearch 数据结构中 {"id": "", "userId": "", "title": ""}*/@Id@Field(type = FieldType.Keyword)val id: Long? = null,/*** @Field: 描述 Java 类型中的属性映射* - name: 对应 ES 索引中的字段名. 默认和属性同名* - type: 对应字段类型,默认是 FieldType.Auto (会根据我们数据类型自动进行定义),但是建议主动定义,避免导致错误映射* - index: 是否创建索引. text 类型创建倒排索引,其他类型创建正排索引. 默认是 true* - analyzer: 分词器名称. 中文我们一般都使用 ik 分词器(ik分词器有 ik_smart 和 ik_max_word)*/@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")val title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")val content: String,
)
b)复杂嵌套结构如下:
import org.springframework.data.annotation.Id
import org.springframework.data.elasticsearch.annotations.Document
import org.springframework.data.elasticsearch.annotations.Field
import org.springframework.data.elasticsearch.annotations.FieldType@Document(indexName = "album_list")
data class AlbumListDo(@Id@Field(type = FieldType.Keyword)var id: Long,@Field(type = FieldType.Nested) // 表示一个嵌套结构var userinfo: UserInfoSimp,@Field(type = FieldType.Text, analyzer = "ik_max_word")var title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")var content: String,@Field(type = FieldType.Nested) // 表示一个嵌套结构var photos: List<AlbumPhotoSimp>,
)data class UserInfoSimp(@Field(type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word")val username: String,@Field(type = FieldType.Keyword, index = false)val avatar: String,
)data class AlbumPhotoSimp(@Field(type = FieldType.Integer, index = false)val sort: Int,@Field(type = FieldType.Keyword, index = false)val photo: String,
)
对于一个小型系统来说,一般也不会创建这种复杂程度的文档,因为会涉及到很多一致性问题, 需要通过大量的 mq 进行同步,给系统带来一定的开销.
因此,一般会将需要进行模糊查询的字段存 Document 中(es 就擅长这个),而其他数据则可以在 Document 中以 id 的形式进行存储. 这样就既可以借助 es 高效的模糊查询能力,也能减少为保证一致性而带来的系统开销. 从 es 中查到数据后,再通过其他表的 id 从数据库中拿数据即可(这点开销,相对于从大量数据的数据库中进行 like 查询,几乎可以忽略).
1.3、ElasticsearchRestTemplate 的使用
1.3.1、创建索引 设置映射
@SpringBootTest(classes = [DataEsApplication::class])
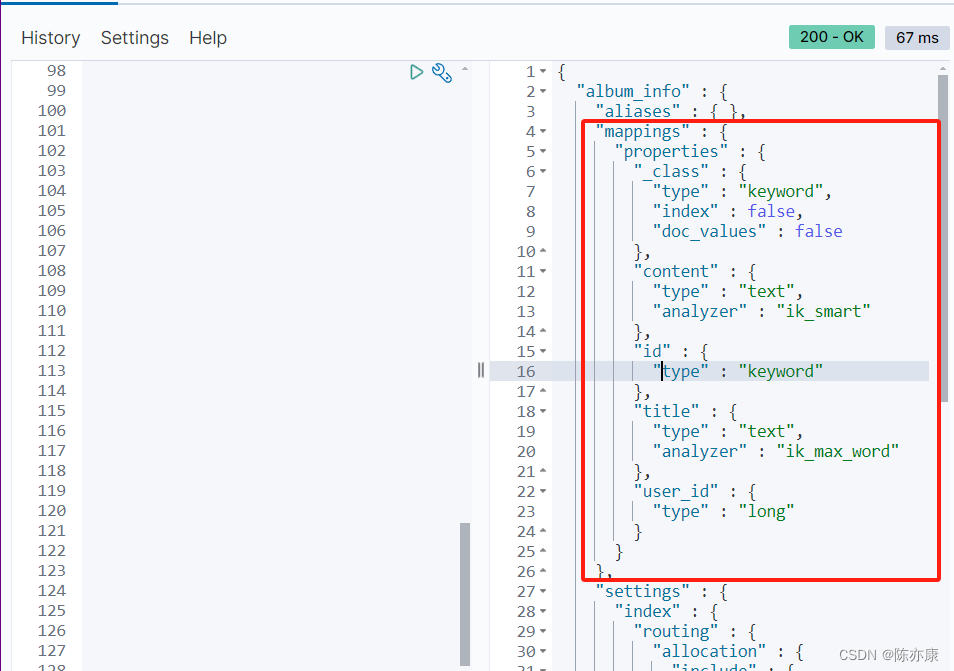
class DataEsApplicationTests {@Resource private lateinit var elasticsearchTemplate: ElasticsearchRestTemplate@Testfun test1() {//创建索引elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).create()//设置映射elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).putMapping(elasticsearchTemplate.indexOps(AlbumInfoDo::class.java).createMapping())}}
效果如下:
1.3.2、创建索引映射注意事项(必看)
a)在没有创建索引库和映射的情况下,也可以直接向 es 库中插入数据,如下代码:
@Testfun test1() {val o = AlbumListDo(id = 1,userinfo = UserInfoSimp(userId = 1,username = "cyk",avatar = "http:photo1.com"),title = "天气很好的一天",content = "早上起来,我要好好学习,然去公园散步~",photos = listOf(AlbumPhotoSimp(1, "www.photo1"),AlbumPhotoSimp(2, "www.photo2")))val result = esTemplate.save(o)println(result)}
b)即使上述代码中 AlbumListDo 中有各种注解标记,但是不会生效!!! es 会根据插入的数据,自动转化数据结构(无视你的注解).
c)因此,一定要先创建索引库和映射,再进行数据插入!
1.3.3、简单的增删改查
/*** 更新和添加都是这样* 更新的时候会根据 id 进行覆盖*/@Testfun testSave() {//保存单条数据val a1 = AlbumInfoDo(id = 1,userId = 10000,title = "今天天气真好",content = "学习完之后,我要出去好好玩")val result = elasticsearchTemplate.save(a1)println(result)//保存多条数据val list = listOf(AlbumInfoDo(2, 10000, "西安六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumInfoDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumInfoDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多"))val resultList = elasticsearchTemplate.save(list)resultList.forEach(::println)}@Testfun testDelete() {//根据主键删除elasticsearchTemplate.delete("1", AlbumInfoDo::class.java)}@Testfun testGet() {val result = elasticsearchTemplate.get("1", AlbumInfoDo::class.java)println(result)}
补充一个修改:
override fun update(msg: UpdateAlbumInfoMsg): Int {val query = UpdateQuery.builder(msg.albumId.toString()) //指定修改的文档 id.withDocument(org.springframework.data.elasticsearch.core.document.Document.create() //指定修改字段.append("title", msg.title) .append("content", msg.content).append("ut_time", msg.utTime)).build()val result = restTemplate.update(query, IndexCoordinates.of("album_doc")).resultreturn result.ordinal}
1.3.4、搜索
a)一般搜索
import org.cyk.dataes.model.AlbumInfoDo
import org.elasticsearch.index.query.QueryBuilders
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.domain.PageRequest
import org.springframework.data.domain.Sort
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class TemplateTests {@Resource private lateinit var elasticsearchTemplate: ElasticsearchRestTemplate/*** 全文检索查询(match_all)*/@Testfun testMatchAllQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)println("总数为: ${hits.totalHits}")hits.forEach { println(it.content) }}/*** 全文检索查询(match)*/@Testfun testMatchQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "天气")).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 精确查询(term)*/@Testfun testTerm() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.termQuery("user_id", 10001)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 范围查询*/@Testfun testRangeQuery() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.rangeQuery("id").gte(1).lt(4)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 复合查询(bool)*/@Testfun testBoolQuery() {val boolQuery = QueryBuilders.boolQuery()//必要条件: query.must 得到一个集合val mustList = boolQuery.must()mustList.add(QueryBuilders.rangeQuery("user_id").gte(10000).lt(10003))//其他的搜索条件集合的获取方式类似val mustNotList = boolQuery.mustNot()val should = boolQuery.should()//当然,还有一种简化的写法,如下,下述代码相当于 query.should().add(QueryBuilders.matchAllQuery())boolQuery.should(QueryBuilders.matchAllQuery())val query = NativeSearchQueryBuilder().withQuery(boolQuery).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach { println(it.content) }}/*** 排序和分页*/@Testfun testSortAndPage() {val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).withPageable(PageRequest.of(0, 3) //参数一: 页码(从 0 开始),size 每页查询多少条数据.withSort(Sort.by(Sort.Order.desc("id"))) //根据 id 降序排序(这里也可以根据多个字段进行升序降序)).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)hits.forEach{ println(it.content) }}/*** 高亮搜索*/@Testfun testHighLight() {//定义高亮字段val field = HighlightBuilder.Field("title")//a) 前缀标签field.preTags("<span style='color:red'>")//b) 后缀标签field.postTags("</span>")//c) 高亮的片段长度(多少个几个字需要高亮,一般会设置的大一些,让匹配到的字段尽量都高亮)field.fragmentSize(10)//d) 高亮片段的数量field.numOfFragments(1)// withHighlightFields(Field... 高亮字段数组)val query = NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "天气")).withHighlightFields(field).build()val hits = elasticsearchTemplate.search(query, AlbumInfoDo::class.java)//注意,hit.content 中本身是没有高亮数据的,因此这里需要手工处理hits.forEach {val result = it.content//根据高亮字段名称,获取高亮数据集合,结果是 List<String>val hList = it.getHighlightField("title")if(hList.size > 0) {//有高亮数据result.title = hList.get(0)}println(result)}}}
b)基于 completionSuggestion 实现自动补全
data 如下:
@Document(indexName = "album_doc")
data class AlbumDocDo (@Id@Field(type = FieldType.Keyword)val id: Long,@Field(name = "user_id", type = FieldType.Long)val userId: Long,@Field(type = FieldType.Text, analyzer = "ik_max_word", copyTo = ["suggestion"])val title: String,@Field(type = FieldType.Text, analyzer = "ik_smart")val content: String,@Field(name = "ct_time", type = FieldType.Long)val ctTime: Long,@Field(name = "ut_time", type = FieldType.Long)val utTime: Long,@CompletionField(maxInputLength = 100, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")val suggestion: Completion? = null,
)
自动补全的字段必须是 completion 类型. 自动补全字段为 title,将他 copy 到了 suggestion 字段,实现自动补全.
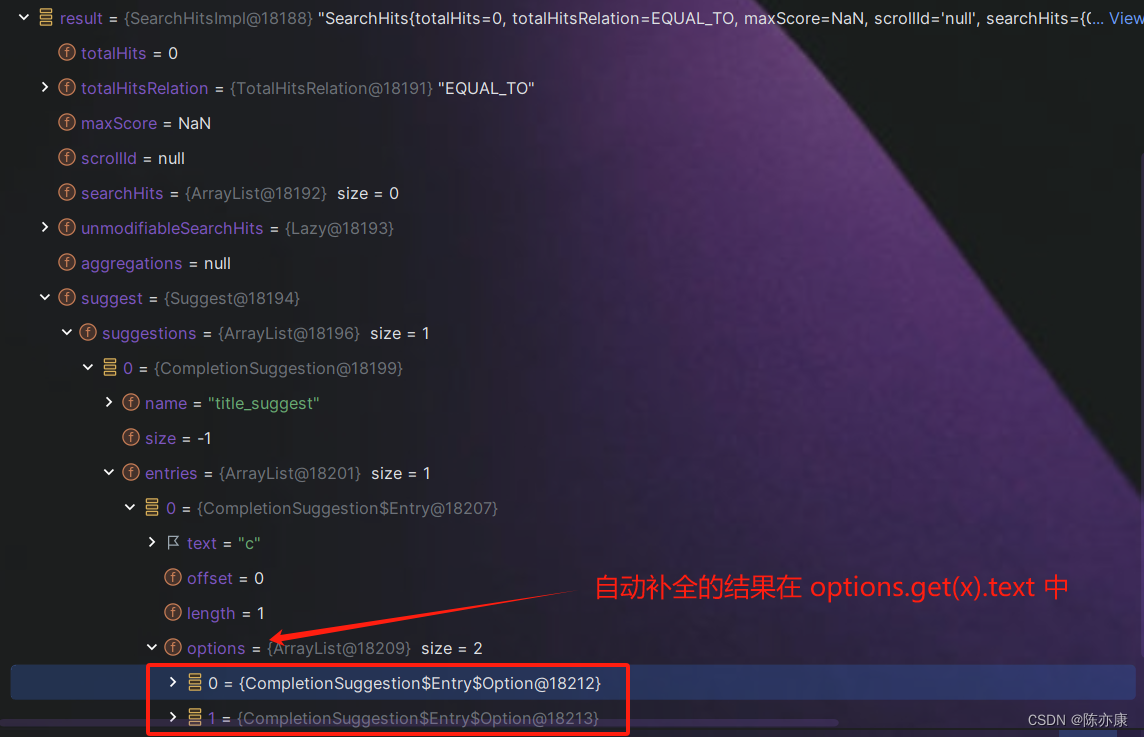
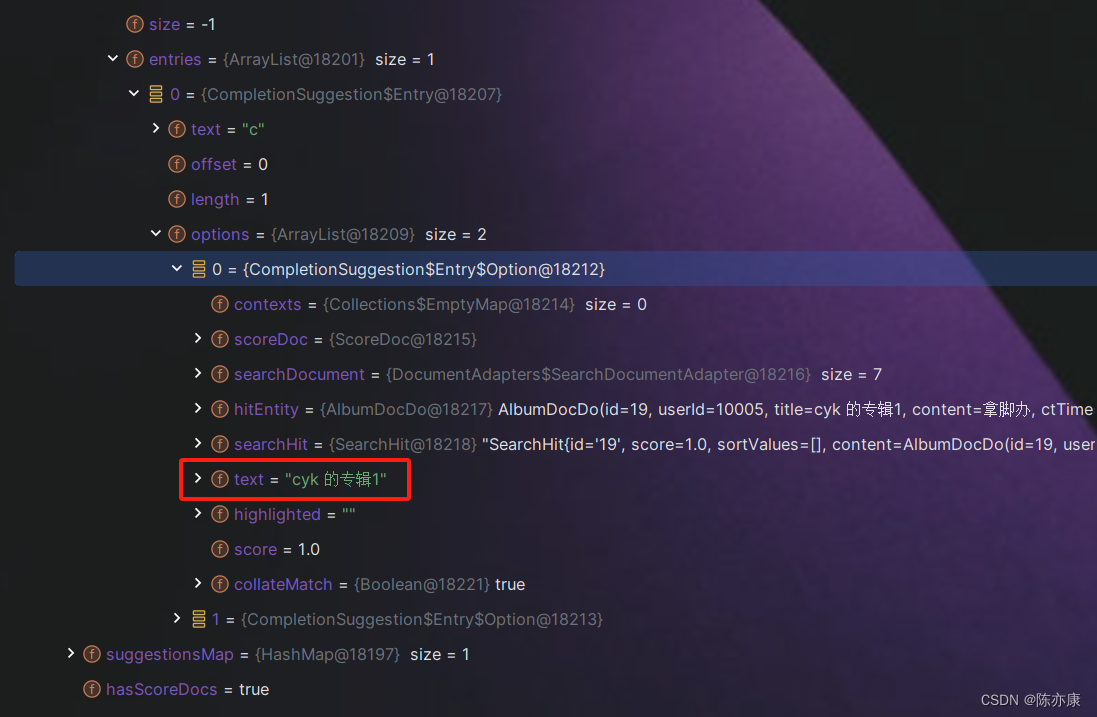
override fun suggestTexts(o: AlbumSuggestDto): List<String> {val suggest = SuggestBuilder().addSuggestion("title_suggest", //自定义补全名SuggestBuilders.completionSuggestion("suggestion") //自动补全时需要查询的字段.prefix(o.text) //要进行补全的值(用户搜索框中输入的).skipDuplicates(true) //如果查询时有重复的词条,是否自动跳过(true 为跳过).size(o.limit) //获取多少个结果)val query = NativeSearchQueryBuilder().withSuggestBuilder(suggest).build()val hits = restTemplate.search(query, AlbumDocDo::class.java)val suggests = hits.suggest?.getSuggestion("title_suggest") //根据自定义补全名获取对应的补全结果集?.entries?.get(0) //结果集(记录了根据什么前缀(prefix)进行自动补全,补全的结果对象...)?.options?.map(::map) ?: emptyList() //补全的结果对象(其中 text 就是自动补全的结果)return suggests}private fun map(hit: Suggest.Suggestion.Entry.Option): String {return hit.text}
例如需要自动补全 "c",result 结构如下
1.4、ElasticsearchRepository
1.4.1、使用方式
这个东西就跟 JPA 的使用方式一样,只不过高版本的 SpringData Elasticsearch 没有给 ElasticsearchRepository 接口提供复杂搜索查询,建议还是使用 ElasticsearchTemplate
自定义一个接口, 继承 ElasticsearchRepository 接口,如下:
import org.cyk.dataes.model.AlbumInfoDo
import org.springframework.data.elasticsearch.repository.ElasticsearchRepositoryinterface AlbumInfoRepo: ElasticsearchRepository<AlbumInfoDo, Long> //<实体类,主键类型>
1.4.2、简单的增删改查
import org.cyk.dataes.model.AlbumInfoDo
import org.cyk.dataes.service.AlbumInfoESRepo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class RepoTests {@Resource private lateinit var albumInfoESRepo: AlbumInfoESRepo@Testfun testSave() {//增加单个val a = AlbumInfoDo(1, 10000, "今天天气真好", "学习完之后,我要出去好好玩")val result = albumInfoESRepo.save(a)println(result)//批量新增val list = listOf(AlbumInfoDo(2, 10000, "西安六号线避雷", "前俯后仰。他就一直在那前后动。他背后是我朋友,我让他不要挤了,他直接就急了,开始故意很大力的挤来挤去。"),AlbumInfoDo(3, 10000, "字节跳动快上车~", "#内推 #字节跳动内推 #互联网"),AlbumInfoDo(4, 10000, "连王思聪也变得低调老实了", "如今的王思聪,不仅交女友的质量下降,在网上也不再像以前那样随意喷这喷那。显然,资金的紧张让他低调了许多"))val resultList = albumInfoESRepo.saveAll(list)resultList.forEach(::println)}@Testfun testDel() {//根据 id 删除albumInfoESRepo.deleteById(1)//删除所有albumInfoESRepo.deleteAll()}@Testfun testFind() {//查询所有val resultList = albumInfoESRepo.findAll()resultList.forEach(::println)//根据 id 查询val result = albumInfoESRepo.findById(1)println(result.get())}}
1.4.3、分页排序查询
import org.cyk.dataes.service.AlbumInfoESRepo
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.data.domain.PageRequest
import org.springframework.data.domain.Sort
import javax.annotation.Resource@SpringBootTest(classes = [DataEsApplication::class])
class RepoTests2 {@Resourceprivate lateinit var albumInfoESRepo: AlbumInfoESRepo@Testfun testFindPageAndSort() {//从 0 下标开始向后获取 3 个,并根据 id 降序排序val result = albumInfoESRepo.findAll(PageRequest.of(0, 3,Sort.by(Sort.Direction.DESC, "id")))result.content.forEach(::println)}}







![[WinForm开源]原神混池模拟器-蒙德篇:软件的基本介绍、使用方法、常见问题解决与代码开源](https://img-blog.csdnimg.cn/direct/bb8f21542c99420aae39e801b56d2226.png)